Будучи программистом я многое узнал о том, как создаётся программное обеспечение. Вот несколько фактов, которые могут вас удивить.

Anton Karakulov @brutto
Conceptmeister
ksqlDb или SQL как инструмент обработки потоков данных
16 min

Kafka нельзя назвать новым продуктом на рынке ПО. Прошло примерно 10 лет с того времени, как компания разработчик LinkedIn выпустила его в свет. И хотя к тому времени на рынке уже были продукты со схожей функциональностью, но открытый код и широкая поддержка экспертного сообщества прежде всего в лице Apache Incubator позволила ему быстро встать на ноги, а впоследствии составить серьезную конкуренцию альтернативным решениям.
Традиционно Kafka рассматривался как набор сервисов для приема и передачи данных, позволяющий накапливать, хранить и отдавать данные с крайне низкой задержкой и высокой пропускной способностью. Этакий надежный и быстрый (да и в общем-то наиболее популярный на данный момент) брокер сообщений по этой причине весьма востребован во множестве ETL процессов. Преимущества и возможности Kafka многократно обсуждались, в том числе и на Хабре. К тому же, статей на данную тематику весьма много на просторах интернета. Не будем повторять здесь достоинства Kafk-и, достаточно посмотреть на список организаций, выбравших этот продукт базовым инструментом для технических решений. Обратимся к официальному сайту, согласно которому на данный момент Kafka используется тысячами компаний, в том числе более 60% компаний из списка Fortune 100. Среди них Box, Goldman Sachs, Target, Cisco, Intuit и другие [1].
На сегодняшний день Apache Kafkaне без оснований часто признается лучшим продуктом на рынке систем по передаче данных. Но Kafka не только интересен в качестве брокера сообщений. Огромный интерес он представляет и в силу того, что на его основе возникли и развиваются многие специфические программные продукты, которые позволяют Kafka существенным образом расширить возможности. А это свою очередь позволяет ему уверено продвигаться в новые области ИT рынка.
Советы по архитектуре кода для начинающих
8 min

Для кого статья
Вы уже написали свои первые 1000 строк кода и сейчас хотите сделать их понятнее, потому что внесение изменений занимает столько-же времени, сколько написать заново, но советы из ООП, SOLID, clean architecture и т.д. непонятны вам.
О чем статья
Эта статья - не объяснение принципов ООП, SOLID своими словами, а попытка создать промежуточный уровень между никакой и чистой архитектурами. 100% советы будут накладываться друг на друга и перефразировать SOLID, но так даже лучше.
От кого статья
Я Middle разработчик. Конечно, не гуру разработки, но кому, как не мне, помнить о проблемах, с которыми сталкивался когда только начинал свой путь.
Отказ от ответственности
Уверен, каждый пункт из статьи может быть предметом спора, но на то это и вольный пересказ. Вся статья идет под эмблемой "Лучше применить такую архитектуру, чем не применять вообще никакой".
Формат статьи - наводящие советы / вопросы.
Как мы Schema Registry для Kafka настраивали, и что могло пойти не так…
11 min
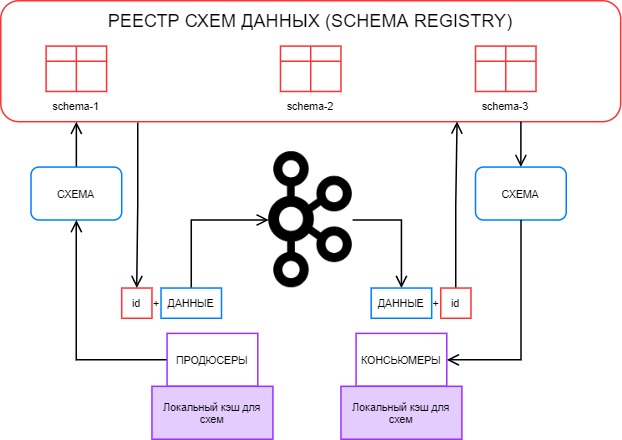
Всем привет.
В статье я опишу, как мы настраивали реестр схем данных для того, чтобы использовать его для сериализации и десериализации сообщений Kafka.
Спойлер: на данный момент реестр схем данных настроен и используется в боевой системе, каких-то проблем, связанных с SR, замечено не было.
