
Доклад Алексея Лесовского про то, что нового есть в PostgreSQL в плане мониторинга.
Охватывать Алексей будет 13 и 14 версии. Далее от его лица.

Пару слов о себе и о том, кто я такой.
- Я начинал карьеру с системного администратора. Долгое время работал с Linux. Через какое-то время столкнулся с Postgres, стал администрировать его.
- И потом уже в компании DataEgret я полностью сосредоточился над администрированием Postgres. В компании я уже проработал примерно 7,5 лет. И за все это время сталкивался в основном с Postgres, а также со всякими штуками, которые вокруг Postgres. Сама компания занимается исключительно Postgres, консалтингом и обслуживанием.
- Я люблю заниматься мониторингами. Люблю статистику, люблю различные визуализации. И люблю сравнивать различные системы мониторинга, их функциональность и то, чем они отличаются друг от друга.
- В свободное от работы время люблю программировать. И являюсь автором таких утилит, как pgcenter, Noisia, pgstats.dev и коллектор метрик для Prometheus и pgscv.

Как я сказал на предыдущем слайде, я люблю мониторинги.
Первая система мониторинга, с которой я столкнулся, это была Cacti. Это было, наверное, более 10 лет назад. Это довольно простая рисовалка графиков, построенная на базе RRDtool. Я с ней поработал какое-то время.
Потом столкнулся с Zabbix. Zabbix поразил меня своими возможностями по кастомизации. И я долгое время работал именно с Zabbix. Писал для него различные модули, различные штуки, чтобы мониторить различные сервисы, а именно redis'ы, кэши и т. д.
Какое-то короткое время я поработал с Nagios. После Zabbix он мне показался немного устаревшим.
И в последние 7-8 лет я работаю с Prometheus. Работаю с ним с 2014-го года. Он мне очень нравится. И у меня очень хорошая в нем экспертиза.

Но если говорить про Postgres, то в плане мониторинга Postgres есть тоже много всяких инструментов. Но если на них посмотреть детальней, то это, как правило, какой-то агент, который ходит в базу, забирает данные. Это какой-то простенький UI, который рисует какие-то графики поверх всего этого.
Раньше UI были у каждого мониторинга свои, но в последнее время тенденция идет к тому, что люди просто берут Grafana и в Grafana рисуют нужные для них дашборды. Очень удобно.

Если мы посмотрим на все эти мониторинги, то окажется, что под капотом всех этих мониторингов находится postgres'овый Statistics Collector, т. е. коллектор статистики. Это встроенная в Postgres подсистема, которая предоставляет интерфейсы для отдачи всяких метрик наружу через SQL-интерфейс.

Если открыть эту ссылку, то можно будет увидеть длинную-длинную портянку документации. В ней описано, что такое Stats Collector, для чего он нужен, какие данные он может отдавать, какие подсистемы мониторить. Очень много информации о нем.
Там всего два примитива. Это функции. И на основе этих функций сделаны представления, так называемые, вьюхи. Делая SQL-запросы к этим вьюхам, мы можем получать данные. К этим SQL-вьюхам обращаются все агенты мониторинга и получают данные.
Тут вопрос в том, что в каждой новой версии добавляются новые представления, новые вьюхи. И с каждой новой версией мониторинг становится все обширнее и обширнее.

Если представить Postgres в виде такой упрощенной диаграммы, разделить каждую подсистему Postgres в отдельный блок, то получится примерно вот такая диаграмма.

И если мы возьмем все эти вьюхи и функции, которые есть в Stats Collector и наложим их поверх диаграммы, получится примерно такая картина. Блоков много и функций, вьюх еще больше. В этом можно довольно легко запутаться и растеряться.

С 13-ой и 14-ой версией добавилось еще больше вьюх и функций. И во всем этом ориентироваться становиться довольно сложно.
В этом докладе я расскажу, что нового появилось в 13-ой и 14-ой версии, почему это появилось, как было плохо жить без этого в предыдущих версиях и как этими штуками пользоваться вам, если вы работаете с базой данных.

Свой доклад я условно разбил на 7 частей. В каждой части я буду описывать какую-то из подсистем Postgres или какую-то из проблем. И первая часть связана со временем.
Поднимите руку, кто знаком с вьюхой pg_stat_activity. Есть такие? Есть несколько рук.

Pg_stat_activity на мой взгляд очень клевая вьюха. Она позволяет смотреть текущую активность. Если в базе возникает какая-то проблема, это первое место, куда нужно зайти и посмотреть, что происходит.
Но, как правило, ее бывает недостаточно. Если мы видим какую-то долгую активность, например, долгий запрос, долгий выполняющийся вакуум, у нас нет представления о том, когда он закончится. Мы можем представить, что, наверное, он закончится через 2 минуты или 20 минут. Посмотрели через 20 минут, он все еще выполняется. Подумали, что, наверное, он закончится через 30 минут. И это тоже будет неправильно. Это будет приблизительной и вероятностной оценкой.
Начиная с версии 9.6 ситуация стала лучше. Начали добавляться progress views. Это штуки, которые показывают прогресс выполнения долгих операций.
В 9.6 добавили вьюху для отслеживания вакуумов.
В 12 версии добавились вьюхи для отслеживания операции создания index, reindex и операции типа кластеризации таблиц по индексу и vacuum full.

