

Всем привет, меня зовут Артемий, я работаю старшим Android-разработчиком в core-команде RuStore. Мой опыт в индустрии уже 8 лет. За это время я успел поработать в разных проектах и компаниях. У меня был опыт работы на проекте, в котором было свыше 300 модулей и больше 60 Android-разработчиков. Такие условия заставляют задуматься о масштабируемости на принципиально ином уровне.
Сегодня я расскажу о способах обеспечения масштабируемости проекта и как этому может навредить неправильное восприятие Чистой Архитектуры (далее — ЧА). Предупреждаю сразу, это лонгрид в двух частях!
Цена и ценность. Немного теории
В одном из докладов, да и в жизни, часто слышал мнение, что ЧА дорогая, но стоящая. От одного человека, наоборот, слышал слова, что она того не стоит. А вы считаете ЧА дорогой?
Давайте вспомним начало книги Роберта Мартина, которая так и называется — «Чистая Архитектура». В ней автор рассказывал про период своей жизни, когда он работал над проектом в команде беспринципных разработчиков, то есть ещё не было выработано основных принципов, о которых впоследствии и рассказывается в книге. Без долгих предисловий, проект умер оказался в том состоянии, когда для выпуска фич с той же скоростью увеличивали численность разработчиков. Автор даже привёл графики, которые хорошо характеризуют положение проекта:

Из графиков видно, что увеличение численности разработчиков не оказывало существенного влияния. Количество строк в кодовой базе практически не росло, а стоимость написания строки кода значительно увеличивалась. Далее в книге Дядя Боб описал необходимые принципы, которые должны были помогать нам бороться со стоимостью, а не примкнуть к ней.

В статьях и докладах тезис о дороговизне подкрепляют разными утверждениями:
ЧА должна соответствовать определённому набору критериев.
Дорого поддерживать принципы, указанные в книге.
Сложность поддержки слоёв.
Много компонентов.
Но думаю, что все проблемы, с которыми сталкиваются разработчики, имеют общее начало.
Непонимание терминологии
Корень проблем со стоимостью лежит в непонимании, что же такое ЧА. Когда на собеседовании спрашивают: «Что такое ЧА?», кандидаты чаще всего рассказывают не про книгу и её содержание, не про одноимённую главу из этой же книги, а про одноимённую схему. А собеседующие, в свою очередь, чаще всего ожидают пояснения именно по ней.

Но это не ЧА, это лишь один из вариантов представления её структуры.

Получается, что многие путают причину и следствие. ЧА не выводится из этой схемы. Это схема была выведена в результате применения принципов ЧА. Но выведена на основе опыта конкретного человека в определённом проекте для определённой платформы. Можно, конечно, попробовать вывести определение ЧА из вариантов её реализации, но для этого нам нужно больше вариантов, иначе мы будем иметь однобокое представление о ней.

Я не смог найти ни одной статьи, в которой рассказывалось бы о других вариантах реализации ЧА, и не считаю правильным давать определение ЧА, основываясь лишь на одном результате. Нужно возвращаться к истокам и искать ответ в книге. Сам автор не дал нам чёткого определения, но я могу предложить способ вывести его. Для этого нам понадобится ответить на вопрос: «Для чего нужен SOLID?».
Тема SOLID ещё более избитая, чем тема ЧА, но насколько часто вы видите в статьях о SOLID ответ на вопрос: «А зачем он нужен?». Думаю, что немало ошибок можно было бы избежать, если бы авторы этих статей сначала задавались вопросом о целях.
Почему для определения важен именно SOLID?
Первая половина книги Дяди Боба рассказывает нам про 11 принципов. Среди них есть 6 принципов организации компонентов (которые, в свою очередь, делятся на принципы сочетаемости и связности компонентов), а также 5 принципов SOLID. Казалось бы, SOLID занимает меньше половины, но на самом деле всё немного сложнее.
Вот схема зависимостей принципов, в зависимости от которых мы формируем наши зависимости (иначе говоря - принципы ЧА):

