На днях Амит Капила закоммитил патч Масахико Савады, который позволяет выполнять очистку в параллельном режиме. Сама таблица по-прежнему очищается одним (ведущим) процессом, но для очистки индексов он теперь может запускать фоновые рабочие процессы, по одному на каждый индекс. В ручном режиме это позволяет ускорить очистку больших таблиц с несколькими индексами; автоматическая очистка пока не использует эту возможность.

Егор Рогов @erogov
Пользователь
MVCC in PostgreSQL-7. Autovacuum
10 min
Translation
To remind you, we started with problems related to isolation, made a digression about low-level data structure, discussed row versions in detail and observed how data snapshots are obtained from row versions.
Then we explored in-page vacuum (and HOT updates) and vacuum. Now we'll look into autovacuum.
We've already mentioned that normally (i. e., when nothing holds the transaction horizon for a long time) VACUUM usually does its job. The problem is how often to call it.
If we vacuum a changing table too rarely, its size will grow more than desired. Besides, a next vacuum operation may require several passes through indexes if too many changes were done.
If we vacuum the table too often, the server will constantly do maintenance rather than useful work — and this is no good either.
Note that launching VACUUM on schedule by no means resolves the issue because the workload can change with time. If the table starts to change more intensively, it must be vacuumed more often.
Autovacuum is exactly the technique that enables us to launch vacuuming depending on how intensive the table changes are.
Then we explored in-page vacuum (and HOT updates) and vacuum. Now we'll look into autovacuum.
Autovacuum
We've already mentioned that normally (i. e., when nothing holds the transaction horizon for a long time) VACUUM usually does its job. The problem is how often to call it.
If we vacuum a changing table too rarely, its size will grow more than desired. Besides, a next vacuum operation may require several passes through indexes if too many changes were done.
If we vacuum the table too often, the server will constantly do maintenance rather than useful work — and this is no good either.
Note that launching VACUUM on schedule by no means resolves the issue because the workload can change with time. If the table starts to change more intensively, it must be vacuumed more often.
Autovacuum is exactly the technique that enables us to launch vacuuming depending on how intensive the table changes are.
MVCC in PostgreSQL-6. Vacuum
13 min
Translation
We started with problems related to isolation, made a digression about low-level data structure, then discussed row versions and observed how data snapshots are obtained from row versions.
Last time we talked about HOT updates and in-page vacuuming, and today we'll proceed to a well-known vacuum vulgaris. Really, so much has already been written about it that I can hardly add anything new, but the beauty of a full picture requires sacrifice. So keep patience.
In-page vacuum works fast, but frees only part of the space. It works within one table page and does not touch indexes.
The basic, «normal» vacuum is done using the VACUUM command, and we will call it just «vacuum» (leaving «autovacuum» for a separate discussion).
So, vacuum processes the entire table. It vacuums away not only dead tuples, but also references to them from all indexes.
Vacuuming is concurrent with other activities in the system. The table and indexes can be used in a regular way both for reads and updates (however, concurrent execution of commands such as CREATE INDEX, ALTER TABLE and some others is impossible).
Only those table pages are looked through where some activities took place. To detect them, the visibility map is used (to remind you, the map tracks those pages that contain pretty old tuples, which are visible in all data snapshots for sure). Only those pages are processed that are not tracked by the visibility map, and the map itself gets updated.
The free space map also gets updated in the process to reflect the extra free space in the pages.
Last time we talked about HOT updates and in-page vacuuming, and today we'll proceed to a well-known vacuum vulgaris. Really, so much has already been written about it that I can hardly add anything new, but the beauty of a full picture requires sacrifice. So keep patience.
Vacuum
What does vacuum do?
In-page vacuum works fast, but frees only part of the space. It works within one table page and does not touch indexes.
The basic, «normal» vacuum is done using the VACUUM command, and we will call it just «vacuum» (leaving «autovacuum» for a separate discussion).
So, vacuum processes the entire table. It vacuums away not only dead tuples, but also references to them from all indexes.
Vacuuming is concurrent with other activities in the system. The table and indexes can be used in a regular way both for reads and updates (however, concurrent execution of commands such as CREATE INDEX, ALTER TABLE and some others is impossible).
Only those table pages are looked through where some activities took place. To detect them, the visibility map is used (to remind you, the map tracks those pages that contain pretty old tuples, which are visible in all data snapshots for sure). Only those pages are processed that are not tracked by the visibility map, and the map itself gets updated.
The free space map also gets updated in the process to reflect the extra free space in the pages.
MVCC in PostgreSQL-5. In-page vacuum and HOT updates
9 min
Translation
Just to remind you, we already discussed issues related to isolation, made a digression regarding low-level data structure, and then explored row versions and observed how data snapshots are obtained from row versions.
Now we will proceed to two closely connected problems: in-page vacuum и HOT updates. Both techniques can be referred to optimizations; they are important, but virtually not covered in the documentation.
When accessing a page for either an update or read, if PostgreSQL understands that the page is running out of space, it can do a fast in-page vacuum. This happens in either of the cases:
Now we will proceed to two closely connected problems: in-page vacuum и HOT updates. Both techniques can be referred to optimizations; they are important, but virtually not covered in the documentation.
