
Вспомните, делали ли вы в последние годы какой-нибудь существенный выбор, не почитав предварительно в интернете отзывов тех, кто уже выбрал это ранее?
Мы живем в эпоху «развивающегося отзывизма».
Почти все покупки, выбор места отдыха, работы, ученья и леченья, банка и танка, фильма и фирмы… Лучше прочесть один отзыв, чем тысячи реклам.
Хотя, скорее всего, отзывами вы пользовались не во всех случаях.
Например, при выборе спутника\спутницы жизни.
Или при выборе кабинки в общественном туалете :).
Или – при выборе способа распараллеливания программ. В последнем случае — наверное, просто потому, что таких отзывов вам не попадалось. Попробую это исправить. А именно, расскажу, чего ждать от Cilk+, OpenMP, OpenCL, TBB и ArBB(Ct) с точки зрения их возможностей, простоты освоения и использования, качества документации, а также ожидаемой производительности.
Сразу отмечу, что все нижеописанные средства либо бесплатны, либо входят в цену компилятора.
OpenMP.
Набор прагм компилятора для автоматического распараллеливания (также можно использовать дополнительные библиотечные функции).
Поддерживается всеми основными компиляторами, иначе — просто игнорируется, не вызывая ошибок.
Работает на всех распространенных архитектурах (в теории – и на ARM) и ОС (в теории – даже на Android).
Документация хорошая и есть везде — вплоть до глянцевых журналов.
Простота изучения — исключительная. Время освоения и имплементации – минуты. Для сложного проекта – не более часа.
Отладка – ограничена, но возможна – см. Intel Parallel Studio.
Недостатки: не использует GPU, не поддерживает многие нужные для «продвинутого» контроля и синхронизации потоков функции; не всегда обеспечивает хорошую производительность; неоптимально «комбинируется» в различных компонентах приложения и с другими средствами распараллеливания.
Пример. Цикл for с использованием OpenMP будет выглядеть так:
#pragma omp parallel for
for (i = 0; i < n; ++i)
result[i] = a[i] * b[i];OpenCL(Open Computing Language)
Молодой (2008г рождения) стандарт гетерогенного параллельного программирования. То есть, внутри использует не только CPU, но и GPU, что является его главным, а может, и единственным преимуществом. Поддерживается AMD, Apple, ARM, Intel, NVidia и всеми компаниями-производителями мобильных телефонов. Не поддерживается Microsoft.
Еще одно декларируемое достоинство OpenCL – автоматическая векторизация кода при наличии возможностей железа. Но того же эффекта можно добиться и не используя OpenCL :)
Концепция стандарта: центральный хост и множество OpenCL устройств (Compute Unit), параллельно выполняющих определенные программистом функции-ядра (kernel). Кернелы пишутся на диалекте языка С (С с некоторыми ограничениями и дополнениями) и компилируются специальным компилятором.
Основная программа, выполняемая на хосте, должна много всего и всем :):
- создать окружение OpenCL,
- создать кернелы,
- определить платформу выполнения = контексты, устройства и очереди,
- создать и построить программу (динамическую библиотеку для кернелов),
- выделить и инициализировать объекты в памяти,
- определить ядра и присоединить их к их аргументам, и, наконец, передать память и ядра на выполнение OpenCL устройствам.
Документация: очень мало.
Самое сложное в изучении\имплементировании средство, особенно учитывая недостаток документации и, особенно, примеров. Время освоения и имплементации – дни. Для сложного проекта – недели.
Прочие недостатки: не лучшая производительность на имеющихся примерах, использующих только CPU, трудности отладки и поиска проблем с производительностью.
Пример. Цикл for из функции
void scalar_mul(int n, const float *a, const float *b, float *result) {
int i;
for (i = 0; i < n; ++i)
result[i] = a[i] * b[i];
}
в переводе на OpenCL превратиться в кернел:
__kernel void scalar_mul(__global const float *a, __global const float *b,
__global float *result) {
size_t id = get_global_id(0);
result[id] = a[id] * b[id];
}
… плюс понадобится еще полный экран кода (!) для основной программы-хоста (см. выше). Этот код, вызывающий специальные OpenCL функции, конечно, можно списать из примера Intel OpenCL SDK, но разбираться в нем все равно придется.
Три следующие средства распараллеливания программ образуют Inel Parallel Building Blocks:
Cilk Plus, TBB, ArBB.
Cilk Plus.
«Плюс» означает расширения Cilk для работы с массивами.Расширение С\С++, поддерживаемое исключительно компиляторами Intel (Windows, Linux) и, с августа 2011, — gcc 4.7, что сразу показывает недостаток – отсутствие реальной кросс-платформености. GPU также не поддерживается.
Достоинства:
Простота освоения. Cilk немногим сложнее OpenMP. Вводится в проект за считанные минуты, в худшем случае – часы работы.
При этом, производительность превосходит OpenMP. Кроме того, Сilk хорошо комбинируется со всеми Inel Parallel Building Blocks и OpenCL.
При использовании Intel Cilk SDK изменения кода минимальны, всю работу выполняет компилятор «за сценой».
Документация: немного, но, учитывая простоту Cilk, это не проблема.