Чек-лист — как тестировать поиск
16 min

Я посмотрела, как тестируют поиск начинающие тестировщики, и решила написать этот чит-лист проверок. Это такая серебряная пуля, которую можно применить на любом проекте, лишь немного варьируя под себя, под свой проект.
Поиск — он же есть практически в каждой системе. Поэтому здорово, когда есть шпаргалка «какие вопросы задать аналитику» и «какие проверки провести». Именно это мы в статье и обсудим. Сначала я дам чек-лист, а потом разберу каждый пункт отдельно.
Фильтр Блума на PHP
3 min
Что это?
Википедия гласит:
Это вероятностная структура данных, придуманная Бёртоном Блумом в 1970 году, позволяющая компактно хранить множество элементов и проверять принадлежность заданного элемента к множеству. При этом существует возможность получить ложно-положительное срабатывание (элемента в множестве нет, но структура данных сообщает, что он есть), но не ложно-отрицательное.

А попроще
Это способ проверки существования элемента в огромной выборке.
Рекомендательные системы: идеи, подходы, задачи
11 min

Многие привыкли ставить оценку фильму на КиноПоиске или imdb после просмотра, а разделы «С этим товаром также покупали» и «Популярные товары» есть в любом интернет- магазине. Но существуют и менее привычные виды рекомендаций. В этой статье я расскажу о том, какие задачи решают рекомендательные системы, куда бежать и что гуглить.
Пишем простую систему рекомендаций на примере Хабра
4 min

Сегодня мы поговорим о рекомендательных системах, а точнее о самой простой форме коллаборативной фильтрации. В программе передач: что такое рекомендательная система, на чем основана, каков математический аппарат и как её можно воплотить в код. В качестве бонуса предоставим результаты в виде простого сервиса.
- Что такое рекомендательная система
- Интуиция
- Теория
- Реализация: код и данные
- Сервис Хабра-рекомендаций
- Хабра-аналитика
NEO4J – графовые базы данных
9 min
В данной статье будет рассмотрена графовая система управления базами данных в Neo4j, а именно:
Настройка поиска Sphinx для интернет-магазина
5 min
Информации по Sphinx не так много, как хотелось бы. Лишняя статья не помешает.
Первые шаги в освоении Sphinx мне помогли сделать статьи Создание ознакомительного поискового движка на Sphinx + php и Пример Sphinx поиска на реальном проекте — магазин автозапчастей Tecdoc Советую начать с них.
Некоторое время на моем сайте работал поиск через LIKE по каждому слову запроса. Хотелось большего, и вот какие случаи теперь будут обрабатываться правильно:
- Словоформы. Выдача по «винты» и «винтов» должна быть одинаковой.
- Поиск по фрагменту слова.
- Поиск нецелых чисел. Разделитель точка и запятая.
- Буква Ё
- Типичные ошибки. Например «Аммортизатор».
- Синонимы. Регулятор и ESC.
- Язык. mAh и мАч, В и V, AAA латиницей и кириллицей.
- Слово из букв и цифр. 10х15х4, 6000mAh
Карма, основанная на кластерах
4 min
По мотивам статьи Кармическое проклятье Хабра и десятков подобных. Здесь предлагается почелленджить идею, как можно сделать лучше. Есть куча алгоритмов ранжирования контента, среди пользователей Хабра лучшие умы России, предлагаю обсудить этот вопрос и придумать решение. Затравку для обсуждения я дам, а дальше в комментариях доработаем. Погнали!
Хранимые, отображаемые и DOM-based XSS: выявление и блокирование
13 min
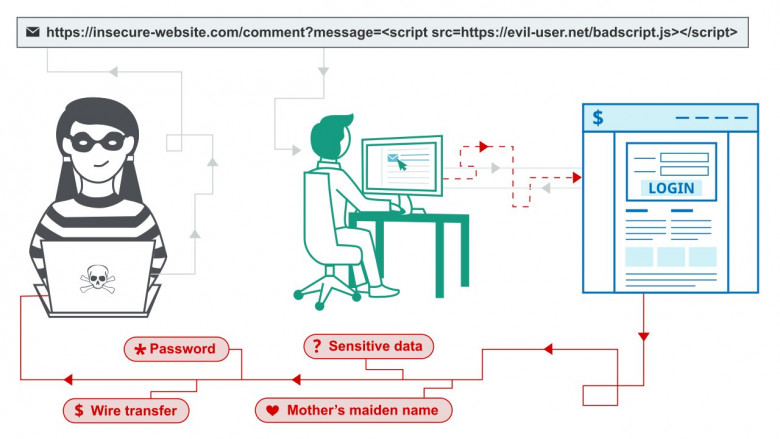
В статье расскажем про хранимые, отображаемы типы XSS и XSS в DOM-объектах, проведем обзор фреймворков для их поиска (XXSer и XXStrike) и узнаем, как точно Nemesida WAF Free блокирует попытки эксплуатации XSS.
