Он пьянел медленно, но все-таки опьянел, как-то сразу, скачком; и когда в минуту просветления увидел перед собой разрубленный дубовый стол в совершенно незнакомой комнате, обнаженный меч в своей руке и рукоплещущих безденежных донов вокруг, то подумал было, что пора идти домой. Но было поздно.
Аркадий и Борис Стругацкие
31 января 2017 года произошло важное для мира OpenSource событие: один из админов GitLab.com, пытаясь починить репликацию, перепутал консоли и удалил основную базу PostgreSQL, в результате чего было потеряно большое количество пользовательских данных и сам сервис ушел в офлайн. При этом все 5 различных способов бэкапа/репликации оказались нерабочими. Восстановились же с LVM-снимка, случайно сделанного за 6 часов до удаления базы. It, как говорится, happens. Но надо отдать должное команде проекта: они нашли в себе силы отнестись ко всему с юмором, не потеряли голову и проявили удивительную открытость, написав обо всем в твиттере и выложив в общий доступ, по сути, внутренний документ, в котором команда в реальном времени вела описание разворачивающихся событий.
Во время его чтения буквально ощущаешь себя на месте бедного YP, который в 11 часов вечера после тяжелого трудового дня и безрезультатной борьбы с Постгресом, устало щурясь, вбивает в консоль боевого сервера роковое sudo rm -rf и жмет Enter. Через секунду он понимает, что натворил, отменяет удаление, но уже поздно — базы больше нет...
По причине важности и во многих смыслах поучительности этого случая мы решили целиком перевести на русский язык его журнал-отчет, сделанный сотрудниками GitLab.com в процессе работы над инцидентом. Результат вы можете найти под катом.
Итак, давайте узнаем во всех подробностях, как это было.
Инцидент с базой данных GitLab.com от 31/01/2017
Замечание: этот инцидент затронул базу данных (включая задачи (issues) и запросы на слияние (merge requests)); git-репозитории и wiki-страницы не пострадали.
Прямая трансляция на YouTube — следите за тем, как мы обсуждаем и решаем проблему!
- Понесенные потери
- Хронология (время указано в UTC)
- Восстановление — 2017/01/31 23:00 (бэкап от примерно 17:20 UTC)
- Возникшие проблемы
- Помощь со стороны
- HugOps (добавляйте здесь посты из twitter и откуда-либо еще, в которых люди по-доброму реагировали на случившееся)
- Stephen Frost
- Sam McLeod
Понесенные потери
- Потеряны данные примерно за 6 часов.
- Потеряно 4613 обычных проектов, 74 форка и 350 импортов (грубо); всего 5037. Поскольку Git-репозитории НЕ потеряны, мы сможем воссоздать те проекты, пользователи/группы которых существовали до потери данных, но не сможем восстановить задачи (issues) этих проектов.
- Потеряно около 4979 (можно сказать, около 5000) комментариев.
- Потенциально потеряно 707 пользователей (сложно сказать точнее по логам Kibana).
- Веб-хуки, созданные до 31 января 17:20, восстановлены, созданные после — потеряны.
Хронология (время указано в UTC)
- 2017/01/31 16:00/17:00 — 21:00
- YP работает над настройкой pgpool и репликацией в staging, создает LVM-снимок, чтобы загрузить боевые данные в staging, а также в надежде на то, что сможет использовать эти данные для ускорения загрузки базы на другие реплики. Это происходит примерно за 6 часов до потери данных.
- Настройка репликации оказывается проблематичной и очень долгой (оценочно ~20 часов только на начальную синхронизацию pg_basebackup). LVM-снимок YP использовать не смог. Работа на этом этапе была прервана (так как YP была нужна помощь другого коллеги, который в тот день не работал, а также из-за спама/высокой нагрузки на GitLab.com).
- 2017/01/31 21:00 — Всплеск нагрузки на сайт из-за спамеров — Twitter | Slack
- Блокирование пользователей по их IP-адресам.
- Удаление пользователя за использование репозитория в качестве CDN, в результате чего 47 000 айпишников залогинились под тем же аккаунтом (вызвав высокую нагрузку на БД). Информация была передана командам технической поддержки и инфраструктуры.
- Удаление пользователей за спам (с помощью создания сниппетов) — Slack
- Нагрузка на БД вернулась к норме, вручную запущен vacuum нескольких таблиц PostgreSQL, чтобы почистить большое количество оставшихся пустых строк.
