Александр Крижановский ( @krizhanovsky )
По материалам доклада "Механика web-акселерации" c конференции Saint HighLoad++.
Меня зовут Александр Крижановский и я СЕО в Tempesta Technologies. Мы занимаемся разработкой высокопроизводительных сетевых приложений на заказ. Очень гордимся, что разработанное нами по заказу Positive Technologies AF ядро Web Application Firewall упомянул в своём обзоре Gartner в 2015 году. Также разрабатываем большие базы данных, наша компания — один из крупнейших котрибьютеров MariaDB.
Кроме заказного софта разрабатываем собственный Application Delivery Controller на базе Tempesta FW. Это Web Accelerator, нагруженный дополнительными функциями — в нашем случае, защитой от DDoS-атак и web-атак.
Цель статьи — рассказать о принципах и механизме работы HTTP протоколов и серверов и критериях выбора Web Accelerator для вашего проекта. Я расскажу про:
HTTP connections & messages management
HTTP decoders & parsers
Web caches
Network I/O
Multitasking
TLS
Как работает Web Accelerator
На схеме ниже представлены три клиента, работающие по трём протоколам: HTTP/2, устаревшему HTTP/1.0, HTTPS/1.1. В этом примере proxy-сервер должен терминировать TLS, задаунгрейдить либо сапгрейдить протокол HTTP в протокол, понятный upstream серверам. Например, чаще всего прокси общаются с апстримами (бакендами) по HTTP/1.1.
На картинке ниже у нас есть один большой сервер и два маленьких. Большой — самый быстрый и способен обработать больше всего запросов, поэтому акселератор отправляет ему запросов больше, чем маленьким. Если один из серверов выйдет из строя, то акселератор распределит трафик между двумя оставшимися (failovering). Еще одна, интересная для нас, задача proxy-сервера — раздавать контент из кэша.

Принцип работы HTTP connections & messages management

Ключевая функция HTTP- протоколов — управление соединениями и сообщениями. В большинстве случаев прокси устанавливают с апстримами HTTP/1 соединения и в общем случае для HTTP/1, каждое TCP соединение может быть использовано только одним сообщением в каждый момент времени.
Определим, сколько серверных соединений нужно поддерживать proxy-серверу до web сервера. Если у вас есть клиенты, которые шлют запросы одновременно, то число клиентских запросов будет равно числу соединений с бэкэндом. Например, если прислали 1000 запросов, с бэкендом будет установлено 1000 соединений.
Ограничения HTTP connections
Установка HTTP connections довольно медленная, из-за этого большинство HTTP proxy серверов поддерживают keep-alive соединения. Поэтому если вы один раз установили 1000 соединений и поддерживаете их в keep-alive состоянии, то если вам придёт 1000 запросов, вы направите их параллельно в эти 1000 соединений. А если поступит 1500 запросов, то 500 окажутся в очереди, а 1000 будут обслуживаться.
Действует тоже правило: сколько у вас соединений с бэкендом, столько запросов параллельно вы можете обработать. Но это правило создает ограничение по ресурсам:
Если придет DDoS, то вы не сможете отработать множество других запросов;
Если вы действительно будете динамически устанавливать новые соединения, то достаточно быстро исчерпаете количество портов и получите отказ.
HTTP pipelining
Для решения этой задачи есть HTTP pipelining. Он позволяет отправить множество запросов пакетом в одном серверном соединении. Затем, возможно, подождать, когда они обработаются, и также пакетом принять ответы сервера.

