Впервые данный алгоритм встретил на Википедии и не обратил на него особого внимания. Позже изучая научные труды сотрудников Яндекса, я обратил внимание на то, что они ссылаются на него, например, в статье Сегаловича об алгоритмах определения нечетких дубликатов, поэтому решил разобраться, в чем смысл его использования. Постараюсь на простых примерах это объяснить. Итак, для чего этот алгоритм?
Первое. Вводится зависимость релевантности от вхождения или не вхождения слов в запросах с более чем одного слова.
Пусть есть несколько запросов состоящих из нескольких слов, например (пример чисто иллюстративный):
Пусть сравниваются два документы (опять же иллюстративно) и первый документ не содержит слова Galaxy. Согласно расчетов оценка релевантности эта сума релевантностей каждого из слов.

Релевантность каждого из слова равна его IDF * на второй множитель в выражении выше. Релевантность всего поискового запроса равна сумме релевантностей всех слов. Таким образом, отсутствие слова или другими словами (его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
(его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
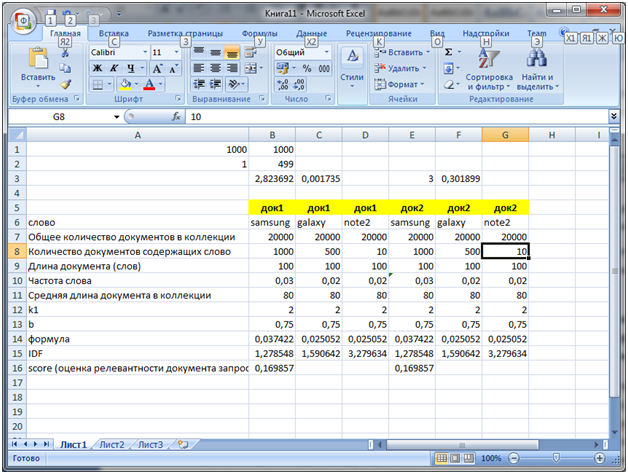
Второе. Преимущество при поиске в запросах с более чем 2-ух слов, одно из которых менее употребительно (более узкоспециализированное) будет отдаваться документам которые содержат это узкоспециализированное слово. Например, есть запрос купить Samsung Galaxy Note 2 (чисто иллюзорный пример). Пусть Note 2 – это более редкое слово (меньше раз встречается в коллекции чем Samsung и Galaxy). Пусть есть 2-а документа каждый из которых релевантен запросу и каждый из них содержит кроме Samsung и Galaxy также Note 2. При этом в первом документе note 2 употребляется только один раз, тогда как во втором – 3 раза (подразумевается, что документ содержит больше информации о Note 2). Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы. Вот что получается по BM25 в Excel.

Обратите также внимание, что из-за того, что количество документов содержащее слово Note 2 меньше равно в 50 раз от содержащих слово galaxy (500) мы получаем IDF равный 3,279634 что значительно больше IDF для слова galaxy.
Пока что у нас были одинаковые значения частот для слова note 2 (для других слов также). Теперь давайте в Excel увеличим частотность слова note 2 для док2, вместо 0,02 сделаем 0,05 (5 вхождений слова).
