Итак, тема рейтинговых систем продолжает будоражить умы хабрапользователей. Появляются всё новые и новые схемы, формулы, тесты. И каждый раз всё сводится к одному и тому же вопросу: как совместить среднюю оценку пользователей с нашей уверенностью в этой оценке. Например, если один фильм получил 80 положительных и 20 отрицательных голосов, а другой — 9 положительных и 1 отрицательный, то какой из фильмов лучше? Не претендуя на создание новой универсальной рейтинговой системы, я всё же предложу один из возможных подходов к решению именно этого вопроса.

Юрий Самуйлов @NetMozg
User
DataTalks 25.10.14: первая встреча
4 min
Tutorial
Добрый вечер! Сегодня вперые говорим об анализе данных в нашем блоге. Для многих это крайне актуальная тема. Однако в Беларуси не так много действительно полезных встреч и конференций, посвященных аналитике.
25 октября 2014 года в Минске состоялся первый DataTalks. DataTalks – это неформальные встречи специалистов в области анализа данных. Для участников это отличная возможность узнать об опыте применения аналитики в компаниях, работающих на мировом и местном рынках, а также познакомиться со специалистами в области анализа данных из различных индустрий.
Докладчики из Wargaming, Yandex, Dmlabs.org и Нанотех, на примерах решаемых ими задач, объясняли общие закономерности и применимость алгоритмов, которые важно знать и использовать при анализе данных в любой индустрии. Вопросы спикерам перерастали в профессиональные дискуссии, остановить которые не могло даже начало следующего доклада.

25 октября 2014 года в Минске состоялся первый DataTalks. DataTalks – это неформальные встречи специалистов в области анализа данных. Для участников это отличная возможность узнать об опыте применения аналитики в компаниях, работающих на мировом и местном рынках, а также познакомиться со специалистами в области анализа данных из различных индустрий.
Докладчики из Wargaming, Yandex, Dmlabs.org и Нанотех, на примерах решаемых ими задач, объясняли общие закономерности и применимость алгоритмов, которые важно знать и использовать при анализе данных в любой индустрии. Вопросы спикерам перерастали в профессиональные дискуссии, остановить которые не могло даже начало следующего доклада.
Вероятностные модели: от наивного Байеса к LDA, часть 1
6 min
Tutorial
Продолжаем разговор. Прошлая статья была переходной от предыдущего цикла о графических моделях вообще (часть 1, часть 2, часть 3, часть 4) к новому мини-циклу о тематическом моделировании: мы поговорили о сэмплировании как методе вывода в графических моделях. А теперь мы начинаем путь к модели латентного размещения Дирихле (latent Dirichlet allocation) и к тому, как все эти чудесные алгоритмы сэмплирования применяются на практике. Сегодня – часть первая, в которой мы поймём, куда есть смысл обобщать наивный байесовский классификатор, и заодно немного поговорим о кластеризации.

Веб-аналитика: Не все цифры одинаково полезны
5 min
Нас всё время спрашивают: какова погрешность сбора данных в Google Analytics? Какому счетчику лучше доверять? Нельзя ли избавиться ото всех несовпадений и получить точные цифры посещаемости?
Мы всегда отвечаем: погрешность обычно около 10%, явного лидера по точности нет, убрать все ошибки невозможно — так уж устроена технология.Практически никто не понимает, что неточный сбор данных — это не единственная ошибка, влияющая на результат анализа. Даже идеально собранные данные не позволят нам точно подсчитать нужные показатели на сайте (прежде всего, процент конверсии). Собранных данных может быть недостаточно! Это понимает каждый: если на сайт пришли всего 15 посетителей и ни один из них не заполнил форму заявки на кредит, о конверсии говорить рано. Так подсказывает нам здравый смысл; но в какой момент можно сказать, что данных хватает? Ждать ли еще 100 посещений? 200? 500?