К сожалению, эта возможность реализована в небольшом количестве серверов — например, в Tempesta FW, Squid и Polipo. Еще один недостаток — сложность управления этими очередями и вытекающая из них проблема безопасности.
HTTP Response Splitting Attack
Рассмотрим одну из возможных атак: HTTP Response Splitting Attack. Вот как это выглядит:

В этом кейсе наш сервер уязвим, потому что параметр lang, как есть, вставляется в тело ответа. Клиент присылает запрос (он выделен черным шрифтом), в котором закодирован фейковый ответ. Proxy-сервер принимает такой запрос, и если он не понимает, что в нем лежит, то как есть отдает его серверу. А тот генерирует свой ответ и в параметр lang поступает фейковый ответ от клиента. От бакенда на proxy-сервер прилетают два ответа: оригинальный с “lang=foobar” и то, что у нас синъектировано в конце запроса клиента.
Теперь если клиент сразу после этого пришлет еще один запрос, то proxy сервер получит целых два запроса от клиента и три ответа от сервера.
В HTTP/1.1 он соединит второй инъектированный ответ со вторым запросом клиента. В результате и второй запрос клиента, и то, что инъектировано на сервер, окажется под контролем злоумышленника. В кэш он сможет положить абсолютно всё, что ему захочется. На любой запрос, на любой URL легко разместит любой контент.
Атака возникает из-за того, что proxy-сервер не разбирается, что именно к нему пришло. Он просто отправляет это на сервер. Атака сработает если между proxy и upstream используется HTTP/1.1, который может соединять запросы по количеству: первый — с первым, второй — со вторым и так далее.
HTTP/2 лучше защищен, так как у него есть ID HTTP сообщения (stream id). А значит такая атака уже не пройдет, если до бэкенда у вас установлен протокол HTTP/2.

Преимущество HTTP/2 в том, что в нем качественно сделаны пайплайны и поэтому с ним проще работать. Уходит проблема head of line (HoL) blocking (отличное описание этой проблемы можно найти в главе по HTTP/2 книги High Performance Browser Networking by Ilya Grigorik, которую очень советуем к прочтению).
А ещё у него есть сжатие, но непонятно, преимущество это или недостаток. Сжатие позволяет экономить пропускную способность сети, но нагружает CPU. Также из-за компрессии мы теряем возможность обойтись без копирований (для HTTP/1 легко сделать zero-copy реализацию). В целом HTTP/2 соединение с бэкендами имеет смысл в двух случаях:
Если у вас долгий канал, например, используете CDN, то в пайплайне актуален HTTP/2. Ведь у сети доставки содержимого CDN достаточно латентное соединение до upstream сервера
Если у вас медленная логика на самом application-сервере. Если reverse proxy стоит рядом с upstream, то HTTP/2 имеет мало смысла.
Идемпотентные запросы

Идемпотентные запросы — это безопасные запросы, такие как GET, HEAD, TRACE, OPTIONS и т.д. Неидемпотентные — это, как правило, POST или любой другой запрос, который меняет состояние сервера (может быть и GET если так построена прикладная логика сервиса).
Переотправлять неидемпотентные запросы, как правило, нельзя. Если мы отправили запрос на сервер и он упал, то мы не можем его переотправить в другое соединение другому серверу. Но в HTTP/2 есть такая возможность, так как он контролирует, какие запросы прошли, а какие нет благодаря своим ID идентификаторам. Так с его помощью мы можем повторять неидемпотентные запросы.
Представим, что мы отправили неидемпотентный запрос и сервер на нем упал.

Мы не знаем, что произошло на сервере. Если мы второй раз отправим запрос, то можем изменить состояние приложения дважды.
Еще одна проблема с так называемыми запорсами-убийцами. Запрос, который вызывает динамическую логику, может уронить один сервер. Но если вслед за этим мы его перенаправим на другой, он тоже ляжет. Так мы положим весь кластер. Поэтому в proxy-серверах обычно ограничено количество попыток переотправить запрос. Клиент не будет ждать бесконечно, пока мы переберем все сервера и наконец обслужим его, поэтому мы должны ограничить время на эту операцию.
Посмотрим на схеме, как это происходит внутри proxy-сервера, который поддерживает пайплайнинг для HTTP/1.1.

