Всем привет. Сразу поделим аудиторию на две части — тех, кто любит смотреть видео, и тех, кто, как я, лучше воспринимает тексты. Чтобы не томить первых, запись моего выступления на Дата-Ёлке:
Там есть все основные моменты, но формат выступления не предполагает подробного рассмотрения статей. Любители ссылок и подробных разборов, добро пожаловать под кат.
Те, кто дочитал до этого места, наконец, могут узнать, что все ниже написанное может быть использовано против них в суде является исключительно моей точкой зрения, и точки зрения других людей могут отличаться от моей.
Тренды
В 2017-ом году в развитии нашей области (обработки естественного языка, NLP) я выделяю две основных тенденции:
- ускорение и параллелизация — все модели стремятся ускорить, в том числе за счет большей параллельности;
- обучение без учителя — подходы с обучением без учителя уже давно популярны в машинном зрении, но относительно редки в NLP (в качестве редкого, но яркого примера использования этих идей можно привести, пожалуй, word2vec); в этом году использование таких подходов стало весьма популярно.
Теперь разберем подробнее главные идеи этого года.
Attention Is All You Need

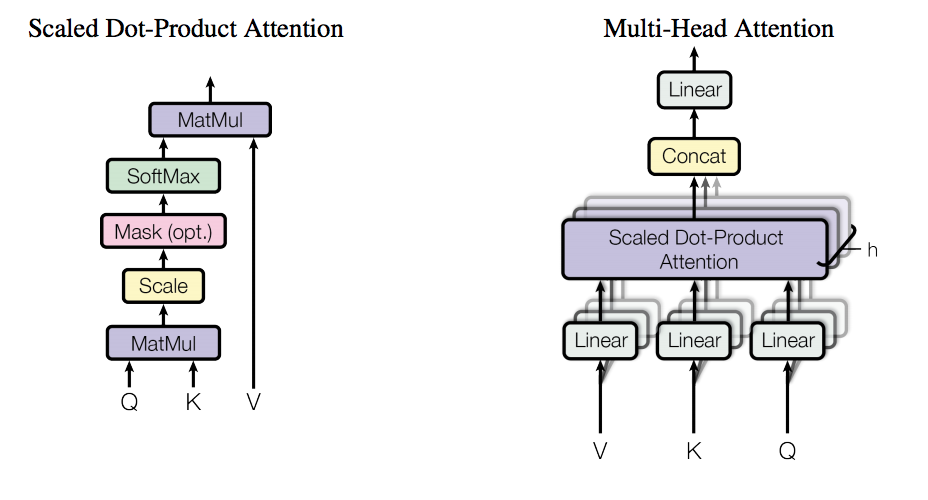
Эта уже известная работа знаменует собой второе пришествие полносвязных сетей в область NLP. Её авторами являются сотрудники компании Google (кстати, один из авторов, Илья Полосухин, будет выступать на нашем хакатоне DeepHack.Babel). Идея, лежащая в основе архитектуры Transformer (именно она изображена на картинке), проста, как все гениальное: давайте забудем о рекуррентности и всяком таком и просто используем внимание (attention), чтобы добиться результата.
Но сначала давайте вспомним, что все текущие передовые системы машинного перевода работают на рекуррентных сетях. Интуитивно рекуррентные нейронные сети должны отлично подходить для задач обработки естественного языка, в том числе для машинного перевода, в силу того, что у них есть явным образом заложенная в архитектуру память, используемая в процессе работы. У этой особенности архитектуры есть очевидные достоинства, но также и неразрывно связанные с ними недостатки: так как мы используем память для работы с данными, мы можем обрабатывать их только в конкретной последовательности. Как следствие этого, полная обработка данных может занимать много времени (по сравнению, например, с CNN). И это как раз то, с чем хотели побороться авторы работы.
И вот Transformer — архитектура для машинного перевода, не имеющая никакой рекуррентности. И только внимание, которое делает всю работу.
Давайте сначала вспомним, как выглядит стандартный подход к вниманию, предложенный Дмитрием Богдановым (Dzmitry Bahdanau).
