
Что такое CouchDB для вас? Вероятно любой, кто хоть немного интересуется популярной нынче темой NoSQL, прекрасно знает общие детали: это такая симпатичная игрушка с map/reduce-запросами, которые пишутся на JavaScript, с которой можно работать, гоняя JSON по HTTP-протоколу, а также не исключено, что слышали, что она fault-tolerant, тобишь не ломается вообще. Дальше этого обычно дело не идёт, в результате CouchDB отправляется в delicious в общую кучу со всякими MongoDB, Cassandra, Hadoop и т.п.
Примерно такого мнения придерживался и я вплоть до недавнего времени, пока не возникла острая необходимость переосмыслить архитектуру текущего проекта (упёршегося лбом в свою реляционную БД) и пересесть на документную базу данных, которая бы умела map/reduce. После того, как более пристально взгялнул на CouchDB, я понял, что он уникален в своём классе, его не следует ставить в один ряд с упомянутыми продуктами. Идеи, которые заложены в CouchDB настолько концептуальны, что способны в корне перевернуть представление о разработке веб-приложений.
О том, что же меня так впечатлило, постараюсь рассказать под катом.
Сразу хочу сказать, что если вы уже имеете определённый опыт использования CouchDB, то, вероятно, что вы уже и сами «с усами» и эта статья не для вас. А вот что касается остальных, то может после прочтения появится желание и возможность прилечь на такой вот красный диван и расслабиться, как и рекомендуют разработчики Кауча.
Следует сказать, что шумиха вокруг CouchDB вплоть до последнего времени несколько поутихла, на хабре нечасто проскакивают упоминания об этой БД, хотя за последний месяц твиттер буквально взорвался новостями о релизе CouchDB 1.0 и о выходе Cloudant из фазы закрытого Beta-тестирования (о чём я расскажу чуть подробнее ниже). Поиск говорит, что на хабре это событие толком-то и не было освещено, тогда как выход MongoDB 1.6 отметили отдельным постом. Такую несправедливость надо исправлять, так как если вы помните CouchDB как сырую альфу с медленными инсертами и бешеным потреблением памяти и процессора, то забудьте — это всё уже в далёком прошлом. На сегодняшний день это production-ready система с доступной комерческой поддержкой и реальными примерами использования в продакшне такими компаниями как BBC, например.
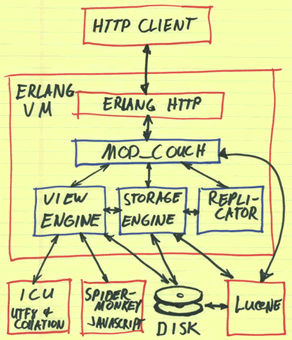
Я не буду детально расписывать основные возможности, о которых вы при желании сможете прочитать на сайте проекта. Постараюсь рассказать о том, что для меня не было очевидно до тех пор, пока я не решился посмотреть на этот продукт поближе в результате чего не уделял этому продукту должного внимания, тогда как мог бы сэкономить себе кучу времени и нервных клеток.
map/reduce
Казалось бы, что здесь сложно кого-то чем-то удивить. Многие NoSQL базы данных используют именно эту парадигму доступа к данным, которые не имеют строго определённой схемы. Плюс ещё настораживает использования JavaScript для описания map/reduce-функций. Первое впечатление — это же должно быть страшно медленно, ведь как минимум
map() необходимо выполнять для каждого документа в базе данных. Плюс ещё и движок-то SpiderMonkey — далеко не V8 по быстродействию. В чём же подвох?Зоркий глаз узреет, что вобще-то в CouchDB используется не map/reduce чистом виде, а т.н. incremental map/reduce. Вся идея заключается в том, что CouchDB не расчитывает свои представления (так называемые views — результаты выполнения функций вроде
map() и reduce()) каждый раз. Это делается только при первом обращении к новому представлению, после чего результат спокойно индексируется и ID документов спокойно попадают в B+-дерево по нужному нам ключу с дополнительной информацией в узлах (а также результатами промежуточных редьюсов). Далее всё просто: когда в базу попадает новый документ (или изменяется старый) для него один раз вызывается map() после чего он кладётся в дерево индекса. Т.е. нет необходимости перерасчитывать индекс целиком, дерево просто инкрементно достраивается.Когда нам нужны результаты, Кауч просто отдаёт нам то, что уже посчитано заранее, нет необходимости заново обходить документы, выполняя
map(). В отличие от того, чтобы проиндексировать несколько отдельных колонок для ускорения поиска, как делает большинство баз данных, мы проиндексировали все результаты запроса одним махом. Представьте себе MySQL, которому вобще не нужно «выполнять» запрос — он может сразу достать все его результаты из одного единственного индекса.Единственный аналог, который приходит в голову — это materialized views из «больших» РСУБД вроде Oracle, но только намного более легковесный. Не забывайте, что хранится только индекс результатов и только нужные вам значения — избыточность не такая уж большая по сравнению с обычными базами данных с кучей индексов, ведь индексируются только результаты map/reduce — те данные, которые вам нужны в контексте данного запроса, а не все колонки. Да и винты нынче дешёвые относительного того потенциала, который сулит этот метод.
