
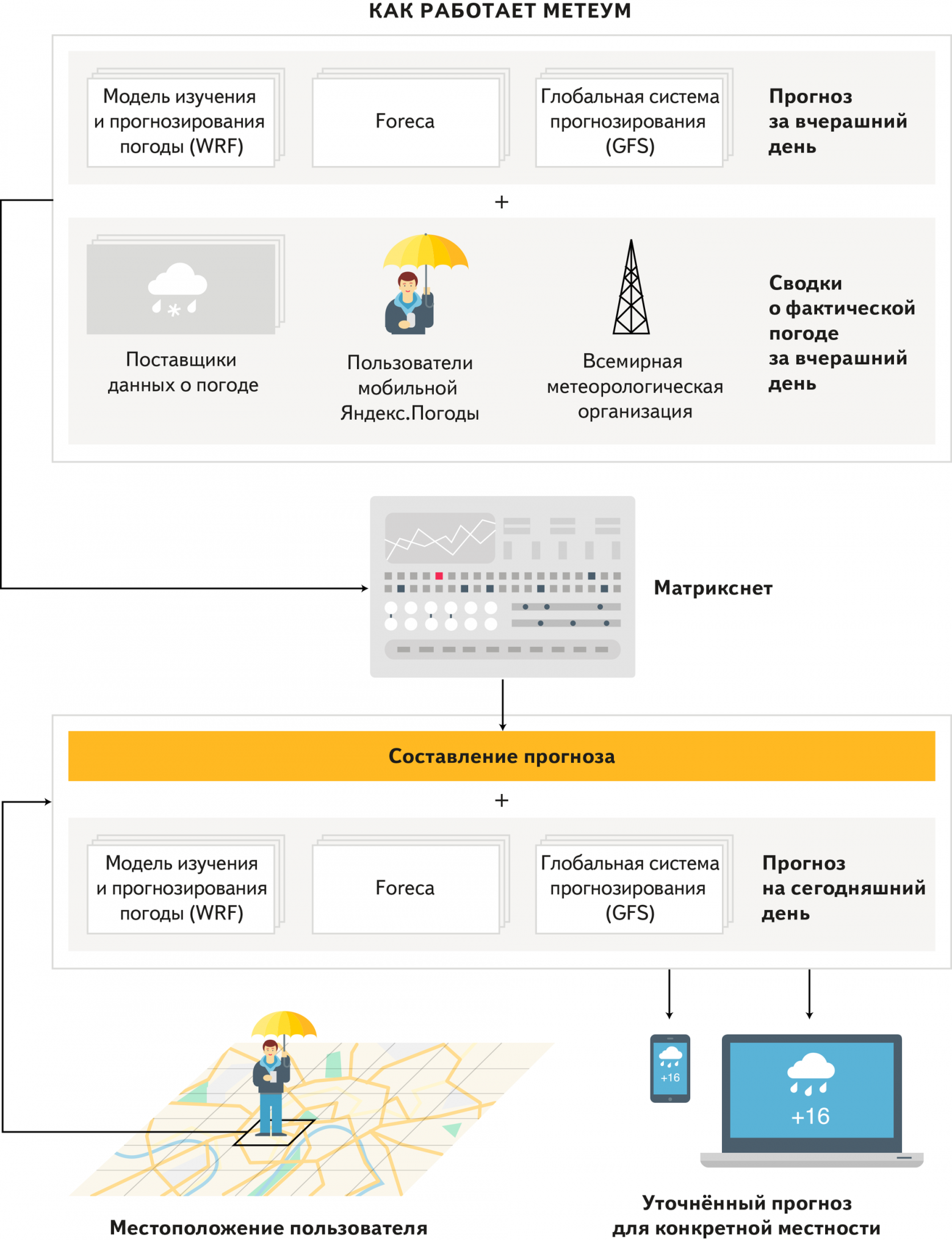
Сегодня мы анонсируем новую технологию Метеум — теперь с её помощью Яндекс.Погода будет строить собственный прогноз погоды, а не полагаться только на данные партнёров, как это было раньше.
Причём прогноз будет рассчитываться отдельно для каждой точки, из которой вы его запрашиваете, и пересчитываться каждый раз, когда вы на него смотрите, чтобы быть максимально актуальным.

В этом посте я хочу рассказать немного о том, как в наше время устроен мир погодных моделей, чем наш подход отличается от обычных, почему мы решились строить собственный прогноз и почему верим, что у нас получится лучше, чем у всех остальных.
