 Недавно мы рассказывали здесь о том, как делался проект «Весь Толстой в один клик». С помощью 3249 (трех тысяч двухсот сорока девяти) волонтеров и 1 (одной) хорошей OCR-технологии мы оцифровали 46820 страниц 90-томного собрания сочинений писателя, тщательно вычитали их и выложили во всеобщий доступ.
Недавно мы рассказывали здесь о том, как делался проект «Весь Толстой в один клик». С помощью 3249 (трех тысяч двухсот сорока девяти) волонтеров и 1 (одной) хорошей OCR-технологии мы оцифровали 46820 страниц 90-томного собрания сочинений писателя, тщательно вычитали их и выложили во всеобщий доступ. Но если вы думали, что наш «роман с Толстым» на этом закончился, то вы ошибались – оцифровав тексты писателя, мы начали исследовать их при помощи технологии извлечения информации ABBYY Compreno – не пропадать же такому богатому материалу. О том, что дал нам «text mining Толстого» и где теперь используются полученные результаты, читайте дальше.
Введение
Главной целью проекта «Весь Толстой в один клик» было сделать творчество Толстого по-настоящему всеобщим достоянием, чтобы все вышедшие из-под его пера тексты были доступны в один клик в любой точке Земли. Как, кстати, и завещал сам автор, еще при жизни отказавшийся от всех прав на свои тексты (да-да, анонимус, Лев Толстой знал про копилефт и опендату задолго до этих ваших интернетов и Ричарда Столлмана).
Однако возможность загрузить книжку в удобном формате в ридер или планшет – не единственный плюс оцифровки. Теперь тексты Толстого можно не только читать, но и «измерять», то есть исследовать разными количественными методами, используя весь арсенал средств автоматической обработки текста (АОТ, она же NLP). Ведь если у вас есть все тексты писателя в электронном виде, даже с помощью одного-двух грамотных поисковых запросов вы можете получить любопытные данные, на добычу которых в иные времена мог потратить недели и месяцы упорного труда какой-нибудь литературовед. А уж если у вас к тому же имеется продвинутая технология анализа естественного языка, то есть шансы сделать серьезное филологическое открытие (даже не будучи филологом). Ниже я расскажу, что удалось намерить и узнать нам, но перед этим – пара слов о том, кто, как и зачем занимается автоматической обработкой художественных текстов и что интересного может при этом получиться.
Лирическое отступление: Distant Reading и «вычислительная филология»
В 2010 году Google насчитал в мире 130 миллионов книг, причем к этой статистике было приписано «по крайней мере, до воскресенья». Сегодня их наверняка на несколько миллионов больше. Само по себе это не проблема – и так понятно, что читать «все обо всем» – плохая идея
Возможное (хотя и спорное) решение этой проблемы одним из первых предложил эпатажный критик и бывший неомарксист Франко Моретти, возглавляющий ныне Stanford Literary Lab. Он заявил, что литературоведы сегодня должны «прекратить читать книги и начать считать, картографировать и визуализировать их». Обычному чтению (close reading) Моретти противопоставляет чтение «удаленное» (distant reading), то есть автоматический анализ текстовых корпусов, подсчет статистики, построение графов и т.п. По его мнению, только так мы можем сделать литературоведение «объективным» и избежать выводов, сделанных на базе «смехотворно маленькой» выборки. Результаты исследований Stanford Literary Lab, выполненных в духе «distant reading», можно посмотреть здесь.
«Дистанционное чтение» с помощью Compreno
Исследователи из Стэнфорда в основном используют самую простую статистику – например, частотность слов и N-граммов и их распределение по тексту. Мы же с самого начала решили исследовать такие аспекты художественного текста, которые нельзя вытащить простым Ctrl+F. Например, речевую активность героев: попробуйте сходу посчитать, сколько раз говорит что-нибудь Наташа Ростова (или любой другой персонаж). Довольно быстро вы поймете, что для этого вам, во-первых, неплохо бы уметь автоматически разрешать местоименную анафору (для примеров типа «Наташа стала надевать платье. — Сейчас, сейчас, не ходи, папа, — крикнула она отцу»), во-вторых, каким-то образом ограничить набор глаголов, которыми может выражаться факт «говорения» (а они довольно разнообразны), а в третьих, иметь как минимум автоматическую морфологию, а лучше еще и синтаксис (т.к. порядок слов свободный, и не так просто отыскать говорящего в примерах типа «Он никогда не благословлял своих детей и только, подставив ей щетинистую, еще небритую нынче щеку, сказал, строго и вместе с тем внимательно-нежно оглядев ее: — Здорова?.. ну, так садись!»).
