В январе этого года в одном из сервисов ICQ была найдена уязвимость. Она была связана с доступом к файлам, которые когда-то пользователи передавали друг-другу. Уязвимость устранили, но такие ситуации отнюдь не уникальные.
Ниже мы рассмотрим еще один сервис, предназначенный для файлообмена между пользователями.
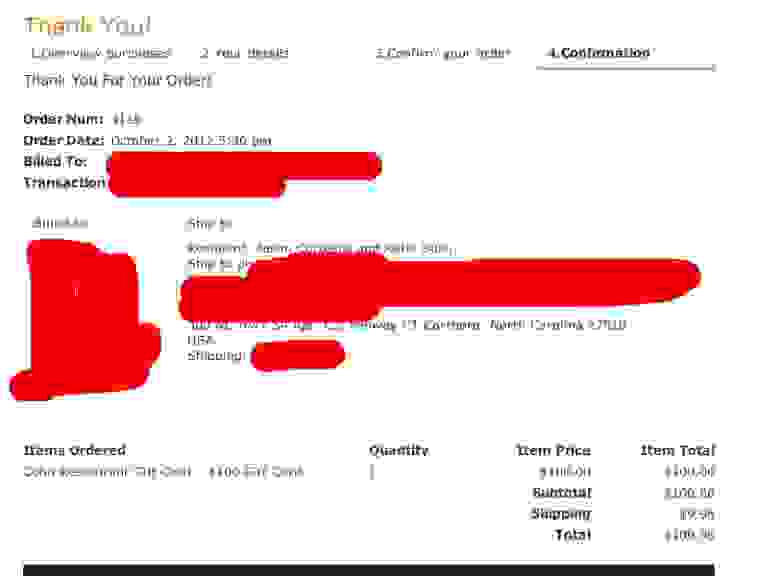
Сегодня один из заказчиков прислал мне ТЗ используя сайт droplr.com. Сервис действительно удобный. Я не пользуюсь всякими дропбоксами и подобными просто из-за низкой скорости интернета. Но данный сервис мне понравился, всё достаточно удобно, интерфейс, клиенты под различные платформы, но самое главное — можно качать чужие файлы.
Когда я перешел по ссылке от заказчика, стало ясно, что на droplr используется сокращатель ссылок. В результате страница для загрузки файла имеет примерно такой вид:
В случае с первым вхождением используется лишь один символ нижнего регистра, который как показало время совершенно безразличен системе.
Вторая последовательность длиной в 4 символа может состоять из строчных, прописных латинских символов и цифр.
Учитывая, что сервисом пользуется огромная масса народа, можно предположить, что при брутфорсе второго параметра мы будем часто натыкаться на чужие файлы, ведь общее число возможных вариантов — 14776336.
Обычно, подобные задачи я пишу на PHP или голом BASH, там есть всё что нужно, прямо из коробки. Но нужно развиваться, поэтому решил остановиться на Python, поскольку некоторый опыт работы с ним уже есть.
Судя по задаче нам необходимо как-то обращаться к сервису, в Python для этого есть много реализаций и интерфейсов, я решил остановиться на requests, поскольку эта библиотека обладает всеми требованиями, которые нам необходимы.
В случае, если у вас стоит pip, то установка займет всего несколько секунд.
Для парсинга страницы существует мощная библиотека под названием BeautifulSoup. Установка через pip тоже элементарна.
Скачать скрипт можно на GitHub.
Как я и думал, после первых 5 минут работы было найдено порядка 10 изображений с персональными данными, да еще какими!
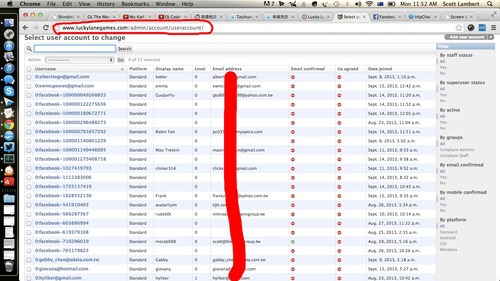
Админка сайте, включая некоторые данные о юзерах.