В новой 13-ой версии добавилась еще одна такая же вьюха. По названию можно понять, что она для трекинга операций Analyze.
Что такое Analyze? Analyze — это сбор статистики по тому, как меняются данные в таблице: качественно или количественно для планировщика, чтобы планировщик мог делать нормальные планы для запросов.

Что у нас появилось? У нас появилась эта вьюха. И в ней мы видим этап операции, т. е. мы уже представляем, в каком месте выполняется Analyze. Уже примерно представляем, что происходит.

У нас есть информация о размере sample, который нужен этой операции, и сколько обработано байт страниц в этом sample. Т. е. мы уже можем делать какие-то процентные вычисления и можем примерно предположить, когда у нас закончится операция.

И есть поддержка партиционированных таблиц. Если у какой-то таблицы есть много дочерних таблиц, мы можем по этой вьюхе смотреть, когда закончится выполнение обработки партиционированной таблицы.

И самое главное, есть поле pid — идентификатор процесса. С помощью этого поля мы можем делать JOINS с pg_stat_activity и pg_locks. И можем брать оттуда расширенную информацию. Это может быть время транзакции, состояние сессии, адрес клиента, порт. Это могут быть какие-то ожидания, на чем, допустим, завис этот процесс. Это очень полезное поле, которое позволяет получать дополнительную информацию.
Плюс можно присоединить pg_locks и получить блокировки. На мой взгляд, это очень круто.

Но это не все. Добавилась еще одна progress view. В 13-ой версии она связана с трекингом резервных копий. Есть такая утилита pg_basebackup. У нее есть специальный ключик, который показывает прогресс выполнения взятия резервной копии. Это было довольно удобно, потому что резервная копия выполняется довольно долго, если база большая. И когда ты утилиту запустил, видишь, что у тебя выполняется прогресс и когда он примерно закончится. Но с точки зрения самого Postgres, это посмотреть было нельзя.
И в 13-ой версии появилась эта вьюха. Можно уже со стороны сервера посмотреть выполнение резервного копирования и примерно спрогнозировать, когда оно закончится.

Также у нас есть этап операции. Мы можем посмотреть, на каком этапе делается резервная копия.

Есть полный размер, сколько нужно отправить данных и уже сколько отправлено. Т. е. мы можем посчитать проценты, можем примерно прикинуть, сколько осталось.

И также можем соединиться с pg_stat_activity и pg_locks и взять информацию о том, откуда запущен бэкап, на каких блокировках он, возможно, висит. Это расширенная информация из этих вьюх.

Последняя progress view, которая добавилась в 14-ой версии, связана с трекингом операций copy.
Что такое copy? Это обычно логические дампы, которые берутся через утилиту pg_dump, либо восстанавливаются через утилиту pg_restore. Это начальное копирование таблиц при использовании логической репликации, когда у нас есть публикация, подписка и мы какие-то таблицы стримим на удаленный сервер по логической репликации. Начальная загрузка таблиц осуществляется через copy.
Либо это прямые вызовы командой COPY пользователем, т. е. пользователь захотел загрузить какую-то таблицу в файл, либо, наоборот, в таблицу загрузить данные из файла. И как раз эта вьюха позволяет отслеживать прогресс выполнения и примерно понимать, когда у нас закончится эта операция, не висит ли она на чем-нибудь, не заблокирована ли она и нет ли там каких-либо проблем.

Классический набор полей — это детали копи-команды. По ней мы определяем, что это за команда: запущена ли она для выгрузки данных или на загрузку данных.
Можем видеть, сколько у нас байт обработано, сколько строк. Мы снова можем строить проценты и в процентах видеть прогресс выполнения.

И pid для соединения с pg_stat_activity и pg_locks. Можно смотреть блокировки, ожидания. Это очень полезно. Про это обязательно нужно помнить.

Что еще? В pg_stat_activity можно видеть не только долгую активность по вакуумам, по копи-операциям, даже простые DML, DDL-запросы тоже могут выполняться долго. Хотелось бы, чтобы в будущих версиях появились тоже progress views для трекинга прогресса выполнения checkpoints, DDL-операций, DML-запросов. Если это появится, то это будет очень круто и информативно.

Следующий раздел также связан со временем.

И снова pg_stat_activity. Когда мы смотрим в pg_stat_activity, мы можем получить информацию о том, когда запустилась сессия, когда запустилась транзакция, запрос или когда поменялся state, состояние процесса.
Но pg_stat_activity неудобен тем, что это снимок. Мы работаем со снимком, и данные между двумя снимками нам остаются неизвестными.

Но, тем не менее, при работе с одним снимком мы видим state процесса. Что нам это дает?

