
Первая часть статьи может быть доказательством того, что трассировщики лучей — это изящный пример программного обеспечения, позволяющий создавать потрясающе красивые изображения исключительно с помощью простых и интуитивно понятных алгоритмов.
К сожалению, эта простота имеет свою цену: низкую производительность. Несмотря на то, что существует множество способов оптимизации и параллелизации трассировщиков лучей, они всё равно остаются слишком затратными с точки зрения вычислений для выполнения в реальном времени; и хотя оборудование продолжает развиваться и становится быстрее с каждым годом, в некоторых областях применения необходимы красивые, но в сотни раз быстрее создаваемые изображения уже сегодня. Из всех этих областей применения самыми требовательными являются игры: мы ожидаем рендеринга отличной картинки с частотой не менее 60 кадров в секунду. Трассировщики лучей просто с этим не справятся.
Тогда как это удаётся играм?
Ответ заключается в использовании совершенно иного семейства алгоритмов, которое мы исследуем во второй части статьи. В отличие от трассировки лучей, которая получалась из простых геометрических моделей формирования изображений в человеческом глазе или в камере, сейчас мы будем начинать с другого конца — зададимся вопросом, что мы можем отрисовать на экране, и как отрисовать это как можно быстрее. В результате мы получим совершенно другие алгоритмы, которые создают примерно похожие результаты.
Прямые
Снова начнём с нуля: у нас есть холст с размерами
 и
и  , и мы можем расположить на нём пиксель (
, и мы можем расположить на нём пиксель ( ).
).Допустим, у нас есть две точки,
 и
и  с координатами
с координатами  и
и  . Отрисовка этих двух точек по отдельности тривиальна; но как можно отрисовать отрезок прямой линии из в ?
. Отрисовка этих двух точек по отдельности тривиальна; но как можно отрисовать отрезок прямой линии из в ?Давайте начнём с представления прямой с параметрическими координатами, как мы делали это ранее с лучами (эти «лучи» — не что иное, как прямые в 3D). Любую точку на прямой можно получить, начав с
и переместившись на какое-то расстояние в направлении от к :
Мы можем разложить это уравнение на два, по одному для каждой из координат:


Давайте возьмём первое уравнение и вычислим
 :
:


Теперь мы можем подставить это выражение во второе уравнение вместо
:

Немного преобразуем его:

Заметьте, что
 — это постоянная, зависящая только от конечных точек отрезка; давайте обозначим её
— это постоянная, зависящая только от конечных точек отрезка; давайте обозначим её  :
:
Что же такое
? Судя по тому, как она определена, она является показателем изменения координаты  на изменение единицы длины координаты
на изменение единицы длины координаты  ; другими словами, это показатель наклона прямой.
; другими словами, это показатель наклона прямой.Давайте вернёмся к уравнению. Раскроем скобки:

Группируем константы:

Выражение
 снова зависит только от конечных точек отрезка; давайте обозначим его
снова зависит только от конечных точек отрезка; давайте обозначим его  , и наконец получим
, и наконец получим
Это классическая линейная функция, которой можно представить почти все прямые. Ею нельзя описать вертикальные прямые, потому что они имеют бесконечное количество значений
при одном значении , и ни одного при всех остальных. Иногда в процессе получения такого представления из исходного параметрического уравнения такие семейства прямых можно упустить; это происходит при вычислении , потому что мы проигнорировали то, что  может давать деление на ноль. Пока давайте просто проигнорируем вертикальные прямые; позже мы избавимся от этого ограничения.
может давать деление на ноль. Пока давайте просто проигнорируем вертикальные прямые; позже мы избавимся от этого ограничения.Итак, теперь у нас есть способ вычисления значения
для любого интересующего нас значения . При этом мы получим пару  , удовлетворяющую уравнению прямой. Если мы будем двигаться от
, удовлетворяющую уравнению прямой. Если мы будем двигаться от  к
к  и вычислять значение для каждого значения , то получим первое приближение нашей функции отрисовки прямой:
и вычислять значение для каждого значения , то получим первое приближение нашей функции отрисовки прямой:DrawLine(P0, P1, color) {
a = (y1 - y0)/(x1 - x0)
b = y0 - a*x0
for x = x0 to x1 {
y = a*x + b
canvas.PutPixel(x, y, color)
}
}В этом фрагменте
x0 и y0 — это координаты и точки P0; в дальнейшем я буду использовать эту удобную запись. Также заметьте, что оператор деления / должен выполнять не целочисленное деление, а деление вещественных чисел.Эта функция является непосредственной наивной интерпретацией приведённого выше уравнения, поэтому очевидно, что она работает; но можем ли мы ускорить её работу?
Заметьте, что мы не вычисляем значения
для всех : на самом деле, мы вычисляем их только как целочисленные инкременты , и мы делаем это в следующем порядке: сразу после вычисления  мы вычисляем
мы вычисляем  :
:

Мы можем воспользоваться этим для создания более быстрого алгоритма. Давайте возьмём разность между
последовательных пикселей:



Это не очень удивительно; в конце концов, наклон
— это показатель того, насколько меняется на каждую единицу инкремента , то есть именно то, что мы здесь делаем.Интересно то, что мы можем тривиальным образом получить следующее:

Это значит, что мы можем вычислить следующее значение
только с помощью предыдущего значения и прибавлением наклона; попиксельное умножение не требуется. Нам нужно с чего-то начать (в самом начале нет никакого «предыдущего значения », поэтому мы начнём с , а затем будем прибавлять  к и к , пока мы не доберёмся до .
к и к , пока мы не доберёмся до .Считая, что
 , мы можем переписать функцию следующим образом:
, мы можем переписать функцию следующим образом:DrawLine(P0, P1, color) {
a = (y1 - y0)/(x1 - x0)
y = y0
for x = x0 to x1 {
canvas.PutPixel(x, y, color)
y = y + a
}
}Эта новая версия функции имеет новое ограничение: она может отрисовывать прямые только слева направо, то есть при
. Эту проблему довольно просто обойти: поскольку неважно, в каком порядке мы отрисовываем отдельные пиксели, то если у нас будет прямая справа налево, мы просто поменяем P0 и P1, чтобы превратить её в лево-правую версию той же прямой, после чего отрисуем её как раньше:DrawLine(P0, P1, color) {
# Make sure x0 < x1
if x0 > x1 {
swap(P0, P1)
}
a = (y1 - y0)/(x1 - x0)
y = y0
for x = x0 to x1 {
canvas.PutPixel(x, y, color)
y = y + a
}
}Теперь мы можем отрисовать пару прямых. Вот
 :
:
Вот как она выглядит вблизи:
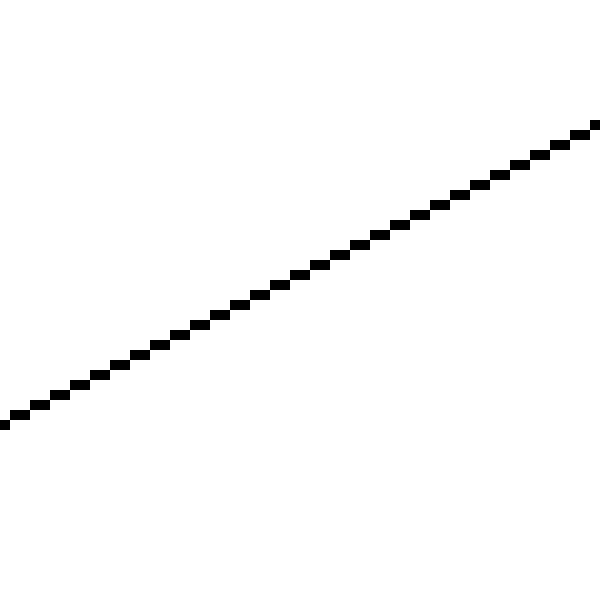
Прямая выглядит ломаной потому, что мы можем рисовать пиксели только по целочисленным координатам, а математические прямые на самом деле имеют нулевую ширину; рисуемое нами является дискретизированным приближением к идеальной прямой
(Примечание: существуют способы отрисовки более красивых приближенных прямых. Мы не будем использовать по двум причинам: 1) это медленнее, 2) наша цель — не рисовать красивые прямые, а разработать базовые алгоритмы для рендеринга 3D-сцен.).Давайте попробуем нарисовать ещё одну прямую,
 :
:
А вот как она выглядит вблизи:
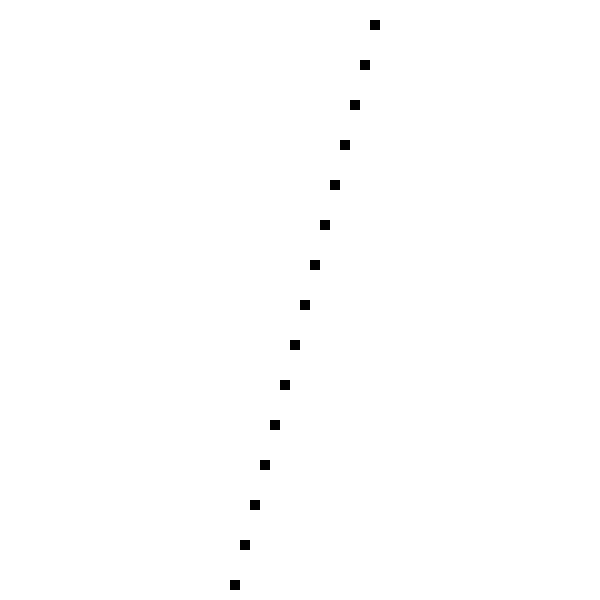
Ой. Что случилось?
Алгоритм работал так, как и задумано; он прошёл слева направо, вычислил значение
для каждого значения и отрисовал соответствующий пиксель. Проблема в том, что он вычислял одно значение для каждого значения , в то время как для некоторых значений нам нужно несколько значений .Это прямое последствие выбора формулировки, в которой
 ; на самом деле по той же самой причине мы не можем рисовать вертикальные прямые, предельный случай, при котором есть одно значение с несколькими значениями .
; на самом деле по той же самой причине мы не можем рисовать вертикальные прямые, предельный случай, при котором есть одно значение с несколькими значениями .Мы без всяких проблем можем рисовать горизонтальные прямые. Почему же нам не удаётся так же просто отрисовывать вертикальные линии?
Как оказывается, мы можем это сделать. Выбор
был произвольным решением, поэтому нет никаких причин, мешающих выразить прямую как  , переработав все уравнения и поменяв и , чтобы в результате получить следующий алгоритм:
, переработав все уравнения и поменяв и , чтобы в результате получить следующий алгоритм:DrawLine(P0, P1, color) {
# Make sure y0 < y1
if y0 > y1 {
swap(P0, P1)
}
a = (x1 - x0)/(y1 - y0)
x = x0
for y = y0 to y1 {
canvas.PutPixel(x, y, color)
x = x + a
}
}Это аналогично предыдущей
DrawLine, за исключением перемены мест вычислений и . Полученная функция может справляться с вертикальными линиями и сможет правильно отрисовать  ; разумеется, она не справится с горизонтальными прямыми и не сможет правильно отрисовать
; разумеется, она не справится с горизонтальными прямыми и не сможет правильно отрисовать  ! Что же нам делать?
! Что же нам делать?Нам просто нужно выбирать нужную версию функции в зависимости от прямой, которую нужно нарисовать. И критерии будут достаточно простыми; имеет ли прямая более различающиеся значения
или ? Если есть больше значений , чем , мы используем первую версию; в противном случае применяется вторая.Вот версия
DrawLine, обрабатывающая все случаи:DrawLine(P0, P1, color) {
dx = x1 - x0
dy = y1 - y0
if abs(dx) > abs(dy) {
# Прямая ближе к горизонтальной
# Проверяем, что x0 < x1
if x0 > x1 {
swap(P0, P1)
}
a = dy/dx
y = y0
