В мае 2021 года ваш покорный слуга выступил на Codefest c докладом про интеграции и связанные с ними трудности. Поездка на эту конференцию запомнилась сразу несколькими вещами. Во-первых, было чертовски приятно выступить оффлайн — организаторам и участникам большой респект! А во-вторых, ни одна компания из тех, где я раньше работал, не поддерживала так сильно своих спикеров, как это делает Каруна. И где, как не в блоге компании, публиковать расшифровку доклада.

Всем привет! Меня зовут Алексей Мерсон. Сегодня мы поговорим про то, почему интеграции для разработчика — это боль, и как эту боль уменьшить. Немного о себе: я работаю архитектором в компании Каруна, а в целом в разработке около 20 лет. За это время через мои руки прошло больше десятка проектов. И почти все они так или иначе были про интеграции. Более того, несколько лет я работал в отделе, который так и назывался: отдел интеграционных проектов. Ну и раз мы говорим про интеграции, давайте начнем с определения.
В общем смысле интеграция — это объединение частей в единое целое. А в контексте разработки — это взаимодействие с каким-либо внешним сервисом для того, чтобы реализовать какую-то функциональность. Определение предельно простое. Так что, получается, что интеграция — это просто?

Да, интеграция — это просто. Так же просто, как кататься на велосипеде. Который горит, и всё горит, ну вы в курсе этого мема. Давайте разберёмся, почему так, и что с этим делать.
Представим, что мы разрабатываем некую систему (приложение, сервис, whatever) и никакой интеграции нет. Прелесть этой ситуации в том, что всё находится под контролем нашей команды, то есть только команда решает, что разрабатывать, как, по какой архитектуре, какие фичи делать и так далее.

Но как только появляется взаимодействие с внешним сервисом, тут же появляется и незримая граница. И вот за пределами этой границы мы уже не имеем прямого влияния на то, что происходит. И остаётся только искать обходные пути либо подстраиваться под внешние реалии.

Именно в отсутствии контроля и заключается источник всех бед в интеграциях. Но с этим мы ничего сделать не можем, это фундаментальная проблема. Поэтому нам остаётся только бороться со следствиями этого факта. Способов борьбы много, но сегодня мы поговорим про три: это адаптация, тестирование и изоляция.
Адаптация
Какие проблемы решает адаптация?
Изменения. Причем как изменения во внешнем сервисе, от которых мы хотим изолироваться, чтобы эти изменения влияли на наше приложение, так и изменения в нашем приложении. Но тут цель обратная: мы хотим иметь свободу внесения изменений, не ломая интеграцию.
Разные модели. С точки зрения Domain Driven Design доменные модели нашего приложения и внешнего сервиса лежат в разных контекстах (Bounded Context). Значит, для взаимодействия между этими моделями понадобится некий слой адаптации, который в DDD называется Anti-Corruption Layer.
Разные технологии. Сервисы могут быть построены на разных стеках, разных технологиях, которые могут быть несовместимы напрямую.
По сути адаптация — это классический паттерн «адаптер». Но часто его понимают в слишком узком смысле, то есть как класс SomethingAdapter, который принимает что-то на вход и отдаёт что-то на выход. Но я предлагаю взглянуть на него шире, не ограничиваясь кодом приложения. И сейчас я приведу пример, как мы на одном из проектов использовали паттерн «адаптер». Пример будет про XML и XSLT.
И все такие щас: «Чувак, серьезно, XML в 2021м?».

Но на это я могу сказать вот что: есть как минимум два типа компаний, для которых XML по-прежнему дорог и близок. Во-первых, это компании, которые занимаются интеграциями с государственными сервисами или не дай бог сами их пишут.

А во-вторых, это все, кто путешествуют на прекрасном сверхсветовом корабле под названием Enterprise.

Время там, как известно, течёт по-другому, и пока в обычном мире рождаются и умирают сотни JS-фреймворков, в энтерпрайзе, скажем, до сих пор используют Cobol. При том, что на нём и до ковида было не густо с разработчиками.
В общем, XML. Только не надо вчитываться в следующий скриншот, он здесь для иллюстрации масштаба проблемы.
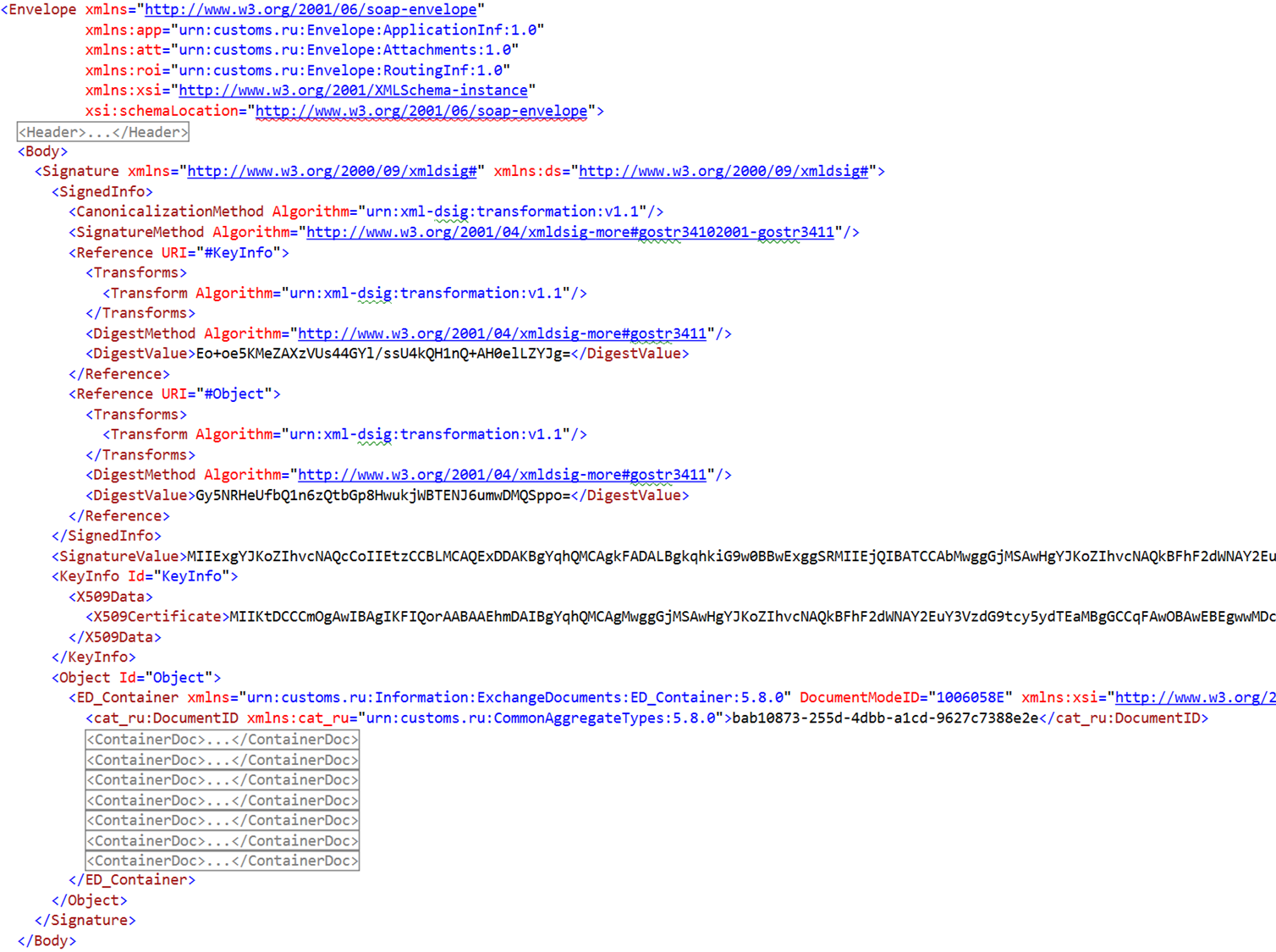
Тем не менее, это реальный XML в формате SOAP Envelope с цифровой подписью, который использовался для информационного обмена в одном из государственных ведомств. Смысл здесь в том, что нас с точки зрения бизнес-логики интересует только этот блок.

