Привет, Хабр! Эта статья о том, как тестируют компиляторы. Она будет интересна разработчикам и тестировщикам компиляторов, а также всем, кто тестирует сложные технологии. Разберём проблемы тестирования LuaJIT и подходы к решению: неструктурированный фаззинг, синтаксический, семантический, сравнительный фаззинги и тестирование оптимизаций. Статья написана на основе доклада Сергея Бронникова из Tarantool на конференции HighLoad++.

Tarantool — база данных, платформа для in-memory вычислений. Бизнес-логика в Tarantool описывается с помощью языка Lua. В качестве рантайма используется собственный форк LuaJIT — среда исполнения для Lua версии 5.1, которая работает гораздо быстрее других реализаций. LuaJIT также включает в себя трассирующий JIT-компилятор.
Если сравнивать производительность LuaJIT с другими реализациями Lua, то можно сказать, что LuaJIT с выключенной JIT-компиляцией работает в 2-4 раза быстрее PUC Rio Lua, и в 2-100 раз быстрее с включенной. Мультипликатор 100 достигается только в случае математических и синтетических вычислений. Код LuaJIT распространяется свободно под лицензией MIT.
LuaJIT — нишевая технология, которая используется в продуктах крупных компаний — в телекомах (Cisco и Qualcomm), агрегаторах рекламных сетей (Iponweb), базах данных (Tarantool), антифроде (Cloudflare) и даже текстовых редакторах (NeoVim).
Проблемы тестирования LuaJIT
LuaJIT — сложная в реализации технология, требующая аккуратного, дотошного тестирования.
Одна из проблем LuaJIT в том, что у него нет собственного набора тестов, который помог бы обнаружить проблемы и ошибки. Кроме того, основной автор LuaJIT, Майк Пол (Mike Pall), не добавляет тесты для новых изменений в коде LuaJIT. Поэтому, несмотря на все усилия по тестированию форка LuaJIT в Tarantool, в процессе эксплуатации Tarantool выявляются неприятные баги.
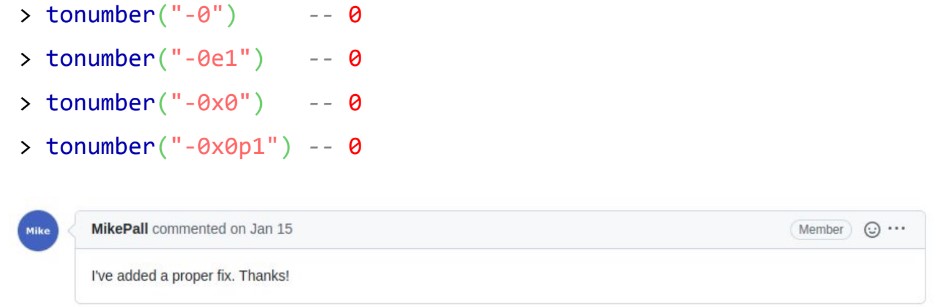
Расскажу об одном из примеров такого бага. В Lua есть функция tonumber, она конвертирует строку в число. Если с помощью функции сконвертировать строку “-0.0” в число, то получится -0. Баг заключался в том, что если сконвертировать строку “-0”, то получится 0 уже без знака, что некорректно. Баг появился в баг-трекере LuaJIT под номером #528, его Майк Пол закрыл в 2019 году с комментарием: «Спасибо, я исправил».
Пример бага: LuaJIT#528

Но спустя два года появился тот же самый баг, для которого наш разработчик приложил патч с исправлением. Майк закрывает пулл-реквест со словами “Я добавил правильный фикс, спасибо!”.
Опишу ещё один пример бага с кодом для воспроизведения чуть посложнее. Если в цикле выполняются манипуляции над строками, в частности, поиск одной строки в другой, то в какой-то момент LuaJIT возвращает неправильную позицию начала подстроки в строке. Баг был исправлен.
Пример бага: LuaJIT#505