for x = x0 to x1 {
canvas.PutPixel(x, y, color)
y = y + a
}
} else {
# Прямая ближе к вертикальной
# Проверяем, что y0 < y1
if y0 > y1 {
swap(P0, P1)
}
a = dx/dy
x = x0
for y = y0 to y1 {
canvas.PutPixel(x, y, color)
x = x + a
}
}
}Это безусловно сработает, но код не особо красив; в нём есть две реализации кода, инкрементно вычисляющих линейную функцию, и эта логика вычислений и выбора перемешана. Поскольку мы будем часто использовать линейные функции, то стоит потратить немного времени на разделение кода.
У нас есть две функции,
и . Чтобы абстрагироваться от того, что мы работаем с пикселями, давайте запишем это в общем виде как  , где
, где  — независимая переменная, для которой мы выбираем значения, а
— независимая переменная, для которой мы выбираем значения, а  — зависимая переменная, значения которой зависят от другой, и которую мы хотим вычислить. В случае более горизонтальной прямой является независимой переменной, а — зависимой; в случае более вертикальной прямой всё наоборот.
— зависимая переменная, значения которой зависят от другой, и которую мы хотим вычислить. В случае более горизонтальной прямой является независимой переменной, а — зависимой; в случае более вертикальной прямой всё наоборот.Разумеется, любую функцию можно записать как
. Мы знаем ещё два аспекта, полностью задающие её: её линейность и два её значения; а именно,  и
и  . Мы можем написать простой метод, получающий эти значения и возвращающий промежуточные значения , полагая, как и ранее, что
. Мы можем написать простой метод, получающий эти значения и возвращающий промежуточные значения , полагая, как и ранее, что  :
:Interpolate (i0, d0, i1, d1) {
values = []
a = (d1 - d0) / (i1 - i0)
d = d0
for i = i0 to i1 {
values.append(d)
d = d + a
}
return values
}Заметьте, что значение
, соответствующее  , находится в
, находится в values[0], значение для  находится в
находится в values[1], и так далее; в общем случае, значение  находится в
находится в values[i_n - i_0], если считать, что находится в интервале ![$[i_0, i_1]$](https://habrastorage.org/getpro/habr/formulas/2bb/0a7/6d0/2bb0a76d07f7ad5e0967997f90fe9070.svg) .
.Существует тупиковый случай, который нужно учитывать; нам может понадобиться вычислить
для единственного значения , то есть при  . В этом случае мы не можем даже вычислить , поэтому мы будем обрабатывать это как особый случай:
. В этом случае мы не можем даже вычислить , поэтому мы будем обрабатывать это как особый случай:Interpolate (i0, d0, i1, d1) {
if i0 == i1 {
return [ d0 ]
}
values = []
a = (d1 - d0) / (i1 - i0)
d = d0
for i = i0 to i1 {
values.append(d)
d = d + a
}
return values
}Теперь мы можем написать
DrawLine с использованием Interpolate:DrawLine(P0, P1, color) {
if abs(x1 - x0) > abs(y1 - y0) {
# Прямая ближе к горизонтальной
# Проверяем, что x0 < x1
if x0 > x1 {
swap(P0, P1)
}
ys = Interpolate(x0, y0, x1, y1)
for x = x0 to x1 {
canvas.PutPixel(x, ys[x - x0], color)
}
} else {
# Прямая ближе к вертикальной
# Проверяем, что y0 < y1
if y0 > y1 {
swap(P0, P1)
}
xs = Interpolate(y0, x0, y1, x1)
for y = y0 to y1 {
canvas.PutPixel(xs[y - y0], y, color)
}
}
}Этот
DrawLine может правильно обрабатывать все случаи:
Исходный код и рабочее демо >>
Хотя эта версия не сильно короче предыдущей, она чётко разделяет вычисление промежуточных значений
и , решение о выборе независимой переменной плюс сам код отрисовки. Преимущество этого возможно не совсем очевидно, но мы будем снова активно использовать Interpolate в последующих главах.Следует учесть, что это не самый лучший или быстрый алгоритм отрисовки; важным результатом этой главы стал
Interpolate, а не DrawLine. Лучшим алгоритмом отрисовки линий скорее всего является алгоритм Брезенхэма.Заполненные треугольники
Мы можем использовать метод
DrawLine для отрисовки контура треугольника. Такой тип контура называется каркасным, потому что он выглядит как каркас треугольника:DrawWireframeTriangle (P0, P1, P2, color) {
DrawLine(P0, P1, color);
DrawLine(P1, P2, color);
DrawLine(P2, P0, color);
}Мы получим вот такой результат:

Можем ли мы залить треугольник каким-нибудь цветом?
Как обычно бывает в компьютерной графике, для этого есть множество способов. Мы будем отрисовывать заполненные треугольники, воспринимая их как набор отрезков горизонтальных прямых, которые, если их отрисовать вместе, выглядят как треугольник. Ниже представлено очень грубое первое приближение того, что мы хотим сделать:
для каждой координаты y горизонтальной прямой, занятой треугольником
вычислить x_left и x_right для этого y
DrawLine(x_left, y, x_right, y)Давайте начнём с части «для каждой координаты y горизонтальной прямой, занятой треугольником». Треугольник задаётся тремя вершинами
, и  . Если мы отсортируем эти точки, увеличивая значение , таким образом, что
. Если мы отсортируем эти точки, увеличивая значение , таким образом, что  , то интервал значений , занятых треугольником, будет равен
, то интервал значений , занятых треугольником, будет равен ![$[y_0, y_2]$](https://habrastorage.org/getpro/habr/formulas/c38/541/375/c385413751b90c2e0b6df53f88c385e1.svg) :
:if y1 < y0 { swap(P1, P0) }
if y2 < y0 { swap(P2, P0) }
if y2 < y1 { swap(P2, P1) }Затем нам нужно вычислить
x_left и x_right. Это немного сложнее, потому что у треугольника три, а не две стороны. Однако с точки зрения значений у нас всегда есть «длинная» сторона от до и две «короткие» стороны от до и от lj (Примечание: существует особый случай, когда  или
или  , то есть когда у треугольника есть горизонтальная сторона; в таких случаях есть две стороны, которые можно считать «длинными» сторонами. К счастью, не важно, какую сторону мы выберем, поэтому можно придерживаться этого определения.). То есть значения
, то есть когда у треугольника есть горизонтальная сторона; в таких случаях есть две стороны, которые можно считать «длинными» сторонами. К счастью, не важно, какую сторону мы выберем, поэтому можно придерживаться этого определения.). То есть значения x_right получаются или от длинной стороны, или от обеих коротких сторон; а значения x_left получаются от другого множества.Мы начнём с вычисления значений
для трёх сторон. Так как мы отрисовываем горизонтальные отрезки, то нам нужно ровно одно значение для каждого значения ; это значит, что мы можем получить значения непосредственно с помощью Interpolate, используя в качестве независимого значения , а в качестве зависимого значения :x01 = Interpolate(y0, x0, y1, x1)
x12 = Interpolate(y1, x1, y2, x2)
x02 = Interpolate(y0, x0, y2, x2)x02 будет или x_left, или x_right; другой будет конкатенацией x01 и x12.Заметьте, что в этих двух списках есть повторяющееся значение: значение
для  является и последним значением
является и последним значением x01, и первым значением x12. Нам просто нужно избавиться от одного из них.remove_last(x01)
x012 = x01 + x12Наконец у нас есть
x02 и x012, и нам нужно определить, что из них является x_left и x_right. Для этого надо посмотреть на значения для одной из прямых, например, для средней:m = x02.length / 2
if x02[m] < x012[m] {
x_left = x02
x_right = x012
} else {
x_left = x012
x_right = x02
}Теперь осталось только отрисовать горизонтальные отрезки. По причинам, которые станут понятны позже, мы не будем использовать для этого
DrawLine; вместо этого мы будем отрисовывать пиксели по отдельности.Вот полная версия
DrawFilledTriangle:DrawFilledTriangle (P0, P1, P2, color) {
# Сортировка точек так, что y0 <= y1 <= y2
if y1 < y0 { swap(P1, P0) }
if y2 < y0 { swap(P2, P0) }
if y2 < y1 { swap(P2, P1) }
# Вычисление координат x рёбер треугольника
x01 = Interpolate(y0, x0, y1, x1)
x12 = Interpolate(y1, x1, y2, x2)
x02 = Interpolate(y0, x0, y2, x2)
# Конкатенация коротких сторон
remove_last(x01)
x012 = x01 + x12
# Определяем, какая из сторон левая и правая
m = x012.length / 2
if x02[m] < x012[m] {
x_left = x02
x_right = x012
} else {
x_left = x012
x_right = x02
}
# Отрисовка горизонтальных отрезков
for y = y0 to y2 {
for x = x_left[y - y0] to x_right[y - y0] {
canvas.PutPixel(x, y, color)
}
}
}Вот результат; для проверки мы вызвали
DrawFilledTriangle, а потом DrawWireframeTriangle с одинаковыми координатами, но разными цветами:
Исходный код и рабочее демо >>
Вы можете заметить, что чёрный контур треугольника не полностью совпадает с зелёной внутренней областью; это особенно заметно в правом нижнем ребре треугольника. Так получилось потому, что DrawLine() вычисляет
для этого ребра, но DrawTriangle() вычисляет . На такую аппроксимацию мы готовы пойти, чтобы достичь нашей цели — высокоскоростного рендеринга.Затенённые треугольники
В предыдущей части мы разработали алгоритм для отрисовки треугольника и заливки его цветом. Нашей следующей целью будет отрисовка затенённого треугольника, который похож на залитый градиентом.
Хотя затенённые треугольники выглядят красивее, чем одноцветные, это не является основной целью главы; это просто особое применение техники, которую мы создадим. Наверно, она будет самой важной в этом разделе статьи; почти всё остальное будет построено на её основе.
Но давайте начнём с простого. Вместо заполнения треугольника сплошным цветом, мы хотим заполнить его оттенками цвета. Это будет выглядеть так:

Исходный код и рабочее демо >>
Первый шаг заключается в формальном определении того, что мы хотим отрисовать. Для этого мы назначим каждой вершине вещественное значение
 , обозначающее яркость цвета вершины. находится в интервале
, обозначающее яркость цвета вершины. находится в интервале ![$[0.0, 1.0]$](https://habrastorage.org/getpro/habr/formulas/bbe/f49/71e/bbef4971e53976fa6c76ea58c9dbbfbb.svg) .
.Чтобы получить точный цвет пикселя, имея цвет
 и яркость , мы просто выполним поканальное умножение:
и яркость , мы просто выполним поканальное умножение:  . То есть при
. То есть при  мы получим чёрный, а при
мы получим чёрный, а при  — исходный цвет .
— исходный цвет .Вычисление затенения ребра
Итак, для отрисовки затенённого треугольника нам нужно вычислить значение
для каждого пикселя треугольника, получить соответствующий оттенок цвета и закрасить пиксель. Всё очень просто!Однако на этом этапе мы знаем только значения
для заданных вершин. Как вычислить значения для остальной части треугольника?Давайте сначала рассмотрим рёбра. Выберем ребро
 . Мы знаем
. Мы знаем  и
и  . Что происходит в
. Что происходит в  , то есть в середине отрезка ? Поскольку мы хотим, чтобы яркость плавно изменялась от
, то есть в середине отрезка ? Поскольку мы хотим, чтобы яркость плавно изменялась от  к
к  , то
, то  должно быть каким-то значением между и . Так как — это средняя точка отрезка , то почему бы не сделать средним значением и ?
должно быть каким-то значением между и . Так как — это средняя точка отрезка , то почему бы не сделать средним значением и ?Если более формально, то у нас есть функция
 , для которой нам известны предельные значения
, для которой нам известны предельные значения  и
и  , и нам нужно сделать её плавной. Мы больше ничего не знаем об , поэтому можем выбрать любую функцию, соответствующую этим критериям, например, линейную функцию:
, и нам нужно сделать её плавной. Мы больше ничего не знаем об , поэтому можем выбрать любую функцию, соответствующую этим критериям, например, линейную функцию: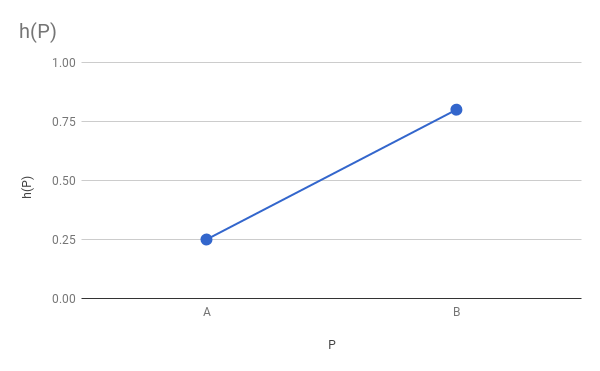
Разумеется, основой кода затенённого треугольника будет код сплошного треугольника, созданный в предыдущей главе. Один их первых шагов включает в себя вычисление конечных точек каждого горизонтального отрезка, то есть
x_left и x_right для сторон  ,
,  и
и  ; мы использовали
; мы использовали Interpolate() для вычисления значений , имея  и
и  … и именно это мы и хотим сделать здесь, достаточно просто заменить на !
… и именно это мы и хотим сделать здесь, достаточно просто заменить на !То есть мы можем вычислить промежуточные значения
точно таким же образом, как мы вычисляли значения :x01 = Interpolate(y0, x0, y1, x1)
h01 = Interpolate(y0, h0, y1, h1)
x12 = Interpolate(y1, x1, y2, x2)
h12 = Interpolate(y1, h1, y2, h2)
x02 = Interpolate(y0, x0, y2, x2)
h02 = Interpolate(y0, h0, y2, h2)Следующим этапом будет превращение этих трёх векторов в два вектора и определение того, какой из них представляет левосторонние значения, а какой — правосторонние. Заметьте, что значения
не играют никакой роли в том, что чем является; это полностью определяется значениями . Значения «приклеиваются» к значениям , потому что являются другими атрибутами тех же физических пикселей. То есть, если x012 имеет значения для правой стороны треугольника, тогда h012 имеет значения для правой стороны треугольника: # Конкатенация коротких сторон
remove_last(x01)
x012 = x01 + x12
remove_last(h01)
h012 = h01 + h12
# Определяем, какая из сторон левая и правая
m = x012.length / 2
if x02[m] < x012[m] {
x_left = x02
x_right = x012
h_left = h02
h_right = h012
} else {
x_left = x012
x_right = x02
h_left = h012
h_right = h02
}Вычисление внутреннего затенения
Остался единственный шаг — отрисовка самих горизонтальных отрезков. Для каждого отрезка мы знаем
 и
и  , а теперь мы также знаем
, а теперь мы также знаем  и
и  . Однако вместо итерирования слева направо и отрисовки каждого пикселя базовым цветом нам нужно вычислить значения для каждого пикселя отрезка.
. Однако вместо итерирования слева направо и отрисовки каждого пикселя базовым цветом нам нужно вычислить значения для каждого пикселя отрезка.Мы снова можем считать, что
линейно изменяется с и использовать Interpolate() для вычисления этих значений:h_segment = Interpolate(x_left[y-y0], h_left[y-y0], x_right[y-y0], h_right[y-y0])И теперь это просто вопрос вычисления цвета для каждого пикселя и его отрисовки.