Всё остальное — это инфраструктурная часть, которая нужна только в middleware, но из-за нее нам очень больно десериализовывать такой XML. Причём всё еще хуже, потому что подписывается не только корневой документ. Он может содержать вложенные документы, которые точно также подписываются цифровой подписью, и нас точно так же интересует только часть документа.
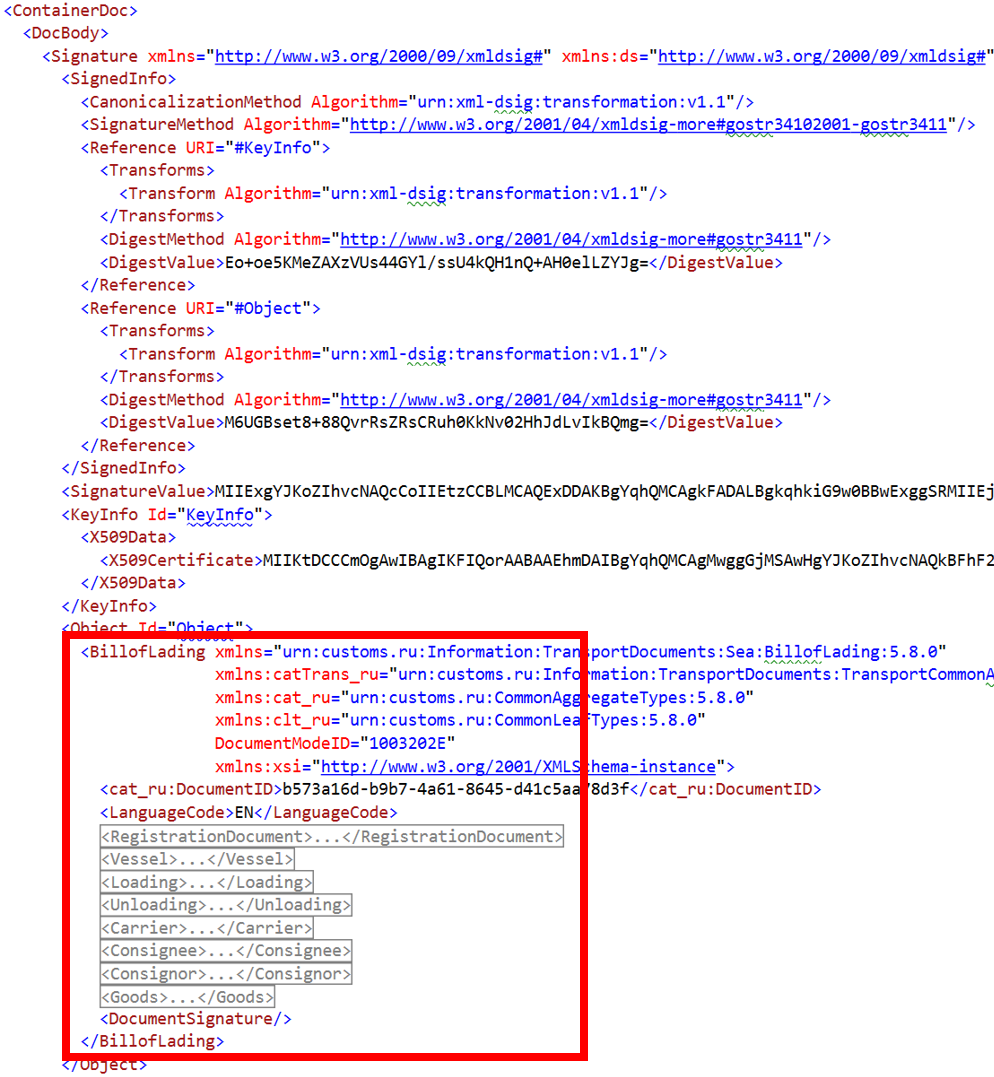
Можно было написать кучу некрасивого кода, заморочиться и порешать эту проблему в коде. Но мы поступили проще. Мы написали вот такое XSLT-преобразование.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:sig="http://www.w3.org/2000/09/xmldsig#">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes"/>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="sig:Signature">
<xsl:apply-templates select="./sig:Object/*" />
</xsl:template>
</xsl:stylesheet>После того, как мы накатываем это преобразование на исходный XML, всё, что связано с цифровой подписью, уходит обратно в ад, откуда оно пришло. Казалось бы, можно праздновать победу, но нет. Здесь еще куча пространств имён (namespaces).

Пространства имён — это тоже большая боль при десериализации. Причём если бы они никогда не менялись, мы бы один раз прописали их в маппингах в коде и на этом успокоились. Но у некоторых из них есть версия, и версия эта довольно часто меняется.

И каждый раз при смене версии нам бы пришлось менять её в коде, пересобирать, деплоить. Что мы сделали? Написали ещё одно XSLT-преобразование.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="no"/>
<xsl:template match="/|comment()|processing-instruction()">
<xsl:copy>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template>
<xsl:template match="*">
<xsl:element name="{local-name()}">
<xsl:apply-templates select="@*|node()"/>
</xsl:element>
</xsl:template>
<xsl:template match="@*">
<xsl:attribute name="{local-name()}">
<xsl:value-of select="."/>
</xsl:attribute>
</xsl:template>
</xsl:stylesheet>И после того, как мы применяем его к этому документу, пространства имён отправляются вслед за цифровой подписью. Остаётся прекрасный простой XML-документ, который элементарно мапится на обычные POCO-классы, десериализуется, и мы можем легко работать с ним в коде.
