В далёком 2014 я ещё учился на экономиста, но уже очень мечтал уйти в анализ данных. И когда мне предложили выполнить мой первый платный разработческий проект для моего университета, я был счастлив. Проект заключался в написании кода эконометрической модели для пакета Stata. Стату я с тех пор люто возненавидел, но сам проект научил меня многому.
В этом посте я расскажу про Cross-Nested Ordered Probit, забавную модель для предсказания порядковых величин, покажу её код на PyTorch, и порассуждаю о различиях и сходствах машинного обучения и эконометрики.
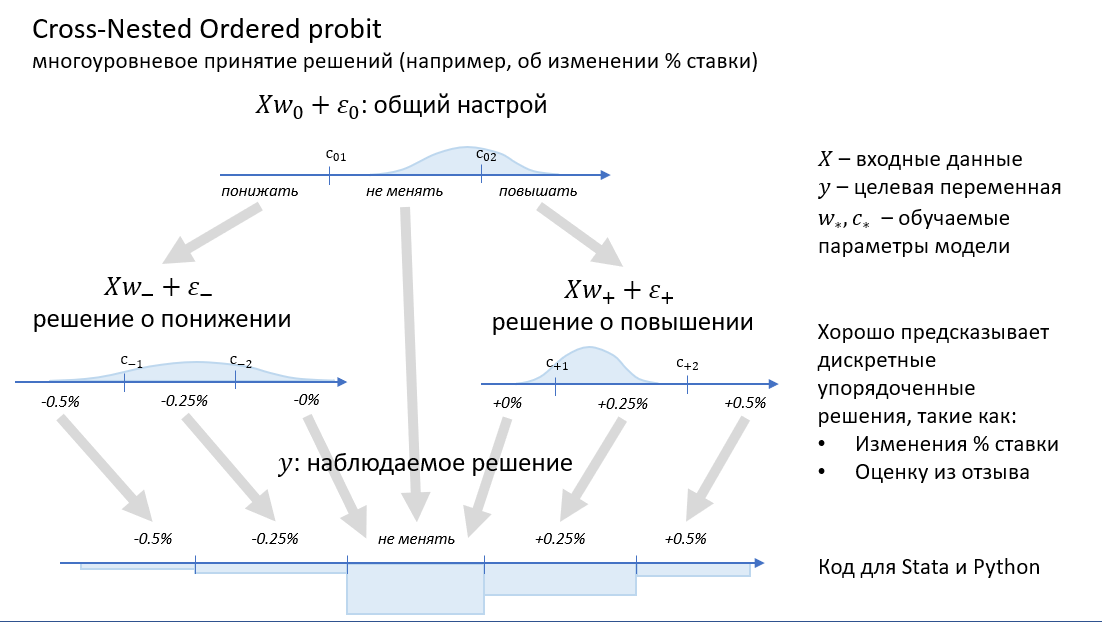
В этом посте я рассказываю об эконометрике в целом, повествую о тормозном ходе своего проекта, показываю устройство модели CNOP, и пытаюсь сделать выводы из всего этого. Если вас интересует в первую очередь модель, переходите сразу к третьей секции. Если же, наоборот, вас не интересует математика и код, смело пропускайте эту секцию.
В разделе про модель я привожу её код на питонячьем фреймворке PyTorch. Если вы эконометрист и привыкли работать в Stata, я надеюсь показать вам, что Python тоже удобный. Если вы MLщик и привыкли к PyTorch, возможно, вам покажутся интересными пара статистических трюков.
Об эконометрике
Эконометрика – это наука о применении статистических методов к экономическим данным. В самом начале XX века сформировалась современная статистика как наука: корреляции, проверки гипотез, метод максимального правдоподобия, всё вот это вот. Где-то в 30-х годах экономисты начали активно применять статистику для ответа на важные экономические вопросы типа "на сколько центов растёт ВВП страны при увеличении государственных расходов на один доллар?" или "влияет ли ключевая ставка центрального банка на совокупный объем инвестиций в стране?". Для этого обычно строили линейные регрессии с экономическими переменными, а потом применяли к их коэффициентам статистические тесты, например, чтобы проверить, действительно ли влияние ненулевое. За почти столетие разнообразие и сложность эконометрических моделей выросли, и современные крутые экономисты обосновывают ими свои теории. Иногда эконометрика применяется и на практике – например, в том же ЦБ.
