
Hello world!
Представляю вашему вниманию третью часть практического руководства по Rust.
Другой формат, который может показаться вам более удобным.
Руководство основано на Comprehensive Rust — руководстве по Rust от команды Android в Google и рассчитано на людей, которые уверенно владеют любым современным языком программирования. Еще раз: это руководство не рассчитано на тех, кто только начинает кодить 😉
В этой части мы рассмотрим следующие темы:
- управление памятью, времена жизни (lifetimes) и контроллер заимствований (borrow checker): безопасность памяти
- умные указатели (smart pointers): типы указателей стандартной библиотеки
Материалы для более глубокого изучения названных тем:
- Книга/учебник по Rust (на русском языке) — главы 4, 10 и 15
- rustlings — упражнения 06, 16 и 19
- Rust на примерах (на русском языке) — примеры 15 и 19
- Rust by practice — упражнения 5 и 17
Также см. Большую шпаргалку по Rust.
Управление памятью
Обзор памяти программы
Программы выделяют (allocate) память двумя способами:
- стек (stack): непрерывная область памяти для локальных переменных
- значения имеют фиксированный размер, известный во время компиляции
- очень быстрый: просто перемещаем указатель стека (stack pointer)
- легко управлять: следуем за вызовами функций
- отличная локализованность памяти (память находится в одном месте)
- куча (heap): хранилище значений за пределами вызовов функций
- значения имеют динамический размер, определяемый во время выполнения
- немного медленнее, чем стек: имеются некоторые накладные расходы
- нет гарантии локализованности памяти
Пример
Создание String помещает метаданные фиксированного размера в стек и данные динамического размера (настоящую строку) в кучу:
fn main() {
let s1 = String::from("Привет");
}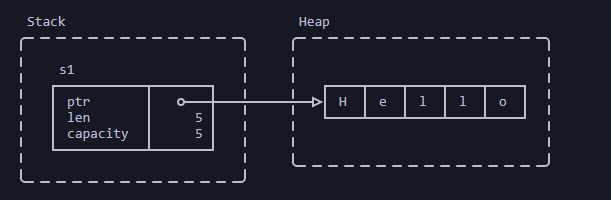
Мы можем исследовать память, но это совершенно небезопасно:
fn main() {
let mut s1 = String::from("Привет");
s1.push(' ');
s1.push_str("всем");
// Только для целей обучения.
// Это может привести к непредсказуемому поведению
unsafe {
let (ptr, capacity, len): (usize, usize, usize) = std::mem::transmute(s1);
println!("ptr = {ptr:#x}, len = {len}, capacity = {capacity}");
}
}Подходы к управлению памятью
Традиционно, языки программирования делятся на 2 категории:
- полный контроль через ручное управление памятью: C, C++, Pascal и др.
- когда выделять и освобождать память в куче решает программист
- программист определяет, указывает ли указатель на валидную память
- опыт показывает, что программисты совершают ошибки
- полная безопасность через автоматическое управление памятью во время выполнения:
- система обеспечивает, что память не освобождается до тех пор, пока на нее имеются ссылки
- обычно реализуется с помощью подсчета ссылок (reference counting), сборку мусора (garbage collection) или RAII
Rust предлагает новый подход — полный контроль и безопасность во время компиляции обеспечивают правильное управление памятью.
Это делается с помощью владения (ownership).
- в
Cуправление памятью осуществляется с помощью функцийmallocиfree. Часто ошибки заключаются в не вызовеfree, ее многократном вызове или разыменовании указателя на освобожденный ресурс C++предоставляет инструменты, такие как умные указатели (unique_ptr,shared_ptr), которые автоматически вызывают деструкторы для освобождения памяти после возврата значения из функции. Однако это решает далеко не все проблемыCJava,Go,Python,JavaScriptи др. полагаются на сборщик мусора (garbage collector) в определении неиспользуемой памяти и ее освобождении. Это позволяет избежать багов, связанных с разыменованием указателей на освобожденные ресурсы и т.п. Однако GC имеет свою цену времени выполнения и его сложно настраивать
Модель владения и заимствования Rust позволяет добиться производительности C без свойственных ему проблем с безопасностью памяти. Rust также предоставляет умные указатели, похожие на умные указатели C++. Доступны и другие варианты, такие как подсчет ссылок. Существуют даже сторонние крейты, поддерживающие сборку мусора во время выполнения (мы не будем их рассматривать).
Владение
Все привязки переменных имеют свою область видимости (scope). Попытка использовать переменную за пределами ее области видимости приводит к ошибке:
struct Point(i32, i32);
fn main() {
{
let p = Point(3, 4);
println!("x: {}", p.0);
}
println!("y: {}", p.1);
}Мы говорим, что переменная владеет (own) значением. Каждое значение может иметь только одного владельца.
В конце области видимости переменная уничтожается (dropped), а память освобождается (freed). Здесь может запускаться деструктор для освобождения ресурсов.
GC начинает с корневых узлов (roots) для обнаружения всех достижимых (reachable) объектов. Это похоже на принцип "одного владельца" в Rust.
