Прошло шесть с лишним лет с момента, когда я начал работать над проектом Bonsai. Если в двух словах, то это вики-движок, заточенный под хранение семейной истории и построение генеалогических деревьев. Он распространяется в полностью открытом и бесплатном виде, подразумевая установку на ваш собственный сервер в качестве docker-контейнера.

Более подробно о его устройстве и истории создания можно почитать в моих предыдущих статьях 3+ годичной давности: раз, два. Изначально я планировал выпускать мажорную версию и писать про нее статью раз в год, но родительство и переезд вносят в планы изрядную долю хаоса. Тем не менее, проект все еще активен и развивается. Сегодня я расскажу о том, что было реализовано и улучшено за последнее время.
По сравнению с предыдущими версиями Bonsai стало гораздо проще разворачивать. Теперь он не имеет вообще никаких обязательных зависимостей и умещается в один контейнер, который можно поднять в одну команду с помощью docker-compose:
Я сделал изначальную ставку на этот способ из-за большей безопасности и удобства повседневного использования. К сожалению, ставка не оправдалась из-за муторного процесса регистрации приложений в Google / Facebook, отпугивавшего многих потенциальных пользователей.
Кроме того, летом 2021 года Facebook запустил новые правила модерации приложений, требуя предоставлять им демо-учетки. В контексте Bonsai это бессмысленно и невозможно, поскольку нарушает основополагающую идею о конфиденциальности хранящихся внутри данных. С тех пор авторизация через Facebook более не рекоммендуется (однако все еще поддерживается), а способом авторизации по-умолчанию является старый добрый пароль.
Оказался первым кандидатом на выпиливание по нескольким причинам. Во-первых, он неоправданно жирный: контейнер Elasticsearch занимал больше самого приложения, а использовался едва ли 1% от доступного функционала. Во-вторых, у меня так и не получилось добиться от него вменяемого ранжирования запросов по релевантности: поиск по фразе «Иван Петров» показывал варианты типа «Петр Иванов», «Михаил Петрович» вперед полного совпадения.
В итоге перешли на Lucene.NET и вздохнули с облегчением: поиск работает толковее, поведение зафиксировано легковесными unit-тестами, да и общий размер контейнеров уменьшился на треть.
Использовался исключительно для получения HTTPS-сертификата, который, в свою очередь, нужен был только для авторизации по сторонним сервисам. Использование выходило довольно неуклюжим: необходимо было руками редактировать docker-compose.yml и прописывать туда IP-адрес и пароль.
Как и бэкапы, настройка HTTPS может быть произведена множеством разных способов и поэтому теперь находится в зоне ответственности админа. Я лично использую Cloudflare Tunnel (бесплатный при условии размещения домена в Cloudflare), по настройке которого есть очень простое руководство.
На момент начала проекта вопрос «какую базу данных использовать» казался очевидным: у меня был позитивный опыт работы с PostgreSQL, она современная, хорошо поддерживается в .NET, может напрямую работать с JSON-данными, имеет огромный запас по производительности и так далее. Даже полнотекстовый поиск есть, но докрутить его до получения вменяемых результатов так и не получилось.
Основная претензия к PostgreSQL была в том, что он требует обслуживания. Например, обновление между мажорными версиями требует ручной выгрузки данных через дамп. Для меня же было принципиально сохранять полную обратную совместимость и выполнять апгрейд приложения в один клик, просто выбрав последнюю версию.