Машинное обучение тоже выросло из статистических методов, но независимо от эконометрики – его создали в 50-х годах инженеры и программисты. Стартовав с той же позиции, что и эконометрика, ML пошло по иному пути. Эконометрика заботится о том, чтобы внутренняя структура модели максимально соответствовала реальности, и пытается делать выводы о мире из коэффициентов модели, подкрепляя их статистическими тестами и вдумчивым выбором переменных. Машинное обучение устроено более прагматично, там основная цель - чтобы прогноз был как можно ближе к реальности, и это проверяется "в лоб" на тестовой выборке, а структура модели подбирается та, которая позволяет в итоге делать прогнозы более точными. В итоге эконометрист и MLщик могут обучить две модели с совершенно одинаковой математической составляющей, но сделать из них очень разные выводы.
О проекте
Фаза первая: взрыв энтузиазма. Проект мне предложил Андрей, крутой препод-эконометрист. Модель CNOP придумал он в 2013 году (статья), и он же написал код для неё и пары похожих в допотопной программулине Gauss. Моей задачей было переписать этот код на Stata, чтобы им могли пользоваться другие люди, и написать про это статью для Stata Journal. Я взялся за дело с радостью, тем более и деньги за проект предлагались приятные.
Программа Stata устроена довольно забавно. Её основной интерфейс построен на идее low-code: нужно или вводить в командной строке простенькие императивные команды типа regress y x1 x2, или накликивать эти же команды через последовательность диалоговых окон. Этому мы учились на парах по эконометрике. Но внутреннюю логику этих команд на языке Stata описать сложно: там даже простые циклы не очень очевидные, а для имплементации нужно работать с матрицами, применять алгоритмы оптимизации, и всё такое. Поэтому, оказывается, под капотом Статы есть ещё один язык программирования – Mata, что-то среднее между C и Matlab. И вот по этой самой Мате особо нет ресурсов в интернете – ни книг, ни блогпостов, ни ответов на Stackoverflow, только толстенький официальный мануал. И вот этот мануал я сел потихоньку осваивать.
Первые версии нескольких моделек у меня получилось запустить довольно быстро, и я дико радовался, что всё работает: функция правдоподобия максимизируется, параметры оцениваются, магия – вершится. Но вершилась она довольно медленно и бажно, Mata регулярно сыпала ошибками, которых не было ни в документации, ни в интернете. Никакого автодифференцирования в Мате, конечно же нет, и все градиенты, равно как и матрицы вторых производных, мне нужно было вычислять вручную – и я делал это с кучей тупых ошибок. В мануале был подробно описан синтаксис языка и возможности встроенных функций, но я нигде не мог найти примеры проектов: как отлаживать код, как писать юнит-тесты, как раскладывать код по файлам, чтобы им было удобно пользоваться, как правильно сшивать воедино интерфейсы Stata и Mata. Кажется, про это просто никто не думал. А я думал и постепенно приунывал.
Фаза вторая: избегание. Первые несколько месяцев я старательно работал над проектом, искал костыли для возникающих у меня проблем, и казалось, что горизонт близко – пофиксить ещё несколько багов, доделать ещё несколько фич, провести кучу разного тестирования с готовыми моделями, написать текст статьи... Но потом меня захватила иная жизнь: диплом, госы, военка, поступление в магистратуру и ШАД, стажировка в Питере – и проект оказался на заднем плане. У меня не было нормального решения для некоторых технических проблем и не было с кем проконсультироваться о них, и это демотивировало. Я продолбал сроки, когда можно было получить за проект оплату, и это меня демотивировало ещё больше. Мне хотелось выйти из этого проекта – мол, возись сам со своей Статой – но я не чувствовал морального права на это. Я начал игнорировать письма от Андрея и паниковать, когда он звонил мне на телефон. Иногда я находил время и садился сделать что-то по проекту, но в целом он скорее стоял, чем двигался. И так продолжалось несколько лет. Несколько грёбаных лет.