Тестирование LuaJIT в Tarantool
Мы в Tarantool вкладываем много сил в тестирование LuaJIT, чтобы как можно меньше багов попадало в публичные версии. Для этого мы используем регрессионные тесты из референсной реализации Lua, тест-сьют lua-Harness от Франсуа Перра, собственные тесты для LuaJIT. Запускаем полный цикл тестирования для каждого изменения в свой форк LuaJIT.
Благодаря такому расширенному набору тестов покрытие кода составляет 78% по строкам и 67% по ветвлениям. К сожалению, этого недостаточно и неприятные баги всё еще появляются в ходе эксплуатации.
Тестирования всё ещё недостаточно!
Принципиальные подходы к тестированию LuaJIT
Прежде чем перейти к рассмотрению подходов к рандомизированному тестированию компиляторов и LuaJIT я хотел бы отметить доклад Антона Солдатова, который он делал в 2018 году на Highload. В нём он системно рассказывает, как они с командой работали над улучшением тестирования форка LuaJIT в IponWeb и использовали для этого обычные тесты на основе примеров. Обязательно посмотрите, если интересуетесь темой.
Если рассматривать стандартные подходы к тестированию систем и LuaJIT в частности, то тесты можно разделить на две категории: те, что делаются на основе примеров и рандомизированное тестирование.
Тесты на основе примеров
Это так называемое example-based тестирование, когда заранее известно, какие данные передадут в программу и какое поведение программы стоит ожидать. Такой подход хорошо описывается паттерном Arrange – Act – Assert: подготовили данные, проверили, что поведение. При каждом запуске теста используются одни и те же входные и выходные данные от запуска к запуску. Все регрессионные тесты для LuaJIT написаны с использованием такого подхода.
Рандомизированное тестирование
Это тестирование неизвестного - заранее неизвестно, какие данные попадут в программу. Такой подход идеален для тестирования компиляторов, потому что он позволяет найти данные для таких тестовых случаев, которые человек при разработке мог не учесть.
В некоторых научных работах описывают рандомизированное тестирование для референсной реализации Lua, но, к сожалению, особого успеха в этом не достигли. Есть простой фаззер в репозитории OSS-Fuzz для референсной реализации Lua, который нашел несколько багов (по состоянию на май 2023 года в OSS Fuzz там используется мой набор тестов).
Если упростить схему фаззинга, то она будет выглядеть так:

Генератор входных данных каждый раз создаёт новые данные для передачи в программу и проверяет выполнение некоторых инвариантов для неё. Если инварианты нарушаются, то, скорее всего, выявлена аномалия, которая может быть багом.
Более детально схема фаззинга выглядит так:

Словарь — это список ключевых слов, которые могут иметь специальные значения для программы. Корпус — входные данные, при передаче которых программа должна вести себя корректно. Мутационный движок на каждой итерации изменяет эти данные. Далее корпус и словарь передаются в программу, результаты анализируются, проверяются на соответствие инвариантам и далее обратная связь передаётся в мутационный движок. Для этого используют тестовые оракулы, такие как SMT-решатели, санитайзеры или логические проверки. В результате этих манипуляций в какой-то момент должны обнаружиться баги.

Результаты исследований касаются именно рандомизированного тестирования референсной реализации Lua, а не LuaJIT. В первой работе описывается только один минорный баг, который заключался в неправильном приведении типа данных.
Рассмотрим подходы к рандомизированному тестированию компиляторов. К ним относятся неструктурированный, синтаксический, семантический и сравнительный фаззинг, а также тестирование оптимизаций.
Неструктурированный фаззинг

Входными данными может быть текст из корпуса или случайные байты. Мутационный движок меняет данные на уровне байтов, то есть может вставить случайные байты или какие-то удалить.
Тестовый оракул будет проверять, корректно ли ведёт себя программа, не происходит ли аномалий. В качестве тестовых оракулов можно использовать как санитайзеры, вроде Address Sanitizer и других). А ещё можно измерять потребление памяти, чтобы отслеживать аномалии при работе с памятью — например, утечки. Или измерять время, чтобы отслеживать зацикливание в программах и проблемы с производительностью.
Успешные реализации (state of the art)
Среди фаззинг движков наиболее популярны три инструмента:
AFL++ — форк популярного фаззера AFL.
hongfuzz — фаззинг фреймворк.
libFuzzer — C/C++ библиотека для фаззинга из проекта LLVM.
Мы для тестирования LuaJIT используем библиотеку libFuzzer, но, к слову, “обёртки” для libFuzzer можно запускать и под такими движками как honggfuzz и AFL.
Реализация синтаксического фаззинга для LuaJIT
Мы написали фаззер с использованием библиотеки libFuzzer и Lua С API, составили корпус из регрессионных тестов для LuaJIT и сделали словарь ключевых слов на основе грамматики LuaJIT 5.1.
Точно такой же подход используется для тестирования референсной реализации PUC Rio Lua, о которой говорили раньше.
Так выглядит пример входных данных, которые можно получить из фаззера, который сгенерировал файл с набором байт.