К счастью, все это уже «зашито» в Compreno. Синтактико-семантические деревья, которые выдает парсер, содержат всю необходимую информацию о том, кто что и как сказал, в них уже снята синтаксическая и лексическая омонимия и разрешена местоименная анафора. Например, в таком фрагменте «Неужели? — воскликнула Анна Михайловна. — Ах, это ужасно! Страшно подумать… Это мой сын, — прибавила она, указывая на Бориса. — Он сам хотел благодарить вас» надо понять, кто такая она, и правильно определить семантический класс многозначного глагола прибавить. Compreno справляется с обеими задачами – так выглядит поддерево для «прибавила она, указывая на Бориса»:

Получать из таких деревьев упоминания персонажей и нужные сведения о них позволяет наш механизм извлечения информации, который мы уже не единожды описывали здесь с разных сторон (раз, два). Благодаря опоре на глубинный синтаксис и семантическую иерархию мы можем покрыть большой класс случаев 1-2 древесными шаблонами. Например, правило, которое ищет такую структуру:

сработает на таких разных примерах, как:
— А меня хотите поцеловать? — прошептала она чуть слышно, исподлобья глядя на него, улыбаясь и чуть не плача от волненья.
Денисов, ты этим не шути,- крикнул Ростов,- это такое высокое, такое прекрасное чувство, такое…
Тише, тише, разве нельзя тише? — видимо более страдая, чем умирающий солдат, проговорил государь и отъехал прочь.
Тетушка прокашлялась, проглотила слюни и по-французски сказала, что она очень рада видеть Элен;
Помимо речевой активности, мы исследовали и некоторые другие аспекты поведения героев Толстого. Ниже я расскажу о том, что нам удалось узнать.
Импульсивная Наташа Ростова и невозмутимый Андрей Болконский: что удалось понять с помощью Compreno
Для начала мы просто подсчитали, сколько раз каждый персонаж «Войны и мира» выступает с каким-либо высказыванием, и составили топ самых «разговорчивых» героев в абсолютных цифрах. Тех, кто знаком с содержанием романа, он вряд ли удивит:
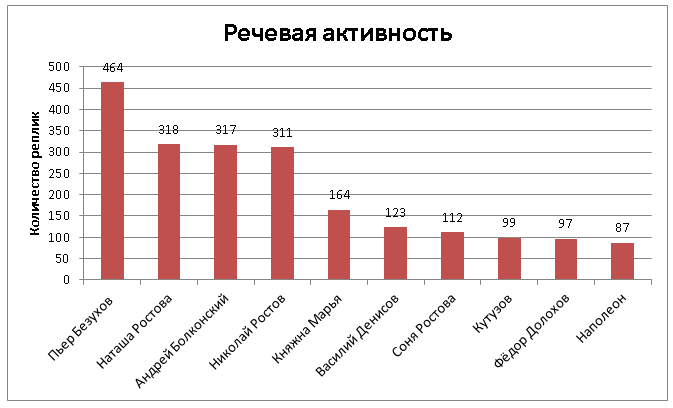
Здесь частотность, по-видимому, является не более чем индикатором «центральности» персонажа.
Если нормировать полученные цифры на общее количество упоминаний в тексте (предварительно убрав слишком малочастотных героев), наш топ заметно меняется:
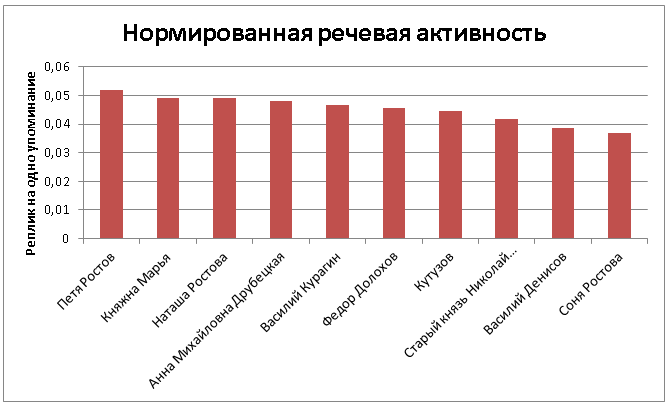
Теперь наверху Петя Ростов – эмоциональный и разговорчивый ребенок в первом томе, юный восторженный романтик-подросток – в четвертом (вплоть до собственной гибели). Следом идут три женских персонажа – княжна Марья, тихая, скромная и измученная строгим отцом, которую мы узнаем главным образом по разговорам с другими персонажами и внутреннему монологу, Наташа Ростова, непосредственная и живая героиня, чьи реплики читатель слышит на протяжении всего романа (в первом томе ей 13 лет, в эпилоге – 29), и Анна Друбецкая, деятельная интриганка, способная уболтать любого нужного ей человека into submission.
