Если слово Xapian вам незнакомо, рекомендую ознакомиться с небольшой статьей.
Вкратце же, Xapian — представляет собой написанный на с++ набор инструментов для индексирования текстовой информации, с возможностью поиска по базе индексированной информации. Для работы не требует установленного сервера, достаточно наличия его библиотек. Может обрабатывать огромные массивы информации(проверено до 1.5Тб), измеряемой миллионами документов. Является конкурирующим продуктом Sphinx и Apache Lucene.
Мной он был выбран из этих трех продуктов за возможность использования из .Net.
Прежде всего нужно скачать dll' ки Xapian под .Net.
Затем еще одну вспомогательную dll — Zlib1.dll, без нее будут выкидываться исключения при попытке обращения оберточной dll к скомпиленной на C++.
Собственно для работы это все что требовалось. Можно создавать проект. XapianCSharp.dll сразу добавляем в Reference. _XapianSharp.dll и zlib1.dll добавляем в проект(просто как контент), и помечаем Copy to Output Directory как Copy always.
Делаем две функции для тестирования работы:
Функцию Write напишите на свой вкус.
Теперь создаем каталог с текстовыми файлами, или используем имеющийся, вызываем IndexFolder(имя_каталога), ждем пока файлы проиндексируются. И можем вызывать Search, передавая строку с ключевыми словами для поиска, разделенных пробелом.
Конфигурация железа:
Intel Pentium III 996Mhz
Ram 256Mb
Количество индексируемых файлов: 641489
Объем индексируемых файлов: 2,38Gb
Время индексирования файлов: больше недели(помним о железе, на 4x Core операция займет, скорее всего, несколько часов, своп соответственно тоже снижает производительность в разы).
Нагрузка во время индексирования
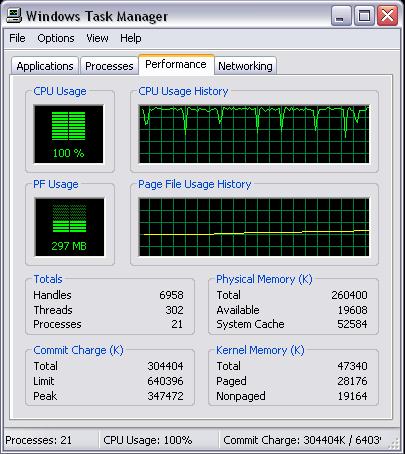
Таблица среднего времени поиска
Показатели весьма оптимистичные, особенно для такой слабой машины.
Источники:
Статья на codeproject'е
Официальный сайт
Вкратце же, Xapian — представляет собой написанный на с++ набор инструментов для индексирования текстовой информации, с возможностью поиска по базе индексированной информации. Для работы не требует установленного сервера, достаточно наличия его библиотек. Может обрабатывать огромные массивы информации(проверено до 1.5Тб), измеряемой миллионами документов. Является конкурирующим продуктом Sphinx и Apache Lucene.
Мной он был выбран из этих трех продуктов за возможность использования из .Net.
Прежде всего нужно скачать dll' ки Xapian под .Net.
Затем еще одну вспомогательную dll — Zlib1.dll, без нее будут выкидываться исключения при попытке обращения оберточной dll к скомпиленной на C++.
Собственно для работы это все что требовалось. Можно создавать проект. XapianCSharp.dll сразу добавляем в Reference. _XapianSharp.dll и zlib1.dll добавляем в проект(просто как контент), и помечаем Copy to Output Directory как Copy always.
Делаем две функции для тестирования работы:
....
using Xapian;
....
//Путь указываем куда хотим, если базы по нему не окажется
//она будет создана автоматически
string xapianBase="H:\\XapianDB\\xap.db";
....
