
И снова всем привет!
На этот раз рассмотрим извлекающие методы, которым нужны эталонные рефераты для обучения. При этом эти методы всё ещё могут лишь выбирать предложения из оригинального текста. К методам этой группы и относятся описываемые ниже SummaRuNNer и BertSumExt.
Статьи цикла:
1) Постановка задачи автоматического реферирования и методы без учителя
2) Извлекающие методы автоматического реферирования ⬅️
3) Секреты генерирующего реферирования текстов
Я не хочу объяснять вещи, которые не связаны непосредственно с реферированием. Поэтому под спойлером ссылки на другие источники, в которых необходимые для понимания вещи объясняются подробно.
Первое, что потребуется — понимание того, как обучать нейронные сети. То есть обратное распространение ошибки и различные модификации стохастического градиентного спуска.
📚🇬🇧 Deep Learning, глава 6
📺🇬🇧 Stanford CS231n, лекция 4
📄🇷🇺 курс Воронцова, «Нейронные сети: градиентные методы оптимизации»
Дальше — рекуррентные сети.
📄🇬🇧 «Understanding LSTM Networks»
📄🇷🇺 «LSTM – сети долгой краткосрочной памяти»
📺🇬🇧 Stanford CS224N, лекция 6
И наконец, механизм внимания и внимания-на-себя, Трансформеры и BERT.
📄🇬🇧 курс Лены Войты, глава «Sequence to Sequence (seq2seq) and Attention»
📄🇬🇧 курс Лены Войты, глава «(Introduction to) Transfer Learning»
📄🇬🇧 «The Illustrated BERT, ELMo, and co.»
📄🇷🇺 «BERT, ELMO и Ко в картинках»
📺🇬🇧 Stanford CS224N, лекция 14
💡🇬🇧 «Attention Is All You Need»
💡🇬🇧 «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding»
Извлекающие методы реферирования
SummaRuNNer
SummaRuNNer — один из первых нейросетевых извлекающих методов автоматического реферирования с учителем.
Основная его идея — метод "оракула", сведение задачи автоматического реферирования к бинарной классификации предложений. Он заключается в том, чтобы набрать предложения из исходного документа так, чтобы квазиреферат из них был максимально похож на эталонный реферат по какой-либо метрике (например, по ROUGE). При этом мы делаем этот набор жадно: сначала выбираем такое первое предложение, которое максимально похоже на эталонный реферат по нашей метрике, потом подбираем второе предложение так, чтобы получившиеся два предложения оптимизировали метрику, и так далее. Останавливаемся тогда, когда добавление нового предложения не улучшает нашу целевую метрику. Вот пример кода для метода "оракула".
Архитектура модели представляет из себя двухуровневую двунаправленную рекуррентную нейронную сеть, первый уровень которой проходится по словам, а второй уровень — по предложениям. Схематично она представлена на рисунке ниже.
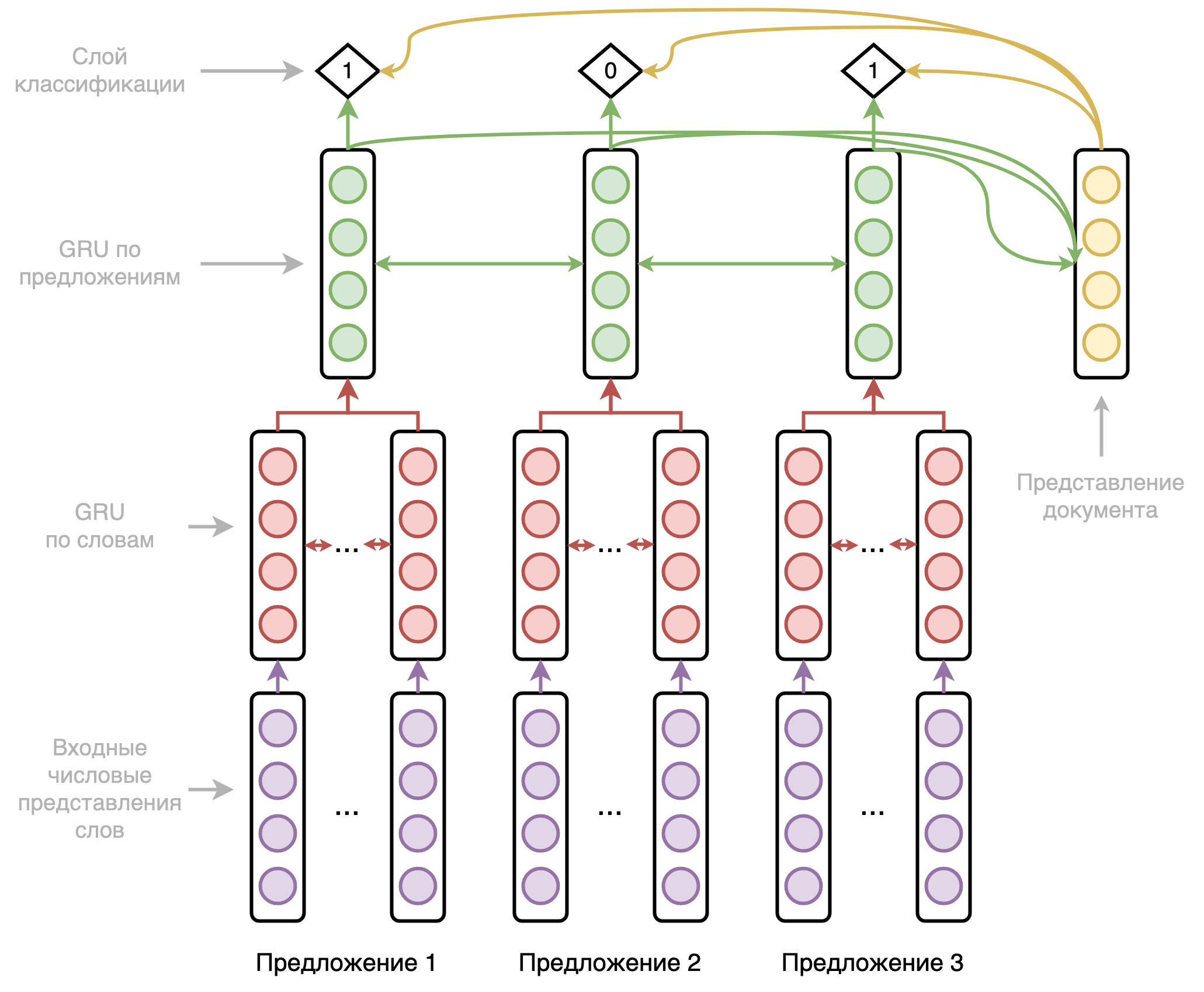
Подробнее на архитектуре я останавливаться не буду, рекуррентные сети уже не особо актуальны, как и большинство применяемых в этой модели хаков. Отмечу только, что модель по ходу своей работы собирает эмбеддинг документа и использует его в предсказаниях вместе с выходами сети и позиционными эмбеддингами. А также используется упомянутый в первой статье цикла штраф за однообразие.