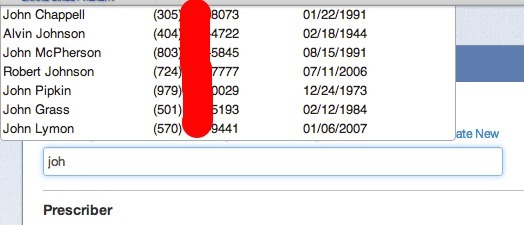
А вот и номера телефонов
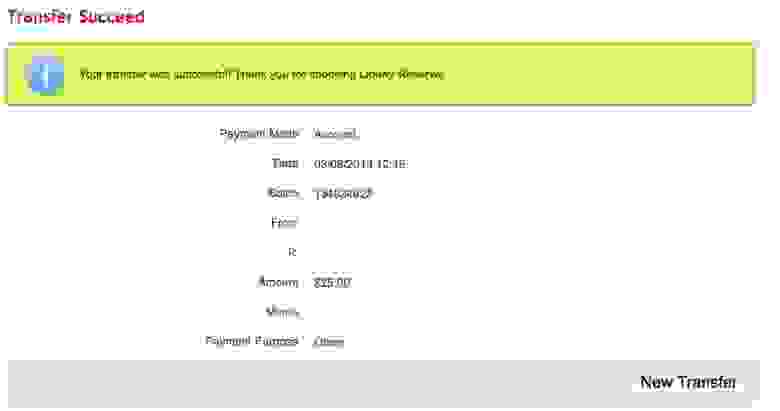
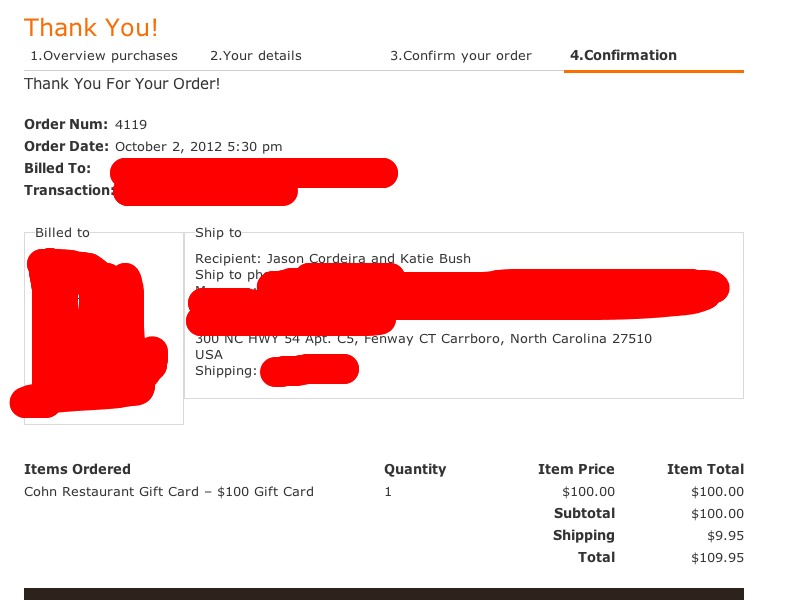
Один день из жизни LR.
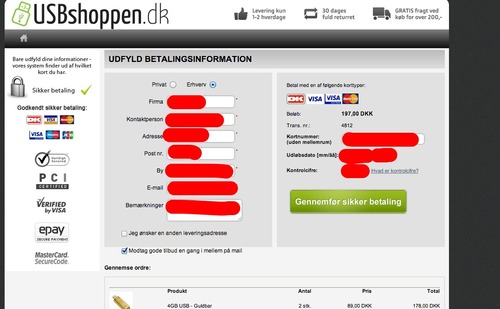
Из разряда, на друг, покупай за мой счёт.
Думаю этого достаточно для демонстрации 5 минут работы скрипта.
Будьте бдительны, не публикуйте персональные и тем более платежные данные в сети.
На сайте нет абсолютно никаких проверок на бота. Нам даже юзер агента отсылать не нужно. Естественно никакого бана за множественные запросы не следует.
Прямая ссылка на файл живет около минуты, новую ссылку можно получить только после посещения страницы скачивания файла.
Примерно 80% рандомных ссылок указывают на файлы.
UP #1 пользователь lybin добавил поддержку многопоточности.
UP #2 больше нет HEAD запроса, всё в одном GET, добавлен User Agent, Referer и таймаут.
Ниже мы рассмотрим еще один сервис, предназначенный для файлообмена между пользователями.
Сегодня один из заказчиков прислал мне ТЗ используя сайт droplr.com. Сервис действительно удобный. Я не пользуюсь всякими дропбоксами и подобными просто из-за низкой скорости интернета. Но данный сервис мне понравился, всё достаточно удобно, интерфейс, клиенты под различные платформы, но самое главное — можно качать чужие файлы.