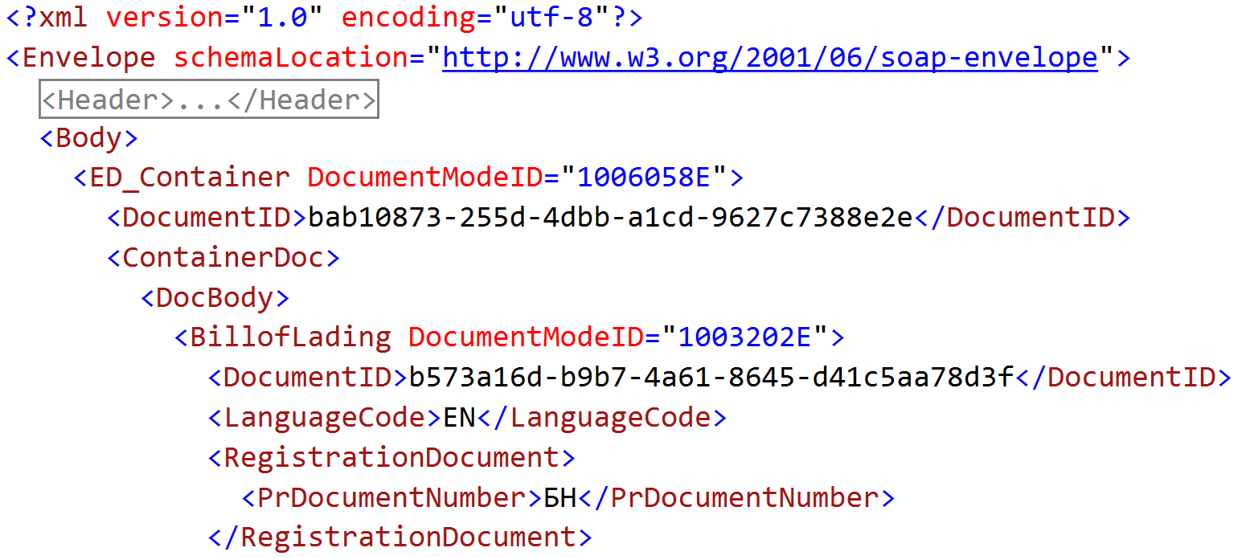
Таким образом, применение паттерна «адаптер» в нашем случае свелось просто к последовательному применению XSLT-преобразований к входящим XML-кам.
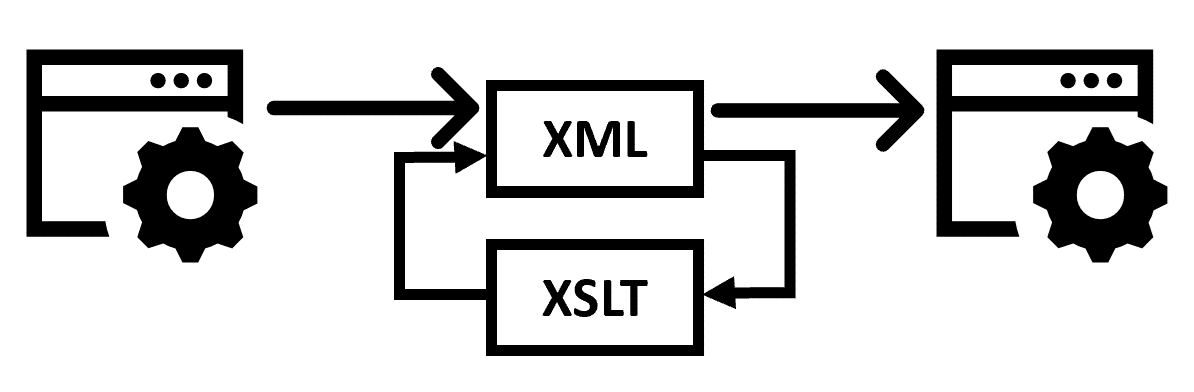
Этим мы сделали себе жизнь сильно проще, и XML, который приходил в совершенно неудобном виде от внешней системы, мы преобразовали к виду, который удобен нам. Именно в этом и заключается смысл адаптации.
Тестирование

Какие проблемы решаются тестированием стороннего сервиса?
Ошибки реализации. Внешние сервисы делают такие же люди, как и мы. А значит они тоже делают ошибки, в сервисах бывают баги. И мы хотим об этих багах узнать раньше, чем нам о них расскажут клиенты нашего сервиса, которые заведут злобные тикеты в поддержку. Поэтому внешний сервис надо покрывать тестами, которые нам расскажут о том, что есть какие-то проблемы.
Нестабильность. Я видел много разных сервисов. Часто сервисы могут то работать, то не работать. А некоторые сервисы даже не работают бОльшую часть времени. И очень хорошо бы иметь тесты, которые будут нам говорить, жив сейчас сервис или нет, причём тесты эти очень желательно запускать регулярно. Мы тогда не только получим информацию, жив ли сервис в данный момент, что нам может быть важно для диагностики каких-то текущих проблем. Но и получим статистику, с которой можно будет уже предметно разговаривать о стабильности с вендором сервиса.
Внезапные изменения. Это почти как первый пункт, только это не баг, а фича. Часто вендоры сервисов могут запилить какую-то фичу и ВНЕЗАПНО забыть рассказать о том, что они собирались это сделать. А эта фича может ломать нашу бизнес-логику. Поэтому опять же тесты, которые запускаются и проверяют, что все работает так, как мы ожидаем, расскажут нам заранее об этой проблеме.
Вот так было построено тестирование на одном из проектов.

TFS раз в сколько-то времени запускает коллекцию тестов в Postman. Postman пробегается по коллекции и выполняет каждый тест, который по сути представляет из себя запрос и ассерты на ответ. Соответственно, получается статистика, что прошло, что упало. Статистика отправляется в Report Portal. Report Portal — это опенсорсный продукт и отчёт в нём выглядит как-то так.
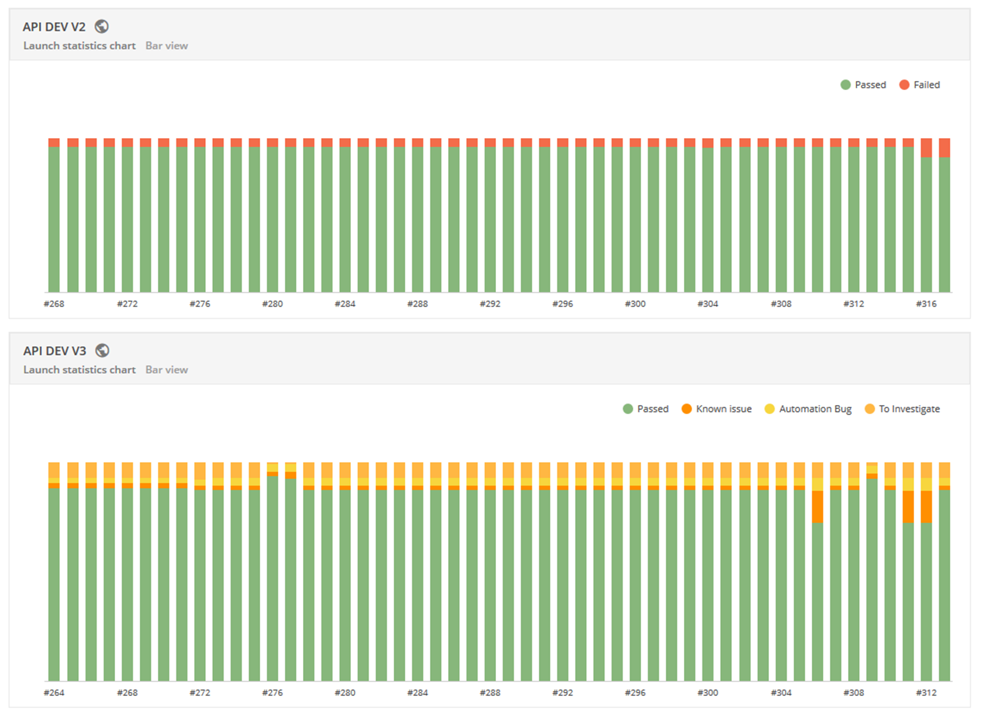
То есть мы получаем красивый график. На каждый запуск мы видим, сколько тестов прошло, сколько упало. Мы можем видеть динамику, что проблемы нарастают или наоборот. Плюс он использует ML, чтобы подсказать, какие проблемы уже встречались раньше (и на их исследование не нужен тратить время), а какие — новые, внезапно появившиеся.