В этом примере первый клиент отправляет неидемпотентный запрос — выделен большим красным квадратом. В первую очередь мы должны поддержать клиентские очереди, чтобы сохранить порядок ответов на пришедшие запросы. Дальше нужно выстроить логику нагрузки между серверами: для этого мы распределяем наши запросы по очередям для серверов. Неидемпотентный запрос ставится в очередь абсолютно также, как и все другие запросы, но он последний, кто отправляется в соединение.
Допустим, мы отправили три запроса к большому серверу, он падает, ни одного ответа не приходит. Тогда мы попытаемся переотправить все отправленные ему запросы, кроме неидемпотентного, с которым этого сделать нельзя. Но поскольку у нас есть ограничение на размер очереди отправки (на слайде - 5), то в нее можно вместить только 3 запроса. Соответственно наш последний (синий) запрос тоже исключается. Когда мы исключаем запросы, мы не сообщаем клиенту сразу, что запросы не удались. Вместо этого в клиентскую очередь делаем линк на ошибочный ответ для этого запроса. Они стоят в очереди, пока не придут ответы на запросы, которые стоят до них.
После переотправки запросов, RFC требует, чтобы в очередь, куда мы отправили запросы, которые уже уронили сервер, больше ничего не добавлялось. Так мы сообщаем, что эта очередь больше недоступна для следующей отправки (жирная красная черта на слайде).
Давайте посмотрим, что в это время происходит с ответами сервера.

Существует два типа обработки ответов:
Buffering. Буферизированная обработка в основном используется всеми proxy серверами. Поступивший HTTP ответ мы сначала собираем и сохраняем в оперативной памяти и/или на диске сервера, а потом отдаём клиенту большим куском.
Streaming. Существует поддержка стриминга для ответов — например, у гибкого решения кэширования страниц на уровне сервера Varnish и проекта веб-сервера Tengine. Проблема в том, что когда вам приходит часть ответа от сервера, вы сразу можете отправить его клиенту. Но если мы направляем, например, двухсотый статус ответа клиенту, не факт, что сможем прислать клиенту весь ответ целиком.
Приоритизация
В HTTP/2 есть приоритизация, которая работает с параллельными стримами вместо TCP соединений в HTTP/1. В этом примере у нас есть два стрима: для HTML и для картинки. HTML для нас более важен — он позволяет построить DOM дерево документа, что приоритетнее, чем отобразить картинку, поэтому у неё приоритет 4, а у HTML — 12.

В самом простом варианте мы заведем два счетчика (12 и 4), и с каждым отправленным фреймом в более приоритетном стриме будем декрементировать первый счетчик. Получится 12, 11, 10 и т.д. Когда счетчики сравняются и составят 4 и 4, можем миксовать фреймы. У нас получатся всплески из первого стрима. Это не очень здорово, поэтому обычно используется Weighted Fair Queue (WFQ) — механизм планирования пакетных потоков данных с различными приоритетами. Благодаря ему мы сможем сразу миксовать фреймы правильно, то есть отправить три фрейма первого стрима, один фрейм второго и т.д.
Понятное дело, такое взвешивание потребует ресурсов. В библиотеке nghttp2 используется логарифмическое время, а в H2O более оптимальная версия, которая работает быстрее, но планирует стримы субоптимальным образом.

Перед proxy-серверами часто стоит задача модифицировать сообщения, которые они проксируют. Рассмотрим случай, что нам нужно добавить собственный IP адрес в X-Forwarded-For. Обычно это делается так: мы полностью создаем новое сообщение с новым значением этого заголовка.

В случае с Tempesta мы работаем с socket буферами в ядре, которые поддерживают фрагментацию. В этом случае мы HTTP сообщение режем на две части. Туда, куда нужно вставить новый фрагмент, добавляем третий и переопределяем указатели на эти фрагменты так, чтобы они собрались в правильном порядке уже на сетевом адаптере. Так можно делать очень сложные трансформации сетевого трафика без копирования.
HTTP decoders & parsers
HTTP parser
Самый простой вариант написать HTTP парсер — использовать multi-pass подход. Это пример из парсера Varnish, который несколько раз обрабатывает исходный код.

