В 2023 году, в эпоху взрывного роста нейросетей, вся IT-отрасль продолжает давать кандидатам в стажёры (и не только) домашние тестовые задания. Компании тратят время на то, чтобы придумать эти задания, студенты тратят время на то, чтобы их сделать, потом компании снова тратят время на проверку… В этой небольшой заметке я продемонстрирую, что все задачи последних лет решаются за несколько минут при использовании нейронки, доступ к которой может получить каждый.

Я возьму тестовые задания на Python, C++, Go и C# и буду использовать только открытые источники, убрав названия компаний и прямые ссылки, чтобы исключить любые подозрения в предвзятости.
А в качестве нейронки использую ChatGPT Plus (GPT 4). Она всё еще очень глупа, много выдумывает и постоянно смешно ошибается, но как раз для таких задач годится хорошо.
И да, вместо дисклеймера. Если вы хоть немного успели «посотрудничать» с ChatGPT, то статья может показаться вам глубоко капитанскоочевидной (она такая и есть, безусловно). Но если вы вместо хайпа по нейронкам предпочитаете работать, то у вас нет времени на такие развлечения. Так что, возможно, несколько минут, которые вы сейчас потратите на прочтение, сэкономят вам много часов инвестиций в «ненастоящих стажеров» и «ненастоящих джунов». И соответственно, помогут не наделать ошибок при найме.
Скорее всего, все ваши задания решаются нейронкой.
Если вы думаете, что ваше задание слишком комплексное, чтобы его могла сгенерировать нейронка, смотрите:
- Сервис — генератор случайных значений — GO — сервис и докер для него
- Клиент-серверный пинг понг — С++ — два бинарника с доптребованиeм, cmake
- RSS feed reader
Если вы думаете, что уникальность (вы сами его придумали) задания, обеспечивает его нерешаемость нейронкой, смотрите:
Задачи
Число вхождений массива в подмассив — Python
На вход программе подаются два массива целых чисел, разделённых пробелом. Необходимо найти число вхождений второго массива в первый. То есть посчитать, сколько раз последовательность чисел второго массива (без перестановок) встречается в первом.
Данное задание можно решить различными способами, но одним из наиболее простых и наглядных является использование простого алгоритма, который проходит по всем элементам первого массива и сравнивает их с элементами второго массива. Вот пример решения на Python:
def count_subarray(array1, array2):
count = 0
len2 = len(array2)
for i in range(len(array1)):
if array1[i:i+len2] == array2:
count += 1
return count
# Пример использования
array1 = [1, 2, 3, 1, 2, 3, 4, 1, 2]
array2 = [1, 2, 3]
print(count_subarray(array1, array2)) # Выведет 2Этот код создаёт функцию count_subarray, которая принимает два массива в качестве аргументов. Функция инициализирует счётчик вхождений count значением 0. Затем она проходит по всем элементам array1 и сравнивает подмассив длины array2, начинающийся с текущего элемента, с array2. Если они равны, увеличивается счётчик count. В конце функция возвращает значение count, которое представляет количество вхождений array2 в array1.
Обратите внимание, что данный подход будет работать для неотсортированных массивов, поскольку мы ищем точные последовательности чисел.
Итог: ответ верный.
Каноничный путь UNIX — Python
Дана строка, которая является абсолютным путем к файлу или директории в системе Unix.
Нужно упростить эту строку до каноничного пути.
Каноничный путь — это тот путь, который будет максимально простым и строгим, а именно:
- Путь начинается с единичного слеша /
- Любые две директории разделяются одиночным слешем
- Путь не может оканчиваться слешем /
- Путь может содержать только истинные директории к нужному файлу (то есть в пути не может быть '.' или '..')
На вход подается путь к файлу или директории в системе Unix.
На выходе ожидается каноничный путь.
Пример:
абсолютный путь: /home/abc/../abc/file.txt
каноничный путь: /home/abc/file.txt
Программа должна возвращать упрощенный каноничный путь до файла или директории
Sample Input:
/../
Sample Output:
/
Задача может быть решена с помощью стека. Мы проходим по каждому компоненту пути (директории или файлу), разделяя строку по слешам. Если текущий компонент — это "..", то мы выходим из последней директории (если она существует). Если текущий компонент — это "." или пустая строка, мы пропускаем этот компонент. Иначе, мы входим в данную директорию (добавляем её в стек). В конце, стек содержит каноничный путь, который мы объединяем в одну строку.
def simplify_path(path):
path_parts = path.split("/")
stack = []
for part in path_parts:
if part == "..":
if stack:
stack.pop()
elif part and part != ".":
stack.append(part)
return "/" + "/".join(stack)
# Пример использования:
print(simplify_path("/home/abc/../abc/file.txt")) # Выведет: /home/abc/file.txt
print(simplify_path("/../")) # Выведет: /
Обратите внимание, что этот подход работает только для абсолютных путей и не обрабатывает относительные пути. Если вам нужно обработать и относительные пути, вам понадобится дополнительная логика для обработки таких ситуаций.
Итог: На мой взгляд решение хорошее, все условия соблюдены.