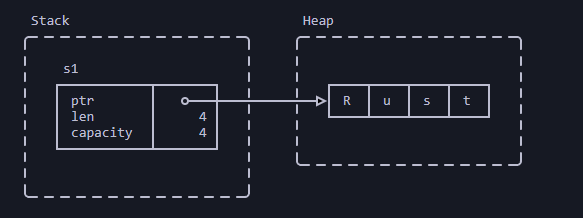
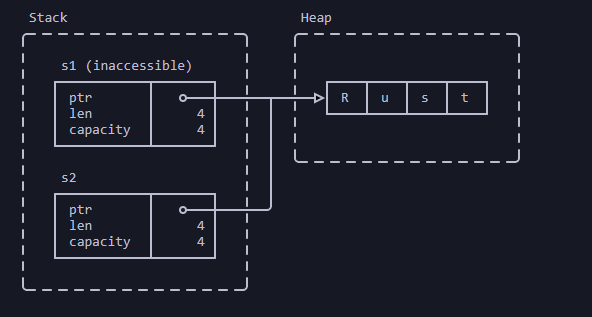
Перемещение
Присвоение перемещает (move) владение значения между переменными:
fn main() {
let s1: String = String::from("Привет");
let s2: String = s1;
println!("s2: {s2}");
// println!("s1: {s1}");
}- Присвоение
s1s2перемещает владение строкой"Привет" - когда
s1выходит за пределы области видимости, ничего не происходит, потому что эта переменная больше ничем не владеет - когда
s2выходит за пределы области видимости, данные строки освобождаются
Перед перемещением владения:
После:
Когда мы передаем значение в функцию, оно присваивается ее параметру, происходит перемещение владения:
fn say_hello(name: String) {
println!("Привет {name}")
}
fn main() {
let name = String::from("Алиса");
// Владение перемещается в `say_hello`
say_hello(name);
// say_hello(name);
}- Вызывая функцию
say_hello, функцияmainпередает ей владение значениемname. После этогоnameбольше не может использоваться вmain - память, выделенная в куче для
name, будет освобождена после вызоваsay_hello mainможет сохранить владение значениемname, если передаст вsay_helloссылку на него (&name), и параметром, принимаемымsay_hello, будет ссылка (name: &String)- вторым вариантом является передача
say_helloкопии/клонаname(name.clone()) - в
Rust, в отличие отC++, копии значений чаще всего приходится создавать явно
Clone
Иногда нам нужно создать копию значения. Для этого предназначен трейт Clone:
#[derive(Default)]
struct Backends {
hostnames: Vec<String>,
weights: Vec<f64>,
}
impl Backends {
fn set_hostnames(&mut self, hostnames: &Vec<String>) {
// Вектор реализует трейт `Clone` по умолчанию
self.hostnames = hostnames.clone();
self.weights = hostnames.iter().map(|_| 1.0).collect();
}
}Идея Clone заключается в том, чтобы облегчить определение места распределения кучи.
Клонирование часто используется для быстрого решения проблем, связанных с владением и заимствованием, с последующей оптимизацией за счет их удаления.
Копируемые типы
Хотя семантика перемещения используется по умолчанию, некоторые типы по умолчанию копируются:
fn main() {
let x = 42;
let y = x;
println!("x: {x}"); // переменная `x` не была бы доступной без копирования
println!("y: {y}");
}Такие типы реализуют трейт Copy.
Мы можем сделать так, чтобы наши типы использовали семантику копирования:
#[derive(Copy, Clone, Debug)]
struct Point(i32, i32);
fn main() {
let p1 = Point(3, 4);
let p2 = p1;
println!("p1: {p1:?}");
println!("p2: {p2:?}");
}- После присвоения
p1иp2владеют собственными данными - мы также можем использовать
p1.clone()для явного копирования данных
Копирование и клонирование — это разные вещи:
- копирование относится к побитовому копированию областей памяти и не работает с произвольными объектами
- копирование не позволяет использовать собственную логику (в отличие от конструкторов копирования в
C++) - клонирование — это более общая операция, которая также позволяет настраивать поведение путем реализации трейта
Clone - копирование не работает на типах, которые реализуют трейт
Drop
Попробуйте сделать следующее в примере:
- добавьте поле
Stringв структуруPoint. Пример не будет компилироваться, посколькуStringне является копируемым типом - удалите
Copyиз атрибутаderive. При попытке вывести значениеp1в терминал возникнет ошибка - попробуйте клонировать
p1явно
Трейт Drop
Значения, реализующие трейт Drop, могут определять код, который запускается при их выходе за пределы области видимости:
struct Droppable {
name: &'static str,
}
impl Drop for Droppable {
fn drop(&mut self) {
println!("уничтожение {}", self.name);
}
}
fn main() {
let a = Droppable { name: "a" };
{
let b = Droppable { name: "b" };
{
let c = Droppable { name: "c" };
let d = Droppable { name: "d" };
println!("выход из блока B");
}
println!("выход из блока A");
}
drop(a);
println!("выход из main");
}Ремарки:
обратите внимание, что
std::mem::dropиstd::ops::Drop::drop— это разные вещи
значения автоматически уничтожаются при выходе за пределы их области видимости
после уничтожения значения, вызывается его реализация
Drop::drop, если значение реализуетstd::ops::Drop
все поля структуры также уничтожаются, независимо от того, реализуют они
Dropили нет
std::mem::drop— это пустая функция, не принимающая никаких значений. Важно то, что она принимает владение значением, которое уничтожается после ее вызова. С помощью этой функции можно уничтожать значения до того, как они выйдут за пределы их области видимости
- это может быть полезным для объектов, которые выполняют какую-то работу при уничтожении: снятие блокировки (releasing lock), закрытие файла (дескриптора) и др.
Почему
Drop::dropне принимаетself?
- Короткий ответ: в этом случае
std::mem::dropбудет вызвана в конце блока, что приведет к другому вызовуDrop::dropи переполнению стека!
- Короткий ответ: в этом случае
Попробуйте заменить
drop(a)наa.drop()
Упражнение: тип "Строитель"
В этом упражнении мы реализуем сложный тип, который владеет всеми своими данными. Мы будем использовать "шаблон построителя" (builder patterm) для поэтапного построения нового значения с использованием удобных функций.
