TensorFlow — современная платформа глубокого обучения и машинного обучения, дающая возможность извлекать максимальную производительность из оборудования Intel. Эта статья познакомит сообщество разработчиков искусственного интеллекта (ИИ) с методиками оптимизации TensorFlow для платформ на базе процессоров Intel Xeon и Intel Xeon Phi. Эти методики были созданы в результате тесного сотрудничества между специалистами корпораций Intel и Google. Представители обеих корпораций объявили об этом сотрудничестве на первой конференции Intel AI Day в прошлом году.

Мы описываем различные проблемы производительности, с которыми мы столкнулись в процессе оптимизации, и принятые нами решения. Также указан уровень повышения производительности для образца распространенных моделей нейросетей. Принятые методики оптимизации дают возможность повысить производительность на несколько порядков. Например, наши измерения зафиксировали повышение производительности в 70 раз для обучения и в 85 раз для влияния на процессорах Intel Xeon Phi 7250 (KNL). Платформы на базе процессоров Intel Xeon E5 v4 (BDW) и Intel Xeon Phi 7250 стали основной нового поколения решений корпорации Intel. В частности, следует ожидать повышения производительности процессоров Intel Xeon (Skylake) и Xeon Phi (Knights Mill), которые будут выпущены позднее в этом году.
При оптимизации производительности моделей глубинного обучения на современных ЦП возникает ряд проблем, достаточно близких к проблемам оптимизации других ресурсоемких приложений в области высокопроизводительных вычислений.
В корпорации Intel для решения этих задач разработали ряд оптимизированных примитивов глубинного обучения, которые можно использовать в разных платформах глубинного обучения для эффективной реализации общих готовых компонентов. Эти готовые компоненты, помимо умножения матриц и свертки, поддерживают следующие возможности.
Дополнительные сведения об оптимизированных примитивах библиотеки Intel Math Kernel Library для глубоких нейросетей (Intel MKL-DNN) см. в этой статье.
В TensorFlow реализованы оптимизированные версии операций, использующие примитивы Intel MKL-DNN во всех возможных случаях. Это необходимо, чтобы воспользоваться масштабированием производительности на платформах с архитектурой Intel. Кроме того, реализованы и другие методики оптимизации. В частности, по соображениям производительности в Intel MKL используется формат, отличный от формата по умолчанию в TensorFlow. При этом потребовалось свести к минимуму издержки при преобразовании из одного формата в другой. Также нужно было позаботиться о том, чтобы пользователям TensorFlow не пришлось переделывать существующие модели нейросетей, чтобы воспользоваться оптимизированными алгоритмами.

Мы реализовали ряд методов оптимизации графов.
Эти меры оптимизации позволяют добиться более высокой производительности без увеличения нагрузки на программистов TensorFlow. Для оптимизации производительности первостепенное значение имеет оптимизация формата данных. Собственный формат TensorFlow зачастую не является наиболее эффективным для обработки определенных операций на ЦП. В таких случаях мы вставляем преобразование данных из формата TensorFlow во внутренний формат, выполняем операцию на ЦП, затем преобразуем данные обратно в формат TensorFlow. Такие преобразования приводят к издержкам производительности, их следует избегать. При оптимизации формата данных определяются подграфы, которые можно целиком выполнить с помощью операций, оптимизированных для Intel MKL, а преобразование формата в пределах подграфов исключено. Автоматически вставляемые узлы преобразования занимаются преобразованием формата данных на границах подграфов. Еще один полезный способ оптимизации — проход слияния, автоматически объединяющий операции, которые можно эффективно выполнить в рамках одной операции Intel MKL.