Условно говоря, у postgres'ового соединения есть несколько состояний. Условно говоря, есть хорошие, есть плохие. И можно представить, что сессия ничего не делает. Она находится в состоянии idle и ждет запроса от приложения. Когда приложение присылает запрос, postgres'овый процесс начинает его обрабатывать, читать какие-то данные. И результат выполнения этого запроса потом отдает клиенту. Это активное состояние.
Плюс есть 2 отрицательных, условно, плохих состояний. Это состояние открытой транзакции, когда приложение с помощью команды BEGIN открывает транзакцию, что-то в ней делает, может быть, изменяет какие-то строки или читает какие-то данные. Потом уходит обратно в приложение и оставляет транзакцию открытой. В это время в Postgres эта транзакция может удерживать какие-то блокировки на другие строки. Вакуум не может вычистить эти строки. Т. е. очень частое нахождение в таких состояниях негативно влияет на производительность самого Postgres, поэтому их следует избегать. И оно считается негативным.
Есть еще экзотический пятый state, но он практически не встречается. И в документации помечен как нерекомендуемый для использования. Это fastpath-функции.

С точки зрения мониторинга, очень часто возникает вопрос: "Сколько времени наши сессии проводят в этих состояниях?". Т. е. сколько времени сессии проводят в хороших состояниях и заняты полезной активной работой и сколько времени они находятся в негативных состояниях и тратят время впустую?

Если мы возьмем практически любой postgres'овый мониторинг, есть такой классический график соединений. Мы берем из pg_stat_activity снимок, берем разбивку по состояниям и рисуем график. Здесь у нас есть какие-то процессы и они находятся в каких-то состояниях.

Если мы возьмем то, что появилось в новой 14-ой версии, то у нас появились новые расширенные метрики, которые позволяют считать нам время, проведенное в сессиях.

В pg_stat_database появились две группы полей. Первая группа показывает время, проведенное в сессиях.

Вторая группа показывает статусы завершения сессий, т. е. нормально ли сессия завершилась, либо была какая-то ошибка и была завершена принудительно, может быть, какая-то аварийная ситуация возникла. Т. е. мы по этим счетчикам можем отслеживать поведение и нормальность поведения приложения при работе с базой. Это очень круто. Мы можем прийти к разработчикам уже с конкретными цифрами и сказать: "Вот здесь приложение работает не оптимально, нужно в коде что-то привести к оптимизации, чтобы время баз данных тратилось более рационально".

Сравним 2 графика.
Первый график, верхний, это классический график, на основе состояний процессов. Он статичный, не отображает никакой динамики.
Нижний график построен на основе новых метрик: сколько времени проведено в сессиях. И здесь видно, что приложение относительно много времени занималось выполнением запросов. Т. е. на одну секунду реального времени база данных две секунды выполняла какие-то запросы. И в какое-то время приложение перестало выполнять полезную нагрузку и перешло в состояние idle. У нас активное время перестало считаться, и процесс проводит время в состоянии idle, ожидая, когда приложение отправит запросы. Т. е. здесь мы уже можем более точно оценивать то, куда тратиться время работы базы данных.

Сравним с idle transaction.
Нижние графики — это классические графики. У нас есть соединение с разбивкой по статусам. Это график справа. И справа — это длительность транзакций. Видно, что есть зеленые пятнышки. Есть какие-то транзакции, которые занимают до двух-четырех секунд. Но сколько времени тратится не понятно.
С помощью новых метрик мы можем конкретно увидеть, сколько времени уходит на эти idle transactions. Конкретно в этом случае на одну секунду реального человеческого времени уходит четыре секунды времени базы данных, т. е. четыре секунды приложение где-то что-то делает, чем-то занимается непонятным, база данных при этом находится в состоянии открытой транзакции и ждет, когда приложение ее закроет. Это уже более точная оценка, которая позволяет нам эффективно отслеживать работу приложений.

Давайте посмотрим на другую группу. Это счетчики завершения сессий.
Сверху — это классический график, который показывает состояние соединений. В нижнем графике я сэмулировал заведомо багнутое приложение, когда на каждый запрос создается отдельное соединение. Это неправильное поведение приложений в целом, которое следует избегать.
Дело в том, что создание соединений в Postgres не бесплатное и довольно ресурсоемкое. В данном случае приложение работает медленней, чем могло бы. Время, которое тратится на установку соединения и его завершения, могло бы быть потрачено приложением на то, чтобы исполнять запросы.
Такую проблему в реальной жизни довольно тяжело искать. Postgres не предоставлял раньше никаких инструментов для этого, и приходилось смотреть с точки зрения операционной системы, что происходит. Там нужно было устанавливать количество форков. И это нетривиально было, особенно там, где доступа к операционной системе нет.
Сейчас есть все эти метрики в Postgres. Стало жить чуть лучше.
Плюс есть еще аварийные статусы завершения соединений, которые также желательно отслеживать.

Следующий раздел про планирование.
Что такое планирование? Условно говоря, выполнение запроса можно разделить на две части: построение плана и затем выполнение запроса, согласно этому плану.

И в Postgres было всего 2 способа, как можно получать данные по тому, как работает планирование:
- Есть ручной способ, с помощью explain. Мы можем взять какой-то запрос, передать его команде EXPLAIN, посмотреть, какой получился план. Это удобно для какого-то дебагинга отдельных запросов.
- Второй вариант полуавтоматический. Мы можем взять расширение auto_exaplain, настроить его, чтобы при достижении какого-то порогового значения план этого запроса записывался в журнал. Потом мы идем в журнал, грепаем его, ищем нужные запросы, планы и анализируем.
Т. е. полностью автоматического способа статистики не было.

