 Бывает меня спрашивают — как я пишу эмуляторы? Попробую ответить на примере одной провалившейся консоли.
Бывает меня спрашивают — как я пишу эмуляторы? Попробую ответить на примере одной провалившейся консоли.Эмуляция — почти бесконечное занятие, всегда остаются неточности, и если меня спросят сколько я потратил на эмуляцию 3DO, то я лишь пожму плечами, но одно знаю точно — с эмуляцией 3DO все очень хорошо. Поэтому пришло время найти новую жертву и ей оказался Atari Jaguar. 1000 часов — примерно столько я потратил на разработку ядра эмуляции данной консоли в проекте «Феникс», и вероятно еще столько же понадобится, чтобы поднять совместимость с текущих 95% до 99%, а оставшийся 1% потребует еще, возможно не одну тысячу часов, но это уже отдельные скучные истории про отладку едва уловимых глюков.

Почему именно Ягуар? Во-первых, он плохо эмулировался существующими эмуляторами. Во-вторых, он хорошо «задокументирован», есть спецификации, принципиальные схемы и даже HDL-коды его чипов!
Первый этап — сбор информации о противнике (300 часов)
На изображении ниже приведен упрощенный план действий по сбору первичной информации, необходимой для создания эмулятора вашей любимой игровой приставки.

Данный этап как вы видите далеко не всегда ограничивается словом «погуглить», это полноценный и наиболее важный этап разработки, это целое исследование. Что же касается «погуглить», то в первую очередь рекомендую провести поиск патентов на подсистемы консоли, даташитов по маркировкам чипов и просто почитать информацию на связанных с технической стороной консоли ресурсах. Далее уже исходя из найденного сосредоточиться на сборе данных согласно плану.
Кто-то справедливо заметит, что есть еще один источник знаний — чужие проекты. Если вы хотите присоединиться к проекту, тогда это правильная мысль, но если нет, то я не рекомендую опираться на подобный источник информации, хотя бы до собственного релиза, чтобы не повторять чужие ошибки. В случае Ягуара есть проект Virtual Jaguar, я помню хотел улучшить его, но быстро отбросил эту идею, как только увидел сам код.
Извлечение схемы — задача, которую обязательно стоит сделать в первую очередь, поскольку из нее можно подчерпнуть полезную информацию о режимах работы элементов, шинах и назначении хотя бы части выводов у чипов, для которых вам не удалось найти документацию. Если есть возможность — можно сделать компьютерную томографию печатной платы, но у старых консолей обычно два слоя и вполне хватает простого мультиметра, чтобы составить принципиальную схему путем прозвонки.
Поиск программного обеспечения для эмулируемой платформы охватывает как само эмулируемое в дальнейшем ПО (дампы — BIOS, ROM, ISO), так и средства разработки для данной платформы. Последние особенно важны для создания тестов, которые будут служить для выявления внутренней структуры элементной базы, кроме того, результаты этих же тестов могут послужить в дальнейшем и для проверки будущего эмулятора на соответствие реальному железу. Довольно часто оригинальные SDK не совместимы с современными ОС, поэтому возможно вам придется адаптировать эти SDK под современные компиляторы или даже использовать эмуляторы старых ПК для написания тестов. Если со средствами разработки совсем плохо, имеет смысл написать свой ассемблер или даже простенький компилятор. Поверьте, подготовка средств разработки, многократно окупится в дальнейшем, поможет сэкономить кучу времени.
Что касается дампов, если они не сделаны кем-то ранее, то для получения ПЗУ, наиболее простой способ — это выпаять чип и считать его содержимое в программаторе, более сложный, но аккуратный — найти способ подключения консоли к компьютеру — через отладочный интерфейс или какой-то порт расширения и написать специальную программу для обмена данными с ПК. Например, на 3DO я подключался к JTAG ARM-процессора и делал дамп ПЗУ, еще я подключался к фабричному порту отладки консоли и запускал на ней свой код, для этого пришлось смастерить небольшое устройство с контроллером и ПЛИС.
Определение элементной базы — важнейшая из задач данного этапа. Если вам удалось найти достаточно подробную документацию по всем компонентам, то все замечательно и можно приступать к созданию эмулятора, но что если среди основных компонентов вам попались самые настоящие черные ящики? Тут есть несколько вариантов. Можно действовать в лоб (если позволяют навыки, время и деньги) — это вскрыть чип, иначе говоря — отснять весь чип на микроскопе и восстановить схему устройства. Я таким никогда не занимался, но это беспроигрышное решение, при условии, что у вас хватит терпения или таланта автоматизировать обработку полученной таким образом информации.