Мы также настроили ряд компонентов платформы TensorFlow, чтобы добиться наивысшей производительности ЦП для разных моделей глубинного обучения. На основе существующего распределителя пула в TensorFlow мы создали наш собственный распределитель. Он действует таким образом, что TensorFlow и Intel MKL вместе используют одни и те же пулы памяти (с помощью функциональности imalloc в Intel MKL), а память не возвращается операционной системе слишком рано. Это позволяет избежать снижения производительности при «промахе» мимо страниц памяти и при очистке страниц памяти. Кроме того, мы тщательно настроили библиотеки управления многопоточной работой (pthreads в TensorFlow и OpenMP в Intel MKL) таким образом, чтобы они могли работать вместе и не боролись друг с другом за ресурсы ЦП.
Примененные меры оптимизации позволили резко повысить производительность на платформах с процессорами Intel Xeon и Intel Xeon Phi. Для демонстрации прироста производительности мы описываем наши наиболее известные методы, а также показатели производительности при базовых и при оптимизированных настройках для трех распространенных тестов ConvNet.
Следующие параметры важны для производительности процессоров Intel Xeon (Broadwell) и Intel Xeon Phi (Knights Landing). Мы рекомендуем настраивать их в соответствии с вашей конкретной моделью нейросети и используемой платформой. Мы тщательно настроили эти параметры, чтобы добиться наилучших результатов для тестов convnet на процессорах Intel Xeon и Intel Xeon Phi.
Пример настроек для процессора Intel Xeon
(семейство Broadwell, 2 физических процессора, 22 ядра)