In-page vacuum during regular updates
When accessing a page for either an update or read, if PostgreSQL understands that the page is running out of space, it can do a fast in-page vacuum. This happens in either of the cases:
- A previous update in this page did not find enough space to allocate a new row version in the same page. Such a situation is remembered in the page header, and next time the page is vacuumed.
- The page is more than
fillfactorpercent full. In this case, vacuum is performed right away without putting off till next time.
MVCC in PostgreSQL-4. Snapshots
9 min
Translation
After having discussed isolation problems and having made a digression regarding the low-level data structure, last time we explored row versions and observed how different operations changed tuple header fields.
Now we will look at how consistent data snapshots are obtained from tuples.
Data pages can physically contain several versions of the same row. But each transaction must see only one (or none) version of each row, so that all of them make up a consistent picture of the data (in the sense of ACID) as of a certain point in time.
Isolation in PosgreSQL is based on snapshots: each transaction works with its own data snapshot, which «contains» data that were committed before the moment the snapshot was created and does not «contain» data that were not committed by that moment yet. We've already seen that although the resulting isolation appears stricter than required by the standard, it still has anomalies.
Now we will look at how consistent data snapshots are obtained from tuples.
What is a data snapshot?
Data pages can physically contain several versions of the same row. But each transaction must see only one (or none) version of each row, so that all of them make up a consistent picture of the data (in the sense of ACID) as of a certain point in time.
Isolation in PosgreSQL is based on snapshots: each transaction works with its own data snapshot, which «contains» data that were committed before the moment the snapshot was created and does not «contain» data that were not committed by that moment yet. We've already seen that although the resulting isolation appears stricter than required by the standard, it still has anomalies.
MVCC in PostgreSQL-3. Row Versions
13 min
Translation
Well, we've already discussed isolation and made a digression regarding the low-level data structure. And we've finally reached the most fascinating thing, that is, row versions (tuples).
As already mentioned, several versions of each row can be simultaneously available in the database. And we need to somehow distinguish one version from another one. To this end, each version is labeled with its effective «time» (
(As usual, in reality this is more complicated: the transaction ID cannot always increment due to a limited bit depth of the counter. But we will explore more details of this when our discussion reaches freezing.)
Tuple header
As already mentioned, several versions of each row can be simultaneously available in the database. And we need to somehow distinguish one version from another one. To this end, each version is labeled with its effective «time» (
xmin) and expiration «time» (xmax). Quotation marks denote that a special incrementing counter is used rather than the time itself. And this counter is the transaction identifier.(As usual, in reality this is more complicated: the transaction ID cannot always increment due to a limited bit depth of the counter. But we will explore more details of this when our discussion reaches freezing.)
MVCC in PostgreSQL-2. Forks, files, pages
11 min
Translation
Last time we talked about data consistency, looked at the difference between levels of transaction isolation from the point of view of the user and figured out why this is important to know. Now we are starting to explore how PostgreSQL implements snapshot isolation and multiversion concurrency.
In this article, we will look at how data is physically laid out in files and pages. This takes us away from discussing isolation, but such a digression is necessary to understand what follows. We will need to figure out how the data storage is organized at a low level.
If you look inside tables and indexes, it turns out that they are organized in a similar way. Both are database objects that contain some data consisting of rows.
There is no doubt that a table consists of rows, but this is less obvious for an index. However, imagine a B-tree: it consists of nodes that contain indexed values and references to other nodes or table rows. It's these nodes that can be considered index rows, and in fact, they are.
Actually, a few more objects are organized in a similar way: sequences (essentially single-row tables) and materialized views (essentially, tables that remember the query). And there are also regular views, which do not store data themselves, but are in all other senses similar to tables.
All these objects in PostgreSQL are called the common word relation. This word is extremely improper because it is a term from the relational theory. You can draw a parallel between a relation and a table (view), but certainly not between a relation and an index. But it just so happened: the academic origin of PostgreSQL manifests itself. It seems to me that it's tables and views that were called so first, and the rest swelled over time.
In this article, we will look at how data is physically laid out in files and pages. This takes us away from discussing isolation, but such a digression is necessary to understand what follows. We will need to figure out how the data storage is organized at a low level.
Relations
If you look inside tables and indexes, it turns out that they are organized in a similar way. Both are database objects that contain some data consisting of rows.
There is no doubt that a table consists of rows, but this is less obvious for an index. However, imagine a B-tree: it consists of nodes that contain indexed values and references to other nodes or table rows. It's these nodes that can be considered index rows, and in fact, they are.
Actually, a few more objects are organized in a similar way: sequences (essentially single-row tables) and materialized views (essentially, tables that remember the query). And there are also regular views, which do not store data themselves, but are in all other senses similar to tables.
All these objects in PostgreSQL are called the common word relation. This word is extremely improper because it is a term from the relational theory. You can draw a parallel between a relation and a table (view), but certainly not between a relation and an index. But it just so happened: the academic origin of PostgreSQL manifests itself. It seems to me that it's tables and views that were called so first, and the rest swelled over time.
MVCC in PostgreSQL-1. Isolation
24 min
Translation
Hello, Habr! With this article I start a set of series (or a series of sets? — In a word, the idea is grandiose) about the internal structure of PostgreSQL.
