Примечание от переводчика: я серверный Java-программист, но при этом так исторически сложилось, что работаю исключительно под Windows. В команде все сидят в основном на Mac или Linux, но кто-то же должен вживую тестировать веб-интерфейсы проектов под настоящим IE, кому как не мне? Так что я уже довольно много лет использую его и по рабочей необходимости, и — в силу лени — в качестве основного браузера. По-моему, с каждой новой версией, начиная с девятой, он становится всё более и более достойным, а Project Spartan и вовсе обещает быть отличным. По крайней мере, в технологическом плане — на равных с другими. Предлагаю вашему вниманию перевод статьи из блога разработчиков, дающей некоторые основания на это надеяться.

Поставив перед собой задачу обеспечить в Windows 10 по-настоящему совместимую и современную веб-платформу, мы постоянно работаем над улучшением поддержки стандартов, в частности, в отношении DOM L3 XPath. Сегодня нам хотелось бы рассказать, как мы этого добились в Project Spartan.
До того, как реализовать поддержку стандарта DOM L3 Core и нативных XML-документов в IE9, мы предоставляли веб-разработчикам библиотеку MSXML посредством механизма ActiveX. Кроме объекта XMLHttpRequest, MSXML обеспечивала и частичную поддержку языка запросов XPath через набор собственных API, selectSingleNode и selectNodes. С точки зрения приложений, использующих MSXML, этот способ просто работал. Однако, он совершенно не соответствовал стандартам W3C ни для взаимодействия с XML, ни для работы с XPath.
Авторам библиотек и разработчикам сайтов приходилось обёртывать вызовы XPath для переключения между имплементациями «на лету». Если вы поищете в сети учебники или примеры по XPath, вы сразу заметите обёртки для IE и MSXML, например,
Для нашего нового движка, ориентированного на веб без плагинов, нам потребовалось обеспечить нативную поддержку XPath.
Мы сразу же начали оценивать имеющиеся варианты воплощения такой поддержки. Можно было бы написать её с нуля, или полностью интегрировать в браузер MSXML, или портировать System.XML из .NET, но всё это потребовало бы слишком много времени. Поэтому мы решили для начала реализовать поддержку некоторого основного подмножества XPath, попутно думая над полной.
Чтобы определить, за какое начальное подмножество стандарта стоит взяться, мы использовали внутренний инструмент, собирающий статистику по запросам на сотнях тысяч самых популярных сайтов. Выяснилось, что наиболее часто встречаются запросы таких видов:
Каждый из них прекрасно соответствует некоему селектору CSS, который можно перенаправить к уже имеющейся у нас очень быстрой реализации API селекторов CSS. Сравните сами:
Таким образом, первый шаг в реализации поддержки XPath заключался в написании конвертера из запросов XPath в селекторы CSS, и перенаправлению вызова в правильное место. Сделав это, мы снова использовали нашу телеметрию, чтобы измерить процент успешных запросов, а также выяснить, какие именно из неуспешных встречаются чаще всего.