Пример настроек для процессора Intel Xeon Phi
(семейство Knights Landing, 68 ядер)

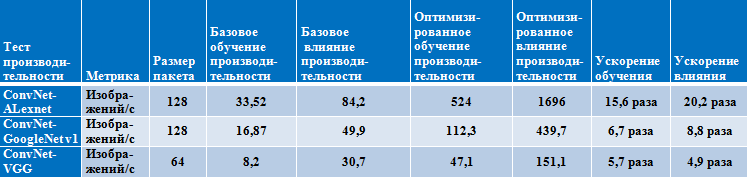
Результаты производительности на процессоре Intel Xeon
(семейство Broadwell, 2 физических процессора, 22 ядра)
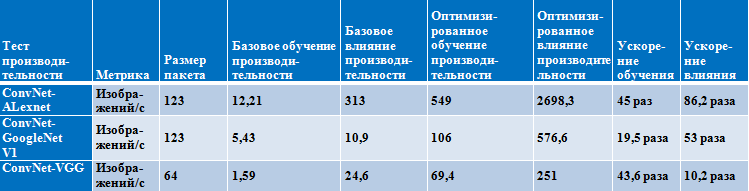
Результаты производительности на процессоре Intel Xeon Phi
(семейство Knights Landing, 68 ядер)
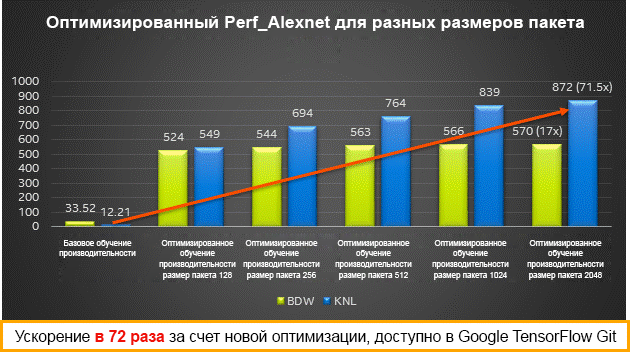
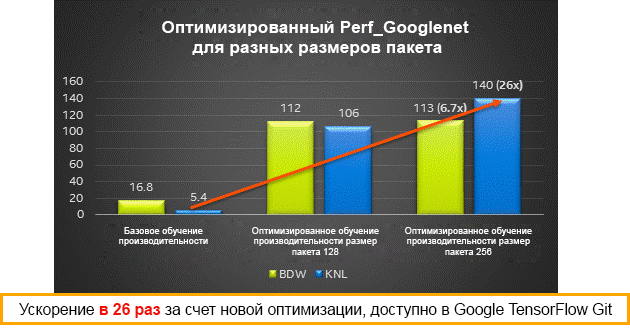
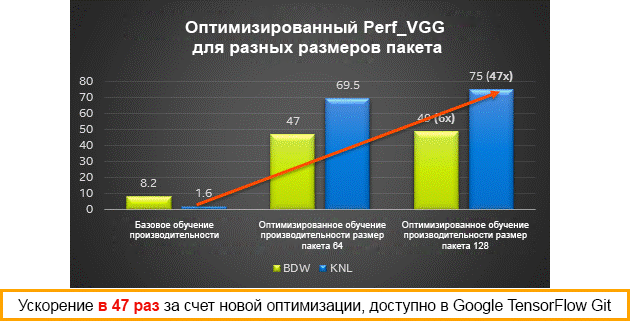
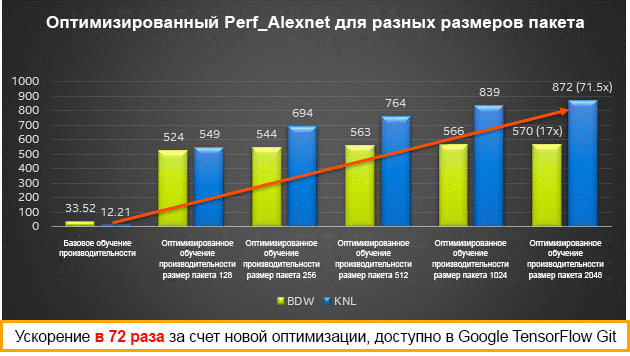
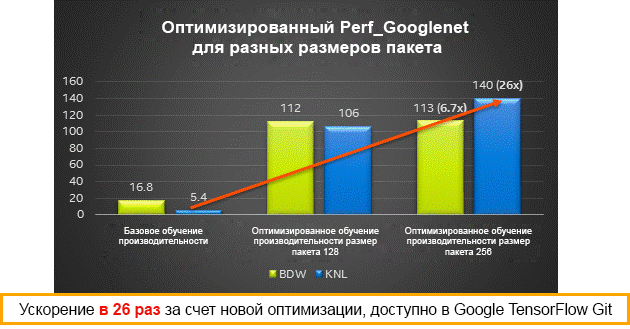
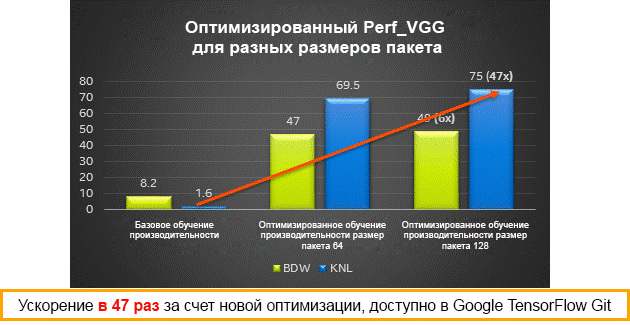
Результаты производительности для различных размеров пакетов на процессорах Intel Xeon (Broadwell) и Intel Xeon Phi (Knights Landing) — обучение
Можно либо установить уже готовые двоичные пакеты с помощью pip или conda согласно инструкциям в статье Доступен оптимизированный для Intel пакет wheel TensorFlow, либо самостоятельно собрать пакеты из исходного кода по приведенным ниже инструкциям.
Оптимизация TensorFlow означает, что решения глубинного обучения, построенные на основе этой широко доступной и широко распространенной платформы, теперь гораздо быстрее работают на процессорах Intel; повышаются гибкость, доступность и масштаб таких решений. Производительность процессоров Intel Xeon Phi, к примеру, масштабируется почти линейно при добавлении ядер и узлов, что позволяет резко снизить время обучения для моделей машинного обучения. Наращивание производительности TensorFlow одновременно с повышением производительности процессоров Intel даст возможность обрабатывать более крупные и сложные нагрузки ИИ.
