
Привет, Хабр! Меня зовут Денис, я – PHP-разработчик в Badoo, и сейчас я расскажу, как мы сами используем Pinba. Предполагается, что вы уже знаете, что это за инструмент, и у вас есть опыт его эксплуатации. Если нет, то для ознакомления рекомендую статью моего коллеги, Максима Матюхина.
Вообще на Хабре есть достаточно материалов об использовании Pinba в различных компаниях, включая пост Олега Ефимова в нашем блоге. Но все они касаются других компаний, а не Badoo, что немного нелогично: сами придумали инструмент, выложили в open source и не делимся опытом. Да, мы часто упоминаем Pinba в различных публикациях и в докладах на IT-конференциях, но обычно это выглядит как-то так: «А вот эти замечательные графики мы получили по данным из Pinba» или «Для измерения мы использовали Pinba», и всё.
Общение с коллегами из других компаний показало две вещи: во-первых, достаточно много людей используют Pinba, а во-вторых, часть из них не знают или не используют все возможности этого инструмента, а некоторые не до конца понимают его предназначение. Поэтому я постараюсь рассказать о тех нюансах, которые явно не указаны в документации, о новых возможностях и наиболее интересных кейсах применения Pinba в Badoo. Поехали!
Небольшое введение
В документации сказано, что «Pinba – это сервер статистики, использующий MySQL в качестве интерфейса...» Обратите внимание на понятие «интерфейс», использующееся не в значении хранилища данных, а именно в значении интерфейса. В первых версиях Pinba, автором которой был ещё Андрей Нигматулин, не было никакого MySQL-интерфейса, и для получения данных необходимо было использовать отдельный протокол. Что, естественно, неудобно.
Позднее Антон Довгаль tony2001 добавил этот функционал, чем значительно облегчил процесс получения данных. Стало возможным не писать никакие скрипты, достаточно любым MySQL-клиентом присоединиться к базе и простыми SQL-запросами получить всю информацию. Но при этом внутри себя Pinba хранит данные в своём внутреннем формате, и MySQL-движок используется только для отображения. Что это значит? А значит это то, что на самом деле никаких реальных таблиц не существует. «Ложки нет». Вы даже можете спокойно удалить одну из так называемых таблиц с «сырыми» данными, например, requests – и после этого все ваши отчёты по-прежнему будут работать.
Ведь сами данные никуда не исчезнут. Вы просто не сможете обращаться к этой таблице в SQL-запросах. Именно поэтому основной причиной использования именно отчётов (а не «сырых» таблиц) является то, что при сложных запросах (несколько JOIN и т. п.) Pinba должна «на лету» отфильтровать и сгруппировать все данные.
Я понимаю, что, зная SQL, можно легко из таблиц с «сырыми» данными получить все выборки, но это путь к тёмной стороне силы. Этот способ крайне ресурсозатратен. Конечно, все запросы будут работать, и зачастую, когда нужно срочно что-нибудь отдебажить, можно залезть в таблицу requests или tags. Но очень не рекомендую делать это без надобности только потому, что так проще и быстрее. Вся сила Pinba – в отчётах.
Создавать отчёты достаточно просто, но и тут существуют некоторые тонкости. Как я уже сказал, никаких таблиц не существует, и когда вы создаёте отчёт, то есть выполняете запрос CREATE TABLE, вы лишь сообщаете сервису о том, какие агрегации вам будут нужны. И пока не будет сделан первый запрос в эту «таблицу», никакие агрегации не будут собираться. Тут есть один важный нюанс: если вы начали собирать какие-то данные, а потом они уже не нужны, то «таблицу» с отчётом лучше удалить. Pinba не мониторит, перестали вы пользоваться отчётом или нет: один раз запросили данные – они будут собираться всегда.