В зависимости от топологии можно применять или совмещать внутрисхемное и внесхемное тестирование черных ящиков. В обоих случаях не будет лишним анализатор цифровых сигналов и осциллограф. Внутрисхемное тестирование предпочтительней и быстрее, при данном подходе, вы пишете специальный код, который будет тестировать интересующее вас устройство внутри консоли. Допустим вы тестируете видеопроцессор, исходя из данных в SDK или других соображений, вы делаете различные варианты записи в регистры и анализируете результат на экране, фиксируете возникающие прерывания и задержки.
Иногда бывает сложно определить поведение компонента на основе внутрисхемных тестов, например, когда он не работает напрямую с центральным процессором. В таком случае разумно выполнить внесхемное тестирование, для этого вы делаете специальную печатную плату для подключения к ПК и пересаживаете на нее тестируемую микросхему, затем подаете сигналы на входы и считываете выходы, а дальше все зависит от ваших умственных способностей. Единственное — нужно точно знать где и какие входы и выходы у данной микросхемы, это частью можно выяснить по взаимной связи компонентов, а в особо тяжелых случаях путем разрезания дорожек (ножки поднимать не рекомендую — бывает ломаются). Если вы решили головоломку, то не будет лишним вернуть на место не саму микросхему, а прицепить ее эмуляцию на ПЛИС, чтобы окончательно убедиться в правильности своих выводов, это конечно процедура не из простых, но зато, если вы захотите сделать приставку на FPGA – у вас уже будет задел.
А что с Ягуаром? А с ним все очень здорово, как я и говорил, есть исходные HDL-коды его чипов, спецификации и принципиальные схемы. Конечно хотелось бы еще и рабочую приставку, но имея все перечисленное — можно с уверенностью сказать, что без оной можно вполне обойтись. Поэтому я сразу отнес документацию в типографию:
- Technical Reference Manual Tom&Jerry (это не герои известного мультфильма, а основные чипы консоли, кстати, сразу виден общий с 3DO стиль, в 3DO тоже два основных чипа с интересными названиями — Madam&Clio, и если я правильно помню — в 3DO ушла часть разработчиков из команды Atari);
- Motoroll M68000 Famaly Programmer's Reference Manual – документация по CPU приставки;
- Принципиальная схема приставки — очень важно понимать, что с чем и как взаимодействует, без нее приставка была бы все же необходима.
Разумеется это не вся документация, а лишь основная ее часть, пришлось так же поискать даташиты на всякие мелочи вроде EEPROM или кварца, мне правда за отсутствием живой консоли и картриджей пришлось найти их фотографии и по маркировкам электронных компонентов уже производить поиск.
А вот HDL-код оказался весьма крепким орешком. Он написан на мало кому известном HDL компании Toshiba, по отношению к современному Verilog или VHDL он словно ассемблер по отношению к С++, раскидан по сотне файлов и держать в голове интерконнект компонентов (по крайней мере для меня) не представляется возможным. Из этого кода мне нужно было сделать кхм… «книгу», ну что же — напишем транслятор! Код выложил на гитхаб (вдруг кому надо), но поскольку код нужен был для однократного применения — я решил взять пример с авторов Virtual Jaguar и сосредоточиться лишь на достижении приемлемого результата в кратчайшие сроки, иными словами — этот мой код очень плох для понимания.