Фаза третья: бесконечное доделывание. Я ковырял что-то по этому проекту в 2015 году - и тогда он был уже почти годов. И в 2016. В 2017 мы всё-таки сели и проделали большое исследование нашего семейства моделек на синтетических данных – и обнаружили кучу новых проблем. К 2018 году мы их пофиксили и таки выложили препринт статьи. Это была моя первая настоящая научная публикация, и я по идее должен был чувствовать триумф, но я, конечно же, его не чувствовал. Потом временем ревьюеры из Stata Journal предложили несколько правок, и правки эти требовали изменений в коде. Я обещал внести эти изменения, и откладывал их до 2019 года. Ещё одна итерация ревью затянулась до середины 2020. В следующем номере Stata Journal статья должна наконец-то выйти, наверное. Если вы пользуетесь Stata и хотите применить её у себя, то код есть в моём репозитории.
Почему я доделывал этот проект так медленно? Потому что у меня не было никакой мотивации с ним торопиться. Почему я его всё-таки доделал? Наверное, в первую очередь потому, что у меня не было нормального механизма для выхода из проекта, а оставлять проект навеки незавершённым мне не позволяла какое-то врождённое стремление к порядку. И вот ради этого непонятного абстрактного порядка я всё-таки выделил несколько десятков часов своей жизни на то чтобы сесть на задницу и завершить. И этот пост – последний мой шаг в завершении проекта.
О модели
Изначально модель называлась Cross-Nested Ordered Probit, потом мы переименовали её в Zero Inflated Ordered Probit. Первое название мне кажется более информативным, и сейчас я попробую эту информацию расшифровать и проиллюстрировать кодом. Начнём с понятия Ordered.
Ordered Probit
Типичнейшая задача эконометрики – регрессия, то есть предсказание чисто числовой величины. И обычно это линейная регрессия: прогноз величины  равен
равен , где
, где  - матрица признаков,
- матрица признаков, – вектор коэффициентов наклона,
– вектор коэффициентов наклона,  – свободный член. Реальные данные редко содержат идеально линейные зависимости, и почти всегда остатки
– свободный член. Реальные данные редко содержат идеально линейные зависимости, и почти всегда остатки  , то есть разница между фактом и прогнозом, ненулевые. В эконометрике обычно делают допущение, что у правильно подобранной модели эти остатки имеют нормальное распределение.
, то есть разница между фактом и прогнозом, ненулевые. В эконометрике обычно делают допущение, что у правильно подобранной модели эти остатки имеют нормальное распределение.
Картинка немного меняется, если мы решаем задачу классификации, то есть предсказание выбирается из конечного множества. Например, мы хотим угадать, какое образование у человека (среднее, высшее, или учёная степень), или хотим по тексту отзыва определить, какую оценку поставит клиент товару (от 1 до 5 звёздочек), или по экономическим показателям в стране мы хотим понять, как ЦБ изменит на ближайшем заседании ключевую ставку (оставит как есть, понизит на 0.25% или на 0.5%, или повысит на 0.25% или 0.5%). Классическая линейная регрессия тут не очень подходит, потому что остатки в ней будут иметь не нормальное, а непонятно какое распределение (а в случае с образованием вообще непонятно, как определить числовой . Можно решать эти задачи как стандартную классификацию, то есть предсказывать вероятности каждого исхода по отдельности. Самая простая модель для этого, множественная логистическая регрессия, считает вероятность класса
. Можно решать эти задачи как стандартную классификацию, то есть предсказывать вероятности каждого исхода по отдельности. Самая простая модель для этого, множественная логистическая регрессия, считает вероятность класса  прямо пропорциональной
прямо пропорциональной  (экспонента нужна, чтобы вероятности были неотрицательными). Это неплохо, но теперь для каждого класса нужно выучивать свои коэффициенты наклона, и если обучающих данных мало, может получиться не очень хорошо. Чтобы побороть эту проблему, и придумали порядковые модели: что-то промежуточное между регрессией и классификацией.
