Идиома ranges — крайне удачное развитие итераторов. Она позволяет писать высокопроизводительный код, не выделяющий память, где это не надо, находясь на предельно высоком уровне абстракции. Кроме того делает библиотеки гораздо более универсальными, а их интерфейсы гибкими. Под катом краткое описание и практические примеры использования идиомы, тесты производительности, а так же сравнение с популярными реализациями итераторов в C++ и C#.
Далее в статье вместо английского «range» будет использоваться устоявшийся перевод «диапазон». Это немного режет слух, и это слово имеет множество других значений, но всё же лучше подходит для русского текста.
Немного теории
Статья исключительно практическая, но сначала всё же синхронизируем теорию. Во-первых, обязательно требуется понимание ленивых вычислений. Во-вторых, нужна структурная типизация. И если про ленивые вычисления можно почитать на вики и там всё предельно чётко, то с точностью формулировок структурной типизации есть проблемы. На вики написано совсем мало.
Здесь под структурной типизацией мы будем понимать утиную типизацию, но с проверкой на этапе компиляции. Так работают шаблоны в C++ и D, интерфейсы в Go. То есть функция принимает аргументы всех типов, таких, что на объекте можно вызвать все используемые функцией методы и операторы. В отличие от более распространённой номинативной типизации, где необходимо указывать список реализуемых интерфейсов, структурная не предъявляет требований к объявлению типа. Достаточно, что с объектом можно сделать то, что используется внутри функции. Однако, проверка совместимости происходит не в рантайме во время динамического вызова, а во время компиляции. Если такая формулировка всё ещё не понятна — не беда, гораздо понятнее будет практическое применение.
Вычисление AB группы
Постановка задачи
Рассмотрим одну простую задачу. Нужно написать функцию, вычисляющую, к какой AB группе относится пользователь. При AB тестировании нам надо разбить всех пользователей на несколько случайных групп. Традиционно это делается так: считаем хэш от id пользователя и id теста и берём остаток от деления на количество групп. Хэш даёт некую рандомизацию, а использование id теста делает разбиение различным для различных тестов. Если отбросить все детали предметной области, то нам нужна функция, формально описываемая формулой:
ab_group(groupId, userId, count) = hash(groupId + userId) % count, где groupId и userId – строки, а count – положительное число. В качестве hash() используется jenkins_one_at_a_time_hash.
Реализация в лоб
static uint32_t get_ab_group(const string& testId, const string& uid, size_t count) {
string concat = testId + uid;
uint32_t hashVal = string_hash32(concat.c_str(), concat.size());
return hashVal % count;
}
static uint32_t string_hash32 (const char *key, size_t len) {
uint32_t hash, i;
for (hash = i = 0; i < len; ++i) {
hash += key[i];
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return hash;
}
Реализация хэш-функции была честно откуда-то скопирована, а всё остальное, как видите, требует всего 3 строки кода. Данная реализация решает поставленную задачу: тесты проходят, результаты совпадают с посчитанными ранее. Есть только один недостаток – скорость работы. Выбор C++ обоснован необходимостью использования функции из плагина к infinidb. Нам было нужно считать группу «на лету» для всей базы пользователей. Ожидалось, что функция будет выдавать скорость в десятки миллионов в секунду, ведь хэш-функция работала с такой скоростью.
Оптимизации
Для того чтобы понять, что здесь тормозит не понадобилось даже запускать профайлер. Ещё во время написания было понятно, что быстро это работать не будет из-за одной строки:
string concat = testId + uid;Здесь происходит создание новой строки с выделением памяти под неё и последующим копированием. При этом мы освобождаем память сразу при выходе из функции. То есть на самом деле объект строки в куче не нужен. Можно конечно выделить память на стеке, но на общее решение этот подход не претендует.