6 ошибок снижающих конверсию вашего магазина
6 min
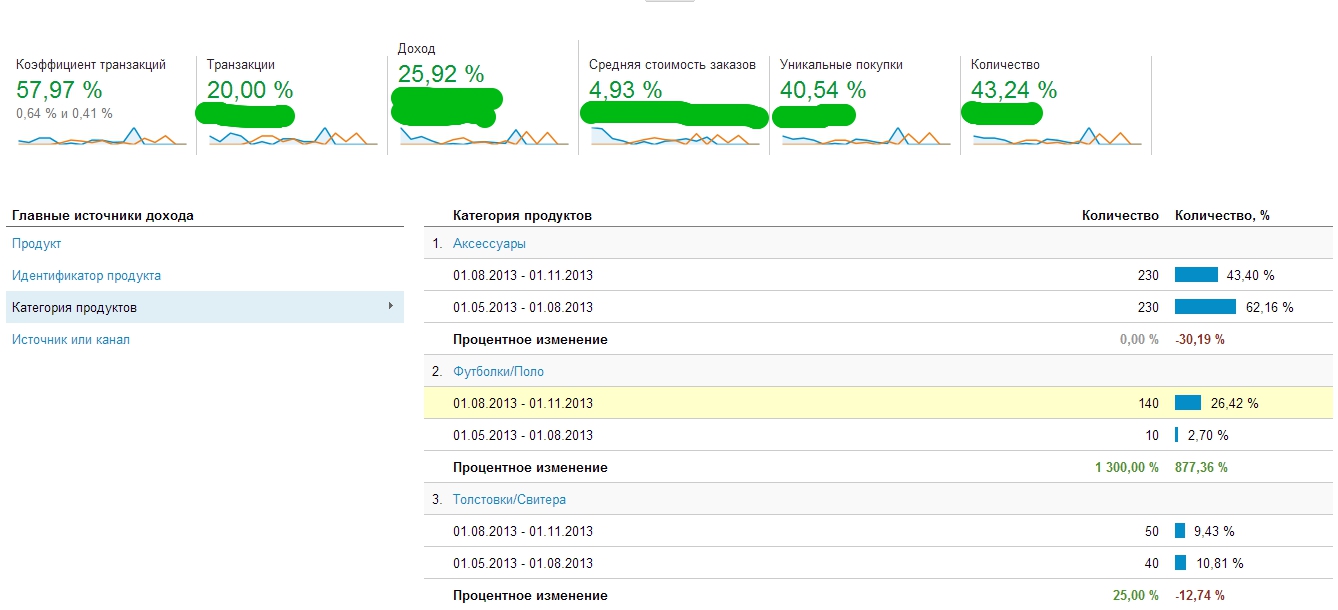
В статье я расскажу реальные истории изменений интернет магазинов и о том, какой эффект они дали. Все истории 2012-2013 годов.
На протяжении многих лет я специализируюсь на анализе текущего положения дел интернет магазина и последующем увеличении его конверсии. За это время у меня набрались некоторые хинты, внедрение которых всегда позволяло на значительную величину увеличить продажи. (Значительное – это конечно, не 500%, а 1%-5%). Другими словами — отсутствие этих вещей, снижает эффективность магазина. Накопилось их значительно больше 6, но я постарался написать о тех, внедрение которых не требует много времени или ресурсов.
Google Analytics: User Id и многоканальные последовательности
1 min
Сейчас много говорят о фишках GA — User Id и многоканальной последовательности. Я решил проверить, как они работают вместе.
Возьмем для примера такую ситуацию: пользователь, сидя на работе, приходит к вам с контекстной рекламы, выбирает товары в вашем интернет-магазине, добавляет их в корзину, регистрируется, чтобы оплатить… и почему-то этого не делает. Однако, придя домой, он советуется с женой и решает все же купить, что и делает с успехом (но уже с домашнего компьютера).
При этом, мы, конечно, должны использовать user Id, для того, чтобы Гугл мог их как-то связать.
Будет ли в итоге фигурировать контекстная реклама в мультиканальной последовательности? Похоже, что нет.
Возьмем для примера такую ситуацию: пользователь, сидя на работе, приходит к вам с контекстной рекламы, выбирает товары в вашем интернет-магазине, добавляет их в корзину, регистрируется, чтобы оплатить… и почему-то этого не делает. Однако, придя домой, он советуется с женой и решает все же купить, что и делает с успехом (но уже с домашнего компьютера).
При этом, мы, конечно, должны использовать user Id, для того, чтобы Гугл мог их как-то связать.
Будет ли в итоге фигурировать контекстная реклама в мультиканальной последовательности? Похоже, что нет.