Изоляция

Зачем нам может понадобиться изоляция от стороннего API, какие проблемы это решает? На самом деле ровно те же, что и тестирование, только с другого конца. Когда мы говорили про тестирование, мы говорили, что хотим узнать заранее о проблемах, которые возникли на удаленном сервисе. Здесь же мы, наоборот, хотим тестировать своё приложение и не задумываться о тех проблемах, которые могут возникнуть на удалённом сервисе. То есть мы хотим тестировать приложение в детерминированных условиях, когда мы можем быть уверены, что, если что-то пошло не так, оно пошло не так, потому что проблемы у нас, а не на удалённой стороне. Чтобы это сделать, нам нужно заменить внешний сервис стабами (stubs).
Детали реализации зависят от конкретной платформы, но в общем способов можно предложить три:
подменить сторонний сервис целиком;
закэшировать ответы сервиса;
сделать заглушку в своём коде.
Подмена сервиса
Это когда мы делаем какую-то упрощённую реализацию сервиса. То есть контракты она реализует такие же, как реальный сервис, но внутри устроена как-то по-простому. Или не по-простому, но так, как нам нужно для наших тестов, так чтобы наши тесты позволяли протестировать нашу логику. Сложность здесь в том, что если мы делаем замену внешнему сервису, то, значит, его надо написать, куда-то задеплоить, нужна инфраструктура, нужны усилия девопсов. Так что этот способ достаточно трудоёмкий, но зато он самый гибкий и самый прозрачный с точки зрения приложения, т.к. в этом случае оно ничего не знает про подмену.
Кэширование
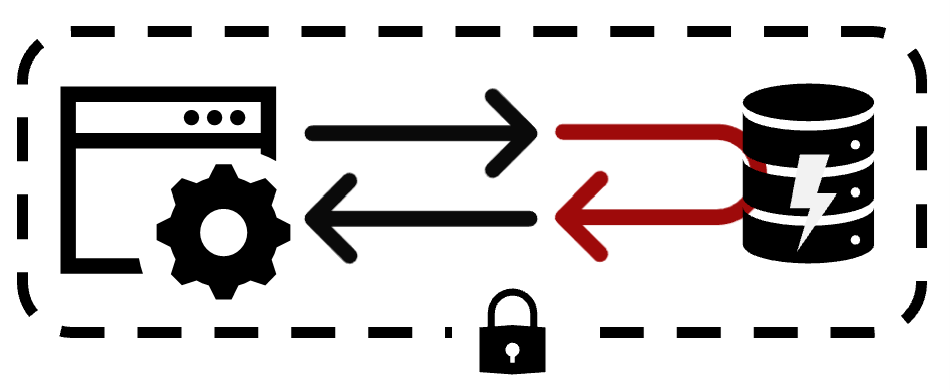
Мы просто между внешним сервисом и нашим ставим кэш, который на конкретный запрос отдаёт предустановленный ответ. Для простых сервисов типа курсов валют это хороший способ, потому что нам скорее важно получить ответы в правильном формате, чтобы наша логика смогла их обработать. Какой именно курс пришёл, нас, наверное, не сильно волнует с точки зрения тестов нашей системы. Но если ситуация чуть-чуть сложнее, то всё, никакой логики мы сюда добавить не можем, т.к. это по сути key-value storage.
Заглушка в коде
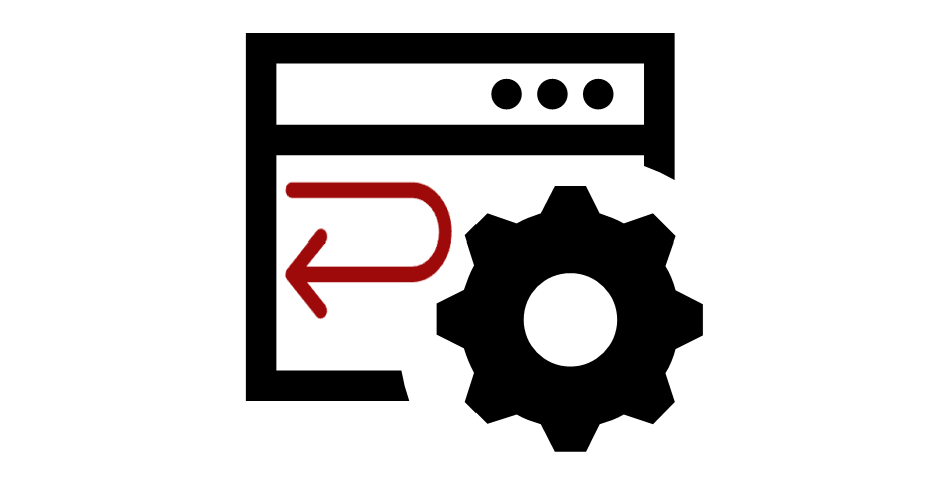
Это такой компромиссный вариант. Что здесь имеется в виду: мы встраиваемся в middleware приложения и где-то делаем «короткое замыкание». То есть реквест не отправляется вовне, а заворачивается на какой-то внутренний код, который генерирует и возвращает ответ. В частности, на одном из .NET-проектов мы использовали для этих целей HttpClient. В этом случае все интеграции шли через HttpClient, и для тестовых запросов он вместо честного вызова внешнего сервиса шёл в стабы и возвращал ответ на основе тестовой логики.
Ещё одна вещь помимо стабов, которая нам нужна для изоляции — это тестовые окружения.