Определение частоты встречаемости IP адресов — Python
Дан лог сервера, который содержит логи операций с машинами. Для идентификации машин используются IPv4 адреса.
Нужно определить частоту встречаемости IP адресов.
На вход принимается лог.
На выходе ожидается список адресов с количеством упоминаний адреса (список IP-адресов, отсортированных в порядке убывания количества упоминаний). Если несколько IP-адресов имеют одинаковое количество упоминаний, то к ним применяется сортировка строк по убыванию.
Важно:
В логе может встречаться текст похожий на IP, но не являющимся им, например, 0.0.0.1000
Также в логах могут встречаться маски подсети, например 192.168.0.0/16. Их не нужно считать как ip.
Строки логов могут быть пустые.
Строка лога не обязательно содержит ip, но в логах обязательно содержится хотя бы один ip.
Например, если лог содержит следующие записи:
[2019-08-29 13:00:13] login to 10.64.64.8
[2019-08-29 13:15:35] logout from 95.213.255.16
[2019-08-29 14:14:33] ssh connection to 10.64.64.8
[2019-09-01 14:14:35] request from 35.228.158.140 to 10.64.65.8
[2019-09-01 14:14:35] login to 35.228.158.140
[2019-09-01 15:29:01] login to 35.228.158.140Программа должна вывести на экран:
35.228.158.140 3
10.64.64.8 2
95.213.255.16 1
10.64.65.8 1Sample Input:
[2019-08-29 13:00:13] login to 10.64.64.8
[2019-08-29 13:15:35] logout from 95.213.255.16
[2019-08-29 14:14:33] ssh connection to 10.64.64.8
[2019-09-01 14:14:35] request from 35.228.158.140 to 10.64.65.8
[2019-09-01 14:14:35] login to 35.228.158.140
[2019-09-01 15:29:01] login to 35.228.158.140Sample Output:
35.228.158.140 3
10.64.64.8 2
95.213.255.16 1
10.64.65.8 1Эта задача может быть решена с помощью регулярных выражений и словаря для подсчёта вхождений каждого IP-адреса. Вот пример решения на Python:
import re
from collections import Counter
def parse_logs(logs):
# Регулярное выражение для поиска IPv4-адресов
ip_pattern = re.compile(r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b')
# Инициализация счетчика для подсчета встречаемости IP-адресов
ip_counter = Counter()
# Проход по всем логам и подсчет количества IP-адресов
for log in logs:
ip_addresses = ip_pattern.findall(log)
for ip in ip_addresses:
# Проверка, является ли подстрока действительным IP-адресом
parts = list(map(int, ip.split('.')))
if all(map(lambda part: 0 <= part < 256, parts)):
ip_counter[ip] += 1
# Возвращаем отсортированный по убыванию список IP-адресов и их количества
return sorted(ip_counter.items(), key=lambda item: (-item[1], -int(item[0].replace('.', ''))))
# Пример использования
logs = [
'[2019-08-29 13:00:13] login to 10.64.64.8',
'[2019-08-29 13:15:35] logout from 95.213.255.16',
'[2019-08-29 14:14:33] ssh connection to 10.64.64.8',
'[2019-09-01 14:14:35] request from 35.228.158.140 to 10.64.65.8',
'[2019-09-01 14:14:35] login to 35.228.158.140',
'[2019-09-01 15:29:01] login to 35.228.158.140'
]
print(parse_logs(logs))
В этом коде мы используем регулярное выражение для поиска всех IP-адресов в каждом логе. Затем мы проверяем, что каждая часть адреса находится в допустимом диапазоне (от 0 до 255). Если адрес действителен, мы увеличиваем его счётчик в Counter. В конце мы возвращаем список IP-адресов и их количества, отсортированный в порядке убывания количества и по самому адресу, преобразованному в число, если количество совпадает.
Видим прокол: не учтены дополнительные условия — подсети попадут в ответ. Но если кандидат потратит хотя бы минуту на чтение задания и тестирование, он это увидит.
Напоминаем роботу про дополнительные условия, получаем новое решение.
import re
from collections import Counter
def parse_logs(logs):
# Регулярное выражение для поиска IPv4-адресов
ip_pattern = re.compile(r'\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b')
# Инициализация счетчика для подсчета встречаемости IP-адресов
ip_counter = Counter()
# Проход по всем логам и подсчет количества IP-адресов
for log in logs:
ip_addresses = ip_pattern.findall(log)
for ip in ip_addresses:
# Проверка, является ли подстрока действительным IP-адресом
parts = list(map(int, ip.split('.')))
if all(map(lambda part: 0 <= part < 256, parts)) and '/' not in log:
ip_counter[ip] += 1
# Возвращаем отсортированный по убыванию список IP-адресов и их количества
return sorted(ip_counter.items(), key=lambda item: (-item[1], -int(item[0].replace('.', ''))))
# Пример использования
logs = [
'[2019-08-29 13:00:13] login to 10.64.64.8',
'[2019-08-29 13:15:35] logout from 95.213.255.16',
'[2019-08-29 14:14:33] ssh connection to 10.64.64.8',
'[2019-09-01 14:14:35] request from 35.228.158.140 to 10.64.65.8',
'[2019-09-01 14:14:35] login to 35.228.158.140',
'[2019-09-01 15:29:01] login to 35.228.158.140',
'[2019-09-01 15:29:01] invalid ip 0.0.0.1000',
'[2019-09-01 15:29:01] subnet mask 192.168.0.0/16',
'empty log',
'[2019-09-01 15:29:01] no ip here'
]
print(parse_logs(logs))Итог: задача решена, дополнительные условия учтены.