Мы построили собственный прогноз с использованием традиционной модели атмосферы и максимально подробной сеткой, но и постарались собрать все возможные источники данных об атмосферных условиях, статистику о том, как ведёт себя погода на деле, и применили к этим данным машинное обучение, чтобы уменьшить вероятность ошибок.
Сейчас в мире есть несколько основных моделей, по которым предсказывают погоду. Например, модель с открытым исходным кодом WRF, модель GFS, которые изначально являлись американской разработкой. Сейчас ее развитием занимается агентство NOAA.
Модель WRF поддерживается и развивается учеными по всему миру, однако и у нее есть официальная версия — её развитием и поддержкой занимается американский научный институт NCAR, находящийся в Болдере, Колорадо. Изначально WRF развивалась как две параллельные ветки — ARW и NMM, ныне упраздненная. Модели GFS и WRF имеют несколько разный вектор развития (GFS распространяет глобальные и ориентированные на США продукты). WRF в первую очередь локальная модель, которую можно настроить под определенную местность.
По своей сути WRF – это open source программа, написанная на Фортране (см. врезку) и отражающая текущее понимание учеными законов физики и динамики атмосферы и, соответственно, погоды. Как всякий уважающий себя представитель open source software, WRF не работает «из коробки». То есть, вероятно, большинству линуксоидов удастся ее запустить, но только после изрядного количества времени, потраченного на чтение мануалов и компиляцию. При этом качество предсказаний погоды с помощью сырой версии может неприятно удивить. WRF создана, чтобы описывать сложную динамическую систему – атмосферу Земли, и потому нуждается в аккуратной настройке.
Весь процесс работы модели можно разделить на две условные части: предсказание физики и предсказание динамики. Физические модули WRF отслеживают количество тепла, которое выделяется и поглощается в атмосфере, а также образование осадков в нужное время и в нужном месте. Динамика – это движение воздушных масс, роза ветров, формирование циклонов и прочее. За физику отвечает набор полуэмпирических моделей, по одной на тот или иной процесс, за динамику – параметризованная версия уравнения Эйлера.
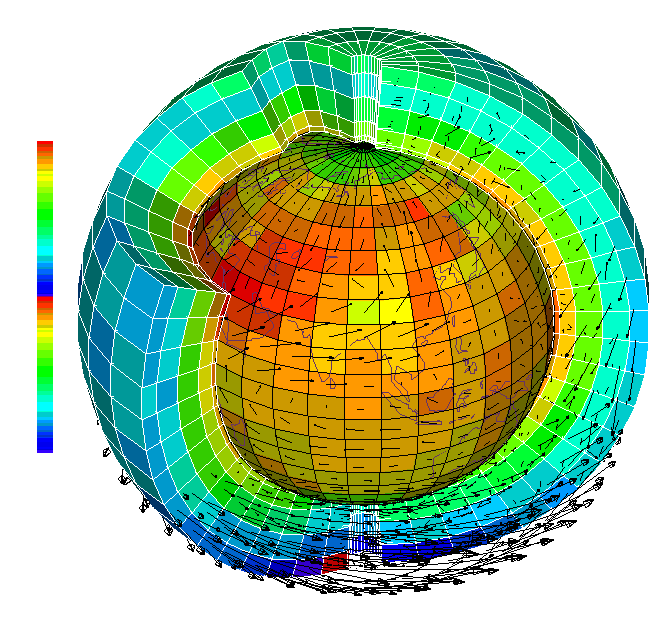
На картинке показан срез расчетной сетки модели. Результаты расчетов температуры отображены цветом ячеек и являются в основном следствием физических процессов – нагрева и охлаждения. Стрелочки показывают перенос воздушных масс, то есть результат расчета динамики.
Уравнение Эйлера – это дифференциальное уравнение в частных производных. Понятно, что компьютер не может решать дифференциальные уравнения в частных производных без посторонней помощи. Помощь в данном случае состоит в разложении уравнений математической модели на конечно-разностные схемы. То есть, представляя производные в виде разностей, можно получить максимально правильное решение уравнения.
Сложность, однако, не только в том, чтобы как можно точнее приблизить численное решение к пока что не найденному аналитическому. Она еще и в том, чтобы адекватно параметризовать процессы, управляющие атмосферой извне. Солнечная радиация, тепловое излучение почвы, влияние парниковых газов, фазовые переходы водяного пара – вот неполный список всего того, что нужно учесть при попытках прогнозировать погоду.