Тестовые окружения
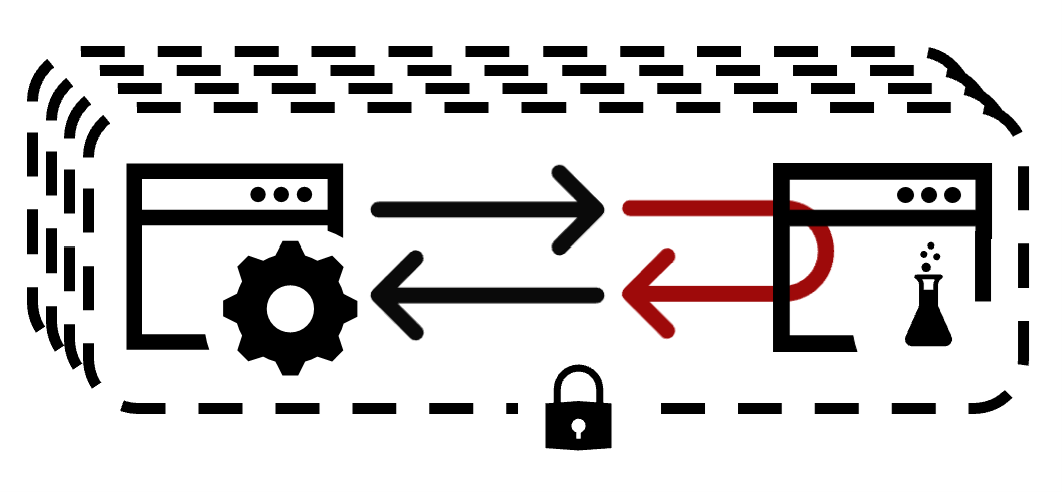
Окружение — это набор всего того, что нужно приложению для работы, то есть данные, интеграции, инфраструктура, деплой. На каждом окружении всё это свое. Разбивать на окружения опять же можно по-разному. В минимальном варианте окружений должно быть два — это production и не production, потому что одна из целей тестового окружения — не затрагивать production, не затрагивать боевых пользователей. Но на одном из моих проектов мы пришли к схеме с четырьмя окружениями, и я хочу немножко подробней о ней рассказать, так как она кажется мне удачной.
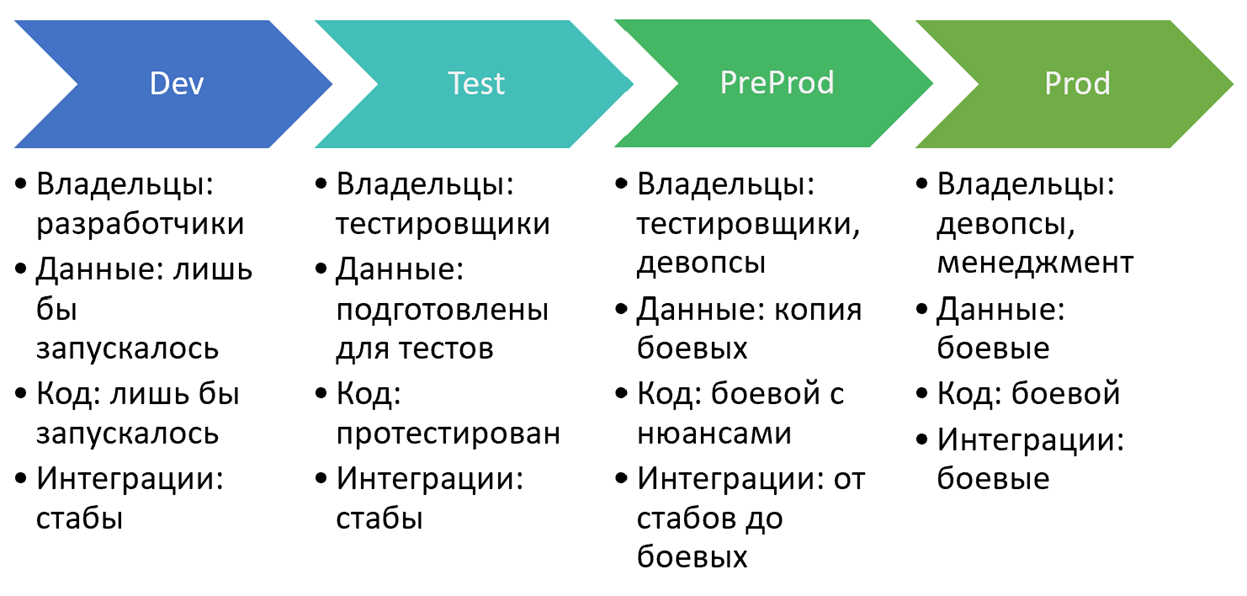
Dev. Владельцы этого окружения — разработчики. Основная задача этого окружения — дать возможность разрабатывать фичи, дать возможность отлаживать код. И ещё одна цель — continuous integration, то есть возможность проверить, что совместная работа нескольких разработчиков не сломала всё, что сборка и тесты проходят. Соответственно, данные на этом окружении могут быть кривые, косые. Главное, чтобы приложение запускалось и позволяло протестировать нужный функционал, который разрабатывается в данный момент. В интеграциях здесь используются стабы, от интеграций нам в этом случае почти ничего не нужно. Главное, чтобы была возможность отлаживаться и проходить свой сценарий. Ну и код — лишь бы запускалось, лишь бы собиралось, то есть билды должны проходить, какие-то автотесты (если есть) должны проходить. Большего мы здесь не ждём.
Если разработка фичи закончена, то код переезжает на Test. Тут уже владельцы — тестировщики. И основная задача этого окружения — прогнать приложение по тестовым сценариям, во-первых, для того, чтобы понять, что функционал реализован правильно, во-вторых, чтобы исключить регресс. Данные здесь максимально статичные, они подготовлены так, чтобы тесты выполнялись и проходили по одному сценарию. Поэтому данные не должны меняться, во всяком случае, не должны меняться без ведома тестировщиков. В частности, поэтому плохо объединять Dev и Test окружения, так как разработчики могут там что-то поменять. Интеграции здесь тоже стабы, которые должны возвращать то, что нужно для тестов. Код на этом окружении готов к тестированию. Если что-то не так, то код допиливается на Dev и снова закидывается на Test. Когда тестирование завершено, код переезжает на Preprod.
Prepod — он почти как Prod, но есть нюанс. В отличие от Prod здесь нет боевых пользователей. Это основное различие: мы должны протестировать приложение в условиях, максимально приближенных к боевым, но не затрагивая реальных пользователей. Поэтому здесь уже в ответственных не только тестировщики, но и девопсы, потому что инфраструктура на препроде гораздо сложнее. На Dev и Test мы можем мириться с недостатком быстродействия, с недоступностью, и так далее. На Preprod мы должны тестировать в боевой конфигурации: если есть какие-то балансировщики нагрузки, то они должны здесь быть; если есть какая-то кластеризация, то она должна здесь быть. Соответственно, интеграции — от стабов до боевых. Что я имею в виду: в идеале, интеграция должна быть с реальным сервисом, но с его не боевой версией. Однако не все разработчики внешних сервисов предоставляют что-либо, кроме боевого варианта. В таком случае мы должны выбрать: либо мы интегрируемся с боевым сервисом, либо используем стабы в зависимости от ситуации.
И наконец если мы успешно закончили тесты на Preprod, код выкатывается на Prod. Здесь уже владельцы — девопсы, менеджеры, в общем все те, кто отвечает за то, чтобы функционал был доставлен пользователям, и они были довольны. Соответственно, код боевой, данные боевые и интеграции тоже боевые.