Самый вместительный контейнер — С++
Дана последовательность h содержащая n целочисленных высот.
На координатной плоскости нарисовано n вертикальных линий,
i-й элемент определяет линию от точки (i, 0) до точки (i, h[i]).
Найдите две линии, которые образуют вместе с осью x "контейнер",
который может содержать наибольшее количество "двумерной воды" так,
чтобы она не выливалась за его пределы. Контейнер наклонять нельзя.
Вроде какая-то распространённая классическая задача.
Эта задача — классическая задача в области алгоритмов, которую можно решить с помощью метода двух указателей. Суть алгоритма заключается в том, чтобы начать с самого широкого контейнера и пробовать уменьшить ширину контейнера в надежде на то, что мы найдем контейнер с большей высотой. Здесь важно заметить, что минимальная высота определяет максимальный объем контейнера.
Следующий код на C++ реализует этот алгоритм:
#include <vector>
#include <algorithm>
#include <iostream>
using namespace std;
int maxArea(vector<int>& height) {
int max_area = 0;
int left = 0;
int right = height.size() - 1;
while (left < right) {
// Высчитываем площадь
int area = min(height[left], height[right]) * (right - left);
max_area = max(max_area, area);
// Если текущий слева меньше, чем текущий справа, смещаем указатель слева вправо
if (height[left] < height[right]) {
left++;
} else {
// В противном случае смещаем указатель справа влево
right--;
}
}
return max_area;
}
int main() {
vector<int> heights1 = {1,8,6,2,5,4,8,3,7};
vector<int> heights2 = {1,1};
vector<int> heights3 = {4,3,2,1,4};
vector<int> heights4 = {1,2,1};
cout << "Maximum water that can be contained: " << endl;
cout << "Example 1: " << maxArea(heights1) << endl; // Expected output: 49
cout << "Example 2: " << maxArea(heights2) << endl; // Expected output: 1
cout << "Example 3: " << maxArea(heights3) << endl; // Expected output: 16
cout << "Example 4: " << maxArea(heights4) << endl; // Expected output: 2
return 0;
}
Функция maxArea принимает вектор height, содержащий высоты линий. Она инициализирует переменные max_area (для хранения максимальной площади контейнера), left и right (для хранения индексов левой и правой границ контейнера). Затем в цикле функция вычисляет площадь контейнера, используя текущие границы, и обновляет max_area, если текущая площадь больше максимальной. Если левая граница меньше правой, функция сдвигает левую границу вправо, иначе она сдвигает правую границу влево. Функция возвращает max_area после завершения цикла.
Итог: подробно не проверял, но с виду ответ правильный.
Решение кажется тоже достаточно эффективным.
Логичнее было вернуть две линии, а не площадь, но это минорное исправление, которое сам робот легко сделает по просьбе человека.
Клиент-серверный пинг-понг — С++
Написать клиент и сервер, которые бесконечно обмениваются друг с другом ping-pong-сообщениями.
Необходимо описать сборку решения на cmake и использовать какую-то популярную библиотеку для логирования.
Здесь два простых примера клиента и сервера, написанных на C++ с использованием библиотеки Boost.Asio для сетевых операций и spdlog для логирования. Они бесконечно обмениваются сообщениями Ping и Pong.
Server.cpp
#include <boost/asio.hpp>
#include <boost/array.hpp>
#include <spdlog/spdlog.h>
using boost::asio::ip::tcp;
int main() {
boost::asio::io_service io_service;
tcp::acceptor acceptor(io_service, tcp::endpoint(tcp::v4(), 1234));
for (;;) {
tcp::socket socket(io_service);
acceptor.accept(socket);
for (;;) {
boost::array<char, 128> buf;
boost::system::error_code error;
size_t len = socket.read_some(boost::asio::buffer(buf), error);
if (error == boost::asio::error::eof) {
break;
} else if (error) {
throw boost::system::system_error(error);
}
spdlog::info("Received: {}", std::string(buf.data(), len));
boost::asio::write(socket, boost::asio::buffer("Pong"));
}
}
return 0;
}Client.cpp
#include <boost/asio.hpp>
#include <boost/array.hpp>
#include <spdlog/spdlog.h>
#include <chrono>
#include <thread>
using boost::asio::ip::tcp;
int main() {
boost::asio::io_service io_service;
tcp::resolver resolver(io_service);
tcp::resolver::query query(tcp::v4(), "localhost", "1234");
tcp::resolver::iterator iterator = resolver.resolve(query);
tcp::socket socket(io_service);
boost::asio::connect(socket, iterator);
for (;;) {
boost::asio::write(socket, boost::asio::buffer("Ping"));
boost::array<char, 128> buf;
boost::system::error_code error;
size_t len = socket.read_some(boost::asio::buffer(buf), error);
spdlog::info("Received: {}", std::string(buf.data(), len));
std::this_thread::sleep_for(std::chrono::seconds(1));
}
return 0;
}Для компиляции этих двух файлов с помощью CMake, вы можете создать следующий файл CMakeLists.txt:
cmake_minimum_required(VERSION 3.10)
project(PingPong)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED True)
find_package(Boost REQUIRED COMPONENTS system)
find_package(spdlog REQUIRED)
add_executable(Client Client.cpp)
add_executable(Server Server.cpp)
target_link_libraries(Client Boost::system spdlog::spdlog)
target_link_libraries(Server Boost::system spdlog::spdlog)Чтобы собрать проект:
- Создайте директорию build:
mkdir build && cd build - Вызовите CMake:
cmake .. - Вызовите Make:
make
Запустите сервер, а затем клиент. Они начнут обмениваться сообщениями Ping и Pong, и эти сообщения будут логироваться.