The material will be based on training courses (in Russian) on administration that Pavel pluzanov and I are creating. Not everyone likes to watch video (I definitely do not), and reading slides, even with comments, is no good at all.
Of course, the articles will not be exactly the same as the content of the courses. I will talk only about how everything is organized, omitting the administration itself, but I will try to do it in more detail and more thoroughly. And I believe that the knowledge like this is as useful to an application developer as it is to an administrator.
I will target those who already have some experience in using PostgreSQL and at least in general understand what is what. The text will be too difficult for beginners. For example, I will not say a word about how to install PostgreSQL and run psql.
The stuff in question does not vary much from version to version, but I will use the current, 11th vanilla PostgreSQL.
The first series deals with issues related to isolation and multiversion concurrency, and the plan of the series is as follows:
Off we go!
The material will be based on training courses (in Russian) on administration that Pavel pluzanov and I are creating. Not everyone likes to watch video (I definitely do not), and reading slides, even with comments, is no good at all.
Unfortunately, the only course available in English at the moment is 2-Day Introduction to PostgreSQL 11.
Of course, the articles will not be exactly the same as the content of the courses. I will talk only about how everything is organized, omitting the administration itself, but I will try to do it in more detail and more thoroughly. And I believe that the knowledge like this is as useful to an application developer as it is to an administrator.
I will target those who already have some experience in using PostgreSQL and at least in general understand what is what. The text will be too difficult for beginners. For example, I will not say a word about how to install PostgreSQL and run psql.
The stuff in question does not vary much from version to version, but I will use the current, 11th vanilla PostgreSQL.
The first series deals with issues related to isolation and multiversion concurrency, and the plan of the series is as follows:
- Isolation as understood by the standard and PostgreSQL (this article).
- Forks, files, pages — what is happening at the physical level.
- Row versions, virtual transactions and subtransactions.
- Data snapshots and the visibility of row versions; the event horizon.
- In-page vacuum and HOT updates.
- Normal vacuum.
- Autovacuum.
- Transaction id wraparound and freezing.
Off we go!
And before we start, I would like to thank Elena Indrupskaya for translating the articles to English.
Блокировки в PostgreSQL: 4. Блокировки в памяти
11 min
Напомню, что мы уже поговорили о блокировках отношений, о блокировках на уровне строк, о блокировках других объектов (включая предикатные), и о взаимосвязи разных типов блокировок.
Сегодня я заканчиваю этот цикл статьей про блокировки в оперативной памяти. Мы поговорим о спин-блокировках, легких блокировках и закреплении буфера, а также про средства мониторинга ожиданий и семплирование.
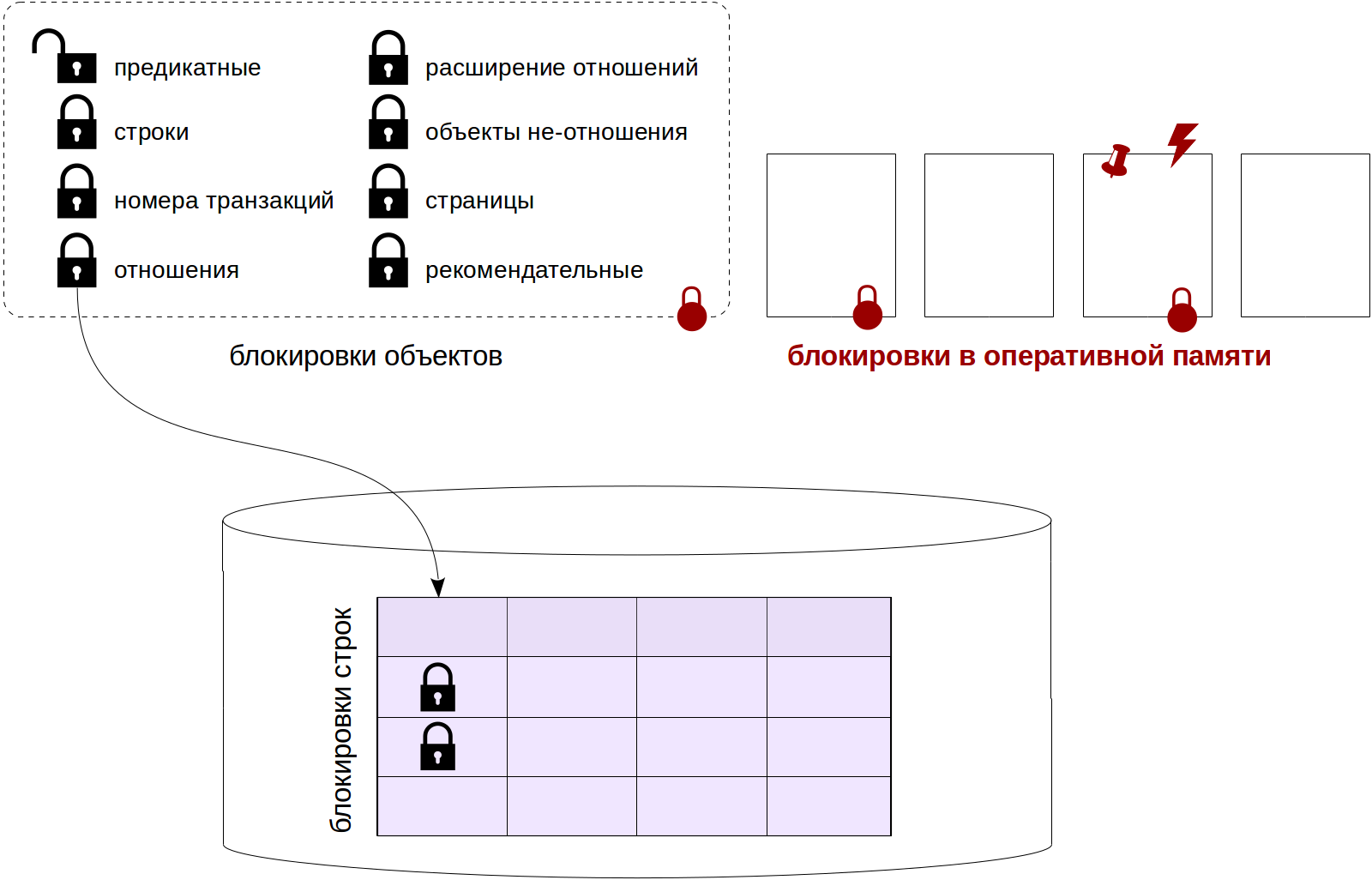
Сегодня я заканчиваю этот цикл статьей про блокировки в оперативной памяти. Мы поговорим о спин-блокировках, легких блокировках и закреплении буфера, а также про средства мониторинга ожиданий и семплирование.
