
Мы в КРОК запустили собственную публичную облачную платформу в России одними из первых, еще в конце 2009 года. Нам нужен был рост в геометрической прогрессии из года в год. Чтобы обеспечить подобную динамику, архитектура облачной платформы должна была быть сверхгибкой и масштабируемой, а сама платформа — хорошо управляемой. В какой-то момент мы начали упираться в архитектурные ограничения, заложенные еще на заре развития облака, а именно в подсистему хранения данных.
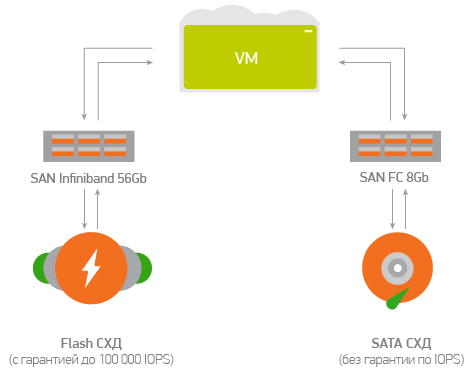
Одна из важнейших задач роста — обеспечение потребностей заказчиков не только в части объемов дисковой емкости, но и в части гарантированной производительности используемых дисков. Нужно было избежать взаимного влияния соседей по СХД, сделать ситуацию полностью управляемой, дать гарантии по производительности дисков в рамках SLA в пределах от 400 IOPS до 100 000 IOPS на диск.
Ко всему прочему тема с гарантированными дисками в облаке была подогрета и законом о персональных данных, вступающим в силу с 1 сентября 2015 года. Многие заказчики размещали и размещают свои ИТ-сервисы за границей, зачастую — на выделенном физическом высокопроизводительном оборудовании в ЦОДе провайдеров. Данные теперь нужно перенести на территорию России, но от высокой гарантированной производительности дисков отказываться совсем заказчикам не хочется или вовсе нельзя, а ждать поставки оборудования в РФ уже нет возможности. Облако в этом случае является, пожалуй, одним и, возможно, единственным способом успеть перенести данные в РФ и получить аналогичные технические параметры производительности, как на используемом ранее физическом оборудовании провайдера.
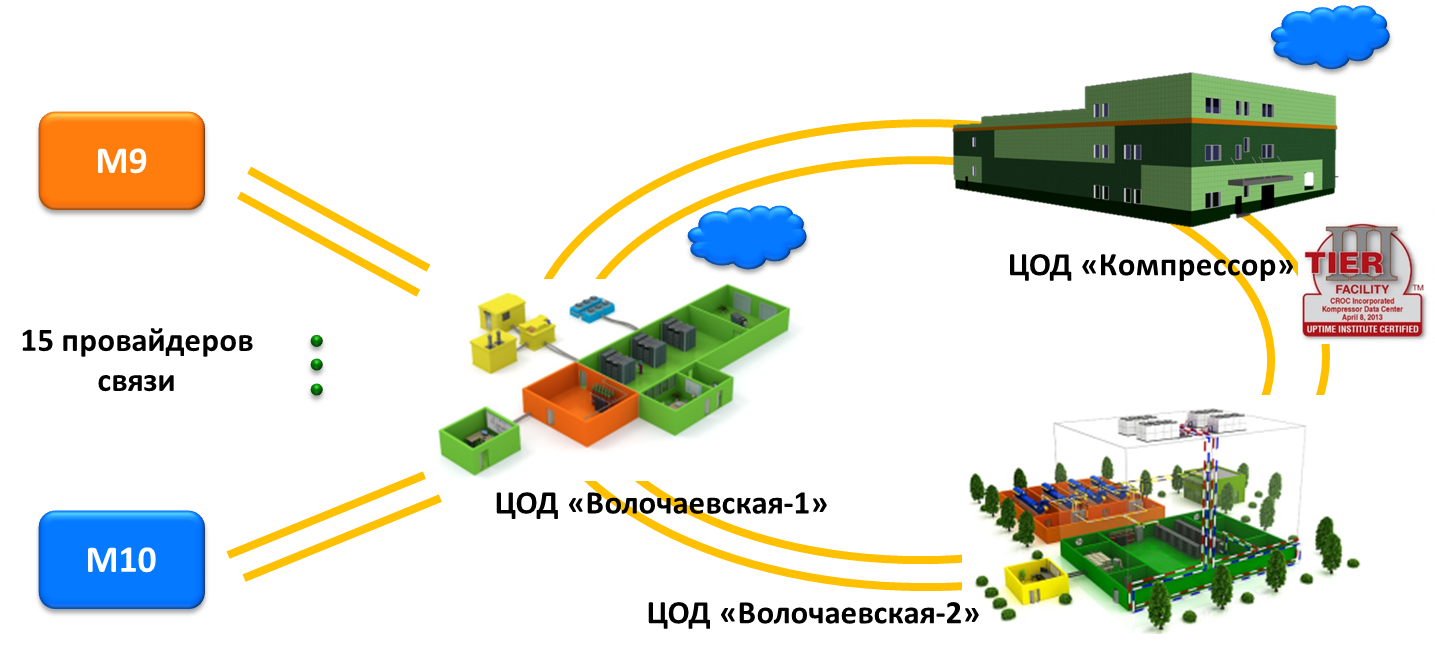
Облако КРОК сейчас — это более 500 физических серверов и 12 хранилищ данных, распределенных между двумя удаленными площадками. Порядка 70% размещенных в облаке виртуальных серверов — это продуктивные среды крупных корпоративных клиентов и компаний средней величины. Тестовых сред и сред разработки всего порядка 30%. У нас размещен ряд довольно тяжелых инсталляций Oracle, SAP и различных высоконагруженных OLAP-систем заказчиков.