Вероятно, эта задача была бы совсем уж неподъемной, если бы не наблюдения. За те годы, в течение которых человечество интересовалось будущими метеоусловиями (а это большой срок), накопился некоторый опыт проведения атмосферных измерений. Были придуманы такие вещи, как метеостанции, спутниковые спектрометры, самолетные приборы, радары, лидары — да мало ли чего еще. Тот объем данных, который является минимально необходимым для составления прогноза на уровне точности, соответствующем современным стандартам, необходимо использовать все доступные источники информации: более 10000 метеостанций по всему миру, более 80 спутников на околоземной орбите, около 1500 станций радиологического зондирования.
Сейчас данные о наблюдениях за атмосферой по всему земному шару, полученные в один фиксированный момент времени, представляют собой терабайты станционных наблюдений, радарных сканирований и спутниковых снимков. Их мало для того, чтобы полностью описать текущее состояние атмосферы, но они могут быть использованы для уточнения начальных условий модели.

Некоторые из доступных человечеству способов наблюдения за атмосферой
Поскольку точность решения дифференциальных уравнений во многом зависит от точности задания начальных условий, все данные наблюдений используются для составления максимально точного поля атмосферных параметров. Для совмещения расчетов модели и разрозненных экспериментальных данных существует технология ассимиляции данных, унаследовавшая проработанный математический аппарат из теории управления и вариационного исчисления. Таким образом, помимо численных моделей, в прогнозе погоды нам помогают данные синхронных наблюдений с орбиты и наземных станций.
Сейчас наша система расчетных областей численной модели спроектирована таким образом, чтобы покрывать территорию нашей необъятной родины прогнозами двух типов – на сетке с грубым разрешением (6 на 6 км) и на сетке с мелким разрешением (2 на 2 км). Эти сетки вложены друг в друга и взаимодействуют, передавая между собой данные о граничных и начальных условиях.
Чтобы рассчитывать, обрабатывать и хранить параметры атмосферы на таких масштабах, необходимы огромные вычислительные мощности. Дневной объем поступающих в хранилище прогнозов составляет более 10Тб. Прогноз погоды на 48 часов с заданным уровнем детализации для Московской области даже на кластерах Яндекса занимает около 6 часов.
Прогноз погоды рассчитывается каждый раз, когда пользователь обращается к сервису. Это продиктовано не только желанием отдавать самый точный актуальный прогноз погоды специально для координат пользователя, но еще и суровой необходимостью. Дело в том, что объем данных о погоде с высоким разрешением настолько велик, что предрасчет такого прогноза над территорией всей нашей родины займет несколько часов, и ни одна рантаймовая база не сможет отвечать на запросы за приемлемое время. Это также верно не только для результатов Метеума, но и для некоторых моделей, которые входят в его состав. Например, модели GFS и WRF передают такое количество информации, что для их передачи в API был организован микросервис, который, в отличие от многих баз данных хранить, обновлять и отдавать данные непосредственно из памяти входящих в микросервис машин.
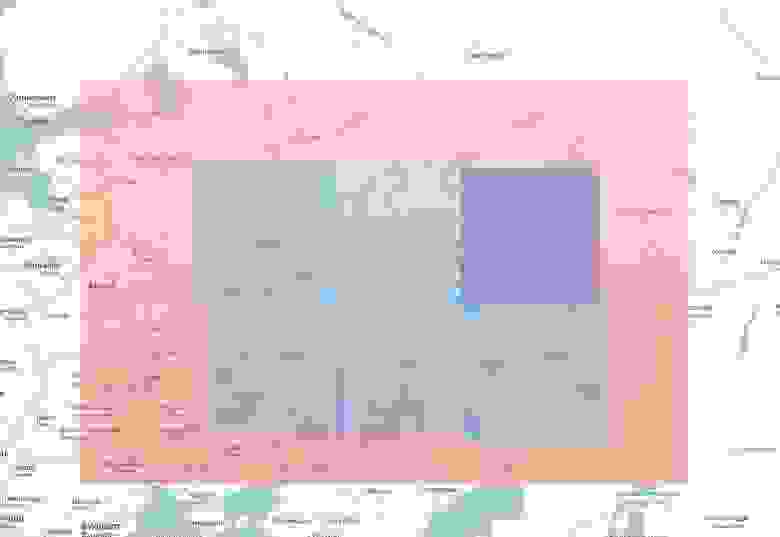
Так на одном из ранних этапов работы выглядело расположение расчетных областей в центральном регионе РФ. Красный – внешний домен с сеткой 6 на 6 км, синие – вложенные области с более высоким разрешением (2 на 2 км)
Система получения, обработки и анализа данных, расчетов модели и их совмещения в алгоритме ассимиляции данных – это цепочка из многих звеньев. Помимо правильной обработки поступающих данных, необходимо корректно настроить их усвоение в начальных условиях для дифференциальных уравнений. За разработку и физическое обоснование этих алгоритмов отвечает теория ассимиляции данных — наука о корректном сочетании наблюдений с прогнозами математических моделей. Однако наблюдения за состоянием атмосферы, которые мы получаем из различных источников, могут пригодиться и для других целей.