- 2017/01/31 22:00 — Получено предупреждение об отставании репликации — Slack
- Попытки починить db2, отставание на этом этапе 4 GB.
- db2.cluster отказывается реплицироваться, каталог /var/opt/gitlab/postgresql/data вычищен, чтобы обеспечить чистую репликацию.
- db2.cluster отказывается подключаться к db1, ругаясь на слишком низкое значение max_wal_senders. Эта настройка используется для ограничения количества клиентов WAL (репликации).
- YP увеличивает max_wal_senders до 32 на db1, перезапускает PostgreSQL.
- PostgreSQL ругается на то, что открыто слишком много семафоров, и не стартует.
- YP уменьшает max_connections с 8000 до 2000, PostgreSQL стартует (при том, что он нормально работал с 8000 почти целый год).
- db2.cluster все еще отказывается реплицироваться, но на соединения больше не жалуется, а вместо это просто висит и ничего не делает.
- В это время YP начинает чувствовать безысходность. Раньше в этот день он сообщил, что собирается заканчивать работу, так как было поздно (около 23:00 по местному времени), но остался на месте по причине неожиданно возникших проблем с репликацией.
- 2017/01/31 около 23:00
- YP думает, что, возможно, pg_basebackup чересчур педантично относится к чистоте директории для данных, и решает ее удалить. Спустя пару секунд он замечает, что запустил команду на db1.cluster.gitlab.com вместо db2.cluster.gitlab.com.
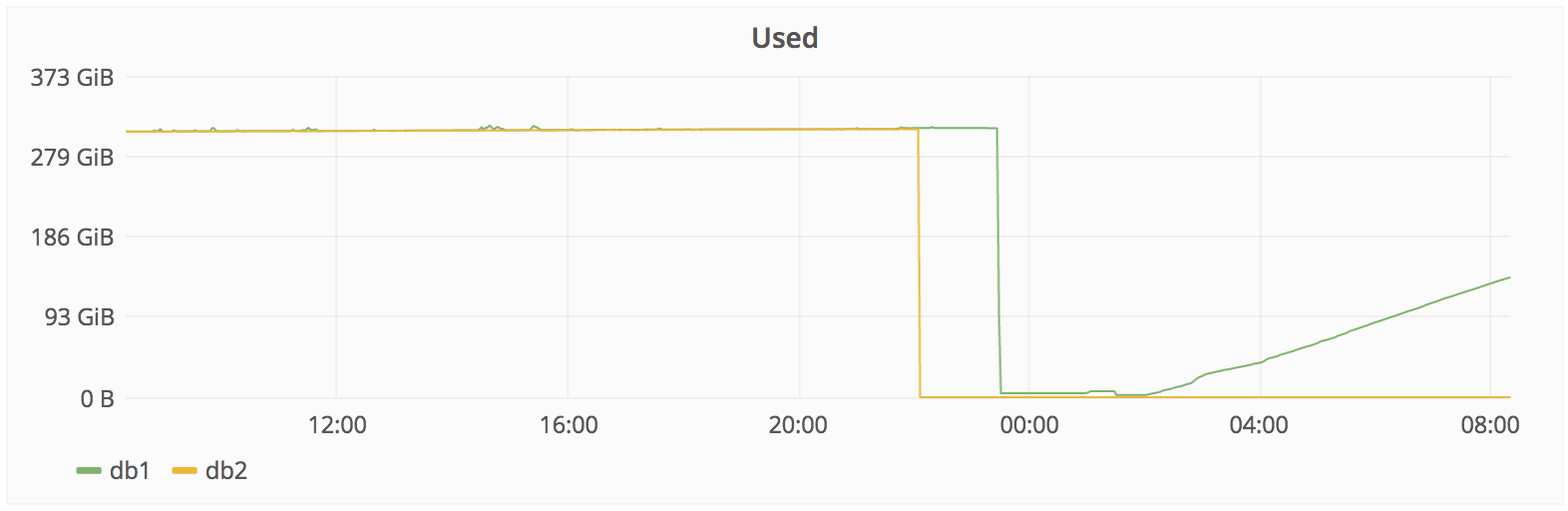
- 2017/01/31 23:27: YP отменяет удаление, но уже слишком поздно. Из примерно 310 Гб осталось только 4.5 — Slack.
