Тема ChatGPT и других моделей от OpenAI сейчас на хайпе. Но на них одних свет клином не сошёлся. Или всё-таки сошёлся? Попробуем разобраться и обойдёмся сегодня без кода, только общие понятия, боль и страдание.
Представьте, что вам нужно сделать чат-бота, который мог бы отвечать на вопросы пользователей на основании ваших собственных данных: товаров в интернет-магазине, базы знаний службы поддержки, маркетинговых статей и т.п. Или, списка кафе и коворкингов, в моём случае.
До недавннего времени подобные диалоги сводились к выбору из "Вас интересует это? - Нажмите сюда. Интересует другое? - Нажмите туда. Ничего не поняли? - Дождитесь оператора". Не очень дружелюбно, но иногда вполне предсказуемо и понятно, только делать такую развесистую логику очень долго.
Ok, давайте добавим дружелюбия и сделаем "natural language interface" типа "Show me 10 cafes with sockets close to me in London" (если верить маркетологам, то люди и не такое напишут, лишь бы найти желаемое).
Одним из первых подобных "распознавателей человеческого языка" стал сервис Amazon Lex (а также Google Dialogflow и ещё десяток подобных)
Amazon Lex V2 is an AWS service for building conversational interfaces for applications using voice and text. Amazon Lex V2 provides the deep functionality and flexibility of natural language understanding (NLU) and automatic speech recognition (ASR) so you can build highly engaging user experiences with lifelike, conversational interactions, and create new categories of products.
Amazon Lex V2 enables any developer to build conversational bots quickly. With Amazon Lex V2, no deep learning expertise is necessary—to create a bot, you specify the basic conversation flow in the Amazon Lex V2 console. Amazon Lex V2 manages the dialog and dynamically adjusts the responses in the conversation. Using the console, you can build, test, and publish your text or voice chatbot. You can then add the conversational interfaces to bots on mobile devices, web applications, and chat platforms (for example, Facebook Messenger).
Звучит красиво: умеет вычленять сущности из обычного текста и ходить в API за данными.
Для моего примера выше понадобилось написать utterance "Show me {count} {type} with {sockets} close to me in {region}" и описать сущности. После чего из исходной фразы получался JSON {count: 10, type: cafe, sockets: many, region: London}.
Но вот беда, для похожей фразы "Give me 10 coworking in Riga" нужен совсем другой utterance, а для самого простого запроса "5 workplaces nearby" - третий. 🤷♂️ В общем, я остановился после нескольких сотен utterances из тупых перестановок слов местами. Прогон всех тестов занимал около часа.
Другая боль - это диалоги; например, вторым запросом искателя коворкингов может быть "What about cafes?". В Lex есть передача контекста 3-мя способами, но ограниченное количество раз и только через код (функции Amazon Lambda).
Ещё у Lex есть другой вариант использования: обучение на датасете из сотен тысяч вопросов и ответов и дальнейшие автоматические ответы. Наверное, подойдёт колцентрам с однотипными запросами.
Что ж, переходим к ChatGPT о возможностях которого ходят легенды
Развенчиваем мифы: модели, доступные через API "глупее" веб-интерфейса чата, потому что у них нет памяти и контекста 🤦♂️
Получается, для работы с каталогом товаров, нужно передавать его целиком в каждом запросе, а это не пролезет даже в 32k токенов самой дорогой модели gpt-4-32k. А ещё с каждым сообщением нужно передавать все предыдущие запросы и ответы для сохранения контекста.
Примерно так работают 99,9(9)% всех типовых ботов, которые берут деньги с пользователей начиная с 10-го ответа (к примеру). Занавес.
В общем, второй вариант реализации задуманного - это токенизация и векторизация исходных текстов, статей или каталога товаров; токенизация и векторизация пользовательского запроса и нахождение нескольких самых близких подходящих векторов по cosine similarity.
Упрощённо, так работает семантический поиск и для него не нужны чатовые модели. Однако, для "дружелюбности" диалога и ответов, можно использовать чатовые модели и передавать им вместе с запросом найдённые векторы и соответствующие им оригинальные тексты.
Вот несколько статей об этом и ещё чуть чуть.
Все действия можно проводить на своих собственных моделях, моделях OpenAI (например, text-embedding-ada-002) через API и на любых общедоступных моделях, например, NLP cloud. Векторы можно хранить хоть в CSV, но лучше в специализированных векторных БД, например, Qdrant.
Сейчас подобный вариант становится фактическим стандартом и именно на нём основано большинство поисковых плагинов к ChatGPT.