Блокировки в PostgreSQL: 3. Блокировки других объектов
15 min
Мы уже поговорили о некоторых блокировках на уровне объектов (в частности — о блокировках отношений), а также о блокировках на уровне строк, их связи с блокировками объектов и об очереди ожидания, не всегда честной.
Сегодня у нас сборная солянка. Начнем с взаимоблокировок (вообще-то я собирался рассказать о них еще в прошлый раз, но та статья и так получилась неприлично длинной), затем пробежимся по оставшимся блокировкам объектов, и в заключение поговорим про предикатные блокировки.
При использовании блокировок возможна ситуация взаимоблокировки (или тупика). Она возникает, когда одна транзакция пытается захватить ресурс, уже захваченные другой транзакцией, в то время как другая транзакция пытается захватить ресурс, захваченный первой. Это проиллюстрировано на левом рисунке ниже: сплошные стрелки показывают захваченные ресурсы, пунктирные — попытки захватить уже занятый ресурс.
Визуально взаимоблокировку удобно представлять, построив граф ожиданий. Для этого мы убираем конкретные ресурсы и оставляем только транзакции, отмечая, какая транзакция какую ожидает. Если в графе есть контур (из вершины можно по стрелкам добраться до нее же самой) — это взаимоблокировка.

Сегодня у нас сборная солянка. Начнем с взаимоблокировок (вообще-то я собирался рассказать о них еще в прошлый раз, но та статья и так получилась неприлично длинной), затем пробежимся по оставшимся блокировкам объектов, и в заключение поговорим про предикатные блокировки.
Взаимоблокировки
При использовании блокировок возможна ситуация взаимоблокировки (или тупика). Она возникает, когда одна транзакция пытается захватить ресурс, уже захваченные другой транзакцией, в то время как другая транзакция пытается захватить ресурс, захваченный первой. Это проиллюстрировано на левом рисунке ниже: сплошные стрелки показывают захваченные ресурсы, пунктирные — попытки захватить уже занятый ресурс.
Визуально взаимоблокировку удобно представлять, построив граф ожиданий. Для этого мы убираем конкретные ресурсы и оставляем только транзакции, отмечая, какая транзакция какую ожидает. Если в графе есть контур (из вершины можно по стрелкам добраться до нее же самой) — это взаимоблокировка.
Блокировки в PostgreSQL: 2. Блокировки строк
14 min
В прошлый раз мы говорили о блокировках на уровне объектов, в частности — о блокировках отношений. Сегодня посмотрим, как в PostgreSQL устроены блокировки строк и как они используются вместе с блокировками объектов, поговорим про очереди ожидания и про тех, кто лезет без очереди.
