
После длительной подготовки, подборки материала и предварительных апробаций курса 19 октября мы запустились. Корпоративный интенсивный практический курс анализа данных от экспертов этого дела. В настоящий момент у нас прошло 6 занятий, половина нашего курса, и это краткий обзор того, что мы на них делаем.
Прежде всего, нашей задачей было создать курс, на котором мы дадим максимум практики, которую слушатели сразу смогут применять в ежедневной работе.
Мы часто видели, как люди, приходящие к нам на собеседования, несмотря на неплохое знание теории, из-за недостатка опыта не могли воспроизвести все этапы решения типичной задачи машинного обучения – подготовка данных, отбор/конструирование признаков, выбор моделей, их правильная композиция, достижение высокого качества и правильная трактовка полученных результатов.
Поэтому у нас главное – это практика. Открываем тетрадки IPython и сразу с ними работаем.
На первом занятии мы обсудили деревья и леса решений и разобрали технику извлечения признаков на примере набора данных соревнования Kaggle «Titanic: Machine Learning from Disaster».
Мы считаем, что участие в соревнованиях по машинному обучению обязательно для поддержания необходимого уровня и постоянного повышения экспертизы аналитика. Поэтому, начиная с первого занятия мы запустили собственное соревнование по предсказанию выплат в автостраховании (сейчас очень популярная в бизнесе тема) с помощью Kaggle Inclass. Соревнование продлится до окончания курса.
На втором занятии мы занимались анализом данных Titanic, используя Pandas и средства визуализации. Также попробовали простые методы классификации на задаче по предсказанию выплат в автостраховании.
На третьем занятии рассмотрели задачу Kaggle «Greek Media Monitoring Multilabel Classification (WISE 2014)» и применение смешивания алгоритмов как основной методики для большинства соревнований Kaggle.
На третьем занятии мы также рассмотрели возможности библиотеки машинного обучения Scikit-Learn, а потом детальнее — линейные методы классификации: логистическую регрессию и линейный SVM, обсудили, когда лучше применять линейные модели, а когда — сложные. Поговорили о важности признаков в задаче обучения и о метриках качества классификации.
Главной темой четвертого занятия стал алгоритм мета-обучения стекинг и его применение в победном решении задачи Kaggle компании Otto “Classify products into correct category”.
На четвертом занятии мы подобрались к главной проблеме машинного обучения – борьбе с переобучением, посмотрели, как для этого использовать кривые обучения и валидации, как правильно проводить кросс-валидацию, какие показатели можно оптимизировать в этом процессе для достижения лучшей обобщающей способности. Также изучили методы построения ансамблей классификаторов и регрессоров – бэггинг, метод случайных подпространств, бустинг, стекинг и др.
И так далее – каждое занятие новая практическая задача.
Так как нашим основным языком на курсе является Python, то мы, конечно, знакомим с основными библиотеками анализа данных на языке Python- NumPy, SciPy, Matplotlib, Seaborn, Pandas и Scikit-learn. Мы уделяем этому достаточно много времени, поскольку работа исследователя данных во многом состоит из вызова различных методов перечисленных модулей.
Понимание теории, на которой основаны методы также важно. Поэтому мы рассмотрели основные математические методы, реализованные в SciPy — нахождение собственных чисел, сингулярное разложение матрицы, метод максимального правдоподобия, методы оптимизации и др. Эти методы были рассмотрены не просто теоретически, а в связке с алгоритмами машинного обучения, их использующими – методом опорных векторов, логистической регрессией, спектральной кластеризацией, методом главных компонент и др. Такой подход – сначала практика, потом теория, наконец, практика на новом уровне, с теоретическим пониманием – реализован многими школами машинного обучения за рубежом.
Рассмотрим чуть детальней один из популярных методов, часто применяемый участниками соревнований Kaggle – стекинг, который мы изучали на четвертом занятии.
В самой простой форме идея стекинга заключается в том, чтобы взять M базовых алгоритмов (например, 10), разбить обучающую выборку на две части — скажем, А и В. Сначала обучить на части A все M базовых алгоритмов и сделать предсказания для части B. Потом наоборот, обучить все модели на части B и сделать прогнозы для объектов из части A. Так можно получить матрицу предсказаний, размеры которой n x M, где n — число объектов в исходной обучающей выборке, M — число базовых алгоритмов. Эта матрица подается на вход еще одной модели — модели второго уровня, которая, фактически, обучается на результатах обучения.