В 13-ой версии в pg_stat_statements добавилась статистика, которая сохраняет себе время, потраченное на планирование запросов.
Существующие поля, связанные со временем выполнения были переименованы в exec_time. И вдобавок к ним добавились поля plan_time. Т. е. у нас есть время, потраченное на планирование, время, потраченное на выполнение, и время, потраченное на ввод-вывод. Мы уже в pg_stat_statements можем конкретно посмотреть, сколько ресурсов тратится на выполнение запросов. Это очень круто.
Но тут есть нюанс. По умолчанию оно выключено. Его нужно включать отдельно. Выключили в связи с тем, что в некоторых инсталляциях трекинг этого времени планирования может давать некий overhead к выполнению запроса. Overhead на уровне 1 %, но в каких-то нагруженных инсталляциях это может быть неприемлемо, поэтому его надо включать отдельно.

Кроме того в pg_stat_statements добавили отдельный флажок, который показывает уровень выполнения запроса.
Что это такое? Мы у себя на практике используем построение отчетов на основе pg_stat_statements. Мы берем, условно говоря, сумму по всем запросам. Потом для каждого запроса считаем вклад этого запроса в суммарную утилизацию и считаем проценты. Так мы выискиваем основные, жадные до ресурсов, запросы, чтобы потом их можно было оптимизировать.
Есть уровень выполнения, который регулируется параметром track. Можно отслеживать запросы верхнего уровня и можно отслеживать запросы, включая вложенный уровень. Допустим, у нас есть функция. Внутри функции есть еще какие-то запросы. Т. е. pg_stat_statements можно настроить таким образом, чтобы считать и время выполнения функции, и время выполнения всех вложенных запросов.
Но тут есть проблема. Если мы в таком случае считаем суммарные агрегаты, мы статистику считаем дважды. И у нас totals считаются криво.
Соответственно, чтобы решить эту проблему, нужно как-то разделять вложенный уровень от верхнего уровня. И как раз в 14-ой версии появился флажок toplevel. Он позволяет решить эту проблему. И наконец-то статистику можно считать нормально, не ориентируясь на то, что мы не знаем о уровне выполнения.

Кроме того, в pg_stat_statements добавлены некоторые небольшие улучшения, которые делают его еще лучше, еще полезней. Например, трекинг количества строк для служебных операций. Раньше в Postgres не было этой информации. У нас не было полной картины, сколько срок возвращено в результате нагрузки, в результате запросов. Сейчас это немножко подтюнили и для служебных операций есть эта статистика.
Плюс добавлена дополнительная служебная вьюха pg_stat_statements_info. Она показывает количество аллокаций, когда в pg_stat_statements не хватило места для статистики и ее размер нужно увеличить.
Плюс добавилась статистика утилизаций write ahead log.
Write ahead log — это штука, которая гарантирует сохранность данных. Прежде, чем изменить данные, мы эти изменения записываем в write ahead log, потом уже меняем сами данные. Если произошла какая-то авария в базе данных, база данных запускается, читает write ahead log и накатывает все изменения, согласно этому write ahead log и продолжает работу. Так реализован механизм надежной записи ваших данных в базу.
Write ahead log довольно ресурсоемкий. И если запись журнала работает медленно, то это напрямую сказывается на скорости выполнения запросов. И теперь с помощью новой добавленной статистики мы можем по каждому запросу посчитать, сколько было сгенерировано в write ahead log.

Следующий раздел как раз посвящен write ahead log, потому что в новых версиях есть дополнительные вещи, связанные с его отслеживанием.

Мы можем посчитать через pg_stat_statements, сколько у нас записано в write ahead log. Мы, условно говоря, можем просуммировать все эти значения и получить какую-то общую статистику по серверу, можем построить какой-то график rate и отслеживать пики записей в wrire ahead log.

Есть другой способ. Он более упрощенный. Можно взять текущую позицию в журнале транзакции и сравнить с нулевой отметкой. Мы получим большую цифру. Это будет количество байт, записанных в write ahead log за всю историю жизни сервера. По этой величине мы можем посчитать график rate и посмотреть, какие у нас есть пики, провалы во время записи в write ahead log.

Но! Теперь это все не нужно, в 14-ой версии появилась отдельная вьюха, которая позволяет всю эту статистику получить из одного места, без прибегания к обходным путям.

У нас есть теперь статистика по тому, сколько записей записано в write ahead log, сколько fpi-страниц, сколько байтов записано. Мы уже можем иметь количественные и качественные характеристики, как у нас утилизация в write ahead log происходит.

Есть информация о том, когда не хватает буферов для записей WAL, и мы можем уже подкрутить конфигурацию. Раньше информации этой не было и приходилось опытным путем высчитать, какой нужен размер буфера, чтобы его потом выставить в конфиге.