HDL от Toshiba оказался весьма специфичным языком с нестрогим синтаксисом, например описание цепей в нем нестрогое, т.е. разрядность каждой цепи похоже раскрывается только после линковки всех модулей и сквозной декомпозиции, поэтому для определения разрядности и ширины цепей пришлось написать десятки эвристик. Но все еще оставались единичные случаи, когда разрядность цепи не получалось установить из контекста, тогда я делал предположение, что это цепь единичная (что оправдалось). Приведу простой пример:
/*2 input nand gate */
DEF ND2 (z:OUT; a,b:IN);
этот элемент может использоваться очень по разному:
//единичные цепи могут записываться так:
label := ND2 (z, a, b);
label := ND2 (z[2], a[0..1]); //a[0..1] – разделяется по входам
label := ND2 (z[2], a[0-1]); //эквивалентно предыдущему
label := ND2 (z[1], a{5}, b[2]); //{} - означает выборку из цепи для которой разрядность больше единицы
//с репликами все становится еще веселее:
label[0-4] := ND2 (z[0-4], a{9-13}, b); //здесь b размножается,
label[0-4] := ND2 (z[0-4], a{9-13}, b[9-13]); //один к одному
label[0..4] := ND2 (z[0..4], a{9..13}, b[9..13]); //эквивалентно предыдущему
label[0..4] := ND2 (z[0..4], a[0..4], b[0-7]); //здесь b размножается на пять 8-битных цепей
label[0-4] := ND2 (z[0-4], a[0-4], b[0..7]); //аналогично предыдущему
Весь этот зверинец усугубляется тем, что например цепь z, a или b не обязательно должна быть где-то объявлена, она считается объявленной при первом ее использовании, пучки цепей могут быть и с дырками, например: z[0..5] и z[10..12] – это нормально, что нет z[6..9], это конечно не важно для компиляции, когда все разбивается и оптимизируется на уровне отдельных сигналов для ПЛИС, но у нас другая задача — сохранить всю доступную структурную информацию, поэтому нас не интересует декомпозиция. Немного масла в огонь добавляет и тот факт, что это язык описания аппаратуры, а не обычный программный код, поэтому все его блоки исполняются параллельно и их порядок в коде совершенно не важен, отсюда транслятор должен анализировать связи в отдельном проходе.
По окончанию разработки лексического и синтаксического анализаторов, когда все цепи сошлись, пришло время сделать из кода своего рода книгу, иными словами транслировать его в более удобное представление. Для этого мне пришлось реализовать извлечение комментариев с привязкой их к блокам кода, а также вложение всех модулей друг в друга начиная с верхнего, при этом не всегда получалось сделать полный инлайн из-за конкатенации и декомпозиции цепей на уровне подключения блоков, поэтому в таких случаях приходилось включать и карту соединений, например:
R1count := R1COUNT(
count[0..5] = reghalf/*OUT*/ @ sysr1[0..4]/*OUT*/, /// counter
clk = clk[1]/*IN*/, /// system clock
cnten = sromold/*IN*/, /// counter enable
cntld = mmult/*IN*/, /// counter load
mr1[0..4] = preinstr'16'{5..9}/*IN*/, /// value to load
)
Когда все указанные механизмы были готовы, нужно было улучшить читабельность полученной «книги», например заменить ND2 (z, a, b) на z <= ~(a&b). Было проработано около сотни примитивов, удалены нефункциональные блоки и наконец, можно было приступать к самой эмуляции!
Что мы имеем? Систему из пяти процессоров (OB – обеспечивает подготовку и подачу данных на видео ЦАП, DSP – призван отвечать за звук, GPU – призван отвечать за построение графических сцен, Blitter – отвечает за заливку полигонов, m68k – управляет всем этим хозяйством), при чем все эти процессоры имеют общее пространство памяти и соответственно могут писать в регистры ввода-вывода друг друга практически без ограничений, иначе говоря оптимизировать этот бардак будет сложно.
Второй этап — создание виртуальной платформы (500 часов)
Проект «Феникс» изначально проектировался как мультиплатформенный эмулятор, это как раз тот случай, когда излишнее забегание вперед оказалось оправданным. Каждая платформа наследуется от класса базовой платформы и формируется путем создания и компоновки в древовидную структуру ее элементов, которые наследуются от базового класса устройств. Другими словами используются ООП возможности языка С++. Большинство эмуляторов написаны в стиле С, что по моему мнению изрядно осложняет процесс их развития. Базовые классы обеспечивают меня унифицированным доступом к фронтенду эмулятора, в том числе к отладчику.

В классе платформы я обычно реализую карту памяти консоли и соединяю все её компоненты. В классах устройств эмулируется их функционал и прописываются хранимые переменные и их формат для отладчика, а так же если устройство является процессором — реализуются функции дизассемблирования и отладки, делать это лучше сразу, поскольку даже при ошибочной реализации эмулируемых инструкций — отладчик сильно упрощает поиск ошибок.