Как работают рекомендательные системы. Лекция в Яндексе
11 min
Привет, меня зовут Михаил Ройзнер. Недавно я выступил перед студентами Малого Шада Яндекса с лекцией о том, что такое рекомендательные системы и какие методы там бывают. На основе лекции я подготовил этот пост.
План лекции:
- Виды и области применения рекомендательных систем.
- Простейшие алгоритмы.
- Введение в линейную алгебру.
- Алгоритм SVD.
- Измерение качества рекомендаций.
- Направление развития.
Метрики эффективности для вертикальной поисковой выдачи на основе кликовой модели
15 min
Translation

В 2014 году был опубликован доклад Яндекс, раскрывающий детали и выводы эксперимента, посвященного влиянию поведения пользователей на метрики оценки эффективности выдачи. Перевод осуществлён при поддержке Исследовательского отдела компании ALTWeb Group, который занимается изучением влияния поведенческих факторов на порядок и методы ранжирования. Результаты собственных исследований ALTWeb Group использует для разработки и внедрения современных решений в области цифровой коммерции. Публикации из открытых источников используются в научных целях.
Приводимый доклад Яндекс раскрывает одну из сторон влияния поведенческих факторов на формирование подхода к построению страниц поисковой выдачи. Текст исследования приводится целиком и в ознакомительных целях.
Деньги, товар и немного статистики. Часть вторая
2 min
В первой части статьи я писал о статистической обработке данных по ценам на товары за более чем 30 лет.
Здесь я попробую отследить взаимосвязи между отдельными товарами.
Если быть более точным, под катом немного matlab-кода и изображения графов.
Здесь я попробую отследить взаимосвязи между отдельными товарами.
Если быть более точным, под катом немного matlab-кода и изображения графов.
О формуле Байеса, прогнозах и доверительных интервалах
9 min
На Хабре много статей по этой теме, но они не рассматривают практических задач. Я попытаюсь исправить это досадное недоразумение. Формула Байеса применяется для фильтрации спама, в рекомендательных сервисах и в рейтингах. Без нее значительное число алгоритмов нечеткого поиска было бы невозможно. Кроме того, это формула явилась причиной холивара среди математиков.
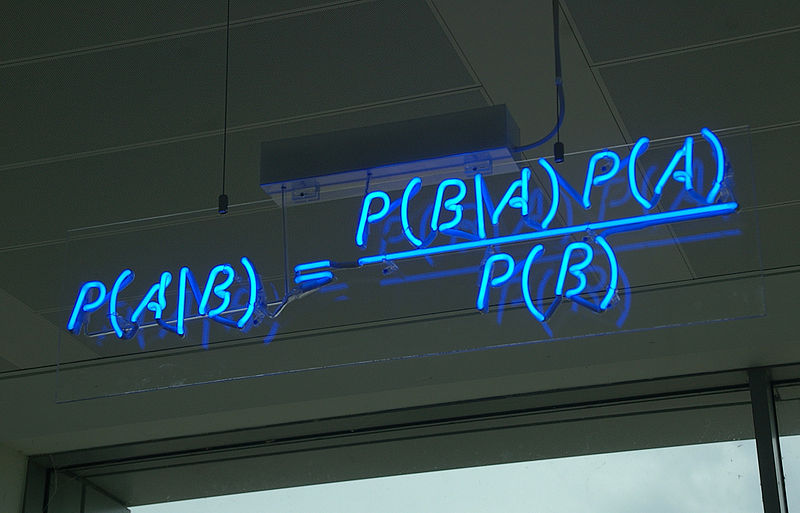
Социальные share-кнопки pluso слетели, пришлось сделать свои
2 min
До недавнего времени мы пользовались PLUSO — это такой бесплатный сервис, генерирующий скрипт, который позволяет посетителям сайта публиковать ссылки на ваши статьи в социальные медиа (закладки, социальные сети). Сервис выглядит в виде кнопок – иконок соц.сетей; удобен в установке и неплохо смотрится. Но обнаружилась и ложка дегтя в этой бочке меда. Pluso подключает кучу не нужных файлов, что довольно сильно тормозит работу ресурса, на котором эти кнопки размещены.
Мы спонтанно решили написать для своего сайта такие кнопочки. Писать пришлось немного, сервер на nodejs, база данных — redis, все работает быстро и не грузит сайт, в отличие от pluso. А еще один минус pluso — отсутствие документации, например, как отследить закрытие окна pluso — никому не известно. В своих кнопках мы добавили событие onclose, которое срабатывает при закрытии этого окна.