Другая клевая штука — это время, потраченное на запись и синхронизацию. Теперь можно по этим метрикам смотреть тормоза в производительности записи WAL. Раньше это приходилось делать через операционную систему. Мы смотрели на latency дисков, на утилизацию диску и по ним косвенно предполагали, что, наверное, запросы работают медленно, потому что диски тормозят, и все медленно работает. Теперь можно просто смотреть по метрикам времени и напрямую сказать, что у нас запись запросов тормозит, потому что у нас много времени уходит на запись WAL. Стало гораздо все проще.

И отмечу, что WAL также трекается в pg_stat_statements, как я уже сказал раньше. Он стал трекатстья в утилитах типа explain, auto_explain. Это информация о том, сколько было сгенерировано WAL. И появилась информация о том, сколько WAL сгенерировал автовакуум. Эта информация обычно попадает в журнал.

Следующий раздел связан с памятью.

В операционной системе Linux довольно сложно посчитать память, т. е. сколько памяти занимает один процесс, потому что сама подсистема виртуальная память довольно не простая. Там есть объем памяти, который затребовал процесс; объем памяти, сколько он сейчас используется; есть активные и неактивные списки; есть файловая анонимная память; плюс на все это накладываются большие страницы. И если говорить конкретно про Postgres, то посчитать, сколько памяти занимает postgres'овый процесс, довольно сложно.
Я привел ссылку на статью, где один из разработчиков Postgres Андерс описывает, как он искал overhead на утилизацию памяти postgres'овым процессом. Там чтиво примерно на 10-15 минут. Суть в том, что любой из взятых им способом, он с погрешностями и не дает точной оценки.

Начиная с 14-ой версии, появилась функция, которая позволяет с точки зрения Postgres показать раскладку утилизации памяти.

У нас есть информация, для чего выделена эта память, для чего она используется. Мы можем уже с точки зрения Postgres знать, где какой сегмент какой подсистемы используется и для чего.

И есть статистика об утилизации: сколько всего байт, сколько использовано и сколько свободно.

Но есть нюанс как всегда. Эта вьюха показывает утилизацию текущей сессии. Т. е. вы подключаетесь к Postgres. Для вас создается сессия, вы сделали какие-то запросы, погоняли. Потом этой функцией смотрите раскладку памяти.
Чтобы посмотреть раскладку памяти другого процесса, нужно вызвать другую функцию, ей передать идентификатор процесса, и она сделаем dump раскладки памяти в postgres'овый журнал. На мой взгляд, это не очень удобно. Но все-таки то, что появилось, уже лучше, чем ничего. Раньше мы с точки зрения операционной системы смотрели на всю эту картину и не имели точной оценки. Сейчас мы можем хотя бы из Postgres посмотреть и получить точную информацию.
Сама функция больше всего пригодится в случаях, когда нужно дебажить какие-то страшные случаи, связанные с утечкой памяти, либо если кто-то разрабатывает Postgres, им тоже будет полезно смотреть эти функции, чтобы понимать, что написанная функциональность не течет.

Следующий раздел посвящен двум статистикам, которые чаще всего используются. Как минимум, я их часто использую. Они, на мой взгляд, самые полезные.

Это pg_stat_activity, которая показывает текущую активность, и pg_stat_statements, которая показывает утилизацию ресурсов запросами. Т. е. если нужно искать какие-то проблемы в базе данных, обычно это те две статистики, куда мы обращаемся.
Раньше не было возможности соединить эти две вьюхи. В pg_stat_activity есть текст запроса, в pg_stat_statements есть текст запроса, но он нормализованный, т. е. все реальные значения заменены знаками доллар. На глаз, конечно, можно посмотреть, сопоставить и сказать, что вот это один и тот же запрос, это одни и те же ресурсы, значит, что этот запрос использует столько ресурсов. Но это все сложно и не работает со 100%-ой гарантией.

Начиная с 14-ой версии, появилась возможность считать идентификатор запроса queryid, который есть в pg_stat_statements. Его теперь можно считать и для pg_stat_activity. Соответственно, появилась возможность заджойнить две эти вьюхи и получить полную статистику по запросу.

Мы видим в pg_stat_activity какой-то долгий запрос, можем присоединить pg_stat_activity и получить суммарную статистику утилизации ресурсов этим запросом. Это очень круто.

Что еще? Также в pg_stat_activity появилось поле leader_pid. Начиная с версии 9.6, Postgres научился некоторые операции делать параллельно в несколько процессов. Условно говоря, есть лидерский процесс, пришел запрос от приложения, ему нужно прочитать таблицу. Лидерский процесс запускает несколько дочерних процессов. Эти дочерние процессы параллельно начинают таблицу читать. После прочтения они возвращают результат лидеру. Лидер отдает результат клиенту. Все круто.
Но есть нюанс. Иногда нужно посчитать статистику по всей группе. Нужно взять и родительский процесс, и все его дочерние. Но тут есть проблема. В отсутствие leader_pid приходилось к различным уловкам прибегать, например, отсортировать по идентификатору процесса, потом посмотреть на текст запроса. И если он совпадает, то, скорее всего, это одна и та же группа. И мы по этой группе посчитаем статистику.
Но есть случаи, когда этот способ не работает. Запросто в этой группе может получиться так, что идентификаторы совпадают по убыванию, но при этом там два лидера, и два лидера запустили несколько дочерних процессов. И мы получим две группы, но визуально будет казаться, что это одна группа.
Leader_pid позволяет взять конкретную группу и посчитать по ней какую-то статистику.