#[derive(Debug)]
enum Language {
Rust,
Java,
Perl,
}
#[derive(Clone, Debug)]
struct Dependency {
name: String,
version_expression: String,
}
// Представление пакета ПО
#[derive(Debug)]
struct Package {
name: String,
version: String,
authors: Vec<String>,
dependencies: Vec<Dependency>,
// Это поле является опциональным
language: Option<Language>,
}
impl Package {
// Метод для возврата представления пакета как зависимости
// для использования в создании других пакетов
fn as_dependency(&self) -> Dependency {
todo!("1")
}
}
// Строитель пакета. Для создания `Package` используется метод `build`
struct PackageBuilder(Package);
impl PackageBuilder {
fn new(name: impl Into<String>) -> Self {
todo!("2")
}
// Метод установки версии пакета
fn version(mut self, version: impl Into<String>) -> Self {
self.0.version = version.into();
self
}
// Метод установки автора пакета
fn authors(mut self, authors: Vec<String>) -> Self {
todo!("3")
}
// Метод добавления дополнительной зависимости
fn dependency(mut self, dependency: Dependency) -> Self {
todo!("4")
}
// Метод установки языка. Если не установлен, по умолчанию имеет значение `None`
fn language(mut self, language: Language) -> Self {
todo!("5")
}
fn build(self) -> Package {
self.0
}
}
fn main() {
let base64 = PackageBuilder::new("base64").version("0.13").build();
println!("base64: {base64:?}");
let log =
PackageBuilder::new("log").version("0.4").language(Language::Rust).build();
println!("log: {log:?}");
let serde = PackageBuilder::new("serde")
.authors(vec!["djmitche".into()])
.version(String::from("4.0"))
.dependency(base64.as_dependency())
.dependency(log.as_dependency())
.build();
println!("serde: {serde:?}");
}impl Package {
fn as_dependency(&self) -> Dependency {
Dependency {
name: self.name.clone(),
version_expression: self.version.clone(),
}
}
}
impl PackageBuilder {
fn new(name: impl Into<String>) -> Self {
Self(Package {
name: name.into(),
version: "0.1".into(),
authors: vec![],
dependencies: vec![],
language: None,
})
}
fn version(mut self, version: impl Into<String>) -> Self {
self.0.version = version.into();
self
}
fn authors(mut self, authors: Vec<String>) -> Self {
self.0.authors = authors;
self
}
fn dependency(mut self, dependency: Dependency) -> Self {
self.0.dependencies.push(dependency);
self
}
fn language(mut self, language: Language) -> Self {
self.0.language = Some(language);
self
}
fn build(self) -> Package {
self.0
}
}Умные указатели
Box
Box — это собственный указатель на данные в куче:
fn main() {
let five = Box::new(5);
println!("пять: {}", *five);
}Box<T> реализует Deref<Target = T>: мы можем вызывать методы T прямо на Box<T>.
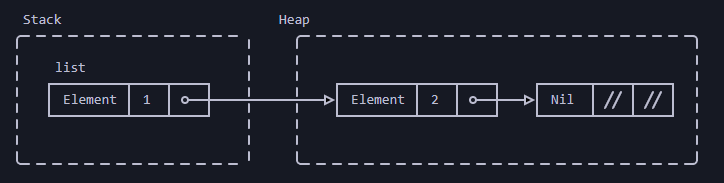
Рекурсивные типы или типы динамического размера должны использовать Box:
#[derive(Debug)]
enum List<T> {
// Непустой список: первый элемент и остальная часть списка
Element(T, Box<List<T>>),
// Пустой список
Nil,
}
fn main() {
let list: List<i32> =
List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}
Ремарки:
Boxпохож наstd::unique_ptrвC++, за исключением того, что он не может иметь значениеNULLBoxможет быть полезным, когда
- у нас есть тип, размер которого неизвестен во время компиляции, а компилятору
Rustнужен точный размер - мы хотим передать владение большого количества данных. Вместо копирования большого количества данных в стеке, мы храним данные в куче в
Boxи перемещаем только указатель
- у нас есть тип, размер которого неизвестен во время компиляции, а компилятору
- если мы попытаемся внедрить
Listпрямо вListбез использованияBox, компилятор не сможет вычислить точный размер структуры в памяти (Listбудет иметь бесконечный размер) Boxрешает эту проблему, поскольку он имеет такой же размер, что обычный указатель и просто указывает на следующий элемент списка в куче- удалите
Boxиз определенияListи изучите ошибку компилятора
Нишевая оптимизация
#[derive(Debug)]
enum List<T> {
Element(T, Box<List<T>>),
Nil,
}
fn main() {
let list: List<i32> =
List::Element(1, Box::new(List::Element(2, Box::new(List::Nil))));
println!("{list:?}");
}Box не может быть пустым, поэтому указатель всегда является валидным и не может иметь значение NULL. Это позволяет компилятору оптимизировать слой памяти:

Rc
Rc — это общий указатель с подсчетом ссылок. Он используется, когда нужно сослаться на одни и те же данные из нескольких мест:
use std::rc::Rc;
fn main() {
let a = Rc::new(10);
let b = Rc::clone(&a);
println!("a: {a}");
println!("b: {b}");
}- В многопоточных контекстах следует использовать Arc и Mutex
- мы можем понизить общий указатель до слабого указателя (Weak) для создания циклов, которые будут правильно уничтожены в свое время
Ремарки:
- счетчик
Rcгарантирует, что содержащееся в нем значение действительно до тех пор, пока существуют ссылки на него RcвRustпохож наstd::shared_ptrвC++Rc::cloneобходится дешево: он создает указатель на одно и то же место в памяти и увеличивает счетчик ссылок. Он не создает глубоких клонов, и его обычно можно игнорировать при поиске в коде проблем с производительностьюmake_mutфактически клонирует внутреннее значение при необходимости ("клонирование при записи" — clone-on-write) и возвращает изменяемую ссылкуRc::strong_countиспользуется для определения количества активных ссылокRc::downgrade(вероятно, в сочетании сRefCell) позволяет создавать объекты со слабым подсчетом ссылок для создания циклов, которые будут правильно удалены в будущем
Упражнение: двоичное дерево
Бинарное дерево (binary tree) — это древовидная структура данных, в которой каждый узел имеет 2 дочерних элемента (левый и правый). Мы создадим дерево, в котором каждый узел хранит значение. Для данного узла N все узлы в левом поддереве N содержат меньшие значения, а все узлы в правом поддереве N — большие значения.
Если задание покажется вам легким и вы быстро с ним справитесь, попробуйте реализовать итератор по дереву, который будет возвращать все значения по порядку.