Оказалось, что такая реализация покрывает аж 94% запросов, и позволяет сразу же заработать множеству сайтов. Из безуспешных большинство оказалось видов
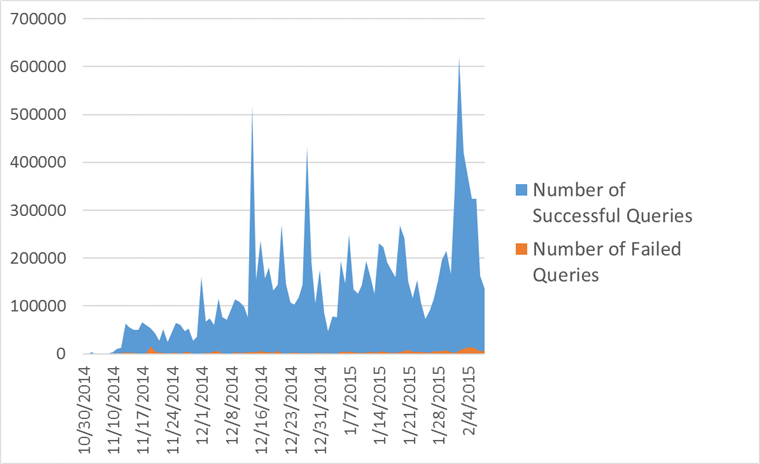
Результат прогона телеметрии по запросам XPath
Поддерживать подавляющее большинство запросов XPath простой конверсией в селекторы CSS — это отлично, но всё равно недостаточно, потому что реализовать оставшиеся похожим образом уже не получится. Грамматика XPath включает в себя такие продвинутые вещи, как функции, запросы к не-DOM элементам, узлам документа, и сложные предикаты. Некоторые авторитетные сайты (включая MDN) предлагают в таких случаях платформам, не имеющим адекватной нативной поддержки XPath, использовать библиотеки-полифиллы.
Например, wicked-good-xpath (WGX), который написан на чистом JS. Мы проверили его на нашем внутреннем наборе тестов для спецификации XPath, и в сравнении с нативными имплементациями он показал 91% совместимости, а также очень приличную производительность. Так что идея использовать WGX для оставшихся 3% сайтов показалась нам весьма привлекательной. Более того, это проект с исходниками, открытыми под лицензией MIT, что замечательно сочетается с нашим намерением делать всё больший вклад в дело открытого кода. Но мы, правда, ещё ни разу не использовали JavaScript-полифилл внутри IE для обеспечения поддержки какого-нибудь веб-стандарта.
Чтобы дать возможность WGX работать, и при этом не испортить контекст документа, мы запускаем его в отдельном, изолированном экземпляре движка JS, передавая ему на вход запрос и необходимые данные со страницы, а на выходе забираем готовый результат. Модифицировав код WGX для обеспечения работы в таком «оторванном» от документа режиме, мы сразу же улучшили отображение контента многих сайтов в нашем новом браузере.


Сайты до использования WGX

А это после. Обратите внимание на появившиеся цены и цифры выигрышных билетов
Однако, в WGX нашлись и баги, из-за которых он ведёт себя отлично и от спецификации W3C, и от других браузеров. Мы планируем сначала их все поправить, а потом поделиться патчами с сообществом.
Таким образом, в результате некоторого дата-майнинга по Сети, и с помощью библиотеки с открытым кодом, наш новый движок за короткое время обзавёлся производительной поддержкой XPath, а пользователи скоро получат лучшую поддержку веб-стандартов. Вы можете скачать очередной Windows 10 Technical Preview, и убедиться в этом сами. А ещё можете написать через UserVoice, насколько хорошо у нас это получилось, или твитнуть нам, или высказаться в комментариях к оригинальной статье.
PS от переводчика: тенденция превращения JavaScript в язык, на котором пишутся платформы, как говорится, налицо. Взять Firefox'овский Shumway, или PDF.js. Теперь вот и Microsoft свой браузер, по крайней мере частично, на JS переводит.
Обеспечивая совместимость с DOM L3 XPath
Поставив перед собой задачу обеспечить в Windows 10 по-настоящему совместимую и современную веб-платформу, мы постоянно работаем над улучшением поддержки стандартов, в частности, в отношении DOM L3 XPath. Сегодня нам хотелось бы рассказать, как мы этого добились в Project Spartan.
Немного истории
До того, как реализовать поддержку стандарта DOM L3 Core и нативных XML-документов в IE9, мы предоставляли веб-разработчикам библиотеку MSXML посредством механизма ActiveX. Кроме объекта XMLHttpRequest, MSXML обеспечивала и частичную поддержку языка запросов XPath через набор собственных API, selectSingleNode и selectNodes. С точки зрения приложений, использующих MSXML, этот способ просто работал. Однако, он совершенно не соответствовал стандартам W3C ни для взаимодействия с XML, ни для работы с XPath.
