Не давно писал как можно рекомендовать товар в Интернет-магазинах или других местах, используя информацию о пользователе. Сейчас хочу показать алгоритм, который позволяет рекомендовать друзей, например в социальных сетях.
Первый шаг, представим информацию о пользователя в интервальной шкале и рекомендуем пользователю друзей используя коэффициент корреляции Пирсона, который будет измеряет степень линейной зависимости между двумя интервальными переменными. Например, у нас есть 4 пользователя: Дима, Анна, Петя и Саша. Мы знаем о них информацию, которую представляем в виде чисел в массиве (интересы, блоги, возраст и т.д.)
Первый шаг, представим информацию о пользователя в интервальной шкале и рекомендуем пользователю друзей используя коэффициент корреляции Пирсона, который будет измеряет степень линейной зависимости между двумя интервальными переменными. Например, у нас есть 4 пользователя: Дима, Анна, Петя и Саша. Мы знаем о них информацию, которую представляем в виде чисел в массиве (интересы, блоги, возраст и т.д.)

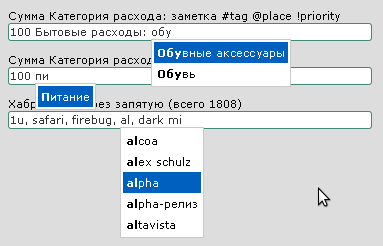
 Привет всем! Очень странно, что я не нашел на Хабре ничего такого, про что расскажу вам далее…
Привет всем! Очень странно, что я не нашел на Хабре ничего такого, про что расскажу вам далее…