Решил взять небольшую паузу в ежедневном хобби-кодировании, и поделиться с вами описанием того, что я, собственно, делаю. Итак, я пытаюсь разработать и реализовать виртуальную машину для несуществующей операционной системы, которую я, быть может, тоже когда-нибудь начну воплощать в жизнь. Не буду спорить с пеною у рта, доказывая, зачем нужна ещё одна ОС, отвечу кратко: главным образом затем, что мне это интересно.

1. Существует две главных сущности: модуль и поток.
2. Модуль содержит в себе неизменный код и изменяемые данные.
3. Модуль перманентен.
Последний пункт говорит о том, что модуль существует всегда. На практике это должно реализовываться посредством виртуальной памяти. Т.е. страницы модуля, используемые в данный момент, подгружается в оперативную память, а неиспользованные – выгружается на диск. Поддержка перманентности должна быть на уровне системы, т.е. совершенно прозрачной для прикладного программиста. Это можно считать свопом, доведённым до логического завершения, когда нам не нужно больше загружать модуль в оперативную память, поскольку он будет находиться в “вечном” свопе, и автоматически подгружаться по требованию. Другими словами, файловая система больше не понадобится.
4. Модуль имеет множество внешних процедур, доступных для вызова извне. Данные модуля доступны только косвенно, через его внешние процедуры.
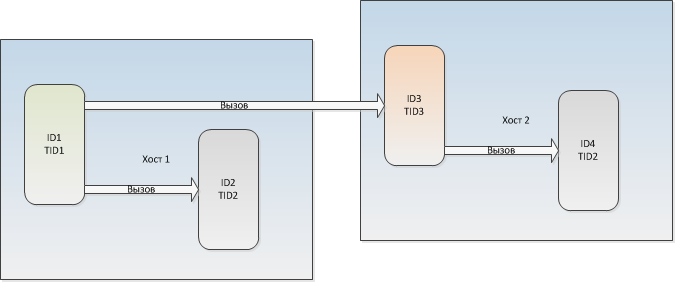
5. Модуль имеет UUID экземпляра (ID) и UUID типа (TID).
6. При копировании модуля, для копии генерируется новый ID, но сохраняется старый TID.
7. Модуль может быть найден по ID в глобальной сети, или по TID на локальном хосте.
Каждому TID на локальном хосте соответствует только один модуль, даже если есть несколько модулей с одинаковым TID.
8. Поток может вызвать внешнюю процедуру по ID её модуля и её числовому идентификатору.
9. Поток может вызвать внешнюю процедуру по TID её модуля, расположенного на том же хосте, и её числовому идентификатору.
Грубо говоря, TID необходим для использования модулей как динамически загружаемые библиотеки. В самом деле, на хостах будет много одинакового кода (системное ПО, кодеки, и проч.), доступ к которым должен быть очень эффективным, и которые не имеет смысла использовать удалённо.
1. Вызов внешней процедуры синхронен.
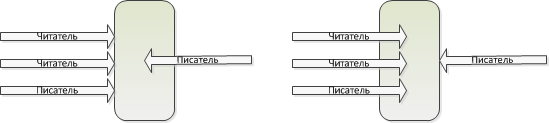
2. Внешняя процедура может быть функцией (f-процедурой), читателем (r-процедурой) или писателем (w-процедурой). F-процедура не использует модифицируемые данные модуля, r-процедура читает модифицируемые данные, а w-процедура их изменяет.
3. Вызов f-процедуры модуля вызываются без блокирования.
4. Вызов r-процедуры не блокируется, если в данном модуле уже вызваны другие r-процедуры.
5. Вызов r-процедуры и w-процедуры блокируется, если в данном модуле уже вызвана w-процедура.
6. Если r-процедуры и w-процедуры блокированы, при разблокировке первой выполняется w-процедура.
Т.е. может быть множество читателей без писателя, или только один писатель. Писатель имеет более высокий приоритет над читателями.
В вышеприведённых тезисах очень много чего не хватает. В частности, совершенно отсутствуют архитектура безопасности. Увы, её я пока не могу сформулировать.