Сегодня утром мы обнаружили, что социальные share-кнопки pluso сломались! При запросе на share.pluso.ru/pluso-like.js выводится 502 ошибка и как результат — куча сайтов остались без своих любимых share — кнопок.
Мы спонтанно решили написать для своего сайта такие кнопочки. Писать пришлось немного, сервер на nodejs, база данных — redis, все работает быстро и не грузит сайт, в отличие от pluso. А еще один минус pluso — отсутствие документации, например, как отследить закрытие окна pluso — никому не известно. В своих кнопках мы добавили событие onclose, которое срабатывает при закрытии этого окна.
Сегодня утром мы обнаружили, что социальные share-кнопки pluso сломались! При запросе на share.pluso.ru/pluso-like.js выводится 502 ошибка и как результат — куча сайтов остались без своих любимых share — кнопок.
Как измерить релевантность контента
10 min
Оценка контента одна из главных составляющих формулы релевантности. Знание текстовых признаков и вклад каждого из них в оценку сайта позволит приблизиться к более профессиональной работе с ресурсом. В данной статье будет рассмотрена модель, позволяющая восстановить формулу ранжирования по каждому конкретному запросу, указана значимость определение тематики сайта при продвижении по определенному запросу, а также проработан вопрос, связанного с определением неестественного текста.
Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.
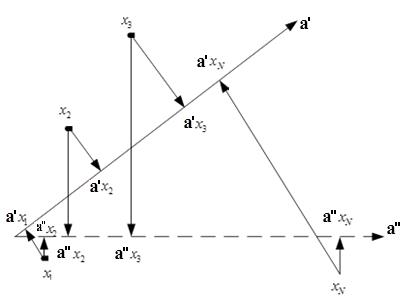
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
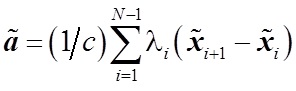 , где
, где 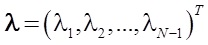 — решение стандартной задачи квадратичного программирования при линейных ограничениях:
— решение стандартной задачи квадратичного программирования при линейных ограничениях: 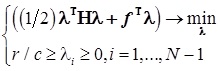 , где
, где
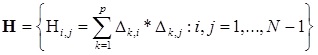 — симметричная матрица
— симметричная матрица
 — вектор коэффициента
— вектор коэффициента
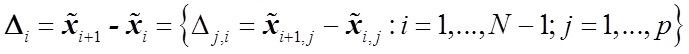 — разница векторов характеристик
— разница векторов характеристик
Данный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Восстановление формулы ранжирования
Если переводить данную задачу в область математики, то входные данные можно представить набором векторов, где каждый вектор – множество характеристик каждого сайта, а координаты в векторе – параметр, по которым оценивается сайт. В описанном векторном пространстве обязательно должна быть задана функция, определяющая отношение порядка двух объектов между собой. Эта функция позволяет ранжировать объекты между собой по принципу «больше — меньше», однако при этом сказать, насколько именно одно больше или меньше другого – нельзя. Такого вида задачи относятся к задачам оценки порядковой регрессии.
Наши сотрудники разработали алгоритм на основе модели линейной регрессии с регулируемой селективностью, который позволил с определенной долей погрешности восстановить ранги сайтов и спрогнозировать изменение выдачи при соответствующих корректировках параметров сайта. Первым шагом алгоритма является обучение модели. В данном случае обучающая выборка представляет собой результаты ранжирования сайтов в рамках одного поискового запроса. Упорядоченность сайтов в рамках поискового запроса фактически означает, что в признаковом пространстве существует некоторое направление, на которое объекты обучающей выборки должны проектироваться в нужном порядке. Это направление и является искомым в задаче восстановления формулы ранжирования. Однако судя по рис.1, таких направлений может быть много.
Рис. 1. Выбор направляющего вектора
Для решения данного вопроса был рассмотрен подход, лежащий в основе метода опорных точек, а именно – выбор такого направления, которое будет обеспечивать максимальное удаление объектов друг от друга.