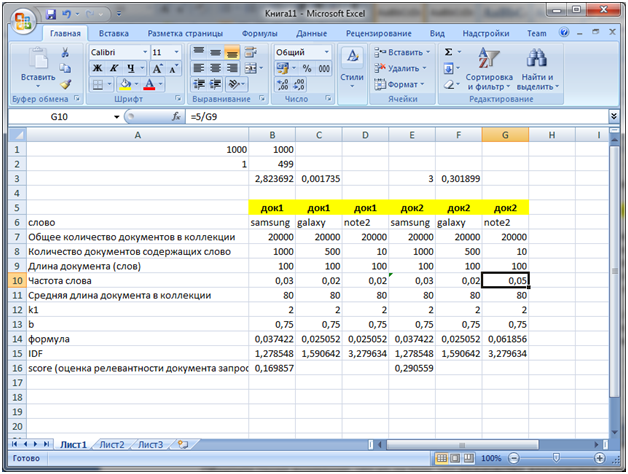
Обратите внимание, что значение IDF не изменяется но значение формула (второй множитель на изображении в самом вверху) теперь стало равно 0,061856 и именно это значение участвует в вычислении score, которое теперь для док2 равно уже 0,290559
Теперь самое главное. Увеличим частоту вхождения слова galaxy до 5 в док 1
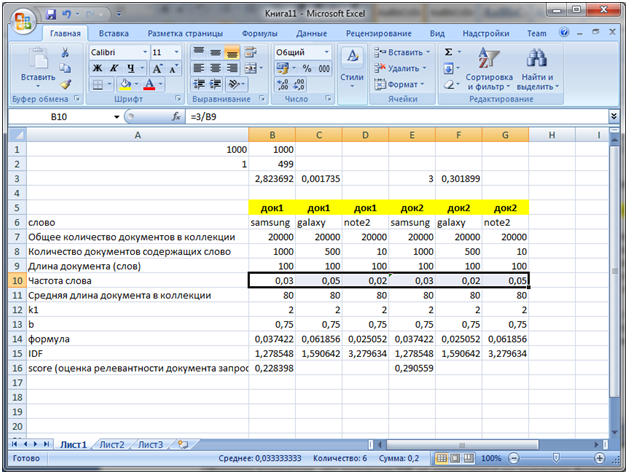
Как мы видим суммарная частота каждого из слов в док1 и док2 одинакова. Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
На практике наличие слов в многосложных запросах очень важно. Конечно же релевантность современных поисковых систем определяется не только исходя из частот как это было показано на примере формулы BM25, но все же некоторые корреляции провести можно. В основном это касается того, что если в документе нет слова из поискового запроса то такому документу значительно сложнее подняться в ТОП по запросу по сравнению с теми, у которых это слово содержится. Давайте рассмотрим пример на поисковой системе Яндекс.
Вводим запрос Samsung galaxy. У меня выдача касалась Samsung galaxy в целом (2 сайта, как обычно Википедия) остальное модели, картинки и т.д.
Вводим запрос samsung galaxy note 2. Выдача полностью меняется, теперь представлены страницы, которые содержат информацию не просто о Samsung galaxy, а о Samsung galaxy note 2.
Вводим запрос samsung galaxy note 2 ценаОпять выдача меняется теперь в выдаче страницы, которые уже содержат слово цена, а не просто Samsung galaxy.
Вводим запрос samsung galaxy note 2 цена Харьков. Выдача кардинально меняется, все страницы в ТОП10 содержат слово Харьков.
Можно ли сказать, что слово Харьков является более узкоспециализированным, как это приводилось в алгоритме BM25 выше? IDF cлова Харьков знает только поисковая система, но в контексте поискового запроса Samsung galaxy note 2 оно без сомнения сужает область поиска. Может быть пример с Яндексом немного неудачен, в силу того, что в приведенном случае большую роль будет играть учет региональности запроса, но я думаю со мной согласится любой сеошник, что слово из поискового запроса обязательно должно быть в тексте, я же всего лишь постарался показать работу алгоритма BM25 и раскрыть 2-а важных его аспекта.
Ссылка на xls документ — книга11.xls
Первое. Вводится зависимость релевантности от вхождения или не вхождения слов в запросах с более чем одного слова.
Пусть есть несколько запросов состоящих из нескольких слов, например (пример чисто иллюстративный):
- купить смартфон Samsung
- купить смартфон Samsung Galaxy
Пусть сравниваются два документы (опять же иллюстративно) и первый документ не содержит слова Galaxy. Согласно расчетов оценка релевантности эта сума релевантностей каждого из слов.

Релевантность каждого из слова равна его IDF * на второй множитель в выражении выше. Релевантность всего поискового запроса равна сумме релевантностей всех слов. Таким образом, отсутствие слова или другими словами
 (его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.
(его частота) равна 0 дает релевантность 0. Поэтому если по двум первым словам score будет одинаково то более релевантным будет тот документ, который содержит слово Galaxy.Второе. Преимущество при поиске в запросах с более чем 2-ух слов, одно из которых менее употребительно (более узкоспециализированное) будет отдаваться документам которые содержат это узкоспециализированное слово. Например, есть запрос купить Samsung Galaxy Note 2 (чисто иллюзорный пример). Пусть Note 2 – это более редкое слово (меньше раз встречается в коллекции чем Samsung и Galaxy). Пусть есть 2-а документа каждый из которых релевантен запросу и каждый из них содержит кроме Samsung и Galaxy также Note 2. При этом в первом документе note 2 употребляется только один раз, тогда как во втором – 3 раза (подразумевается, что документ содержит больше информации о Note 2). Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы. Вот что получается по BM25 в Excel.