I need more power©
Тот факт, что
map() по сути выполняется один единственный раз для каждого нового/изменённого узла, очень интересен. Это позволяет выполнять довольно тяжёлые операции над новым документом, все равно это делается единожды. И если вам кажется, что со встроенным JavaScript рантаймом особо не разгонешься, то тут всплывает ещё одна интересная особенность CouchDB — на самом деле он не завязан ни на какой конкретный язык, а использует абстракцию в виде View-сервера. Т.е. вы просто подключаете view-сервер для вашего любимого языка программирования и пишите map() и reduce() например на Python, пользуясь его его богатой стандартной библиотекой.По большому счёту никто не мешает вам при добавлении нового документа прямо из
map() осуществить геокодинг адреса вашего добавляемого в базу клиента с помощью внешнего сервиса (Google Maps API например) и посчитать для него геоиндекс другой внешней библиотекой. Или просто взять и проиндексировать ваш документ с помощью Sphinx, получив ещё и супербыстрый полнотекстовый индекс вашей БД (если недостаточно хорошей интеграции с Apache Lucene). Вобщем простор для творчества ограничен только фантазией.Если нужно больше скорости, то все ваши view-функции можно переписать на C, воспользовавшись тем фактом, что интерфейс view-сервера прост как лопата, а view в CouchDB — это точно такой же документ, а точнее design-документ со специальным ID. Поэтому ему совсем не обязательно содержать непосредственно код функций — можно положить туда в том числе любой идентификатор, который будет понятен вашему view-серверу. В общем заметно, что вот это идейное единство данных и инструкций по их обработке в виде точно таких же данных сродни идеологии Lisp.
Пусть говорят, что map/reduce парадигма не обеспечивает такой мощи как SQL-запросы, но на практике просто нужно научиться мыслить её категорями. Так например заблуждение, что JOIN нельзя сделать без SQL, т.к. джойны не масштабируются и так далее. Это всё не лишено смысла, тем не менее заявление слишком общее. Во-первых документ можно содержать не только пары ключ-значение, но и коллекции, другие объекты и всё остальное, что можно описать пользуясь JSON, ну а во-вторых даже более сложные джойны можно реализовывать, зная основные паттерны — реализация map/reduce в CouchDB очень мощная и в то же время понятная и логичная.
Веб, как он есть
В отличие от большинства альтернатив, CouchDB разрабатывался в первую очередь как база данных для нужд веб-приложений. Отсюда корни такого нетривиального решения как доступ к базе через REST-интерфейс. Да, у HTTP в чистом виде, есть оверхэд, но он полностью компенсируется тем, насколько элегантным является это решение. Во-первых вам не нужно искать драйвер для любимого языка программирования — любой HTTP-клиент справится (все примеры — это чаще всего curl прямо из командной строки). Более того, таким клиентом может быть веб-браузер. Можно написать веб-приложение вобще не используя какой-либо middleware на сервере — с базой можно работать при помощи JavaScript через Ajax (например CouchApp — фреймворк на базе jQuery от создателей CouchDB).
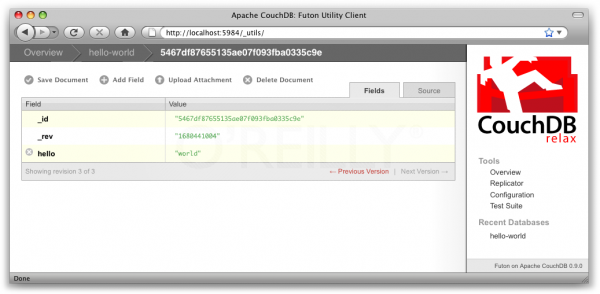
После старта Кауч ведёт себя словно обычный HTTP-сервер, вы можете зайти на него с помощью вашего браузера и выполнять GET-запросы просто используя строку адреса вашего браузера, получая JSON в качестве результата. А также сразу будет доступен Futon — административный интерфейс CouchDB-инстанса. Кстати он реализован полностью на JavaScript без серверного middleware, расширяем и умеет много всего интересного несмотря на свою простоту.
