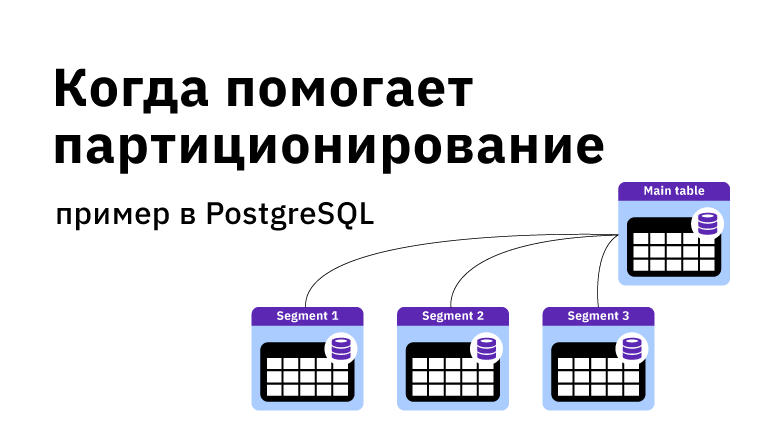
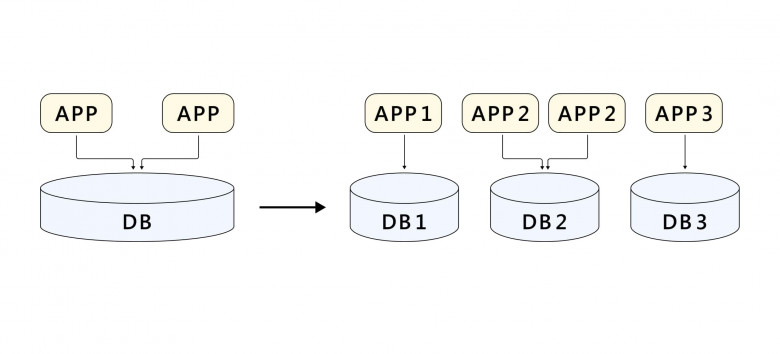
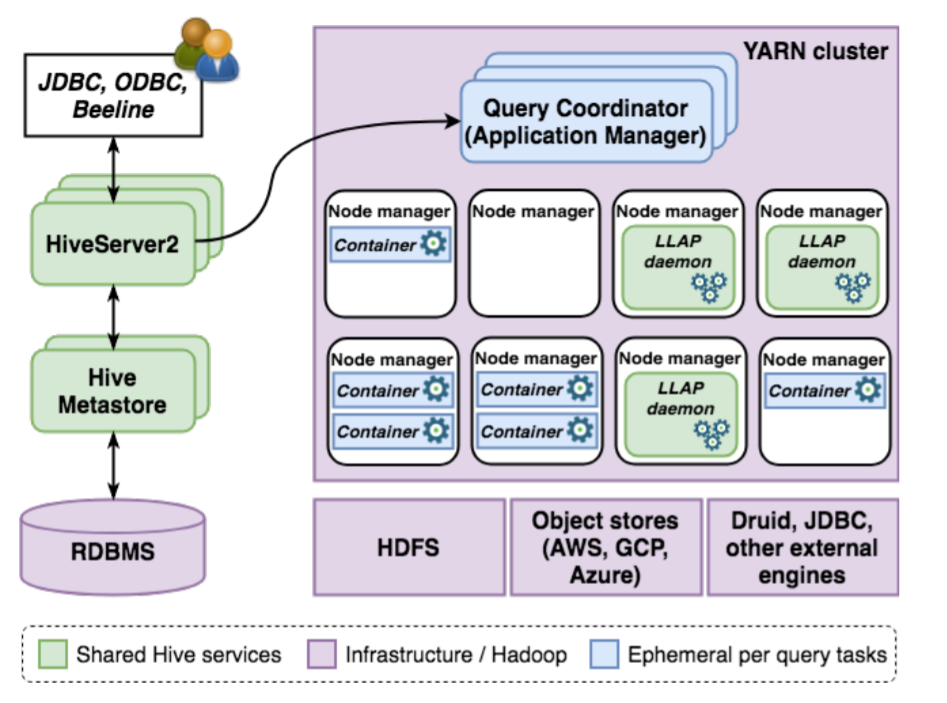
В этой статье вы узнаете о том, какими способами мы пытались обновлять таблицы в Hadoop, содержащие сотни терабайт данных.
И если в начале нашего пути процесс обновления длился несколько часов (до десяти-двенадцати часов), то теперь ему требуется всего тридцать-сорок минут, а использование вычислительных ресурсов уменьшено вдвое!
При этом была создана библиотека расширения Spark, которая предоставляет DataSource для преобразования данных в файлах в формат этого DataSource, изменения данных командой MERGE через DataFrame API или SQL, а в будущем ещё и UPDATE, DELETE и некоторые операции DDL.
Файлы при этом можно будет читать любым привычным способом, ведь они не модифицированы, а метаданные не обязательны для их чтения.
Вы увидите код этой библиотеки на языке Scala, который сможете использовать, а может быть даже доработать и поделиться своими успехами.
Я постараюсь пояснить, почему был сделан тот или иной выбор, но могу умолчать о чём-то, что кажется очевидным, или, наоборот, о чём я не имею представления. Вы сможете задать вопросы, а я постараюсь ответить на них.
Это первая статья из нескольких, и в ней будет рассказано только о немногих реализованных классах (они нужны для распределения данных определённым способом), поэтому наберитесь терпения, я расскажу всё по частям. Впрочем, пора перейти к повествованию.