
Пауза — временное молчание, перерыв в звучании музыкального произведения в целом или какой-либо его части или отдельного голоса.
[Википедия]
Удивительно, но иногда так бывает, чтобы что-то сделать в целом быстрее, надо это делать медленнее или вообще с паузами. Например, при имплементации активного ожидания spin-wait в многопотоковом коде рекомендуется использовать инструкцию pause, которая, как утверждает Intel Instruction Set Reference, делает это ожидание наиболее эффективным. «Какая чушь!» — скажете вы. Как может быть ожидание эффективным? Разработчики микропроцессоров утверждают, что при активном ожидании с инструкцией pause чип потребляет намного меньше энегии еще со времен Pentium 4. В чем еще может быть эффективность ожидания? Поговорим об этом ниже.
На самом деле в данном посте я не буду сравнивать эффективность реализации spin-wait’ов – это уже не интересно. Что мне показалось интересным, это подробно разобрать один случай профилирования параллельного OpenMP-приложения, в котором, если представить проблему упрощенно, множество потоков борются за один разделяемый ресурс. При этом время выполнения операции над этим ресурсом ничтожно мало по сравнению с накладными расходами на синхронизацию. Понятно, что программисты допустили ошибку, проектируя реализацию своей задачи в параллельном приложениии – такие ошибки вообще часто встречаются и являютя предметом обсуждений в блогосфере ISN (пример). Однако, сразу понять, что происходит, было не так уж и легко, так как проект непростой и его профилировка и анализ занимает какое-то время. Для облегчения понимания проблемы и ускорения тестов я редуцировал программу до простого теста, который, если взглянуть на него опытным глазом, сразу обнаруживает в себе ошибку. Но так мы все умеем делать, сходу находить проблемы в простых тестах. Моя же задача – показать примерный ход исследования (т.к. до методологии он не дотягивает) и возможности профилировщика, позволяющие делать заключения о проблемах в коде и дальше искать методы их решения.
Как я уже упомянул, мы выяснили, что тот код, который мы исследуем, реализует многопоточный доступ к переменной, которая защищена критической секцией. Из результатов Hotspot-профилировки видно, что функция ComputePot занимает больше всего времени процессора, и есть еще вызовы ожидания – вспомогательные функции из библиотеки libomp5.so, которые вызываются при создании и уничтожениии параллельных регионов OpenMP (fork/join).
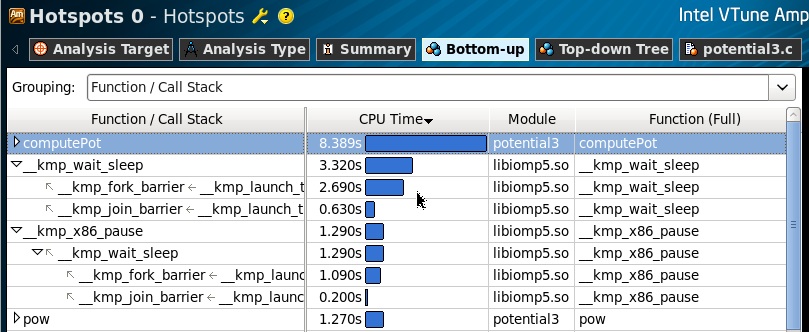
Если мы взглянем на распределение времени выполения в исходном коде, то увидим, что собственно функции вычисления (pow, sqrt) в теле региона отнимают пренебрежимо малую часть от всего времени выполнения функции computePot. А проблема производительности лежит в плоскости синхронизации доступа потоков OpenMP к переменной lPot. Избыточный доступ многих потоков к одному ресурсу на многоядерной машине никогда эффективным не был. Еще раз оговорюсь, что данный пример сильно упрощен, и с точки зрения локальной переменной lPot критическая секция тут не нужна, но мы оставляем ее на месте, иначе пример не будет отражать той имплементации, от которой он был редуцирован.

Дальше нам нужно понять, где существует возможность уменьшения накладных расходов на синхроницацию. Первым порывом было переписать имплементацию на pthreads, исключив тем самым вероятность накладных расходов библиотеки OpenMP. Действительно, что может быть проще – создаем потоки pthreads и синхронизируем доступ к переменной с помощью pthread_mutex_lock/unlock. Сразу скажу, что в реальном примере и в реальные сроки это сделать было практически невозможно, так как пришлось бы понаписать уйму кода, который разделяет нагрузку и данные между потоками. Попробуем тогда на этом микротесте. Результат оказался ожидаемый – какого-либо значимого прироста производительности не наблюдается. Что ж, тогда продолжим исследовать библиотеку OpenMP (предпочтение было сделано ей, так как «ковыряние» в ней намного приятнее, чем libpthread, хотябы потому, что ее разработчики сидят под боком, и всегда можно подоставать их глупыми вопросами).
Для анализа библиотечных и системных вызовов нам понадобиться профиль Lightweight Hotspots, который базируется на технологи Hardware Event-based Sampling (EBS) и известен тем, что профилирует все вызовы, как на пользовательском уровне, так и на уровне ядра. При этом в данном случае нам не нужно каких-либо специалных счетчиков процессора, так как мы измеряем только собственное время выполнения функций (self-time).