Отдельно стоит упомянуть загрузчики дампов, их задача обеспечить проверку дампа на корректность и преобразование в формат используемый эмулятором, а также извлечение контрольных сумм независящих от формата хранения на диске. Контрольные суммы необходимы для двух вещей: однозначной связи с сохранениями игрового процесса и применения костылей для проблемных игр. Например, часть любительских разработок под Ягуар никогда не проверялась на реальном железе, и они работают на некоторых эмуляторах только потому, что они тестировались исключительно в этих эмуляторах, поэтому будьте осторожны при написании своего эмулятора, для таких игр приходится делать исключения, например отключать выравнивание записи или чтения.
Итак, реализовать эскиз платформы — дело одного вечера, дальше начинается главная работа…
Центральный процессор M68000
Наш центральный процессор — очень популярный в свое время M68000, на него очень хорошая документация и довольно много готовых эмуляторов, есть даже с подходящими лицензиями, не требующими открытия кода проекта. Но для меня каждый новый процессор написанный собственноручно — это как для коллекционера — новая уникальная вещица, поэтому чужого брать не будем — пишем свой — с блекджеком и … Кроме того, для успеха затеи нужно «понять» процессор, и нет ничего лучше, чем заэмулировать его самостоятельно.
Как вообще пишутся эмуляторы процессоров? В самом простом варианте, которого стоит придерживаться, они пишутся как обычные интерпретаторы. Вы читаете команду по адресу в PC (регистр — счетчик команд), определяете ее тип и выполняете действия над регистрами, которые она должна выполнять в реальном процессоре. Обработку прерываний можно реализовать в виде вызова делегатов, которые будут передаваться из внешних классов-устройств. Не стоит сразу делать всякие крутые оптимизации, потому что с ними код становится менее понятным, оптимизировать лучше в самом конце разработки, даже если пользователи закидывают вас помидорами из-за низкой производительности.
После того как создан интерпретатор команд и дизассемблер, имеет смысл протестировать получившийся процессор, и вот тут можно воспользоваться доступным опытом! Существует немало готовых тестов — их стоит обязательно погонять, чтобы найти ошибки в реализации инструкций. При наличии железа непременно стоит написать свои тесты, что я также сделал, правда для CD-i, в которой похожий процессор и большая часть инструкций совпадает. Тесты очень важны и в дальнейшем, допустим вы провели оптимизацию и нужно убедиться, что ничего не сломалось.
Blitter
Эта хитрая штука рисует полигоны в Ягуаре, точнее сканлайны полигонов, еще она умеет заливать четырехугольники и вращать их в плоскости экрана, делать затенение и работать с Z-буфером. Именно с этой части я начал, и к сожалению сделать для нее вменяемых тестов без железа было невозможно, но тут очень помогло наличие HDL-кода. По сути я сделал уже транслятор этого кода в некоторое подобие С, поэтому разбирая разные блоки, при необходимости я мог делать тесты для сопоставления своего кода и оригинального HDL кода. Например, код из моей HDL трансляции:
lowen <= width[4] | width[5];
ya[0] <= lowen ? 0 : {ytm[2],ytm[1],ytm[0],0}[width[2..3]];
ya[1] <= lowen ? 0 : {ytm[3],ytm[2],ytm[1],ytm[0]}[width[2..3]];
ya[2] <= width[5] ? 0 : {ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0,0}[width[2..4]];
ya[3] <= width[5] ? 0 : {ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0}[width[2..4]];
ya[4] <= width[5] ? 0 : {ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0}[width[2..4]];
ya[5] <= width[5] ? 0 : {ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0]}[width[2..4]];
ya[6] <= {ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0,0,0,0,0,0}[width[2..5]];
ya[7] <= {ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0,0,0,0,0}[width[2..5]];
ya[8] <= {ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0,0,0,0}[width[2..5]];
ya[9] <= {ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],ytm[0],0,0,0,0}[width[2..5]];
ya[10] <= {ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],ytm[1],0,0,0,0}[width[2..5]];