Ещё один момент, который нужно учитывать при создании отчётов: для каждого типа отчёта есть свой набор полей. При отображении в MySQL Pinba ориентируется на порядок полей, а не на их названия, поэтому нельзя просто взять и поменять местами поля или не указать часть полей:
CREATE TABLE `tag_report_perf` (
`script_name` varchar(128) NOT NULL DEFAULT '',
`tag_value` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`hit_count` int(11) DEFAULT NULL,
`hit_per_sec` float DEFAULT NULL,
`timer_value` float DEFAULT NULL,
`timer_median` float DEFAULT NULL,
`ru_utime_value` float DEFAULT NULL,
`ru_stime_value` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
`p75` float DEFAULT NULL,
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL,
`p100` float DEFAULT NULL,
KEY `script_name` (`script_name`)
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tag_report:perf::75,95,99,100'В этом примере мы создаём отчёт типа tag_report; значит, первое поле всегда будет содержать название скрипта, за ним будет идти значение тега perf, затем – полный набор всех полей и в конце – нужные нам перцентили. Это тот случай, когда не надо фантазировать, а следует просто взять структуру таблицы из документации и скопировать её. Естественно, поля с названием тегов можно и даже нужно назвать более понятно, чем tag1_value, tag2_value, и порядок тегов и перцентилей в таблице должен совпадать с их порядком в описании.
Агрегации по тегам запроса (request’s tags)
Как вы знаете, у Pinba есть несколько типов отчётов, и относительно недавно (полтора года назад) мы добавили ещё отчёты по тегам запроса. До этого по тегам запроса (не путайте с тегами таймеров, это разные вещи) можно было только фильтровать, но никаких агрегаций не было.
Зачем нам потребовалась такой функционал? Один из основных типов контента в Badoo – фотографии. Нашим сервисом пользуются более 350 миллионов пользователей, у большинства из которых есть фотографии. Для отдачи фотографий у нас есть два типа машин: так называемые фотокеши – машины с «быстрыми» дисками, на которых лежат только активно запрашиваемые изображения, и основные “стороджи” — машины, где хранятся все фотографии.
Подробнее о системе хранения фотографий рассказывал на последнем HighLoad++ Артём Денисов. Если мы откажемся от кеширования и пустим весь трафик на «медленные» фотохранилища, то в лучшем случае сущеcтвенно увеличится время отдачи фото, в худшем – мы вообще не сможем с некоторых машин отдавать контент, и запросы будут отваливаться по тайм-ауту. Сейчас хитрейт у нас порядка 98%.
Казалось бы, всё очень хорошо, но падение хитрейта, скажем, до 96% сразу увеличивает нагрузку на кластер фотохранилища в два раза. Поэтому нам очень важно следить за хитрейтом и не допускать значительных падений. И мы решили делать это с помощью Pinba. Поскольку на машинах с фотокешами не используется PHP (весь контент отдаётся через веб-сервер), мы используем плагин Pinba к nginx.
Но вот незадача – внутри nginx мы не можем использовать таймеры и агрегацию по тегам таймера, но активно можем проставлять теги на сам запрос. Причём нам очень хотелось сделать разбивку по размеру изображений, по типу приложения и по ещё нескольким параметрам. У запроса может быть несколько тегов, и по всем нам нужно агрегировать. Для этой цели были созданы следующие типы отчётов:
rtag_info– агрегация по одному тегу,rtagN_info– агрегкация по нескольким тегам,rtag_report– агрегация по одному тегу и хосту,rtagN_report– агрегация по нескольким тегам и хосту.
Вот примеры отчётов:
CREATE TABLE `photoscache_report_hitrate` (
`hostname` varchar(64) NOT NULL DEFAULT '',
`tag1_value` varchar(64) DEFAULT NULL,
`tag2_value` varchar(64) DEFAULT NULL,
`tag3_value` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`req_time_total` float DEFAULT NULL,
`req_time_percent` float DEFAULT NULL,
`req_time_per_sec` float DEFAULT NULL,
`ru_utime_total` float DEFAULT NULL,
`ru_utime_percent` float DEFAULT NULL,
`ru_utime_per_sec` float DEFAULT NULL,
`ru_stime_total` float DEFAULT NULL,
`ru_stime_percent` float DEFAULT NULL,
`ru_stime_per_sec` float DEFAULT NULL,
`traffic_total` float DEFAULT NULL,
`traffic_percent` float DEFAULT NULL,
`traffic_per_sec` float DEFAULT NULL,
`memory_footprint_total` float DEFAULT NULL,
`memory_footprint_percent` float DEFAULT NULL,
`req_time_median` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
KEY `hostname` (`hostname`)
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='rtagN_report:served_by,build,img_size'
CREATE TABLE `photoscache_top_size` (
`geo` varchar(64) DEFAULT NULL,
`req_count` int(11) DEFAULT NULL,
`req_per_sec` float DEFAULT NULL,
`req_time_total` float DEFAULT NULL,
`req_time_percent` float DEFAULT NULL,
`req_time_per_sec` float DEFAULT NULL,
`ru_utime_total` float DEFAULT NULL,
`ru_utime_percent` float DEFAULT NULL,
`ru_utime_per_sec` float DEFAULT NULL,
`ru_stime_total` float DEFAULT NULL,
`ru_stime_percent` float DEFAULT NULL,
`ru_stime_per_sec` float DEFAULT NULL,
`traffic_total` float DEFAULT NULL,
`traffic_percent` float DEFAULT NULL,
`traffic_per_sec` float DEFAULT NULL,
`memory_footprint_total` float DEFAULT NULL,
`memory_footprint_percent` float DEFAULT NULL,
`req_time_median` float DEFAULT NULL,
`index_value` varchar(256) DEFAULT NULL,
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='rtag_info:geo:tag.img_size=top:95,99'(да в последнем отчёте мы агрегируем по тегу geo и фильтруем по тегу img_size).