Ну и прежде, чем продолжить — анекдот.
— А вот мой папа говорит, что приятнее дать, чем получить.
— Он у тебя, наверное, священник?
— Не. Боксер.

Так вот, большинство из нас — боксёры в интеграционном смысле, то есть мы не только пользуемся сторонними сервисами, но и сами предоставляем интеграции. И давайте дальше поговорим о том, какие проблемы возникают у нас, когда мы сами предоставляем какой-то сервис.
На самом деле, в таком случае главная наша проблема — это клиенты. Они вечно чё-то ходят, жалуются, плачут. То мол баги, то фичи выкатываем, не предупредив, а то и вообще якобы сервис у нас лежит. Причём хуже того, клиенты нашего сервиса сами являются разработчиками, поэтому они думают, что знают, как у нас всё написано, и как можно было написать лучше. Что с этой проблемой сделать, можно выразить одной фразой: «Убить нельзя удовлетворить». Вопрос только, куда поставить запятую. Давайте проголосуем. Кто за убить? А кто за удовлетворить? У меня плохая новость для тех, кто выбрал убить. Дело в том, что если убить клиентов, то как бы и сервис не нужен, и его тоже придётся убить. Поэтому остается только удовлетворить.
Как мы можем удовлетворить клиентов? Мы можем решить их проблему, избавить их от боли. Кажется просто, но на самом деле непростая вещь — это разобраться, в чём же проблема. Потому что часто люди ищут, где светлее, а не где потерялось. То есть разработчики пишут то, что интереснее, а не то, что требуется. Иногда это получается так, потому что требования прошли через много рук. Поэтому нужно разбираться, в чём же задача клиентов, и каждому придётся немножко побыть бизнес-аналитиком. Кажется, что нужны отдельные бизнес-аналитики, менеджеры продукта, пускай они разбираются. Но на самом деле они-то в итоге придут к вам, и их требования тоже надо будет понять, поэтому всё равно придётся разбираться. А иногда мы делаем внутренние сервисы, где сами являемся постановщиками задачи, и никто за нас это не сделает.
Ну окей, разобрались с тем, какую проблему решать. Начали разрабатывать сервис. Нам от сервиса нужно три вещи: эффективность, понятность и стабильность.
Эффективность
Всё просто: сервис либо решает проблему, либо нет. Если не решает, то что там с его понятностью и стабильностью, клиентов уже мало волнует. Если же решает, то нужно, чтобы решением смогли воспользоваться. Для этого сервис должен быть понятным, простым в использовании.
Понятность
Первое, что для этого нужно, — стандарты. Нужно придерживаться тех стандартов, которые существуют в индустрии. Не надо изобретать хитро выдуманные типы данных. Не надо делать инновационные схемы организации URL`ов на сервисе. Это запутает. Нужно использовать принцип наименьшего удивления. То есть человек ожидает то, что уже 100 раз видел в других сервисах.