Здесь надо сказать, что Толстой считал важным снабжать каждого персонажа собственным стилем речи – это было частью его творческого метода. Даже свою общеизвестную нелюбовь к Шекспиру («признанные всем миром за гениальные художественные произведения сочинения Шекспира <…> были мне отвратительны») он объяснял именно тем, что якобы «у Шекспира отсутствует главное, если не единственное средство изображения характеров, «язык», то есть то, чтобы каждое лицо говорило своим, свойственным его характеру, языком». Поэтому на следующем этапе мы попытались выделить какие-то значимые параметры, по которым речь персонажей может устойчиво различаться.
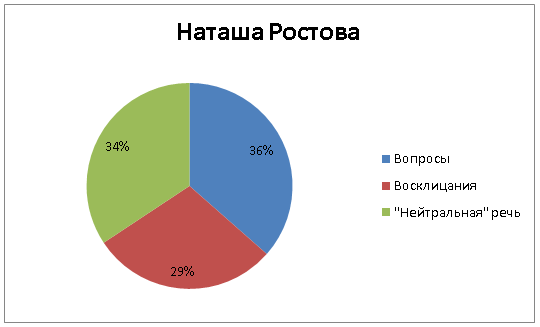
Первый напрашивающийся параметр – количество восклицательных и вопросительных предложений. По соотношению вопросов, восклицаний и всей прочей (условно нейтральной) речи уже можно довольно много понять о персонаже. Сравним трех молодых Ростовых, Андрея Болконского и Пьера Безухова. Предсказуемый чемпион по восклицаниям – младший из Ростовых, Петя:
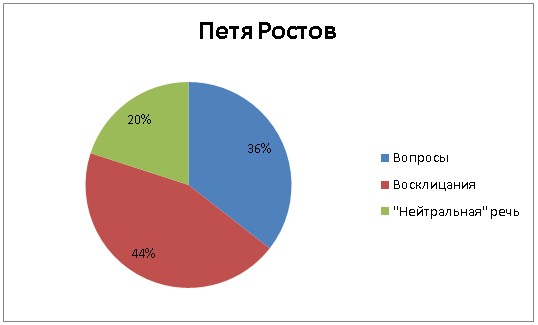
Наташа старше Пети и проявляет чуть больше сдержанности, но все равно остается весьма эмоциональной, лишь треть ее речи условно «нейтральна»:
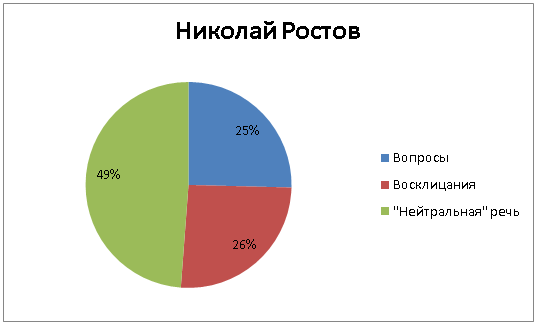
Старший брат Пети и Наташи Николай восклицает и спрашивает еще меньше, однако до половины доля нейтральной речи не дотягивает – как и все Ростовы, он тоже весьма эмоционален:
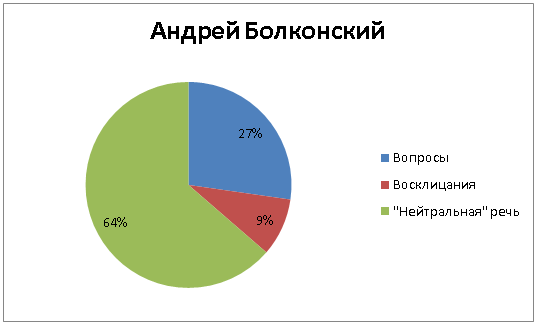
Другое дело – князь Андрей Болконский, безупречно выдержанный, гордый, относящийся к светскому обществу с холодным презрением и проявляющий эмоции лишь в кругу близких людей (не зря в оскароносной советской экранизации его играл волевой красавец Вячеслав «Штирлиц» Тихонов). Болконский совсем мало восклицает, да и спрашивает он относительно немного:
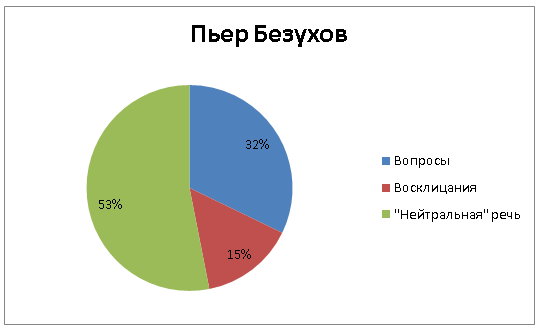
Пьер Безухов – пожалуй, самый рефлексирующий персонаж романа. Он явно более эмоционален, чем Андрей Болконский, но не в сторону «восклицаний», как вся семья Ростовых. Пьер восклицает редко, зато спрашивает почти так же часто, как совсем по-детски непосредственные Петя с Наташей:
Также с помощью Compreno можно легко получить характеристику, которую Толстой дает самому акту произнесения речи, и это тоже может выступать своеобразным параметром. Чаще всего такая характеристика выражена в виде деепричастного оборота, присоединенного к глаголу говорения (закричал Пьер, решительным и пьяным жестом ударяя по столу) или дополнения в творительном падеже с предлогом с (спрашивал князь Василий еще с большим, чем прежде, подергиванием щек). Например, речь богатого, важного и корыстного князя Василия Курагина чаще, чем у других персонажей, сопровождается деепричастными оборотами, в которых характеризуется либо его внешность (потирая лысину, оправляя жабо), либо скрытые намерения, свойства характера, движения души (говоря вещи, которым он и не хотел, чтобы верили, с злобой придвигая к себе отодвинутый столик); Анна Михайловна Друбецкая, вечно лебезящая перед героями, от которых ей что-то нужно, часто говорит «улыбаясь» или «с улыбкой»; у флегматичного, постоянно сонного Кутузова говорение часто сопровождается движением головы: он то кивает ей, то опускает ее.
Чувствительная Марья Болконская и интриги вокруг наследства Пьера: глубинный синтаксис «Войны и мира»
В нашем следующем микроисследовании мы решили не ограничиваться речевой активностью и рассматривать все ситуации «активности» героя в тексте. Для этого мы собрали статистику по глубинным позициям, в которые попадают персонажи под различными предикатами. Глубинные позиции в деревьях Compreno схожи с семантическими ролями: например, если герой совершает активное действие (говорит, идет, стреляет, бьет), он попадает в позицию агента (Agent); если оказывается в роли пассивного объекта внешнего воздействия (его ругают, везут, бьют, хвалят, любят), попадает в позицию объекта (Object), если он воспринимает, видит, слышит, чувствует или, например, любит что-либо, то становится экспериенцером (Experiencer); если выступает адресатом сообщения (сказала она Пьеру), попадает в позицию адресата (Addressee). Есть и другие позиции (всего их в нашей модели около 500), но здесь мы используем лишь несколько наиболее распространенных из числа тех, что могут появляться под предикатом.
Важно, что глубинные позиции отражают именно смысловые роли участника речевой ситуации и не зависят напрямую от конкретной реализации в предложении. Так, во фразах Пьер любил Наташу и Наташа была любима Пьером Пьер окажется экспериенцером, а Наташа – объектом вне зависимости от залога.