Авторам библиотек и разработчикам сайтов приходилось обёртывать вызовы XPath для переключения между имплементациями «на лету». Если вы поищете в сети учебники или примеры по XPath, вы сразу заметите обёртки для IE и MSXML, например,
// code for IE
if (window.ActiveXObject || xhttp.responseType == "msxml-document") {
xml.setProperty("SelectionLanguage", "XPath");
nodes = xml.selectNodes(path);
for (i = 0; i < nodes.length; i++) {
document.write(nodes[i].childNodes[0].nodeValue);
document.write("<br>");
}
}
// code for Chrome, Firefox, Opera, etc.
else if (document.implementation && document.implementation.createDocument) {
var nodes = xml.evaluate(path, xml, null, XPathResult.ANY_TYPE, null);
var result = nodes.iterateNext();
while (result) {
document.write(result.childNodes[0].nodeValue);
document.write("<br>");
result = nodes.iterateNext();
}
}Для нашего нового движка, ориентированного на веб без плагинов, нам потребовалось обеспечить нативную поддержку XPath.
Оценка возможных вариантов
Мы сразу же начали оценивать имеющиеся варианты воплощения такой поддержки. Можно было бы написать её с нуля, или полностью интегрировать в браузер MSXML, или портировать System.XML из .NET, но всё это потребовало бы слишком много времени. Поэтому мы решили для начала реализовать поддержку некоторого основного подмножества XPath, попутно думая над полной.
Чтобы определить, за какое начальное подмножество стандарта стоит взяться, мы использовали внутренний инструмент, собирающий статистику по запросам на сотнях тысяч самых популярных сайтов. Выяснилось, что наиболее часто встречаются запросы таких видов:
- //element1/element2/element3
- //element[@attribute=«value»]
- .//*[contains(concat(" ", @class, " "), " classname ")]
Каждый из них прекрасно соответствует некоему селектору CSS, который можно перенаправить к уже имеющейся у нас очень быстрой реализации API селекторов CSS. Сравните сами:
- element1 > element2 > element3
- element[attribute=«value»]
- *.classname
Таким образом, первый шаг в реализации поддержки XPath заключался в написании конвертера из запросов XPath в селекторы CSS, и перенаправлению вызова в правильное место. Сделав это, мы снова использовали нашу телеметрию, чтобы измерить процент успешных запросов, а также выяснить, какие именно из неуспешных встречаются чаще всего.
Оказалось, что такая реализация покрывает аж 94% запросов, и позволяет сразу же заработать множеству сайтов. Из безуспешных большинство оказалось видов
- //element[contains(@class, «className»)]
- //element[contains(concat(" ", normalize-space(@class), " "), " className ")]
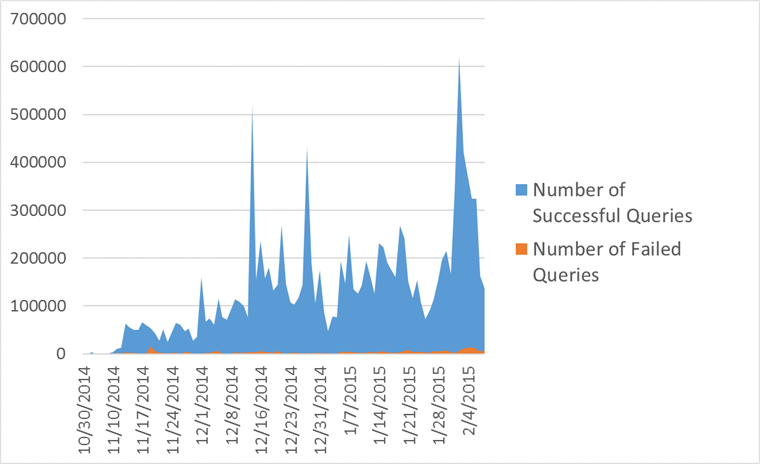
Результат прогона телеметрии по запросам XPath
Обеспечение поддержки оставшихся 3% сайтов
Поддерживать подавляющее большинство запросов XPath простой конверсией в селекторы CSS — это отлично, но всё равно недостаточно, потому что реализовать оставшиеся похожим образом уже не получится. Грамматика XPath включает в себя такие продвинутые вещи, как функции, запросы к не-DOM элементам, узлам документа, и сложные предикаты. Некоторые авторитетные сайты (включая MDN) предлагают в таких случаях платформам, не имеющим адекватной нативной поддержки XPath, использовать библиотеки-полифиллы.