Программист, не знакомый с идиомой диапазонов, предложил вполне классическое решение. Так как от самой строки зависит только первая часть функции вычисления хэша, то её можно вынести в отдельную функцию, которая вернёт промежуточный результат. Её можно вызывать несколько раз для разных строк, передавая промежуточный результат от вызова к вызову. Ну и в конце позвать некий финализатор, который даст окончательный хэш.
static uint32_t string_hash32_start(uint32_t hash, const char *key, size_t len)
{
for(uint32_t i = 0; i < len; ++i) {
hash += key[i];
hash += (hash << 10);
hash ^= (hash >> 6);
}
return hash;
}
static uint32_t string_hash32_end(uint32_t hash)
{
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return hash;
}
static uint32_t get_ab_group(const string& testId, const string& uid, size_t count)
{
uint32_t hash = 0;
hash = string_hash32_start(hash, test_id);
hash = string_hash32_start(hash, uid);
hash = string_hash32_end(hash);
return hashVal % count;
}
Подход вполне понятный, много, где так делается. Вот только не очень хорошо читается, да и изначальную функцию разобрать пришлось. А ведь не всегда можно так сделать. Потребуй алгоритм нескольких проходов по всей строке или проход в обратном направлении, и такой подход уже был бы не реализуем.
Ranges
Для того, чтобы сделать функцию действительно обобщённой нам понадобится минимум изменений. Алгоритм мы не трогаем вовсе, просто меняем тип аргумента с сишной строки на шаблон:
template <typename Range>
static uint32_t string_hash32_v3 (Range r) {
uint32_t hash = 0;
for (const char c : r) {
hash += c;
hash += (hash << 10);
hash ^= (hash >> 6);
}
hash += (hash << 3);
hash ^= (hash >> 11);
hash += (hash << 15);
return hash;
}То есть функция стала принимать любой объект, foreach по которому даёт char. На эту роль подходит любой контейнер из std, с аргументом char. Сишная zero-terminated строка так же несложно оборачивается в такой контейнер. Но, что самое главное, теперь можно передать ленивый генератор.
Возьмём функцию concat из библиотеки ranges-v3. Эта функция возвращает объект, который поддерживает интерфейс итерирования по нему и отдаёт поэлементно содержимое всех переданных ему коллекций. Сначала проходит по первой, потом по второй и тд. То есть выглядит как строка a + b, только не выделяет память, а просто ссылается на оригинальные строки. А раз крякает как утка, то и использовать будем, как утку:
static uint32_t get_ab_group_ranges_v3(const string& testId, const string& uid, size_t count) {
auto concat = concat(testId, uid);
uint32_t hashVal = string_hash32_v3(concat);
return hashVal % count;
}Выглядит так же, как самая первая неоптимизированная версия, просто вместо оператора + позвали функцию concat из библиотеки ranges-v3. А вот работает ощутимо быстрее.
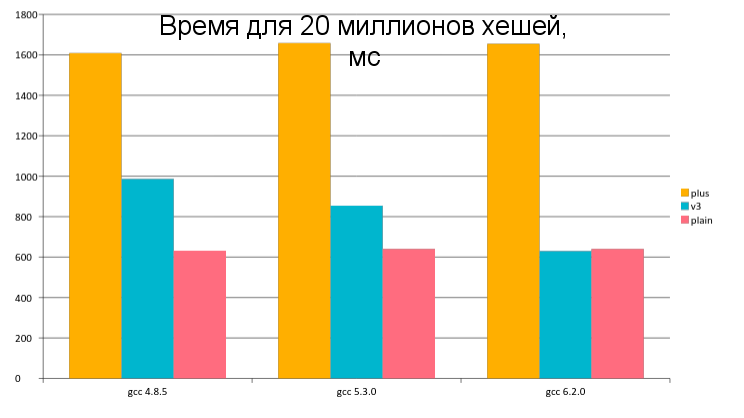
Время для 20 миллионов хешей, мс
| gcc 4.8.5 | gcc 5.3.0 | gcc 6.2.0 | |
| plus | 1609 | 1658 | 1655 |
| v3 | 987 | 855 | 630 |
| plain | 631 | 640 | 640 |
Пояснение к таблице. plus — самая первая реализация, использующая конкатенацию строк. v3 — реализация на диапазноах. plain — первая оптимизированная версия, с разбиением хэширования на start и end.
