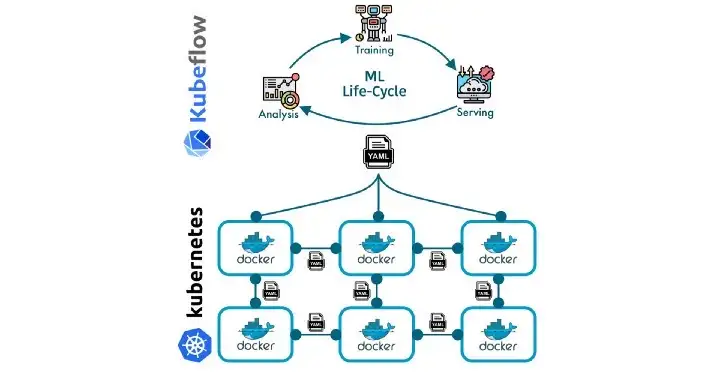
Новые экспериментальные модели машинного обучения важно быстро разворачивать в продакшене, иначе данные устареют и появятся проблемы воспроизводимости экспериментов. Но не всегда это можно сделать быстро, так как часто процесс передачи модели от Data Scientist к Data Engineer плохо налажен. Эту проблему решает подход MLOps, но, чтобы его реализовать, нужны специальные инструменты, например Kubeflow.
При этом установка и настройка Kubeflow — довольно непростой процесс. Хотя существует официальная документация, она не описывает, как развернуть Kubeflow в продакшен-варианте, а не просто на тестовой локальной машине. Также в некоторых инструкциях встречаются проблемы, которые нужно обходить и искать их решения.
Я Александр Волынский, архитектор облачной платформы Mail.ru Cloud Solutions. В этой статье познакомлю вас с Kubeflow на базовом уровне и покажу, как его разворачивать. Мы не будем подробно знакомиться со всеми компонентами Kubeflow, потому что это выходит за рамки базового ознакомления.