Все привыкли рассуждать только про 5 принципов, но цели применения остальных принципов ничуть не отличаются.
Чтобы ответить на вопрос: «Для чего нужен SOLID?», далеко ходить не надо, обратимся к Википедии и узнаем ответ:
Для создания системы, которую можно будет легко поддерживать и расширять в течение долгого времени.
Для улучшения ПО.
Если ЧА основана на принципах, которые имеют чёткие цели, то можно заложить эти цели в определение ЧА:
Чистая Архитектура — это архитектура, которую можно будет легко поддерживать, расширять и улучшать в течение долгого времени.
Казалось бы, теперь любители писать код в одном классе смогут спокойно сказать, что их архитектура Чистая, т.к. им так легко. Но останется ли это так «в течение долгого времени»? Кажется, будто команде из пары человек внести изменения достаточно просто, даже если код находится в одном классе. Но если вы уйдёте с проекта, смогут ли ваши приемники сказать вам спасибо? А если добавить щепотку масштабирования, и вам в помощь наймут десяток другой человек?
Важно понимать, что «лёгкость» – это не какое-то абстрактное чувство, а сохранение основного показателя – TTM (Time to market). Я мог бы сказать, что также важны время на Onboarding новичков, Build Time проекта и т.п., но всё это входит в TTM.
Противопоставление ЧА другим архитектурам
Отлично, определение выведено. Но если в нём вас смущает наличие слова «архитектура», то вы ещё не пришли к полному пониманию. Одна из проблем в понимании ЧА заключается в том, что её могут ошибочно противопоставлять другим архитектурами. Все же мы слышали, что есть и другие архитектуры? Луковичная (слоистая), гексагональная, может, кто-то вспомнит и другие. Но ЧА не может им противопоставляться.
Когда мы начали считать ЧА полноценной архитектурой? Думаю, всё начинается со статей по этой теме. Когда я только начинал изучать её, мне понравилась схема ЧА, пропущенная через призму мобильной разработки с указанием компонентов, которые характерны для нас:

Хоть схема и пропущена через призму мобильной разработки, но по структуре своей не отличается от книжной. От статьи к статье мы видим одну и ту же привычную для нас структуру: везде между строк выводят огромный знак равенства между термином и схемой. В итоге схема считается конечной формой реализации ЧА. Но нельзя винить в этом авторов статей, ведь Дядя Боб сам подписал эту схему, как ЧА.

Согласно выведенному нами определению можно понять, что «чистота» — это свойство. Оно означает, что любая архитектура, которой мы пытались противопоставляться, может быть «чистой». Достаточно лишь руководствоваться определёнными принципами.
Что делает ЧА дорогой?
Лишние интерфейсы
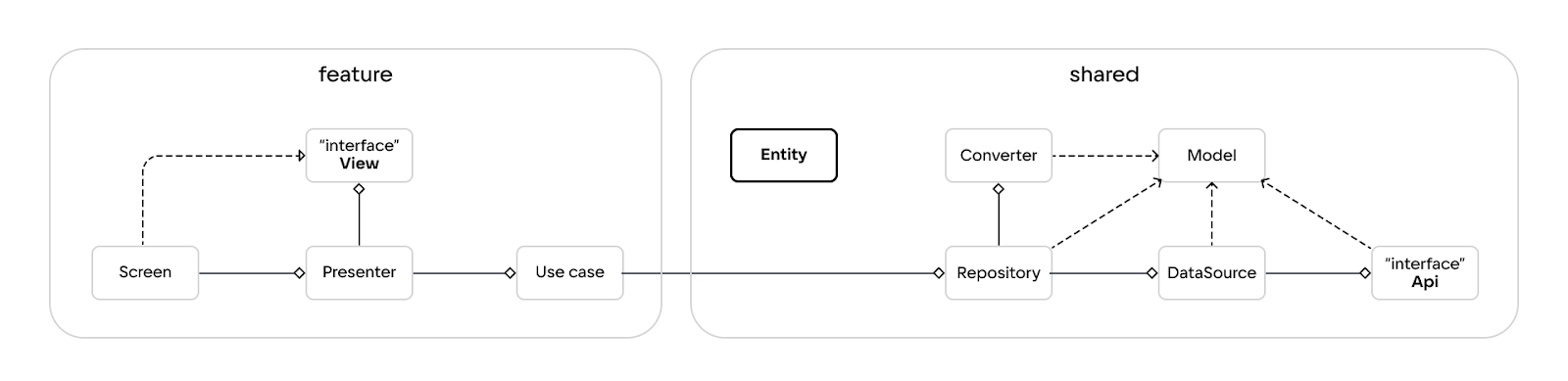
Эту проблему я покажу на примере монолитной структуры, в которой модули нарезаны по слоям.