Например, нам приходит HTTPS, мы сначала сравниваем HTTP, потом HTTPS.

Два раза идти по одним и тем же данным — не очень здорово, поэтому большинство серверов используют state-машину или конечный автомат. Она представляет цикл с двумя switch по состоянию и входным данным. В ответ приходит первое состояние и символ 'b':

Перейдём на нужное состояние, найдём нужный символ и тогда поймём, куда двигаться дальше: конец вложенного switch блока, конец внешнего switch, конец цикла:

И начинаем с начала:

И только теперь понимаем, где должны были быть:

В этом примере мы ходим по коду по кругу и у нас возникают промахи кэша инструкций — это когда запрашиваемые данные отсутствуют в кэше и их нужно подгружать из основного источника. Но вместо хождения кругами мы могли бы сделать прямой переход с помощью парсера.

Сервера используют парсеры разных типов:
Nginx и Apache Traffic Server — Case/swith;
Varnish и HAProxy — Multi-pass;
Tempesta FW, H2O, CloudFlare — SIMD.
На прошлых конференциях HighLoad и Scale я рассказывал про алгоритмы HTTP парсера, которые способны быстро поглощать данные. Это важно, потому что если мы запланируем DDoS-атаку с помощью HTTP флуда, то отправлять простой запрос на индексную страницу не имеет смысла. Целесообразнее отправить более тяжелый запрос, который сложнее обработать HTTP серверу.
Вот пример реального URL с сайта Booking.com для посуточного бронирования жилья.

Справа вы увидите фрагмент парсинга URL из Nginx. L7 DDoS - это не вся история. В URL могут поступать инъекционные атаки, которые важно разбирать и анализировать. Если мы хотим фильтровать web атаки, то должны применять сложную, но очень быструю, логику анализа HTTP.
На этом слайде показан вывод perf для Nginx под HTTP flood c большим URL из примера выше.

HTTP/{2,3} Decoders
К сожалению, в HTTP/2 и в QPACK в HTTP/3 используется Алгоритм сжатия Хаффмана — Huffman encoding. Так как он работает не с байтами, а с битами, то при работе с ним мы не можем использовать векторное расширение процессора.

Следующий алгоритм, который используется в HTTP/2 — это динамическая таблица компрессии. Работает она следующим образом. Например, мы шлем большой User-Agent размером несколько килобайт. Клиент один раз отправляет такой user agent, мы сохраняем его и сообщаем, что присвоили ему dynamic ID, например, 1. В следующий раз когда клиент присылает нам заголовок, и вместо всего тела приходит только ID 1. Так мы понимаем, что к нам пришел тот же User-Agent и мы не тратим время и ресурсы на новую загрузку.
Казалось бы, это эффективная компрессия, но если клиент пришлет не один, а сотни запросов с десятками таких запросов, то на сервере при их распаковке в HTTP/1.1 произойдет DoS.
Такая атака была популярна в 2016 году, когда большинство серверов перешли на HTTP/2. Эту атаку частично исправили лимитами, но это не отменяет факта, что HTTP/2 очень прожорлив не только к вычислительным ресурсам, но и к памяти.
Кроме того, HTTP/2 компрессия хорошо работает только с запросами, потому что она распространяется только на HTTP-заголовки. В HTTP ответах и Post-запросах основную часть данных составляют тело запроса и ответа, поэтому ощутимых преимуществ не будет.