ya[11] <= {ytm[13],ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],ytm[2],0,0,0,0}[width[2..5]];
ya[12] <= {ytm[14],ytm[13],ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],ytm[3],0,0,0,0}[width[2..5]];
ya[13] <= {0,ytm[14],ytm[13],ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],ytm[4],0,0,0,0}[width[2..5]];
ya[14] <= {0,0,ytm[14],ytm[13],ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],ytm[5],0,0,0,0}[width[2..5]];
ya[15] <= {0,0,0,ytm[14],ytm[13],ytm[12],ytm[11],ytm[10],ytm[9],ytm[8],ytm[7],ytm[6],0,0,0,0}[width[2..5]];
/// bits 16-19 use MX8G enabled for shifts 4-11, the low four and
///high four must be swapped
mid8en\ <= ~(width[4] ^ width[5]);
ya[16] <= mid8en\ ? 0 : {ytm[10],ytm[9],ytm[8],ytm[7],ytm[14],ytm[13],ytm[12],ytm[11]}[width[2..4]];
ya[17] <= mid8en\ ? 0 : {ytm[11],ytm[10],ytm[9],ytm[8],0,ytm[14],ytm[13],ytm[12]}[width[2..4]];
ya[18] <= mid8en\ ? 0 : {ytm[12],ytm[11],ytm[10],ytm[9],0,0,ytm[14],ytm[13]}[width[2..4]];
ya[19] <= mid8en\ ? 0 : {ytm[13],ytm[12],ytm[11],ytm[10],0,0,0,ytm[14]}[width[2..4]];
tm4en\ <= ~(width\[4] & width[5]);
ya[20] <= tm4en\ ? 0 : {ytm[14],ytm[13],ytm[12],ytm[11]}[width[2..3]];
ya[21] <= tm4en\ ? 0 : {0,ytm[14],ytm[13],ytm[12]}[width[2..3]];
ya[22] <= tm4en\ ? 0 : {0,0,ytm[14],ytm[13]}[width[2..3]];
ya[23] <= ytm[14] & width[2] & width[3] & width\[4] & width[5];
А это рабочий эквивалент на С++:
int ya=0;
if(width<48)
{
if((width>>2)<2)ya=ytm>>(2-(width>>2));
else if((width>>2)>2)ya=ytm<<((width>>2)-2);
else ya=ytm;
ya&=0xffffff;
}
Сравнительные тесты позволили построить все компоненты Tom&Jerry с некоторой надеждой на работоспособность при первом запуске, которая разумеется не оправдалась, но тем не менее, число возможных ошибок было радикально уменьшено.
У меня часто спрашивают — можно ли для Ягуара сделать тоже самое, что я сделал для 3DO – аппаратный рендер с произвольным разрешением? Простой ответ «нет». Но если декомпилировать код GPU, тогда наверное можно для каждой игры индивидуально, причина этого в том, что блиттер рисует строками, а полигоны из строк формирует программа GPU, своя для каждой игры, и увы GPU это полноценный RISС-процессор с полным доступом к пространству памяти консоли, который не получится реализовать внутри шейдера.
Два весёлых друга GPU & DSP
Они реально весёлые — в них столько аппаратных ошибок! А еще они очень похожи и различаются лишь несколькими инструкциями. Поэтому где один процессор, там и другой. Здесь процесс шел веселее, поскольку я уже поднаторел на блиттере, да и часть HDL-блоков совпадала, поэтому работы стало поменьше.
Основной причиной самых неприятных аппаратных ошибок Ягуара был блок Scoreboard, который отвечает за своего рода суперскалярность, если вы посмотрите на него, то возможно вы поймете, почему я не стал пытаться его понять и отложил связанные с ним проблемы на этап отладки. Этот код похоже тяжело давался авторам консоли, и понять что там к чему — довольно сложно, хотя цель его предельно ясна, но повторить его ошибки можно только повторив его один в один, что конечно приведет к фатальному падению скорости эмуляции. Например, инструкция LOAD может переписать содержимое регистра назначения уже после исполнения следующей за ней инструкции, которая пишет в тот же самый регистр. И хотя основные чудеса описаны в документации, мне удалось найти и те, что не описаны. В общем гонка инструкций без правил — для Ягуара это нормально.
Когда имеешь дело с процессором — очень важно точно воспроизвести вычисление всех флагов арифметической подсистемы точнее, чем описано в документации, мне это удалось, что положительно повлияло на совместимость, но ценой существенного снижения производительности. Дело в том, что ALU и блок сдвига в данных процессорах всегда формируют флаги, т.е. для инструкций с неопределенным состоянием флага (согласно мануалам) нужно, чтобы отработали подсистемы результат от которых не используется, кроме как для формирования флага. Два процессора с частотой 26+МГц с одной инструкцией за такт и подобным оверхедом — это довольно сильно бьет по производительности — но совместимость превыше всего!