(экспонента нужна, чтобы вероятности были неотрицательными). Это неплохо, но теперь для каждого класса нужно выучивать свои коэффициенты наклона, и если обучающих данных мало, может получиться не очень хорошо. Чтобы побороть эту проблему, и придумали порядковые модели: что-то промежуточное между регрессией и классификацией.
Работает порядковая модель так. У нас по-прежнему есть единый скор  , но мы пытаемся превратить его в вероятности каждого из дискретных классов, так, чтобы чем больше этот скор, тем вероятнее были бы "высокие" классы. Например, можно представить, что к этому скору снова добавляется нормально распределённая случайная величина
, но мы пытаемся превратить его в вероятности каждого из дискретных классов, так, чтобы чем больше этот скор, тем вероятнее были бы "высокие" классы. Например, можно представить, что к этому скору снова добавляется нормально распределённая случайная величина  , и от того, в какой диапазон попадёт сумма
, и от того, в какой диапазон попадёт сумма  , и зависит итоговый выбранный класс.
, и зависит итоговый выбранный класс.

Получается, нам нужно выучить коэффициенты  и ещё пороги
и ещё пороги  , с помощью которых будет выбираться вероятность итогового класса
, с помощью которых будет выбираться вероятность итогового класса  . Задав модели такую структуру, мы, во-первых, сократили число обучаемых параметров (по сравнению с обычной многоклассовой классификацией), и во-вторых, придали модели полезный inductive bias: оценка "4" похожа на оценки "3" и "5", меньше похожа на "2", совсем не похожа на "1", и так далее. Собственно, такая модель и называется Ordered Probit. Ordered – потому что упорядоченная. Probit – потому что активационная функция строится на основе CDF нормального распределения.
. Задав модели такую структуру, мы, во-первых, сократили число обучаемых параметров (по сравнению с обычной многоклассовой классификацией), и во-вторых, придали модели полезный inductive bias: оценка "4" похожа на оценки "3" и "5", меньше похожа на "2", совсем не похожа на "1", и так далее. Собственно, такая модель и называется Ordered Probit. Ordered – потому что упорядоченная. Probit – потому что активационная функция строится на основе CDF нормального распределения.
Слой, который превращает скоры  в вероятности, мог бы выглядеть во фреймворке PyTorch как-то так. Вектор
в вероятности, мог бы выглядеть во фреймворке PyTorch как-то так. Вектор cutpoints – это те самые пороги. Поскольку они должны идти строго по возрастанию, я параметризовал этот вектор: bias– это первый порог, log_difs – логарифмы (положительной) разности между парами последующих порогов. Вероятность попадания случайной величины между i-тым и i+1-ым порогами равна разности CDF нормального распределения на этих порогах.
import torch
import torch.nn as nn
class OrderedProbitHead(nn.Module):
""" A layer transforming a vector of hidden states into a matrix of probabilities.
Input size: [batch, 1]
Output size: [batch, levels]
"""
def __init__(self, levels):
super(OrderedProbitHead, self).__init__()
assert levels >= 3
self.levels = levels
self.bias = nn.Parameter(torch.randn(1))
self.log_difs = nn.Parameter(torch.randn(levels - 2))
self.activation = torch.distributions.normal.Normal(0, 1).cdf
@property
def cutpoints(self):
diffs = torch.cat([torch.tensor([0]), torch.exp(self.log_difs)], 0)
return self.bias + torch.cumsum(diffs, 0)
def forward(self, x):
cdfs = self.activation(self.cutpoints - x)
lhs = torch.cat([cdfs, torch.ones_like(x)], 1)
rhs = torch.cat([torch.zeros_like(x), cdfs], 1)
return lhs - rhsИмея такой слой, можно собрать уже полноценную модельку для порядковой классификации:
class OrderedProbitModel(nn.Module):
""" A model transforming a vector of features into a matrix of probabilities
Input size: [batch, features]
Output size: [batch, levels]
"""
def __init__(self, features, levels, smoothing=1e-10):
super(OrderedProbitModel, self).__init__()
self.dense = nn.Linear(features, 1, bias=False)
self.head = OrderedProbitHead(levels)
self.smoothing = smoothing
def forward(self, x):
probas = self.head(self.dense(x))
if self.smoothing:
probas = (1 - self.smoothing) * probas + self.smoothing * torch.ones_like(probas) / self.levels
return probasЧисто математически, CDF нормального распределения строго возрастает, поэтому все выходные вероятности должны получиться строго положительными. На практике, за счёт вычислительных округлений иногда на выходе получаются нули. Чтобы это не портило обучение, я добавляю ко всем вероятностям небольшое положительное число, параметр smoothing.