Сотрудничество между корпорациями Intel и Google для оптимизации TensorFlow организовано в ходе непрерывной деятельности, направленной на повышение доступности ИИ для разработчиков и исследователей данных, для реализации возможности запуска приложений ИИ там, где они нужны, на любых устройствах и в любой среде, от пользовательских устройств до облаков. Специалисты Intel считают, что более высокая доступность ИИ является важнейшим фактором для создания моделей и алгоритмов ИИ нового поколения, способных решить наиболее актуальные проблемы бизнеса, науки, техники, медицины и общества.
В ходе сотрудничества уже удалось резко повысить производительность на платформах с процессорами Intel Xeon и Intel Xeon Phi. Код с улучшенными алгоритмами доступен в репозитории TensorFlow корпорации Google в GitHub. Мы просим разработчиков из сообщества ИИ попробовать эти меры оптимизации и поделиться своими отзывами.

Мы описываем различные проблемы производительности, с которыми мы столкнулись в процессе оптимизации, и принятые нами решения. Также указан уровень повышения производительности для образца распространенных моделей нейросетей. Принятые методики оптимизации дают возможность повысить производительность на несколько порядков. Например, наши измерения зафиксировали повышение производительности в 70 раз для обучения и в 85 раз для влияния на процессорах Intel Xeon Phi 7250 (KNL). Платформы на базе процессоров Intel Xeon E5 v4 (BDW) и Intel Xeon Phi 7250 стали основной нового поколения решений корпорации Intel. В частности, следует ожидать повышения производительности процессоров Intel Xeon (Skylake) и Xeon Phi (Knights Mill), которые будут выпущены позднее в этом году.
При оптимизации производительности моделей глубинного обучения на современных ЦП возникает ряд проблем, достаточно близких к проблемам оптимизации других ресурсоемких приложений в области высокопроизводительных вычислений.
- При переработке кода необходимо задействовать современные векторные инструкции. Это означает, что все основные примитивы, такие как свертка, умножение матриц и пакетная нормализация, перерабатываются в векторный код с использованием последней версии (AVX2 — для процессоров Intel Xeon и AVX512 — для процессоров Intel Xeon Phi).
- Для достижения наивысшей производительности важно обратить особое внимание на эффективность использования всех доступных ядер. Для этого следует рассматривать как распараллеливание в пределах заданного уровня, так и работу и распараллеливание между разными уровнями.
- Данные должны быть доступны всегда (если это возможно), когда они нужны исполняемым блокам. Это означает, что придется сбалансировать применение технологий упреждающей выборки, блокирования кэша и форматов данных, обеспечивающих локальность данных как в пространстве, так и во времени.
В корпорации Intel для решения этих задач разработали ряд оптимизированных примитивов глубинного обучения, которые можно использовать в разных платформах глубинного обучения для эффективной реализации общих готовых компонентов. Эти готовые компоненты, помимо умножения матриц и свертки, поддерживают следующие возможности.
- Прямая пакетная свертка
- Внутреннее произведение
- Опрос: максимум, минимум, среднее значение
- Нормализация: нормализация локального отклика по каналам (LRN), пакетная нормализация
- Активация: блок линейной ректификации (ReLU)
- Манипуляция данными: многомерная транспозиция (преобразование), разделение, сцепление, суммирование, пересчет
Дополнительные сведения об оптимизированных примитивах библиотеки Intel Math Kernel Library для глубоких нейросетей (Intel MKL-DNN) см. в этой статье.