Следующая задача, которая была решена — выбор стратегии обучения. Рассматривалось два варианта – сокращенная стратегия обучения, при которой учитывается порядок двух соответствующих элементов, и полная стратегия, которая учитывает весь порядок объектов. В результате экспериментов была выбрана сокращенная стратегия, которая заключается в решении следующего уравнения:(1)
, где — решение стандартной задачи квадратичного программирования при линейных ограничениях: , где — симметричная матрица — вектор коэффициента — разница векторов характеристикДанный подход на различных выборках (100 признаков и 500 признаков на 20 различных множествах поисковых запросов) показал хорошие результаты (см. табл. 1).
Энтропия и WinRAR
5 min

Понятие энтропии используется практически во всех областях науки и техники,
от проектирования котельных до моделей человеческого сознания.
Основные определения как для термодинамики, так и для динамических систем и способы вычисления понять не сложно. Но чем дальше в лес — тем больше дров. Например, недавно выяснил (благодаря Р. Пенроуз, «Путь к реальности», стр 592-593), что для жизни на Земле важна не просто солнечная энергия, а её низкая энтропия.
Если ограничится простыми динамическими системами или одномерными массивами данных (которые могут быть получены как «след» движения системы), то и тогда можно насчитать минимум три определения энтропии как меры хаотичности.
Самое глубокое и полное из них (Колмогорова-Синая) можно наглядно изучить,
используя программы — архиваторы файлов.
Отслеживание взаимодействия с контентом при помощи Google Analytics
7 min
По умолчанию в Google Analytics отслеживать взаимодействие посетителей с контентом сайта довольно просто. Используя стандартный код отслеживания, вы сможете получать различную информацию такую как: время проведённое посетителем на странице (time on site), показатель отказов (bounce rate) и количество просмотров (pageviews).
Но иногда этих данных может быть недостаточно. Например, для блогеров или сайтов, где статьи и различные публикации основной контент, этих метрик может не хватать.
Мы хотим получать более детальную информацию по каждому сообщению или статье. Читают ли люди комментарии или только сообщение, статью? Открывают ли они во вкладках несколько сообщений?
Каким способом лучше получать детальную информацию о том как посетители сайта взаимодействуют с каждой страницей?
Эта статья о том, как измерить степень взаимодействия с контентом при помощи кастомизированного кода отслеживания Google Analytics (далее GA).
Но иногда этих данных может быть недостаточно. Например, для блогеров или сайтов, где статьи и различные публикации основной контент, этих метрик может не хватать.
Мы хотим получать более детальную информацию по каждому сообщению или статье. Читают ли люди комментарии или только сообщение, статью? Открывают ли они во вкладках несколько сообщений?
Каким способом лучше получать детальную информацию о том как посетители сайта взаимодействуют с каждой страницей?
Эта статья о том, как измерить степень взаимодействия с контентом при помощи кастомизированного кода отслеживания Google Analytics (далее GA).
Загадка Google Analytics: больше посетителей, чем посещений
3 min
Недавно я столкнулся с ситуацией, когда клиент был сбит с толку одним феноменом, который на первый взгляд действительно выглядит очень странно. Сотрудники клиента установили счетчик посещений лишь на одной странице. То есть они настроили отчет только на одну конкретную страницу, открывающуюся при запросе, и увидели, что есть повторные посещения. Затем они случайно взглянули на уникальные посещения и были очень удивлены. Количество уникальных посетителей было больше числа посещений. Давайте рассмотрим этот факт и увидим, какое объяснение такой странности может быть.
Рейтинги людей: новый герой будущей эпохи
12 min
! Актуальное состояние темы поддерживается теперь в этом гугло-документе.
Сервисы по рейтингованию людей способны стать контролирующим звеном в связке бренды — сайты — пользователи, изменить расстановку сил в существующей экосистеме различных сайтов, а также привнести новые возможности сетевых социальных взаимодействий. Более того, они способны распространить свое влияние и на офлайн, на отношение бизнесов и клиентов или клиентов с клиентами. Под катом очень много букв в обоснование этих тезисов и по другим связанным темам.
Сервисы по рейтингованию людей способны стать контролирующим звеном в связке бренды — сайты — пользователи, изменить расстановку сил в существующей экосистеме различных сайтов, а также привнести новые возможности сетевых социальных взаимодействий. Более того, они способны распространить свое влияние и на офлайн, на отношение бизнесов и клиентов или клиентов с клиентами. Под катом очень много букв в обоснование этих тезисов и по другим связанным темам.