Итог: вроде примерно то, что надо.
Сканер опасных файлов — С++
Требуется реализовать утилиту на языке C++, работающую из командной строки, выполняющую сканирование файлов в директории, с целью нахождения в ней “подозрительных” (suspicious) файлов.
В рамках задачи определено 3 типа “подозрительного” содержимого в файле:
JS suspicious: файл с расширением .js, содержащий строку: <script>evil_script()</script>
CMD suspicious: файл с расширением CMD/BAT, содержащий строку: rd /s /q "c:\windows"
EXE suspicious: файл с расширением EXE/DLL, содержащий строки: CreateRemoteThread, CreateProcessПосле завершения выполнения утилиты пользователю должен быть выведен отчет о сканировании, в котором присутствует следующая информация:
общее количество обработанных файлов;
количество детектов на каждый тип “подозрительного” содержимого;
количество ошибок анализа файлов (например, не хватает прав на чтение файла);
время выполнения утилиты.Пример исполнения утилиты из командной строки:
scan_util ~/Downloads
====== Scan result ======
Processed files: 150
JS detects: 5
CMD detects: 1
EXE detects: 2
Errors: 1
Execution time: 00:00:31
=========================Для упрощения задачи условимся:
В директории находятся только файлы, вложенных директорий нет;
В каждом файле присутствует только один тип “подозрительного” содержимого.
Рекомендуется максимальное использование (утилизация) вычислительных ресурсов устройства, на котором выполняется утилита.
Реализация этой утилиты может быть выполнена с использованием различных компонентов стандартной библиотеки C++. Заметим, что для максимального использования вычислительных ресурсов можно использовать многопоточность с помощью библиотеки <thread> и <future>.
Вот пример реализации, который использует многопоточность для ускорения процесса сканирования файлов:
#include <iostream>
#include <fstream>
#include <vector>
#include <chrono>
#include <thread>
#include <future>
#include <filesystem>
#include <algorithm>
#include <stdexcept>
#include <cstring>
namespace fs = std::filesystem;
struct ScanResult {
int processedFiles = 0;
int jsDetects = 0;
int cmdDetects = 0;
int exeDetects = 0;
int errors = 0;
};
ScanResult detectSuspicious(const fs::path& dir) {
ScanResult result;
std::vector<std::future<ScanResult>> futures;
for (const auto& entry : fs::directory_iterator(dir)) {
futures.push_back(std::async(std::launch::async, [&entry]() {
ScanResult localResult;
localResult.processedFiles = 1;
std::ifstream file(entry.path(), std::ios::binary);
if (!file) {
++localResult.errors;
return localResult;
}
std::string content(std::istreambuf_iterator<char>(file), {});
if (entry.path().extension() == ".js" &&
content.find("<script>evil_script()</script>") != std::string::npos)
++localResult.jsDetects;
else if ((entry.path().extension() == ".cmd" || entry.path().extension() == ".bat") &&
content.find("rd /s /q \"c:\\windows\"") != std::string::npos)
++localResult.cmdDetects;
else if ((entry.path().extension() == ".exe" || entry.path().extension() == ".dll") &&
content.find("CreateRemoteThread") != std::string::npos &&
content.find("CreateProcess") != std::string::npos)
++localResult.exeDetects;
return localResult;
}));
}
for (auto& fut : futures) {
ScanResult localResult = fut.get();
result.processedFiles += localResult.processedFiles;
result.jsDetects += localResult.jsDetects;
result.cmdDetects += localResult.cmdDetects;
result.exeDetects += localResult.exeDetects;
result.errors += localResult.errors;
}
return result;
}
int main(int argc, char* argv[]) {
if (argc != 2) {
std::cerr << "Usage: " << argv[0] << " <directory>\n";
return 1;
}
fs::path dir(argv[1]);
if (!fs::exists(dir) || !fs::is_directory(dir)) {
std::cerr << "Invalid directory: " << argv[1] << '\n';
return 1;
}
auto start = std::chrono::high_resolution_clock::now();
ScanResult result = detectSuspicious(dir);
auto finish = std::chrono::high_resolution_clock::now();
std::cout << "\n====== Scan result ======\n\n"
<< "Processed files: " << result.processedFiles << "\n\n"
<< "JS detects: " << result.jsDetects << "\n\n"
<< "CMD detects: " << result.cmdDetects << "\n\n"
<< "EXE detects: " << result.exeDetects << "\n\n"
<< "Errors: " << result.errors << "\n\n"
<< "Execution time: " << std::chrono::duration_cast<std::chrono::seconds>(finish - start).count()
<< "\n\n=========================\n";
return 0;
}
Замечания по коду:
- Структура
ScanResultсодержит счетчики для всех исследуемых данных. - Функция
detectSuspiciousитерирует по всем файлам в указанной директории и для каждого файла создает отдельную задачу для выполнения в отдельном потоке с помощьюstd::async. - В каждом потоке открывается файл, читается его содержимое и проверяется на наличие подозрительных строк в соответствии с его расширением.