Исходники
К сожалению я сейчас в отпуске и не имею доступа к исходникам этого бенчмарка. По возможности они будут выложены на github. Пока могу предложить только самостоятельные эксперименты, благо что ranges-v3 — header-only и не составляет труда ею воспользоваться.
Мы можем наблюдать интересное явление: с GCC6 обобщённая версия с диапазонами работает так же быстро, как оптимизированная узкоспециализированная. Конечно тут хорошо поработал оптимизатор. Отлично видно развитие оптимизаций от gcc4 до gcc5 и 6.
Все итераторы и вызовы методов на них были заинлайнены. Лишние условия в цикле переупорядочены и упрощены. В итоге на некоторых компиляторах дизассемблер обеих версий показывает одно и то же. А на GCC6 range-версия даже немного быстрее. Этот феномен не изучал, но в корректности работы уверен, поэтому могу только порадоваться развитию технологий и посоветовать использовать последние версии компиляторов.
Иногда оптимизатор и вовсе творит чудеса. Так, например, в библиотеке обработки изображений он может объединять последовательные преобразования в одно, более быстрое: 2 поворота можно собрать в один, любые афинные преобразования можно собрать в одно. Перевод оригинальной статьи был на Хабре.
Из интересных примеров: 4 поворота на 90 градусов, компилятор вообще выкинул из кода.
Поиск подстрок
Как было показано в примерах и бенчмарках, диапазоны быстрые. Однако основное их преимущество в том, что они удобные и быстрые одновременно. Ну, или как минимум показывают отличное соотношение удобства написания к скорости работы.
Рассмотрим следующую задачу: найти все вхождения чисел в заданной строке. Далее для повышения читаемости используется D, а не C++. Для такой функции можно предложить два классических интерфейса. Удобный:
double[] allNumbersArr(string input);И быстрый:
Nullable!double findNumber(string input, ref size_t begin);С удобным всё понятно: на вход строка, на выход массив чисел. Недостаток – необходимо создавать массив под результат. Причём создавать только в куче.
С быстрым сложнее. С первого взгляда не очень понятно, как этим пользоваться. Он возвращает одно значение и то не всегда, иногда может вернуть null. Предполагается, что функция будет вызываться в цикле для обхода всех значений и будет получать метку, откуда начинать поиск.
string test = "123 gfd 44";
size_t begin = 0;
Nullable!double iter;
while (iter = findNumber(test, begin), !iter.isNull) {
double val = iter.get;
writeln(val);
}Не самый интуитивно понятный и читаемый способ. Зато не требует массивов и быстрее работает. Правда каждый раз, используя функцию придётся писать этот не самый тривиальный while, не забывать, что нужна переменная begin и как пользоваться Nullable. В чистом C, кстати пришлось бы ещё добавить указатель на begin, а в виду отсутствия Nullable добавить ещё один флажок, что ничего не нашли. Ну или сравнивать полученный begin с длинной строки. В общем быстро, но неудобно.