Далее, инкапсуляция сложности. Каждая проблема обладает естественной сложностью, которую решать не хочется, неприятно, и можно отдать на откуп клиентам, а можно инкапсулировать внутри сервиса. Я приведу пример из реальной жизни, так сказать, из наболевшего, но аналогия, я думаю, будет понятна. Всем знакома фраза: «Где карту открывали, туда и идите». Та самая история, когда сложность перекладывается на клиента. Можно было бы порешать это тем, что изменить бизнес-процессы, какие-то юридические вещи, и сделать так, чтобы идти можно было в любой офис. Но тем не менее это перекладывается на клиента. Так делать не надо. Ещё один момент. Если вы отдаете сложность клиенту, то общая сложность решения задачи для всех клиентов будет равна сложности одного клиента умножить на количество клиентов. Если же вы решили её на своей стороне, то множитель будет единица. Вы решили проблему один раз и осчастливили много людей, в пределе — бесконечное количество.
Ну и, наконец, документация. Для любого сервиса документация — очень важная вещь. Причём речь не только о спецификации типа «такой-то метод принимает такие-то параметры, возвращает то-то». Этого недостаточно. Должны быть howto, tutorial`ы, примеры. Может быть, даже автогенерированные прокси-клиенты — в каком-то смысле это тоже документация, потому что она показывает, как работать с сервисом. Давайте теперь я покажу те инструменты, которые мы использовали на моём прошлом проекте, чтобы упростить жизнь клиентам нашего сервиса.
OpenAPI — то, что раньше называлось Swagger, а когда подключились крупные компании, стало стандартом описания RESTful API. По спецификации OpenAPI вы получаете json или yaml, который описывает в декларативном виде весь ваш API. Дальше по нему, в частности, можно сгенерировать Swagger UI. Что такое Swagger UI?
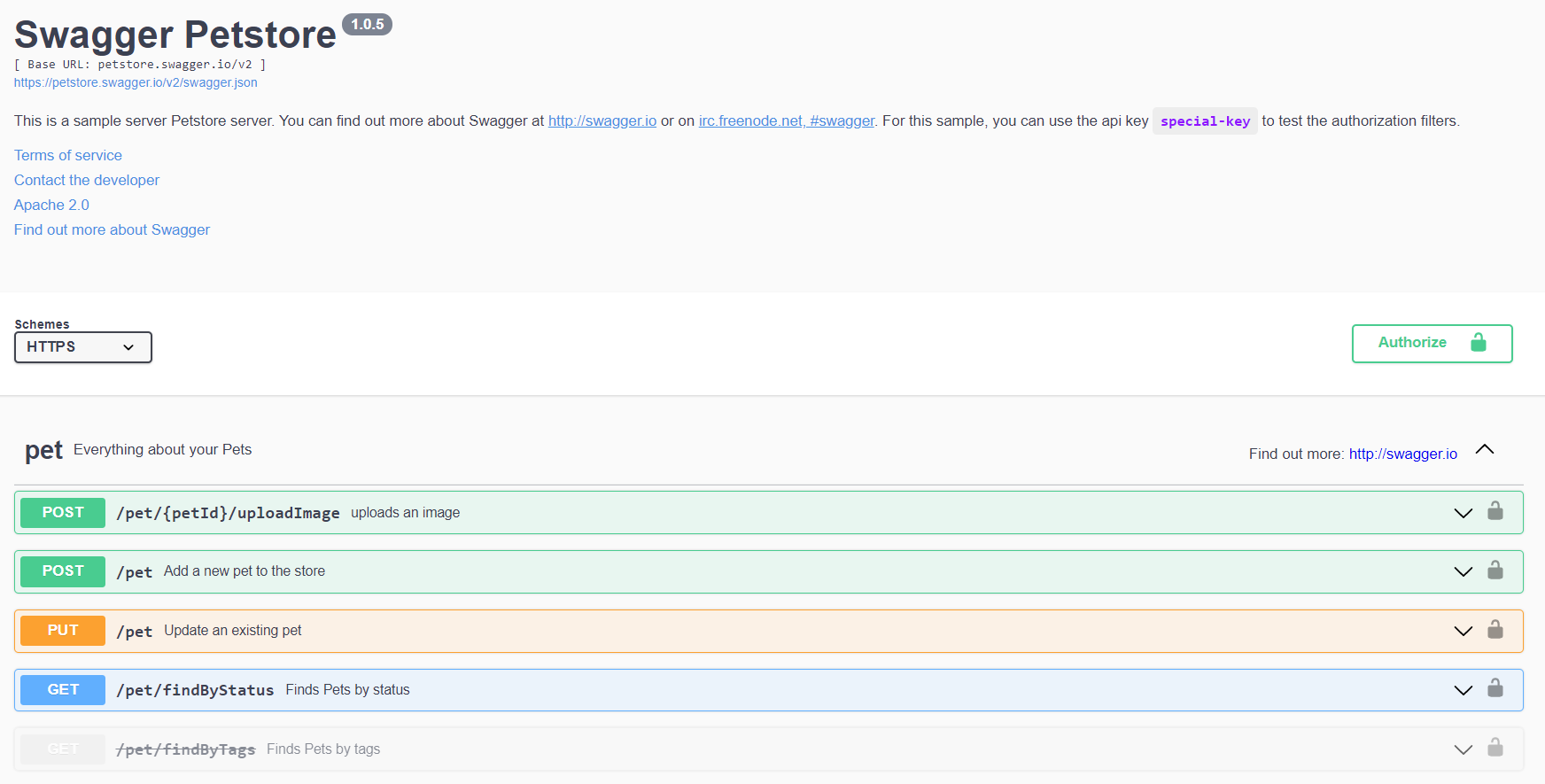
Это страничка вот такого вида, которая обычно хостится как часть самого сервиса или где-то рядом. Вы можете зайти на неё просто из браузера. И, во-первых, она показывает все возможные способы вызова вашего API: все эндпоинты, все методы, все параметры и т.д. Во-вторых, она подтягивает документацию из кода, в частности из xml-комментариев либо из описания API. И третье — она дает возможность прямо на месте этот API подёргать. Вам не нужно никаких клиентов, никакого постмана, никакого кода писать. У вас есть возможность прямо на месте вызвать API, это очень удобно. На самом деле возможностей больше, но ключевыми мне кажутся эти три.
Для автогенерации клиентов к API мы использовали NSwag. NSwag — набор утилит, который позволяет вам уже в .NET-приложении получить все прелести в виде OpenAPI спецификации и SwaggerUI. В этот набор входит приложение NSwagStudio, которое позволяет взять спецификацию OpenAPI и настроить по ней генерацию клиента на C#/TypeScript для вашего API, чтобы дальше этот прокси-класс использовать в ваших приложениях.
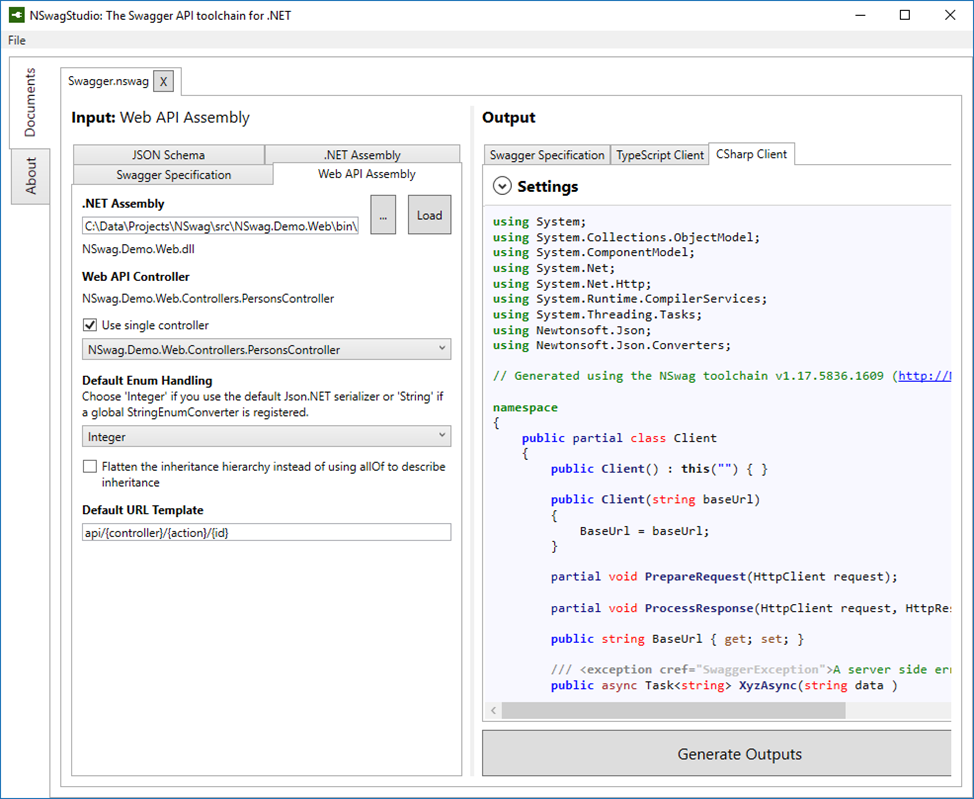
Причём настройки генерации сохраняются в файл с расширением nswag, и вы можете его добавить себе в проект. После чего с помощью дополнения к студии под названием REST API Client Code Generator вы можете правой кнопкой щёлкнуть на этом файлике и сказать Generate Output, затем рядом с nswag-файлом у вас появится прокси-клиент.
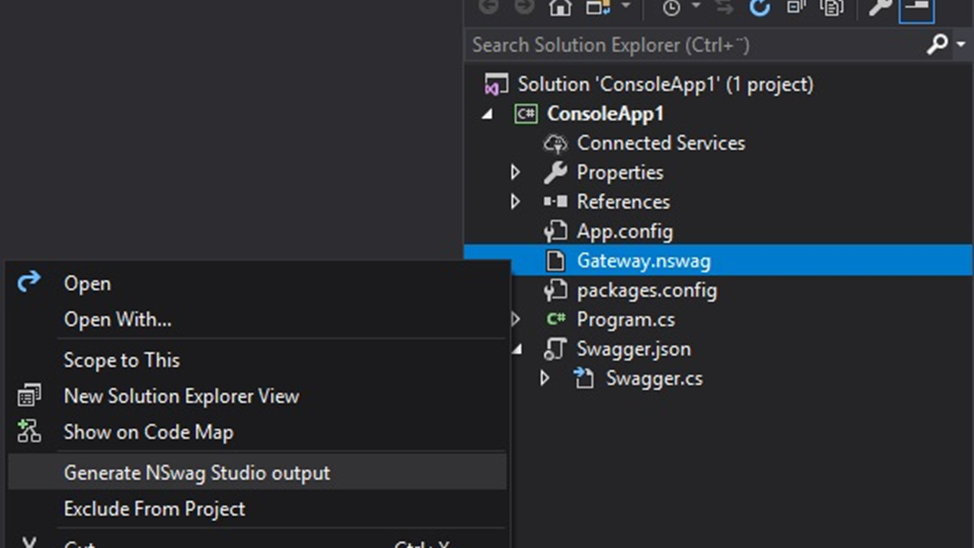
Забавный факт, что этот эддон требует для работы джаву.