- В главной функции
mainпроверяется корректность аргументов командной строки, выполняется сканирование и выводятся результаты.
Итог: в коде точно есть как минимум одна проблема — локальная переменная entry захватывается по ссылке, что приводит к ошибке.
Если исправить на захват по значению, то кажется решение становится правильным.
Сервис — генератор случайных значений — GO
Необходимо реализовать сервис на Go для генерации случайных значений.
Сервис реализует JSON API работающее по HTTP. Каждой генерации присваивать уникальный id, по которому можно получить результат генерации методом retrieve.
Реализовать методы:
POST /api/generate/ — генерация случайного значения и его идентификатора
GET /api/retrieve/ — получение значения по id, которое вернулось в методе generate
Проект должен быть работоспособным и до конца реализованным, должна быть приведена структура файлов проекта. Не должно быть TODO, все необходимо реализовать до конца.
Я немного сократил и конкретизировал задание, но при желании все допусловия также могут быть выполнены GPT.
Отлично, ваше приложение может состоять из трех основных частей:
- Главный файл
main.go, который будет инициализировать ваш сервер и роутер. - Контроллер, который будет обрабатывать запросы и генерировать/возвращать данные.
- Сервис, который будет хранить данные и предоставлять методы для их получения.
Ниже представлен простой пример реализации вашего приложения на Go.
Файловая структура:
/myproject
|-- main.go
|-- controller
| |-- controller.go
|-- service
|-- service.gomain.go:
package main
import (
"net/http"
"myproject/controller"
"github.com/gorilla/mux"
)
func main() {
r := mux.NewRouter()
r.HandleFunc("/api/generate/", controller.Generate).Methods("POST")
r.HandleFunc("/api/retrieve/{id}", controller.Retrieve).Methods("GET")
http.ListenAndServe(":8080", r)
}controller/controller.go:
package controller
import (
"encoding/json"
"net/http"
"myproject/service"
"github.com/gorilla/mux"
)
func Generate(w http.ResponseWriter, r *http.Request) {
id, value := service.GenerateValue()
json.NewEncoder(w).Encode(map[string]string{
"id": id,
"value": value,
})
}
func Retrieve(w http.ResponseWriter, r *http.Request) {
id := mux.Vars(r)["id"]
value, found := service.GetValue(id)
if !found {
w.WriteHeader(http.StatusNotFound)
json.NewEncoder(w).Encode(map[string]string{
"error": "Value not found",
})
return
}
json.NewEncoder(w).Encode(map[string]string{
"id": id,
"value": value,
})
}service/service.go:
package service
import (
"math/rand"
"strconv"
"sync"
)
var (
mu sync.RWMutex
data = make(map[string]string)
)
func GenerateValue() (string, string) {
mu.Lock()
defer mu.Unlock()
id := strconv.Itoa(rand.Int())
value := strconv.Itoa(rand.Int())
data[id] = value
return id, value
}
func GetValue(id string) (string, bool) {
mu.RLock()
defer mu.RUnlock()
value, found := data[id]
return value, found
}Обратите внимание, что в этом примере мы используем Gorilla Mux для управления роутами. Это очень популярная библиотека, но вы можете использовать любую другую по своему усмотрению.
Этот код хранит сгенерированные данные в памяти и не сохраняет их после перезагрузки сервера. Если вам нужно сохранять данные между перезагрузками, вы должны использовать некоторую форму постоянного хранилища, такую как базу данных.
Итог: как минимум это решение работает:
-> % curl -X POST http://localhost:8080/api/generate/
{"id":"2080282532813236477","value":"58477870582709028"}
-> % curl -X POST http://localhost:8080/api/generate/
{"id":"2383079509972796201","value":"7856768647560731715"}
-> % curl http://localhost:8080/api/retrieve/2383079509972796201
{"id":"2383079509972796201","value":"7856768647560731715"}
-> % curl http://localhost:8080/api/retrieve/2080282532813236477
{"id":"2080282532813236477","value":"58477870582709028"}Также, отдельным сообщением я попросил его сгенерировать Dockerfile
Сначала вам нужно будет создать файл go.mod в корне вашего проекта, если вы его ещё не создали, это можно сделать с помощью команды go mod init <module-name>. Это поможет Go определить ваш проект как модуль и управлять зависимостями.