Диапазоны предлагают объединить удобство со скоростью. Реализация будет выглядеть так:
auto allNumbers(string input) {
alias re = ctRegex!`\d+(\.\d+)?`;
auto matches = matchAll(input, re);
return matches.map!(a => a.hit.to!double);
}Функция возвращает Воландеморт тип (тип, который нельзя называть, у него нет имени за пределами реализации map). Функция matchAll вернёт ленивый range, который начнёт искать при первом обращении. map тоже ленивая, поэтому не будет трогать matches, пока не попросят. То есть в момент вызова функции не произойдёт поиск всех вхождений и не создастся массив под них. Но вот выглядит результат как все вхождения чисел. Примеры использования:
auto toWrite = allNumbers("124 ads 85 3.14 43");
foreach (d; toWrite) {
writeln(d);
}Здесь writeln пройдёт по всем вхождениям и напечатает на экран.
auto toSum = allNumbers("1 2 3 4 5");
writeln("sum is ", sum(toSum));sum – алгоритм стандартной библиотеки. Принимает диапазон любых чисел и, очевидно, суммирует. Опять же придётся пройти по всем, но никаких массивов, в один момент времени существет один double.
auto toCheck = allNumbers("1qwerty");
writeln("there are some ", !toCheck.empty);А тут мы вообще только проверили, а есть ли числа в строке. При этом произойдёт минимум необходимого. Если числа есть, то поиск остановится на первом и empty вернёт false. Полный проход по строке произойдёт только, если чисел нет. Я думаю многие на талкивались на проблемы с производительностью из-за того, что для проверки наличия создавались массивы. Как самый эпичный случай:
bool exists = sql.query(“SELECT * FROM table”).count() > 0;Подняли всю таблицу в память только для того, чтобы проверить не пустая ли она. Такой код бывает. И его уже не получается «развидеть». От sql запроса диапазоны понятное дело не спасут (тут уже вообще ничего не поможет), но в случае строк или файлов лишней работы не будет.
Важно отметить, что функции стандартной библиотеки D, а так же ranges-v3 для C++, как и любые хорошие функции для работы с диапазонами, не указывают конкретных типов. Они обобщены до предела, и конкатенировать можно и обычные массивы, списки и хэши, а что самое важное – другие диапазоны. Ничего не мешает передать аргументом результат работы алгоритма, будь то фильтрация, отображение или другую конкатенацию. В этом смысле Range – развитие итератора. На них точно так же строятся обобщённые алгоритмы как stl и есть надежда, что stl2 возьмёт за основу диапазоны.
Пока что мы рассмотрели всего лишь два алгоритма: поиск и объединение. На самом деле ленивых диапазонов очень много. Для D можно посмотреть на список здесь и здесь. Для С++ лучшим источником является библиотека Ranges-V3.
Короткий обзор наиболее полезных алгоритмов
iota – генератор последовательности натуральных чисел. От 0 до заданного. Есть версии для задания шага и начального значений.
chunks – разбить входной диапазон на несколько других с фиксированной длиной. Позволяет на заботиться о не кратной длине, пустых входных данных и тд. Очень удобен для работы с API, ограничивающими размерность входных данных (REST Facebook с ограничениями на все массовые запросы)
auto numbers = iota(35);
foreach (chunk; numbers.chunks(10)) {
writeln(chunk);
}Выводит
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29]
[30, 31, 32, 33, 34]enumerate – для входного диапазона создаёт диапазон из элемента и его номера в исходном
zip – собирает несколько диапазонов в диапазон, где в первом элементе кортеж из первых элементов исходных, во втором из вторых и тд. Очень удобен для одновременного итерирования по коллекциям одинаковой длины.
repeat – повторять до бесконечности заданное значение
take – взять заданное количество элементов
auto infPi = repeat(3.14);
writeln(infPi.take(10));
[3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14, 3.14]Преимущества структурной типизации
Этот параграф скорее относится к структурной типизации вообще, нежели к диапазонам, но без них всё равно не обошлось. Классическая «проблема» ООП: нельзя передать массив потомков в функцию, где ожидается массив предков. Нельзя не потому, что авторы языков такие плохие, а потому что это приведёт к логическим ошибкам. Допустим было бы можно. Массивы обычно передаются по ссылке. Теперь передадим в функцию, ожидающую массив животных, массив кошек. А эта функция возьмёт, да добавит в массив собаку! И на выходе мы имеем массив кошек, в котором есть собака. Const мог бы решить проблему, но только этот частный случай, да и запрещать вставлять кошек не хочется.