Вторая проблема — такая же, как с ElasticSearch. Контейнер занимал более половины общего объема приложения, однако я использовал только крошечную часть его функционала. Запас по производительности тоже не имел смысла: код самого Bonsai станет bottleneck'ом гораздо раньше, чем база. Особенно это стало бросаться в глаза после того, как все остальные зависимости были выпилены.
В итоге была добавлена поддержка SQLite. Причин выбора этой БД много:
SQLite поддерживает все возможности, которые я использовал ранее: представления, JSON-операции и тому подобное. С одной фичей повезло особенно:
Возможность указывать порядок сортировки в функциях-агрегаторах добавили только в ноябре 2023. Это исчезающе редкий пример того, как прокрастинация играет на руку: первый раз я задумался о портировании в 2021, и начни я миграцию прямо тогда, пришлось бы выкручиваться сложным и некрасивым способом.
Теперь SQLite используется в качестве бэкенда по-умолчанию для новых инсталляций. Существующие инсталляции можно легко перевести на SQLite: достаточно проставить опцию в конфиге, и все данные будут автоматически перенесены. С другой стороны, PostgreSQL будет по-прежнему поддерживаться, поэтому те, кто не желает обновляться, могут просто оставить все как есть.
Конечно, миграция не прошла идеально гладко. Неожиданной подставой оказалось то, что в SQLite функция lower() работает только для ASCII. Автор официального пакета отказался предоставлять сборку вместе с расширением
Второй проблемой является то, что в миграциях БД использовались специфичные для PostgreSQL конструкции. Все «сложные» запросы отныне придется дублировать на двух диалектах. Поддержка усложнится, но хочется надеяться, что оно того стоит.
Ключевой возможностью Bonsai является автоматическое построение генеалогических деревьев по данным, хранящимся в базе. Для вычисления визуального расположения элементов используется библиотека ELK.js.
Увы, эта библиотека хорошо отрисовывает только небольшие деревья (20-30 элементов), а дальше сложность алгоритма растет экспоненциально и получается либо очень запутанно, либо очень медленно (либо и то, и другое одновременно). Пользователи, занесшие 250+ записей в базу, жаловались на невозможность пользоваться фичей как таковой, но выжать ничего больше из ELK.js не выходило.
Я пытался найти замену и рисовать деревья иными способами (GraphViz, MSAGL), но не один из них не дал желаемого результата. В порыве отчаянья я даже пытался переписать оригинальный ELK c Java на C#, надеясь на большую производительность по сравнению с Node.JS, но спустя три изнурительных дня забросил это начинание.
Когда задача не поддается прямым методом, зачастую помогает сделать шаг назад и посмотреть на нее в другой плоскости. А настолько ли необходимо одно большое дерево со всеми страницами? Как им пользуются, какую информацию оно позволяет получить? Поговорив со знакомыми, я получил несколько ответов, которые примерно укладывались в две группы:
Итого: можно сделать несколько «срезов» дерева, представляющих частичную (и потому более наглядную) информацию. Срезов поддерживается три:
Самый простой срез: рекурсивно показать биологических родителей, затем их родителей и так далее. Дерево приобретает вид перевернутой пирамиды.
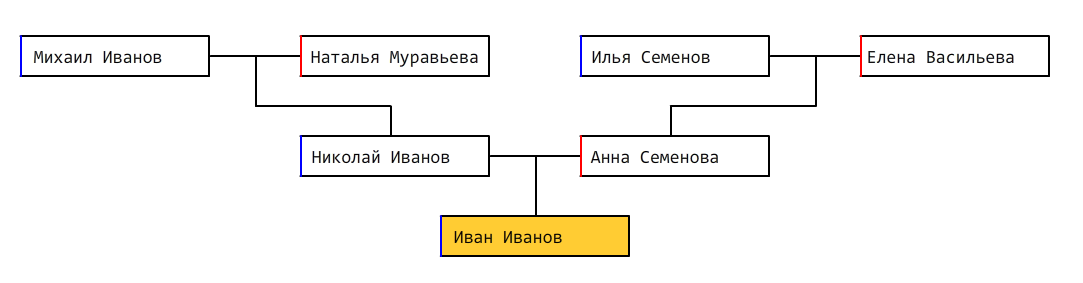
Отображает детей, их детей, и так далее, а также супругов, являющихся вторым родителем для каждого ребенка. Дерево приобретает вид вертикальной колонны или пирамиды, в зависимости от количества детей.

