Как это писалось
Одним долгим зимним вечером моя жена играла в Bookworm adventures, и периодически пинала меня по поводу составления слов подлиннее из имеющихся букв. Быстрый поиск по интернету страничек, позволяющих составлять слова из набора букв дал кучу сайтов, которые пытаются делать это на серверной стороне, и один, который делает это на клиентской ява-апплетом. Те, которые составляют слова мощностями сервера либо имеют ограничение на размер набора букв (обычно, почему-то в 8), либо глубоко задумываются, если им послать набор «abcdefghijklmnopqrstuvwxyz». Ява-апплет же имел ограничение в 12 букв, работал шустро и почти подходил (в игре предлагаются 16 букв для составления слов).
Рядом с ява-апплетом, лежал словарик из 170 тысяч английских слов. Незадолго до этого я собеседовался и мне задали задачу, решать которую предполагалось с использованием префиксных деревьев, тогда, к стыду своему, из всех знаний про префиксные деревья у меня в голове осталось только название, и никакого опыта использования не было. Посему решено было этот пробел заполнить.
Деньги я зарабатываю программированием на
Как это все работает
Постановка задачи следующая: пользователь вводит строку, состоящую из букв, необходимо найти в словаре все слова, состоящие из введенных пользователем букв, и использующих каждую букву не более одного раза. Пользователю не запрещено указывать букву более одного раза, если он хочет, чтобы нашлись слова, в которых эта буква встречается соответствующее количество раз.
Как говорит википедия (английская более многословна), префиксное дерево — это дерево хранящее префиксы (т.е. первые несколько букв) слов из словаря. Структура дерева такова, что каждый последующий уровень дерева после корня хранит следующую букву префикса относительно предыдущего уровня. В корне дерева хранится пустой префикс, не содержащий никаких букв. Если пройти по пути от корня дерева до какой-либо листовой вершины, и записывать слева направо буквы из посещаемых вершин, то по окончании пути у нас получится какое-либо слово из словаря. Однако, стоит отметить, что слова не обязательно заканчиваются в листовых вершинах, например, словарь из слов BAD, CAB, CAD, DAB, AB, AD, BA представляется следующим деревом:
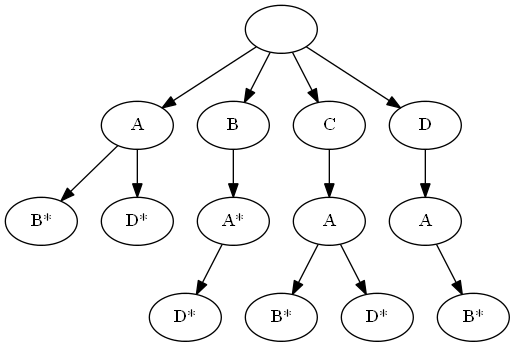
звездочками отмечены узлы, в которых заканчиваются слова.
Итак, в программе дерево представлено ссылкой на корневой узел, каждый узел является объектом Javascript, имеющим поля
data, в котором сохранена буква, соответствующая узлу; terminator если этим узлом заканчивается слово; и некоторым количеством полей с именем из одной буквы со ссылками на дочерние узлы, хранящие поддеревья для соответствующей буквы. Т.е. узел A первого уровня дерева с рисунка в виде JSON выглядит так:{
"data" : "A",
"terminator" : false,
"B" :
{
"data" : "B",
"terminator" : true
},
"D" :
{
"data" : "D",
"terminator" : true
}
}
Словарь представлен в виде массива строк. Для построения дерева, начнем с пустым корневым узлом, будем выбирать последовательно слова из словаря, разбивать на буквы и создавать узлы по необходимости:
var trieRoot;
function buildTrie(wordList)
{
trieRoot = { "data" : "", "terminator" : false };
for ( var i = 0; i < wordList.length; ++i )
{
var word = wordList[i];
var letters = word.split("");
var curNode = trieRoot;
for ( var j = 0; j < letters.length; ++j )
{
if ( curNode[letters[j]] == undefined )
{
curNode[letters[j]] = { "data" : letters[j], "terminator" : false };
}
curNode = curNode[letters[j]];
}
curNode.terminator = true;
}
}
Для составления слов из набора букв необходимо сгенерировать все размещения длиной от 1 до количества букв из списка, задаваемого пользователем. Если в процессе конструирования очередного размещения уже сконструированный префикс отсутствует в словаре, то дальнейшее конструирование размещения можно прекращать. Размещения генерируются простой рекурсивной функцией, одновременно в ней же проверяется наличие текущего префикса.
var letters = [];
var used = [];
var result = [];
var words = {};
function findWords(node, depth)
{
if ( depth > 0 )
{
result[depth - 1] = node.data;
if ( node.terminator )
{
var word = result.slice(0, depth).join("");
words[word] = 1;
}
}
for ( var i = 0; i < letters.length; ++i )
{
var child;
if ( !used[i] && (child = node[letters[i]]) != undefined )
{
used[i] = true;
findWords(child, depth + 1);
used[i] = false;
}
}
}
В массиве
letters лежит список букв, введенных пользователем, массив used хранит флаги использования соответствующей по индексу буквы из массива letters в текущем размещении. В result хранится текущее размещение, в words — найденные слова, хранятся в объекте, используемом как ассоциативный массив, чтобы исключить повторения в случае, когда пользователь задает несколько повторений одной буквы («AAABBBCCCDDD»).Весь остальной код посвящен обработке ввода и вывода, и к самим деревьям отношения имеет мало.
Зачем это надо
Что касается меня, я теперь могу честно сказать, что знаю, что такое префиксное дерево и сталкивался с практической его реализацией. А вообще, практически такое дерево можно применить, например, для хранения и быстрого поиска информации по первым введенным символам (вроде search suggestions), поиск происходит очень быстро, время поиска зависит только от длины префикса и размера алфавита, причем если пожертвовать памятью, можно избавиться от зависимости от размера алфавита.