Классические дисковые массивы имеют исторически сложившуюся архитектурную особенность, которая наиболее ярко проявилась с негативной стороны при использовании их в качестве централизованных хранилищ в составе публичной облачной платформы. На базе классических дисковых массивов с дисковыми полками и контроллерной парой мы запустились и жили до недавнего времени. На хранилищах данного типа практически отсутствовали внятные механизмы управления качеством предоставления услуг. Классические дисковые СХД, как правило, позволяют только создать приоритеты выдаваемой производительности на определенные виртуальные диски. Когда количество таких дисков на каждом из массивов доходит до сотен и тысяч, о задании каких-либо приоритетов можно забыть. Подобные механизмы управления производительностью на СХД не только не работали, а просто ухудшали и без того сложную ситуацию с недостатком производительности и управляемости.
Второй серьезной архитектурной проблемой стала жесткая привязка параметров емкости и производительности дисковых массивов. Проще говоря, есть 8 физических дисков по 150 ГБ со скоростью вращения 15k. Мы хотим собрать из них RAID10. Эффективная емкость логического диска получится на уровне 600 ГБ. Сам по себе каждый диск в отдельности выдает до 150 IOPS, а значит, логический диск выдаст порядка 1000 IOPS. В итоге получаем ситуацию: на каждый ТБ эффективной дисковой емкости приходится около1500 IOPS производительности.
Теперь посмотрим на наиболее распространенные задачи заказчиков: хотим базу на 2 ТБ разместить в облаке и получить производительность 10 000–50 000 IOPS. Выходит, чтобы получить такую производительность, нужно взять гораздо больше дисковой емкости, нежели на самом деле необходимо (10–50 ТБ). Вы можете возразить мне, что на массивах есть контроллерная пара с кэшом и что можно добавить полку с твердотельными дисками и т. д. Кэш контроллеров на случайном чтении/записи сильно ситуацию не улучшит. Твердотельные диски лишь отчасти спасают ситуацию с производительностью, а решение проблемы с управляемостью лишь отодвигают в будущее. К тому же, классический контроллер не может раскрыть всю производительность твердотельного диска.
Ситуация с производительностью дисков в облаке КРОК становилась критической, заказчики начинали жаловаться на непредсказуемые просадки по производительности дисковой подсистемы. Нужно было принимать решение о дальнейшем развитии облака. Рассматривали различные решения, в том числе и переход на High-End массивы. Но осознавали, что это не решение проблемы, а просто дорогой «костыль», который позволит прожить еще пару лет, пока мы не придем к аналогичной ситуации. Про «неуправляемость» подобных решений я уже писал выше. Также Hi-End массивы не предназначены для очень частого создания и удаления дисковых лунов — данные операции занимают много времени и превращаются в длинные очереди из запросов, что не подходит для работы в облаке. В общем, задача не бралась малой кровью, и мы были вынуждены начать все с чистого листа, провести локальную революцию в части хранения данных в облаке.
С чистого листа — так с чистого листа. Решили отталкиваться от потребностей заказчиков. Чего же хотят заказчики?
- Диски с гарантированной производительностью без возможности взаимного влияния соседей по массиву друг на друга. Гарантии должны быть зафиксированы в SLA или договоре.
- Прозрачного наращивания и уменьшения производительности дисковых ресурсов на лету с изменением тарифов за использование разных дисков.
- Возможность размещения высоконагруженных БД в облаке (20 000–100 000 IOPS на диск).
- Предоставление мощностей на территории РФ (задержки и политические факторы). Закон про перенос персональных данных в РФ до 1 сентября 2015 года только подстегивал.