Например, wicked-good-xpath (WGX), который написан на чистом JS. Мы проверили его на нашем внутреннем наборе тестов для спецификации XPath, и в сравнении с нативными имплементациями он показал 91% совместимости, а также очень приличную производительность. Так что идея использовать WGX для оставшихся 3% сайтов показалась нам весьма привлекательной. Более того, это проект с исходниками, открытыми под лицензией MIT, что замечательно сочетается с нашим намерением делать всё больший вклад в дело открытого кода. Но мы, правда, ещё ни разу не использовали JavaScript-полифилл внутри IE для обеспечения поддержки какого-нибудь веб-стандарта.
Чтобы дать возможность WGX работать, и при этом не испортить контекст документа, мы запускаем его в отдельном, изолированном экземпляре движка JS, передавая ему на вход запрос и необходимые данные со страницы, а на выходе забираем готовый результат. Модифицировав код WGX для обеспечения работы в таком «оторванном» от документа режиме, мы сразу же улучшили отображение контента многих сайтов в нашем новом браузере.
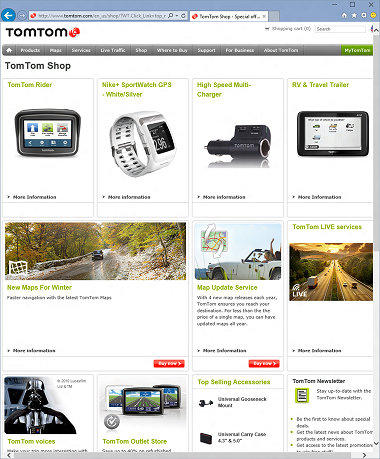

Сайты до использования WGX
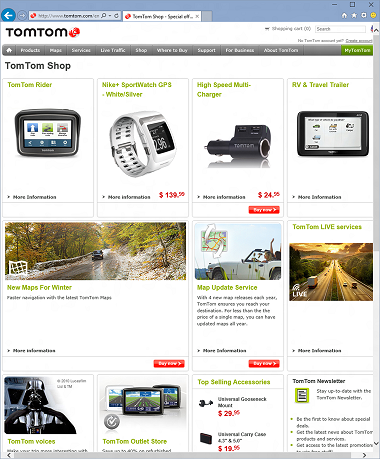

А это после. Обратите внимание на появившиеся цены и цифры выигрышных билетов
Однако, в WGX нашлись и баги, из-за которых он ведёт себя отлично и от спецификации W3C, и от других браузеров. Мы планируем сначала их все поправить, а потом поделиться патчами с сообществом.
Таким образом, в результате некоторого дата-майнинга по Сети, и с помощью библиотеки с открытым кодом, наш новый движок за короткое время обзавёлся производительной поддержкой XPath, а пользователи скоро получат лучшую поддержку веб-стандартов. Вы можете скачать очередной Windows 10 Technical Preview, и убедиться в этом сами. А ещё можете написать через UserVoice, насколько хорошо у нас это получилось, или твитнуть нам, или высказаться в комментариях к оригинальной статье.
PS от переводчика: тенденция превращения JavaScript в язык, на котором пишутся платформы, как говорится, налицо. Взять Firefox'овский Shumway, или PDF.js. Теперь вот и Microsoft свой браузер, по крайней мере частично, на JS переводит.