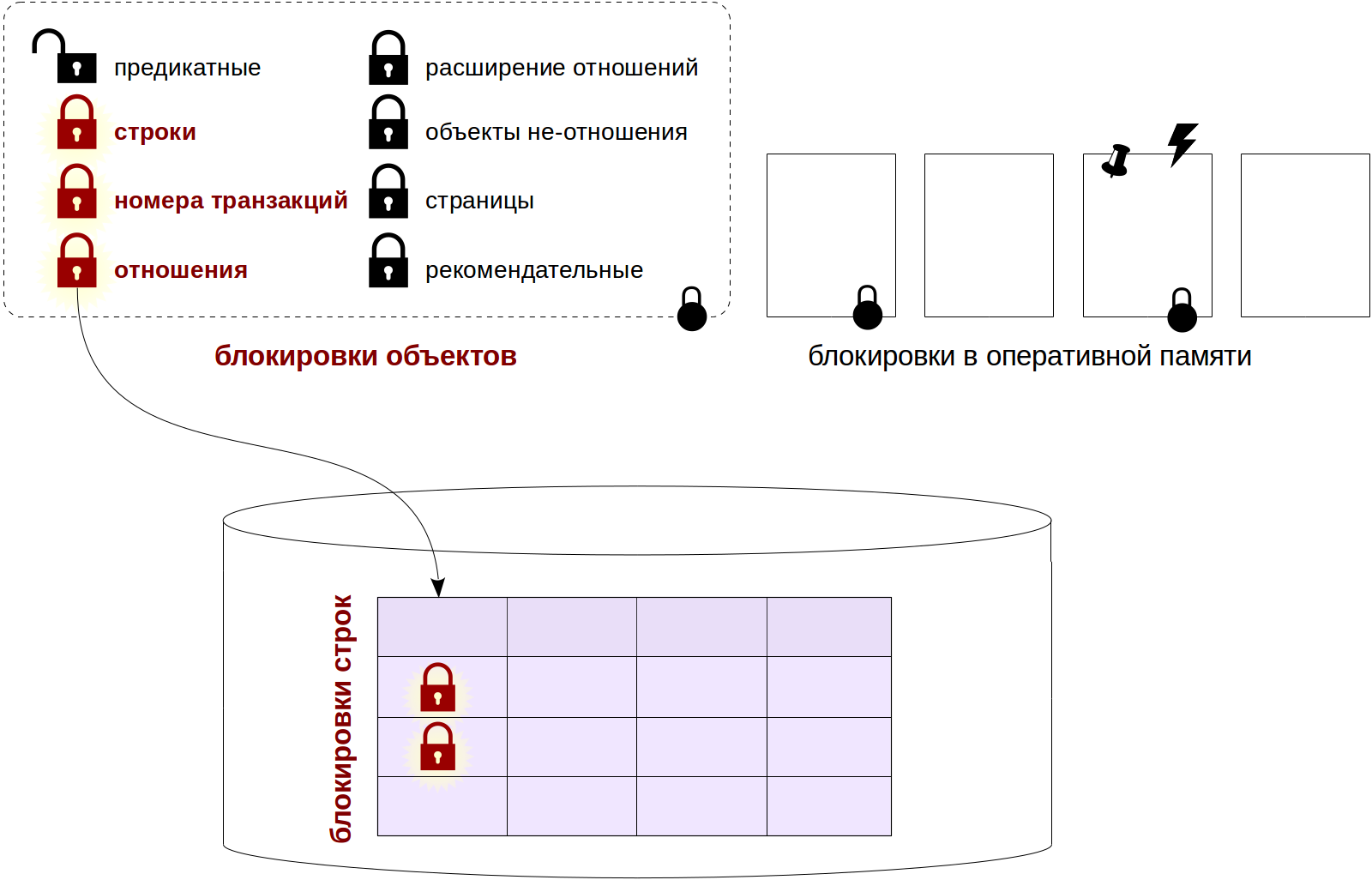
Напомню несколько важных выводов из прошлой статьи.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки строк
Устройство
Напомню несколько важных выводов из прошлой статьи.
- Блокировка должна существовать где-то в разделяемой памяти сервера.
- Чем выше гранулярность блокировок, тем меньше конкуренция (contention) среди одновременно работающих процессов.
- С другой стороны, чем выше гранулярность, тем больше места в памяти занимают блокировки.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки в PostgreSQL: 1. Блокировки отношений
14 min
Два предыдущих цикла статей были посвящены изоляции и многоверсионности и журналированию.
В этом цикле мы поговорим о блокировках (locks). Я буду придерживаться этого термина, но в литературе может встретиться и другой: замóк.
Цикл будет состоять из четырех частей:
Материал всех статей основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
В этом цикле мы поговорим о блокировках (locks). Я буду придерживаться этого термина, но в литературе может встретиться и другой: замóк.
Цикл будет состоять из четырех частей:
- Блокировки отношений (эта статья);
- Блокировки строк;
- Блокировки других объектов и предикатные блокировки;
- Блокировки в оперативной памяти.
Материал всех статей основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
Читайте и другие серии.
Индексы:
- Механизм индексирования;
- Интерфейс метода доступа, классы и семейства операторов;
- Hash;
- B-tree;
- GiST;
- SP-GiST;
- GIN;
- RUM;
- BRIN;
- Bloom.
Изоляция и многоверсионность:
- Изоляция, как ее понимают стандарт и PostgreSQL;
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Журналирование:
- Буферный кеш;
- Журнал предзаписи — как устроен и как используется при восстановлении;
- Контрольная точка и фоновая запись — зачем нужны и как настраиваются;
- Настройка журнала — уровни и решаемые задачи, надежность и производительность.
WAL в PostgreSQL: 4. Настройка журнала
17 min
Итак, мы познакомились с устройством буферного кеша и на его примере поняли, что когда при сбое пропадает содержимое оперативной памяти, для восстановления необходим журнал предзаписи. Размер необходимых файлов журнала и время восстановления ограничены благодаря периодически выполняемой контрольной точке.
В предыдущих статьях мы уже посмотрели на довольно большое число важных настроек, так или иначе относящихся к журналу. В этой статье (последней в этом цикле) мы рассмотрим те вопросы настройки, которые еще не обсуждались: уровни журнала и их назначение, а также надежность и производительность журналирования.