Когда HTTP/2 только появился, большинство серверов использовали HTTP/1, соответственно, HTTP/2 сначала просто декодировался в HTTP/1.1 и отправлялся в имеющуюся логику HTTP/1.Сейчас это в большинстве реализаций оптимизировали, но такой код ещё можно встретить.
Например, snippet из Nginx, где cookies — header, который статически индексируется. Это означает, что мы априори знаем его индекс, и поэтому могли бы сравнивать два int, но в теле сервера всё равно сравниваются строки.
Tempesta тоже изначально сделана для HTTP/1, но мы при работе над HTTP/2 полностью переписали HTTP/1 логику.
H2O не умеет кэшировать контент, а мы умеем, и кэшируем его в своем бинарном формате внутри баз данных. Бинарный формат очень быстро трансформируется в HTTP/2, поэтому передать контент по HTTP/2 быстрее, чем по HTTP/1.
Web Caching
Существует много вариантов политик, в соответствии с которыми контент кэшируется или нет.

Например, GET может быть на самом деле не идемпотентным. Если он обращается по определённому URL и в этом URL происходит какое-то действие на сервере, мы не должны кэшировать такие запросы. POST, наоборот, может быть идемпотентным.

Есть политики, определяющиеся Cache-Control, но интересный топик здесь кэшируем ли мы Set-Cookie или нет? Ведь в этом заголовке могут быть чувствительные к безопасности данные.

Все сервера разрешают кэшировать ответы с Set-Cookie, но если они чувствительны с точки зрения безопасности, то требуют обязательно устанавливать Cache-Control. Стоит помнить, что не все серверы кэшируют ответы Set-Cookie.

Было обсуждение, можно ли вообще разрешать кэшировать POST. RFC документация разрешает, но только для кэширования на последующие GET.
Интересный пример у eBay (ссылка на блок eBay 2012 г.). POST им понадобился, чтобы отправлять запросы в базу данных. У них достаточно большие каталоги с большим количеством параметров, и они легко могли превысить 2-4 кБ запрос при использовании GET. В свою очередь промежуточные proxy-серверы могли обрезать такие запросы по лимитам на URI по размеру. Соответственно, они отправляют идемпотентные по своей сути кэшированные POST запросы, но при этом осуществляют обычной поиск в базе.
Proxy-сервер внутри кэша должен учитывать, сколько времени ответ будет оставаться валидным. HTTP позволяет управлять запросами клиента о том, какой ответ считать валидным, а какой нет, с учётом прошедшего времени.

Интересно, что HTTP сервера могут отдавать невалидные, уже протухшие ответы из кэша, но при этом параллельно запускать запросы на upstream сервер, чтобы получить актуальную версию.
Серверный HTTP/2 PUSH для HTTP proxy. Если мы, например, отправим запрос на индексный HTML, который зависит от CSS, то, зная это, HTTP/2 сервер может сразу запушить CSS клиенту. Proxy этого не знает, но мы все равно можем сделать серверный PUSH с нашего web-proxy. Когда сервер получает запрос, он в своем ответе может добавить хэдер link. Тогда в этом хедере будет прописан CSS-ресурс, от которого зависит ответ. А proxy-сервер распарсит этот заголовок, ведь у него CSS в кэше и он сразу способен сделать PUSH CSS и HTML клиенту.

Early Hints. Это еще одна доступная в H2O оптимизация. Рассмотрим ситуацию, когда на upstream крутится тяжелая логика, и достаточно долгое время upstream тратит на генерации контента. Первый раз, когда proxy получит ответ с link хедером, это будет уже через некоторое, долгое, время.
Вместо этого upstream может получить запрос на индексную страницу, понять, что есть зависимость, и отдать ответ сразу proxy-серверу. В свою очередь proxy-сервер сразу отдаст CSS из кэша, и потом, когда передаст основной контент, запустит процесс дальше.

Заголовок Vary говорит о возможности передавать контент разных типов. Не буду здесь подробно останавливаться, скажу только, что Vary — это по сути вторичный индекс в БД. То есть первый ключ по URI, вторичный ключ по Vary-заголовкам. Кэширующие сервера типа Tempesta FW и Apache Traffic Server используют in-memory СУБД для хранения веб кэша, что позволяет эффективнее работать с вторичными ключами, заголовком Vary в данном случае.