Отображаются страницы в радиусе «двух шагов» от текущей, то есть от бабушек до внуков.
С этим срезом было больше всего трудностей:
Радиус из двух шагов не является идеальным. Например, я знаю случаи, когда благодаря молодым родителям ребенок может проводить много времени со своими пра-бабушками, которые не попадают в радиус (false negative). С другой стороны, увеличение радиуса до трех шагов сильно раздувает граф, в него попадет много лишних людей (false positives), и время рендеринга графа ощутимо увеличивается, поэтому число 2 выбрано в качестве разумного компромисса.
План на будущее: проэкспериментировать с более сложными критериями, например пересечение по времени жизни, назначение различных весов для разных типов связей и тому подобное.
Типы деревьев можно включить по одному на странице настроек. У себя я отключил полное дерево и включил три частичных:

Теперь дерево можно отобразить в полноэкранном режиме или в отдельном окне. Таким образом его можно легко экспортировать, например, используя браузерные плагины для создания скриншотов или встроенный функционал экспорта страницы в PDF.
Тут стоит сразу оговориться, что сделать максимально навороченную админку не является целью проекта. Основная цель — сохранение данных на протяжении десятилетий. Для этого проект придется переписывать полностью раз в 15-20 лет, и чем больше всякой дичи в него накручено, тем сложнее это будет сделать. Любой новый функционал должен быть либо тривиально реализуемым, либо давать моментальную ощутимую пользу по сравнению с затратами на разработку.
Тем не менее, главная страница админки была кардинально переработана и теперь представляет собой список показателей и ленту истории:

У страниц теперь считается «процент заполненности». Для разных типов страниц он складывается из разных полей, список которых отображается при наведении:

Ссылка «N можно улучшить» под числом страниц на главной сортирует их, начиная с наименьшего процента заполненности. Так можно легко определить, какие страницы требуют доработки, а какие уже готовы.
Аналогично, ссылка «N без отметок» под количеством медиа-файлов предлагает добавить отметки на фото и видео, где они отсутствуют.
В редакторе текста теперь можно легко добавлять ссылки на другие страницы, используя символ @ по аналогии с тем, как это сделано в Github:

В той части, которая доступна читателям, также появилось несколько небольших улучшений:
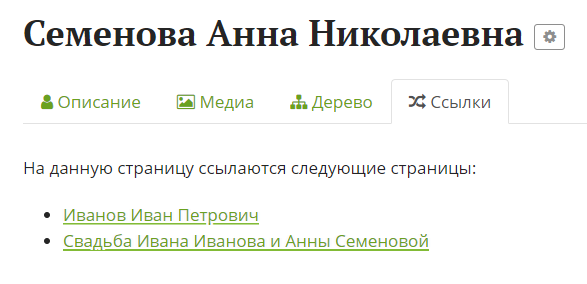
На отдельной вкладке показываются все страницы, которые ссылаются на данную:
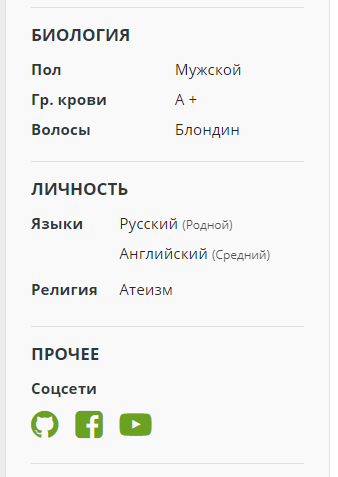
Для страниц можно указывать ссылки на социальные сети. Поддерживаются Twitter (который теперь X), Одноклассники, VK, Telegram, Youtube и Github, а также соцсети-которые-нельзя-называть.
Можно сказать, что разработка вышла на некое спокойное плато: проектом уже давно можно комфортно пользоваться, новый функционал добавляется без фанатизма, большинство возникающих багов тривиальны и исправляются за полчаса.
Это позволяет оглянуться назад и сделать выводы: архитектура проекта оказалась верной и прошла проверку временем. В предыдущих моих проектах рано или поздно появлялось тянущее чувство, что очень лакомую фичу X не получится реализовать (или, что еще хуже, поправить баг) без полного переписывания, но в этот раз такого нет.
В первой статье в 2019 году я рассказывал, что изначально хотел сделать базу полностью формализованной, чтобы позволить находить в ней ответы на конкретные вопросы вида «какая марка была у первого автомобиля моего деда», но отказался от этого подхода в пользу неструктурированного текста, надеясь на развитие нейросетей. Это ставка тоже оправдалась: ChatGPT уже отлично отвечает на вопросы по скормленному ему тексту. Думаю, что в течение всего пары лет этот функционал будет встроен в браузер и он сможет сам переходить по страницам, чтобы найти нужный ответ.
Общие планы на дальнейшую разработку такие:
Стоит ли переводить приложение на другие языки? Однозначного ответа у меня нет. С одной стороны, это (теоретически) позволило бы большему числу пользователей воспользоваться проектом и, возможно, присоединиться к разработке. С другой стороны, это огромный пласт работы: для полноценной локализации нужно будет не просто перевести строки, но учесть культурные различия в типах родственных связей, добавить поддержку RTL и тому подобное. А что делать с самими страницами? Пока что склоняюсь к мысли, что лучшим решением тут будет, опять же, функция автоматического перевода, встроенная в браузер. Так или иначе, время покажет.
Репозиторий проекта, с документацией и инструкцией по установке:
https://github.com/impworks/bonsai
Развернутый демо-инстанс, на котором данные сбрасываются каждые 15 минут:
https://bonsai.kirillorlov.pro/
Если вы пользуетесь проектом, напишите мне. Буду рад любой обратной связи!
В 2020 году от Bonsai отпочковался проект Isotope, заточенный под ведение фотогалереи. На отдельную статью историй не наберется, но все же он стоит отдельного упоминания.