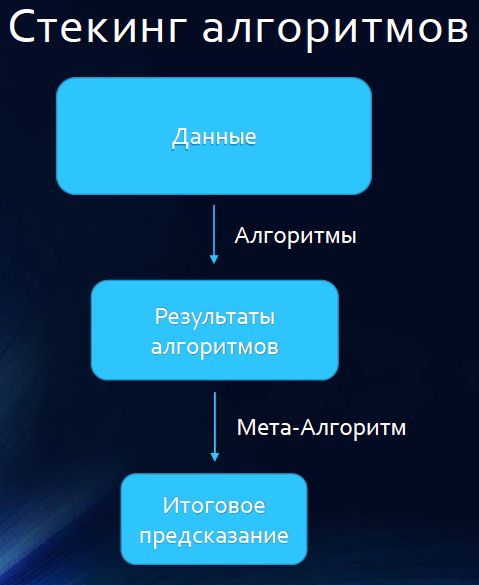
Чаще схему делают чуть сложнее. Чтобы обучать модели на большем количестве данных, чем половине обучающей выборки, выборку K раз разбивают на K частей. Модели обучают на K-1 частях обучающей выборки, предсказания делают на одной части и вносят результаты в матрицу предсказаний. Это K-кратный стекинг.
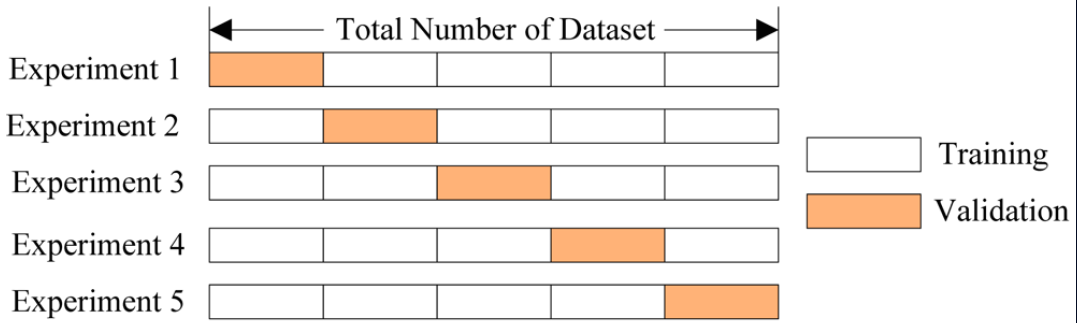
Рассмотрим вкратце схему победителей соревнования Kaggle «Otto Group Product Classification Challenge». www.kaggle.com/c/otto-group-product-classification-challenge
Задача заключалась в правильном отнесении товаров к одной из 9 категорий на основе 93 признаков, суть которых компания Otto не раскрывает. Предсказания оценивались на основе средней F1-меры. Соревнование стало самым популярным за всю историю Kaggle, возможно, потому что порог входа был низким, данные хорошо подготовлены, можно было быстро взять и попробовать одну из моделей.
В решении победителей соревнования использовался по сути тот же K-кратный стекинг, только на втором уровне обучались три модели, а не одна, и затем предсказания этих трех моделей смешивались.
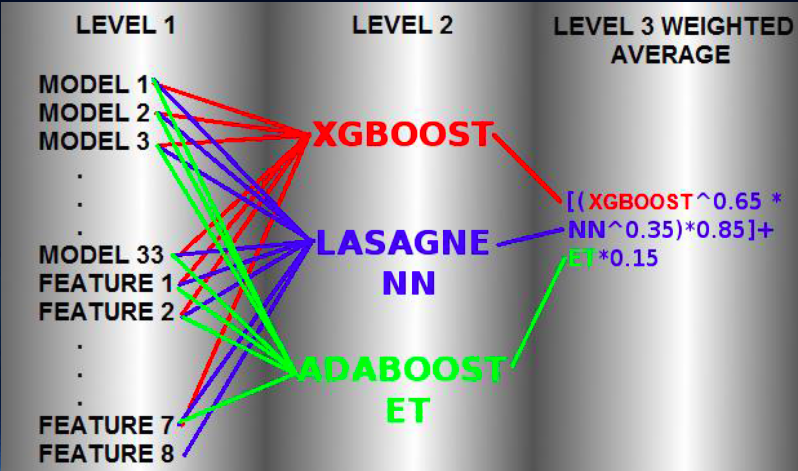
На первом уровне обучались 33 модели — различные реализации многих алгоритмов машинного обучения с разными наборами признаков, в том числе созданными.