В конфигурационных файлах nginx устанавливаем нужные теги:
location ~ '.....' {
...
pinba_tag fit_size '500x500';
pinba_tag is_fit 1;
pinba_tag img_size '920';
…– и в итоге можем получить вот такие графики хитрейта:
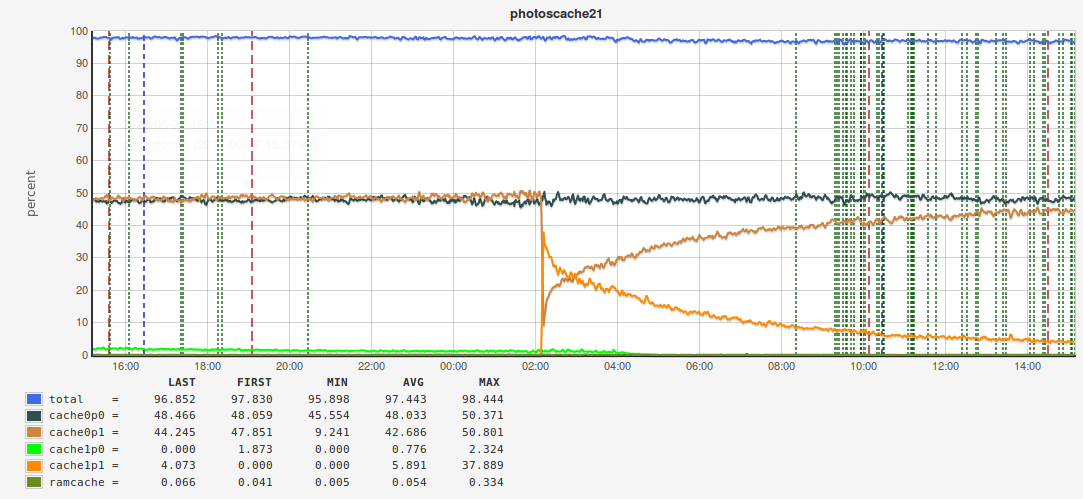
Мы плавно перешли к примерам использования. Я не буду заострять внимание на достаточно тривиальных примерах – просто перечислю некоторые основные вещи, которые мы мониторим с помощью Pinba:
- количество и время запросов на PHP-кластеры;
- потребление памяти PHP-скриптами;
- время запроса ко всем внешним сервисам (демоны на C, Go, Memcached, MySQL и т. п.);
- с помощью nginx-плагина мониторим количество запросов в секунду и время каждого запроса к nginx с разбиением по статус ответа;
- и другие.
Мониторинг очередей
Практически в каждом более-менее серьёзном проекте рано или поздно возникает задача обработки очереди событий. Определённые действия пользователя на сайте инициируют отправку события, на которое может быть подписано несколько обработчиков, и для каждого из них есть своя очередь. У нас этот процесс разделён на три части:
- транспорт – события со всех хостов собираются и отправляются на машину, где работает скрипт-клонировщик, который клонирует события в очередь для каждого подписчика;
- очередь: событие лежит в очереди (мы для очередей используем как MySQL, так и другие брокеры, например, Darner);
- процессинг: событие дошло до подписчика и начинает обрабатываться.