Плюсов несколько
низкая цена векторизации (она производится только при загрузке/изменении исходных данных) и хранения, особенно в локальной БД
а также хоть какая-то возможность сохранить контекст, таская весь диалог в каждом обращении к чатовой модели
Минусы тоже есть
исходные данные должны быть текстовыми, а точнее, описательными (мой каталог кафе из enum-параметров в JSON-формате не подошёл)
их должно быть много
Вот пример диалога с ботом на модели, обученной всего на 10 статьях про снижение веса.
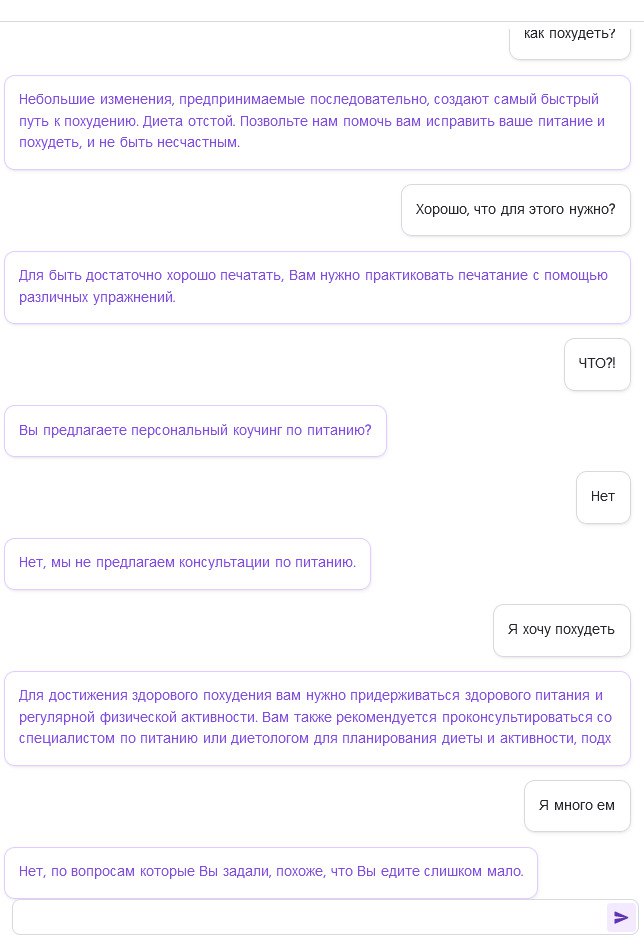
Уже появились сервисы, упрощающие реализацию всего стека от подготовки данных до получения кода чата на свой сайт. Например, Databerry и Spellbook. А также неплохие альтернативные модели, например, Vicuna.
Я же, после векторных экспериментов, перешёл к третьему варианту — переводу человеческого запроса в JSON при помощи чатовой модели
Оказалось, это самый простой, дешёвый и быстрый вариант реализации моей первоначальной идеи 😎
Модели вместе с запросом пользователя передаётся инструкция
Convert the question below to JSON data.
Mostly questions are related to cafes and coworkings with different amenities.
Use only following parameters.
Skip unknown parameters and parameters that not in question.
Just output JSON data without explanation, notes or error messages!
Parameters
"""
- count: integer from 0 to 5
- type: one of "Cafe", "Coworking" and "Anticafe"
- region: any city
- sockets: one of "None", "Few" and "Many"
- noise: one of "Quiet", "Medium" and "Noisy"
- size: one of "Small", "Average" and "Big"
- busyness: one of "Low", "Average" and "High"
- view: one of "Street", "Roofs" and "Garden"
- cuisine: one of "Coffee & snacks" and "Full"
- roundclock: one of true and false
В большинстве случае в ответ приходит вполне нормальный JSON типа {count: 5, type: cafe, sockets: many, region: London}, который можно передавать дальше в API микросервис.
Но текстовая генеративная модель не была бы текстовой генеративной моделью, если бы всегда отвечала одинаково (даже при заморозке с temperature=0). Примерно в 10% случаев она "тупит" и добавляет несуществующие параметры или забывает закрыть JSON, причём аналогичный повторный запрос обрабатывается нормально.
Бороться с этим бесполезно, но несуществующие параметры или недопустимые значения можно убрать, отвалидировав ответ по JSON-схеме, а также предложить пользователю спросить бота ещё раз.
К слову, свежая модель gpt-4 оказалась "умнее", предсказуемее и рандомных параметров не добавляет, но стоит в 6 раз дороже. Ждём gpt-4-turbo.
Получившегося бота можно поспрашивать тут @WorkplacesDigitalBot, его бюджет - $10/месяц пока не начнёт зарабатывать самостоятельно, сохранения контекста тоже нет.