Как не надо индексировать
5 min

Развитие происходит по спирали: когда-то люди не умели правильно индексировать, потом (в основном) научились, потом пришли noSQL и все снова забыли знание древних. Что вы будете делать, когда последние из старых DBA отплывут в Валинор?
Снова и снова и сталкиваюсь с полным набором антипаттернов индексирования. Я их перечислю, но! Для каждого антипаттерна есть исключение, когда именно это и стоит делать. Поэтому кликбейтно сформулированное правило верно в 95% случаях, но если вы хотите копнуть глубже, то прочитайте про исключения.
И в конце полезные скрипты для MSSQL, Postgres и MySQL.
Как устроен Domain-Driven Design
13 min
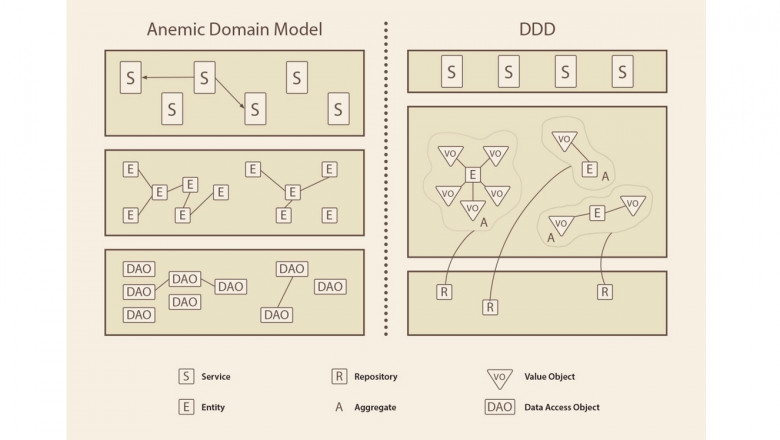
Многие проекты на Django начинаются просто: есть база данных и к приложению, которое крутится на сервере, идут обращения. Например, так начиналась Dodo IS (информационная система компании Додо Пицца, где работал автор сегодняшней статьи). Но если использовать Django из коробки, можно натворить много бед и встретить пачку антипаттернов. Возможно, вы встречали такое на старых legacy-проектах.
Евгений Пешков развивает сообщество DDD-практиков, рассказывая, какие проблемы решает Domain-Driven Design (предметно-ориентированное проектирование) в современном мире. На конференции Russian Python Week 2020 он выступил с рассказом об этом. Кстати, 19 августа пройдет встреча DDDevotion-сообщества, присоединяйтесь, будем о чем поговорить.
В сегодняшней статье будет его рассказ про то, как устроен Domain-Driven Design и какие инструменты использует, чтобы наиболее точно описать требования бизнеса и сам бизнес.
Первое правило машинного обучения: начните без машинного обучения
6 min
Translation

Эффективное использование машинного обучения — сложная задача. Вам нужны данные. Вам нужен надёжный конвейер, поддерживающий потоки данных. И больше всего вам нужна высококачественная разметка. Поэтому чаще всего первая итерация моих проектов вообще не использует машинное обучение.
Что? Начинать без машинного обучения?
Об этом говорю не только я.
Догадайтесь, какое правило является первым в 43 правилах машинного обучения Google?
Правило №1: не бойтесь запускать продукт без машинного обучения.
Машинное обучение — это здорово, но для него требуются данные. Теоретически, можно взять данные из другой задачи и подстроить модель под новый продукт, но она, скорее всего, не справится с базовыми эвристиками. Если вы предполагаете, что машинное обучение придаст вам рост на 100%, то эвристика даст вам 50%.