// Узел дерева
#[derive(Debug)]
struct Node<T: Ord> {
value: T,
left: Subtree<T>,
right: Subtree<T>,
}
// Поддерево, которое может быть пустым
#[derive(Debug)]
struct Subtree<T: Ord>(Option<Box<Node<T>>>);
// Контейнер, хранящий набор значений с помощью двоичного дерева.
// Значение сохраняется только один раз, независимо от того, сколько раз оно добавляется
#[derive(Debug)]
pub struct BinaryTree<T: Ord> {
root: Subtree<T>,
}
impl<T: Ord> BinaryTree<T> {
fn new() -> Self {
todo!("реализуй меня")
}
fn insert(&mut self, value: T) {
todo!("реализуй меня")
}
fn has(&self, value: &T) -> bool {
todo!("реализуй меня")
}
fn len(&self) -> usize {
todo!("реализуй меня")
}
}
impl<T: Ord> Subtree<T> {
fn new() -> Self {
todo!("реализуй меня")
}
fn insert(&mut self, value: T) {
todo!("реализуй меня")
}
fn has(&self, value: &T) -> bool {
todo!("реализуй меня")
}
fn len(&self) -> usize {
todo!("реализуй меня")
}
}
impl<T: Ord> Node<T> {
fn new(value: T) -> Self {
todo!("реализуй меня")
}
}
fn main() {
let mut tree = BinaryTree::new();
tree.insert("foo");
assert_eq!(tree.len(), 1);
tree.insert("bar");
assert!(tree.has(&"foo"));
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn len() {
let mut tree = BinaryTree::new();
assert_eq!(tree.len(), 0);
tree.insert(2);
assert_eq!(tree.len(), 1);
tree.insert(1);
assert_eq!(tree.len(), 2);
tree.insert(2); // дубликат
assert_eq!(tree.len(), 2);
}
#[test]
fn has() {
let mut tree = BinaryTree::new();
fn check_has(tree: &BinaryTree<i32>, exp: &[bool]) {
let got: Vec<bool> =
(0..exp.len()).map(|i| tree.has(&(i as i32))).collect();
assert_eq!(&got, exp);
}
check_has(&tree, &[false, false, false, false, false]);
tree.insert(0);
check_has(&tree, &[true, false, false, false, false]);
tree.insert(4);
check_has(&tree, &[true, false, false, false, true]);
tree.insert(4);
check_has(&tree, &[true, false, false, false, true]);
tree.insert(3);
check_has(&tree, &[true, false, false, true, true]);
}
#[test]
fn unbalanced() {
let mut tree = BinaryTree::new();
for i in 0..100 {
tree.insert(i);
}
assert_eq!(tree.len(), 100);
assert!(tree.has(&50));
}
}Подсказка: для сопоставления с шаблоном при сравнении значений следует использовать std::cmp::Ordering.
impl<T: Ord> BinaryTree<T> {
fn new() -> Self {
Self { root: Subtree::new() }
}
fn insert(&mut self, value: T) {
self.root.insert(value);
}
fn has(&self, value: &T) -> bool {
self.root.has(value)
}
fn len(&self) -> usize {
self.root.len()
}
}
impl<T: Ord> Subtree<T> {
fn new() -> Self {
Self(None)
}
fn insert(&mut self, value: T) {
match &mut self.0 {
None => self.0 = Some(Box::new(Node::new(value))),
Some(n) => match value.cmp(&n.value) {
Ordering::Less => n.left.insert(value),
Ordering::Equal => {}
Ordering::Greater => n.right.insert(value),
},
}
}
fn has(&self, value: &T) -> bool {
match &self.0 {
None => false,
Some(n) => match value.cmp(&n.value) {
Ordering::Less => n.left.has(value),
Ordering::Equal => true,
Ordering::Greater => n.right.has(value),
},
}
}
fn len(&self) -> usize {
match &self.0 {
None => 0,
Some(n) => 1 + n.left.len() + n.right.len(),
}
}
}
impl<T: Ord> Node<T> {
fn new(value: T) -> Self {
Self { value, left: Subtree::new(), right: Subtree::new() }
}
}Заимствование
Заимствование значения
Как мы знаем, вместо передачи владения (ownership) значением при вызове функции, можно позволить функции заимствовать (borrow) это значение:
#[derive(Debug)]
struct Point(i32, i32);
fn add(p1: &Point, p2: &Point) -> Point {
Point(p1.0 + p2.0, p1.1 + p2.1)
}
fn main() {
let p1 = Point(3, 4);
let p2 = Point(10, 20);
let p3 = add(&p1, &p2);
println!("{p1:?} + {p2:?} = {p3:?}");
}- Функция
addзаимствует 2 точки (point) и возвращает новую точку - вызывающий (caller,
main) сохраняет владение точками
Ремарки:
- возврат значения из функции
addобходится дешево, поскольку компилятор может исключить операцию копирования - компилятор
Rustумеет выполнять оптимизацию возвращаемого значения (return value optimization — RVO) - в
C++исключение копирования должно быть определено в спецификации языка, поскольку конструкторы могут иметь побочные эффекты. ВRustэто не проблема. ЕслиRVOне произошло,Rustвыполняет простое и эффективное копированиеmemcpy
Проверка заимствований
Контроллер заимствований (borrow checker) ограничивает способы заимствования значений. Для определенного значения в любое время:
- мы можем иметь одну или более общие/распределенные (shared) ссылки на значение или
- мы можем иметь только одну эксклюзивную/исключительную (exclusive) ссылку на значение
fn main() {
let mut a: i32 = 10;
let b: &i32 = &a;
{
let c: &mut i32 = &mut a;
*c = 20;
}
println!("a: {a}");
println!("b: {b}");
}Ремарки:
- обратите внимание: требование состоит в том, чтобы конфликтующие ссылки не существовали в одно время. Не имеет значения, где ссылка разыменовывается
- код примера не компилируется, поскольку
aзаимствуется как мутабельная (черезc) и как иммутабельная (черезb) одновременно - переместите
println!("b: {b}");перед областью видимостиc, чтобы скомпилировать код - после этого изменения компилятор понимает, что
bиспользуется только до нового мутабельного заимствованияa. Это особенность контроллера заимствований, которая называется "нелексическим временем жизни" (non-lexical lifetimes) - ограничение эксклюзивной ссылки является довольно строгим.