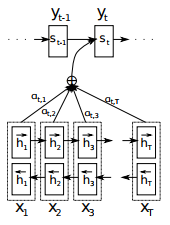
Идея механизма внимания в том, что мы должны сфокусироваться на некотором релевантном входе в кодировщик (encoder), чтобы произвести лучшее декодирование. В самом простом случае, релевантность определяется как похожесть каждого входа к текущему выходу. Эта похожесть определяется в свою очередь, как сумма входов с весами, где веса суммируются в 1, и наибольший вес соответствует наиболее релевантному входу.
На картинке выше представлен классический подход авторства Дмитрия Богданова: у нас есть один набор входов — скрытое состояние кодировщика (h), а также набор коэффициентов для этих входов (а). Эти коэффициенты рассчитываются каждый раз, на основании некоторого другого входа, отличного от скрытых состояний.
В отличие от классического подхода, авторы этой работы предложили так называемый self-attention на входных данных. Слово "self" в данном случае означает, что внимание применяется к к тем же данным, на которых оно вычисляется. В то же время в классическом подходе внимание вычисляется по некоторому дополнительному входу относительно тех данных, к которым оно применяется.
Более того, этот self-attention называется Multi-Head, т.к. выполняет одну операцию несколько раз в параллель. Эта особенность может напомнить сверточные фильтры, т.к. каждая из "голов" смотрит на разные места входной последовательности. Другая важная особенность — это то, что в это варианте внимание принимает на вход три сущности, а не две, как в стандартном подходе. Как можно увидеть на картинке выше, сначала вычисляется "sub-attention" на входах Q (запрос) и K (ключ), а потом выход sub-attention комбинируется с V (значение) из входа. Эта особенность отсылает нас к понятию памяти, разновидностью которой и является механизм внимания.
Помимо самого важного, есть еще две существенные особенности:
- кодирование позиции (positional encoding),
- маскированное внимание для декодировщика (masked attention).
Positional encoding — как мы помним, вся архитектура модели является полносвязной сетью, так что само понятие последовательности внутрь сети не заложено. Чтобы добавить знание о существовании последовательностей, был предложен positional encoding. Как по мне, использование тригонометрических функций (sin и cos), которыми и создается positional encoding, представляется совершенно неочевидным выбором, но это работает: вектор position encoding, скомбинированный с вектором слова (например, с упомянутым выше word2vec), доставляет знания о значении слова и его относительной позиции в последовательности в сеть.
Маскированное внимание — простая, но важная особенность: опять же, т.к. в сети нет понятия о последовательностях, нам нужно каким-то образом отфильтровать представления сети о следующих словах, которые недоступны во время декодирования. Так что, как можно заметить на картинке, мы вставляем маску, которая "закрывает" слова, которых сеть еще не должна видеть.
Все эти особенности позволяют сети не только работать, но даже улучшить текущие результаты по машинному переводу.
Parallel Decoder for Neural Machine Translation
Последняя из описанных особенностей архитектуры не устраивала авторов следующей работы, сотрудников группы Ричарда Сохера (Richard Socher) из Salesforce Research (кстати, один из сотрудников, Ромэн Полюс (Romain Paulus), автор другой известной работы про суммаризацию, также будет выступать на нашем хакатоне DeepHack.Babel). Маскированное внимание для декодировщика было для них недостаточно быстрым, по сравнению быстрым параллельным кодировщиком, так что они решили сделать следующий шаг: "Почему бы не сделать параллельный декодировщик, если у нас есть уже параллельный кодировщик?" Это мое предположение, но готов ручаться, что авторы этой работы имели какие-то похожие мысли в головах. И они нашли способ осуществить задуманное.

Они назвали это Non-Autoregressive Decoding, всю архитектуру Non-Autoregressive Transformer, что означает, что теперь ни одно слово не зависело от другого при декодировании. Это некоторое преувеличение, но не такое и большое. Идея в том, что кодировщик здесь дополнительно выдет так называемый уровень фертильности (fertility rate) для каждого входного слова. Этот уровень фертильности используется, чтобы сгенерировать собственно перевод для каждого слова, основываясь только на самом слове. На это можно посмотреть, как на некий аналог стандартной матрицы соответствий в машинном переводе (alignment matrix):

Как можно заметить, некоторые из слов соотносятся с несколькими словами, а некоторые не соотносятся ни с каким конкретным словом другого языка. Таким образом, fertility rate просто нарезает эту матрицу на кусочки, где каждый кусочек относится к конкретному слову исходного языка.