Затем вы можете создать Dockerfile в корне вашего проекта. Он может выглядеть следующим образом:
# Start from the latest golang base image
FROM golang:latest
# Add Maintainer Info
LABEL maintainer="Your Name <your-email@domain.com>"
# Set the Current Working Directory inside the container
WORKDIR /app
# Copy go mod and sum files
COPY go.mod go.sum ./
# Download all dependencies. Dependencies will be cached if the go.mod and the go.sum files are not changed
RUN go mod download
# Copy the source from the current directory to the Working Directory inside the container
COPY . .
# Build the Go app
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o main .
# This container exposes port 8080 to the outside world
EXPOSE 8080
# Run the binary program produced by `go install`
CMD ["./main"]Теперь вы можете собрать Docker-образ с помощью следующей команды:
docker build -t my-go-app .
И запустить его:
docker run -p 8080:8080 my-go-app
Обратите внимание, что вместо "Your Name <your-email@domain.com>" и my-go-app вы должны использовать свои собственные значения.
Этот Dockerfile создает образ Docker с вашим приложением на Go, устанавливает все зависимости и выполняет приложение при запуске контейнера. Сервер будет доступен на порту 8080.
RSS feed reader
Задание необходимо выполнить на C#
Графическое приложение для чтения RSS ленты с сайта.
В файле настроек хранятся:
Лента, которую обрабатывает фидер. По умолчанию это (https://habr.com/rss/interesting/).
Частота обновления ленты приложением.
Основное окно должно содержать список элементов ленты (item): Каждый элемент ленты должен отображать название и дату публикации (поля item->title и item->pubDate ).
Дата публикации статьи должна отображаться в удобном для чтения пользователем формате.
При нажатии на заголовок должен открываться браузер с переходом на выбранную статью (или в уже открытом браузере должна открываться ссылка). Пользователь должен иметь возможность посмотреть описание статьи (поле item->description).
Содержание описания выводится в виде обычного текста (как есть), без форматирования по тегам.
Данные должны периодически обновляться.
Частота обновления должна быть взята из файла конфигурации. Файл настроек имеет формат XML.
Выведи структуру решения, затем выведи содержимое каждого файла.
Пиши ответ с учетом того, что мне нужно собрать под mono в linux.
Последнее допусловие от меня, так как мне надо это все собрать, чтобы проверить.
Принимая во внимание ваш запрос, ниже приведено решение на основе Windows Forms (System.Windows.Forms) и XmlReader для чтения RSS-ленты. Данный пример включает простую форму с ListBox для отображения заголовков новостей и TextBox для отображения описания выбранной новости.
Структура решения:
RssReader
├── Program.cs
├── RssFeed.cs
├── RssItem.cs
├── Settings.cs
└── MainForm.csProgram.cs
using System;
using System.Windows.Forms;
public class Program
{
[STAThread]
static void Main()
{
Application.EnableVisualStyles();
Application.SetCompatibleTextRenderingDefault(false);
Application.Run(new MainForm());
}
}RssFeed.cs
using System;
using System.Collections.Generic;
using System.Xml;
public class RssFeed
{
public static List<RssItem> Load(string url)
{
List<RssItem> rssItems = new List<RssItem>();
using (XmlReader reader = XmlReader.Create(url))
{
while (reader.ReadToFollowing("item"))
{
RssItem item = new RssItem();
reader.ReadToFollowing("title");
item.Title = reader.ReadElementContentAsString();
reader.ReadToFollowing("description");
item.Description = reader.ReadElementContentAsString();
reader.ReadToFollowing("link");
item.Link = reader.ReadElementContentAsString();
reader.ReadToFollowing("pubDate");
item.PubDate = DateTime.Parse(reader.ReadElementContentAsString());
rssItems.Add(item);
}
}
return rssItems;
}
}RssItem.cs
using System;
public class RssItem
{
public string Title { get; set; }
public string Description { get; set; }
public string Link { get; set; }
public DateTime PubDate { get; set; }
}Settings.cs
using System;
using System.Xml;
public class Settings
{
public string RssUrl { get; set; }
public TimeSpan RefreshRate { get; set; }
public static Settings Load(string path)
{
XmlDocument xmlDoc = new XmlDocument();
xmlDoc.Load(path);
var settingsNode = xmlDoc.SelectSingleNode("/settings");
string url = settingsNode["rssUrl"].InnerText;