Rustиспользует его, чтобы гарантировать отсутствие гонок за данными (data races).Rustтакже использует это ограничение для оптимизации кода. Например, значение общей ссылки можно безопасно кэшировать в регистре на время ее существования - контроллер заимствований предназначен для использования многих распространенных шаблонов, таких как одновременное получение эксклюзивных ссылок на разные поля в структуре. Но в некоторых ситуациях он не понимает, что мы хотим сделать, и с ним приходится бороться
Внутренняя изменчивость
Rust предоставляет несколько безопасных способов изменения значения, используя только общую ссылку на это значение. Все они заменяют проверки во время компиляции проверками во время выполнения.
Cell и RefCell
Cell и RefCell реализуют то, что в Rust называется внутренней изменчивостью (interior mutability): мутацией значений в неизменяемом контексте.
Cell обычно используется для простых типов, поскольку требует копирования или перемещения значений. Более сложные типы внутреннего пространства обычно используют RefCell, который отслеживает общие и эксклюзивные ссылки во время выполнения и паникует, если они используются неправильно.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug, Default)]
struct Node {
value: i64,
children: Vec<Rc<RefCell<Node>>>,
}
impl Node {
fn new(value: i64) -> Rc<RefCell<Node>> {
Rc::new(RefCell::new(Node { value, ..Node::default() }))
}
fn sum(&self) -> i64 {
self.value + self.children.iter().map(|c| c.borrow().sum()).sum::<i64>()
}
}
fn main() {
let root = Node::new(1);
root.borrow_mut().children.push(Node::new(5));
let subtree = Node::new(10);
subtree.borrow_mut().children.push(Node::new(11));
subtree.borrow_mut().children.push(Node::new(12));
root.borrow_mut().children.push(subtree);
println!("graph: {root:#?}");
println!("graph sum: {}", root.borrow().sum());
}Ремарки:
- если бы в этом примере мы использовали
CellвместоRefCell, нам пришлось бы переместитьNodeизRc, чтобы добавить дочерние элементы, а затем вернуть его обратно. Это безопасно, поскольку в ячейке всегда есть одно значение, на которое нет ссылки, но это не эргономично - для того, чтобы сделать что-то с
Node, нужно вызвать какой-нибудь методRefCell, обычноborrowилиborrow_mut - ссылочные циклы могут быть созданы путем добавления
rootвsubtree.children(не пытайтесь вывести их в терминал) - для того, чтобы вызвать панику во время выполнения, добавьте
fn inc(&mut self), который увеличиваетself.valueи вызывает тот же метод для своих дочерних элементов. Это вызовет панику из-за наличия ссылочного цикла:thread 'main' panicked at 'already borrowed: BorrowMutError'
Упражнение: показатели здоровья
Вы работаете над внедрением системы мониторинга здоровья. В рамках этого вам необходимо отслеживать показатели здоровья пользователей.
Ваша задача — реализовать метод visit_doctor в структуре User.
#![allow(dead_code)]
pub struct User {
name: String,
age: u32,
height: f32,
visit_count: usize,
// Опциональное поле
last_blood_pressure: Option<(u32, u32)>,
}
pub struct Measurements {
height: f32,
blood_pressure: (u32, u32),
}
// 'a - это время жизни, мы поговорим об этом в следующем разделе
pub struct HealthReport<'a> {
patient_name: &'a str,
visit_count: u32,
height_change: f32,
// Опциональное поле
blood_pressure_change: Option<(i32, i32)>,
}
impl User {
pub fn new(name: String, age: u32, height: f32) -> Self {
Self {
name,
age,
height,
visit_count: 0,
last_blood_pressure: None,
}
}
pub fn visit_doctor(&mut self, measurements: Measurements) -> HealthReport {
todo!("Обновляем показатели здоровья пользователя на основе измерений в результате посещения врача")
}
}
fn main() {
let bob = User::new(String::from("Bob"), 32, 155.2);
println!("I'm {} and my age is {}", bob.name, bob.age);
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_visit() {
let mut bob = User::new(String::from("Bob"), 32, 155.2);
assert_eq!(bob.visit_count, 0);
let report = bob.visit_doctor(Measurements {
height: 156.1,
blood_pressure: (120, 80),
});
assert_eq!(report.patient_name, "Bob");
assert_eq!(report.visit_count, 1);
assert_eq!(report.blood_pressure_change, None);
let report = bob.visit_doctor(Measurements {
height: 156.1,
blood_pressure: (115, 76),
});
assert_eq!(report.visit_count, 2);
assert_eq!(report.blood_pressure_change, Some((-5, -4)));
}
}impl User {
// ...
pub fn visit_doctor(&mut self, measurements: Measurements) -> HealthReport {
// Увеличиваем количество посещений врача
self.visit_count += 1;
// Показатели кровяного давления из измерений
let bp = measurements.blood_pressure;
// Отчет
let report = HealthReport {
patient_name: &self.name,
visit_count: self.visit_count as u32,
// Изменение роста
height_change: measurements.height - self.height,
// Изменение давления.
// Последнее измерение давления может быть пустым,
// поэтому выполняется сопоставление с шаблоном
blood_pressure_change: match self.last_blood_pressure {
Some(lbp) => {
Some((bp.0 as i32 - lbp.0 as i32, bp.1 as i32 - lbp.1 as i32))
}
None => None,
},
};
self.height = measurements.height;
self.last_blood_pressure = Some(bp);
report
}
}Срезы и времена жизни
Срезы
Срез (slice) — это представление (view) (часть) большой коллекции значений:
fn main() {
let mut a: [i32; 6] = [10, 20, 30, 40, 50, 60];
println!("a: {a:?}");
let s: &[i32] = &a[2..4];
println!("s: {s:?}");
}- Срезы заимствуют данные из исходного типа
- Вопрос: что произойдет, если модифицировать
a[3]перед выводомsв терминал?