WRF является стандартом индустрии метеопрогнозирования, однако есть и другие модели: прогнозы, сделанные с помощью них мы получаем от наших партнеров. Несмотря на все знания человечества об атмосферных процессах, спутники и суперкомпьютеры, все эти модели, как вы знаете, ошибаются. Интересным является то, что в их прогнозах есть систематически воспроизводимые закономерности.
Помимо собственно модели WRF, которая рассчитывается на кластерах Яндекса, мы получаем прогнозы для 12000 городов по всему миру, сделанные одним из наших партнеров — компанией Foreca. Более детальная информация о глобальном состоянии атмосферы к нам приходит из американской модели Global Forecast System, которая считается одной из самых точных глобальных моделей в мире и имеет разрешение в 0.25 градуса.
Поведение этих моделей в разных метеорологических ситуациях позволяет Метеуму более точно оценивать корректировки, которые необходимо сделать к прогнозу и оптимально подобрать комбинацию исходных данных.
Некоторые из моделей прогноза погоды завышают количество выпавших на землю осадков, другие — занижают ночную температуру в черте города. Имея в распоряжении архив прогнозов моделей, можно выделить очень много таких закономерностей, в том числе и гораздо менее очевидных, чем те, о которых я говорил выше. Человеку это сделать достаточно сложно из-за огромных объемов данных, а вот алгоритмы машинного обучения с этим прекрасно справляются. Для выявления закономерностей и взаимосвязей между прогнозами моделей и реальной метеорологической обстановкой, мы используем известный вам алгоритм машинного обучения Матрикснет.
Матрикснет принимает на вход специальным образом переработанные архивы прогнозов погоды и сопоставляет их с данными о реальной метеорологической обстановке. В качестве данных о реальной погоде используются наблюдения, полученные на тысячах профессиональных метеостанций по всему миру.
В результате таких сопоставлений получается формула корректировки прогноза, которая, в зависимости от метеорологической ситуации, составляет оптимальную комбинацию прогнозов из данных моделей, предоставленных нашими поставщиками.
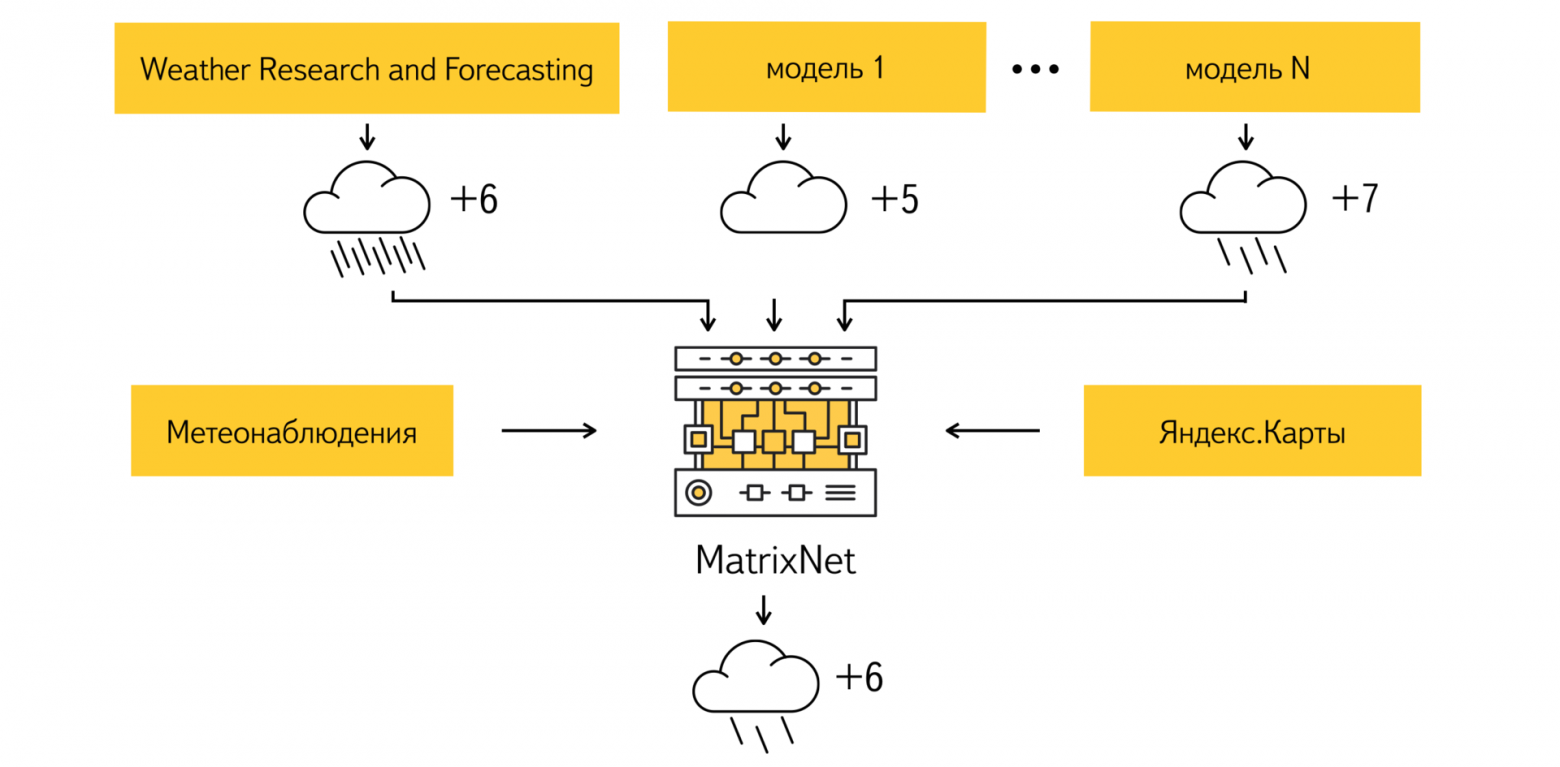