Основная задача журнала предзаписи — обеспечить возможность восстановления после сбоя. Но, если уж все равно приходится вести журнал, его можно приспособить и для других задач, добавив в него некоторое количество дополнительной информации. Есть несколько уровней журналирования. Они задаются параметром wal_level и организованы так, что журнал каждого следующего уровня включает в себя все, что попадает в журнал предыдущего уровня, плюс еще что-то новое.
В предыдущих статьях мы уже посмотрели на довольно большое число важных настроек, так или иначе относящихся к журналу. В этой статье (последней в этом цикле) мы рассмотрим те вопросы настройки, которые еще не обсуждались: уровни журнала и их назначение, а также надежность и производительность журналирования.
Уровни журнала
Основная задача журнала предзаписи — обеспечить возможность восстановления после сбоя. Но, если уж все равно приходится вести журнал, его можно приспособить и для других задач, добавив в него некоторое количество дополнительной информации. Есть несколько уровней журналирования. Они задаются параметром wal_level и организованы так, что журнал каждого следующего уровня включает в себя все, что попадает в журнал предыдущего уровня, плюс еще что-то новое.
WAL в PostgreSQL: 3. Контрольная точка
12 min
Мы уже познакомились с устройством буферного кеша — одного из основных объектов в разделяемой памяти, — и поняли, что для восстановления после сбоя, когда содержимое оперативной памяти пропадает, нужно вести журнал предзаписи.
Нерешенная проблема, на которой мы остановились в прошлый раз, состоит в том, что неизвестно, с какого момента можно начинать проигрывание журнальных записей при восстановлении. Начать с начала, как советовал Король из Алисы, не получится: невозможно хранить все журнальные записи от старта сервера — это потенциально и огромный объем, и такое же огромное время восстановления. Нам нужна такая постепенно продвигающаяся вперед точка, с которой мы можем начинать восстановление (и, соответственно, можем безопасно удалять все предшествующие журнальные записи). Это и есть контрольная точка, о которой сегодня пойдет речь.
Каким свойством должна обладать контрольная точка? Мы должны быть уверены, что все журнальные записи, начиная с контрольной точки, будут применяться к страницам, записанным на диск. Если бы это было не так, при восстановлении мы могли бы прочитать с диска слишком старую версию страницы и применить к ней журнальную запись, и тем самым безвозвратно повредили бы данные.
Нерешенная проблема, на которой мы остановились в прошлый раз, состоит в том, что неизвестно, с какого момента можно начинать проигрывание журнальных записей при восстановлении. Начать с начала, как советовал Король из Алисы, не получится: невозможно хранить все журнальные записи от старта сервера — это потенциально и огромный объем, и такое же огромное время восстановления. Нам нужна такая постепенно продвигающаяся вперед точка, с которой мы можем начинать восстановление (и, соответственно, можем безопасно удалять все предшествующие журнальные записи). Это и есть контрольная точка, о которой сегодня пойдет речь.
Контрольная точка
Каким свойством должна обладать контрольная точка? Мы должны быть уверены, что все журнальные записи, начиная с контрольной точки, будут применяться к страницам, записанным на диск. Если бы это было не так, при восстановлении мы могли бы прочитать с диска слишком старую версию страницы и применить к ней журнальную запись, и тем самым безвозвратно повредили бы данные.
WAL в PostgreSQL: 2. Журнал предзаписи
8 min
В прошлый раз мы познакомились с устройством одного из важных объектов разделяемой памяти, буферного кеша. Возможность потери информации из оперативной памяти — основная причина необходимости средств восстановления после сбоя. Сегодня мы поговорим про эти средства.
Увы, чудес не бывает: чтобы пережить потерю информации в оперативной памяти, все необходимое должно быть своевременно записано на диск (или другое энергонезависимое устройство).
Поэтому сделано вот что. Вместе с изменением данных ведется еще и журнал этих изменений. Когда мы что-то меняем на странице в буферном кеше, мы создаем в журнале запись об этом изменении. Запись содержит минимальную информацию, достаточную для того, чтобы при необходимости изменение можно было повторить.
Чтобы это работало, журнальная запись в обязательном порядке должна попасть на диск до того, как туда попадет измененная страница. Отсюда и название: журнал предзаписи (write-ahead log).
Если происходит сбой, данные на диске оказываются в рассогласованном состоянии: какие-то страницы были записаны раньше, какие-то — позже. Но остается и журнал, который можно прочитать и выполнить повторно те операции, которые уже были выполнены до сбоя, но результат которых не успел дойти до диска.
Журнал
Увы, чудес не бывает: чтобы пережить потерю информации в оперативной памяти, все необходимое должно быть своевременно записано на диск (или другое энергонезависимое устройство).
Поэтому сделано вот что. Вместе с изменением данных ведется еще и журнал этих изменений. Когда мы что-то меняем на странице в буферном кеше, мы создаем в журнале запись об этом изменении. Запись содержит минимальную информацию, достаточную для того, чтобы при необходимости изменение можно было повторить.
Чтобы это работало, журнальная запись в обязательном порядке должна попасть на диск до того, как туда попадет измененная страница. Отсюда и название: журнал предзаписи (write-ahead log).