Итак, у нас есть уровень фертильности, но этого недостаточно для полностью параллельного декодирования. Вы можете заметить на картинке несколько дополнительных уровней внимания — позиционное внимание (которое соотносится с positional encoding) и inter-attention (которое заменило маскированное внимание из оригинальной работы).
К сожалению, давая серьезный прирост в скорости (в 8 раз в некоторых случаях), Non-Autoregressive Decoder дает качество на несколько единиц BLEU хуже оригинала. Но это повод, чтобы искать пути улучшения!
Unsupervised Machine Translation
Следующая часть статьи посвящена задаче, которая казалась невозможной еще несколько лет назад: машинный перевод, обученный без учителя. Работы, которые мы будем обсуждать:
- Unsupervised Neural Machine Translation
- Unsupervised Machine Translation Using Monolingual Corpora Only
- Style-Transfer from Non-Parallel Text by Cross-Alignment
Последняя работа, если судить по названию, лишняя в этом ряду, но как говорится, первое впечатление обманчиво. Все три работы имеют общую идею в основе. В двух словах она может быть изложена так: у нас есть два автокодировщика для двух разных текстовых источников (например, разных языков, или текстов разных стилей), и мы просто меняем местами декодирующие части этих автокодировщиков. Как это работает? Давайте попробуем разобраться.
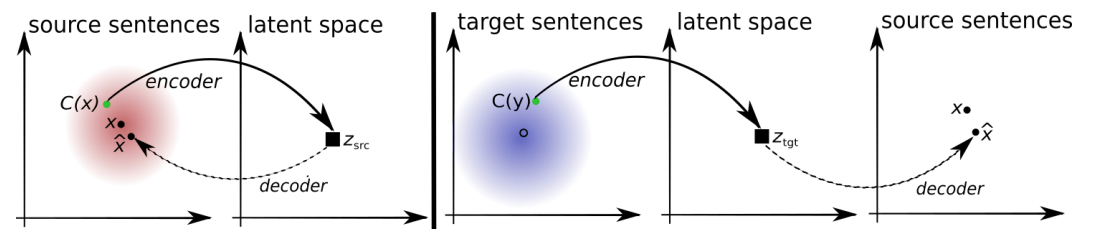
Автокодировщик (слева на картинке выше) — это кодировщик-декодировщик (encoder-decoder), где декодировщик декодирует обратно в оригинальное пространство. Это значит, что вход и выход принадлежат к одному языку (или стилю). Таким образом, мы имеем некоторый текст и тренируем кодировщик делать векторное представление этого текста таким образом, чтобы декодировщик смог реконструировать оригинальное предложение. В идеальном случае реконструированное предложение будет в точности таким же. Но в большинстве случаем это не так, и нам нужно как-то измерять похожесть исходного и реконструированного предложений. И для машинного перевода такая мера была придумана. Это стандартная сейчас метрика, которая называется BLEU.
- BLEU — эта метрика измеряет, как много слов и n-грамм (n последовательных слов) перекрываются между данным переводом и некоторым референсным, заранее известным переводом. Наиболее часто используется версия BLUE, которая называется BLUE-4, которая работает со словами и словосочетаниями длины от 2 до 4. Дополнительно вводится штраф за слишком короткий перевод (относительно референсного).
Как вы могли догадаться, эта метрика не дифференцируема, так что нам нужен какой-то другой способ тренировать наш переводчик. Для автокодировщика это может быть стандартная кросс-энтропия, но этого недостаточно для перевода. Пока опустим это и продолжим.
ОК, сейчас у нас есть способ построить наш автокодировщик. Следующее, что мы должны сделать, — это натренировать их пару: один для языка-источника (стиля) и другой для целевого языка. И еще нам нужно их скрестить, чтобы декодировщик целевого языка мог "восстанавливать" закодированные строки языка-источника, и наоборот, что в данном случае все равно.