TimeSpan refreshRate = TimeSpan.Parse(settingsNode["refreshRate"].InnerText);
return new Settings { RssUrl = url, RefreshRate = refreshRate };
}
}MainForm.cs
using System;
using System.Diagnostics;
using System.Windows.Forms;
using System.Xml;
public class MainForm : Form
{
private Settings settings;
private Timer timer;
private ListBox rssListBox;
private TextBox descriptionTextBox;
private Button openButton;
public MainForm()
{
settings = Settings.Load("settings.xml");
rssListBox = new ListBox() { Dock = DockStyle.Top, Height = 300 };
descriptionTextBox = new TextBox() { Multiline = true, ReadOnly = true, Dock = DockStyle.Top, Height = 150 };
openButton = new Button() { Text = "Open in browser", Dock = DockStyle.Top };
rssListBox.SelectedIndexChanged += RssListBox_SelectedIndexChanged;
openButton.Click += OpenButton_Click;
Controls.Add(openButton);
Controls.Add(descriptionTextBox);
Controls.Add(rssListBox);
LoadRssItems();
timer = new Timer();
timer.Interval = (int)settings.RefreshRate.TotalMilliseconds;
timer.Tick += Timer_Tick;
timer.Start();
}
private void RssListBox_SelectedIndexChanged(object sender, EventArgs e)
{
if (rssListBox.SelectedItem is RssItem item)
{
descriptionTextBox.Text = item.Description;
}
}
private void OpenButton_Click(object sender, EventArgs e)
{
if (rssListBox.SelectedItem is RssItem item)
{
Process.Start(item.Link);
}
}
private void Timer_Tick(object sender, EventArgs e)
{
LoadRssItems();
}
private void LoadRssItems()
{
var rssItems = RssFeed.Load(settings.RssUrl);
rssListBox.Items.Clear();
rssListBox.Items.AddRange(rssItems.ToArray());
}
}После того как все файлы созданы, вы можете собрать проект с помощью команды:
mcs -out:RssReader.exe *.cs -r:System.Windows.Forms.dll -r:System.Drawing.dll -r:System.Xml.Linq.dll
А затем запустить его:
mono RssReader.exe
Примечание: Пожалуйста, убедитесь, что у вас установлен Mono и что вы находитесь в правильной директории, когда выполняете эти команды.
Собираем, запускаем
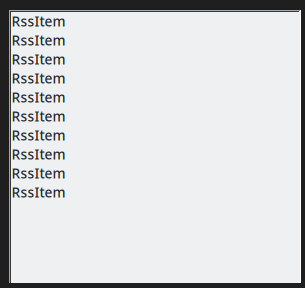
Получилась какая-то ерунда. Окно, в котором каждая строчка — просто слово RssItem.
Помним, что мы не умеем сами править код, пишем текстом претензию роботу.
появилось окно с 10 строчками RssItem
Извините за путаницу. Очевидно, в ListBox нужно отобразить не сами объекты RssItem, а их заголовки. Для этого вам нужно изменить метод LoadRssItems() в файле MainForm.cs следующим образом:
private void LoadRssItems()
{
var rssItems = RssFeed.Load(settings.RssUrl);
rssListBox.Items.Clear();
foreach (var item in rssItems)
{
rssListBox.Items.Add(item.Title);
}
}В данном случае в ListBox добавляются только заголовки новостей (свойство Title объектов RssItem). Однако, чтобы отобразить описание новости и открыть ее в браузере, вам потребуется сам объект RssItem. Поэтому рекомендуется добавить в класс RssItem переопределение метода ToString():
public class RssItem
{
public string Title { get; set; }
public string Description { get; set; }
public string Link { get; set; }
public DateTime PubDate { get; set; }
public override string ToString()
{
return Title;
}
}В таком случае ListBox будет отображать заголовки новостей, но при выборе элемента вы сможете получить полный объект RssItem с его описанием и ссылкой.
Правим, перезапускаем
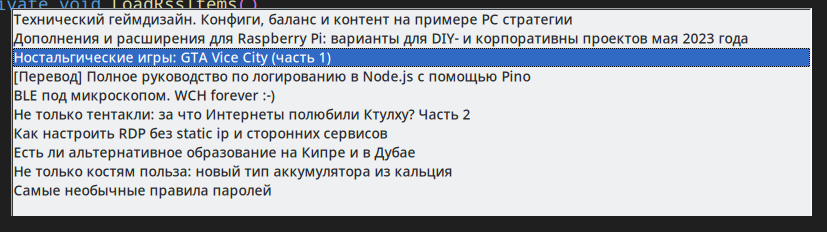
Итог: теперь похоже на правду. Конечно это еще не ридер, так как показывает только заголовки, но это дело получаса и пяти промптов добиться нужного функционала, без всякого знания C#. Добавить функционал и кнопочки тоже не составит большого труда. То есть выполнить задание за один промпт мы не смогли, но приблизились к этому максимально.
И что же делать?
Кажется, пора перестать давать тестовые задания на дом. Это становится явлением из вашего прошлого, и ему пора остаться в истории навсегда.
Если вы всё же хотите это делать, то вероятно стоит:
- Давать на дом настолько большой и комплексный проект (фронт, бэк, тесты, инфра + деплой), что для решения его через нейронку придётся всё равно проявить какие-то знания.
- Пытаться придумать задание с некоторой изюминкой, которую нейронка почему-то пока не может осилить.
- Главное правило — Взять робота и проверять на нем ваши задания, все идеи, потому что ваши предположения о том, что может и не может нейронка скорее всего неверны и без проверки вы ошибетесь.