Обратите также внимание, что из-за того, что количество документов содержащее слово Note 2 меньше равно в 50 раз от содержащих слово galaxy (500) мы получаем IDF равный 3,279634 что значительно больше IDF для слова galaxy.
Пока что у нас были одинаковые значения частот для слова note 2 (для других слов также). Теперь давайте в Excel увеличим частотность слова note 2 для док2, вместо 0,02 сделаем 0,05 (5 вхождений слова).
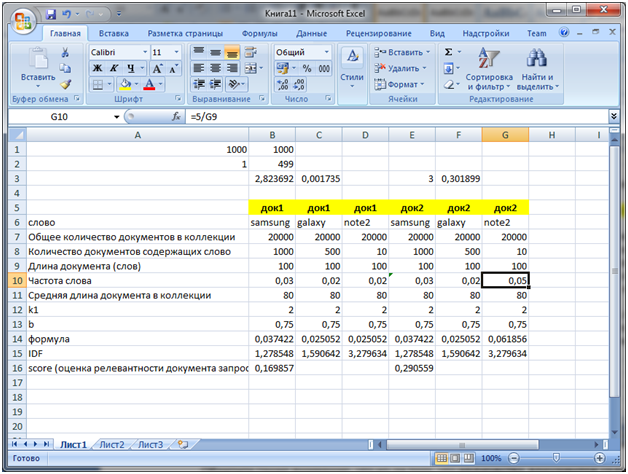
Обратите внимание, что значение IDF не изменяется но значение формула (второй множитель на изображении в самом вверху) теперь стало равно 0,061856 и именно это значение участвует в вычислении score, которое теперь для док2 равно уже 0,290559
Теперь самое главное. Увеличим частоту вхождения слова galaxy до 5 в док 1
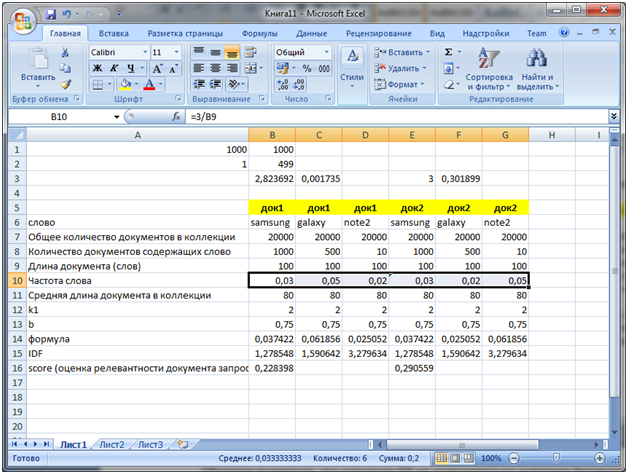
Как мы видим суммарная частота каждого из слов в док1 и док2 одинакова. Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
На практике наличие слов в многосложных запросах очень важно. Конечно же релевантность современных поисковых систем определяется не только исходя из частот как это было показано на примере формулы BM25, но все же некоторые корреляции провести можно. В основном это касается того, что если в документе нет слова из поискового запроса то такому документу значительно сложнее подняться в ТОП по запросу по сравнению с теми, у которых это слово содержится. Давайте рассмотрим пример на поисковой системе Яндекс.
Вводим запрос Samsung galaxy. У меня выдача касалась Samsung galaxy в целом (2 сайта, как обычно Википедия) остальное модели, картинки и т.д.
Вводим запрос samsung galaxy note 2. Выдача полностью меняется, теперь представлены страницы, которые содержат информацию не просто о Samsung galaxy, а о Samsung galaxy note 2.
Вводим запрос samsung galaxy note 2 ценаОпять выдача меняется теперь в выдаче страницы, которые уже содержат слово цена, а не просто Samsung galaxy.
Вводим запрос samsung galaxy note 2 цена Харьков. Выдача кардинально меняется, все страницы в ТОП10 содержат слово Харьков.
Можно ли сказать, что слово Харьков является более узкоспециализированным, как это приводилось в алгоритме BM25 выше? IDF cлова Харьков знает только поисковая система, но в контексте поискового запроса Samsung galaxy note 2 оно без сомнения сужает область поиска. Может быть пример с Яндексом немного неудачен, в силу того, что в приведенном случае большую роль будет играть учет региональности запроса, но я думаю со мной согласится любой сеошник, что слово из поискового запроса обязательно должно быть в тексте, я же всего лишь постарался показать работу алгоритма BM25 и раскрыть 2-а важных его аспекта.
Ссылка на xls документ — книга11.xls