Если передать этот файл в LuaJIT, который может принимать как Lua, так и байт-код, он не сможет разобрать входные данные, завершит исполнение и упадёт. Такой баг уже завели в баг-трекере, и автор LuaJIT закрыл его как неприемлемый. Причем он сначала добавил вопрос “Can Lua code be safely sandboxed?” с ответом “Нет.” в FAQ , а потом закрыл тикет со ссылкой на FAQ.
Такие баги неинтересны и лучше их избегать. Для этого надо использовать опцию –only-ascii=1, которая позволяет использовать только ASCII-символы во время мутаций. Вот так выглядит случайная программа, которая получается в ходе нескольких последовательных мутаций:

Это всё ещё программа Lua, но свою структуру она потеряла и поэтому, возможно, уже синтаксически некорректна.
Теперь о плюсах и минусах этого подхода.
Дешевизна и простота реализации фаззера и высокое покрытие. В течение часа можно достичь достаточно высокого покрытия, если аккуратно составить словарь и корпус для фаззера.
Негативное тестирование синтаксического анализатора. Каждый раз всё с большей вероятностью будут получаться некорректные с точки зрения синтаксиса программы, благодаря чему можно негативно протестировать синтаксический анализатор. А ещё из-за своей простоты фаззер может достигать очень высокой скорости тестирования — 261.000 запусков в секунду.
Один из минусов, что с помощью этого подхода нельзя достаточно глубоко погрузиться в LuaJIT — например, триггерить работу компилятора.
Синтаксический фаззинг
Смысл синтаксического фаззинга в том, чтобы в качестве входных данных использовать данные из корпуса или случайное синтаксическое дерево, затем преобразовывать программу из корпуса в структуру AST, мутировать AST согласно грамматике, преобразовывать структуру обратно в программу и передавать на вход компилятору. Это позволит сгенерировать входные данные, которые будут соответствовать синтаксису Lua. В качестве тестовых оракулов используются оракулы из предыдущего подхода.
Успешные реализации
Примеры успешных реализаций с помощью этого подхода:
CSmith — фаззер, который активно используется для тестирования для С/С++ компиляторов. В основном это GCC и Clang из проекта LLVM. С помощью такого фаззера было найдено около 300 реальных проблем в С-компиляторах.
YARPGen — фаззер, похожий по дизайну на CSmith, с помощью него получилось найти ещё около 200 разных проблем.
Реализация синтаксического фаззинга для LuaJIT
Используем, как и в прошлый раз, связку libFuzzer + Lua С API.
Используем libProtobufMutator — библиотеку для мутаций, с помощью которой можно мутировать структуру данных в формате ProtoBuf. Мы описали грамматику для Lua 5.1 в формате Protobuf, написали сериализатор, который принимает на вход структуру Protobuf и транслирует её в конкретную Lua-программу. Сериализация всегда происходит детерминированно: хотя программы получаются “случайные” мы всегда можем сериализовать из AST конкретную программу, если запомним seed number, которое использовали для её генерации в прошлый раз.
В качестве примера можно рассмотреть структуру Protobuf, полученную в ходе тестирования.

Из такой структуры Protobuf можно сгенерировать случайную программу.
Немного о нюансах сериализатора Protobuf, которые нужно иметь в виду: учитывать типы данных в программе, чтобы не появлялись ошибки вроде “attempt to perform arithmetic on a string value” из-за сложения строк или “вычитания” таблиц, избегать вызова несуществующих методов. Отдельно стоит упомянуть проблему с зацикливанием в программах и избегать рекурсивных вызовов функций, бесконечных циклов или циклов с большим количеством итераций. Такие программы приводят к ложным срабатываниям фаззера.
Плюсы и минусы подхода: синтаксический фаззинг позволяет позитивно протестировать синтаксический анализатор. Грамматика позволяет глубже “забраться” в LuaJIT и не дать ему отсеять входные данные на этапе анализа программы. Фаззинг по грамматике обеспечивает гораздо большее разнообразие синтаксически корректных программ. Реализация такого подхода более затратна по времени, чем в предыдущем подходе. У нас первая версия получилась за один месяц работы одного студента. Один из минусов libProtobufMutator заключается в том, что используются примитивные мутаторы и если хочется более изощренных мутаций, то придётся реализовывать их самостоятельно.
Семантический фаззинг
Синтаксические фаззеры мутируют то, как выглядит код, а семантические — меняют то, что код делает.
Первая публикация по этой теме - «Compiler validation via equivalence modulo inputs» авторства Vu Le, Mehrdad Afshar, Zhendong Su. Она написана в 2014 году, на нее ссылаются около 400 других работ.
Принцип этого подхода в том, что в качестве входных данных выступают случайные синтаксически корректные программы. Мутатор изменяет программу без изменения её поведения.
В качестве тестового оракула у нас выступают уже знакомые санитайзеры: ASAN, UBSan и другие. Мы измеряем потребление памяти, время выполнения и дополнительно ко всем этим тестовым оракулам можем использовать динамические проверки из корпуса.
Успешные реализации