В какой-то момент нам захотелось измерить, сколько времени проходит с момента генерации события до его обработки. Проблема в том, что это уже не какой-то один PHP-скрипт, а несколько различных скриптов (в общем случае даже не PHP): в одном событие бросается, в другом – происходит отправка события в очередь обработчику, наконец, сам скрипт-обработчик, который получает событие из очереди. Как же быть? На самом деле, всё очень просто. В момент генерации события мы фиксируем время и записываем его в данные события и далее на каждом этапе запоминаем разницу между временем отправки и текущим временем. В итоге в самом конце, когда событие обработано, у нас есть все нужные значения таймеров, которые мы отправляем в Pinba. В результате мы можем сделать вот такой отчёт:
CREATE TABLE `tag_info_measure_cpq_consumer` (
`type` varchar(64) DEFAULT NULL,
`consumer` varchar(64) DEFAULT NULL,
`timer` varchar(64) DEFAULT NULL,
....
) ENGINE=PINBA DEFAULT CHARSET=latin1 COMMENT='tagN_info:type,consumer,timer'где timer – это название таймера для определённого этапа обработки события, consumer – название подписчика, type – в нашем случае это тип отправки события (внутри одной площадки или межплощадочный (у нас две площадки с одинаковой инфраструктурой – в Европе и в США, и события могут отправляться с площадки на площадку).
С помощью этого отчёта мы получили вот такие графики:

В этом примере рассматривается событие обновления данных о координатах пользователя. Как видно, весь процесс занимает меньше пяти секунд. Это значит, что, когда вы пришли в любимый бар, открыли приложение Badoo и попробовали найти пользователей рядом, вам действительно покажут тех, кто сейчас находится в этом месте, а не в том, где вы были полчаса назад (естественно, если ваше мобильное устройство отправляет данные о вашем местоположении).
Такой принцип (собрать все таймеры, а потом отправить их в Pinba) используется в Jinba. Jinba – это наш проект для измерения производительности клиентской части, в основе которого лежит Pinba; расшифровывается как JavaScript is not a bottleneck anymore. Подробнее о Jinba можно узнать из доклада Павла Довбуша и на сайте проекта.
Мы собираем все таймеры на клиенте и потом одним запросом отправляем их на PHP-скрипт, который уже отсылает всё в Pinba. Помимо стандартных типов отчётов, в Jinba мы активно используем гистограммы. Я не буду подробно рассказывать про них – скажу только, что благодаря функционалу гистограмм мы имеем возможность в отчётах указывать перцентили.
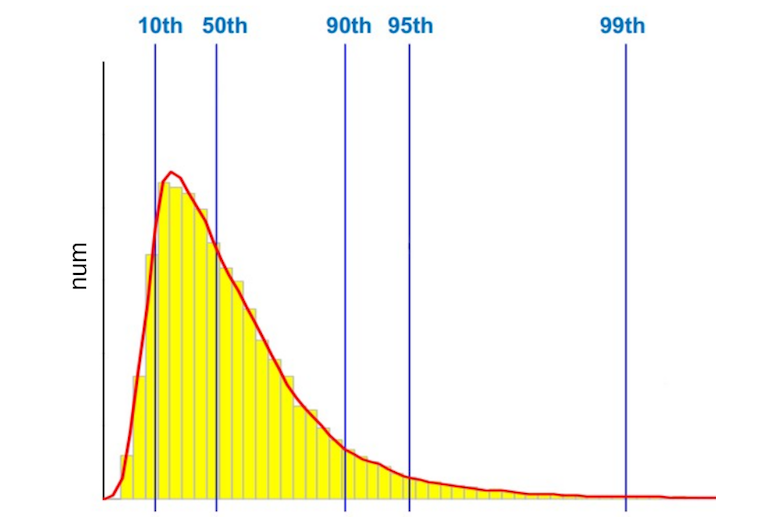
По умолчанию Pinba делит весь временной интервал, в который попадали запросы, на 512 сегментов, и в гистограмме мы сохраняем количество запросов, попавших в тот или иной сегмент. Я уже говорил, что мы измеряем время работы PHP-скриптов, время ответа nginx, время обращения к внешним сервисам и т. п. Но какое время мы измеряем? Например, в секунду было 1000 запросов на какой-то скрипт, соответственно, мы имеем 1000 различных значений. Какое из них нужно отобразить на графике? Большинство скажут: «Среднее арифметическое», – кто-то скажет, что нужно смотреть, сколько выполняются самые медленные запросы. Оставим этот вопрос за рамками этого поста. Для тех, кто не знает, что такое перцентиль, приведу простейший пример: 50-й перцентиль (или медиана) – это такое значение, когда 50% запросов выполняются за время, не превышающее данное значение.