Краткое введение в цепи Маркова
16 min
Translation
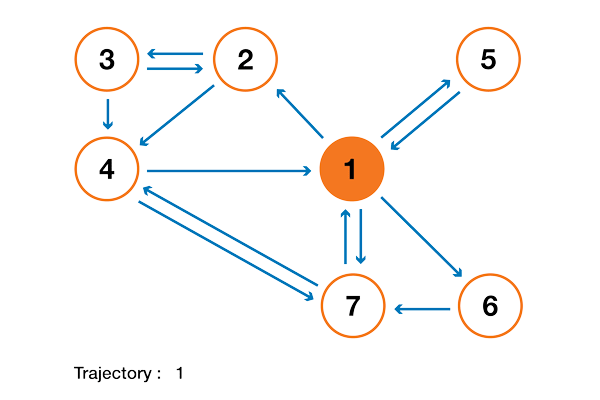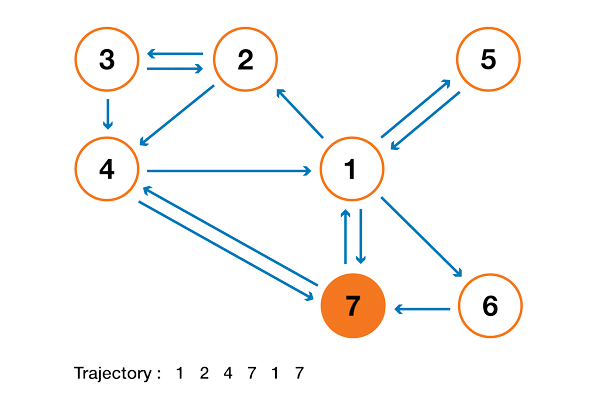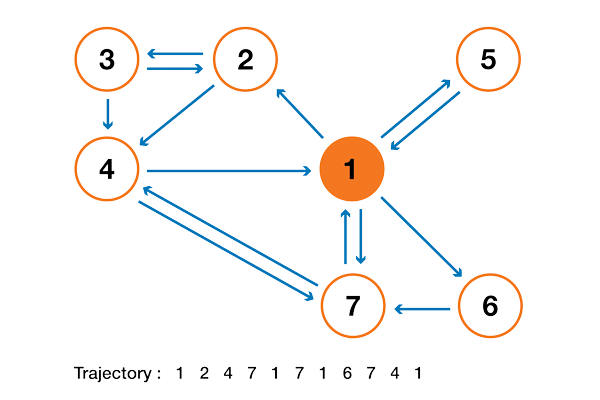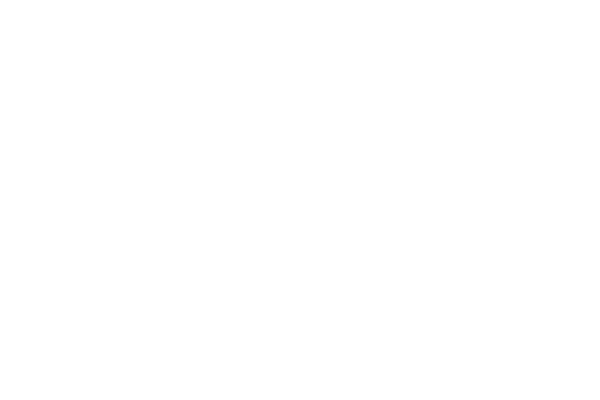
В 1998 году Лоуренс Пейдж, Сергей Брин, Раджив Мотвани и Терри Виноград опубликовали статью «The PageRank Citation Ranking: Bringing Order to the Web», в которой описали знаменитый теперь алгоритм PageRank, ставший фундаментом Google. Спустя чуть менее двух десятков лет Google стал гигантом, и даже несмотря на то, что его алгоритм сильно эволюционировал, PageRank по-прежнему является «символом» алгоритмов ранжирования Google (хотя только немногие люди могут действительно сказать, какой вес он сегодня занимает в алгоритме).