Оказалось, что статистика по глубинным позициям позволяет получить некоторую информацию о различиях в характерах героев и дает «объективное» подтверждение тем образам, которые формируются у читателя во время знакомства с романом. Посмотрим на диаграмму, где представлены доли выбранных нами глубинных позиций для основных героев в первом томе «Войны и мира»:
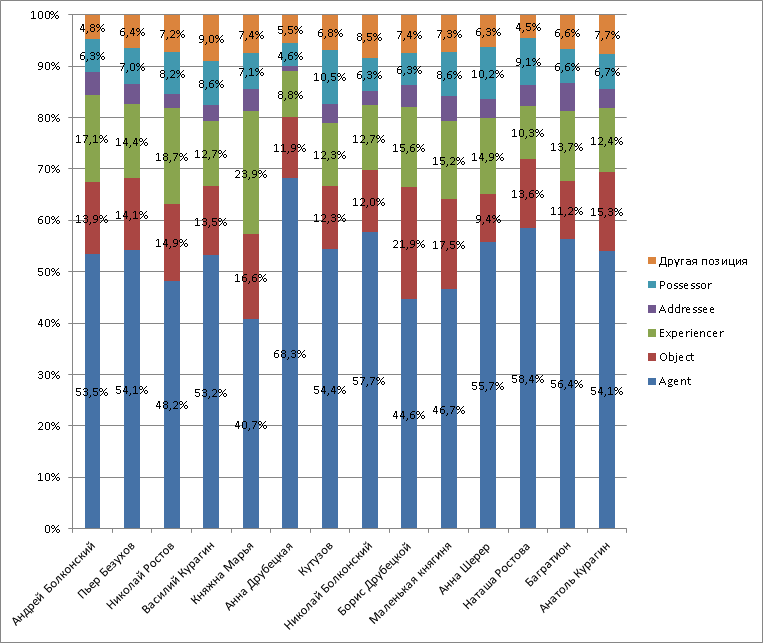
В целом распределения частотностей выглядят похожими, и довольно предсказуемо наиболее частотной позицией для всех героев оказалась агентивная. Однако разброс здесь достаточно велик – от 40,7% у княжны Марьи и 44,6% у Бориса Друбецкого до 68,3% у Анны Друбецкой. Эти три «экстремальных» персонажа и представляют интерес.
Княжна Марья примечательна, в первую очередь, аномально высокой частотностью попадания в позицию экспериенцера. В сочетании с низкой частотностью агентивных употреблений это дает нам портрет персонажа много чувствующего, но мало действующего, что для первого тома полностью соответствует действительности. Сестра Андрея Болконского вместе с отцом – старым, педантичным и строгим до самодурства екатерининским генералом – «безвыездно» живет в имении в Лысых Горах, проводя время в переписке с братом и подругой Жюли, общении с богомольцами и занятиях алгеброй и геометрией, которые устраивает ей старый князь. В поле зрения читателя она появляется исключительно в связи с приездами в Лысые Горы других героев. Литературоведы считают, что образ княжны Марьи создан Толстым под сильным влиянием сентиментализма XVIII века.
Чемпионство Анны Друбецкой по доле агентивных употреблений также легко объяснимо сюжетом первого тома. Эта немолодая дама знатной фамилии, но очень скромного состояния в начале романа развивает бурную деятельность, конечной целью которой является благополучие и продвижение по службе ее единственного сына Бориса. Она описывается как «одна из тех женщин, особенно матерей, которые, однажды взяв себе что-нибудь в голову, не отстанут до тех пор, пока не исполнят их желания, а в противном случае готовы на ежедневные, ежеминутные приставания и даже на сцены». Сначала Анна Михайловна осаждает богатого и влиятельного князя Василия, добиваясь перевода сына в гвардию, затем успешно интригует против него же за наследство графа Безухова, одновременно добывая у Ростовых деньги, чтобы «обмундировать Бориса».
Сам Борис пока еще не стал таким же циничным, ловким и корыстолюбивым, как мать, – это случится в следующих томах. Он не желает переступать через собственную гордость, а потому противится просьбам Анны Михайловны быть «милым», «ласковым» и «внимательным» во время визитов к важным персонам и крайне неохотно участвует в ее хлопотах, выступая в роли пассивного объекта. Пассивность Бориса отражается на нашем графике большой долей объектной глубинной позиции.