Попробуем обучить нашу модель на живых данных. Это решения американского Federal Open Market Committee об изменении процентной ставки за 20 лет. Хотим предсказывать изменение rate_change , опираясь на настрой предыдущего заседания pb разрыв между парой процентных ставок spread интенсивность жилищного строительства houstи темп прироста ВВП gdp. Целевую переменную перекодируем в шкалу от 1 до 5, где 1 и 2 – уменьшение ставки на 0.5% или 0.25%, 3 – ставка не меняется, 4 и 5 – ставка растёт на 0.25% или 0.5%.
import pandas as pd
url = 'https://github.com/avidale/cnop/blob/master/application/rate_change.dta?raw=true'
data = pd.read_stata(url)
data['target'] = data.rate_change.apply(lambda x: int(x * 4 + 2))
print(data.shape)
x = torch.tensor(data[['pb','spread','houst','gdp']].values)
y = torch.tensor(data.target)
data.sample(5)Выглядят данные примерно так:

Пользуясь готовыми инструментами PyTorch, можно собрать функцию для обучения модели. Поскольку и модель, и обучающая выборка небольшие, я положу все данные в один батч, и буду использовать высокий learning rate. На 300 шагов обучения уходит около 6 секунд.
from tqdm.auto import tqdm, trange
def train(model, x, y, steps=300, lr=0.1, max_norm=1.0, wd=1e-6):
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=wd)
pbar = trange(steps)
for i in pbar:
optimizer.zero_grad()
proba = model(x)
loss = loss_fn(torch.log(proba), y)
loss.backward()
nn.utils.clip_grad_norm_(op.parameters(), max_norm)
pbar.set_description(f"Loss: {loss.item():2.10f}")
optimizer.step()
op = OrderedProbitModel(features=4, levels=5)
train(op, x, y)
# Loss: 0.7598916888
print(op.dense.weight.data)
# tensor([[0.9262, 1.5742, 1.3730, 0.2391]])
print(op.head.cutpoints.data)
# tensor([0.4655, 1.8380, 4.8357, 6.3309])Cross-nested
Модель Ordered Probit очень простая и робастная, но может быть недостаточно гибкой, чтобы полноценно описать решение комитета. Мы можем попытаться описать это решение поэтапно. Допустим, сначала комитет решает верхнеуровнево: понижать ли ставку, оставить прежней, или повысить. Если решили повысить или понизить, то выбирают, насколько. Похожим мог бы быть и, например, анализ текста отзыва: сначала мы определяем общую тональность (положительная, отрицательная или нейтральная), потом вычисляем, насколько эта тональность выражена интенсивно. Это можно описать вложенными (nested) моделями: один ordered probit принимает верхнеуровневое решение, другой доуточняет положительные решения, третий – отрицательные.
Вишенкой на тортике будут "разнородные нули". Даже если комитет настроен положительно (или, наоборот, отрицательно), он может решить в итоге не менять ставку. Это значит, что "нулевое" решение может иметь место во всех трёх режимах – положительном, отрицательном и нейтральном. Такая модель и называется cross-nested.