Метеум использует огромное количество данных, и это только начало. Например, в ряде регионов России точные метеоизмерения достаточно редки.
Их не достаточно для построения гиперлокального прогноза. Поэтому Метеум способен использовать большое количество данных, косвенно указывающих на метеообстановку. Мы уже используем данные Яндекс.Карт, которые помогают нам учитывать ландшафт местности. Я приведу еще один пример. Во многих моделях телефонов встроены барометры. Они не такие точные, как в метеостанциях, зато их миллионы. И распределены они там, где живут люди. В следующем году мы начнем использовать их данные для уточнения фактического состояния атмосферы.
Кроме того, уже сейчас в приложениях Яндекс.Погоды есть возможность рассказать о том, какая погода сейчас там, где вы находитесь. Мы изначально создавали Метеум расширяемым под различные классы данных, которые косвенно свидетельствуют о погоде, поэтому сможем учитывать и ваши наблюдения.
Читатели Хабра, наверное, особенно отчетливо представляют себе что за процессами, описанными выше, должна стоять соответствующим образом спроектированная инфраструктура.
В режиме реального времени прогнозы моделей, необходимые для работы Метеума, собираются из нескольких разных источников. Находящиеся в микросервисе прогнозы WRF и GFS весят более 60 Гб и обновляются каждую минуту. Причем они делают это атомарно, большими кусками. Такие требования сделали невозможным использование традиционных рантайм-баз. Прогнозы компании Foreca хранятся в PostgreSQL, так как их объемы и частота обновления значительно ниже. После обработки и показа пользователю, результаты формулы вместе с составными частями (прогнозы поставщиков и другие факторы, передаваемые в Матрикснет), отправляются в кластер MapReduce. Эти данные впоследствии используются для верификации и дополнительной настройки работы Метеума.
Все те процессы, которые мы описали выше, происходят каждый раз, когда пользователь заходит в Яндекс.Погоду. Делая запрос, вы посылаете в Метеум свои географические координаты. Он собирает все необходимые для прогноза данные, анализирует метеорологическую обстановку, тип подстилающей поверхности и составляет на основе этих данных свой собственный прогноз специально для вашего положения.