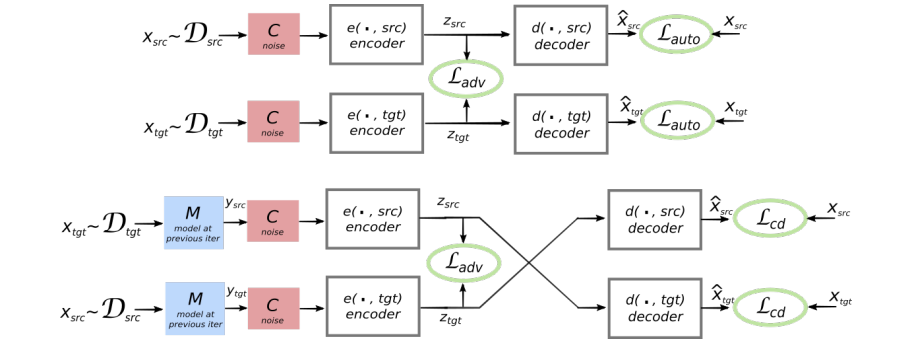
Сейчас будет самое сложное для понимания: в автокодировщике (или любом другом кодировщике-декодировщике) посередине есть так называемое скрытое представление — вектор из некоторого пространства высокой размерности. Если мы хотим, чтобы два автокодировщика были совместимы (в том смысле, который нам нужен), мы должны добиться того, чтобы скрытые представление были из одного пространства. Как этого достичь? С помощью добавления дополнительного штрафа для этих автокодировщиков. Этот штраф назначается дискриминатором, который отсылает нас к концепции GAN.
- GAN — Generative Adversarial Network. Идея GAN может быть выражена, как "сеть играет сама с собой и пытается саму себя обмануть". В архитектуре GAN выделяется три главных компонента: генератор — он производит представления, которые должны как можно сильнее быть похожи на настоящие, Golden Source — выдает настоящие представления, и дискриминатор — он должен отличить от кого ему пришел вход, от генератора или Golden Source; генератор наказывается, если дискриминатор может это угадать. Но верно и обратное — дискриминатор наказывается, если он угадать не может. Таким образом они тренируются совместно в соревновании между собой.
В нашем случае дискриминатор (L_adv на картинке) должен сказать, откуда к нему пришел вход — из языка-источника или целевого языка. На картинке выше изображены два автокодировщика в виде отдельных блоков — кодировщиков и декодировщиков. В середине между ними есть связь, где и расположен дискриминатор. Тренируя два автокодировщика с таким дополнительным штрафом, мы вынуждаем модель делать скрытые представления для обоих автокодировщиков похожими (верхняя часть картинки), а дальше уже все ясно — просто заменим оригинальный декодировщик его аналог из другого автокодировщика (нижняя часть картинки) и вуаля — наша модель может переводить!
Все три упомянутые в этом разделе работы имеют эту идею в своей основе, конечно, со своими особенностями. Пояснение выше большей частью основывается на работе Unsupervised Machine Translation Using Monolingual Corpora Only, так что я должен упомянуть предыдущую работу этих авторов, тем более, что ее результаты используются в обсуждаемой работе выше:
Идея этой работы, также проста, как все гениальное:

Скажем, у нас есть векторные представления для слов двух разных языков. (Предположим, что мы работаем с текстами из одного домена, например, новостями или художественной литературой.) Мы можем достаточно обоснованно предполагать, что словари для этих языков будут весьма близки: для большинства слов из корпуса-источника мы сможем найти соответствия словам целевого корпуса — например, слова, обозначающие понятия, президент, экология и налоги наверняка будут в новостных корпусах на обоих языках. Так почему бы просто не связать такие слова между собой и натянуть одно векторное пространство на другое? Собственно, так они и сделали. Нашли такую функцию, которая преобразует векторные пространства и накладывает точки одного (слова) на точки другого. В этой работе авторы показали, что это можно сделать без учителя, что означает, что им не нужен словарь как таковой.
Работа Style-Transfer from Non-Parallel Text by Cross-Alignment помещена в этой секции, т.к. языки могут быть рассмотрены, как разные стили текста, и авторы сами упоминают про это в своей работе. Также эта работа интересна, т.к. к ней доступна реализация.