Как мы видим из профиля, практически все время было потрачено в фунциях ожидания библиотеки OpenMP: x86_pause, wait_yield, wait_sleep, и часть времени в ядре Linux, вызовы которого мы не может профилировать, не имея символов для модуля ядра. Что нам эта информация дает (кроме той, что, по крайнем мере, нам не нужно «тьюнить ядро»)? Из-за того, что профиль, предоставляемый технологией EBS является плоским, то ничего. Плоским – значит мы имеем список функций, которые набрали больше всего сэмплов (выполнялись больше всего времени), аггрегированных по вызовам. То есть эти функции мог вызывать кто угодго и сколько угодно раз. Нам нужен «выпуклый» профиль, чтобы понять, откуда эти функции вызывались, кто ожидал.
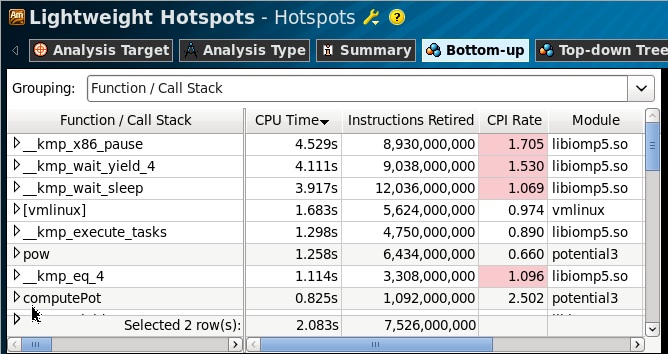
В новой версии VTune Amplifier XE 2013 Beta такая возможность есть. Это совершенно новая технология, основанная на трассировке BTR (Branch Target Register) процессора, позволяет восстановить стек вызова, даже если он был сделан функцией на уровне ядра. Это очень «вкусная» фича, особенно полезна в случаях, когда какие-либо события процессора (не обязательно время) концентрируются в системных вызовах, и нам необходимо узнать, какие функции в пользовательском коде были их инициаторами.

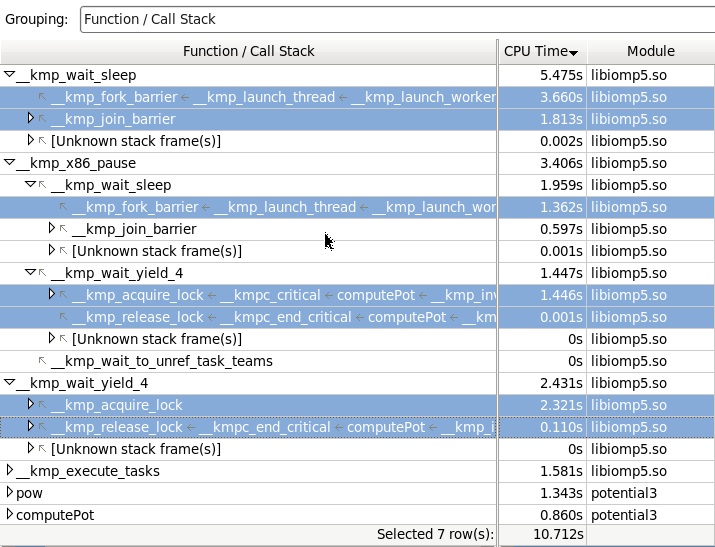
Собирая Lightweight Hotspot профиль со стеками, получаем следующую картину. (Тут необходимо учитывать, что сбор стеков, даже с помошью процессора, это несколько затратная операция, допускающая накладные расходы на выполнение программы, поэтому временные параметры немного изменятся).
Что мы здесь видим: основной потребитель времени функция библиотеки wait_yield_4, которая вызывается по стеку входа в критическую секцию в функции computePot, и которая в конечном счете вызовет функцию x86_pause.
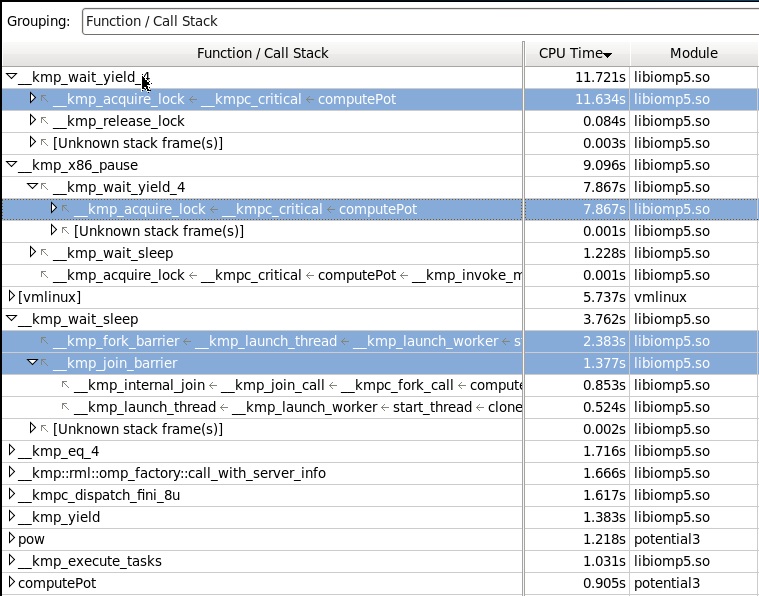
Нетрудно видеть (переключившись в Assembly view), что последняя вызовет ассемблерную инструкию pause.