«Толстая шея» Наташи в вашем смартфоне: оживляем «Войну и мир»
Попытки «подсчитать» литературу часто вызывают критику в том духе, что, мол, авторы пытаются измерить неизмеримое и тем самым опошляют и выхолащивают нетленное произведение классика. Интересно, что такие обвинения звучали еще 100 лет назад, когда никакого distant reading и в помине не было. «Считалось, что изучать самое произведение – значит анатомировать его, а для этого надо, как известно, сначала убить живое существо. Нас постоянно упрекали в этом преступлении», – писал в 1921 году Борис Эйхенбаум, один из крупнейших представителей формального метода в литературоведении (а формалисты тех времен были чем-то вроде людей, придумавших distant reading в теории задолго до изобретения компьютера и не имеющих возможности попробовать его на практике).
Чтобы и нас не обвинили в «убийстве» романа, мы решили заниматься прямо противоположным делом, то есть его оживлением. С этой целью мы вместе с коллегами из Высшей школы экономики присоединились к разработке мобильного приложения «Живые страницы» компании Samsung, в котором теперь используются результаты работы системы извлечения информации на базе ABBYY Compreno.
В приложении «Живые страницы» реализованы несколько нестандартных сценариев знакомства с художественными произведениями и их героями – таймлайны с событиями и судьбами, карточки и «цитатники» персонажей, интерактивные карты с привязкой мест к эпизодам романа.

Все это опирается на инфографику, сделано в игровом стиле и, как нам кажется, имеет больше шансов зацепить десятиклассника-гаджетомана с ADD, чем толстый том, который вручит ему школьная библиотекарша.

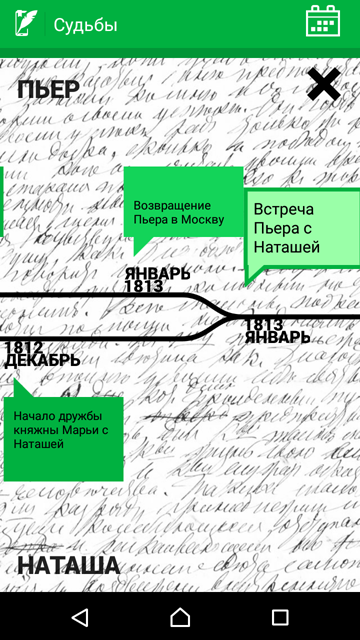
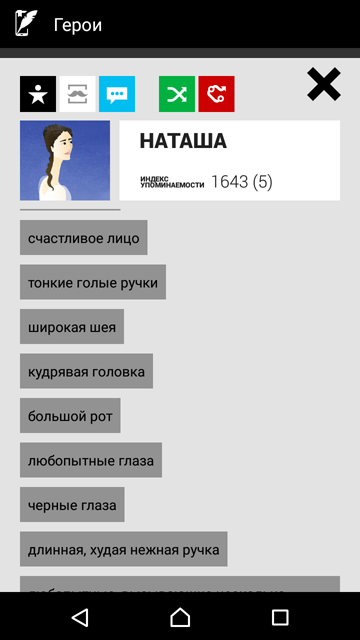
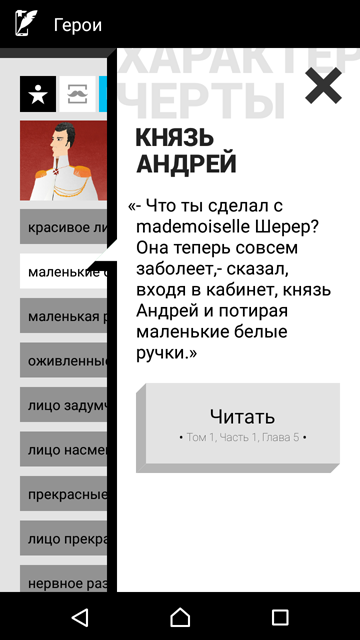
Помимо речи героев для цитатника, Сompreno использовалась для извлечения дат для таймлайнов, локаций для карт, а также эпитетов – различных характеристик, которыми так любил награждать своих персонажей Толстой. Все, конечно, помнят усики маленькой княгини, жены Болконского, но многие ли задумывались, что у самого блестящего красавца Андрея были «маленькие пухлые ручки» (и это в сочетании с небольшим ростом), а у изящной тонкой Наташи Ростовой – «толстая шея» и «большой рот»?


Все желающие могут скачать приложение и сделать еще немало открытий в том же духе. А мы тем временем вернемся к нашим штудиям и продолжим «анатомировать» тексты с помощью Compreno, искать в них новые неожиданные вещи и вскрывать таинственный «код Толстого», который сделал его произведения бессмертными.