Восстановление — 2017/01/31 23:00 (бэкап от ~17:20 UTC)
- Предложенные способы восстановления:
- Смигрировать db1.staging.gitlab.com на GitLab.com (отставание около 6 часов).
- CW: Проблема с веб-хуками, которые были удалены во время синхронизации.
- Восстановить LVM-снимок (отстает на 6 часов).
- Sid: попробовать восстановить файлы?
- CW: Невозможно! rm -Rvf Sid: OK.
- JEJ: Наверное, уже слишком поздно, но может ли помочь, если достаточно быстро перевести диск в режим read-only? Также нельзя ли получить дескриптор файла, если он используется работающим процессом (согласно http://unix.stackexchange.com/a/101247/213510).
- YP: PostgreSQL не держит все свои файлы постоянно открытыми, так что это не сработает. Также похоже, что Azure очень быстро удаляет данные, а вот пересылает их на другие реплики уже не так шустро. Другими словами, данные с самого диска восстановить не получится.
- SH: Похоже, что на db1 staging-сервере отдельный PostgreSQL-процесс льет поток production-данных с db2 в каталог gitlab_replicator. Согласно отставанию репликации db2 был погашен в 2016-01-31 05:53, что привело к остановке gitlab_replicator. Хорошие новости заключаются в том, что данные вплоть до этого момента выглядят нетронутыми, поэтому мы, возможно, сможем восстановить веб-хуки.
- Смигрировать db1.staging.gitlab.com на GitLab.com (отставание около 6 часов).
- Предпринятые действия:
- 2017/02/01 23:00 — 00:00: Принято решение восстанавливать данные с db1.staging.gitlab.com на db1.cluster.gitlab.com (production). Несмотря на то, что они отстают на 6 часов и не содержат веб-хуков, это единственный доступный снимок. YP говорит, что ему сегодня лучше больше не запускать никаких команд, начинающихся с sudo, и передает управление JN.
- 2017/02/01 00:36 — JN: Делаю бэкап данных db1.staging.gitlab.com.
- 2017/02/01 00:55 — JN: Монтирую db1.staging.gitlab.com на db1.cluster.gitlab.com.
- Копирую данные со staging /var/opt/gitlab/postgresql/data/ в production /var/opt/gitlab/postgresql/data/.
- 2017/02/01 01:05 — JN: nfs-share01 сервер выделен в качестве временного хранилища в /var/opt/gitlab/db-meltdown.
- 2017/02/01 01:18 — JN: Копирую оставшиеся production-данные, включая запакованный pg_xlog: ‘20170131-db-meltodwn-backup.tar.gz’.
- 2017/02/01 01:58 — JN: Начинаю синхронизацию из stage в production.
- 2017/02/01 02:00 — CW: Для объяснения ситуации обновлена страничка развертывания (deploy page). Link.
- 2017/02/01 03:00 — AR: rsync выполнился примерно на 50% (по количеству файлов).
- 017/02/01 04:00 — JN: rsync выполнился примерно на 56.4% (по количеству файлов). Передача данных идет медленно по следующим причинам: пропускная способность сети между us-east и us-east-2, а также ограничение производительности диска на staging-сервере (60 Mb/s).
- 2017/02/01 07:00 — JN: Нашел копию нетронутых данных на db1 staging в /var/opt/gitlab_replicator/postgresql. Запустил виртуальную машину db-crutch VM на us-east, чтобы сделать бэкап этих данных на другую машину. К сожалению, она ограничена 120 GB RAM и не потянет рабочую нагрузку. Эта копия будет использована для проверки состояния базы данных и выгрузки данных веб-хуков.
- 2017/02/01 08:07 — JN: Передача данных идет медленно: по объему данных передано 42%.
- 2017/02/02 16:28 — JN: Передача данных закончилась.
- 2017/02/02 16:45 — Ниже приведена процедура восстановления.
- Процедура восстановления
- [x] — Сделать снимок сервера DB1 — или 2 или 3 — сделано в 16:36 UTC.
- [x] — Обновить db1.cluster.gitlab.com до PostgreSQL 9.6.1, на нем по-прежнему 9.6.0, а staging использует 9.6.1 (в противном случае PostgreSQL может не запуститься).
- Установить 8.16.3-EE.1.
- Переместить chef-noop в chef-client (было отключено вручную).
- Запустить chef-client на хосте (сделано в 16:45).