Например, у меня есть pg_center, которая делает профилирование ожиданий для какого-то конкретного запроса.
Здесь простой запрос: select count (*) из таблицы. И видно, что он выполняется 67 секунд, причем 61 секунда уходит на чтение данных. Эта статистика без учета фоновых процессов, т. е. у нас нет полной информации о том, сколько ресурсов требуется этому запросу.
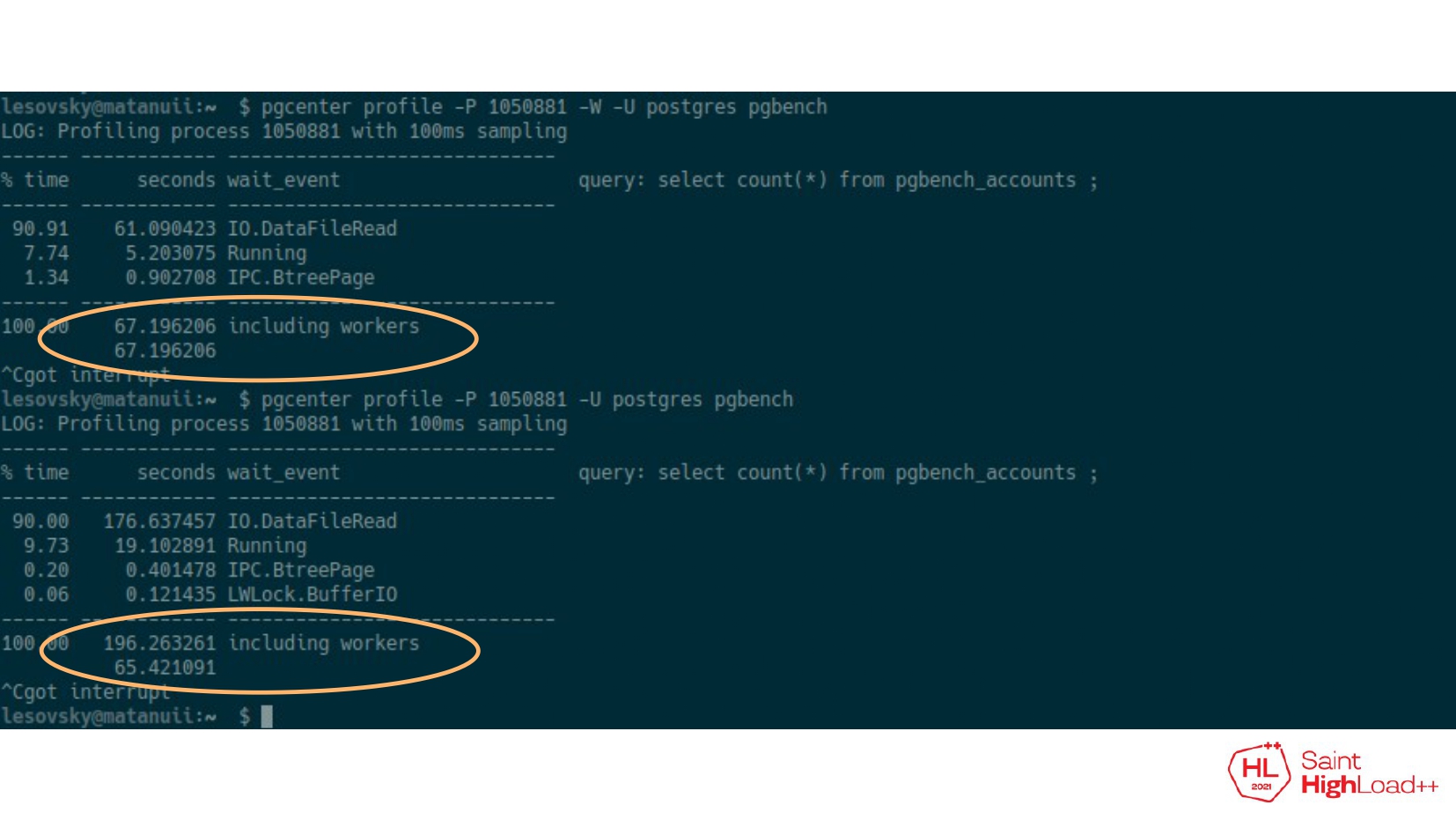
С помощью leader_pid мы можем конкретно найти все дочерние процессы и посмотреть, сколько выполнялся этот запрос. Здесь видно, что 196 секунд он выполнялся. И 176 секунд ушло на чтение данных. Мы имеем полную статистику по всей группе.

Последняя часть. К этой части я отнес все другие интересные новшества, которые не отнесены к другим предыдущим частям, но при этом заслуживают тоже внимания.

Pg_shmem_allocations — это новая вьюха, которая позволяет отслеживать распределение памяти в shared buffers. Раньше была статистика, сколько таблиц и индексов находится в shared buffers, но не было информации о внутренних структурах. Теперь можно получить это через новое представление.

