
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.

CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Термин «машинное обучение» появился еще в 50-х годах. Этот термин обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено. В современном мире мы сталкиваемся с плодами машинного обучения ежедневно по многу раз, многие из нас сами того не подозревая. Оно используется для построения лент в социальных сетях, списков «похожих товаров» в интернет-магазинах, при выдаче кредитов в банках и определении стоимости страховки. На технологиях машинного обучения работает поиск лиц на фотографиях или многочисленные фотофильтры. Для последних, кстати, обычно используются нейронные сети, и о них пишут так часто, что может сложиться ошибочное мнение, будто бы это «серебряная пуля» для решения задач любой сложности. Но это не так.
Нейросети или градиентный бустинг
На самом деле, машинное обучение очень разное: существует большое количество разных методов, и нейросети – лишь один из них. Иллюстрацией этого являются результаты соревнований на платформе Kaggle, где на разных соревнованиях побеждают разные методы, причем на очень многих побеждает градиентный бустинг.
Нейросети прекрасно решают определенные задачи – например, те, где нужно работать с однородными данными. Из однородных данных состоят, например, изображения, звук или текст. В Яндексе они помогают нам лучше понимать поисковые запросы, ищут похожие картинки в интернете, распознают ваш голос в Навигаторе и многое другое. Но это далеко не все задачи для машинного обучения. Существует целый пласт серьезных вызовов, которые не могут быть решены только нейросетями – им нужен градиентный бустинг. Этот метод незаменим там, где много данных, а их структура неоднородна.
Например, если вам нужен точный прогноз погоды, где учитывается огромное количество факторов (температура, влажность, данные с радаров, наблюдения пользователей и многие другие). Или если вам нужно качественно ранжировать поисковую выдачу – именно это в свое время и подтолкнуло Яндекс к разработке собственного метода машинного обучения.
Матрикснет
Первые поисковые системы были не такими сложными, как сейчас. Фактически сначала был просто поиск слов – сайтов было так мало, что особой конкуренции между ними не было. Потом страниц стало больше, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf. Затем страниц стало слишком много на любую тему, произошёл первый важный прорыв — начали учитывать ссылки.
Вскоре интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. И произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Лет десять назад человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Вы, наверное, замечали, что количество найденного почти по любому запросу огромно: сотни тысяч, часто — миллионы результатов. Большая часть из них неинтересные, бесполезные, лишь случайно упоминают слова запроса или вообще являются спамом. Для ответа на ваш запрос нужно мгновенно отобрать из всех найденных результатов десятку лучших. Написать программу, которая делает это с приемлемым качеством, стало не под силу программисту-человеку. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Яндекс еще в 2009 году внедрили собственный метод Матрикснет, основанный на градиентном бустинге. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования теперь пишет машина. Кстати, в качестве отдельных факторов мы в том числе используем результаты работы нейронных сетей (к примеру, так работает алгоритм Палех, о котором рассказывали в прошлом году).
Важная особенность Матрикснета в том, что он устойчив к переобучению. Это позволяет учитывать очень много факторов ранжирования и при этом обучаться на относительно небольшом количестве данных, не опасаясь, что машина найдет несуществующие закономерности. Другие методы машинного обучения позволяют либо строить более простые формулы с меньшим количеством факторов, либо нуждаются в большей обучающей выборке.
Ещё одна важная особенность Матрикснета — в том, что формулу ранжирования можно настраивать отдельно для достаточно узких классов запросов. Например, улучшить качество поиска только по запросам про музыку. При этом ранжирование по остальным классам запросов не ухудшится.
Именно Матрикснет и его достоинства легли в основу CatBoost. Но зачем нам вообще понадобилось изобретать что-то новое?
Категориальный бустинг
Практически любой современный метод на основе градиентного бустинга работает с числами. Даже если у вас на входе жанры музыки, типы облаков или цвета, то эти данные все равно нужно описать на языке цифр. Это приводит к искажению их сути и потенциальному снижению точности работы модели.
Продемонстрируем это на примитивном примере с каталогом товаров в магазине. Товары мало связаны между собой, и не существует такой закономерности между ними, которая позволила бы упорядочить их и присвоить осмысленный номер каждому продукту. Поэтому в этой ситуации каждому товару просто присваивают порядковый id (к примеру, в соответствии с программой учета в магазине). Порядок этих чисел ничего не значит, однако алгоритм будет этот порядок использовать и делать из него ложные выводы.