- Высокую доступность хранения данных.
Мы давно смотрели в сторону использования All-Flash массивов. Так сложилось, что именно на базе данного класса решений наша облачная задача с хранением данных решалась наиболее красиво, а что самое интересное — финансово оправданно. Мы протестировали практически все доступные на рынке решения корпоративного уровня, а также поработали с наиболее заметными стартапами. При выборе решения основными критериями были:
- All-Flash — высокая производительность и отсутствие зависимости дисковой емкости от количества IOPS.
- IOPS’ов должно быть настолько много, чтобы, во-первых, всем хватило, а во-вторых, чтобы можно было гарантировать их выделение в любой момент времени.
- Массивы должны иметь Infiniband адаптеры для подключения к существующей SAN. Дело в том, что в качестве SAN сети и транспорта для виртуальных сетей заказчиков в облачной платформе мы используем 56GB Infiniband. Подключение массивов по той же технологии помогло бы сохранить однообразие SAN и упростило бы управление платформой в целом. Не нужно было бы строить сложные в настройке и эксплуатации фабрики, как в случае с FC SAN, так как при использовании Infiniband все эти вопросы уже автоматически закрыты.
- Документированные и понятные средства управления массивами посредством API. Это требование помогло бы подступиться к задаче управляемости.
Остановились в итоге на массивах Violin Memory 6264. Они полностью удовлетворяли нашим требованиям. В итоге суммарно на 8 приобретенных массивов получили 0.56 ПБ сырой / 0.32 ПБ полезной флеш-емкости с суммарной производительностью 8 000 000 IOPS.
Гарантии производительности осуществляются путем выставления ограничений на уровне гипервизора на каждый диск в отдельности. Программное обеспечение по управлению массивами в автоматическом режиме определяет текущую утилизацию каждого из них и выбирает наименее занятые массивы для размещения новых дисков. Массив совсем компактный. Подумать только: 1 000 000 IOPS всего в 3 юнитах!
Это был безопасный выбор, учитывая, что Violin Memory создала All-Flash рынок в 2007 году и дальше всех продвинулась в совершенствовании продукта. Компания разработала систему с нуля совместно с Toshiba — изобретателем NAND-Flash — и обладает ключевыми патентами на работу с флешом. В массиве нет никаких SAS-петель, батарей и прочих унаследованных от дисковых систем архаизмов, без компромиссов в виде SSD. Вместо этого — современная архитектура FFA на шине PCI, используются носители собственной разработки VIMM емкостью 1.1ТБ. На выходе — номинальное время отклика 250 мкс, 7-значные IOPS, десятки ТБ в 3 юнитах. По заявлениям производителя, догнать Violin Memory невозможно: нужна не переработка существующего продукта, а годы разработок с нуля и доступ к незадокументированным функциям NAND-Flash.
Признаемся честно: при миграции не все пошло гладко, и мы столкнулись с интеграционными проблемами нашего облака и массивов. Суть их заключалась в том, что мы могли реализовать потенциал массивов примерно на 10% от их возможностей, а именно уперлись в максимальное количество создаваемых дисков на один массив. В облаке КРОК мы используем Infiniband как для сети хранения данных, так и для связи между виртуальными машинами. В массивах Violin Memory используется протокол SRP (SCSI over RDMA) для подключения LUN’ов к серверам по Infiniband. Этот протокол обладает следующей особенностью: контрольные команды используют subnet manager сети Infiniband. В обычной ситуации, когда количество LUN’ов и серверов не очень большое, как и подключений между ними, это не является проблемой. Но не в случае облака. Из-за того, что подключений, то есть путей между серверами и LUN’ами, очень много, subnet manager’ы сети Inifiniband уходили в себя при перестроении топологии сети. Просто не хватало процессорной мощности. Большое количество путей также создавало сложности на контроллерах доступа СХД — они начинали работать очень медленно, вызывая ошибки в драйверах, которые считали, что путь отвалился.
Как мы решили проблему? Вместе с вендором провели большую работу по оптимизации количества путей: каждый отдельный LUN мы стали подключать, то есть экспортировать, к отдельному физическому серверу. Сложность заключалась в том, что это нужно было делать при помощи ReST API массива, что тоже проходило нелегко. Если LUN экспортирован на все хосты и на еще один конкретный хост, то он экспортируется и с этого конкретного LUN’а. Это требует выполнения живой миграции всех LUN’ов, чтобы в итоге избавиться от экспорта на все хосты. Так как при каждом включении/выключении сервера проходил новый запрос на API массива, у нас повысились требования к производительности этого API. Тут без вендора мы никак не могли обойтись. Потребовалось инициировать выпуск новых версий прошивок для оборудования.