Проект FuzzIL это дипломная работа студента, в рамках которой он реализовал фаззер для Javascript. С помощью него было найдено большое количество багов в реализациях компиляторов Javascript.
Реализация семантического фаззинга для LuaJIT

В libFuzzer есть интерфейс для реализации собственных функций, которые будут мутировать данные перед передачей в программу. Мы реализовали такую функцию для libFuzzer, она позволяет реализовывать мутации данных на языке Lua: принимает на вход Lua-программу, преобразует её в абстрактное синтаксическое дерево, случайным образом мутирует AST и сериализует обратно в Lua-программу.
Как могут выглядеть примеры мутаций:

Допустим, у нас есть логическое выражение. Для него мы можем добавить двойное отрицание, которое изменит программу, не изменив семантику.
Для случайного выражения в программе можно создать функцию, которая будет возвращать результат выполнения выражения. Ещё один вариант — “обернуть” случайное выражение в цикл с одной итерацией, которая будет вычислять это выражение. Или вставить функцию, которая запускает сборку мусора, в случайные места программы. Независимо от того, в какой момент времени вызовут сборку мусора, программа должна вести себя корректно.
Такой подход позволяет ещё больше разнообразить набор Lua-программ, которые мы будем передавать в LuaJIT, и более фокусно его тестировать. Можно использовать именно такие мутации, которые мутируют нужные части программы, а другие оставляют без изменений. Этот подход позволяет использовать логические проверки (assert’ы) из корпуса, что дополнительно усложняет тестовые оракулы.
LuaJIT это оптимизирующий компилятор. Поэтому нужно иметь в виду, что он может часть кода cоптимизировать. К примеру, может не вычислять некоторые выражения, если поймёт, что выражение недостижимо (оптимизация dead code elimination).
Ещё один недостаток — с таким подходом существенно снижается скорость фаззинга. Примерно до 500 запусков в секунду.
Сравнительный фаззинг
Первая публикация по этой теме «Differential Testing for Software» автора William M. McReeman была еще в 1998 году и на неё ссылаются около 500 других работ.
В сравнительном фаззинге используют генератор со случайными семантически корректными программами, а в качестве тестового оракула выступает другая и более простая с точки зрения реализации программа. Рассмотрим принципиальную схему подхода:

Есть генератор случайных программ, который генерирует Lua-код. Этот код передаётся в три разные программы. В первом случае это LuaJIT с включенными оптимизациями, во втором случае — LuaJIT с выключенными оптимизациями. А в третьем — референсная реализация Lua. Запустим эти программы и сохраним полученные результаты во всех трёх случаях. Если результаты расходятся, то это аномалия, и, возможно, в одной из реализаций есть баг.
Успешные реализации
Одна из свежих статей описывает фаззер Jit-Picker для языка Javascript, с помощью которого было найдено 32 бага. Этот фаззер использует сравнительное тестирование. Ещё один пример не из области компиляторов: SQLancer используется для сравнительного тестирования реализаций языка запросов SQL в СУБД и cryptofuzz используется для проверки криптографических библиотек — сравнивает результаты выполнения криптографических примитивов с помощью сравнительного тестирования. С помощью cryptofuzz удалось найти 160 багов.
Проект Nezha — не конкретный проект по тестированию какой-то одной программы, а движок для сравнительного тестирования. И проект DeepXPLore позволяет с помощью сравнительного тестирования сравнивать модели машинного обучения.
Реализация подхода для LuaJIT
Для LuaJIT использовали libFuzzer и Lua С API. В качестве тестовых оракулов — референсную реализацию Lua, LuaJIT с выключенной оптимизацией, санитайзеры, потребление памяти и время выполнения.
У этого подхода есть преимущества — простота реализации теста и возможность найти проблемы в деталях реализации за счёт того, что разные реализации программы разработаны независимыми группами разработчиков.
К сожалению у подхода есть недостаток - его не получится применить когда, например, используется достаточно редкий язык, для которого нет альтернативной реализации компилятора или интерпретатора.
Еще один минус, который я бы хотел отметить, это ложноположительные срабатывания. Когда мы сравниваем результаты, то одна программа выдаёт предположительно неправильный результат, но мы повлиять на это не можем, а разработчики не считают это багом. Такую реализацию скорее всего не получится использовать для сравнения с другими.
Тестирование оптимизаций