В первую очередь оказалось, что мне привычнее всего систематизировать фотографии в виде вложенных папок и тегов, а в Bonsai страницы для этого тяжеловесны и не имеют иерархии. Кроме того, отсутствие обязательств по долгосрочной поддержке позволило использовать современный SPA, сделать вменяемую мобильную версию и продвинутую админку. Некоторые эксперименты, изначально проверенные там (работа с SQLite, самопальный планировщик задач), были портированы обратно в Bonsai.
Проект также полностью открытый и бесплатный. Если кому-то понравится — пользуйтесь на здоровье!

Более подробно о его устройстве и истории создания можно почитать в моих предыдущих статьях 3+ годичной давности: раз, два. Изначально я планировал выпускать мажорную версию и писать про нее статью раз в год, но родительство и переезд вносят в планы изрядную долю хаоса. Тем не менее, проект все еще активен и развивается. Сегодня я расскажу о том, что было реализовано и улучшено за последнее время.
Упрощение установки и поддержки
По сравнению с предыдущими версиями Bonsai стало гораздо проще разворачивать. Теперь он не имеет вообще никаких обязательных зависимостей и умещается в один контейнер, который можно поднять в одну команду с помощью docker-compose:
docker-compose -f docker-compose.lite.yml upАвторизация через сторонние сервисы
Я сделал изначальную ставку на этот способ из-за большей безопасности и удобства повседневного использования. К сожалению, ставка не оправдалась из-за муторного процесса регистрации приложений в Google / Facebook, отпугивавшего многих потенциальных пользователей.
Кроме того, летом 2021 года Facebook запустил новые правила модерации приложений, требуя предоставлять им демо-учетки. В контексте Bonsai это бессмысленно и невозможно, поскольку нарушает основополагающую идею о конфиденциальности хранящихся внутри данных. С тех пор авторизация через Facebook более не рекоммендуется (однако все еще поддерживается), а способом авторизации по-умолчанию является старый добрый пароль.
Elasticsearch
Оказался первым кандидатом на выпиливание по нескольким причинам. Во-первых, он неоправданно жирный: контейнер Elasticsearch занимал больше самого приложения, а использовался едва ли 1% от доступного функционала. Во-вторых, у меня так и не получилось добиться от него вменяемого ранжирования запросов по релевантности: поиск по фразе «Иван Петров» показывал варианты типа «Петр Иванов», «Михаил Петрович» вперед полного совпадения.
В итоге перешли на Lucene.NET и вздохнули с облегчением: поиск работает толковее, поведение зафиксировано легковесными unit-тестами, да и общий размер контейнеров уменьшился на треть.
Traefik
Использовался исключительно для получения HTTPS-сертификата, который, в свою очередь, нужен был только для авторизации по сторонним сервисам. Использование выходило довольно неуклюжим: необходимо было руками редактировать docker-compose.yml и прописывать туда IP-адрес и пароль.
Как и бэкапы, настройка HTTPS может быть произведена множеством разных способов и поэтому теперь находится в зоне ответственности админа. Я лично использую Cloudflare Tunnel (бесплатный при условии размещения домена в Cloudflare), по настройке которого есть очень простое руководство.
PostgreSQL
На момент начала проекта вопрос «какую базу данных использовать» казался очевидным: у меня был позитивный опыт работы с PostgreSQL, она современная, хорошо поддерживается в .NET, может напрямую работать с JSON-данными, имеет огромный запас по производительности и так далее. Даже полнотекстовый поиск есть, но докрутить его до получения вменяемых результатов так и не получилось.
Основная претензия к PostgreSQL была в том, что он требует обслуживания. Например, обновление между мажорными версиями требует ручной выгрузки данных через дамп. Для меня же было принципиально сохранять полную обратную совместимость и выполнять апгрейд приложения в один клик, просто выбрав последнюю версию.
Вторая проблема — такая же, как с ElasticSearch. Контейнер занимал более половины общего объема приложения, однако я использовал только крошечную часть его функционала. Запас по производительности тоже не имел смысла: код самого Bonsai станет bottleneck'ом гораздо раньше, чем база. Особенно это стало бросаться в глаза после того, как все остальные зависимости были выпилены.