С нашей стороны в решении этого вопроса на протяжении более полугода было занято три программиста и три DEVOPS’а. Мы написали огромное количество тестов (unit-test’ов) для нашего программного кода, оптимизировали систему автоматизированной сборки и тестирования. Этой задачей занималась остальная команда. В результате у нас добавились тысячи строк оттестированного программного кода. Может показаться, будто оптимизация количества путей — это простая задача, но на самом деле ничего простого в ней нет: на ее выполнение нам потребовались серьезные трудозатраты и больше десяти месяцев.

VIMM (Violin Intelligent Memory Module) — флеш-носитель, основной компонент All Flash системы
Итак, диапазон доступной производительности дисков, которые можно создать на массивах, — до 100 000 IOPS на диск. Причем производительность эта гарантированная, а не плавающая, как обычно принято на рынке публичных облачных платформ.
Мы предоставляем заказчикам по умолчанию диски со следующей производительностью: 400, 1000, 3000, 5000, 10000 IOPS соответственно. Заказчики через портал самообслуживания имеют возможность запуска дисков разной производительности, а также смены параметров их количества IOPS на лету. А диски производительностью от 10 000 IOPS до 100 000 IOPS добавляются на портал самообслуживания по запросу в службу технической поддержки. Как правило, это индивидуальные уровни хранения, параметры которых определяются для каждого заказчика в отдельности по итогам нагрузочного тестирования. Мы их не прячем, просто действительно далеко не всем нужны такие высокопроизводительные уровни хранения. Нам не жалко, ведь среднее количество IOPS на 1ТБ емкости в нашем облаке — 25 000. Это действительно фантастический показатель.
Массивы распределены между двумя облачными платформами КРОК в распределенных дата-центрах на территории Москвы: в одном 5 хранилищ, в другом — 3. Это позволяет заказчикам строить Disaster recovery решения с использованием высоконагруженных систем как на одной площадке, так и на другой. Причем управление массивами на обеих площадках выполняется посредством единого портала самообслуживания.
Многие могут заметить: «А вот другие провайдеры связи говорят, что у них тоже каналы гарантированные, а как дело доходит до SLA, опускают глаза». Так вот у КРОК есть совершенно отдельный SLA на производительность дисков, помимо стандартного SLA на доступность виртуальных серверов. Приведу ниже небольшую выдержку из него, а именно определение недоступности производительности гарантированных дисков. «Недоступность производительности флеш-диска — состояние флеш-диска, когда в течение пяти минут процессор виртуальной машины, к которой он подключен, ожидает данные от дисковой подсистемы более 10% времени, или задержка получения данных от дисковой подсистемы более 5мс и при этом количество запросов ввода-вывода (IOPS) на флеш-диск меньше, чем заявленная производительность флеш-диска на 3%».
Под заявленной производительностью флеш-диска здесь подразумеваются как раз стандартные уровни хранения 400, 1000, 3000, 5000, 10000 IOPS соответственно или индивидуальные уровни хранения от 10 000 IOPS до 100 000 IOPS. Как только мы вылетаем за заявленные параметры производительности, начинают капать минуты недоступности. Как только мы вылетаем за SLA 99,9, то сразу же попадаем на штрафы. Так что мы сами себя загоняем в ситуацию, когда плохо работать совсем не в наших интересах.
Что же делать, если гарантированная производительность дисков не нужна, а нужно просто хранить большой объем данных по умеренным ценам? В облаке также есть и SATA-хранилище данных, на котором можно разместить наименее горячие данные по оптимизированным тарифам. А миграция между разными типами хранилищ производится на лету.
Кстати, могу добавить от себя, что услуга оказалась настолько востребованной и своевременной, что мы распродали наши восемь флешовых массивов на 60% за 4 месяца и только что заказали еще восемь таких же. Это будет первое облако в России с > 1 ПБ правильного флеша. Так что будем готовы принять и новый поток заказчиков, который хлынет ближе к середине и концу лета в преддверии Дня знаний о персональных данных. Многие заказчики, кстати, уже своевременно без особых сложностей переехали к нам. Особенно удобно тем, кто раньше использовал мощности Amazon — у нас похожая архитектура, совместимый API и близкий подход к построению публичного облака.
Если у вас есть вопросы по организации дисковых ресурсов для нагруженных ИТ-систем в РФ, я готов ответить в комментариях или же детально с просчетом вашей задачи по почте: MBerezin@croc.ru
Ссылки:
- Рефакторинг серверной страховой компании — когда физического места меньше, чем данных
- Обзор Violin — флеш-СХД, работающей со скоростью, близкой к DRAM