В качестве входных данных используем генератор семантически корректных программ. Во время выполнения программы экспортируем байт-код и промежуточное представление (IR, imtermediate representation) этой программы в компиляторе с включенными оптимизациями и в компиляторе с выключенными оптимизациями. Потом транслируем байт-код и промежуточное представление в логические формулы. Получаем логическую формулу для программы с включенными и выключенными оптимизациями. С помощью SMT-решателя проверяем обе формулы на эквивалентность. Какие бы оптимизации компилятор не использовал, корректность её выполнения не должна измениться.
Найти первую публикацию, которая впервые описывает такой подход было непросто. Думаю, что статья «TVOC: A Translation Validator for Optimizing Compilers» авторов Crack Barrett, Yi Fang, Benjamn Goldberg, Ying Hu, Amir Pnueli & Lenore Zuck от 2005 года может претендовать на первенство, потому что описывает достаточно близкие идеи.
Успешные реализации
Пара успешных примеров реализации — это проекты Alive/Alive2, которые используются для тестирования компилятора Clang из проекта LLVM. При тестировании его оптимизаций нашли порядка 70 багов.
Будет интересно рассказать причину появления Alive. Авторы, которые разработали упомянутый выше фаззер CSmith, нашли много багов в Clang. А потом заметили, что большинство обнаруженных проблем находятся в реализации оптимизации InstCombine (instruction combine). Код с реализацией оптимизации InstCombine включает в себя более 20 KLOC строк. Этот факт усугублялся тем, что реализация оптимизации было сложной, семантика LLVM IR хрупкая и к тому же сложно отличить корректное поведение оптимизации от некорректного. Они искали способ, которым могли бы более фокусно тестировать корректность оптимизаций компилятора. Так из идеи родился проект Alive (см. слайды “Alive: Provably Correct InstCombine Optimizations”), который потом трансформировался в Alive2 (см. “Alive2 Verifying existing optimizations”).
Реализация такого подхода есть для JIT-компилятора Python, для компилятора языка описания контрактов в Solidity и для проверки эквивалентности запросов на языке SQL до и после оптимизации в проекте Cosette.
Похожий проект есть и для GCC - pysmt-gcc. У него не такие масштабы как в случае с Alive/Alive2, так как им занимается всего один человек, но с его помощью он уже нашёл 8 багов в GCC. Вот пример бага от pysmtgcc, найденного в GCC (#106523 “forwprop miscompile”). Он заключается в том, что функция, выполняющая побитовые операции (сдвиги и побитовое логическое И) над парой чисел, иногда возвращает некорректный результат. В примере ниже функция f7 ведёт себя корректно с парами чисел 1, 6 и 7, 4, но возвращает некорректный результат для пары 152, 19.
Пример бага pysmtgcc:

К слову, на момент написания статьи баг GCC#106523 всё ещё не был исправлен.
Реализация тестирования оптимизаций для LuaJIT