Объектный процессор (OB)
Этот фрукт очень необычный, он не только рисует скан-линии для ЦАП, но и может масштабировать спрайты и писать их в эти линии, а еще он может запускать GPU, который в свою очередь частенько запускает Blitter, который может переписывать программу GPU, который в свою очередь должен послать прерывание объектному процессору, который должен продолжить рисовать линии и запускать GPU… В общем удержать систему в когерентном состоянии и обеспечить нормальную производительность эмулятора при таком раскладе — та еще задачка.
В этом блоке был пожалуй наиболее сложный автомат состояний, между прочим рекомендую зарисовывать подобные вещи — очень помогает. По крайней мере сотни строк насыщенного кода становятся намного наглядней.
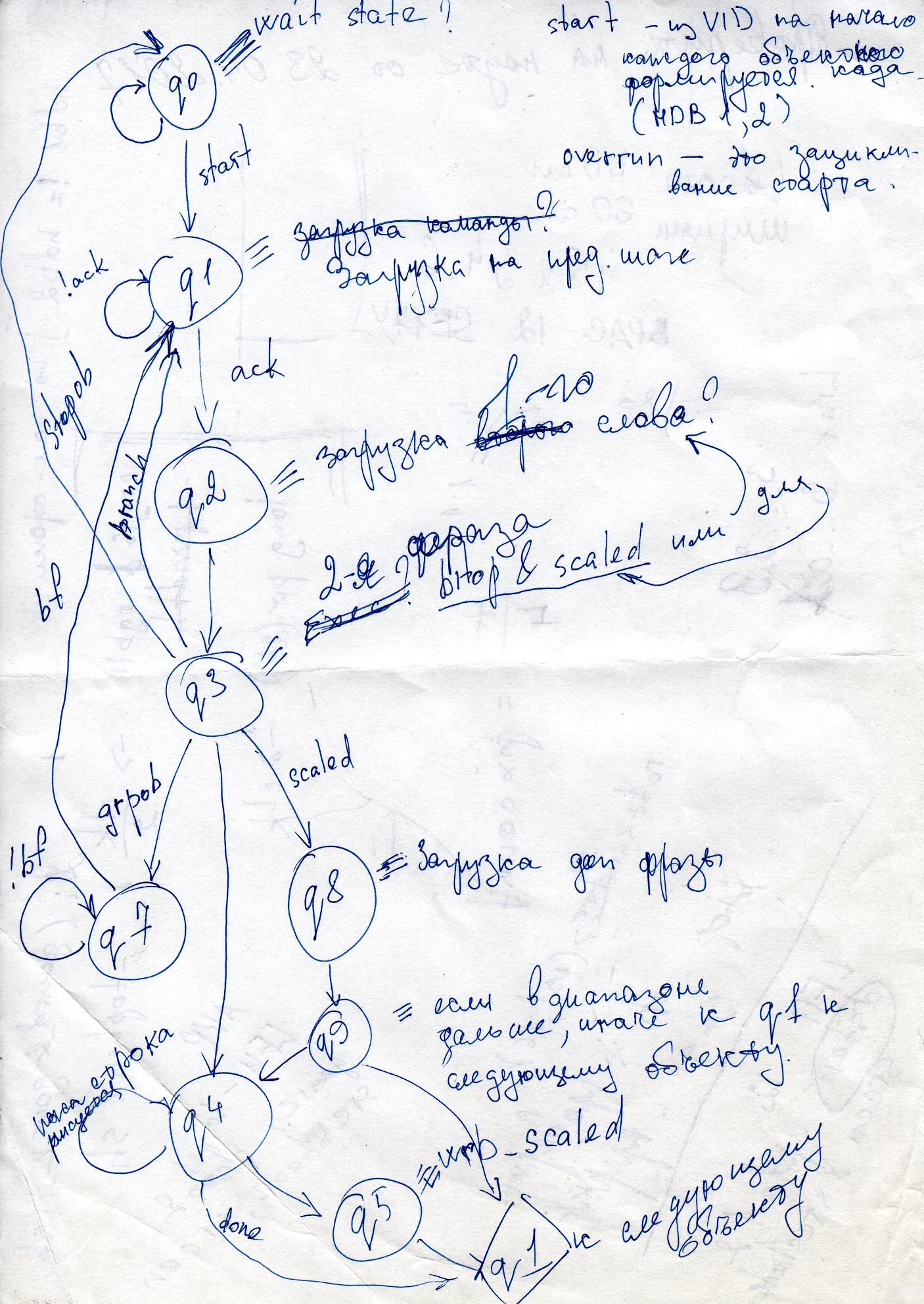
Вообще я целую пачку бумаги потратил на наброски восстанавливаемых алгоритмов, и пару тетрадей на заметки, планы и списки гипотез. Как говорится — плохой карандаш лучше хорошей памяти (в том числе компьютерной).