Большинство HTTP-прокси используют обычную файловую систему для хранения кэша. Varnish здесь достаточно уникален: использует динамическую память mmap либо malloc. Она, к сожалению, не консистентная, соответственно, как только перезапустили Varnish, весь кэш теряется. У Varnish есть и persistent storage, который deprecated и применять его нежелательно.
Есть альтернатива — это легковесная СУБД. Она быстрее обычных файлов. Насколько я знаю, только Apache Traffic Server и Tempesta построены с такой СУБД.
С mmap в Varnish есть проблема, которую достаточно давно описали в блоге на BBC.

Проблема заключается в большом железе. У BBC было очень много ядер, очень много памяти, и еще больше дисков. Что происходило? Виртуальная память в Linux управляется страницами, страницы лежат в списках. Поскольку рабочий набор в оперативной памяти намного меньше диска, приходилось часто подкачивать страницы с диска. Поскольку Linux старается полностью утилизировать оперативную память, нужно было вытеснить из оперативной памяти одну из страниц, чтобы поставить на ее место какую-то другую с диска. Получается, мы должны были постоянно ходить по большим спискам. Проблема упирается в lock contention (конфликт блокировки, когда один процесс или поток пытается получить блокировку, удерживаемую другим процессом или потоком) на списке страниц.
Когда-то я даже делал презентацию на Percona Live и рассказывал о нашем опыте построения БД на mmap, которая тоже не прошла по консистентности. А даже если бы мы решили проблему консистентности, не прошли бы по перформансу.

Requests coalescing. Еще одна фича - слияние запросов. Например, в случае Varnish у вас холодный кэш, а к вам приходит 100 запросов на один ресурс, которые вы должны сразу передать бэкенду. Некоторые proxy-сервера, т.к. Varnish, могут выявлять одинаковые запросы и отправлять только один из них серверу, а 100 копий возвращать клиенту.
Network I/O & Multitasking
Это достаточно старая табличка с ApacheConf, но в ней интересно показано, как Varnish работает с тредами (я ее расширил данными по Tempesta FW).

Треды в Varnish реализованы так, чтоб на один запрос и на один стрим использовался один отдельный поток. Если тысяча запросов поступила параллельно на Varnish — тысяча потоков заработало.
Tempesta работает в Softirq, там нет ни процессов, ни потоков.

В чем недостаток потоков? В том, что каждый поток — это по сути процесс в операционной системе, он тоже расходует страницы памяти. Около шести страниц уходят на один поток, а системный планировщик работает за логарифмическое время. Но даже если у нас тысяча потоков, то логарифм для тысячи — совсем небольшое число и планировщик отрабатывает достаточно быстро.
Как только в модели процессов Web accelerator возникает тяжелая логика, часть запросов может выпадать. Если на виртуалке всего 8 процессов и на неё направят 8 медленных запросов, то остальные застопорятся, потому что окажутся в очереди на обработку. В данном случае потоки более выгодны, потому что вместо очереди на Web Accelerator будет параллелизм.
Все современные ядра Linux компилируются с KPTI, который борется с Meltdown атакой. В этом случае возникает деградация производительности до 40% для user-space процессов из-за более дорогих системных вызовов (lazy TLB оптимизации, можно считать, больше нет). В случае Tempesta мы работаем в ядре в контексте TCP/IP стека, соответственно для нас это не актуально и у нас нет оверхеда, связанного с KPTI.
Epoll. Посмотрим, как работает API мультиплексированного ввода-вывода Epoll, предоставляемого Linux для приложений, и что в этом случае происходит в ОС.

Три пакета поступают на сетевой адаптер, раздаются в softirq, раскладываются по очередям в сокетах.