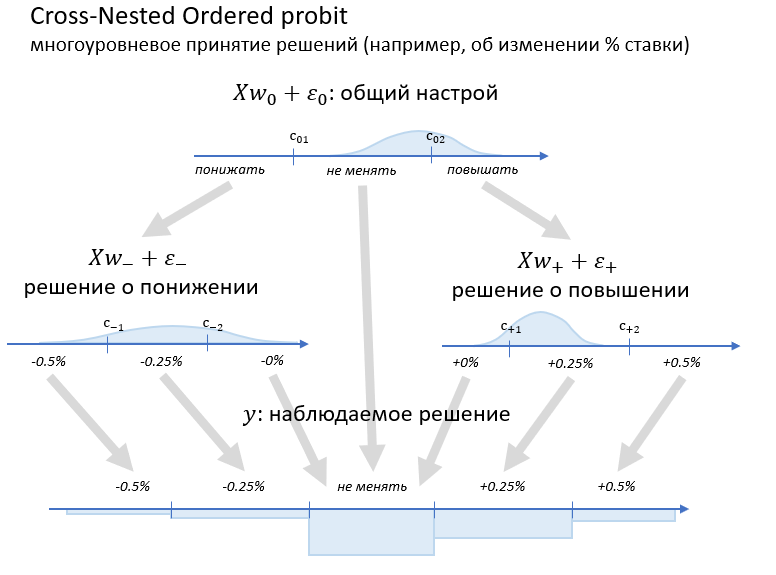
Такая двухуровневая модель ещё немножко отдаляет нас от классической регрессии и приближает к классической классификации. В линейной регрессии или Ordered Probit нужно выучивать один вектор  , в многоклассовой логистической регрессии – пять векторов, в CNOP – три вектора. Отрицательные решения похожи друг на друга, а положительные – друг на друга, но при этом положительные решения могут сильно отличаться от отрицательных.
, в многоклассовой логистической регрессии – пять векторов, в CNOP – три вектора. Отрицательные решения похожи друг на друга, а положительные – друг на друга, но при этом положительные решения могут сильно отличаться от отрицательных.
Закодить это можно примерно так. Dense слой считает три скора, которые потом поступают в три Ordered Probit головы, результаты которых комбинируются в одну матрицу вероятностей.
class CrossNestedOrderedProbitModel(nn.Module):
""" A model transforming a vector of features into a matrix of probabilities.
The model uses a neutral category (center),
negative categories (from 0 to center -1),
and positive categories (from center + 1 to levels - 1).
For each group of categories, parameters are different.
Input size: [batch, features]
Output size: [batch, levels]
"""
def __init__(self, features, levels, center, smoothing=1e-10):
super(CrossNestedOrderedProbitModel, self).__init__()
self.features = features
self.levels = levels
self.center = center
self.smoothing = smoothing
self.dense = nn.Linear(features, 3, bias=False)
self.head_zero = OrderedProbitHead(3)
self.head_neg = OrderedProbitHead(center + 1)
self.head_pos = OrderedProbitHead(levels - center)
def forward(self, x, y=None):
dense = self.dense(x)
nzp = self.head_zero(dense[:, [0]])
negative = self.head_neg(dense[:, [1]])
positive = self.head_pos(dense[:, [2]])
probas = torch.zeros([x.shape[0], self.levels])
probas[:, self.center] += nzp[:, 1]
probas[:, :(self.center+1)] += nzp[:, [0]] * negative
probas[:, self.center:] += nzp[:, [2]] * positive
if self.smoothing:
probas = (1-self.smoothing) * probas + self.smoothing * torch.ones_like(probas) / self.levels
return probas
cnop = CrossNestedOrderedProbitModel(features=4, levels=5, center=2)
train(cnop, x, y, lr=0.1, steps=10000)
# Loss: 0.6336604357Весь этот код для PyTorch я написал вчера за полчаса. Код для Stata я не мог привести в приличное состояние несколько лет. И стыдно, и смешно.
P-values и вторая производная
В головах многих (и эконометристов, и MLщиков) машинное обучение и эконометрика находятся где-то бесконечно далеко друг от друга. В ML модели (в основном нейросети) сложнючие и неинтерпретируемые, а в эконометрике супер прозрачные, и их можно прощупывать статистическими тестами.