Третий этап — охота на жуков (200 часов)
Итак, все блоки готовы и собраны, но по закону Мерфи, не хотят работать. Как морально не готовься к этому, все равно неприятно наблюдать черный или испещренный артефактами экран. Но, если вы не поленились написать удобный отладчик, то вы очень скоро увидите, что основная масса ошибок будет проявляться на первых же инструкциях. Если же не написали, вы можете конечно отлаживаться через отладчик среды разработки и printf, но поверьте мне — написать отладчик намного проще.
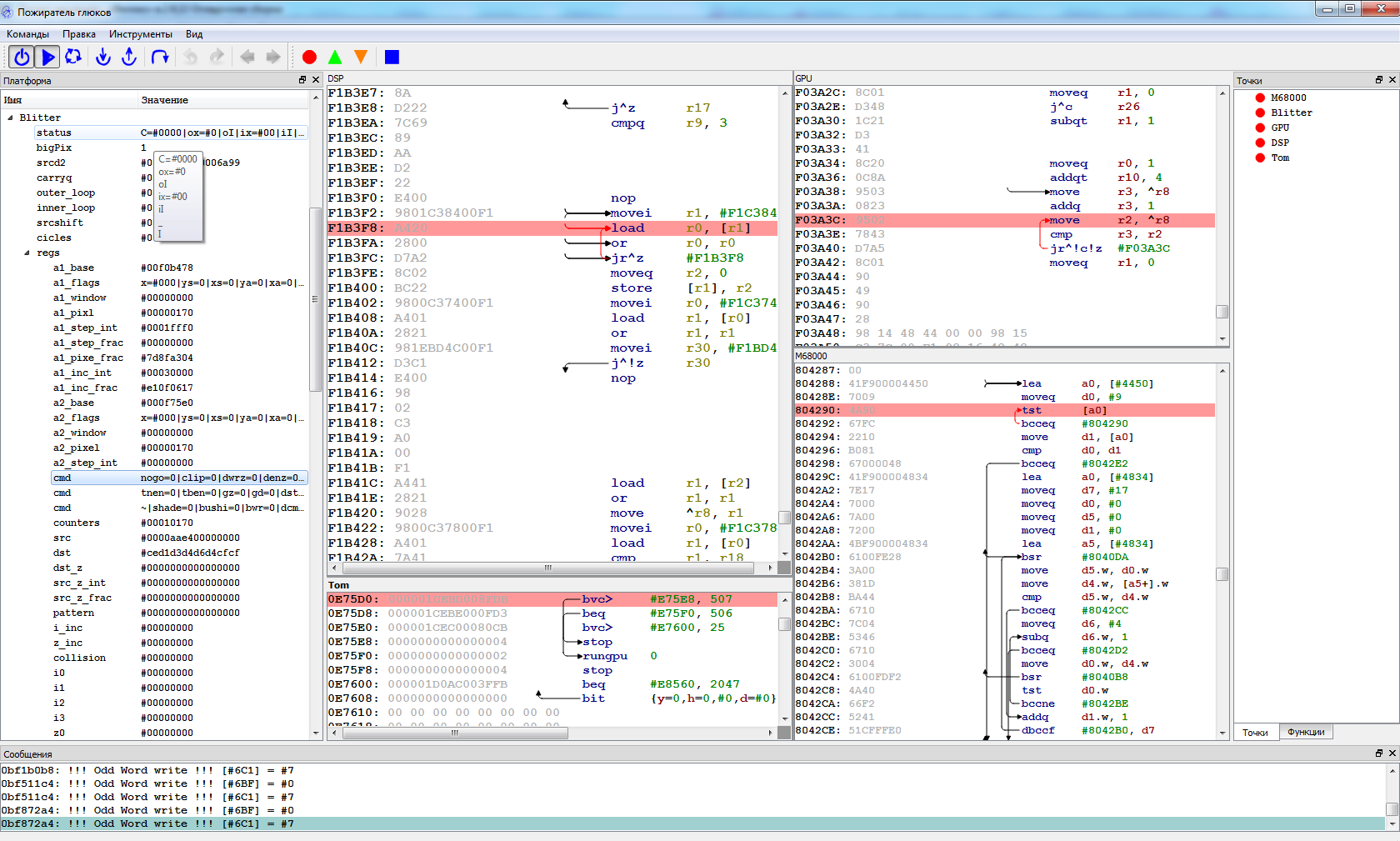
Что я использую помимо дизассемблеров и простого вывода в консоль? Например, карту источника, которая показывает то, какая подсистема произвела запись в данную область памяти, в частности с 5-ю процессорами Ягуара, это сильно помогало с отслеживанием того, кто хулиганит (довольно часто это был Blitter).