Опытный специалист, работающий с машинным обучением, может придумать более интеллектуальный способ превращения категориальных признаков в числовые, однако такая предварительная предобработка приведет к потере части информации и приведет к ухудшению качества итогового решения.
Именно поэтому было важно научить машину работать не только с числами, но и с категориями напрямую, закономерности между которыми она будет выявлять самостоятельно, без нашей ручной «помощи». И CatBoost разработан нами так, чтобы одинаково хорошо работать «из коробки» как с числовыми признаками, так и с категориальными. Благодаря этому он показывает более высокое качество обучения при работе с разнородными данными, чем альтернативные решения. Его можно применять в самых разных областях — от банковской сферы до промышленности.
Кстати, название технологии происходит как раз от Categorical Boosting (категориальный бустинг). И ни один кот при разработке не пострадал.
Бенчмарки
Можно долго говорить о теоретических отличиях библиотеки, но лучше один раз показать на практике. Для наглядности мы сравнили работу библиотеки CatBoost с открытыми аналогами XGBoost, LightGBM и H20 на наборе публичных датасетов. И вот результаты (чем меньше, тем лучше): https://catboost.yandex/#benchmark
Не хотим быть голословными, поэтому вместе с библиотекой в open source выложены описание процесса сравнения, код для запуска сравнения методов и контейнер с использованными версиями всех библиотек. Любой пользователь может повторить эксперимент у себя или на своих данных.
CatBoost на практике
Новый метод уже протестировали на сервисах Яндекса. Он применялся для улучшения результатов поиска, ранжирования ленты рекомендаций Яндекс.Дзен и для расчета прогноза погоды в технологии Метеум — и во всех случаях показал себя лучше Матрикснета. В дальнейшем CatBoost будет работать и на других сервисах. Не будем здесь останавливаться – лучше сразу расскажем про Большой адронный коллайдер (БАК).
CatBoost успел найти себе применение и в рамках сотрудничества с Европейской организацией по ядерным исследованиям. В БАК работает детектор LHCb, используемый для исследования асимметрии материи и антиматерии во взаимодействиях тяжёлых прелестных кварков. Чтобы точно отслеживать разные частицы, регистрируемые в эксперименте, в детекторе существуют несколько специфических частей, каждая из которых определяет специальные свойства частиц. Наиболее сложной задачей при этом является объединение информации с различных частей детектора в максимально точное, агрегированное знание о частице. Здесь и приходит на помощь машинное обучение. Используя для комбинирования данных CatBoost, учёным удалось добиться улучшения качественных характеристик финального решения. Результаты CatBoost оказались лучше результатов, получаемых с использованием других методов.
Как начать использовать CatBoost?
Для работы с CatBoost достаточно установить его на свой компьютер. Библиотека поддерживает операционные системы Linux, Windows и macOS и доступна на языках программирования Python и R. Яндекс разработал также программу визуализации CatBoost Viewer, которая позволяет следить за процессом обучения на графиках.
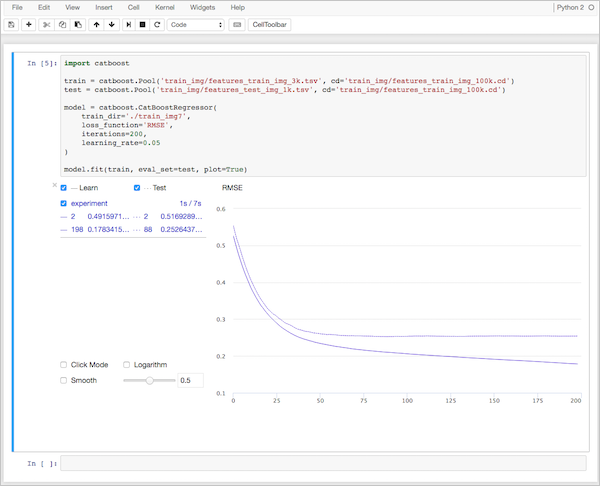
Более подробно все описано в нашей документации.
CatBoost — первая российская технология машинного обучения такого масштаба, которая стала доступна в open sourсe. Выкладывая библиотеку в открытый доступ, мы хотим внести свой вклад в развитие машинного обучения. Надеемся, что сообщество специалистов оценит технологию и примет участие в ее развитии.

CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Термин «машинное обучение» появился еще в 50-х годах. Этот термин обозначает попытку научить компьютер решать задачи, которые легко даются человеку, но формализовать путь их решения сложно. В результате машинного обучения компьютер может демонстрировать поведение, которое в него не было явно заложено. В современном мире мы сталкиваемся с плодами машинного обучения ежедневно по многу раз, многие из нас сами того не подозревая. Оно используется для построения лент в социальных сетях, списков «похожих товаров» в интернет-магазинах, при выдаче кредитов в банках и определении стоимости страховки. На технологиях машинного обучения работает поиск лиц на фотографиях или многочисленные фотофильтры. Для последних, кстати, обычно используются нейронные сети, и о них пишут так часто, что может сложиться ошибочное мнение, будто бы это «серебряная пуля» для решения задач любой сложности. Но это не так.
Нейросети или градиентный бустинг
На самом деле, машинное обучение очень разное: существует большое количество разных методов, и нейросети – лишь один из них. Иллюстрацией этого являются результаты соревнований на платформе Kaggle, где на разных соревнованиях побеждают разные методы, причем на очень многих побеждает градиентный бустинг.
Нейросети прекрасно решают определенные задачи – например, те, где нужно работать с однородными данными. Из однородных данных состоят, например, изображения, звук или текст. В Яндексе они помогают нам лучше понимать поисковые запросы, ищут похожие картинки в интернете, распознают ваш голос в Навигаторе и многое другое. Но это далеко не все задачи для машинного обучения. Существует целый пласт серьезных вызовов, которые не могут быть решены только нейросетями – им нужен градиентный бустинг. Этот метод незаменим там, где много данных, а их структура неоднородна.
Например, если вам нужен точный прогноз погоды, где учитывается огромное количество факторов (температура, влажность, данные с радаров, наблюдения пользователей и многие другие). Или если вам нужно качественно ранжировать поисковую выдачу – именно это в свое время и подтолкнуло Яндекс к разработке собственного метода машинного обучения.
Матрикснет
Первые поисковые системы были не такими сложными, как сейчас. Фактически сначала был просто поиск слов – сайтов было так мало, что особой конкуренции между ними не было. Потом страниц стало больше, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf. Затем страниц стало слишком много на любую тему, произошёл первый важный прорыв — начали учитывать ссылки.
Вскоре интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. И произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
Лет десять назад человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Вы, наверное, замечали, что количество найденного почти по любому запросу огромно: сотни тысяч, часто — миллионы результатов. Большая часть из них неинтересные, бесполезные, лишь случайно упоминают слова запроса или вообще являются спамом. Для ответа на ваш запрос нужно мгновенно отобрать из всех найденных результатов десятку лучших. Написать программу, которая делает это с приемлемым качеством, стало не под силу программисту-человеку. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Яндекс еще в 2009 году внедрили собственный метод Матрикснет, основанный на градиентном бустинге. Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы». Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования теперь пишет машина. Кстати, в качестве отдельных факторов мы в том числе используем результаты работы нейронных сетей (к примеру, так работает алгоритм Палех, о котором рассказывали в прошлом году).
Важная особенность Матрикснета в том, что он устойчив к переобучению. Это позволяет учитывать очень много факторов ранжирования и при этом обучаться на относительно небольшом количестве данных, не опасаясь, что машина найдет несуществующие закономерности. Другие методы машинного обучения позволяют либо строить более простые формулы с меньшим количеством факторов, либо нуждаются в большей обучающей выборке.
Ещё одна важная особенность Матрикснета — в том, что формулу ранжирования можно настраивать отдельно для достаточно узких классов запросов. Например, улучшить качество поиска только по запросам про музыку. При этом ранжирование по остальным классам запросов не ухудшится.
Именно Матрикснет и его достоинства легли в основу CatBoost. Но зачем нам вообще понадобилось изобретать что-то новое?
Категориальный бустинг
Практически любой современный метод на основе градиентного бустинга работает с числами. Даже если у вас на входе жанры музыки, типы облаков или цвета, то эти данные все равно нужно описать на языке цифр. Это приводит к искажению их сути и потенциальному снижению точности работы модели.
Продемонстрируем это на примитивном примере с каталогом товаров в магазине. Товары мало связаны между собой, и не существует такой закономерности между ними, которая позволила бы упорядочить их и присвоить осмысленный номер каждому продукту. Поэтому в этой ситуации каждому товару просто присваивают порядковый id (к примеру, в соответствии с программой учета в магазине). Порядок этих чисел ничего не значит, однако алгоритм будет этот порядок использовать и делать из него ложные выводы.