С теоретической точки зрения интересно заметить, что одна из стандартных интерпретаций алгоритма PageRank основывается на простом, но фундаментальном понятии цепей Маркова. Из статьи мы увидим, что цепи Маркова — это мощные инструменты стохастического моделирования, которые могут быть полезны любому эксперту по аналитическим данным (data scientist). В частности, мы ответим на такие базовые вопросы: что такое цепи Маркова, какими хорошими свойствами они обладают, и что с их помощью можно делать?
100500-ая автоматика полива для растений. Часть 2: Сенсоры и электроника
15 min

В вводной части повествования речь вкратце пошла об общем развитии системы автоматизации полива растений. В этой части, более подробно рассказ об измерительной технике, с которой довелось познакомиться по ходу развития проекта, электронике и, конечно же, о падениях в грязь лицом.
Как построить свою систему поиска похожих изображений
10 min

В интернете есть много информации о поиске похожих изображений и дубликатов. Но как построить свою систему? Какие современные подходы применять, на каких данных обучать, как валидировать качество поиска и куда смотреть при выводе в production?
В этой статье я собрал все необходимые компоненты поисковой системы на изображениях в одном месте, разбавив контент современными подходами.
Отложенные задачи в рамках микро-сервисной архитектуры
9 min
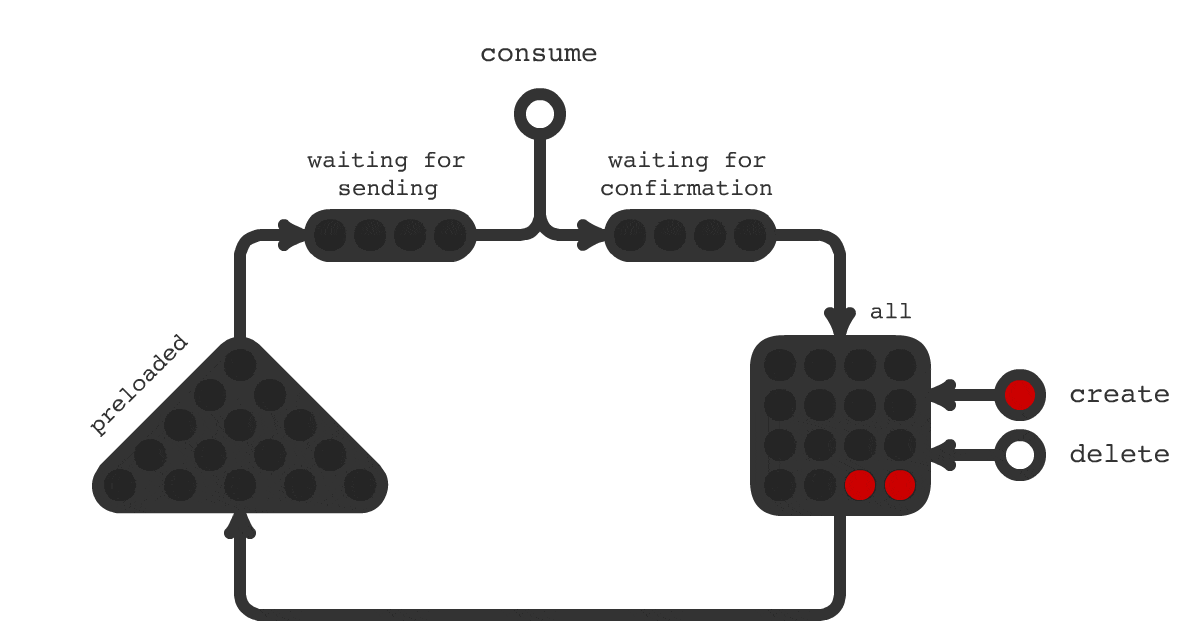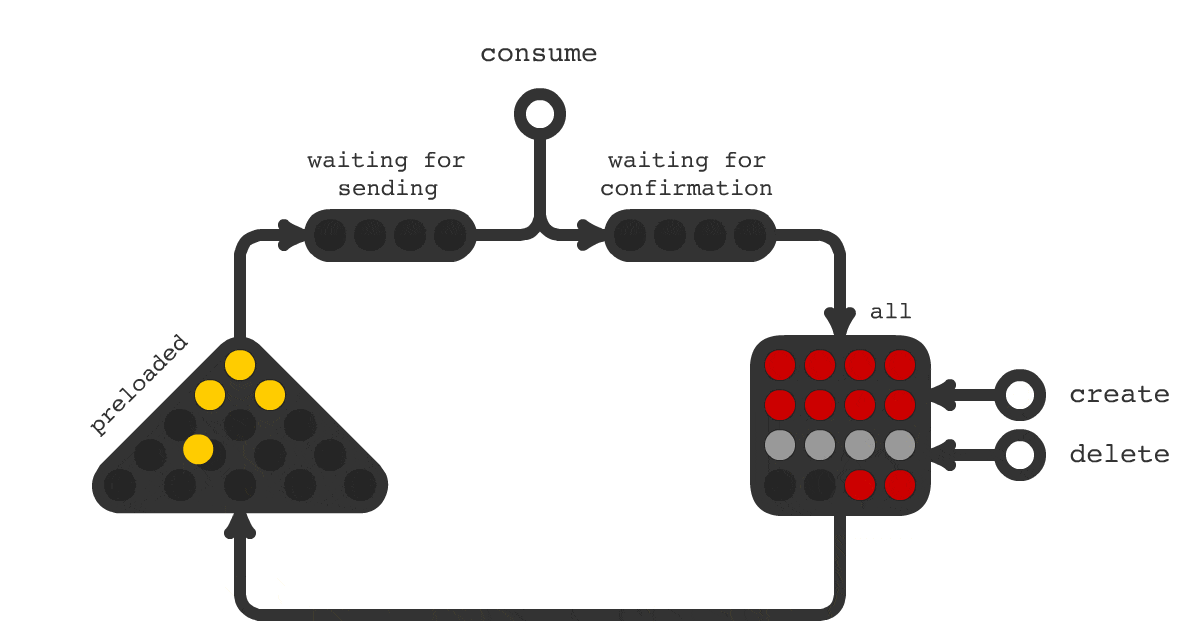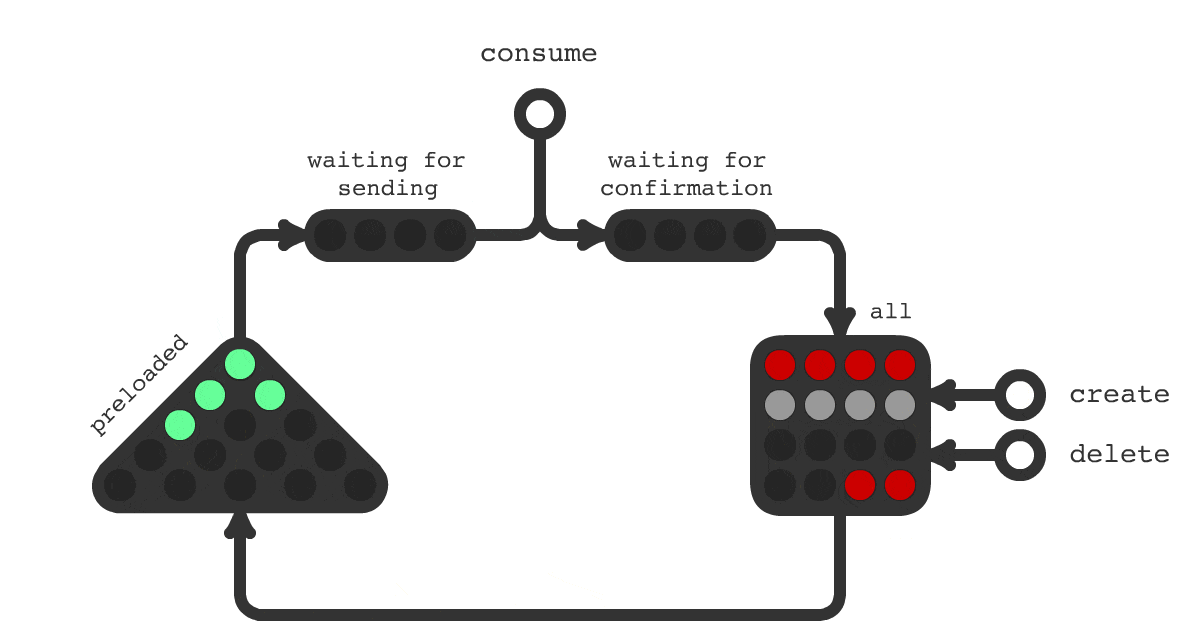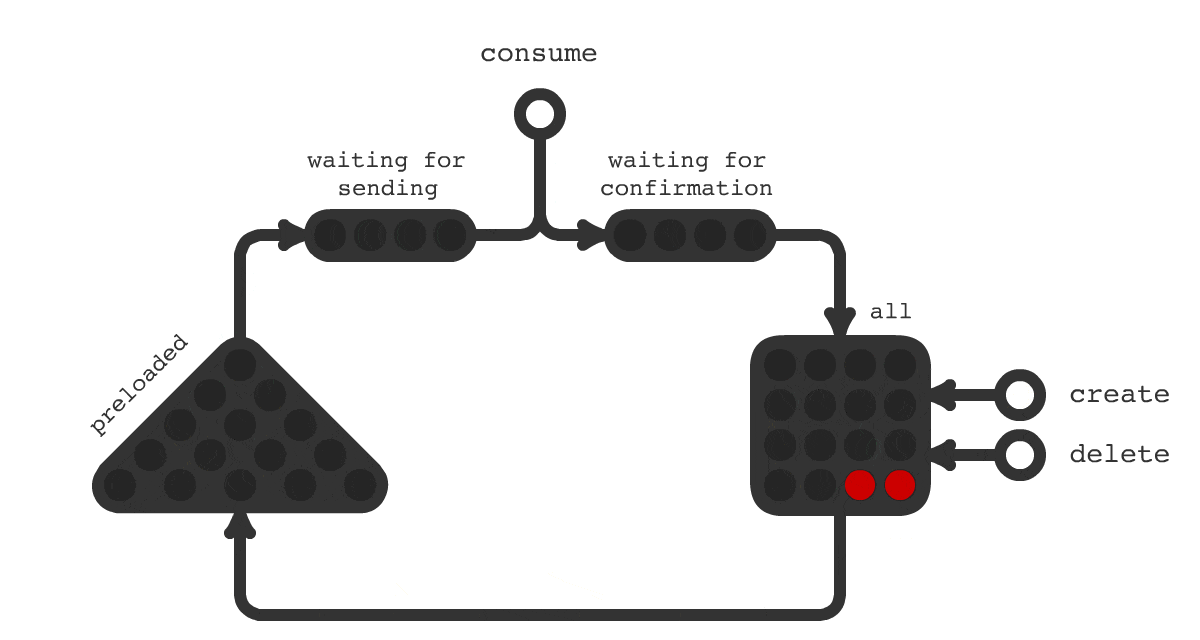
Часто в проектах возникает необходимость выполнения отложенных задач, таких как отправка email, push и других специфических задач, свойственных доменной области вашего приложения. Сложности начинаются, когда обычного crontab уже не достаточно, когда пакетная обработка не подходит и когда у каждой единицы задачи свое время выполнения или оно назначается динамически.
Для решения такой задачи было создано очередное решение под названием Trigger Hook. Принципиальная схема работы показана на рисунке 1. На схеме показано, что происходит с заданиями в течения всего их жизненного цикла. Смена цвета означает смену статуса задачи.
Квантование эмбеддингов: что это, зачем оно нужно и как его правильно готовить
8 min
Привет, меня зовут Женя. Сегодня я расскажу, что такое квантование эмбеддингов, какие бывают способы квантования и как с их помощью мы в Яндекс.Дзене смогли сократить использование памяти, рейта записи и сетевого трафика в четыре раза. Будет совсем немного математики, умеренно размышлений о machine learning, highload и big data и много разноцветных картинок.
Эмбеддинг — числовой вектор, который каким-то (в общем случае непонятным на глаз) образом характеризует интересы пользователя или контент. Например, эмбеддинги могут быть такими.

У каждого пользователя и карточки может быть несколько эмбеддингов разных типов. В основном используются два вида эмбеддингов.
Что такое эмбеддинги?
Эмбеддинг — числовой вектор, который каким-то (в общем случае непонятным на глаз) образом характеризует интересы пользователя или контент. Например, эмбеддинги могут быть такими.
У каждого пользователя и карточки может быть несколько эмбеддингов разных типов. В основном используются два вида эмбеддингов.