Вот код вычисления для
DrawShadedTriangle:DrawShadedTriangle (P0, P1, P2, color) {
# Сортировка точек так, что y0 <= y1 <= y2
if y1 < y0 { swap(P1, P0) }
if y2 < y0 { swap(P2, P0) }
if y2 < y1 { swap(P2, P1) }
# Вычисление координат x и значений h для рёбер треугольника
x01 = Interpolate(y0, x0, y1, x1)
h01 = Interpolate(y0, h0, y1, h1)
x12 = Interpolate(y1, x1, y2, x2)
h12 = Interpolate(y1, h1, y2, h2)
x02 = Interpolate(y0, x0, y2, x2)
h02 = Interpolate(y0, h0, y2, h2)
# Конкатенация коротких сторон
remove_last(x01)
x012 = x01 + x12
remove_last(h01)
h012 = h01 + h12
# Определяем, какая из сторон левая и правая
m = x012.length / 2
if x02[m] < x012[m] {
x_left = x02
x_right = x012
h_left = h02
h_right = h012
} else {
x_left = x012
x_right = x02
h_left = h012
h_right = h02
}
# Отрисовка горизонтальных отрезков
for y = y0 to y2 {
x_l = x_left[y - y0]
x_r = x_right[y - y0]
h_segment = Interpolate(x_l, h_left[y - y0], x_r, h_right[y - y0])
for x = x_l to x_r {
shaded_color = color*h_segment[x - xl]
canvas.PutPixel(x, y, shaded_color)
}
}
}Этот алгоритм гораздо более общий, чем может казаться: до момента, в котором
умножается на цвет, то, что является яркостью цвета, не играет никакой роли. Это значит, что мы можем использовать эту технику для вычисления значения чего угодно, что можно представить как действительное число для каждого пикселя треугольника, начиная со значений этого свойства в вершинах треугольника и считая, что свойство меняется на экране линейно.Поэтому этот алгоритм окажется бесценным в последующих частях; не продолжайте чтение, пока не убедитесь, что хорошо поняли его.
Перспективная проекция
На какое-то время мы оставим в покое 2D-треугольники и обратим внимание на 3D; а конкретнее, на то, как можно представить 3D-объекты на 2D-поверхности.
Точно так же, как мы делали в начале части про трассировку лучей, мы начнём с задания камеры. Мы используем те же самые условия: камера находится в
 , смотрит в направлении
, смотрит в направлении  , а вектор «вверх» является
, а вектор «вверх» является  . Также мы определим прямоугольное окно просмотра размером
. Также мы определим прямоугольное окно просмотра размером  на
на  , рёбра которого параллельны
, рёбра которого параллельны  и
и  и находящееся на расстоянии от камеры. Если что-то из этого вам непонятно, прочитайте главу Основы трассировки лучей.
и находящееся на расстоянии от камеры. Если что-то из этого вам непонятно, прочитайте главу Основы трассировки лучей.Рассмотрим точку
 где-то перед камерой. Камера «видит» , то есть существует некий луч света, отражающийся от и достигающий камеры. Нас интересует нахождение точки
где-то перед камерой. Камера «видит» , то есть существует некий луч света, отражающийся от и достигающий камеры. Нас интересует нахождение точки  , в которой луч света пересекает окно просмотра (заметьте, что это противоположно нашим действиям при трассировке лучей, когда мы начинали с точки в окне просмотра и определяли, что видимо через неё):
, в которой луч света пересекает окно просмотра (заметьте, что это противоположно нашим действиям при трассировке лучей, когда мы начинали с точки в окне просмотра и определяли, что видимо через неё):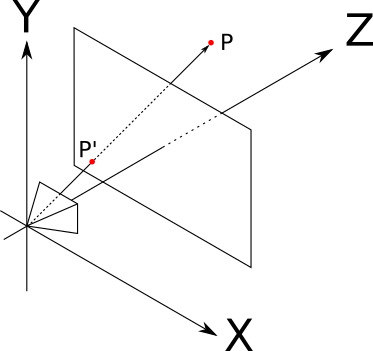
Вот схема ситуации, видимой «справа», то есть когда
направлен вверх, направлен вправо, а  направлен на нас:
направлен на нас: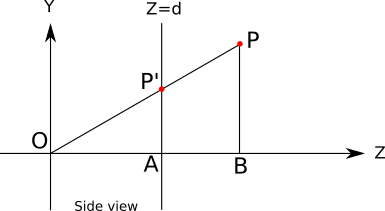
В дополнение к
 , и на этой схеме показаны точки и , которые будут полезны для понимания ситуации.
, и на этой схеме показаны точки и , которые будут полезны для понимания ситуации.Понятно, что
 , потому что мы определили, что — это точка в окне просмотра, а окно просмотра расположено на плоскости
, потому что мы определили, что — это точка в окне просмотра, а окно просмотра расположено на плоскости  .
.Также должно быть понятно, что треугольники
 и
и  подобны: у них две общих стороны
подобны: у них две общих стороны  , аналогичная
, аналогичная  , и
, и  , аналогичная
, аналогичная  ) а оставшиеся их стороны параллельны (
) а оставшиеся их стороны параллельны ( и
и  ). Это подразумевает, что справедливо следующее уравнение пропорциональности:
). Это подразумевает, что справедливо следующее уравнение пропорциональности:
Из него мы получаем