LuaJIT можно использовать как с полностью выключенными оптимизациями, так и оптимизациями на максимальном уровне. Выполняем программу в LuaJIT с включенными и выключенными оптимизациями, экспортируем LuaJIT IR и транслируем промежуточные представления в SMT -формулы, потом передаём всё это на вход SMT-решателю, например Z3.
Немножко о том, в каком месте в LuaJIT появляются оптимизации:
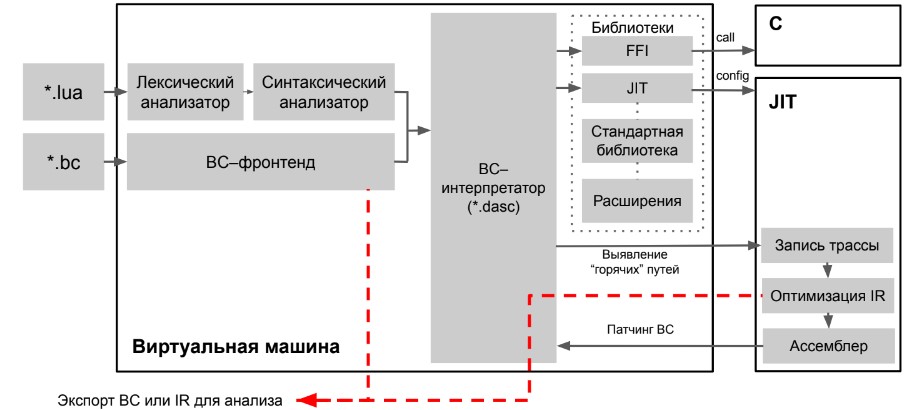
На вход LuaJIT принимает два типа входных данных — Lua-программу или скомпилированный байткод. Всё это передаётся в лексический анализатор, далее синтаксический анализатор и затем поступает в байт-код-интерпретатор. Эта часть называется виртуальной машиной Lua. Если во время выполнения мы обнаруживаем “горячие” участки кода, то начинаем запись трассы. Далее выполняем оптимизации в IR и транслируем в ассемблер для исполнения. Эта часть называется JIT-компилятором. В местах, отмеченных красными стрелками, могут выполняться оптимизации.
Помимо этого в LuaJIT есть ещё встроенные библиотеки. Для нас самый большой интерес представляет модуль jit, который позволяет управлять настройками компилятора:

Эта встроенная библиотека позволяет включать оптимизации, выключать их полностью или более точечно, фокусно влиять на оптимизацию, которую делает компилятор. Например, можно выбрать один конкретный уровень оптимизаций. Или выключить оптимизацию, которая выкидывает мёртвый код. Можно сделать компиляцию более агрессивной и включать компиляцию в циклах, даже если он содержит небольшое количество итераций.
Работу SMT-решателя проще всего продемонстрировать с помощью задачки: нужно найти значение треугольника, чтобы все уравнения выполнялись.

Чтобы решить этот набор уравнений, воспользуемся Python API для SMT-решателя Z3.

Опишем набор уравнений в виде скрипта на Python и попробуем его запустить. SMT-решатель выдаст вердикт, что решение найдено, об этом говорит слово sat, и приведёт набор чисел, при использовании которых этот набор уравнений будет выполняться.
Особенности подхода:
Математически строгий подход.
Фокусное тестирование оптимизаций компилятора.
Сложность в аккуратной трансляции семантики BC/IR в логические формулы — во время трансляции промежуточного представления в логическую формулу нам нужно делать это максимально аккуратно, чтобы соблюсти семантику.
Пример проверки корректности оптимизации в IR
Попробую продемонстрировать подход на примитивном примере. Допустим у нас есть функция на Lua, которая возвращает некоторое число.

Мы выполним эту программу в LuaJIT с O0 и O3 и экспортируем IR в обоих случаях.
Вывод IR для выполнения без оптимизаций (-O0):

Вывод IR для выполнения с включенными оптимизациями (-O3):

Теперь надо транслировать вывод IR в логические формулы. В мире SMT-солверов есть универсальный формат, который понимают большинство из них - это SMT-LIB, поэтому транслировать мы будем именно в него. LuaJIT IR представлен в виде SSA (Static single assignment), то есть каждой переменной значение присваивается лишь единожды. Такая форма упрощает трансляцию в SMT-LIB, но нужно соблюдать три правила:

В первом случае (без оптимизаций) мы получим такой код:

Во втором случае (с оптимизациями) мы получим такой код:

Теперь попробуем проверить на эквивалентность обе формулы:

Заключение
Фаззинг — это сложно, потому что нужно учитывать большое количество деталей.
Фаззинг — это хорошо, потому что дополняет стандартные тесты, а в некоторых случаях даже заменяет их.
А ещё фаззинг позволяет полностью автоматизировать тестирование, избавившись от участия людей. Человек нужен только во время анализа результатов, да и эту стадию тоже можно частично автоматизировать.
Результаты
Баги, которые мы нашли в LuaJIT с помощью фаззинга собраны в списке на этой странице - https://github.com/tarantool/tarantool/wiki/Fuzzing#trophies. Так как LuaJIT и PUC Rio Lua имеют один и тот же C API, то одни и те же тесты можно использовать для тестирования обеих реализаций Lua. Те же самые тесты, что и для LuaJIT, используются для тестирования PUC Rio Lua и за первые дни их использования с помощью этих тестов получилось найти 17 багов, два из них отмечены как security-проблемы. Такой результат красноречиво свидетельствует о пользе, которую фаззинг-тестирование может принести в проекте.