Пример. Ваш любимый цикл for на Cilk будет выглядеть так:
cilk_for (i = 0; i < n; ++i) {
result[i] = a[i] * b[i];
}
TBB (Threading Building Blocks)
Созданная Intel библиотека С++ темплейтов для параллельного программирования. Работает на Linux, Windows, Mac и даже на Xbox360, не требует компилятора Intel. Недостаток: не использует GPU.
В библиотеке реализованы:
• потокобезопасные контейнеры: вектор, очередь, хеш-таблица;
• параллельные алгоритмы for, reduce, scan, pipeline, sort и тд.
• масштабируемые распределители памяти;
• мьютексы и атомарные операции;
Документация и примеры: много, хорошего качества.
Простота освоения и использования. Для не имеющих опыта пользования шаблонами в коде – достаточно сложно. Для имеющих — тоже не всегда элементарно. Могут потребоваться значительные изменения кода. Время изучения\имплементации — от одного рабочего дня до недели.
Достоинства: отличная производительность, независимость от компилятора, возможность использовать отдельные компоненты библиотеки независимо.
Пример.
void scalar_mul(int n, const float *a, const float *b, float *result) {
for (int i = 0; i < n; ++i)
result[i] = a[i] * b[i];
}
с использованием ТВВ придется превратить в оператор() класса так называемого Body (тела цикла):
using namespace tbb;
class ApplyMul {
public:
void operator()( const blocked_range<size_t>& r ) const {
float *a = my_a;
float *b = my_b;
float *result = my_result;
for( size_t i=r.begin(); i!=r.end(); ++i )
result[i] = a[i] * b[i];
}
ApplyMul( float a[], float b[], float result []) :
my_a(a), my_b(b), my_result(result)
{}
};
Где blocked_range -темплейт-итератор, предоставляемый tbb.
И только после этого можно использовать tbb parallel_for
void parallel_mul ( float a[], float b[],float result[], int n ) {
parallel_for(blocked_range<size_t>(0,n), ApplyMul(a, b, result));
}
ArBB (Array Building Blocks).
В девичестве – Ct, про который уже писал в этом блоге izard. Intel библиотека С++ шаблонов для параллельного программирования.
Intel ArBB работает на Windows* и Linux*, поддерживается компиляторами Intel, Microsoft Visual C++ и GCC. При наличии соответствующего run-nime должен работать на GPU и грядущей Intel MIC
Достоинства: заложенная в дизайн полная поточная безопасность (отсутвие data race) использует внутри себя TBB, соответственно, хорошо комбинируется в разных модулях.
Документация: увы, немногословна, примеры – вполне нормальны.
Трудность освоения\имплементации – на уровне TBB.
Недостатки:
Все еще находится в стадии beta.
Спроектирован для обработки больших массивов данных, на небольших массивах за счет накладных расходов не обеспечивает хорошей производительности.
Пример:
Во что превратиться пресловутый цикл for в ArBB? При первом взгляде в документацию можно подумать, что в _for. Но нет. _for в ArBB – это как раз указание на то, что цикл имеет зависимости в итерациях и может выполняться только последовательно. «parallel for» в ArBB вообще нет.
А все тот же
void scalar_mul(int n, const float *a, const float *b, float *result) {
for (int i = 0; i < n; ++i)
result[i] = a[i] * b[i];
}
превратится в
void parallel_mul(dense<f32> a, dense<f32> b, dense<f32> &result) {
result = a * b;
}
с вызовом
dense<f32> va; bind (va, a, n);
dense<f32> vb; bind (vb, b, n);
dense<f32> vres; bind (vres, result, n);
call(parallel_mul)(va, vb, vres);
Резюме №1
Сводная таблица выбора.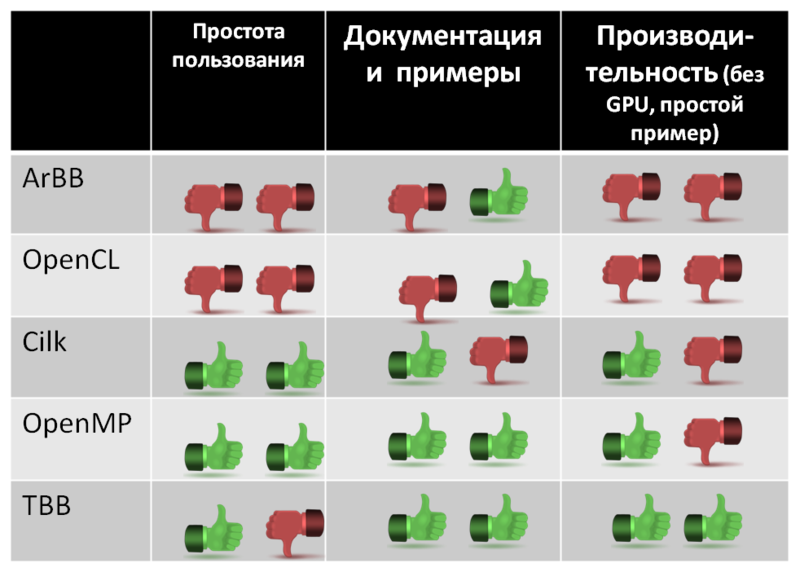
Резюме №2
Горизонтальные прямые на картинке в начале этого поста – параллельны. Хотя, возможно, что по отзывам наблюдателей окажется, что нет.