По нашим собственных оценкам (увы, независимых измерителей в этой области пока нет), на сегодня наш прогноз погоды точнее всех известных нам конкурентов. Например, температурный прогноз на 24 часа у нас ошибается на 35% меньше ближайшего конкурента.
Но мы понимаем, что до идеала ещё далеко, и надеемся, что через некоторое время нам удастся ещё больше увеличить точность, благодаря данным от пользователей приложения, а также дополнительным источникам сведений об атмосфере.
Причём прогноз будет рассчитываться отдельно для каждой точки, из которой вы его запрашиваете, и пересчитываться каждый раз, когда вы на него смотрите, чтобы быть максимально актуальным.

В этом посте я хочу рассказать немного о том, как в наше время устроен мир погодных моделей, чем наш подход отличается от обычных, почему мы решились строить собственный прогноз и почему верим, что у нас получится лучше, чем у всех остальных.
Мы построили собственный прогноз с использованием традиционной модели атмосферы и максимально подробной сеткой, но и постарались собрать все возможные источники данных об атмосферных условиях, статистику о том, как ведёт себя погода на деле, и применили к этим данным машинное обучение, чтобы уменьшить вероятность ошибок.
Сейчас в мире есть несколько основных моделей, по которым предсказывают погоду. Например, модель с открытым исходным кодом WRF, модель GFS, которые изначально являлись американской разработкой. Сейчас ее развитием занимается агентство NOAA.
Модель WRF поддерживается и развивается учеными по всему миру, однако и у нее есть официальная версия — её развитием и поддержкой занимается американский научный институт NCAR, находящийся в Болдере, Колорадо. Изначально WRF развивалась как две параллельные ветки — ARW и NMM, ныне упраздненная. Модели GFS и WRF имеют несколько разный вектор развития (GFS распространяет глобальные и ориентированные на США продукты). WRF в первую очередь локальная модель, которую можно настроить под определенную местность.
Часть 1. Про классическую метеорологию
По своей сути WRF – это open source программа, написанная на Фортране (см. врезку) и отражающая текущее понимание учеными законов физики и динамики атмосферы и, соответственно, погоды. Как всякий уважающий себя представитель open source software, WRF не работает «из коробки». То есть, вероятно, большинству линуксоидов удастся ее запустить, но только после изрядного количества времени, потраченного на чтение мануалов и компиляцию. При этом качество предсказаний погоды с помощью сырой версии может неприятно удивить. WRF создана, чтобы описывать сложную динамическую систему – атмосферу Земли, и потому нуждается в аккуратной настройке.
Лирическое отступление про Фортран
Понятно, что Фортран, наверное, не самый лучший выбор для создания больших систем с открытым исходным кодом. Но существуют две серьезные причины не переписывать WRF на другие языки. Первая – код, что называется, проверен временем: не одно поколение ученых внесло свой вклад в формирование физической модели. Кроме того, данный код широко поддерживается научными группами по всему миру. Вторая причина заключается в том, что для описания такой сложной системы, как окружающая нас среда, требуются изрядные вычислительные ресурсы. Современные же компиляторы, типа Intel Fortran, позволяют собрать исполняемые файлы таким образом, чтобы те выполнялись с максимальной производительностью.
Весь процесс работы модели можно разделить на две условные части: предсказание физики и предсказание динамики. Физические модули WRF отслеживают количество тепла, которое выделяется и поглощается в атмосфере, а также образование осадков в нужное время и в нужном месте. Динамика – это движение воздушных масс, роза ветров, формирование циклонов и прочее. За физику отвечает набор полуэмпирических моделей, по одной на тот или иной процесс, за динамику – параметризованная версия уравнения Эйлера.
На картинке показан срез расчетной сетки модели. Результаты расчетов температуры отображены цветом ячеек и являются в основном следствием физических процессов – нагрева и охлаждения. Стрелочки показывают перенос воздушных масс, то есть результат расчета динамики.
Уравнение Эйлера – это дифференциальное уравнение в частных производных. Понятно, что компьютер не может решать дифференциальные уравнения в частных производных без посторонней помощи. Помощь в данном случае состоит в разложении уравнений математической модели на конечно-разностные схемы. То есть, представляя производные в виде разностей, можно получить максимально правильное решение уравнения.