Эти 33 модели 5 раз обучались на 80% обучающей выборки и делали предсказания для оставшихся 20% данных. Полученные предсказания собирались в матрицу. То есть 5-кратный стекинг. Но отличие от классической модели стекинга еще в том, что к предсказаниям 33 моделей добавились 8 созданных признаков — в основном полученные кластеризацией исходных данных (и сам признак — метки полученных кластеров) либо учитывающие расстояния до ближайших представителей каждого класса.
На результатах обучения 33 моделей первого уровня и 8 созданных признаках обучались 3 модели второго уровня — XGboost, нейронная сеть Lasagne NN и AdaBoost с деревьями ExtraTrees. Параметры каждого алгоритма подбирались в процессе кросс-валидации. Финальная формула для усреднения предсказаний моделей второго уровня подбиралась также в процессе кросс-валидации.
На пятом занятии мы продолжили изучать алгоритмы классификации, а именно, нейронные сети. Также затронули тему обучения без учителя – кластеризацию, снижение размерности и поиск выбросов.
На шестом занятии мы погрузились в Data Mining и анализ потребительской корзины. Распространено мнение что машинное обучение и майнинг данных — это одно и то же или что последнее — часть первого. Мы объясняем, что это не так и указываем на различия.
Изначально машинное обучение было более нацелено на предсказание типа новых объектов на основе анализа обучающей выборки, и именно о задаче классификации чаще всего вспоминают, когда говорят про машинное обучение.
Майнинг данных же был ориентирован на поиск «интересных» закономерностей (паттернов) в данных, например, часто покупаемых вместе товаров. Конечно, сейчас эта грань стирается, и те методы машинного обучения, которые работают не как черный ящик, а выдают и интерпретируемые правила, могут быть использованы и для поиска закономерностей.
Так, дерево решений позволяет понять не только то, что данное поведение пользователя похоже на фрод, но и почему. Такие правила напоминают ассоциативные правила, однако в майнинге данных они появились для анализа продаж, ведь полезно знать, что, казалось бы, не связанные между собой товары покупаются вместе. Купив A покупают и B.
Мы не только обо всем этом рассказываем, но и даем возможность самим проанализировать реальные данные о таких покупках. Так данные о продажах контекстной рекламы помогут понять какие рекомендации о покупке поисковых словосочетаний давать тем, кто хочет продвигать свой онлайн магазин в сети.
Другой важный в майнинге данных метод — это поиск частых последовательностей. Если последовательность <ламинат, холодильник> довольно частая, то скорее всего в вашем магазине закупаются новоселы. А еще такие последовательности полезны для предсказания следующих покупок.
Отдельное занятие посвящено рекомендательным системам. Мы не только учим классическим алгоритмам коллаборативной фильтрации, но и развеиваем заблуждения о том, что SVD, стандарт де факто в этой области, — панацея для всех рекомендательных задач. Так, в задаче рекомендации радиостанций, SVD заметно переобучается, а довольно естественный гибридный подход коллаборативной фильтрациии по сходству пользователей и динамических профилей пользователей и радиостанций на основе тегов прекрасно работает.
Итак, прошло шесть занятий, что дальше? Дальше – больше. У нас будет анализ социальных сетей, мы будем с нуля строить рекомендательную систему, учить обработке и сравнению текстов. Также, конечно, у нас будет анализ Больших данных с помощью Apache Spark.
Еще мы уделим отдельное занятие хитростям и трюкам на Kaggle, про которые расскажет человек, занимающий сейчас 4 место в мировом рейтинге Kaggle.
С 16 ноября мы запускаем второй курс для тех, кто не смог попасть на первый. Подробности, как обычно, на bigdata.beeline.digital.
За хроникой занятий текущего курса можно следить на нашей странице в Facebook.