Побуждается прикладной процесс в user space:

Процесс вычитывает запрос из сокета, формирует ответ из кэша и отдает клиенту:

У кэша достаточно большая и тяжелая структура данных. Из-за этого с большой вероятностью, когда мы будем читать следующий запрос из сокета, его уже не будет в кэшах процессора. Кэши процессора работают не очень оптимально, поэтому в Tempesta мы все запросы обрабатываем сразу в softirq, пока они еще в кэшах процессора.
Zero-copy отправка. Её, в виде системного вызова vmsplice(), используют далеко не все proxy-сервера — насколько я знаю, только HAProxy.

Эта техника двойную буфферизацию для передачи контента файлов, минуя user space. Это работает только для тела ответа. Если вы хотите передавать еще и большие заголовки zero-copy, то это повлечет за собой накладные расходы двух системных вызовов. Соответственно, такая техника имеет смысл, только если вы отправляете большие данные, а в среднем - это просто дополнительный оверхед.
Если посмотреть, что происходит с копированиями на proxy-серверах, то увидим несколько копирований из kernel space в user space.
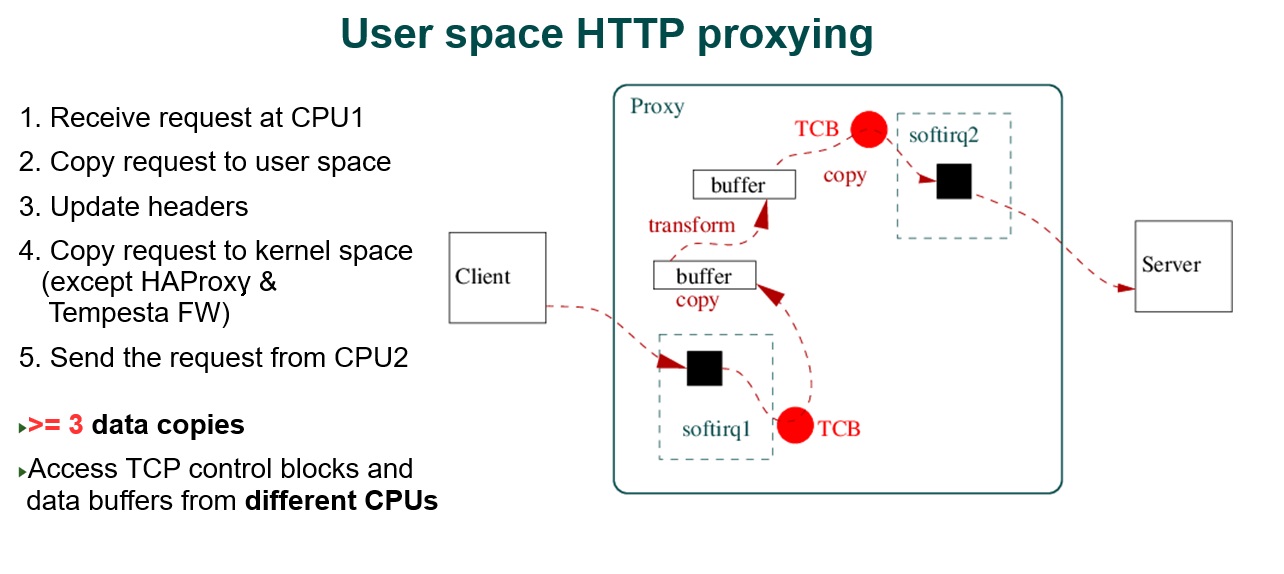
HTTP запрос копируется из ядра в user space, трансформируется с копированием в новый буфер, потом копируется обратно в ядро на отправку и, возможно, отправляется уже с другого процессора. Здесь, мы должны взять блокировку сокета на другом процессоре и данные запроса будут проходить через шину и кэши другого процессора. Так у нас получится минимум три копии данных и lock contention.
В Tempesta между процессорами нам доступно быстрые inter-CPU коммуникация.