В TensorFlow реализованы оптимизированные версии операций, использующие примитивы Intel MKL-DNN во всех возможных случаях. Это необходимо, чтобы воспользоваться масштабированием производительности на платформах с архитектурой Intel. Кроме того, реализованы и другие методики оптимизации. В частности, по соображениям производительности в Intel MKL используется формат, отличный от формата по умолчанию в TensorFlow. При этом потребовалось свести к минимуму издержки при преобразовании из одного формата в другой. Также нужно было позаботиться о том, чтобы пользователям TensorFlow не пришлось переделывать существующие модели нейросетей, чтобы воспользоваться оптимизированными алгоритмами.
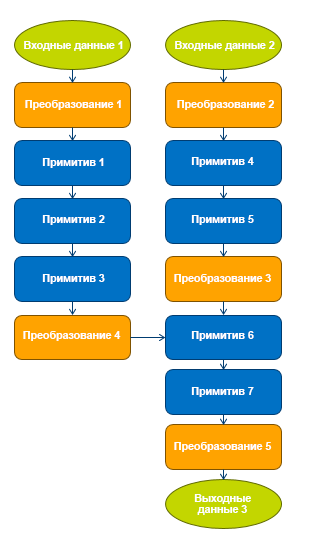
Оптимизация графов
Мы реализовали ряд методов оптимизации графов.
- Замена операций TensorFlow по умолчанию на оптимизированные версии Intel при работе на ЦП. Благодаря этому пользователи могут запускать существующие программы на Python с повышенной производительностью, не изменяя модели нейросетей.
- Устранение ненужного и ресурсоемкого преобразования формата данных.
- Объединение нескольких операций воедино для более эффективного использования кэша ЦП.
- Обработка промежуточных состояний для ускоренного обратного распространения.
Эти меры оптимизации позволяют добиться более высокой производительности без увеличения нагрузки на программистов TensorFlow. Для оптимизации производительности первостепенное значение имеет оптимизация формата данных. Собственный формат TensorFlow зачастую не является наиболее эффективным для обработки определенных операций на ЦП. В таких случаях мы вставляем преобразование данных из формата TensorFlow во внутренний формат, выполняем операцию на ЦП, затем преобразуем данные обратно в формат TensorFlow. Такие преобразования приводят к издержкам производительности, их следует избегать. При оптимизации формата данных определяются подграфы, которые можно целиком выполнить с помощью операций, оптимизированных для Intel MKL, а преобразование формата в пределах подграфов исключено. Автоматически вставляемые узлы преобразования занимаются преобразованием формата данных на границах подграфов. Еще один полезный способ оптимизации — проход слияния, автоматически объединяющий операции, которые можно эффективно выполнить в рамках одной операции Intel MKL.
Прочие алгоритмы оптимизации
Мы также настроили ряд компонентов платформы TensorFlow, чтобы добиться наивысшей производительности ЦП для разных моделей глубинного обучения. На основе существующего распределителя пула в TensorFlow мы создали наш собственный распределитель. Он действует таким образом, что TensorFlow и Intel MKL вместе используют одни и те же пулы памяти (с помощью функциональности imalloc в Intel MKL), а память не возвращается операционной системе слишком рано. Это позволяет избежать снижения производительности при «промахе» мимо страниц памяти и при очистке страниц памяти. Кроме того, мы тщательно настроили библиотеки управления многопоточной работой (pthreads в TensorFlow и OpenMP в Intel MKL) таким образом, чтобы они могли работать вместе и не боролись друг с другом за ресурсы ЦП.
Эксперименты и оценка производительности
Примененные меры оптимизации позволили резко повысить производительность на платформах с процессорами Intel Xeon и Intel Xeon Phi. Для демонстрации прироста производительности мы описываем наши наиболее известные методы, а также показатели производительности при базовых и при оптимизированных настройках для трех распространенных тестов ConvNet.
Следующие параметры важны для производительности процессоров Intel Xeon (Broadwell) и Intel Xeon Phi (Knights Landing). Мы рекомендуем настраивать их в соответствии с вашей конкретной моделью нейросети и используемой платформой. Мы тщательно настроили эти параметры, чтобы добиться наилучших результатов для тестов convnet на процессорах Intel Xeon и Intel Xeon Phi.