Что до wait_sleep, она тоже вызывает x86_pause, но она ответственна за ожидания в начале и конце параллельного региона.
Теперь посмотрим, что у нас ушло в вызовы ядра (неразрешаемые инструментом символы, поэтому в скобках имя модуля [vmlinux]). Здесь видим, что большинство «уходов в ядро» происходило посредством библиотечной функции yeild на попытке захватить критическую секцию.
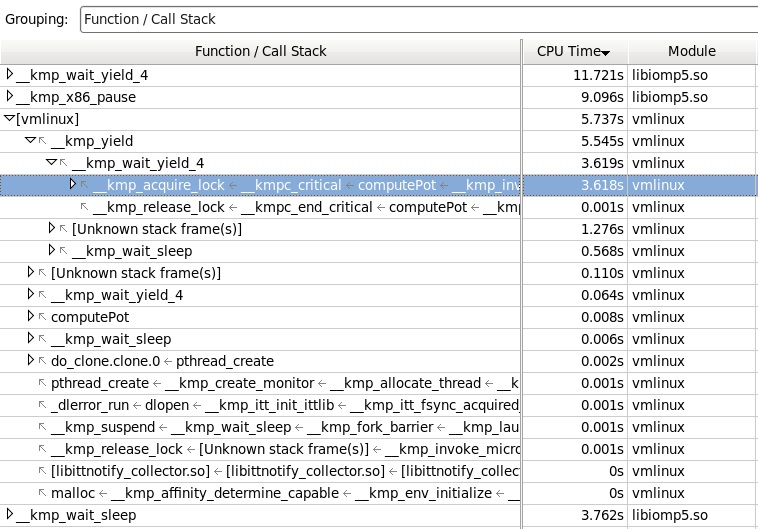
Вот с этим уже можно поиграться. Дело в том, что при неудачной попытке захвата критической секции в OpenMP, управление не сразу передается в ядро, мы собственно и получаем ожидание в spin-wait’е (wait_yield_4) с использованием инструкции pause. Однако, если в течение этого ожидания (десятки миллисекунд) проверка флага не показала, что мьютекс свободен, вызывается следующая функция yield, передающая управление ядру и «усыпляющая» поток, пока его не разбудит сигнал ядра. Мы можем увеличить время ожидания в spin-wait’e для уменьшения вероятности перехода в режим ядра. Если почитать документы по OpenMP библиотеке, то оттуда можно выудить, что существуют полезные глобальные настройки, такие как:
KMP_LIBRARY – run-time execution mode [Serial | Turnaround | Throughput(default)]
KMP_BLOCKTIME – amount of time to wait before sleeping [0| N (default 200 ms) | infinite]
Сконфигурируем OpenMP run-time так, чтобы потоки были максимально активны, и старались не передавать управление другим потокам (именно так и поступают в ситуациях с thread contention, когда потоки борются за разделяемые ресурсы). Установим:
KMP_LIBRARY=Turnaround
KMP_BLOCKTIME=infinite
Считается, что в системах, где работает только наша программа (процессоры не заняты интенсивным выполнением других приложений) такая настройка приносит наибольший прирост быстродействия на синхронизации. Однако, следует помнить, что если количество потоков в программе намного больше числа процессоров, и они борются друг с другом за право встать в очередь исполнения, оптимальными будут прямо противоположные настройки, то есть: KMP_LIBRARY= Throughput, KMP_BLOCKTIME=0.
Запускаем еще раз профилировку и изучаем результаты. Начнем со сравнения результатов. Видим, что сократилось время ожидания в spin-wait'ах, и самое главное, практически исчезло ожидание в ядре (чего мы и добивались). В целом программа отработала примерно в 2 раза быстрее.

Теперь основное время ожидания находится в функции wait_sleep, вызываемой при создании и уничтожении параллельного региона, а паузы вызываемые из wait_yield_4 из захвата критической секции (acquire_lock) уменьшились, видимо из-за того, что потоки получили больше шансов захватить секцию.
Необходимо еще раз упомянуть, что такой прирост производительности с изменением настроек OpenMP run-time был получен в этом простом примере, который, по сути, является вырожденным случаем, на котором хорошо проводить измерения (и хвастаться успехами). В реальном приложении не все так однозначно, и успехи более скромные. Однако, применение данного подхода позволяет изучить проблемы, возникающие при избыточной синхронихации, и попробовать их решить какими-либо способами.
