 What will we do with a drunken sailor,
What will we do with a drunken sailor,What will we do with a drunken sailor,
What will we do with a drunken sailor,
Early in the morning?
Drunken Sailor
В прошлый раз мы остановились на том, что модели на основе свёрточных нейросетей, вполне способны подсказывать интересные и неочевидные ходы и, таким образом, могут использоваться как основа для построения бота для игры Го. Напомню, что источником модели послужила вот эта замечательная книга. Для того чтобы двигаться дальше: дообучать модель, просто с ней экспериментировать или вообще полностью переделать и обучить с нуля, требовались вычислительные ресурсы. И они появились…
За неоднократное проведение хакатонов, митапов и прочих мероприятий, Руководство Компании презентовало меня ноутбуком. Наличием видеокарты, позволяющей задействовать GPU в экспериментах с Machine Learning-ом, было грех не воспользоваться.
Разумеется, видеокарты, самой по себе, недостаточно
Один день пришлось потратить на установку и настройку необходимого софта. Помимо Node.js, речь идёт о CUDA и cuDNN. Дистрибутивы большие, релизы выходят часто, а подобрать их совместимые версии, с первого раза, удаётся не всегда. Мне пришлось откатиться к связке CUDA 11.5.0 + cuDNN 8.3.2, чтобы всё заработало. Кстати, чтобы скачать cuDNN необходимо зарегистрироваться. Вот здесь можно найти подробную, хотя и несколько устаревшую, инструкцию.

Первоначально, модель была разработана авторами упомянутой выше книги, на языке Python, с использованием фреймворка TensorFlow, под управлением API Keras. Модель была обучена на основе 100 игр, взятых из архива KGS, а результаты обучения также были выгружены в GitHub. Для преобразования модели в формат, поддерживаемый Tensorflow.js, потребовался конвертер.
Прежде всего, хотелось дообучить модель на большем объёме входных данных. Архивы KGS ведутся с 2001-го года и в них представлены партии, в которых один из игроков имел 7-ой дан и выше или оба игрока имели 6-ой дан. За каждый год были сыграны тысячи партий и какие-то 100 игр, на фоне этих объёмов, представляют собой совершенно ничтожную выборку.
Попутно, появились ещё две идеи
Во первых, формат SGF, с использованием которого игры закодированы, содержит сопроводительную информацию. В частности, тег RE кодирует результат партии. Например, 'RE[W+Resign]' означает, победу белых, в связи со сдачей противника. Это позволяет отфильтровать из записи партии только ходы победителя, чтобы использовать их для последующего обучения модели.
Вторая идея связана с симметрией доски. Если позиция не симметрична, мы можем получить до 8 различных равнозначных позиций, используя повороты и отражения. Выполнение этих преобразований в боте, на этапе предсказания хода (predict) — не очень хорошее решение. Вычислительные ресурсы бота слишком ценны. При использовании поиска в глубину (например, с использованием MCTS) операция предсказания хода может быть выполнена тысячи раз. Кроме того, бот может выполняться в окружении, в котором использование быстродействующих бакендов Tensorflow.js невозможно, например в браузере. Гораздо разумнее использовать повороты и отражения, чтобы сгенерировать больший объем данных перед выполнением обучения (fit).
Кстати, разбор SGF-нотации - не такая тривиальная задача, как может показаться.
Дело даже не в том, что требуется распарсить сам SGF-файл. Нотация формируется с учётом правил игры Го. Записывается только постановка камней на доску. Если выполнение какого-то хода привело к «смерти» одной или нескольких групп, удаление с доски входящих в них камней нотацией не фиксируется. Для нас это означает необходимость «проигрывания» позиции, в процессе чтения SGF-нотации.
Примерно вот так это выглядит
function RedoMove(move, ko) {
let captured = []; let f = true;
_.each([1, -1, SIZE, -SIZE], function(dir) {
let p = navigate(move, dir);
if (p < 0) return;
let ix = stat.map[p];
if (_.isUndefined(ix)) return;
if (!isEnemy(stat.res[ix].type)) {
f = false;
return;
}
if (stat.res[ix].dame.length > 1) return;
_.each(stat.res[ix].group, function (q) {
board[q] = 0;
captured.push(q);
});
});
if (captured.length == 1 && f) {
ko.push(captured[0]);
}
board[move] = 1;
return board;
}
Вторая идея связана с симметрией доски. Если позиция не симметрична, мы можем получить до 8 различных равнозначных позиций, используя повороты и отражения. Выполнение этих преобразований в боте, на этапе предсказания хода (predict) — не очень хорошее решение. Вычислительные ресурсы бота слишком ценны. При использовании поиска в глубину (например, с использованием MCTS) операция предсказания хода может быть выполнена тысячи раз. Кроме того, бот может выполняться в окружении, в котором использование быстродействующих бакендов Tensorflow.js невозможно, например в браузере. Гораздо разумнее использовать повороты и отражения, чтобы сгенерировать больший объем данных перед выполнением обучения (fit).
В общем, получился вот такой загрузчик. Но, перед тем как приступать к обучению модели, следовало определиться с производительностью. Дело в том, что для выполнения вычислений Tensorflow.js может использовать различные бакенды. Самый простой в использовании (и самый медленный) — 'cpu', подразумевает выполнение всех вычислений в JavaScript-е. Использование @tensorflow/tfjs-node позволяет выполнять вычисления непосредственно с использованием CPU, а @tensorflow/tfjs-node-gpu (при наличии необходимых драйверов) предоставляет возможность задействовать видеокарту. Помимо перечисленного, при помощи @tensorflow/tfjs-backend-wasm можно использовать бакенд 'wasm', с точки зрения производительности представляющий собой промежуточное решение между 'cpu' и 'tensorflow':
- cpu — 6199,47 ms
- wasm — 31,65 ms
- tensorflow (cpu) — 19,57 ms
- tensorflow (gpu) — 2,51 ms
Тут стоит сказать пару слов о том, что именно измерялось. Довольно быстро выяснилось, что при увеличении размера блока данных, затраты времени на выполнение вычислений для всех бакендов растут линейно. Это касается как предсказания хода, так и обучения (в последнем случае, увеличение количества эпох также ведёт к линейному увеличению затрат времени). По этой причине, данные приведены для условного выполнения fit по отношению к одной строке выборки (то есть паре, состоящей из текущей позиции и рекомендуемого хода). В любом случае, здесь больше важны не абсолютные значения (которые могут меняться, в зависимости от характеристик оборудования), а скорее их соотношение.
Существует ещё один способ для увеличения производительности
Используемая модель состоит из нескольких свёрточных слоёв, за которыми следуют плотные слои. Задача свёрточных слоёв — выявление базовых паттернов: хороших и плохих форм, в терминологии игры Го. Плотные слои формируют решение — ответный ход, наилучший в этой позиции, с точки зрения модели. Поскольку мы работаем с уже обученной моделью, то можем рассчитывать что часть слоёв достаточно хорошо выполняют свою работу и не нуждаются в дополнительном обучении. Мы можем «заморозить» эти слои, установив свойство 'trainable' в false. Разумеется, это ускорит процесс обучения, поскольку для «замороженных» слоёв не требуется выполнять изменение коэффициентов при выполнении обратного распространения ошибки:
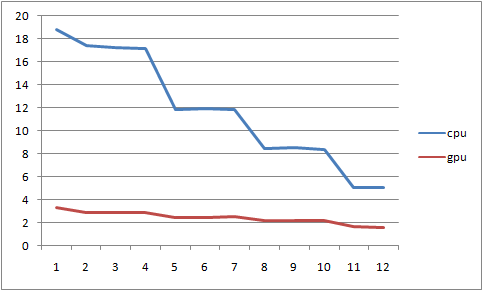
Графики показывают, что при выполнении вычислений с использованием CPU, «замораживание» свёрточных слоёв позволяет значительно увеличить скорость обучения, приблизившись по производительности к GPU. В то же время, при использовании быстрого GPU-бакенда, «замораживание» слоёв вряд ли стоит рассматривать как средство возможной оптимизации, поскольку прирост производительности, в этом случае, ничтожен. Впрочем, есть ещё одна причина для исключения части слоёв из процесса обучения:
Как выяснилось, 'wasm' бакенд, в настоящее время, не поддерживает обратное распространение в свёрточных слоях. Это достаточно распространённая ситуация и Tensorflow.js позволяет доопределить недостающие функции, но в нашем случае возможных путей решения проблемы всего два: можно «заморозить» часть проблемных слоёв модели либо использовать другой бакенд.