Стабильность
Окей, поговорили про понятность, давайте теперь про стабильность. И на самом деле первые два пункта здесь такие же, как в клиентской истории, потому что если вы хотите обеспечить стабильность своего сервиса, вовремя обнаруживать баги, то вам нужно стать клиентом для своего сервиса. Надо будет написать тесты — всё, как я рассказывал в первой части доклада. И, кстати, не забудьте развернуть тестовые инстансы вашего сервиса для использования в клиентских тестовых окружениях.
Но есть третий момент, о котором часто забывают или просто не хотят думать: это версионирование. Версионирование — мегакритичная штука для API, которое вы делаете. Версионирование даёт вам свободу развивать сервис, не затрагивая имеющихся клиентов. То есть, захотели вы сделать breaking changes, захотели переделать всё с нуля — не важно, окей. Вы делаете версию vNext, в которой всё переделываете, а пользователи продолжают пользоваться версией vOld, и у них все хорошо. Дальше вам не нужно назначать единственный день икс, в который всем обязательно нужно переключиться со старого API на новый. Вы просто говорите, что вы собираетесь зарелизить версию vNext, версия vOld будет работать ещё столько-то, скажем год. Через год у вас всё равно будет толпа недовольных клиентов, которые не ожидали отключения (ну как снег в декабре идёт неожиданно для коммунальных служб). Но тем не менее у вас уже будет аргумент, что был целый год на переезд на новую версию. Да и бОльшая часть клиентов этим годом воспользуется продуктивно и всё-таки переедет. Как было реализовано версионирование на моём прошлом проекте:
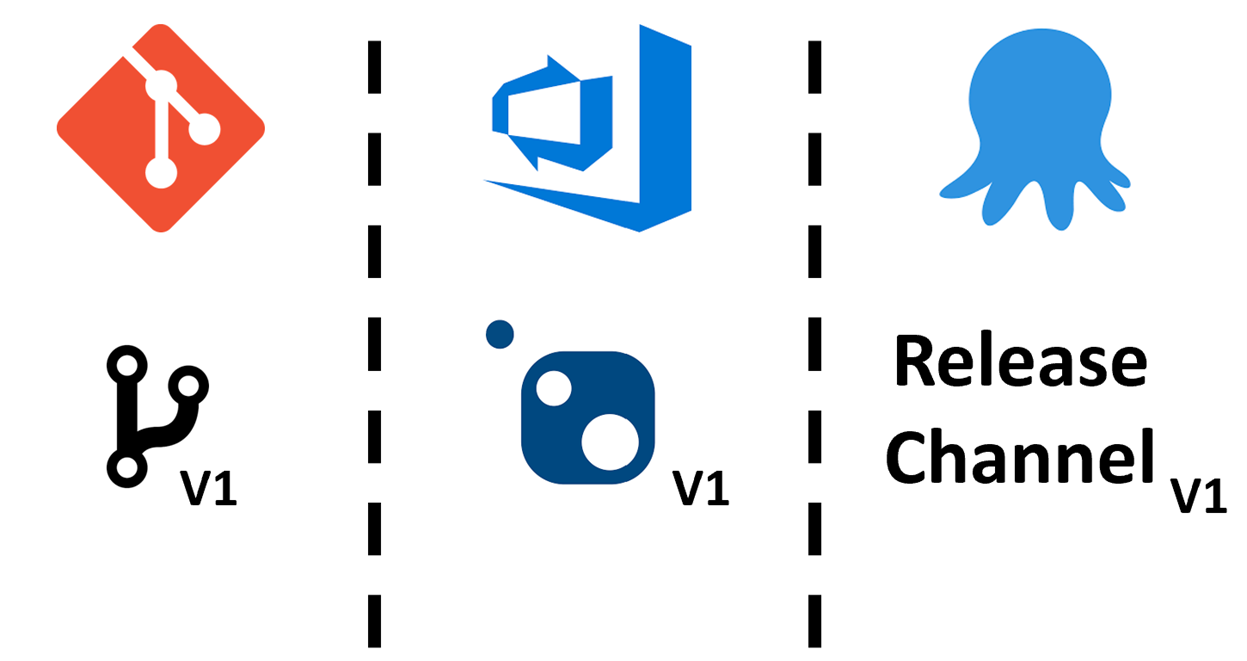
В гите под каждую версию сервиса есть своя ветка. По каждой такой ветке на build-сервере собирается nuget-пакет соответствующей версии. В Octopus есть такая фича как release channels. В release channel можно настроить фильтр по версиям, то есть вы можете сказать, что данный release channel принимает, скажем, только версии 1. Тогда он будет деплоить только версии 1.*. А в конфигурации release channel прописано, куда деплоить, на какой endpoint. Поэтому все пакеты с версией 1 будут попадать на endpoint v1, с версии 2 — на v2, и так далее. Это очень удобно.
Давайте подведём итог
Если мы клиенты интеграции, то все наши беды от потери контроля, от того, что мы не можем, например, сами что-то взять и пофиксить. У нас нет прямого контроля над внешним сервисом. С этим фактом мы ничего сделать не можем, но можем подстроиться и решить проблему с нашей стороны. А именно:
изолировать изменения в адаптерах, чтобы избежать влияния изменений на нашу бизнес-логику;
тестировать интеграции, чтобы вовремя обнаружить проблемы в работе сервиса или же наоборот обнаружить, что мы неправильно представляли себе логику работы сервиса;
тестировать наш код в изоляции от внешних сервисов, чтобы исключить побочные эффекты;
использовать тестовые окружения, потому что тестировать на проде — это зло.
Если же вы сами пишете сервис, то все ваши беды уже от клиентов. Но ничего с этим сделать опять же нельзя, потому что, как мы выяснили, если убить всех клиентов, то как бы и смысла в сервисе нет.
Поэтому начинаем с того, какую боль клиентов сервиса мы решаем. Очень много проблем случается, когда разработчики пишут то, что им бы хотелось, а не то, что нужно клиентам. Это весело, круто, но, к сожалению, бесполезно.
Пишите документацию, сейчас есть куча инструментов, которые позволяют автоматически подтягивать её из кода. Также пишите howto, tutorial`ы, то есть подумайте о том, как человек с нуля воспользуется вашим API. Есть, кстати, такая метрика — time-to-hello-world, то есть время, которое нужно человеку потратить на изучение инструмента, чтобы написать hello world. Чем оно меньше, тем лучше. Если hello world занимает пару месяцев, то, наверное, что-то с сервисом не так.
Пишите тесты, чтобы первыми узнать, что у вас есть проблемы в работе сервиса. Не забывайте про тестовые версии сервиса для клиентских тестовых окружений.
Используйте версионирование: это помогает развивать сервис, не затрагивая имеющихся клиентов.
И если всё это применять, то, конечно, велосипед не превратится автоматически в теслу, но поездка на нём может стать гораздо приятнее и комфортнее.