Мы всегда измеряем среднее арифметическое и старшие перцентили: 95-й, 99-й и даже 100-й (самое высокое время выполнения запроса). Почему нам так важны старшие перцентили? Вот пример графика с ответами одного из наших внешних сервисов:
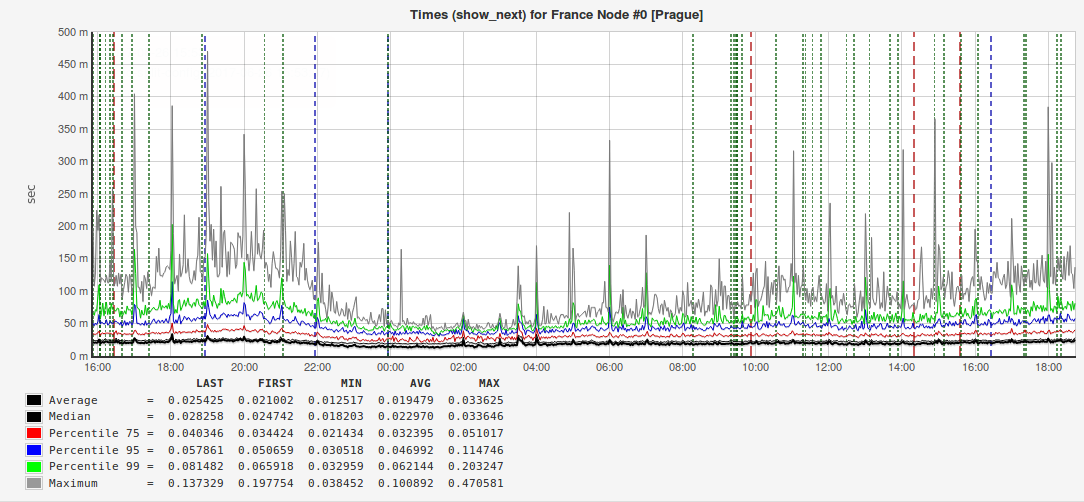
Из рисунка видно, что и среднее арифметическое, и медиана (50-й перцентиль) примерно в два раза меньше, чем 95-й перцентиль. То есть, когда вы будете делать отчёт для руководства или выступать на конференции, то выгодно будет показать именно это время запроса, но если хочется сделать пользователей счастливее, то правильнее будет обратить внимание на 5% медленных запросов. Бывают случаи, когда значение 95-го перцентиля почти на порядок превышает среднее, а это значит, что где-то есть проблема, которую нужно найти и устранить.
MySQL is not a bottleneck anymore
Поскольку мы мониторим запросы ко всем внешним сервисам, то, естественно, мы не можем обойти стороной запросы к базе данных. Мы в Badoo используем MySQL. Когда у нас возникла задача её мониторинга, сначала мы решили использовать Slowlog + Zabbix. Но это оказалось очень неудобно. Slowlog может быть очень большой, и зачастую найти в нём причину возникшей проблемы довольно сложно, особенно когда это нужно сделать быстро. Поэтому мы стали рассматривать коммерческие решения.
На первый взгляд, всё было прекрасно, но смущало то, что триальная версия работала только на ограниченном количестве серверов (на порядок меньшем, чем у нас на одной площадке), и был риск, что на всём кластере решение может на заработать.
Одновременно с тестированием коммерческого решения наши DBA (кстати, у нас их всего два: основной и резервный, или мастер и слейв) сделали собственную разработку. Они использовали performance_schema, скрипты на Python, всё это отправляли в Elastic, а для отчётов использовали Kibana. И, как ни странно, всё работало, но, чтобы сделать мониторинг всего нашего кластера MySQL, потребовался бы сравнимый по мощности кластер Elasticsearch.