Помимо простых брейкпоинтов на исполнение, чтение или запись в отладчике полезно реализовывать функции приостановки по требованию из кода, например, я хочу проверить не выходит ли GPU или DSP за пределы внутренней памяти, и если выходит — вызываю останов и передачу управления отладчику. Таким образом я, к примеру, определил серьезную аппаратную ошибку в Ягуаре. Когда происходит запись во флаговый регистр с переключением банков, то если следующая инструкция читает содержимое регистра, в реальном железе оно должно быть из старого банка. Эту ошибку пришлось реализовать, иначе не работал Wolfenshtain и еще ряд игр. Да, в эмуляции нужно реализовывать и баги, а не только фичи!

Исправили массу ошибок и вроде все работает? Нет, это еще не конец, это только начало охоты! Дальше нужно начать тестирование всех доступных игр, всеми доступными способами! И тут главное не только найти ошибки, но и сделать их повторяемыми, чтобы легко было найти причину. Мне в этом помогают мои форумчане, которым я очень благодарен, ведь протестировать даже сотню игр одному — крайне сложно, хотя и играть в старые игры — одно удовольствие!
В качестве заключения
Немного расскажу об основных приемах для повышения производительности эмуляторов, которыми пользуюсь сам.
- Препроцессинг. Если есть данные которые многократно используются (в основном текстуры), то имеет смысл запомнить и сохранить их максимально обработанные варианты для повторного использования.
- Детектирование интерлоков. Если есть возможность определить, что процессор ожидает некоего события — не нужно эмулировать его инструкции до наступления данного события.
- Квантование времени выполнения. С точки зрения работы кэша, лучше много раз выполнить каждый из нескольких кусков кода, чем выполнять их строго по очереди много раз. Иными словами, если возможно, то лучше не потактовая эмуляция всех устройств, а исполнение каждым устройством максимально возможной порции тактов.
- Рекомпиляция. Рекомпиляция может быть динамической или статической. Статическая — самая быстрая, но возможна только при малом разнообразии эмулируемого кода устройства. Например, код DSP в 3DO SDK насчитывает несколько сотен инструментов, поэтому вполне нормально выполнить их статическую рекомпиляцию, код же центральных процессоров, как правило, слишком разнообразен и здесь уже нужна динамическая рекомпиляция.
- Параллельная эмуляция подсистем. Это не всегда возможно без ущерба для совместимости, поскольку в старых многопроцессорных системах, часто применялись не самые надежные техники синхронизации, и асинхронности в потоках эмуляции могут приводить к зависаниям и прочим ошибкам эмуляции, исправление которых может полностью нивелировать выигрыш от многопоточности.
Что в итоге нужно для успешного написания эмулятора? Я думаю, что ничего особенного — аккуратность и усидчивость, с ними развиваются любые навыки. Здесь нет каких-то особенных и волшебных методов.
Only registered users can participate in poll. Log in, please.
Эмуляцию какой консоли вы бы хотели увидеть в рамках проекта «Феникс»?
1.59% Philips CD-i4
3.97% 3DO M210
9.13% Sega Saturn23
20.63% Nintendo 6452
1.98% Amiga CD325
5.16% Neo-Geo13
51.59% PlayStation130
5.95% Нужная мне консоль плохо эмулируется и здесь не указана15
252 users voted. 98 users abstained.