Работает он на Lock-free буферах per-CPU. Соответственно, на локальном процессоре мы полностью обрабатываем запрос. Если нам нужно его отправить с другого процессора, мы ставим указатель на этот запрос в ring buffer другого процессора. Это будет быстрая операция и уже другой процессор будет отвечать за отправку.
TLS

Как правило, HTTP сервера отвечают за TLS терминацию в контексте своего основного процесса. Только Varnish отличается тем, что по сути перед Web accelerator стоит еще одна proxy — TLS- termination Hitch, который снимает TLS и отправляет в Varnish plain text запрос. Происходит это не очень быстро.
Varnish в платной версии разрабатывает TLS, который работает в контексте процесса, как и в других прокси. В Tempesta есть своя быстрая реализация TLS, которая на 40-200% превосходит по производительности OpenSSL и WolfSSL.

Zero-copying TLS. Nginx хранит кэш на файлах. Если у нас шифрованное соединение, то мы уже не сможем отправить контент, минуя user space, прямо с файла в сокет внутри ядра. Мы должны сначала этот файл скопировать в user space, там его зашифровать, скопировать снова в ядро, и уже там передать в сокет клиенту.
Facebook этим озаботился вместе с Mellanox и разработали kTLS. Он при, условии готовности крипто-контекста и установленного хендшейка, передает ключевой материал в ядро, а ядро может зашифровать страницы, передаваемые в sendfile() и отправить их сразу в сеть, минуя user space.
Но работает это снова только для HTTP/1: в HTTP/2 нам уже нужен фрейминг и снова zero-copy не работает. Возможно, это причина почему до сих пор kTLS не заехал в основную ветку Nginx. Кроме того, kTLS ничего не знает о TCP.

Проблема в том, что TLS работает с записями по умолчанию в 16 кБ. Это приводит к двум проблемам:
16 кБ — это более, чем в 10 раз больше, чем MTU для передачи по Internet в 1,5 кБ. То есть один TLS record режется более, чем на 10 TCP-сегментов.
Принимающая сторона не может начать дешифровку, пока у нее нет TLS record трейлера. В трейлере у нас лежат аутентификационные данные, необходимые для процесса дешифровки. Соответственно, при новом TCP соединение работает медленный старт, маленький congestion window и мы отправляем только пачку TCP сегментов от TLS record на принимающую сторону, а затем отправляем следующую порцию. То есть у нас происходит несколько отправок до того, как мы начинаем расшифровывать TLS record.

Из-за этого у опенсорс-серверов есть особенности эвристики: они начинают отправку TLS records в новых TCP соединения нет с 16 кБ, а начинают, например, только с 3 кб. У всех разные алгоритмы того, как будет работать TCP, но принцип примерно такой.
В Tempesta мы работаем в контексте TCP/IP stack, соответственно, точно знаем текущее состояние всех окон TCP и можем генерировать оптимальный размер TLS record в зависимости от состояния. А QUIC по сути свободен от данной проблемы, потому что работает в контексте UDP, одна UDP — это один TLS record в QUIC.
Полезные ссылки
Kernel HTTP/TCP/IP stack for HTTP DDoS mitigation, Alexander Krizhanovsky, Netdev 2.1;
HTTP Strings Processing Using C, SSE4.2 and AVX2, Alexander Krizhanovsky;
Fast Finite State Machine for HTTP Parsing, Alexander Krizhanovsky;
Reorganizing Website Architecture for HTTP/2 and Beyond, Kazuho Oku;
Server Implementationsof HTTP/2 Priority, Kazuhiko Yamamoto;
NGINX structural enhancements for HTTP/2 performance, CloudFlare.
P.S. Контакты Александра Крижановского:
ak@tempesta-tech.com
LinkedIn: alexander-krizhanovsky
Twitter: @a_krizhanovsky
https://tempesta-tech.com
Очередная конференция Saint HighLoad++ пройдет 22 и 23 сентября 2022 в Санкт-Петербурге. Подробное расписание, программа и билеты по ссылке.
Напоминаем, что 9 августа пройдет офлайн встреча с программным комитетом HighLoad++ 2022 в Москве, подробности и регистрация тут.