К сожалению, даже в Badoo нельзя по щелчку пальцев получить сотню лишних машин для кластера. И тут мы вспомнили про Pinba. Но возник следующий нюанс: как в Pinba сохранять информацию об SQL-запросе? Более того, нужно сохранять информацию не о конкретном запросе, а о «шаблоне» запроса, то есть, если у вас есть 1000 запросов вида Select * from table where field = field_value, и в каждом из них значение поля field_value разное, то нужно в Pinba сохранять данные о шаблоне Select * from table where field = #placeholder#. Для этого мы провели рефакторинг всего кода и везде, где в SQL прямо в коде подставлялись значения полей, мы проставили плейсхолдеры. Но всё равно шаблон запроса может быть слишком большой, поэтому от каждого шаблона мы берём хеш и именно его значение идёт в Pinba. Соответственно, в отдельной таблице мы храним связки «хеш – текст шаблона». В Pinba был создан вот такой отчёт:
CREATE TABLE `minba_query_details` (
`tag_value` varchar(64) DEFAULT NULL,
...
`p95` float DEFAULT NULL,
`p99` float DEFAULT NULL
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tag_info:query::95,99'В PHP-коде мы формируем для каждого запроса такой массив тегов:
$tags = [
‘query’ => $query_hash,
‘dest_host’ => ‘dbs1.mlan’,
‘src_host’ => ‘www1.mlan’,
‘dest_cluster’ => ‘dbs.mlan’,
‘sql_op’ => ‘select’,
‘script_name’ => ‘demoScript.php’,
];Естественно, в коде должно быть одно место, где выполняется запрос к БД, некий класс-обёртка; напрямую вызывать методы mysql_query или mysqli_query, конечно, нельзя.
В том месте, где выполняется запрос, мы считаем время запроса и отправляем данные в Pinba.
$config = [‘host’ => ‘pinbamysql.mlan’, ‘pinba_port’ => 30002];
$PinbaClient = new \PinbaClient($config);
$timer_value = /*Execute query and get execution time */
$PinbaClient→addTimer($tags, $timer_value);
/* Some logic */
$PinbaClient->send();Обратите внимание на использование класса \PinbaClient. Если вы собрали PHP с поддержкой Pinba, то у вас будет этот класс «из коробки» (если используется не PHP, то для других языков есть свои аналоги этого класса). Понятно, что запросов к БД будет очень много, и писать в тот же сервер Pinba, куда собирается статистика по скриптам, не получится. Хомячка разорвет. В настройках php.ini можно указать только один хост Pinba, куда будут отправляться данные по завершении работы скрипта. И тут нам на помощь и приходит класс \PinbaClient. Он позволяет указать произвольный хост с Pinba и отправлять туда значения таймеров. Кстати, для мониторинга очередей у нас тоже используется отдельный сервер Pinba. Поскольку данные в Pinba хранятся ограниченное количество времени, то и в таблице со связкой «хеш – SQL-шаблон» хранятся лишь актуальные хеши.
Запросов действительно много, поэтому мы решили отправлять в Pinba каждый второй. Это примерно сто пятьдесят тысяч запросов в секунду. И всё работает. В любой момент мы можем посмотреть, какие запросы на каких хостах тормозят, какие запросы появились, каких запросов выполняется очень много. И эти отчёты доступны каждому сотруднику.
Ещё один нетривиальный кейс использования Pinba – мониторинг хитрейта мемкеша. На каждой площадке у нас есть кластер машин с Memcached, и необходимо было понять, эффективно ли мы используем мемкеш. Проблема в том, что у нас очень много различных ключей, и объём данных для каждого из них варьируется от нескольких байт до сотен килобайт. Мемкеш разбивает всю предоставленную ему память на страницы, которые затем распределяются по слабам (slabs). Слаб – это фиксированный объём памяти, выделяемый под один ключ. Например, третий слаб имеет размер 152 байта, а четвёртый – 192 байта. Это значит, что все ключи с данными от 152 до 192 байт будут лежать в четвёртом слабе. Под каждый слаб выделяется определённое количество страниц, каждая делится на кусочки (chunks), равные размеру слаба. Соответственно, может возникнуть ситуация, когда некоторым слабам выделяется больше страниц, чем нужно, и хитрейт по этим ключам достаточно высокий, а по другим ключам хитрейт может быть очень низкий, при этом у мемкеша достаточно свободной памяти. Чтобы этого не произошло, нужно перераспределять страницы между слабами. Соответственно, нам нужно знать хитрейт каждого ключа в данный момент времени, и для этого мы тоже используем Pinba.