Когда я перешел по ссылке от заказчика, стало ясно, что на droplr используется сокращатель ссылок. В результате страница для загрузки файла имеет примерно такой вид:
d.pr[a-z]{1}/[A-z0-9]{4}В случае с первым вхождением используется лишь один символ нижнего регистра, который как показало время совершенно безразличен системе.
Вторая последовательность длиной в 4 символа может состоять из строчных, прописных латинских символов и цифр.
Учитывая, что сервисом пользуется огромная масса народа, можно предположить, что при брутфорсе второго параметра мы будем часто натыкаться на чужие файлы, ведь общее число возможных вариантов — 14776336.
Обычно, подобные задачи я пишу на PHP или голом BASH, там есть всё что нужно, прямо из коробки. Но нужно развиваться, поэтому решил остановиться на Python, поскольку некоторый опыт работы с ним уже есть.
Судя по задаче нам необходимо как-то обращаться к сервису, в Python для этого есть много реализаций и интерфейсов, я решил остановиться на requests, поскольку эта библиотека обладает всеми требованиями, которые нам необходимы.
В случае, если у вас стоит pip, то установка займет всего несколько секунд.
pip install requestsДля парсинга страницы существует мощная библиотека под названием BeautifulSoup. Установка через pip тоже элементарна.
pip install beautifulsoup4Скачать скрипт можно на GitHub.
Как я и думал, после первых 5 минут работы было найдено порядка 10 изображений с персональными данными, да еще какими!
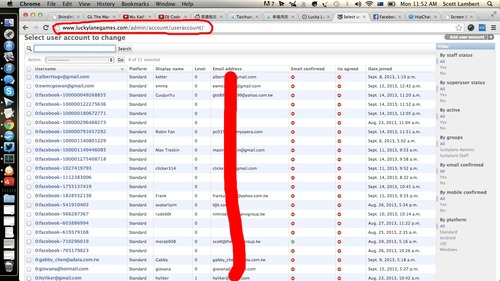
Админка сайте, включая некоторые данные о юзерах.
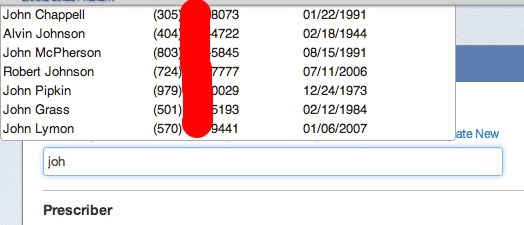
А вот и номера телефонов
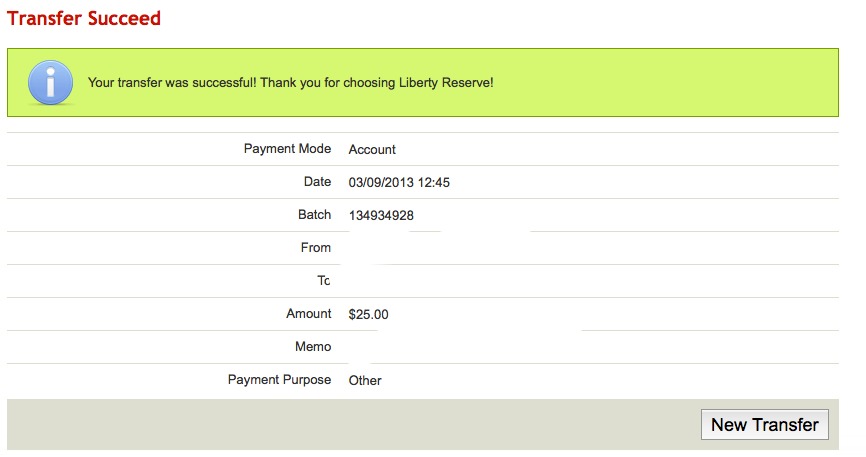
Один день из жизни LR.

Из разряда, на друг, покупай за мой счёт.
Думаю этого достаточно для демонстрации 5 минут работы скрипта.
Будьте бдительны, не публикуйте персональные и тем более платежные данные в сети.
Некоторые особенности
На сайте нет абсолютно никаких проверок на бота. Нам даже юзер агента отсылать не нужно. Естественно никакого бана за множественные запросы не следует.
Прямая ссылка на файл живет около минуты, новую ссылку можно получить только после посещения страницы скачивания файла.
Примерно 80% рандомных ссылок указывают на файлы.
UP #1 пользователь lybin добавил поддержку многопоточности.
UP #2 больше нет HEAD запроса, всё в одном GET, добавлен User Agent, Referer и таймаут.