На самом деле, конечно, модели одни и те же. CrossEntropyLoss, которую оптимизируют примерно все нейросети-классификаторы – это известная из статистики функция правдоподобия, только со знаком минус. А значит, веса нейросети – это оценки максимального правдоподобия, и обладают кучей полезных свойств. В частности, в больших выборках их распределение сходится к совместному нормальному с ковариационной матрицей, равной минус обратной матрице вторых производных функции потерь. На практике это означает, что мы можем легко посчитать стандартные отклонения для весов нейросети, а с их помощью – доверительные интервалы и статистическую значимость. И если в старомодных пакетах типа Stata вторые производные надо считать руками (или полагаться на численные методы), то фреймворки типа PyTorch умеют дифференцировать символьно. Даже два раза.
Итак, код для вычисления стандартных отклонений параметров нейронки:
Вычисляем первые производные (градиент) функции потерь по параметрам;
Проходимся циклом по всем элементам градиента, дифференцируем их ещё раз, и складываем в матрицу;
Инвертируем матрицу;
Ещё раз проходимся по всем параметрам, и достаём с диагонали матрицы соответствующие значения.
Код
def get_standard_errors(model, loss):
all_params = torch.cat([p.view(-1) for p in model.parameters()])
hessian = torch.empty(all_params.shape * 2)
first_order_grads = torch.autograd.grad(loss, model.parameters(), retain_graph=True, create_graph=True)
c = 0
for i, (name, param) in enumerate(model.named_parameters()):
v = param.view(-1)
g = first_order_grads[i].view(-1)
var = torch.empty_like(v)
for j, gg in enumerate(g):
hh = torch.autograd.grad(gg, model.parameters(), retain_graph=True)
hessian[c] = torch.cat([p.view(-1) for p in hh])
c += 1
standard_deviations = torch.diag(torch.inverse(hessian)) ** 0.5
result = []
start = 0
for i, (name, param) in enumerate(model.named_parameters()):
v = param.view(-1)
n = v.shape[0]
ss = standard_deviations[start:start+n].view(param.shape)
result.append(ss)
start += n
return result
Теперь мы можем нарисовать красивую табличку для параметров модели, прямо как в вашем любимом статистическом пакете:
from scipy.stats import norm
def report(model, loss):
result = []
names = []
se = get_standard_errors(model, loss)
for i, (name, param) in enumerate(model.named_parameters()):
shape = param.squeeze().shape
v = param.view(-1).detach().numpy()
s = se[i].view(-1).detach().numpy()
for j, (vv, ss) in enumerate(zip(v, s)):
t = np.abs(vv / ss)
result.append({
'value': vv,
'std': ss,
't': t,
'p-value': norm.cdf(-t) * 2,
'[2.5%': vv-ss*1.96,
'97.5%]': vv+ss*1.96,
})
if len(v) > 1:
names.append(f'{name}{list(np.unravel_index(j, shape))}')
else:
names.append(name)
return pd.DataFrame(result, index=names)
likelihood = nn.CrossEntropyLoss(reduction='sum')
report(op, likelihood(torch.log(op(x)), y)).round(4)
Как видим, в модели Ordered Probit коэффициенты при всех входных признаках значимые, и каждый из них увеличивает вероятность роста ключевой ставки.
Подобным же образом можно было посчитать и предельные эффекты, нужно только дифференцировать не по параметрам, а по обучающим данным.
Как видите, современные нейронки отнюдь не являются несовместимыми со статистическими методами. Просто их нужно правильно готовить.
О жизни
За этот проект я познал много различий и много сходств:
Написав тысячи строк говнокода, я понял, что отличает от него нормальный код (в первую очередь – удобством модификации и внятной структурой).
Поработав с чудовищным фреймворком Stata+Mata, я всей душой полюбил удобные, современные и хорошо поддерживаемые питонячьи фреймворки.
Долго занимаясь и эконометрикой, и машинным обучением, я укрепился в мысли, что это суть одно и то же.
Я прочувствовал, что писать код, который будет частью крупного популярного фреймворка – весьма вдохновляющее занятие.
Я также прочувствовал, что писать код, которым примерно никто примерно никогда не будет пользоваться – довольно уныло.
Даже из не очень крутого проекта может получиться неплохой пост на Хабре.
Вот мой репозиторий, вот блокнот с кодом на питоне, вот статья.
Если захотите поговорить об эконометрике, машинке, статистике и смысли жизни, пишите в комменты или мне в личку.
Спасибо за внимание!