Ремарки:
- мы создаем срез путем заимствования
aи определения начального и конечного индексов в квадратных скобках - если срез начинается с индекса
0, синтаксис диапазонаRustпозволяет не указывать начальный индекс:&a[0..a.len()]==&a[..a.len()] - тоже справедливо для конечного индекса:
&a[2..a.len()]==&a[2..] - срез всего массива можно создать с помощью
&a[..] s— это ссылка на срез целых чисел со знаком. Обратите внимание, что в типеs(&[i32]) не упоминается длина массива. Это позволяет вычислять срезы разных размеров- срезы всегда заимствуют значения объектов. В примере
aостается "живой" (в области видимости) до тех пор, пока "жив" его срез - вопрос об изменении
a[3]может вызвать интересную дискуссию, но ответ заключается в том, что из соображений безопасности памяти мы не можем сделать это черезaна данном этапе выполнения кода, но мы можем безопасно читать данные как изa, так и изs. Это работает до создания среза и после вызоваprintln!, когда срез больше не используется
Строки
Теперь мы можем разобраться с типом &str: это почти &[char], но с данными, хранящимися в кодировке переменной длины (UTF-8).
fn main() {
let s1: &str = "World";
println!("s1: {s1}");
let mut s2: String = String::from("Hello ");
println!("s2: {s2}");
s2.push_str(s1);
println!("s2: {s2}");
let s3: &str = &s2[6..];
println!("s3: {s3}");
}&str— иммутабельная ссылка на строковый срезString— мутабельная ссылка на буфер
Ремарки:
&str— это срез строки, иммутабельная ссылка на закодированные в UTF-8 текстовые данные, хранящиеся в блоке памяти. Строковые литералы ("Hello") хранятся в бинарнике (исполняемом файле) программы- тип
String— это обертка над вектором байтов. Как иVec<T>, он является собственным (owned) String::from()создает строку из литерала строки;String::new()создает новую пустую строку, в которую можно добавлять строковые данные с помощью методовpushиpush_str- макрос
format!генерирует собственную строку из динамических значений. Стиль его форматирования схож сprintln! - мы можем заимствовать срезы
&strизStringчерез&и опциональный диапазон выбора (range selection). Если выбран диапазон байтов, который не совпадает с границами символов (character boundaries), выражение запаникует. Итераторcharsперебирает символы и является предпочтительным способом правильного извлечения символов - байтовые строки позволяют создавать
&[u8]напрямую:
fn main() {
let byte_string = b"abc";
println!("{:?}", byte_string);
assert_eq!(byte_string, &[97, 98, 99])
}Аннотации времен жизни
Ссылка имеет время жизни (lifetime), она не должна "переживать" значение, на которое ссылается. Соблюдение этого правила обеспечивается контроллером заимствований (borrow checker).
Время жизни может определяться неявно — то, что мы видели до сих пор. Времена жизни также могут быть явными: &'a Point, &'static str. Времена жизни начинаются с ' и 'a — имя по умолчанию. &'a Point читается как "заимствование структуры Point, которое является валидным на протяжении времени жизни a".
Времена жизни всегда выводятся (inferred) компилятором, они не могут присваиваться явно. Явные аннотации (annotations) времен жизни создают ограничения в случае неопределенности; компилятор предоставляет валидное решение в рамках этих ограничений.
Времена жизни становятся сложными, когда значения передаются в и возвращаются из функции:
#[derive(Debug)]
struct Point(i32, i32);
fn left_most(p1: &Point, p2: &Point) -> &Point {
if p1.0 < p2.0 {
p1
} else {
p2
}
}
fn main() {
let p1: Point = Point(10, 10);
let p2: Point = Point(20, 20);
let p3 = left_most(&p1, &p2); // каково время жизни `p3`?
println!("p3: {p3:?}");
}В примере компилятор не может самостоятельно определить время жизни p3. Ему требуется наша помощь:
fn left_most<'a>(p1: &'a Point, p2: &'a Point) -> &'a Point { .. }Возвращаемое значение должно жить как минимум также долго, как передаваемые аргументы.
В обычных ситуациях явные аннотации времен жизни не требуются.
Времена жизни в функциях
Времена жизни параметров функции и возвращаемого функцией значения должны быть полностью определены, но в ряде случаев Rust позволяет опустить (elide) аннотации времен жизни. На этот счет существует несколько простых правил:
- каждому аргументу присваивается аннотация времени жизни при отсутствии
- если функция принимает только один параметр, его время жизни становится временем жизни возвращаемого функцией значения
- если функция принимает несколько параметров, но первым параметром является
self, время жизниselfстановится временем жизни возвращаемого функцией значения
#[derive(Debug)]
struct Point(i32, i32);
fn cab_distance(p1: &Point, p2: &Point) -> i32 {
(p1.0 - p2.0).abs() + (p1.1 - p2.1).abs()
}
fn nearest<'a>(points: &'a [Point], query: &Point) -> Option<&'a Point> {
let mut nearest = None;
for p in points {
if let Some((_, nearest_dist)) = nearest {
let dist = cab_distance(p, query);
if dist < nearest_dist {
nearest = Some((p, dist));
}
} else {
nearest = Some((p, cab_distance(p, query)));
};
}
nearest.map(|(p, _)| p)
}
fn main() {
println!(
"{:?}",
nearest(
&[Point(1, 0), Point(1, 0), Point(-1, 0), Point(0, -1),],
&Point(0, 2)
)
);
}Функция cab_distance не требует явных аннотаций времен жизни, поскольку p1 и p2 имеют одинаковый тип.