В итоге была добавлена поддержка SQLite. Причин выбора этой БД много:
- Минималистичная: сборка занимает всего 1.5 мегабайта, вместо 299 мб для PostgreSQL
- Стабильная: заявлена полная обратная совместимость минимум до 2050 года, что перекликается с целями Bonsai по сохранению данных десятилетиями
- Легко бэкапить: достаточно скопировать один файл любым доступным способом
- Не требует обслуживания вообще
- Также имеет хорошую поддержку со стороны .NET и EF
SQLite поддерживает все возможности, которые я использовал ранее: представления, JSON-операции и тому подобное. С одной фичей повезло особенно:
SELECT string_agg(foo, ", " ORDER BY id) FROM barВозможность указывать порядок сортировки в функциях-агрегаторах добавили только в ноябре 2023. Это исчезающе редкий пример того, как прокрастинация играет на руку: первый раз я задумался о портировании в 2021, и начни я миграцию прямо тогда, пришлось бы выкручиваться сложным и некрасивым способом.
Теперь SQLite используется в качестве бэкенда по-умолчанию для новых инсталляций. Существующие инсталляции можно легко перевести на SQLite: достаточно проставить опцию в конфиге, и все данные будут автоматически перенесены. С другой стороны, PostgreSQL будет по-прежнему поддерживаться, поэтому те, кто не желает обновляться, могут просто оставить все как есть.
Конечно, миграция не прошла идеально гладко. Неожиданной подставой оказалось то, что в SQLite функция lower() работает только для ASCII. Автор официального пакета отказался предоставлять сборку вместе с расширением
unicode, а самостоятельная сборка сильно усложнит инфраструктуру Bonsai — в результате проблема была решена денормализацией базы и хранением копии некоторых данных в lowercase-виде.Второй проблемой является то, что в миграциях БД использовались специфичные для PostgreSQL конструкции. Все «сложные» запросы отныне придется дублировать на двух диалектах. Поддержка усложнится, но хочется надеяться, что оно того стоит.
Частичные деревья
Ключевой возможностью Bonsai является автоматическое построение генеалогических деревьев по данным, хранящимся в базе. Для вычисления визуального расположения элементов используется библиотека ELK.js.
Увы, эта библиотека хорошо отрисовывает только небольшие деревья (20-30 элементов), а дальше сложность алгоритма растет экспоненциально и получается либо очень запутанно, либо очень медленно (либо и то, и другое одновременно). Пользователи, занесшие 250+ записей в базу, жаловались на невозможность пользоваться фичей как таковой, но выжать ничего больше из ELK.js не выходило.
Я пытался найти замену и рисовать деревья иными способами (GraphViz, MSAGL), но не один из них не дал желаемого результата. В порыве отчаянья я даже пытался переписать оригинальный ELK c Java на C#, надеясь на большую производительность по сравнению с Node.JS, но спустя три изнурительных дня забросил это начинание.
Когда задача не поддается прямым методом, зачастую помогает сделать шаг назад и посмотреть на нее в другой плоскости. А настолько ли необходимо одно большое дерево со всеми страницами? Как им пользуются, какую информацию оно позволяет получить? Поговорив со знакомыми, я получил несколько ответов, которые примерно укладывались в две группы:
- Общий обзор: это когда хочется посмотреть на всех сразу и почувствовать себя частью чего-то большого. Неожиданно, но для некоторых пользователей структурированность информации в этом представлении не особо важна: с высоты птичьего полета схема воспринимается не как дерево, а как облако тегов, с ориентацией по фотографиям. С этой задачей текущая реализация дерева справляется.
- Поиск связи: нахождение пути от одного члена семьи до другого. Тут запутанная карта действительно мешает, но люди, как правило, интересуются довольно определенными типами маршрутов. За счет оптимизации под эти типовые маршруты можно сделать представление более наглядным.
Итого: можно сделать несколько «срезов» дерева, представляющих частичную (и потому более наглядную) информацию. Срезов поддерживается три:
Все предки
Самый простой срез: рекурсивно показать биологических родителей, затем их родителей и так далее. Дерево приобретает вид перевернутой пирамиды.