Важный момент: на схеме я не указываю зависимости от Entity, потому что любой компонент может зависеть от неё и использовать её. С указанием всех зависимостей от неё схема воспринималась бы тяжелее.
Теперь дам пояснение используемым компонентам, потому что в разных проектах названия компонентов могут отличаться. Надеюсь, каждый сможет найти для себя ассоциации с компонентами из собственных проектов.
Для Domain:
Entity — сущности, характерные для нашего проекта.
UseCase — компонент бизнес-логики.
Интерфейс Repository — компонент, необходимый для применения инверсии зависимости и направления оной с data-слоя на domain-слой.
Для Presentation:
Presenter — компонент презентационной логики.
Интерфейс View — компонент, необходимый для применения инверсии зависимости и направления оной с UI-слоя на presentation-слой.
Для UI:
Screen — компонент UI (для Android это могут быть Activity, Fragment-ы или непосредственно компоненты Screen в Compose).
Для Data:
Model (или DTO) — сущности data-слоя, полученные в сыром виде и ещё не прошедшие конвертацию в доменные сущности.
Repository — компонент, управляющий источниками и конвертерами для формирования данных в сущности domain слоя.
Converter — компонент, конвертирующий модели в сущности domain слоя.
DataSource — компонент источника данных.
Интерфейс API — компонент, с помощью которого мы получаем модели (DTO) через сеть.
Видно, что поддержание такой структуры обходится нам недёшево. Особенно это чувствуется для таких фич, как «дай-покажи», где необходимо просто отобразить какую-то модель, полученную из запроса. А таких фич в мобильной разработке достаточно много.
Что можно сделать?
Для начала предлагаю убрать лишние интерфейсы:

Мы убрали интерфейсы для DataSource и Converter.
Убрать лишние интерфейсы из проекта бывает тяжело, потому что в любом проекте могут оказаться «правозащитники интерфейсов». Сразу отмечу, что Роберт Мартин не был таким. Если кто-то будет ссылаться на его книгу, говоря, что по принципу подмены Барбары Лисков нам необходимы интерфейсы, то знайте, что Дядя Боб в книге использует или описывает интерфейсы как необходимые только в двух случаях:
Для защиты от внешних реализаций, которые от нас не зависят. Для нас это могут быть сторонние библиотеки или сама платформа, под которую мы разрабатываем.
Для инверсии зависимостей.
Что касается самого принципа подмены Барбары Лисков, то автор использует этот принцип в более глобальном смысле, подменяя между собой не реализации конкретных классов, а сервисы (в мобильной разработке равнозначно можно было бы говорить о подмене между собой каких-то модулей или технологий).
Но если рассуждать о принципе подмены на уровне компонентов, то какие аргументы могли бы быть в защиту интерфейсов? Буду приводить на примере DataSource.
Пример 1: подмена между собой локальных и удалённых источников данных
Эти источники очень контекстны. Они могут отличаться друг от друга по количеству методов или их сигнатуре. Например, у локальных источников должна быть возможность их очистки, что будет означать наличие соответствующего метода, которого не будет у удалённого источника. Можно эту проблему обойти, вводя больше интерфейсов. Один интерфейс будет одинаков для обоих источников, а второй — чисто под очистку. Это увеличит количество компонентов, а значит и стоимость вашей архитектуры. И вся эта работа будет бесполезной, если в коде вы их будете использовать так:

А именно — если будете использовать контекст каждого из источников в названии переменных:

Вы можете заявлять, о том, что вам кровь из носу необходимо соблюсти тут принцип подмены, но он будет нарушен, если вы их используете одновременно, указывая названиями переменных, какой из источников к чему относится.
Если вы хотите кешировать данные, то вам придётся различать эти источники принудительно, иначе как вы положите из удалённого источника данные в локальный источник? Более того, локально кешировать лучше уже сконвертированные сущности, чтобы не заниматься множество раз конвертацией. А значит, про общий интерфейс уже и говорить будет нечего. И если вы захотите обойти эту проблему использованием дженериков, это сильно ухудшит восприятия кода и увеличит стоимость поддержки.
Пример 2: разные реализации локальных источников
Подмена между собой источников данных, работающих с оперативной и встроенной памятью
Преимущество оперативной памяти, очевидно, в скорости, а значит и в отсутствии необходимости обращаться к ней асинхронно. Подводя её под асинхронный интерфейс встроенного хранилища, мы лишаемся этого преимущества.
Можно, конечно, рассуждать о случаях, когда из-за синхронизации и множественного обращения к полю из разных потоков мы можем получить какую-то существенную задержку, но не представляю, как в такой ситуации подвязать встроенное хранилище, чтобы оно не навредило процессу. Да и сам случай для мобильной разработки будет носить, скорее всего, искусственный характер. Если в вашем проекте встречаются подобные проблемы, скорее всего, что-то не так на концептуальном уровне.
А в случаях, когда в процессе одновременно участвуют оперативная и встроенная память, мы получаем ситуацию из предыдущего примера: когда класс, использующий оба источника, знает, какой источник каким является, что было разобрано выше.
Можно говорить о случаях, когда в файле хранятся достаточно незначительные объёмы данных, чтобы обращаться к ним синхронно, но все источники используются для разных целей, из-за которых они не могут быть взаимозаменяемыми. Оперативную память можно заменить локальной, но не наоборот из-за существенно разных сроков хранения.
Подмена между собой источников данных, работающих с файлом и БД
Два этих источника являются принципиально разными по своему потенциалу. Чтобы подвести их под один интерфейс, нужно либо забыть про потенциал БД и не пользоваться всеми её преимуществами, либо вручную настраивать работу с файлом как с БД, что будет эквивалентно попытке создания БД вручную. Как не крути, занятие неблагодарное и сигнализирующее о том, что в проекте творится что-то неладное.
Подмена между собой разных реализаций БД или инструментов, работающих с БД
Казалось бы, вот он, пример, в котором нет никаких препятствий, чтобы использовать интерфейсы. Но такая подмена, скорее всего, будет иметь искусственный характер. А в реальности речь будет идти скорее не о подмене, а о полной замене реализаций между собой. Если речь о полной замене, то интерфейсы уже никак не помогут в этом процессе, а может даже будут мешать.
Пример 3: модульные тесты
Считаю, что это действительно важная причина использовать интерфейсы, если у вас нет другой возможности mock-ать финализированные классы, чтобы определять поведение агрегированных полей в тестируемом классе. Но у нас в мобильной разработке под Android такая возможность есть, и мне остаётся только надеяться, что на других платформах с этим всё тоже хорошо. Если нет — поздравляю, интерфейсы для вас оправданы, и сочувствую этой неизбежности.
Пример 4: динамическая подмена
Если речь идёт о динамической подмене, то использование интерфейсов может быть оправдано, но не является обязательным. В зависимости от условий можно, конечно, рассматривать вариант подмены через интерфейсы, а можно реализовывать такую подмену и другими способами, это уже на ваше усмотрение, потому что ситуации могут быть разными.
Но даже если в таком случае интерфейсы и будут оправданы, то сколько таких случаев может быть в проекте. Если пара-тройка на сотни DataSource-ов, то стоит ли создавать интерфейсы для каждого из них?
Лишние инверсии
Эту проблему я покажу на примере многомодульной структуры, в которой модули будут нарезаться по фичам на основной модуль feature и её расшариваемую часть shared, которую могут использовать и другие feature-модули.
Рассмотрим несколько примеров такой структуры:

Интерфейс Repository часто оставляют по привычке при переходе с монолитной структуры проекта, где он нужен был для реализации инверсии зависимостей. Но, как мы видим, нам не удаётся сохранить назначение этого интерфейса, даже если выделять shared-часть из data-слоя, что уж говорить об остальных вариантах.
Давайте попробуем понять, что такое принцип инверсии зависимостей (DIP) и для чего он нужен на самом деле. В книге про ЧА сказано, что DIP основан на SAP (Stable Abstractions Principle) и SDP (Stable Dependencies Principle).

SDP, или принцип устойчивых зависимостей.
Этот принцип говорит нам о том, что зависимости должны быть направлены в сторону устойчивости. При этом важно понимать, что устойчивость не то же самое, что и редкая изменяемость. Устойчивым компонентом является тот, изменяя который вы не сможете избежать изменений в остальных компонентах.
В своей книге Дядя Боб определил Entities как самый устойчивый слой. За ним уже слой бизнес-логики и т. д.:

На практике, для feature-shared структуры изменения в data-слое всегда приведут к пересборке всех зависимых модулей.
Получается, что в нашей схеме устойчивость не обеспечивается должным образом и существует не более чем в умах. А в книге не говорится о ментальных ограничениях. Речь всегда идёт о практическом применении.
Как бы мы могли обеспечить эту устойчивость на практике? В случае с shared-частью от data-слоя мы могли бы выделить дополнительный модуль:

Но в таком случае мы получим отрицательную тенденцию на чрезмерное увеличение количества модулей в проекте. Переплата будет настолько большой, что вряд ли кто-либо решится поддерживать такую структуру.
Для полного счастья в этой схеме остаётся только вынести UseCase в новый модуль и сделать отдельный модуль для UI. Тогда мы получим ту же монолитную структуру, но мелко-мелко нарезанную, и будет у нас структура не многомодульная, а много-многомодульная.
SAP, или принцип устойчивости абстракций
В переводе книги говорится, что устойчивость компонента пропорциональна его абстрактности. А в оригинале — что абстрактность компонента пропорциональна его устойчивости. Но в оригинале автор сам в итоге всё сводит к первому варианту, который использовал переводчик, так что не будем ругать последнего.
То, что автор рассказывает нам про SAP в своей книге, можно трактовать по-разному. Лично для себя я предпочитаю тот вариант трактовки, в котором мы можем использовать абстракции для того, чтобы обеспечить достаточную гибкость для управления зависимостями.
И только теперь можно говорить про DIP
Этот принцип говорит нам о том, что наиболее гибкими получаются системы, в которых зависимости в исходном коде направлены на абстракции, а не на конкретные реализации.
DIP буквально вторит определениям SDP и SAP. Сам автор говорит, что DIP невозможен без SDP и SAP. Как нам увязать эти принципы между собой? SDP — это цель. SAP — это средство. DIP — это результат. Если всё вместе, то DIP — это использование SAP для обеспечения SDP.
А если проще, то мы используем абстракции, чтобы развернуть зависимости в сторону устойчивости. Если это понимать именно так, то DIP перестаёт быть принципом вовсе. Настоящий принцип тот, что лежит в его основе и к которому мы стремимся — это SDP.
В итоге мы видим, что при текущей структуре мы не можем должным образом обеспечить DIP, а значит и SAP бездумно использовать нам нет смысла. А что касается SDP, то к нему мы еще раз вернёмся во второй части. А пока что можно спокойно убирать интерфейс для всех схем.


На этом месте заканчивается первая часть статьи. В следующий раз я вернусь, чтобы рассказать о более экстремальных способах экономии.

Оставайтесь на связи, и до встречи в следующей части :)