Скорее всего всё это будет менее эффективной тратой вашего времени, чем просто провести собес со всеми интересными кандидатами.
Я смог придумать две задачи, на которые Gpt3.5 не мог дать решение. Как водится, когда он не может сделать нормальное решение, он выдумывает несуществующие конструкции. Правда уже через пару недель у нас появилась Gpt4, и оказалось, что она решает эти задачи.
Для примера приведу свою задачу, которую не удалось решить Gpt3.5
Задача
Напиши декоратор на python, который позволяет включить для декорируемой функции кэширование. Должно настраиваться количество хранимых значений. Нельзя использовать стандартные кэш декораторы из functools.
Напиши тесты на этот декоратор. Тесты должны обеспечить проверку готовности декоратора к использованию на продакшне, ничего не пропусти смотри!
Задание несложное, и Gpt3.5, конечно, сделал декоратор, но вот написать на него тесты он не смог. Не придумал, как протестировать собственно само кэширование.
Gpt4 уже не испытывает никаких сложностей с этим.
Ваш декоратор для кэширования может выглядеть следующим образом:
def cache(maxsize):
cache = {}
def decorator(func):
def wrapper(*args, **kwargs):
key = (args, frozenset(kwargs.items()))
if key in cache:
return cache[key]
if len(cache) >= maxsize:
# если кэш заполнен, удаляем одно из значений
cache.pop(next(iter(cache)))
result = func(*args, **kwargs)
cache[key] = result
return result
return wrapper
return decoratorЗдесь cache — это словарь, который используется для хранения результатов вызова функции. Ключами этого словаря являются кортежи, состоящие из аргументов и именованных аргументов, переданных в функцию. Значениями словаря являются результаты вызова функции с данными аргументами.
Когда декорированная функция вызывается, декоратор сначала проверяет, есть ли результат для переданных аргументов в кэше. Если результат найден в кэше, он возвращается и сама функция не вызывается. Если результат в кэше не найден, функция вызывается, ее результат сохраняется в кэше и затем возвращается.
Если количество элементов в кэше достигает maxsize, перед сохранением нового значения удаляется одно из старых значений.
Обратите внимание, что этот декоратор работает только для функций, аргументы которых могут быть хешированы, поскольку они используются в качестве ключей словаря.
Тесты для данного декоратора могут проверять следующие аспекты:
- Проверить, что результат функции кэшируется.
- Проверить, что, когда кэш заполняется, старые значения удаляются.
- Проверить, что декоратор не вносит изменений в результат функции.
- Проверить, что декоратор не влияет на функции без аргументов.
- Проверить, что декоратор обрабатывает именованные аргументы.
- Проверить, что декоратор не работает с функциями, которые принимают аргументы, которые не могут быть хешированы.
Здесь тесты, использующие библиотеку pytest:
import pytest
def test_cache():
counter = 0
@cache(2)
def f(x):
nonlocal counter
counter += 1
return x
assert f(1) == 1 # функция вызывается, counter == 1
assert f(1) == 1 # результат из кэша, counter не изменяется
assert counter == 1
assert f(2) == 2 # функция вызывается, counter == 2
assert f(2) == 2 # результат из кэша, counter не изменяется
assert counter == 2
assert f(1) == 1 # результат из кэша, counter не изменяется
assert counter == 2
assert f(3) == 3 # функция вызывается, counter == 3
assert counter == 3
assert f(1) == 1 # результат уже не в кэше, функция вызывается, counter == 4
assert counter == 4
def test_cache_empty_args():
counter = 0
@cache(2)
def f():
nonlocal counter
counter += 1
f() # counter == 1
f() # результат из кэша, counter не изменяется
assert counter == 1
def test_cache_named_args():
counter = 0
@cache(2)
def f(x=None):
nonlocal counter
counter += 1
return x
assert f(x=1) == 1 # функция вызывается, counter == 1
assert f(x=1) == 1 # результат из кэша, counter не изменяется
assert counter == 1
def test_cache_non_hashable_args():
@cache(2)
def f(x):
return x
with pytest.raises(TypeError):
f([1, 2, 3]) # списки не могут быть хешированы
Запустить тесты можно с помощью команды pytest your_test_module.py, где your_test_module.py.
Решение достаточно хорошее, по большому счёту и не прикопаешься ни к чему.
Итоги
Видимо, у вас попросту больше нет возможности удаленно отличить кандидата, хорошо пишущего код, от человека, хорошо пишущего промпты GPT — только дав ему написать что-то очень большое, что не помещается в рамки тестового задания. Поэтому предлагаю поменять практики отбора кандидатов в соответствии с ходом времени. И продолжить эксперименты с ChatGPT, чтобы вовремя выявить новые задачи, с которыми она может справиться за вас (ну или ваших соискателей).
Если вам было интересно, то приходите ко мне в команду KasperskyOS Tooling Development — будем вместе следить за нейросетями и другими технологиями, которые способны упростить жизнь разработчика. И разбираться, как можно применять их для создания крутых и удобных инструментов.

А если хотите удостовериться в (без)опасности какого-то своего задания — кидайте в комменты, проверим :)