Если происходит сбой, данные на диске оказываются в рассогласованном состоянии: какие-то страницы были записаны раньше, какие-то — позже. Но остается и журнал, который можно прочитать и выполнить повторно те операции, которые уже были выполнены до сбоя, но результат которых не успел дойти до диска.
WAL в PostgreSQL: 1. Буферный кеш
13 min
Предыдущий цикл был посвящен изоляции и многоверсионности PostgreSQL, а сегодня мы начинаем новый — о механизме журналирования (write-ahead logging). Напомню, что материал основан на учебных курсах по администрированию, которые делаем мы с Павлом pluzanov, но не повторяет их дословно и предназначен для вдумчивого чтения и самостоятельного экспериментирования.
Этот цикл будет состоять из четырех частей:
Этот цикл будет состоять из четырех частей:
- Буферный кеш (эта статья);
- Журнал предзаписи — как устроен и как используется при восстановлении;
- Контрольная точка и фоновая запись — зачем нужны и как настраиваются;
- Настройка журнала — уровни и решаемые задачи, надежность и производительность.
Читайте и другие серии.
Индексы:
- Механизм индексирования;
- Интерфейс метода доступа, классы и семейства операторов;
- Hash;
- B-tree;
- GiST;
- SP-GiST;
- GIN;
- RUM;
- BRIN;
- Bloom.
Изоляция и многоверсионность:
- Изоляция, как ее понимают стандарт и PostgreSQL;
- Слои, файлы, страницы — что творится на физическом уровне;
- Версии строк, виртуальные и вложенные транзакции;
- Снимки данных и видимость версий строк, горизонт событий;
- Внутристраничная очистка и HOT-обновления;
- Обычная очистка (vacuum);
- Автоматическая очистка (autovacuum);
- Переполнение счетчика транзакций и заморозка.
Блокировки:
- Блокировки отношений;
- Блокировки строк;
- Блокировки других объектов и предикатные блокировки;
- Блокировки в оперативной памяти.
MVCC в PostgreSQL-8. Заморозка
12 min
Мы начали с вопросов, связанных с изоляцией, сделали отступление про организацию данных на низком уровне, подробно поговорили о версиях строк и о том, как из версий получаются снимки данных.
Затем мы рассмотрели разные виды очистки: внутристраничную (вместе с HOT-обновлениями), обычную и автоматическую.
И добрались до последней темы этого цикла. Сегодня мы поговорим о проблеме переполнения счетчика транзакций (transaction id wraparound) и заморозке.
Затем мы рассмотрели разные виды очистки: внутристраничную (вместе с HOT-обновлениями), обычную и автоматическую.
И добрались до последней темы этого цикла. Сегодня мы поговорим о проблеме переполнения счетчика транзакций (transaction id wraparound) и заморозке.
Indexes in PostgreSQL — 10 (Bloom)
11 min
Translation
In the previous articles we discussed PostgreSQL indexing engine and the interface of access methods, as well as hash indexes, B-trees, GiST, SP-GiST, GIN, RUM, and BRIN. But we still need to look at Bloom indexes.
A classical Bloom filter is a data structure that enables us to quickly check membership of an element in a set. The filter is highly compact, but allows false positives: it can mistakenly consider an element to be a member of a set (false positive), but it is not permitted to consider an element of a set not to be a member (false negative).
The filter is an array of bits (also called a signature) that is initially filled with zeros. different hash functions are chosen that map any element of the set to bits of the signature. To add an element to the set, we need to set each of these bits in the signature to one. Consequently, if all the bits corresponding to an element are set to one, the element can be a member of the set, but if at least one bit equals zero, the element is not in the set for sure.
In the case of a DBMS, we actually have separate filters built for each index row. As a rule, several fields are included in the index, and it's values of these fields that compose the set of elements for each row.
By choosing the length of the signature , we can find a trade-off between the index size and the probability of false positives. The application area for Bloom index is large, considerably «wide» tables to be queried using filters on each of the fields. This access method, like BRIN, can be regarded as an accelerator of sequential scan: all the matches found by the index must be rechecked with the table, but there is a chance to avoid considering most of the rows at all.
Bloom
General concept
A classical Bloom filter is a data structure that enables us to quickly check membership of an element in a set. The filter is highly compact, but allows false positives: it can mistakenly consider an element to be a member of a set (false positive), but it is not permitted to consider an element of a set not to be a member (false negative).
The filter is an array of bits (also called a signature) that is initially filled with zeros. different hash functions are chosen that map any element of the set to bits of the signature. To add an element to the set, we need to set each of these bits in the signature to one. Consequently, if all the bits corresponding to an element are set to one, the element can be a member of the set, but if at least one bit equals zero, the element is not in the set for sure.
In the case of a DBMS, we actually have separate filters built for each index row. As a rule, several fields are included in the index, and it's values of these fields that compose the set of elements for each row.
By choosing the length of the signature , we can find a trade-off between the index size and the probability of false positives. The application area for Bloom index is large, considerably «wide» tables to be queried using filters on each of the fields. This access method, like BRIN, can be regarded as an accelerator of sequential scan: all the matches found by the index must be rechecked with the table, but there is a chance to avoid considering most of the rows at all.
