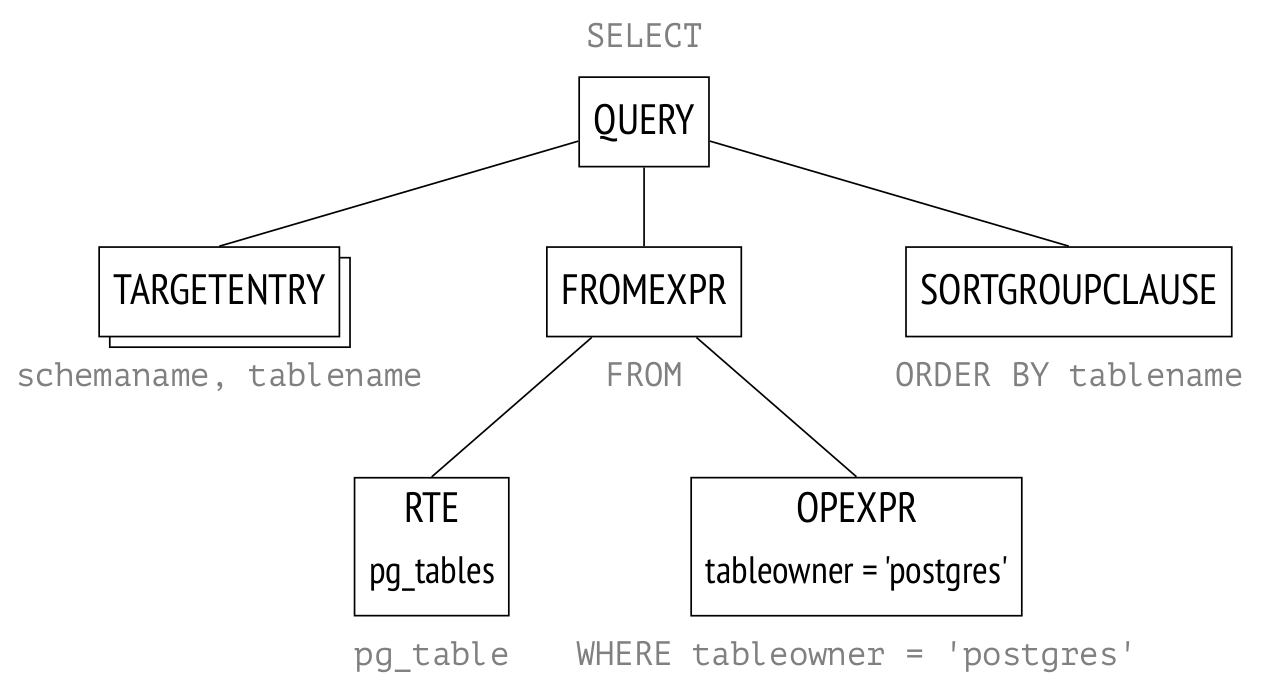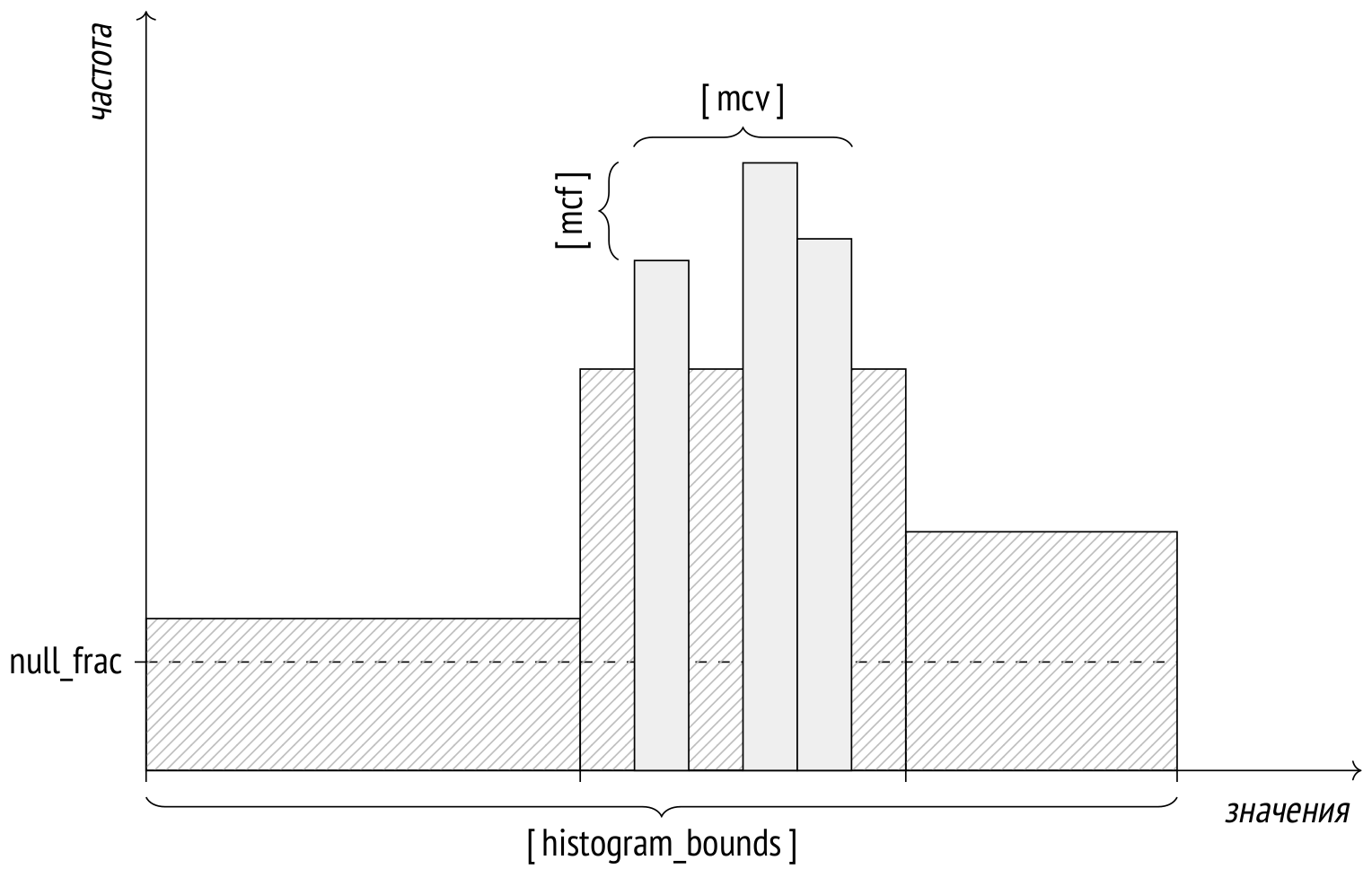
В прошлый раз я рассказал об этапах выполнения запросов. Прежде чем переходить к тому, как работают различные узлы плана (способы доступа к данным и методы соединения), надо разобраться с той основой, на которую опирается стоимостной оптимизатор — со статистикой.
Как обычно, я буду приводить примеры из демобазы. В этой статье будет довольно много планов выполнения, но про их составные части я буду рассказывать только в следующих статьях. Здесь же нас в первую очередь будут интересовать оценки количества строк (кардинальности), то есть числа, указанные в верхней строке плана в позиции rows.