Параметры функции nearest имеют разные типы, поэтому функция требует явных аннотаций времен жизни. Попробуйте переписать ее сигнатуру следующим образом:
fn nearest<'a, 'q'>(points: &'a [Point], query: &'q Point) -> Option<&'q Point> { .. }Такой код не компилируется. Это доказывает, что аннотации проверяются компилятором на корректность.
В большинстве случаев автоматический вывод аннотаций и типов означают, что их не нужно указывать явно. В более сложных ситуациях аннотации времени жизни могут помочь устранить неоднозначность. Часто, особенно при создании прототипов, проще работать с собственными данными, клонируя значения там, где это необходимо.
Времена жизни в структурах
Если структура хранит заимствованные данные, она должна быть аннотирована временем жизни:
#[derive(Debug)]
struct Highlight<'doc>(&'doc str);
fn erase(text: String) {
println!("Bye {text}!");
}
fn main() {
let text = String::from("The quick brown fox jumps over the lazy dog.");
let fox = Highlight(&text[4..19]);
let dog = Highlight(&text[35..43]);
// erase(text);
println!("{fox:?}");
println!("{dog:?}");
}- аннотация
Highlightобеспечивает, чтобы данные, хранящиеся в&str, существовали по крайней мере также долго, как любой экземплярHighlight, использующий эти данные - если
textбудет потреблен до окончания жизниfox(илиdog), контроллер заимствований выбросит ошибку - типы с заимствованными данными вынуждают пользователей сохранять исходные данные. Это может быть полезно для создания упрощенных представлений (lightweight views), но обычно это несколько усложняет их использование
- по возможности делайте так, чтобы структуры владели своими данными
- некоторые структуры с несколькими ссылками внутри могут иметь более одной аннотации времени жизни. Это может быть необходимо, если помимо времени жизни самой структуры, необходимо описать отношения между временами жизни самих ссылок. Это очень продвинутые варианты использования
Упражнение: анализ Protobuf
В этом упражнении вы создадите анализатор двоичной кодировки protobuf. Не волнуйтесь, это проще, чем кажется! Упражнение иллюстрирует общий шаблон парсинга данных, разделенных на фрагменты (срезы). Исходные данные никогда не копируются.
Полный анализ сообщения protobuf требует знания типов полей, индексированных по номерам полей. Обычно это описывается в файле proto. В этом упражнении мы закодируем эту информацию в операторы сопоставления в функциях, которые вызываются для каждого поля.
Мы будем использовать следующий прототип:
message PhoneNumber {
optional string number = 1;
optional string type = 2;
}
message Person {
optional string name = 1;
optional int32 id = 2;
repeated PhoneNumber phones = 3;
}Протосообщение кодируется как серия полей, идущих одно за другим. Каждый из них реализован как "тег", за которым следует значение. Тег содержит номер поля (например, 2 для поля id сообщения Person) и тип поля, определяющий, как полезная нагрузка должна извлекаться из потока байтов.
Целые числа, включая тег, представлены с помощью кодировки переменной длины, называемой VARINT. Функция parse_varint уже определена в коде. Также определены коллбеки для обработки полей Person и PhoneNumber и для парсинга сообщения в виде серии вызовов этих коллбеков.
Вам осталось реализовать функцию parse_field и трейт ProtoMessage для Person и PhoneNumber.
Обратите внимание: это упражнения является сложным и опциональным. Это означает, что на данном этапе освоения Rust вы можете его пропустить и вернуться к нему позже.
use std::convert::TryFrom;
use thiserror::Error;
#[derive(Debug, Error)]
enum Error {
#[error("Invalid varint")]
InvalidVarint,
#[error("Invalid wire-type")]
InvalidWireType,
#[error("Unexpected EOF")]
UnexpectedEOF,
#[error("Invalid length")]
InvalidSize(#[from] std::num::TryFromIntError),
#[error("Unexpected wire-type)")]
UnexpectedWireType,
#[error("Invalid string (not UTF-8)")]
InvalidString,
}
// Тип поля
enum WireType {
// Тип Varint указывает, что значение является единичным `VARINT`
Varint,
// Тип `Len` указывает, что значение - это длина, представленная как
// `VARINT`, точно следующий за этим количеством байтов
Len,
// Тип `I32` указывает, что значение - это точно 4 байта в прямом порядке (little-endian order),
// содержащие 32-битное целое число со знаком
I32,
// Тип `I64` для этого упражнения не нужен
}
#[derive(Debug)]
// Значение поля, типизированное на основе типа поля
enum FieldValue<'a> {
Varint(u64),
// `I64(i64)` для этого упражнения не нужен
Len(&'a [u8]),
I32(i32),
}
#[derive(Debug)]
// Поле, содержащее номер поля и его значение
struct Field<'a> {
field_num: u64,
value: FieldValue<'a>,
}
trait ProtoMessage<'a>: Default + 'a {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error>;
}
impl TryFrom<u64> for WireType {
type Error = Error;
fn try_from(value: u64) -> Result<WireType, Error> {
Ok(match value {
0 => WireType::Varint,
// `1 => WireType::I64` для этого упражнения не нужен
2 => WireType::Len,
5 => WireType::I32,
_ => return Err(Error::InvalidWireType),
})
}
}
impl<'a> FieldValue<'a> {
fn as_string(&self) -> Result<&'a str, Error> {
let FieldValue::Len(data) = self else {
return Err(Error::UnexpectedWireType);
};
std::str::from_utf8(data).map_err(|_| Error::InvalidString)
}
fn as_bytes(&self) -> Result<&'a [u8], Error> {
let FieldValue::Len(data) = self else {
return Err(Error::UnexpectedWireType);
};
Ok(data)
}
fn as_u64(&self) -> Result<u64, Error> {
let FieldValue::Varint(value) = self else {
return Err(Error::UnexpectedWireType);
};
Ok(*value)
}
}
// Функция разбора VARINT, возвращающая разобранное значение и оставшиеся байты
fn parse_varint(data: &[u8]) -> Result<(u64, &[u8]), Error> {
for i in 0..7 {
let Some(b) = data.get(i) else {
return Err(Error::InvalidVarint);
};
if b & 0x80 == 0 {
// Это последний байт `VARINT`, преобразуем его
// в `u64` и возвращаем
let mut value = 0u64;
for b in data[..=i].iter().rev() {
value = (value << 7) | (b & 0x7f) as u64;
}
return Ok((value, &data[i + 1..]));
}
}
// Если байтов больше 7, значит `VARINT` не является валидным
Err(Error::InvalidVarint)
}
// Функция преобразования тега в номер поля и тип поля
fn unpack_tag(tag: u64) -> Result<(u64, WireType), Error> {
let field_num = tag >> 3;
let wire_type = WireType::try_from(tag & 0x7)?;
Ok((field_num, wire_type))
}
// Функция разбора поля, возвращающая оставшиеся байты
fn parse_field(data: &[u8]) -> Result<(Field, &[u8]), Error> {
let (tag, remainder) = parse_varint(data)?;
let (field_num, wire_type) = unpack_tag(tag)?;
let (fieldvalue, remainder) = match wire_type {
_ => todo!("На основе типа поля создаем поле, употребив столько байтов, сколько необходимо")
};
todo!("Возвращаем поле и оставшиеся байты")
}
// Функция разбора сообщения в определенные данные, вызывающая `T::add_field` для каждого поля.