Pg_stat_slru показывает использование SLRU кэшей. Это полезно для дебага подсистемы транзакций, когда у нас очень много транзакций, в LTP нагруженная система, и что-то идет не так и не понятно, что копать. Pg_stat_slru позволяет начать хоть как-то делать дебаг этой подсистемы.
Приведена статья — https://postgres.ai/blog/20210831-postgresql-subtransactions-considered-harmful. Я вам экономлю примерно 30 минут чтения. Она очень клевая, она показывает пример использования этой статистики, кому интересно, рекомендую почитать.

Следующая статистика связана с мониторингом слотов и репликации. Это обычно какие-то кластерные конфигурации, когда у нас несколько узлов, используется репликация, используются слоты. Либо используются какие-то вещи типа Debezium, когда мы захватываем все изменения в базе данных и снова по логической репликации передаем куда-то наружу во внешние системы.
Как правило, все эти вещи сделаны на слотах и репликации. И раньше был pg_replications_slots, но эта вьюха показывала довольно упрощенную статистику. И в новой вьюхе у нас уже есть количественные и качественные характеристики утилизации. По ним тоже можно строить графики и смотреть, как у нас там работают эти подсистемы.

Pg_locks — очень крутая вьюха, которая позволяет отслеживать блокировки, возникающие при работе запросов.
Очень часто бывает нужно посмотреть, как давно блокировка находится в ожидании. Раньше для этого нужно было присоединить pg_stat_activity и по полям pg_stat_activity посчитать вот это ожидание. Теперь можно не присоединять, можно по полю waitstart просто посчитать и посмотреть без лишнего присоединения.

Кроме того, небольшое улучшение, связанное с логированием автовакуума, когда автовакуум завершает работу, dump и его работа попадает в журнал сервера. Там же появляется время, сколько было времени потрачено на выполнение ввода-вывода этими операциями. Нововведение небольшое, но довольно полезное.

И на этом все! Хочется подвести какой-то итог. Статистики очень много. В ней очень легко запутаться, нужно помнить вьюхи, названия функций и имена полей.

Вам, как разработчикам, нужно помнить всего две вещи. Есть pg_stat_activity и pg_stat_statements. Они помогают вам отслеживать проблемы и искать проблемы с производительностью.
Если что-то идет с базой не так, мы смотрим pg_stat_activity. Если мы хотим найти запросы для их последующей оптимизации, мы смотрим pg_stat_statements. Если есть какая-то долгая активность, мы смотрим соответствующие progress views.
Если вы делаете какой-то мониторинг у себя в компании или разрабатываете продукт, можно пользоваться pgstats.dev. Я сам им пользуюсь довольно часто.

Это своего рода справочник. В нем собрана информация о вьюхе, о полях, об истории изменениях. Это более справочный материал для тех, кто разрабатывает мониторинги, либо пишет подсистему мониторинга, занимается ... у себя в компании.