Все потомки
Отображает детей, их детей, и так далее, а также супругов, являющихся вторым родителем для каждого ребенка. Дерево приобретает вид вертикальной колонны или пирамиды, в зависимости от количества детей.

Близкие родственники
Отображаются страницы в радиусе «двух шагов» от текущей, то есть от бабушек до внуков.
С этим срезом было больше всего трудностей:
- Некоторые страницы за пределами радиуса все равно надо включать: например, в случае с единоутробными братьями расстояние до родного отца брата будет равно 3, но его все равно нужно отобразить. Это вызвано ограничением механизма отображения дерева, который требует либо обоих родителей, либо ни одного.
- Некоторые страницы в пределах радиуса, наоборот, отображать нерезонно: например, расстояние от человека до нового мужа его бывшей жены равно 2, но этот человек скорее всего не входит в понятие «близкой семьи».
Радиус из двух шагов не является идеальным. Например, я знаю случаи, когда благодаря молодым родителям ребенок может проводить много времени со своими пра-бабушками, которые не попадают в радиус (false negative). С другой стороны, увеличение радиуса до трех шагов сильно раздувает граф, в него попадет много лишних людей (false positives), и время рендеринга графа ощутимо увеличивается, поэтому число 2 выбрано в качестве разумного компромисса.
План на будущее: проэкспериментировать с более сложными критериями, например пересечение по времени жизни, назначение различных весов для разных типов связей и тому подобное.
Типы деревьев можно включить по одному на странице настроек. У себя я отключил полное дерево и включил три частичных:

Экспорт дерева
Теперь дерево можно отобразить в полноэкранном режиме или в отдельном окне. Таким образом его можно легко экспортировать, например, используя браузерные плагины для создания скриншотов или встроенный функционал экспорта страницы в PDF.
Новый функционал админки
Тут стоит сразу оговориться, что сделать максимально навороченную админку не является целью проекта. Основная цель — сохранение данных на протяжении десятилетий. Для этого проект придется переписывать полностью раз в 15-20 лет, и чем больше всякой дичи в него накручено, тем сложнее это будет сделать. Любой новый функционал должен быть либо тривиально реализуемым, либо давать моментальную ощутимую пользу по сравнению с затратами на разработку.
Тем не менее, главная страница админки была кардинально переработана и теперь представляет собой список показателей и ленту истории:

У страниц теперь считается «процент заполненности». Для разных типов страниц он складывается из разных полей, список которых отображается при наведении:

Ссылка «N можно улучшить» под числом страниц на главной сортирует их, начиная с наименьшего процента заполненности. Так можно легко определить, какие страницы требуют доработки, а какие уже готовы.
Аналогично, ссылка «N без отметок» под количеством медиа-файлов предлагает добавить отметки на фото и видео, где они отсутствуют.
В редакторе текста теперь можно легко добавлять ссылки на другие страницы, используя символ @ по аналогии с тем, как это сделано в Github:

Новый функционал клиентской части
В той части, которая доступна читателям, также появилось несколько небольших улучшений:
Ссылки на эту страницу
На отдельной вкладке показываются все страницы, которые ссылаются на данную:

Профили в соцсетях
Для страниц можно указывать ссылки на социальные сети. Поддерживаются Twitter (который теперь X), Одноклассники, VK, Telegram, Youtube и Github, а также соцсети-которые-нельзя-называть.