MVCC-7. Автоочистка
11 min
Напомню, что мы начали с вопросов, связанных с изоляцией, сделали отступление про организацию данных на низком уровне, подробно поговорили о версиях строк и о том, как из версий получаются снимки данных.
Затем мы рассмотрели внутристраничную очистку (и HOT-обновления), обычную очистку, ну а сегодня посмотрим на автоматическую очистку.
Мы уже говорили о том, что обычная очистка в нормальных условиях (когда никто не удерживает надолго горизонт транзакций) должна справляться со своей работой. Вопрос в том, как часто ее вызывать.
Если очищать изменяющуюся таблицу слишком редко, она вырастет в размерах больше, чем хотелось бы. Кроме того, для очередной очистки может потребоваться несколько проходов по индексам, если изменений накопилось слишком много.
Если очищать таблицу слишком часто, то вместо полезной работы сервер будет постоянно заниматься обслуживанием — тоже нехорошо.
Заметим, что запуск обычной очистки по расписанию никак не решает проблему, потому что нагрузка может изменяться со временем. Если таблица стала обновляться активней, то и очищать ее надо чаще.
Автоматическая очистка — как раз тот самый механизм, который позволяет запускать очистку в зависимости от активности изменений в таблицах.
Затем мы рассмотрели внутристраничную очистку (и HOT-обновления), обычную очистку, ну а сегодня посмотрим на автоматическую очистку.
Автоочистка (autovacuum)
Мы уже говорили о том, что обычная очистка в нормальных условиях (когда никто не удерживает надолго горизонт транзакций) должна справляться со своей работой. Вопрос в том, как часто ее вызывать.
Если очищать изменяющуюся таблицу слишком редко, она вырастет в размерах больше, чем хотелось бы. Кроме того, для очередной очистки может потребоваться несколько проходов по индексам, если изменений накопилось слишком много.
Если очищать таблицу слишком часто, то вместо полезной работы сервер будет постоянно заниматься обслуживанием — тоже нехорошо.
Заметим, что запуск обычной очистки по расписанию никак не решает проблему, потому что нагрузка может изменяться со временем. Если таблица стала обновляться активней, то и очищать ее надо чаще.
Автоматическая очистка — как раз тот самый механизм, который позволяет запускать очистку в зависимости от активности изменений в таблицах.
Indexes in PostgreSQL — 9 (BRIN)
18 min
Translation
In the previous articles we discussed PostgreSQL indexing engine, the interface of access methods, and the following methods: hash indexes, B-trees, GiST, SP-GiST, GIN, and RUM. The topic of this article is BRIN indexes.
Unlike indexes with which we've already got acquainted, the idea of BRIN is to avoid looking through definitely unsuited rows rather than quickly find the matching ones. This is always an inaccurate index: it does not contain TIDs of table rows at all.
Simplistically, BRIN works fine for columns where values correlate with their physical location in the table. In other words, if a query without ORDER BY clause returns the column values virtually in the increasing or decreasing order (and there are no indexes on that column).
This access method was created in scope of Axle, the European project for extremely large analytical databases, with an eye on tables that are several terabyte or dozens of terabytes large. An important feature of BRIN that enables us to create indexes on such tables is a small size and minimal overhead costs of maintenance.
This works as follows. The table is split into ranges that are several pages large (or several blocks large, which is the same) — hence the name: Block Range Index, BRIN. The index stores summary information on the data in each range. As a rule, this is the minimal and maximal values, but it happens to be different, as shown further. Assume that a query is performed that contains the condition for a column; if the sought values do not get into the interval, the whole range can be skipped; but if they do get, all rows in all blocks will have to be looked through to choose the matching ones among them.
It will not be a mistake to treat BRIN not as an index, but as an accelerator of sequential scan. We can regard BRIN as an alternative to partitioning if we consider each range as a «virtual» partition.
Now let's discuss the structure of the index in more detail.
BRIN
General concept
Unlike indexes with which we've already got acquainted, the idea of BRIN is to avoid looking through definitely unsuited rows rather than quickly find the matching ones. This is always an inaccurate index: it does not contain TIDs of table rows at all.
Simplistically, BRIN works fine for columns where values correlate with their physical location in the table. In other words, if a query without ORDER BY clause returns the column values virtually in the increasing or decreasing order (and there are no indexes on that column).
This access method was created in scope of Axle, the European project for extremely large analytical databases, with an eye on tables that are several terabyte or dozens of terabytes large. An important feature of BRIN that enables us to create indexes on such tables is a small size and minimal overhead costs of maintenance.
This works as follows. The table is split into ranges that are several pages large (or several blocks large, which is the same) — hence the name: Block Range Index, BRIN. The index stores summary information on the data in each range. As a rule, this is the minimal and maximal values, but it happens to be different, as shown further. Assume that a query is performed that contains the condition for a column; if the sought values do not get into the interval, the whole range can be skipped; but if they do get, all rows in all blocks will have to be looked through to choose the matching ones among them.
It will not be a mistake to treat BRIN not as an index, but as an accelerator of sequential scan. We can regard BRIN as an alternative to partitioning if we consider each range as a «virtual» partition.
Now let's discuss the structure of the index in more detail.