Зато итерироваться и вызывать методы объектов можно всегда. С диапазонами на C++ это бы выглядело так:
class Animal {
virtual void walk() {}
};
class Cat : public Animal {
void walk() override {}
};
template <typename Range>
void walkThemAll(Range animals) {
for (auto animal : animals) {
animal->walk();
}
}
void some() {
walkThemAll(new Cat[100]);
}Благодаря шаблону Range типизирован именно кошками, и собаку туда уже не затолкать.
Чем это отличается от итераторов?
Если говорить абстрактно, то это и есть итераторы. Но это теоретически, а от существующих реализаций отличий много. От С++ итераторов диапазоны отличаются целостностью. Они сами знают, где заканчиваются и весьма затруднительно получить невалидный диапазон. Итератор в С++ это скорее указатель, а диапазон — ссылка на std::vector.
В C# итераторы более развитые и у них нет проблемы целостности. Но есть несколько других принципиальных отличий. Во-первых, итераторы в шарпе это только одна разновидность диапазонов — InputRange. Это итерируемая в одну сторону сущность без возможности вернуться назад или хотя бы скопировать текущее состояние. Кроме них существуют ForwardRange (с сохранением состояния), BidirectionalRange (возможность итерироватьсяв обратную сторону), RandomAccessRange(произвольный доступ через оператор []), OutputRange(запись без чтения). Всё это даже теоретически не покрыть одним yield return.
Во-вторых, производительность. Виртуальной машине придётся сотворить чудо чтобы произвести оптимизации доступные в C++. А всё из-за разрыва потока выполнения и переключения между контекстами. Да и дженерики в отличие от шаблонов код не генерируют и не могут производить оптимизации частных случаев. А как показывает пример С++, эти оптимизации в разы ускоряют код. Мои предварительные бенчмарки, в которых я не уверен, показывают, что попытка самостоятельно реализовать concat проваливается из-за скорости. Обычная конкатенация просто быстрее. Скорей всего jit хорошо справляется с работой над цельной строкой, а GC с переиспользованием памяти. А вот миллионы лишних переключений и вызовов функций выкинуть некому.
В-третьих, готовые алгоритмы. На D или C++ уже сейчас есть масса ленивых алгоритмов. Шарп может похвастаться только генераторами. Наличие соглашений позволяет писать код вида:
array.sort.chunks(10).map(a=>sum(a)).enumerate;Цепочку вызовов можно продолжать бесконечно. В С++ нет такого вызова через точку, зато есть перегруженный для диапазонов оператор |. Поэтому делать можно то же самое, просто заменив. на |.
А в go, perl, #my_favorite_lang тоже структурная типизация!
Да, и это позволяет написать что-то очень похожее. Не принято, но сделать можно. Быстро это работать не будет потому же, что и в C#. Интерфейсы go, как и дженерики C# используют косвенные вызовы вместо кодогенерации. То есть каждая итерация потребует минимум 2 виртуальных вызова. За время виртуального вызова можно сделать несколько итераций с инлайном, поэтому разница с С++ будет в разы.
На этом всё, спасибо, что дочитали до сюда.
Материал был подготовлен для презентации в компании CrazyPanda и скопирован сюда as is. Распространение и копирование автором не воспрещается, но при условии соблюдении правил habrahabr. Если хабрасообщество заинтересуется вопросом, то возможно последует продолжение непосредственно для хабра.
Ссылки по теме:
» ericniebler.com/2013/11/07/input-iterators-vs-input-ranges
» www.youtube.com/watch?v=mFUXNMfaciE
» ericniebler.com/2015/02/03/iterators-plus-plus-part-1
» github.com/ericniebler/range-v3
» dlang.org/phobos/std_range.html
» dlang.org/phobos/std_algorithm.html