Графики показывают, что при выполнении вычислений с использованием CPU, «замораживание» свёрточных слоёв позволяет значительно увеличить скорость обучения, приблизившись по производительности к GPU. В то же время, при использовании быстрого GPU-бакенда, «замораживание» слоёв вряд ли стоит рассматривать как средство возможной оптимизации, поскольку прирост производительности, в этом случае, ничтожен. Впрочем, есть ещё одна причина для исключения части слоёв из процесса обучения:
RuntimeError: abort(Error: Kernel 'Conv2DBackpropFilter' not registered for backend 'wasm'). Build with -s ASSERTIONS=1 for more info.
at process.abort (C:\Users\valen\SGFLoader\node_modules\@tensorflow\tfjs-backend-wasm\dist\tf-backend-wasm.node.js:5262:9549)
at process.emit (node:events:390:28)
at emit (node:internal/process/promises:136:22)
at processPromiseRejections (node:internal/process/promises:242:25)
at processTicksAndRejections (node:internal/process/task_queues:97:32)
Как выяснилось, 'wasm' бакенд, в настоящее время, не поддерживает обратное распространение в свёрточных слоях. Это достаточно распространённая ситуация и Tensorflow.js позволяет доопределить недостающие функции, но в нашем случае возможных путей решения проблемы всего два: можно «заморозить» часть проблемных слоёв модели либо использовать другой бакенд.
Загрузка данных за 3 года (2001-2003) продолжалась около 9 часов. Обучение проводилось блоками по 128 строк, в течение 7 эпох, с отделением 0.1 входных данных для выполнения валидации. В качестве функции потерь использовалась 'categoricalCrossentropy'. Значение метрики 'accuracy' по завершении 7-ой эпохи обучения, изменялось следующим образом:

График минимизации функции потерь:

Возможно, в дальнейшем, придётся подумать об изменении архитектуры модели и, скорее всего, представления входных данных, но в настоящий момент, более интересны практические результаты.

Картинка кликабельна. Бот под управлением дообученной модели играл чёрными. Обе модели, время от времени, рекомендовали крайне странные ходы, но чёрные, в этой игре, безусловно победили. Разумеется, не стоит ждать сильной игры от очень простого бота, руководствующегося однократным вызовом predict, для выбора лучшего хода. Использование MCTS должно значительно улучшить качество игры. Это потребует большего количества обращений к модели, что не должно стать проблемой, поскольку вопрос с производительностью, на текущий момент, можно считать решённым.