- [x] — Запустить DB — 16:53 UTC
- Мониторить запуск и убедиться, что все прошло нормально.
- Сделать бэкап.
- [x] — Обновить Sentry DSN, чтобы ошибки не попали в staging.
- [x] — Увеличить идентификаторы во всех таблицах на 10k, чтобы избежать проблем при создании новых проектов/замечаний. Выполнено с помощью https://gist.github.com/anonymous/23e3c0d41e2beac018c4099d45ec88f5, который читает текстовый файл, содержащий все последовательности (по одной на строку).
- [x] — Очистить кеш Rails/Redis.
- [x] — Попытаться по возможности восстановить веб-хуки.
- [x] Запустить staging, используя снимок, сделанный до удаления веб-хуков.
- [x] Убедиться, что веб-хуки на месте.
- [x] Создать SQL-дамп (только данные) таблицы “web_hooks” (если там есть данные).
- [x] Скопировать SQL-дамп на production-сервер.
- [x] Импортировать SQL-дамп в рабочую базу.
- [x] — Проверить через Rails Console, могут ли подключаться рабочие процессы (workers).
- [x] — Постепенно запустить рабочие процессы.
- [x] — Отключить страницу развертывания.
- [x] — Затвитить с @gitlabstatus.
- [x] — Создать связанные со сбоем задачи, описывающие дальнейшие планы/действия Скрытый текст
- https://gitlab.com/gitlab-com/infrastructure/issues/1094
- https://gitlab.com/gitlab-com/infrastructure/issues/1095
- https://gitlab.com/gitlab-com/infrastructure/issues/1096
- https://gitlab.com/gitlab-com/infrastructure/issues/1097
- https://gitlab.com/gitlab-com/infrastructure/issues/1098
- https://gitlab.com/gitlab-com/infrastructure/issues/1099
- https://gitlab.com/gitlab-com/infrastructure/issues/1100
- https://gitlab.com/gitlab-com/infrastructure/issues/1101
- https://gitlab.com/gitlab-com/infrastructure/issues/1102
- https://gitlab.com/gitlab-com/infrastructure/issues/1103
- https://gitlab.com/gitlab-com/infrastructure/issues/1104
- https://gitlab.com/gitlab-com/infrastructure/issues/1105
[ ] — Создать новые записи Project Git-репозиториев, у которых нет записей Project, в случаях, когда пространство имен соответствует существующему пользователю/группе.
- PC —
Я создаю список этих репозиториев, чтобы мы могли проверить в базе данных, существуют ли они.
[ ] — Удалить репозитории с неизвестными (потерянными) пространствами имен.
- AR — работаю над скриптом, основанным на данных с предыдущей точки.
[x] — Еще раз удалить спам-пользователей (чтобы они снова не создали проблем).
- [x] CDN-пользователь с 47 000 IP-адресами.
- Сделать после восстановления данных:
- Создать задачу на изменение в терминалах PS1-формата/цветов, чтобы было сразу понятно, какая среда используется: production или staging (production — красный, staging — желтый). Для всех пользователей по умолчанию в приглашении bash показывать полное имя хоста (например, “db1.staging.gitlab.com” вместо “db1”): https://gitlab.com/gitlab-com/infrastructure/issues/1094
- Как-нибудь запретить rm -rf для директории data PostgreSQL? Не уверен, что это выполнимо или необходимо (в том случае, если есть нормальные бэкапы).
- Добавить оповещения для бэкапов: проверка хранилища S3 и т. д. Добавить график, показывающий изменения размеров бэкапов, выдавать предупреждение, когда размер уменьшается более чем на 10%: https://gitlab.com/gitlab-com/infrastructure/issues/1095.
Рассмотреть добавление времени последнего успешного бэкапа в БД, чтобы админы могли легко увидеть эту информацию(предложено клиентом в https://gitlab.zendesk.com/agent/tickets/58274).- Разобраться, почему у PostgreSQL внезапно возникли проблемы с max_connections, установленным в 8000, несмотря на то, что это работало с 2016-05-13. Неожиданное появление этой проблемы во многом ответственно за навалившиеся отчаяние и безысходность: https://gitlab.com/gitlab-com/infrastructure/issues/1096.
- Посмотреть на увеличение порогов репликации через архивацию WAL / PITR — также будет полезно после неудачных обновлений: https://gitlab.com/gitlab-com/infrastructure/issues/1097.