Опытный специалист, работающий с машинным обучением, может придумать более интеллектуальный способ превращения категориальных признаков в числовые, однако такая предварительная предобработка приведет к потере части информации и приведет к ухудшению качества итогового решения.
Именно поэтому было важно научить машину работать не только с числами, но и с категориями напрямую, закономерности между которыми она будет выявлять самостоятельно, без нашей ручной «помощи». И CatBoost разработан нами так, чтобы одинаково хорошо работать «из коробки» как с числовыми признаками, так и с категориальными. Благодаря этому он показывает более высокое качество обучения при работе с разнородными данными, чем альтернативные решения. Его можно применять в самых разных областях — от банковской сферы до промышленности.
Кстати, название технологии происходит как раз от Categorical Boosting (категориальный бустинг). И ни один кот при разработке не пострадал.
Бенчмарки
Можно долго говорить о теоретических отличиях библиотеки, но лучше один раз показать на практике. Для наглядности мы сравнили работу библиотеки CatBoost с открытыми аналогами XGBoost, LightGBM и H20 на наборе публичных датасетов. И вот результаты (чем меньше, тем лучше): https://catboost.yandex/#benchmark
Не хотим быть голословными, поэтому вместе с библиотекой в open source выложены описание процесса сравнения, код для запуска сравнения методов и контейнер с использованными версиями всех библиотек. Любой пользователь может повторить эксперимент у себя или на своих данных.
CatBoost на практике
Новый метод уже протестировали на сервисах Яндекса. Он применялся для улучшения результатов поиска, ранжирования ленты рекомендаций Яндекс.Дзен и для расчета прогноза погоды в технологии Метеум — и во всех случаях показал себя лучше Матрикснета. В дальнейшем CatBoost будет работать и на других сервисах. Не будем здесь останавливаться – лучше сразу расскажем про Большой адронный коллайдер (БАК).
CatBoost успел найти себе применение и в рамках сотрудничества с Европейской организацией по ядерным исследованиям. В БАК работает детектор LHCb, используемый для исследования асимметрии материи и антиматерии во взаимодействиях тяжёлых прелестных кварков. Чтобы точно отслеживать разные частицы, регистрируемые в эксперименте, в детекторе существуют несколько специфических частей, каждая из которых определяет специальные свойства частиц. Наиболее сложной задачей при этом является объединение информации с различных частей детектора в максимально точное, агрегированное знание о частице. Здесь и приходит на помощь машинное обучение. Используя для комбинирования данных CatBoost, учёным удалось добиться улучшения качественных характеристик финального решения. Результаты CatBoost оказались лучше результатов, получаемых с использованием других методов.
Как начать использовать CatBoost?
Для работы с CatBoost достаточно установить его на свой компьютер. Библиотека поддерживает операционные системы Linux, Windows и macOS и доступна на языках программирования Python и R. Яндекс разработал также программу визуализации CatBoost Viewer, которая позволяет следить за процессом обучения на графиках.
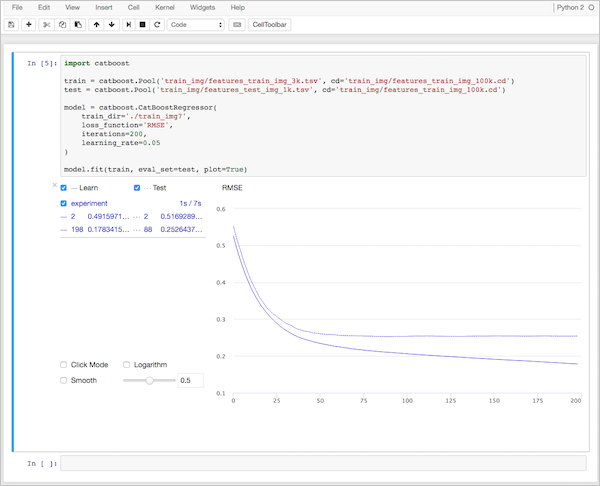
Более подробно все описано в нашей документации.
CatBoost — первая российская технология машинного обучения такого масштаба, которая стала доступна в open sourсe. Выкладывая библиотеку в открытый доступ, мы хотим внести свой вклад в развитие машинного обучения. Надеемся, что сообщество специалистов оценит технологию и примет участие в ее развитии.