Что дальше?
Можно сказать, что разработка вышла на некое спокойное плато: проектом уже давно можно комфортно пользоваться, новый функционал добавляется без фанатизма, большинство возникающих багов тривиальны и исправляются за полчаса.
Это позволяет оглянуться назад и сделать выводы: архитектура проекта оказалась верной и прошла проверку временем. В предыдущих моих проектах рано или поздно появлялось тянущее чувство, что очень лакомую фичу X не получится реализовать (или, что еще хуже, поправить баг) без полного переписывания, но в этот раз такого нет.
В первой статье в 2019 году я рассказывал, что изначально хотел сделать базу полностью формализованной, чтобы позволить находить в ней ответы на конкретные вопросы вида «какая марка была у первого автомобиля моего деда», но отказался от этого подхода в пользу неструктурированного текста, надеясь на развитие нейросетей. Это ставка тоже оправдалась: ChatGPT уже отлично отвечает на вопросы по скормленному ему тексту. Думаю, что в течение всего пары лет этот функционал будет встроен в браузер и он сможет сам переходить по страницам, чтобы найти нужный ответ.
Общие планы на дальнейшую разработку такие:
- Добавить возможность иметь несколько способов авторизации для одной учетки
- Реализовать поиск по медиа-файлам наряду с поиском по страницам
- Исследовать альтернативные способы рисования дерева (возможно, получится-таки заставить GraphViz генерировать желаемое представление?)
- Сделать мобильную версию для читательской секции (не для админки)
- Планомерно обновлять проект по мере выхода новых версий .NET
Стоит ли переводить приложение на другие языки? Однозначного ответа у меня нет. С одной стороны, это (теоретически) позволило бы большему числу пользователей воспользоваться проектом и, возможно, присоединиться к разработке. С другой стороны, это огромный пласт работы: для полноценной локализации нужно будет не просто перевести строки, но учесть культурные различия в типах родственных связей, добавить поддержку RTL и тому подобное. А что делать с самими страницами? Пока что склоняюсь к мысли, что лучшим решением тут будет, опять же, функция автоматического перевода, встроенная в браузер. Так или иначе, время покажет.
Где попробовать?
Репозиторий проекта, с документацией и инструкцией по установке:
https://github.com/impworks/bonsai
Развернутый демо-инстанс, на котором данные сбрасываются каждые 15 минут:
https://bonsai.kirillorlov.pro/
Если вы пользуетесь проектом, напишите мне. Буду рад любой обратной связи!
One more thing...
В 2020 году от Bonsai отпочковался проект Isotope, заточенный под ведение фотогалереи. На отдельную статью историй не наберется, но все же он стоит отдельного упоминания.

В первую очередь оказалось, что мне привычнее всего систематизировать фотографии в виде вложенных папок и тегов, а в Bonsai страницы для этого тяжеловесны и не имеют иерархии. Кроме того, отсутствие обязательств по долгосрочной поддержке позволило использовать современный SPA, сделать вменяемую мобильную версию и продвинутую админку. Некоторые эксперименты, изначально проверенные там (работа с SQLite, самопальный планировщик задач), были портированы обратно в Bonsai.
Проект также полностью открытый и бесплатный. Если кому-то понравится — пользуйтесь на здоровье!
Only registered users can participate in poll. Log in, please.
Ваше мнение
7.32% Я уже пользователь3
39.02% Планирую установить себе16
36.59% Сомнительно, но окэй15
17.07% Я это не понимаю, мне это не интересно7
41 users voted. 12 users abstained.