- Создать для пользователей руководство по решению проблем, которые могут возникнуть после запуска сервиса.
- Поэкспериментировать с перемещением данных из одного дата-центра в другой с помощью AzCopy: Microsoft говорит, что это должно работать быстрее rsync:
- Похоже, это Windows-специфичная вещь, а у нас нет экспертов по Windows (или кого-то хотя бы отдаленно, но в достаточной степени знакомого с вопросом, чтобы грамотно это протестировать).
Возникшие проблемы
- LVM-снимки по умолчанию делаются лишь один раз в 24 часа. По счастливой случайности YP за 6 часов до сбоя сделал один вручную.
- Регулярные бэкапы, похоже, также делались только раз в сутки, хотя YP еще не выяснил, где они хранятся. Согласно JN они не работают: создаются файлы размером в несколько байт.
- SH: Похоже, что pg_dump работает неправильно, поскольку выполняются бинарники от PostgreSQL 9.2 вместо 9.6. Это происходит из-за того, что omnibus использует только Pg 9.6, если data/PG_VERSION установлено в 9.6, но на рабочих узлах этого файла нет. В результате по умолчанию запускается 9.2 и тихо завершается, ничего не сделав. В итоге SQL-дампы не создаются. Fog-гем, возможно, вычистил старые бэкапы.
- Снимки дисков в Azure включены для NFS-сервера, для серверов баз данных — нет.
- Процесс синхронизации удаляет веб-хуки после того, как он синхронизировал данные на staging. Если мы не сможем вытащить их из обычного бэкапа, сделанного в течение 24 часов, они будут потеряны.
- Процедура репликации оказалось очень хрупкой, склонной к ошибкам, зависящей от случайных shell-скриптов и плохо документированной.
- SH: Мы позже выяснили, что обновление базы данных staging работает путем создания снимка директории gitlab_replicator, удаления конфигурации репликации и запуска отдельного PostgreSQL-сервера.
- Наши S3-бэкапы также не работают: папка пуста.
- У нас нет надежной системы оповещений о неудачных попытках создания бэкапов, мы теперь видим такие же проблемы и на dev-хосте.
Другими словами, из 5 используемых способов бэкапа/репликации ни один не работает. => сейчас мы восстанавливаем рабочий бэкап, сделанный 6 часов назад.
http://monitor.gitlab.net/dashboard/db/postgres-stats?panelId=10&fullscreen&from=now-24h&to=now
Помощь со стороны
Hugops (добавляйте здесь посты из twitter или откуда-то еще, в которых люди по-доброму реагировали на случившееся)- A Twitter Moment for all the kind tweets: https://twitter.com/i/moments/826818668948549632
- Jan Lehnardt https://twitter.com/janl/status/826717066984116229
- Buddy CI https://twitter.com/BuddyGit/status/826704250499633152
- Kent https://twitter.com/kentchenery/status/826594322870996992
- Lead off https://twitter.com/LeadOffTeam/status/826599794659450881
- Mozair https://news.ycombinator.com/item?id=13539779
- Applicant https://news.ycombinator.com/item?id=13539729
- Scott Hanselman https://twitter.com/shanselman/status/826753118868275200
- Dave Long https://twitter.com/davejlong/status/826817435470815233
- Simon Slater https://twitter.com/skslater/status/826812158184980482
- Zaim M Ramlan https://twitter.com/zaimramlan/status/826803347764043777
- Aaron Suggs https://twitter.com/ktheory/status/826802484467396610
- danedevalcourt https://twitter.com/danedevalcourt/status/826791663943241728
- Karl https://twitter.com/irutsun/status/826786850186608640
- Zac Clay https://twitter.com/mebezac/status/826781796318707712
- Tim Roberts https://twitter.com/cirsca/status/826781142581927936
- Frans Bouma https://twitter.com/FransBouma/status/826766417332727809
- Roshan Chhetri https://twitter.com/sai_roshan/status/826764344637616128
- Samuel Boswell https://twitter.com/sboswell/status/826760159758262273
- Matt Brunt https://twitter.com/Brunty/status/826755797933756416
- Isham Mohamed https://twitter.com/Isham_M_Iqbal/status/826755614013485056
- Adriå Galin https://twitter.com/adriagalin/status/826754540955377665
- Jonathan Burke https://twitter.com/imprecision/status/826749556566134784
- Christo https://twitter.com/xho/status/826748578240544768