- Формат данных: для достижения наивысшей производительности мы рекомендуем пользователям явным образом указывать формат NCHW для своих моделей нейросетей. Использующийся в TensorFlow по умолчанию формат NHWC не является наиболее эффективным с точки зрения обработки данных в ЦП, при его использовании образуются дополнительные издержки на преобразование.
- Параметры inter-op/intra-op: мы также рекомендуем поэкспериментировать с этими параметрами TensorFlow, чтобы добиться оптимальной настройки для каждой модели и каждой платформы ЦП. Эти параметры влияют на распараллеливание в пределах одного уровня и между уровнями.
- Размер пакета: это еще один важный параметр, влияющий как на доступное распараллеливание для задействования всех ядер, так и на размер рабочего набора и на общую производительность памяти.
- OMP_NUM_THREADS: для наивысшей производительности требуется эффективно задействовать все доступные ядра. Этот параметр особенно важен для процессоров Intel Xeon Phi, поскольку с его помощью можно управлять уровнем гиперпоточности (от 1 до 4).
- Транспозиция при умножении матриц: для матриц определенного размера транспозиция второй входной матрицы b обеспечивает более высокую производительность (более эффективное использование кэша) на уровне умножения матриц. Это справедливо для всех операций умножения матриц, использованных в показанных ниже трех моделях. Пользователям следует поэкспериментировать с этим параметром для других размеров матриц.
- KMP_BLOCKTIME: здесь можно попробовать разные настройки времени ожидания (в миллисекундах) каждого потока после завершения выполнения в параллельной области.
Пример настроек для процессора Intel Xeon
(семейство Broadwell, 2 физических процессора, 22 ядра)

Пример настроек для процессора Intel Xeon Phi
(семейство Knights Landing, 68 ядер)

Результаты производительности на процессоре Intel Xeon
(семейство Broadwell, 2 физических процессора, 22 ядра)
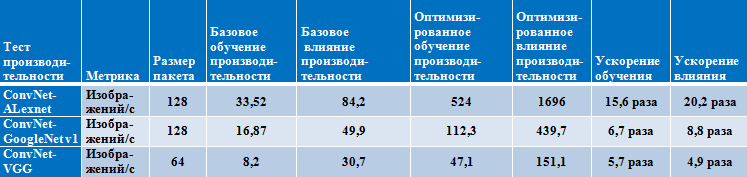
Результаты производительности на процессоре Intel Xeon Phi
(семейство Knights Landing, 68 ядер)

Результаты производительности для различных размеров пакетов на процессорах Intel Xeon (Broadwell) и Intel Xeon Phi (Knights Landing) — обучение
Установка TensorFlow с оптимизациями ЦП
Можно либо установить уже готовые двоичные пакеты с помощью pip или conda согласно инструкциям в статье Доступен оптимизированный для Intel пакет wheel TensorFlow, либо самостоятельно собрать пакеты из исходного кода по приведенным ниже инструкциям.
- Запустите ./configure в папке исходного кода TensorFlow. При этом последняя версия пакета Intel MKL для машинного обучения будет автоматически загружена в tensorflow/third_party/mkl/mklml, если выбрать использование Intel MKL.
- Выполните следующие команды, чтобы создать пакет pip, с помощью которого можно установить оптимизированную сборку TensorFlow.
- PATH можно изменить так, чтобы указывать на определенную версию компилятора GCC.
export PATH=/PATH/gcc/bin:$PATH - LD_LIBRARY_PATH также можно изменить, чтобы указывать на новую GLIBC.
export LD_LIBRARY_PATH=/PATH/gcc/lib64:$LD_LIBRARY_PATH - Сборка для наивысшей производительности на процессорах Intel Xeon и Intel Xeon Phi.
bazel build --config=mkl --copt=”-DEIGEN_USE_VML” -c opt //tensorflow/tools/pip_package:
build_pip_package
- PATH можно изменить так, чтобы указывать на определенную версию компилятора GCC.