В последующих постах я опишу общую архитектуру виртуальной машины, а также детали её реализации вплоть до текущего состояния проекта. К слову сказать, текущая реализация способна исполнять программы вычисления факториала и быстрой сортировки. Для преждевременно любопытствующих даю ссылку на репозиторий: github.com/ababo/AntOS-VM-Prototype

Итак, моё текущее видение системной архитектуры.
1. Существует две главных сущности: модуль и поток.
2. Модуль содержит в себе неизменный код и изменяемые данные.
3. Модуль перманентен.
Последний пункт говорит о том, что модуль существует всегда. На практике это должно реализовываться посредством виртуальной памяти. Т.е. страницы модуля, используемые в данный момент, подгружается в оперативную память, а неиспользованные – выгружается на диск. Поддержка перманентности должна быть на уровне системы, т.е. совершенно прозрачной для прикладного программиста. Это можно считать свопом, доведённым до логического завершения, когда нам не нужно больше загружать модуль в оперативную память, поскольку он будет находиться в “вечном” свопе, и автоматически подгружаться по требованию. Другими словами, файловая система больше не понадобится.
4. Модуль имеет множество внешних процедур, доступных для вызова извне. Данные модуля доступны только косвенно, через его внешние процедуры.
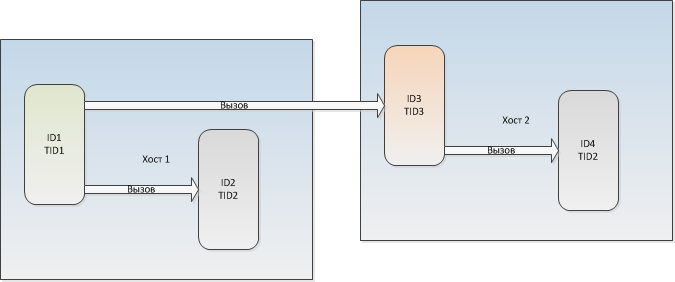
5. Модуль имеет UUID экземпляра (ID) и UUID типа (TID).
6. При копировании модуля, для копии генерируется новый ID, но сохраняется старый TID.
7. Модуль может быть найден по ID в глобальной сети, или по TID на локальном хосте.
Каждому TID на локальном хосте соответствует только один модуль, даже если есть несколько модулей с одинаковым TID.
8. Поток может вызвать внешнюю процедуру по ID её модуля и её числовому идентификатору.
9. Поток может вызвать внешнюю процедуру по TID её модуля, расположенного на том же хосте, и её числовому идентификатору.
Грубо говоря, TID необходим для использования модулей как динамически загружаемые библиотеки. В самом деле, на хостах будет много одинакового кода (системное ПО, кодеки, и проч.), доступ к которым должен быть очень эффективным, и которые не имеет смысла использовать удалённо.
Теперь модель многопоточной синхронизации.
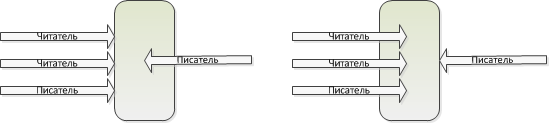
1. Вызов внешней процедуры синхронен.
2. Внешняя процедура может быть функцией (f-процедурой), читателем (r-процедурой) или писателем (w-процедурой). F-процедура не использует модифицируемые данные модуля, r-процедура читает модифицируемые данные, а w-процедура их изменяет.
3. Вызов f-процедуры модуля вызываются без блокирования.
4. Вызов r-процедуры не блокируется, если в данном модуле уже вызваны другие r-процедуры.
5. Вызов r-процедуры и w-процедуры блокируется, если в данном модуле уже вызвана w-процедура.
6. Если r-процедуры и w-процедуры блокированы, при разблокировке первой выполняется w-процедура.
Т.е. может быть множество читателей без писателя, или только один писатель. Писатель имеет более высокий приоритет над читателями.
В вышеприведённых тезисах очень много чего не хватает. В частности, совершенно отсутствуют архитектура безопасности. Увы, её я пока не могу сформулировать.
В последующих постах я опишу общую архитектуру виртуальной машины, а также детали её реализации вплоть до текущего состояния проекта. К слову сказать, текущая реализация способна исполнять программы вычисления факториала и быстрой сортировки. Для преждевременно любопытствующих даю ссылку на репозиторий: github.com/ababo/AntOS-VM-Prototype