- Linux Australia https://twitter.com/linuxaustralia/status/826741475731976192
- Emma Jane https://twitter.com/emmajanehw/status/826737286725455872
- Rafael Dohms https://twitter.com/rdohms/status/826719718539194368
- Mike San Romån https://twitter.com/msanromanv/status/826710492169269248
- Jono Walker https://twitter.com/WalkerJono/status/826705353265983488
- Tom Penrose https://twitter.com/TomPenrose/status/826704616402333697
- Jon Wincus https://twitter.com/jonwincus/status/826683164676521985
- Bill Weiss https://twitter.com/BillWeiss/status/826673719460274176
- Alberto Grespan https://twitter.com/albertogg/status/826662465400340481
- Wicket https://twitter.com/matthewtrask/status/826650119042957312
- Jesse Dearing https://twitter.com/JesseDearing/status/826647439587188736
- Franco Gilio https://twitter.com/fgili0/status/826642668994326528
- Adam DeConinck https://twitter.com/ajdecon/status/826633522735505408
- Luciano Facchinelli https://twitter.com/sys0wned/status/826628970150035456
- Miguel Di Ciurcio F. https://twitter.com/mciurcio/status/826628765820321792
- ceej https://twitter.com/ceejbot/status/826617667884769280
Stephen Frost
- https://twitter.com/net_snow/status/826622954964393984 @gitlabstatus Привет, я разработчик PG, и мне нравится то, что вы делаете. Сообщите, если я могу чем-то помочь, я был бы рад оказаться полезен.
Sam McLeod
- Привет, Сид, очень жаль, что у вас проблемы с базой данных / LVM, это чертовски неприятно. У нас работает несколько кластеров PostgreSQL (master/slave), и я обратил внимание на несколько вещей в вашем отчете:
- Вы используете Slony, а это еще тот кусок сами знаете чего, и это совсем не преувеличение, тут вот даже смеются над ним http://howfuckedismydatabase.com, при этом встроенный бинарник PostgreSQL, отвечающий за потоковую репликацию, очень надежен и быстр, предлагаю переключиться на него.
- Не упоминается использование пулов соединений, зато говорится о тысячах соединений в postgresql.conf — это очень плохо и неэффективно с точки зрения производительности, предлагаю использовать pg_bouncer и не выставлять max_connection в PostgreSQL выше 512-1024; практически, если у вас больше 256 активных соединений, надо масшабироваться горизонтально, а не вертикально.
- В отчете говорится, насколько ненадежны ваши процессы отработки отказа и резервного копирования, мы написали и задокументировали простой скрипт для postgresql failover — если хотите, я его вам перешлю. Что касается бэкапов, то для инкрементных резервных копий в течение дня мы используем pgbarman, а также делаем полные бэкапы дважды в день с помощью barman и pg_dump, важно с точки зрения производительности и надежности хранить ваши бэкапы и директорию с данными postgresql на разных дисках.
- Вы все еще в Azure?!?! Я бы предложил оттуда как можно быстрее съехать, так как там немало странных проблем с внутренним DNS, NTP, маршрутизацией и хранилищами, также я слышал несколько пугающих историй о том, как там все устроено внутри.
Длинная переписка Сида и Сэма с упором в настройку PostgreSQL- Сообщите, если вам нужна помощь по настройке PostgreSQL, у меня в этом вопросе приличный опыт.
- Capt. McLeod: еще вопрос: сколько места на диске занимает ваша база (базы)? Речь идет о терабайтах или это все еще гигабайты?
- Capt. McLeod: выложил свой скрипт отработки отказа / репликации:
- Я также вижу, что вы смотрите на pgpool — я бы предложил pgbouncer взамен
- Capt. McLeod: У pgpool предостаточно проблем, мы его хорошенько протестировали и выкинули.
- Capt. McLeod: Также дайте мне знать, если я могу сказать что-то публично через твиттер или как-то еще в поддержку GitLab и вашей прозрачности в работе над этой проблемой, я знаю, как это тяжело; когда я только начинал, у нас был split-brain на уровне SAN в infoxchange, и меня в буквальном смысле рвало — настолько сильно я нервничал!
- Sid Sijbrandij: Привет, Сэм, спасибо за помощь. Ты не против, если я скопирую это в публичный документ, чтобы это могли остальные члены команды?