В итоге модель получает для каждого предложения оригинального текста оценку вероятности быть включённым в итоговый квазиреферат. Всё, что нам остаётся сделать — отсортировать предложения по этой оценке и взять первые N в качестве квазиреферата.
SummaRuNNeR отлично показал себя на CNN/DailyMail, который долгое время был основным бенчмарком для реферирования, и до сих пор довольно важен. Модель работала лучше всех других моделей на этом наборе данных на момент написания оригинальной статьи (2016 год). Важное её преимущество — высокая по сравнению с абстрактивными методами скорость работы.
Мне довелось написать эту модель, код доступен тут. Можно запустить на своих текстах, в README есть пример применения. Работает она очень резво и выдаёт вполне приличные метрики.
BertSumExt
BertSumExt — метод извлекающего реферирования на основе BERT и сведения к задаче бинарной классификации тем же методом "оракула".
Модификации по сравнению с оригинальным BERT:
- [CLS] токены в начале каждого предложения. На выходе BERT мы ожидаем на позициях этих токенов эмбеддинги предложений, которые им соответствуют. По моему опыту можно использовать и [SEP] токены для тех же целей, это не принципиально. [CLS] теоретически может работать чуть лучше из-за предобучения на NSP (задача предсказания следующего предложения), но на практике я такого не наблюдал.
- Чередующиеся сегментные эмбеддинги. Напомню, что у стандартного BERT три типа эмбеддингов: эмбеддинги токенов, позиционные эмбеддинги, сегментные эмбеддинги. Сегментные эмбеддинги в оригинальной модели выделяли 2 фрагмента текста для NSP. А вот в этой модели мы для каждого предложения используем один из двух сегментных эмбеддингов с чередованием. То есть токены первого предложения получает первый эмбеддинг, токены второго — второй, токены третьего снова первый, и так далее.
- MMR-like фильтрация по триграммам, то есть по тройкам подряд идущих слов. При наборе предложений в квазиреферат мы пропускаем такие предложения, в которых встретилась хотя бы одна триграмма, которая уже была в ранее набранных предложениях.
- Дополнительный Трансформер-кодировщик над представлениями предложений со своими позиционными эмбеддингами.
Схематично это всё представлено на рисунке ниже.

А теперь немного субъективного: код у коллег так себе. Основная его часть взята из OpenNMT, но переделана в худшую сторону. Абстракции протекают, баги не исправляются, пулл-реквесты не принимаются. 120+ issues чего только стоят. У меня и моего студента, Лёши Бухтиярова, получалось запустить это всё, но никому такой опыт не советую.
И это не единственный неприятный момент. По ablation study модификации с сегментными эмбеддингами в оригинальной статье выходит, что она вообще-то не нужна, прирост там крайне незначительный. В оригинальной статье нет ablation study на последнюю модификацию, но оно есть в предыдущей статье автора. И знаете что? Дополнительный Трансформер тоже не нужен.
То есть выходит, что единственное, что нужно для работы модели — взять представления предложений из [CLS] или [SEP] и подать их в линейный слой с сигмоидой, то есть задача сводится к тегировнию токенов. И это правда работает, вот моя модель на основе RuBERT, обученная ровно таким способом (но чередующиеся сегментные эмбеддинги я всё-таки оставил).
Заключение
Бывают отдельные случаи, когда системам автоматического реферирования не позволено генерировать новые тексты. В конце концов, когда автоматика не генерирует отсебятину, доверие к ней выше. И в таких случаях извлекающие методы с учителем — прекрасный выбор. Классификаторы по построению проще и быстрее генераторов, поэтому эти модели могут пригодится ещё и в CPU-bound среде, типа мобильных устройств.
Как было отмечено, этим моделям нужна обучающая выборка. В отличие от абстрактивных методов, она не обязана быть большой — тысяч или даже сотен пар должно хватить. Есть ли такие выборки для русского? К счастью, да: Gazeta, MLSUM, XLSum, WikiLingua.
Осталось ещё две самых больших и самых главных темы: абстрактивные модели и метрики качества. Увидимся в следующих статьях!