//Индексирование файлов указанного каталога
//без рекурсии
private void IndexFolder(string path)
{
try
{
if (Directory.Exists(path))
{
string[] files=Directory.GetFiles(tbIndexFolder.Text);
using (WritableDatabase database=new WritableDatabase(xapianBase, Xapian.Xapian.DB_CREATE_OR_OPEN))
{
using (TermGenerator indexer=new TermGenerator())
{
using (Stem stemmer=new Xapian.Stem("russian"))
{
indexer.SetStemmer(stemmer);
foreach (string file in files)
{
using (Document doc=new Document())
{
//Имя файла используется как ключ, оно и будет выдаваться при поиске
doc.SetData(file);
indexer.SetDocument(doc);
//Не забываем указывать кодировку ваших документов
indexer.IndexText(File.ReadAllText(file, Encoding.GetEncoding(1251)));
//Пишем в базу
database.AddDocument(doc);
}
}
}
}
}
}
}
catch (Exception ex)
{
Write("Exception: "+ex.ToString());
}
}
private void Search(string searchText)
{
try
{
// Открываем базу для поиска
using (Database database=new Database(xapianBase))
{
using (Enquire enquire=new Enquire(database))
{
using (QueryParser qp=new QueryParser())
{
using (Stem stemmer=new Stem("russian"))
{
Write(stemmer.GetDescription());
qp.SetStemmer(stemmer);
qp.SetDatabase(database);
qp.SetStemmingStrategy(QueryParser.stem_strategy.STEM_SOME);
using (Query query=qp.ParseQuery(searchText))
{
Write("Parsed query is: "+query.GetDescription());
enquire.SetQuery(query);
//Тут указываем с какого по какой результат хотим получить
//в данном случае получим первые 100 совпадений
MSet matches=enquire.GetMSet(0, 100);
Write(String.Format("{0} results found.", matches.GetMatchesEstimated()));
Write(String.Format("Matches 1-{0}:", matches.Size()));
//Выполняем поиск
MSetIterator m=matches.Begin();
//Выводим результат поиска
while (m!=matches.End())
{
Write(String.Format("{0}: {1}% docid={2} [{3}]\n",
m.GetRank()+1,
m.GetPercent(),
m.GetDocId(),
m.GetDocument().GetData()));
++m;
}
}
}
}
}
}
}
catch (Exception ex)
{
Write("Exception: "+ex.ToString());
}
}
Функцию Write напишите на свой вкус.
Теперь создаем каталог с текстовыми файлами, или используем имеющийся, вызываем IndexFolder(имя_каталога), ждем пока файлы проиндексируются. И можем вызывать Search, передавая строку с ключевыми словами для поиска, разделенных пробелом.
Тестирование.
Конфигурация железа:
Intel Pentium III 996Mhz
Ram 256Mb
Количество индексируемых файлов: 641489
Объем индексируемых файлов: 2,38Gb
Время индексирования файлов: больше недели(помним о железе, на 4x Core операция займет, скорее всего, несколько часов, своп соответственно тоже снижает производительность в разы).
Нагрузка во время индексирования
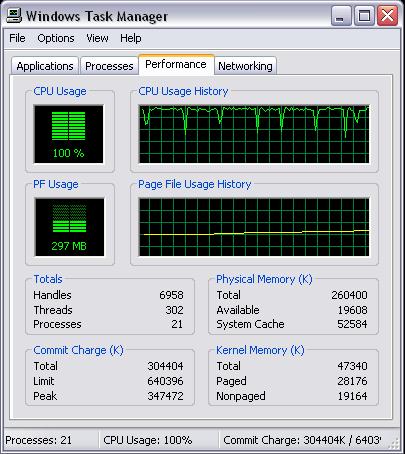
Таблица среднего времени поиска
| Количество слов | Поиск | Время |
| 1 | 1 | 1883 мс. |
| 1 | 2 | 28 мс. |
| 1 | 3 | 31 мс. |
| 2 | 1 | 175 мс. |
| 2 | 2 | 36 мс. |
| 2 | 3 | 41 мс. |
| 3 | 1 | 1074 мс. |
| 3 | 2 | 35 мс. |
| 3 | 3 | 37 мс. |
Показатели весьма оптимистичные, особенно для такой слабой машины.
Источники:
Статья на codeproject'е
Официальный сайт