- Capt. McLeod: Скрипт отработки отказа?
- Sid Sijbrandij: Все, что ты написал.
- Конечно, в любом случае это публичный репозиторий, но он не идеален, очень далек от этого, но хорошо делает свою работу, я постоянно путаю хосты безо всяких последствий, но у вас все может быть по-другому.
- Да, конечно, ты можешь переслать и мои рекомендации.
Если ты сможешь прислать мне информацию о своей VM, на которой запущен PostgreSQL и свой PostgreSQL.conf, я дам рекомендации по его улучшению.
Sid: мы использовали Slony только для обновления с 9.2 до 9.6, в остальных случаях у нас работает потоковая репликация.
Комментарий: ОК, это хорошо, для информации: в рамках мажорных версий PostgreSQL для выполнения обновлений можно использовать встроенную репликацию.
- Rails уже создает пулы соединений (25 на процесс). При 20 процессах на 20 хостах получается где-то 10 000 соединений, при этом будет около 400 активных (поскольку Unicorn — это однопоточное приложение).
Комментарий: Каждое PostgreSQL-соединение использует память, держать сразу много открытых соединений неэффективно; здесь может помочь pg_bouncer — фантастически простой и быстрый инструмент по созданию пулов соединений. Он делает только одну вещь, но делает ее хорошо, тогда как pgpool все усложняет. Он может переписывать запросы, некоторые из которых начинают работать не так, как ожидалось. Pgpool не создан для использования совместно с ORM/db-фреймворками.
Стоит почитать: https://wiki.postgresql.org/wiki/Number_Of_Database_Connections
- Для балансировки нагрузки, создания пулов соединений, качественной отработки отказов и т. д. мы смотрим на pgpool + потоковая репликация с синхронными коммитами (для согласованности данных). Pgbouncer, насколько мы знаем, не балансирует нагрузку (по крайней мере, из коробки). Вот это https://github.com/awslabs/pgbouncer-rr-patch стоит рассмотреть в качестве одного из вариантов.
Вопрос: Используете ли вы в настоящее время несколько active/active PostgreSQL-нод, и если нет, то как выполняете балансировку нагрузки?
Вопрос: Какова ежедневная нагрузка на сайт? Сколько загрузок страниц и запросов в секунду?
* По всей вероятности, секция с вопросами от Сэма, ответами команды GitLab.com и итоговыми рекомендациями будет еще некоторое время пополняться и к самому инциденту прямого отношения уже не имеет. Мы пока не стали включать ее в перевод, так как оригинал еще не стабилизировался.
Заключение
Что показательно, ребята из GitLab сумели превратить свою грубейшую ошибку в поучительную историю и, думаю, не только не потерять, но и завоевать уважение многих айтишников. Также за счет открытости, написав о проблеме в Twitter и выложив лог в Google Docs, они очень быстро получили квалифицированную помощь со стороны, причем, похоже, совершенно безвозмездно.
Как всегда, радуют люди с хорошим чувством юмора: главный виновник инцидента теперь называет себя "Database (removal) specialist" (Специалист по [удалению] баз данных), какие-то шутники предложили 1 февраля сделать днем проверки бэкапов http://checkyourbackups.work/, а пользователи Хабра вспомнили чудесную тематическую картинку:
Какие можно сделать выводы?
- Нужно проверять бэкапы.
- Необходимо учитывать дополнительные трудности при восстановлении файлов в облаке (по крайней мере, в Azure).
- LVM — это не так уж и плохо, и его используют для размещения БД даже такие заметные компании, как GitLab.com, несмотря на потери в производительности.
- Не давать dev/stage/prod-серверам похожие названия.
- Делать интерфейсы dev/stage/prod-серверов отличающимися друг от друга по цвету/формату.
- Не бояться рассказать всему свету о своей ошибке — добрых людей больше, и они помогут.
- Помнить, что даже самое тяжелое поражение можно превратить в победу.
Ссылки по теме:
- Оригинал документа: GitLab.com Database Incident — 2017/01/31: https://docs.google.com/document/d/1GCK53YDcBWQveod9kfzW-VCxIABGiryG7_z_6jHdVik/pub
- Сообщение в блоге GitLab.com: https://about.gitlab.com/2017/02/01/gitlab-dot-com-database-incident/
- Первая статья на Хабре: https://habrahabr.ru/post/320988/