// Все входные данные потребляются
fn parse_message<'a, T: ProtoMessage<'a>>(mut data: &'a [u8]) -> Result<T, Error> {
let mut result = T::default();
while !data.is_empty() {
let parsed = parse_field(data)?;
result.add_field(parsed.0)?;
data = parsed.1;
}
Ok(result)
}
#[derive(Debug, Default)]
struct PhoneNumber<'a> {
number: &'a str,
type_: &'a str,
}
#[derive(Debug, Default)]
struct Person<'a> {
name: &'a str,
id: u64,
phone: Vec<PhoneNumber<'a>>,
}
impl<'a> ProtoMessage<'a> for Person<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
todo!("реализуй меня")
}
}
impl<'a> ProtoMessage<'a> for PhoneNumber<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
todo!("реализуй меня")
}
}
fn main() {
let person: Person = parse_message(&[
0x0a, 0x07, 0x6d, 0x61, 0x78, 0x77, 0x65, 0x6c, 0x6c, 0x10, 0x2a, 0x1a,
0x16, 0x0a, 0x0e, 0x2b, 0x31, 0x32, 0x30, 0x32, 0x2d, 0x35, 0x35, 0x35,
0x2d, 0x31, 0x32, 0x31, 0x32, 0x12, 0x04, 0x68, 0x6f, 0x6d, 0x65, 0x1a,
0x18, 0x0a, 0x0e, 0x2b, 0x31, 0x38, 0x30, 0x30, 0x2d, 0x38, 0x36, 0x37,
0x2d, 0x35, 0x33, 0x30, 0x38, 0x12, 0x06, 0x6d, 0x6f, 0x62, 0x69, 0x6c,
0x65,
])
.unwrap();
println!("{:#?}", person);
}
#[cfg(test)]
mod test {
use super::*;
#[test]
fn as_string() {
assert!(FieldValue::Varint(10).as_string().is_err());
assert!(FieldValue::I32(10).as_string().is_err());
assert_eq!(FieldValue::Len(b"hello").as_string().unwrap(), "hello");
}
#[test]
fn as_bytes() {
assert!(FieldValue::Varint(10).as_bytes().is_err());
assert!(FieldValue::I32(10).as_bytes().is_err());
assert_eq!(FieldValue::Len(b"hello").as_bytes().unwrap(), b"hello");
}
#[test]
fn as_u64() {
assert_eq!(FieldValue::Varint(10).as_u64().unwrap(), 10u64);
assert!(FieldValue::I32(10).as_u64().is_err());
assert!(FieldValue::Len(b"hello").as_u64().is_err());
}
}fn parse_field(data: &[u8]) -> Result<(Field, &[u8]), Error> {
let (tag, remainder) = parse_varint(data)?;
let (field_num, wire_type) = unpack_tag(tag)?;
let (fieldvalue, remainder) = match wire_type {
WireType::Varint => {
let (value, remainder) = parse_varint(remainder)?;
(FieldValue::Varint(value), remainder)
}
WireType::Len => {
let (len, remainder) = parse_varint(remainder)?;
let len: usize = len.try_into()?;
if remainder.len() < len {
return Err(Error::UnexpectedEOF);
}
let (value, remainder) = remainder.split_at(len);
(FieldValue::Len(value), remainder)
}
WireType::I32 => {
if remainder.len() < 4 {
return Err(Error::UnexpectedEOF);
}
let (value, remainder) = remainder.split_at(4);
let value = i32::from_le_bytes(value.try_into().unwrap());
(FieldValue::I32(value), remainder)
}
};
Ok((Field { field_num, value: fieldvalue }, remainder))
}
// ...
impl<'a> ProtoMessage<'a> for Person<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
match field.field_num {
1 => self.name = field.value.as_string()?,
2 => self.id = field.value.as_u64()?,
3 => self.phone.push(parse_message(field.value.as_bytes()?)?),
_ => {} // остальное пропускаем
}
Ok(())
}
}
impl<'a> ProtoMessage<'a> for PhoneNumber<'a> {
fn add_field(&mut self, field: Field<'a>) -> Result<(), Error> {
match field.field_num {
1 => self.number = field.value.as_string()?,
2 => self.type_ = field.value.as_string()?,
_ => {} // остальное пропускаем
}
Ok(())
}
}Это конец третьей части руководства.
Материалы для более глубокого изучения рассмотренных тем:
- Книга/учебник по Rust (на русском языке) — главы 4, 10 и 15
- rustlings — упражнения 06, 16 и 19
- Rust на примерах (на русском языке) — примеры 15 и 19
- Rust by practice — упражнения 5 и 17
Happy coding!
Новости, обзоры продуктов и конкурсы от команды Timeweb.Cloud — в нашем Telegram-канале ↩