Едва ли стоит говорить о том, что HTTP-протокол реализован правильно, поддерживается кеширование и Кауч знает когда отдать 304. Аналогично документ может содержать бинарные вложения (attachments — эквивалент (B)LOB), которые Кауч хранит нативными файлами и отдаёт просто как статический контент. Design-документы могут также содержать
show() и list(), которые позволяют преобразовывать возвращаемые результаты как угодно, например в HTML-страницы и отдавать их непосредственно браузеру. И если ранее вы придерживались мнения, что хранить аватары пользователей и картинки от товаров вашего Интернет-магазина прямо в вашей [реляционной] БД плохо, то с CouchDB всё обстоит по-другому — иногда даже данные без жесткой схемы могут оказаться в определённых случаях более структурированными и целостными.Как известно, всё гениальное просто. В CouchDB масса таких вот несложных вещей, которые делались с расчётом именно на Веб-приложения, а не на абстрактные данные, которые необходимо как-то обрабатывать. В итоге всё выглядит настолько последовательно, что теперь даже непонятно, как это можно было сделать по-другому.
Масштабирование
О CouchDB раньше обычно говорили, что он не масштабируется. Действительно не так давно это было правдой, но только на половину. Обо всём по порядку.
Одна из ключевых и самых интересных особенностей CouchDB — его репликации. Читатель возможно удивится, как репликации могут быть интересными в принципе, воспринимая их как своего рода костыль. В Кауче всё не так, его репликации проектировались изначально при создании БД. Во-первых они умеют master-to-master, что позволяет вам делать все инстансы одинаково функциональными, а не делить их на master/slave. Проблемой такой репликации в «обычных» базах данных являются потенциальные конфликты. Поэтому Кауч (обладающий свойсвом MVCC), при возникновении конфликта сохраняет все конфликтующие версии и умеет эти конфликты разрешать, по сконфигурированным правилам (либо отдать это дело в руки вашего приложения — как вы захотите этим воспользоваться, зависит только от вашей фантазии). Сама по себе репликация сводится к дёрганию URL из REST-ового API CouchDB (или вопрользовавшись Futon, можно просто ввести URL другой базы и клацнуть нажать кнопку) вот так вот это всё сложно.
Так что вот едите вы в транспорте, пописываете что-то там во всякие твиттеры с вашего Nexus One (я разве не упомянул, что CouchDB полностью функционален на телефонах с Android, а также Maemo/MeeGo?), и тут въезжаете в туннель — коннект теряется. Вы можете спокойно продолжать пользоваться приложением, которое по возвращению коннекта сможет слить новые сообщения и залить то, что вы написали одним API-вызовом, не изобретая велосипедов. Например, если вы пользуетесь Ubuntu One, то вы уже используете CouchDB именно таким образом.

Но не будем отвлекаться от темы. Такие репликации — это конечно хорошо (особенно в свете HTTP-природы CouchDB: можно поставить перед кластером Каучей обычный балансер и не переживать), но это не является «настоящим» масштабированием. Репликациями и реляционные БД умеют масштабироваться (хоть и далеко не так элегантно), а что насчёт шардинга? Ведь все хотят размазать данные по кластеру и просто путём добавления нода увеличить объём доступного дискового пространства, максимальную нагрузку, пиковое количество юзеров и так далее, не теряя при этом в скорости. CouchDB делать этого из коробки не умеет. Пока. Но это лишь вопрос времени.
А вот Cloudant умеет. Cloudant — это новый сервис, который буквально пару дней назад завершил Beta-тестирование и теперь доступен каждому. Это хостинг вашей CouchDB-базы данных (на облаке от Amazon), а то и всего приложения, учитывая, что CouchDB может служить не только БД, но и middleware. Ребята воспользовались заложенным в CouchDB потенциалом, и развивают свой форк (который в скором времени имеет шансы стать частью транка), который неограниченно масштабируется шардингом, в который в любой момент можно добавить новый нод, также он обеспечивает избыточность — каждый документ хранится в трёх экземплярах на разных нодах на тот случай, если один из нодов отвалится. Более того, помимо полной поддержки стандартного API, Cloudant позволяет осуществлять map/reduce по результатам другого map/reduce и имеет ещё много интересных особенностей.
Весь код открыт, так что можете поднять и использовать Cloudant на приватном облаке. А ещё можно зарегистрировать бесплатный аккаунт (до 250 мегабайт дискового пространства без учёта старых ревизий документов) и попробовать CouchDB вживую — все основные возможности доступны, в т.ч. Futon.
Сегодня
CouchDB в июле дорос до версии 1.0, чем разработчики подчёркивают его стабильность и готовность к production-использованию. Также релиз Cloudant является знаковым для всего CouchDB-комьюнити. Если вы ещё не пробовали Кауч, потратьте полчаса вашего времени — можете сэкономить намного больше времени в итоге, хотя это, конечно же, будет зависит от специфики вашего конкретного проекта. Продукт делает именно то, для чего он создавался, но не более. Так что не ждите чуда, но надеюсь, что после прочтения, кто-нибудь расслабится, как рекомендуют разработчики (особенно, если есть красный диван).