- Установите оптимизированный пакет wheel TensorFlow.
bazel-bin/tensorflow/tools/pip_package/build_pip_package ~/path_to_save_wheel
pip install --upgrade --user ~/path_to_save_wheel /wheel_name.whl
Конфигурация системы
| BDW4 | KNL11 | ||
|---|---|---|---|
| Архитектура | x86_64 | Архитектура | x86_64 |
| Операционные режимы ЦП | 32-разрядный, 64-разрядный | Операционные режимы ЦП | 32-разрядный, 64-разрядный |
| Порядок байтов | Прямой | Порядок байтов | Прямой |
| Кол-во ЦП | 44 | Кол-во ЦП | 272 |
| Включенные ЦП | 0–43 | Включенные ЦП | 0–271 |
| Потоков на ядро | 1 | Потоков на ядро | 4 |
| Ядер на физический процессор | 22 | Ядер на физический процессор | 68 |
| Физических процессоров | 2 | Физических процессоров | 1 |
| Узлов NUMA | 2 | Узлов NUMA | 2 |
| ИД поставщика | Genuinelntel | ИД поставщика | Genuinelntel |
| Семейство ЦП | 6 | Семейство ЦП | 6 |
| Модель | 79 | Модель | 37 |
| Название модели | lntel® Xeon® E5-2699v4 2,20 ГГц | Название модели | lntel® Xeon Phi(TM) 7250 1,40 ГГц |
| Выпуск | 1 | Выпуск | 1 |
| Частота ЦП, МГц | 2426,273 | Частота ЦП, МГц | 1400 |
| BogoMIPS | 4397,87 | BogoMIPS | 2793,45 |
| Визуализация | VT-x | Кэш данных 1-го уровня | 32 КБ |
| Кэш данных 1-го уровня | 32 КБ | Кэш инструкций 1-го уровня | 32 КБ |
| Кэш инструкций 1-го уровня | 32 КБ | Кэш 2-го уровня | 1024 КБ |
| Кэш 2-го уровня | 256 КБ | ЦП узла NUMA 0 | 0–271 |
| Кэш 3-го уровня | 56 320 КБ | ||
| ЦП узла NUMA 0 | 0–21 | ||
| ЦП узла NUMA 1 | 22–43 | ||
Что это означает для ИИ
Оптимизация TensorFlow означает, что решения глубинного обучения, построенные на основе этой широко доступной и широко распространенной платформы, теперь гораздо быстрее работают на процессорах Intel; повышаются гибкость, доступность и масштаб таких решений. Производительность процессоров Intel Xeon Phi, к примеру, масштабируется почти линейно при добавлении ядер и узлов, что позволяет резко снизить время обучения для моделей машинного обучения. Наращивание производительности TensorFlow одновременно с повышением производительности процессоров Intel даст возможность обрабатывать более крупные и сложные нагрузки ИИ.
Сотрудничество между корпорациями Intel и Google для оптимизации TensorFlow организовано в ходе непрерывной деятельности, направленной на повышение доступности ИИ для разработчиков и исследователей данных, для реализации возможности запуска приложений ИИ там, где они нужны, на любых устройствах и в любой среде, от пользовательских устройств до облаков. Специалисты Intel считают, что более высокая доступность ИИ является важнейшим фактором для создания моделей и алгоритмов ИИ нового поколения, способных решить наиболее актуальные проблемы бизнеса, науки, техники, медицины и общества.
В ходе сотрудничества уже удалось резко повысить производительность на платформах с процессорами Intel Xeon и Intel Xeon Phi. Код с улучшенными алгоритмами доступен в репозитории TensorFlow корпорации Google в GitHub. Мы просим разработчиков из сообщества ИИ попробовать эти меры оптимизации и поделиться своими отзывами.