Сложность, однако, не только в том, чтобы как можно точнее приблизить численное решение к пока что не найденному аналитическому. Она еще и в том, чтобы адекватно параметризовать процессы, управляющие атмосферой извне. Солнечная радиация, тепловое излучение почвы, влияние парниковых газов, фазовые переходы водяного пара – вот неполный список всего того, что нужно учесть при попытках прогнозировать погоду.
Вероятно, эта задача была бы совсем уж неподъемной, если бы не наблюдения. За те годы, в течение которых человечество интересовалось будущими метеоусловиями (а это большой срок), накопился некоторый опыт проведения атмосферных измерений. Были придуманы такие вещи, как метеостанции, спутниковые спектрометры, самолетные приборы, радары, лидары — да мало ли чего еще. Тот объем данных, который является минимально необходимым для составления прогноза на уровне точности, соответствующем современным стандартам, необходимо использовать все доступные источники информации: более 10000 метеостанций по всему миру, более 80 спутников на околоземной орбите, около 1500 станций радиологического зондирования.
Сейчас данные о наблюдениях за атмосферой по всему земному шару, полученные в один фиксированный момент времени, представляют собой терабайты станционных наблюдений, радарных сканирований и спутниковых снимков. Их мало для того, чтобы полностью описать текущее состояние атмосферы, но они могут быть использованы для уточнения начальных условий модели.

Некоторые из доступных человечеству способов наблюдения за атмосферой
Поскольку точность решения дифференциальных уравнений во многом зависит от точности задания начальных условий, все данные наблюдений используются для составления максимально точного поля атмосферных параметров. Для совмещения расчетов модели и разрозненных экспериментальных данных существует технология ассимиляции данных, унаследовавшая проработанный математический аппарат из теории управления и вариационного исчисления. Таким образом, помимо численных моделей, в прогнозе погоды нам помогают данные синхронных наблюдений с орбиты и наземных станций.
Сейчас наша система расчетных областей численной модели спроектирована таким образом, чтобы покрывать территорию нашей необъятной родины прогнозами двух типов – на сетке с грубым разрешением (6 на 6 км) и на сетке с мелким разрешением (2 на 2 км). Эти сетки вложены друг в друга и взаимодействуют, передавая между собой данные о граничных и начальных условиях.
Чтобы рассчитывать, обрабатывать и хранить параметры атмосферы на таких масштабах, необходимы огромные вычислительные мощности. Дневной объем поступающих в хранилище прогнозов составляет более 10Тб. Прогноз погоды на 48 часов с заданным уровнем детализации для Московской области даже на кластерах Яндекса занимает около 6 часов.
Прогноз погоды рассчитывается каждый раз, когда пользователь обращается к сервису. Это продиктовано не только желанием отдавать самый точный актуальный прогноз погоды специально для координат пользователя, но еще и суровой необходимостью. Дело в том, что объем данных о погоде с высоким разрешением настолько велик, что предрасчет такого прогноза над территорией всей нашей родины займет несколько часов, и ни одна рантаймовая база не сможет отвечать на запросы за приемлемое время. Это также верно не только для результатов Метеума, но и для некоторых моделей, которые входят в его состав. Например, модели GFS и WRF передают такое количество информации, что для их передачи в API был организован микросервис, который, в отличие от многих баз данных хранить, обновлять и отдавать данные непосредственно из памяти входящих в микросервис машин.

Так на одном из ранних этапов работы выглядело расположение расчетных областей в центральном регионе РФ. Красный – внешний домен с сеткой 6 на 6 км, синие – вложенные области с более высоким разрешением (2 на 2 км)
Система получения, обработки и анализа данных, расчетов модели и их совмещения в алгоритме ассимиляции данных – это цепочка из многих звеньев. Помимо правильной обработки поступающих данных, необходимо корректно настроить их усвоение в начальных условиях для дифференциальных уравнений. За разработку и физическое обоснование этих алгоритмов отвечает теория ассимиляции данных — наука о корректном сочетании наблюдений с прогнозами математических моделей. Однако наблюдения за состоянием атмосферы, которые мы получаем из различных источников, могут пригодиться и для других целей.
Часть 2. Про машинное обучение
WRF является стандартом индустрии метеопрогнозирования, однако есть и другие модели: прогнозы, сделанные с помощью них мы получаем от наших партнеров. Несмотря на все знания человечества об атмосферных процессах, спутники и суперкомпьютеры, все эти модели, как вы знаете, ошибаются. Интересным является то, что в их прогнозах есть систематически воспроизводимые закономерности.