В данном случае мы поступили аналогично мониторингу запросов к MySQL – сделали рефакторинг и привели все ключи к виду “key_family”:%s_%s, то есть выделили неизменяемую часть (семейство ключа) и отделили её двоеточием от изменяемых частей, например, messages_cnt:13589 (количество сообщений у пользователя с идентификатором 13589) или personal_messages_cnt:13589_4569 (количество сообщений от пользователя 13589 пользователю 4569).
В том месте, где происходит чтение данных по ключу, мы формируем следующий массив тегов:
$tags = [
‘key’ =>’uc’,
‘cluster’ => ‘wwwbma’,
‘hit’ => 1,
‘mchost’ => ‘memcache1.mlan’,
‘cmd’ => ‘get’,
];где key – семейство ключа, cluster – кластер машин, с которого идёт запрос в мемкеш, hit – есть данные в кеше или нет, mchost – хост с мемкешем, cmd – команда, отправляемая в мемкеш.
А в Pinba создан вот такой отчёт:
tag_info_key_hit_mchost | CREATE TABLE `tag_info_key_hit_mchost` (
`key` varchar(190) DEFAULT NULL,
`hit` tinyint(1) DEFAULT NULL,
`mchost` varchar(40) DEFAULT NULL,
...
) ENGINE=PINBA DEFAULT CHARSET=latin1
COMMENT='tagN_info:key,hit,mchost',благодаря которому мы смогли построить вот такие графики:
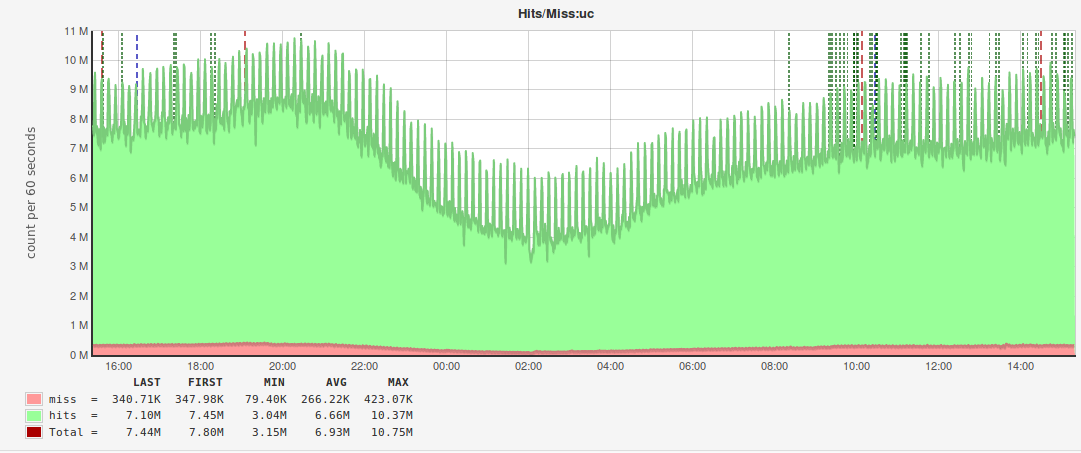
По аналогии с мониторингом MySQL под эти отчёты используется отдельный инстанс Pinba.
Шардинг
C ростом количества пользователей и развитием функционала мы столкнулись с ситуацией, когда на самом высоконагруженном PHP-кластере, куда приходят запросы с мобильных устройств, Pinba перестала справляться. Решение мы нашли очень простое – поднять несколько сервисов Pinba и «раунд робином» отправлять данные в произвольный. Сложность тут одна – как потом собирать данные? При сборе данных мы создали для каждого типа поля своё правило «слияния». Например, количество запросов суммируются, а для значений перцентилей всегда берётся максимальное и т. п.
Резюме
Во-первых, помните, что Pinba – это не хранилище данных. Pinba вообще не про хранение, а про агрегации, поэтому в большинстве случаев достаточно выбрать нужный тип отчёта, указать набор перцентилей – и вы получите нужную выборку в режиме реального времени.
Во-вторых, не используйте без необходимости таблицы с «сырыми» данными, даже если у вас всё работает и ничего не тормозит.
В-третьих, не бойтесь экспериментировать. Как показывает практика, с помощью Pinba можно решать широкий круг задач.
P. S. В следующий раз я постараюсь рассказать вам о граблях, на которые мы наступали во время работы с Pinba, и о том, какие проблемы могут возникнуть. И на этот раз я не ограничусь примерами из PHP.