Controllable Text Generation
Эта секция близка по духу к предыдущей, но все-таки достаточно существенно отличается. Работы, которые тут будут рассмотрены:
В первой работе представлен другой подход в переносу стиля на текстах, который ближе к контролируемой генерации, так что эта работа помещена здесь, в отличие от предыдущей. Идея контролируемой генерации может быть проиллюстрирована следующей картинкой:
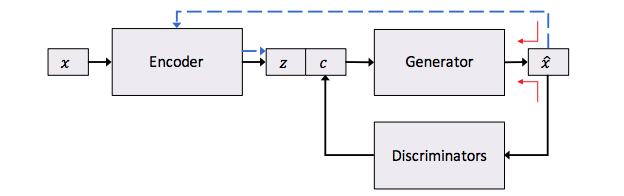
Здесь мы снова видим автокодировщик на тексте, но у него есть особенность: скрытое представление (которое здесь отвечает за смысл) дополнительно обогащено специальными признаками. Эти признаки кодируют специфические свойства текста, такие как тональность или грамматическое время.
На картинке также можно заметить дискриминатор в дополнение к автокодировщику. Дискриминаторов может быть даже больше одного, если мы хотим кодировать больше специфических свойств. В итоге, у нас есть сложная функция потерь — reconstruction loss от автокодировщика и дополнительный штраф для специфических свойств текста. Таким образом, reconstruction loss здесь отвечает только и исключительно за смысл предложения, без других свойств.
Simple Recurrent Unit
Последняя, но от этого не менее важная секция. Она также посвящена скорости вычислений. Несмотря на то, что в начале статьи мы обсуждали потрясение основ в виде возвращения полносвязных сетей, тем не менее все современные системы в NLP работают на рекуррентных сетях. А все знают, что RNN гораздо медленнее CNN. Или нет? Чтобы ответить на этот вопрос, давайт рассмотрим следующую статью:
Я думаю, что авторы этой работы пытались ответить на вопрос: почему же RNN такие медленные? Что их делает такими? И они нашли ключ к решению: RNN — последовательны по своей природе. Но что если можно оставить только небольшой кусочек этой последовательной природы, а все остальное делать параллельно? Давайте предположим, что (почти) все не зависит от своего предыдущего состояния. Тогда мы сможем обрабатывать всю последовательность входов параллельно. Так что задача состоит в том, чтобы выкинуть все ненужные зависимости от предыдущих состояний. И вот к чему это привело:

Как вы видите, только два последних уравнения зависят от предыдущего состояния. И в этих двух уравнениях мы работаем с векторами, а не матрицами. А все тяжелые вычисления могут быть сделаны независимо и параллельно. И потом мы просто делаем немного перемножений, чтобы обработать данные последовательно. Такая постановка показала прекрасные результаты, смотрите сами:
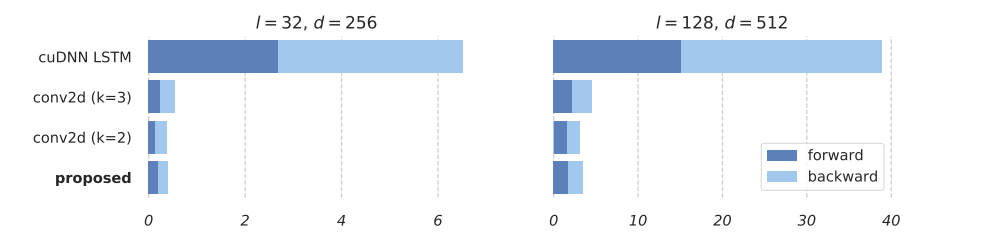
Скорость Simple Recurrent Unit (SRU) почти такая же, как у CNN!
Заключение
В 2017-ом году в нашей области появились новые сильные игроки, такие как Transformer, и были сделаны прорывы, как работающий машинный перевод без учителя, но и старички не сдаются — SRU еще постоят за честь RNN в этой схватке. Так что я смотрю в 2018-ый с надеждой на новые прорывы, которых я еще не могу представить.