Помимо собственно модели WRF, которая рассчитывается на кластерах Яндекса, мы получаем прогнозы для 12000 городов по всему миру, сделанные одним из наших партнеров — компанией Foreca. Более детальная информация о глобальном состоянии атмосферы к нам приходит из американской модели Global Forecast System, которая считается одной из самых точных глобальных моделей в мире и имеет разрешение в 0.25 градуса.

Поведение этих моделей в разных метеорологических ситуациях позволяет Метеуму более точно оценивать корректировки, которые необходимо сделать к прогнозу и оптимально подобрать комбинацию исходных данных.
Некоторые из моделей прогноза погоды завышают количество выпавших на землю осадков, другие — занижают ночную температуру в черте города. Имея в распоряжении архив прогнозов моделей, можно выделить очень много таких закономерностей, в том числе и гораздо менее очевидных, чем те, о которых я говорил выше. Человеку это сделать достаточно сложно из-за огромных объемов данных, а вот алгоритмы машинного обучения с этим прекрасно справляются. Для выявления закономерностей и взаимосвязей между прогнозами моделей и реальной метеорологической обстановкой, мы используем известный вам алгоритм машинного обучения Матрикснет.
Матрикснет принимает на вход специальным образом переработанные архивы прогнозов погоды и сопоставляет их с данными о реальной метеорологической обстановке. В качестве данных о реальной погоде используются наблюдения, полученные на тысячах профессиональных метеостанций по всему миру.
В результате таких сопоставлений получается формула корректировки прогноза, которая, в зависимости от метеорологической ситуации, составляет оптимальную комбинацию прогнозов из данных моделей, предоставленных нашими поставщиками.

Метеум использует огромное количество данных, и это только начало. Например, в ряде регионов России точные метеоизмерения достаточно редки.

Их не достаточно для построения гиперлокального прогноза. Поэтому Метеум способен использовать большое количество данных, косвенно указывающих на метеообстановку. Мы уже используем данные Яндекс.Карт, которые помогают нам учитывать ландшафт местности. Я приведу еще один пример. Во многих моделях телефонов встроены барометры. Они не такие точные, как в метеостанциях, зато их миллионы. И распределены они там, где живут люди. В следующем году мы начнем использовать их данные для уточнения фактического состояния атмосферы.

Кроме того, уже сейчас в приложениях Яндекс.Погоды есть возможность рассказать о том, какая погода сейчас там, где вы находитесь. Мы изначально создавали Метеум расширяемым под различные классы данных, которые косвенно свидетельствуют о погоде, поэтому сможем учитывать и ваши наблюдения.
Часть 3. Behind blue eyes
Читатели Хабра, наверное, особенно отчетливо представляют себе что за процессами, описанными выше, должна стоять соответствующим образом спроектированная инфраструктура.
В режиме реального времени прогнозы моделей, необходимые для работы Метеума, собираются из нескольких разных источников. Находящиеся в микросервисе прогнозы WRF и GFS весят более 60 Гб и обновляются каждую минуту. Причем они делают это атомарно, большими кусками. Такие требования сделали невозможным использование традиционных рантайм-баз. Прогнозы компании Foreca хранятся в PostgreSQL, так как их объемы и частота обновления значительно ниже. После обработки и показа пользователю, результаты формулы вместе с составными частями (прогнозы поставщиков и другие факторы, передаваемые в Матрикснет), отправляются в кластер MapReduce. Эти данные впоследствии используются для верификации и дополнительной настройки работы Метеума.
Часть 4. Тотальный рантайм
Все те процессы, которые мы описали выше, происходят каждый раз, когда пользователь заходит в Яндекс.Погоду. Делая запрос, вы посылаете в Метеум свои географические координаты. Он собирает все необходимые для прогноза данные, анализирует метеорологическую обстановку, тип подстилающей поверхности и составляет на основе этих данных свой собственный прогноз специально для вашего положения.

Часть 5. Что получилось
По нашим собственных оценкам (увы, независимых измерителей в этой области пока нет), на сегодня наш прогноз погоды точнее всех известных нам конкурентов. Например, температурный прогноз на 24 часа у нас ошибается на 35% меньше ближайшего конкурента.
Но мы понимаем, что до идеала ещё далеко, и надеемся, что через некоторое время нам удастся ещё больше увеличить точность, благодаря данным от пользователей приложения, а также дополнительным источникам сведений об атмосфере.