На этом все. Спасибо за внимание! Меня зовут Алексей. Если есть какие-то вопросы, задавайте.
Вопросы
— Добрый день, Алексей! Спасибо за очень интересный доклад. Вопрос про мониторинг достаточно редкий. Бывают приложения, которые работают через хранимые процедуры. Причем хранимые процедуры, если в транзакции крупные ветки, могут быть длинными. Например, идет 20 тяжелых SQL-операторов и в 21-ом происходит некоторое торможение. Как узнать, что происходило? Воспроизвести контекст, при котором вызывается 21-ый оператор отдельно трудно. В Oracle можно было сохранить план выполнения запроса. В Postgres в этом месте план выполнения запроса сохранить нельзя. Хочется понять, что происходило и как действовать.
— Тут есть два варианта. Если говорить конкретно про Postgres, то есть представление pg_stat_user_functions. В нем сохраняется статистика выполнения как раз функций и процедур. Можно там посмотреть время выполнения, найти медленную функцию, которая во всей цепочке вызовов использовалась, и по ней посмотреть. Взять эту конкретную функцию, посмотреть ее текст и пытаться дебажить.
Есть другой вариант с точки зрения приложения, но он более сложный. В приложении нужно занести библиотеку инструментирования, которая будет строить трейсы времени выполнения операции. Это довольно сложный способ.
— Понятно. Я как раз про это и спрашивал. На самом деле функция уже найдена. Она изнутри себя никаких новых функций не вызывает. Идет последовательность SQL-операторов. Как раз я про это в своем докладе буду рассказывать. Приходится строить свою систему инструментирования, хотелось бы, чтобы Postgres предоставлял более простые способы.
— Есть дебагеры для PL/pgSQL-функций. Можно воспользоваться ими, но я в production их практически не видел. Здесь нужно смотреть какие-то другие возможные проблемы. Возможно, во время выполнения функции, когда у нее были тормоза, были какие-то другие вещи, которые коррелировались с этим. Может быть, какие-то блокировки возникали, может быть, какая-то долгая транзакция висела. Тут нужно смотреть на все скопом, что происходило в базе данных.
— Да, понятно. Спасибо! Когда выявлено, что тормозит именно этот оператор именно в этой функции, приходится изобретать что-то свое, к сожалению, хотя было бы интересно, чтобы база в этом тоже помогала.
— База работает с тем, что написал разработчик.
— Алексей, спасибо! Было безумно интересно, уже примеряю на свой проект. Меня тоже зовут Алексей. Вопрос такой — те процедуры и запросы, которые запущены через pg_cron, также можно посмотреть через статистику?
— Да, можно посмотреть через pg_stat_activity, они будут там отображаться.
— Если у меня не просто instanse (1 сервер), а Patroni (кластер из PostgreSQL), сверху арбитр натянут, то я могу как-то агрегировано по всем нодам получить статистику или нужно по каждому?
— Это нужно уже писать свое что-то. Можно по идее поставить Postgres-экспортер, который будет со всех нод собирать метрики, складывать их в хранилище, а мы уже на Grafana, поверх этого хранилища, сделаем дашборд, в которые все эти метрики сагрегируем. Т. е. мы добавим какой-то идентификатор для кластера. У Patroni, например, есть имя кластера. Например, в метках метрик отдаем имя этого кластера и можем по нему уже сагрегировать, и получить статистику по всему кластеру целиком. Но это ручные действия, из коробки — ничего такого нет.
— Добрый день! Вопрос по хранению pg_stat_statements. Как вы его храните? Если в Prometheus, то как? И второй вопрос — как часто делаете resete по pg_stat_statements и нужен ли он вообще?
— У нас довольно все упрощенно. У нас в компании очень много клиентов. И мы стараемся работать неинвазивно и ничего не устанавливать в базу данных. Как правило, у нас есть какая cron-задача, которая раз в сутки делает снимок pg_stat_statements и отправляет его в наше хранилище. В этом хранилище мы уже строим по нему отчеты.
После того, как мы взяли снимок pg_stat_statements, мы делаем resete статистики, и она у нас начинает копиться заново. Т. е. мы делаем его раз в сутки.
— А если я в динамике хочу посмотреть pg_stat_statements?
— Если мы делаем все статистики, в этом нет ничего страшного. Если взять мой любимый Prometheus, у него есть функция rate, которая считает дельту от текущего и предыдущего значения. И она умеет как раз обрабатывать случаи, когда счетчик сбросился в ноль.
— Как раз по Prometheus есть вопрос. Часто, когда очень много запросов, их довольно проблематично хранить в Prometheus. Вы используете какое-то дополнительное хранилище и как-то в Grafana делаете, либо докидываете ресурсов Prometheus?
— Тут такой момент, что у заказчиков, которые к нам приходят, у них либо есть мониторинг, либо нет, но мы их не включаем в свои системы мониторинга, потому что не всегда заказчик на это готов идти. Мы обычно рекомендуем использовать Okmeter. Для них писали техническое задание на мониторинг Postgres. И они хранят текст. Они еще отдельно у себя внутри нормализуют этот запрос, убирают комментарии, схлопывают одинаковые доллары. В общем, они делают еще дополнительную нормализацию. И они хранят весь текст с запроса.
Тут все зависит от того, какая у вас система для долгосрочного хранения метрик. Если мы говорим про Prometheus, то это может быть Thanos, Cortex и VictoriaMetrics. Если у вас позволяют ресурсы, вы можете в вашем экспортере уменьшить длину значения в метке и передавать запросы сохранять. Понятно, что там будет кардинальность, но тут уже нужно смотреть на метрики системы хранения. Если она справляется, то почему бы и нет, можно хранить.
— А как часто вы очищаете pg_stat_statemetns?
— Как часто очищать? Как хотите. Можете часто очищать, если есть в этом необходимость, можете не очищать. Тут все идет от ваших потребностей. Можно оставить и пусть она там копиться какое-то время. Нам важно смотреть какие-то изменения во времени. Т. е. это какая-то дельта или какая-то агрегация по интервалу времени. Здесь сброс счетчиков не особо вреден.
— Скажите, пожалуйста, какие возможности есть диагностики базы данных, если я по каким-то причинам не могу сессию поднять? Толи она вообще не поднимается, толи поднимается очень долго, например, минутами.
— Вы имеете в виду, что PSQL не подключается, вы не можете установить сессию?
— Да, у меня что-то случилось. Я вижу, что база данных почти мертвая, сессию поднять не могу.
— Если мы не можем подключиться к базе данных, нужно смотреть проблемы в том окружении, где работает база данных. Это или операционная система, или контейнер. Мы подключаемся в операционную систему, возможно, через SSH, либо в системных дашбордах смотрим, что у нас происходит с системой. Я бы зашел по SSH, запустил top, посмотрел на утилизацию ресурсов. Если это CPU или, допустим, диски, я бы уже смотрел на работу. Плюс нужно еще посмотреть журналы, что происходит. Может быть, есть какая-то проблема в журналах. Возможно, превышен лимит количества подключений, либо сессия висит на этапе аутентификации.
Причины могут быть разные. Здесь уже нужно использовать обычные методы troubleshooting, которые используются в системном администрировании. Смотрим утилизацию ресурсов, смотрим ошибки, смотрим сатурацию, смотрим в утилизации нет ли очередей скопившихся.