Длина каждого отрезка (со знаком) в этом уравнении — это координата точки, которую мы знаем, или которая нам нужна:
 ,
,  ,
,  и
и  . Если мы подставим их в представленное выше уравнение, то получим
. Если мы подставим их в представленное выше уравнение, то получим
Мы можем нарисовать похожую схему, на этот раз сверху:
направлен вверх, направлен вправо, а направлен на нас:
Воспользовавшись снова подобными треугольниками, мы получим

Уравнение проецирования
Давайте объединим всё вместе. При задании точки
в сцене и стандартных настроек камеры и окна просмотра, проекция в окне просмотра, которую мы обозначим как , можно вычислить следующим образом:
Самое первое, что нужно здесь сделать — забыть о
 ; её значение по определению постоянно, а мы пытаемся перейти от 3D к 2D.
; её значение по определению постоянно, а мы пытаемся перейти от 3D к 2D.Теперь
по-прежнему остаётся точкой в пространстве; её координаты задаются в единицах, используемых для описания сцены, а не в пикселях. Преобразование из координат окна просмотра в координаты холста достаточно простое, и оно полностью противоположно преобразованию «холст-окно просмотра», которое мы использовали в части «Трассировка лучей»:

Наконец мы можем перейти от точки в сцене к пикселю на экране!
Свойства уравнения проецирования
Уравнение проецирования обладает интересными свойствами, о которых стоит поговорить.
Во-первых, в целом оно интуитивно понятно и соответствует опыту реальной жизни. Чем дальше объект вправо (
 ), тем правее он виден (
), тем правее он виден ( увеличивается). То же справедливо для
увеличивается). То же справедливо для  и
и  . Кроме того, чем дальше объект (увеличивается
. Кроме того, чем дальше объект (увеличивается  ), тем меньше он кажется (т.е. и уменьшаются).
), тем меньше он кажется (т.е. и уменьшаются).Однако всё становится менее понятным при уменьшении значения
; при отрицательных значениях , то есть когда объект находится за камерой, объект всё равно проецируется, но вверх ногами! И, разумеется, когда  , вселенная схлопывается. Нам как-то нужно избегать подобных неприятных ситуаций; пока мы будем считать, что каждая точка находится перед камерой, и справимся с этим в другой главе.
, вселенная схлопывается. Нам как-то нужно избегать подобных неприятных ситуаций; пока мы будем считать, что каждая точка находится перед камерой, и справимся с этим в другой главе.Ещё одним фундаментальным свойством перспективной проекции является то, что в ней сохраняется принадлежность точек к одной прямой; то есть проекции трёх точек, принадлежащих одной прямой, в окне просмотра тоже будут принадлежать одной прямой (Примечание: это наблюдение может казаться тривиальным, но стоит например заметить, что угол между двумя прямыми не сохраняется; мы видим, как параллельные линии «сходятся» к горизонту, как будто две стороны дороги.). Другими словами, прямая линия всегда выглядит как прямая.
Это имеет для нас очень непосредственную важность: пока мы говорили о проецировании точки, но как насчёт проецировании отрезка прямой или даже треугольника? Благодаря этому свойству проекция отрезка прямой будет отрезком прямой, соединяющимся с проекциями в конечных точках; следовательно, для проецирования полигона достаточно спроецировать его вершины и отрисовать получившийся полигон.
Поэтому мы можем двигаться дальше и отрисовать наш первый 3D-объект: куб. Мы задаём координаты его 8 вершин и отрисовываем линии между проекциями 12 пар вершин, составляющих рёбра куба:
ViewportToCanvas(x, y) {
return (x*Cw/Vw, y*Ch/Vh);
}
ProjectVertex(v) {
return ViewportToCanvas(v.x * d / v.z, v.y * d / v.z)
# Четыре "передних" вершины.
vAf = [-1, 1, 1]
vBf = [1, 1, 1]
vCf = [1, -1, 1]
vDf = [-1, -1, 1]
# Четыре "задних" вершины.
vAb = [-1, 1, 2]
vBb = [1, 1, 2]
vCb = [1, -1, 2]
vDb = [-1, -1, 2]
# Передняя грань.
DrawLine(ProjectVertex(vAf), ProjectVertex(vBf), BLUE);
DrawLine(ProjectVertex(vBf), ProjectVertex(vCf), BLUE);
DrawLine(ProjectVertex(vCf), ProjectVertex(vDf), BLUE);
DrawLine(ProjectVertex(vDf), ProjectVertex(vAf), BLUE);
# Задняя грань.
DrawLine(ProjectVertex(vAb), ProjectVertex(vBb), RED);
DrawLine(ProjectVertex(vBb), ProjectVertex(vCb), RED);
DrawLine(ProjectVertex(vCb), ProjectVertex(vDb), RED);
DrawLine(ProjectVertex(vDb), ProjectVertex(vAb), RED);
# Рёбра, соединяющие переднюю и заднюю грани.
DrawLine(ProjectVertex(vAf), ProjectVertex(vAb), GREEN);
DrawLine(ProjectVertex(vBf), ProjectVertex(vBb), GREEN);
DrawLine(ProjectVertex(vCf), ProjectVertex(vCb), GREEN);
DrawLine(ProjectVertex(vDf), ProjectVertex(vDb), GREEN);И мы получаем нечто подобное:
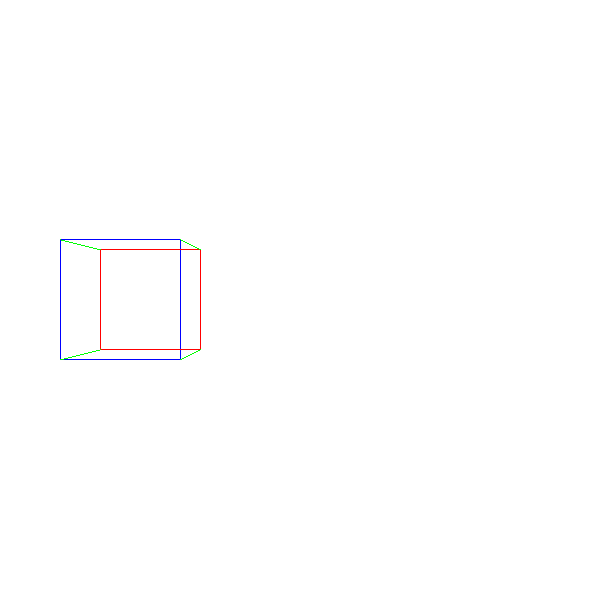
Исходный код и рабочее демо >>
Хотя это и работает, у нас возникли серьёзные проблемы — что если мы хотим отрендерить два куба? Что если мы хотим отрендерить не куб, а что-то другое? Что если мы не знаем, что будем рендерить, пока программа не запущена — например, загружаем 3D-модель с диска? В следующей главе мы узнаем, как решать все эти вопросы.
Настройки сцены
Мы разработали техники для отрисовки треугольника на холсте по заданным координатам его вершин и уравнения для преобразования 3D-координат треугольника в 2D-координаты холста. В этой главе мы узнаем, как представить объекты, состоящие из треугольников, и как манипулировать ими.
Для этого мы используем куб; это не самый простой 3D-объект, который можно создать из треугольников, но он будет удобен для иллюстрации некоторых проблем. Рёбра куба имеют длину в две единицы и параллельны осям координат, а его центр находится в точке начала координат:
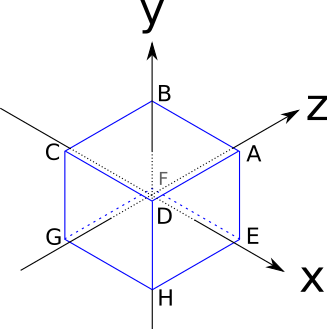
Вот координаты его вершин:








Стороны куба являются квадратами, однако мы знаем только как обращаться с треугольниками. Нет никаких проблем: любой полигон можно разложить на множество треугольников. Поэтому каждую сторону куба мы представим в виде двух треугольников.
Разумеется, не любое множество трёх вершин куба описывает треугольник на поверхности куба (например, AGH находится «внутри» куба), поэтому координат его вершин недостаточно для его описания; нам нужно также составить список треугольников, составленных из этих вершин:
A, B, C
A, C, D
E, A, D
E, D, H
F, E, H
F, H, G
B, F, G
B, G, C
E, F, B
E, B, A
C, G, H
C, H, DЭто показывает, что есть структура, которую можно использовать для представления любого составленного из треугольников объекта: список координат вершин и список треугольников, определяющий, какое множество из трёх вершин образует треугольники объекта.
Каждая запись в списке треугольников может содержать дополнительную информацию о треугольниках; например, мы можем хранить в нём цвет каждого треугольника.
Поскольку наиболее естественным способом хранения этой информации будут два списка, мы используем индексы списка в качестве ссылок на список вершин. То есть вышеприведённый куб можно представить следующим образом:
Vertexes
0 = ( 1, 1, 1)
1 = (-1, 1, 1)
2 = (-1, -1, 1)
3 = ( 1, -1, 1)
4 = ( 1, 1, -1)
5 = (-1, 1, -1)
6 = (-1, -1, -1)
7 = ( 1, -1, -1)
Triangles
0 = 0, 1, 2, red
1 = 0, 2, 3, red
2 = 4, 0, 3, green
3 = 4, 3, 7, green
4 = 5, 4, 7, blue
5 = 5, 7, 6, blue
6 = 1, 5, 6, yellow
7 = 1, 6, 2, yellow
8 = 4, 5, 1, purple
9 = 4, 1, 0, purple
10 = 2, 6, 7, cyan
11 = 2, 7, 3, cyanОтрендерить представленный таким образом объект довольно просто: сначала мы проецируем каждую вершину, сохраняем их во временном списке «спроецированных вершин»; затем мы проходим по списку треугольников, рендеря каждый отдельный треугольник. В первом приближении это будет выглядеть так:
RenderObject(vertexes, triangles) {
projected = []
for V in vertexes {
projected.append(ProjectVertex(V))
}
for T in triangles {
RenderTriangle(T, projected)
}
}
RenderTriangle(triangle, projected) {
DrawWireframeTriangle(projected[triangle.v[0]],
projected[triangle.v[1]],
projected[triangle.v[2]],
triangle.color)
}Мы не можем просто применить этот алгоритм к кубу, как есть, и надеяться на правильное отображение — некоторые из вершин находятся за камерой; а это, как мы уже видели, приводит к странному поведению. На самом деле, камера находится внутри куба.
Поэтому мы просто переместим куб. Чтобы сделать это, нам просто нужно сдвинуть каждую вершину куба в одном направлении. Давайте назовём этот вектор
 , сокращённо от Translation. Давайте просто переместим куб на 7 единиц вперёд, чтобы он точно полностью был перед камерой, и на 1,5 единицы влево, чтобы он выглядел интереснее. Поскольку «вперёд» — это направление , а «влево» —
, сокращённо от Translation. Давайте просто переместим куб на 7 единиц вперёд, чтобы он точно полностью был перед камерой, и на 1,5 единицы влево, чтобы он выглядел интереснее. Поскольку «вперёд» — это направление , а «влево» —  , то вектор перемещения будет иметь следующий вид
, то вектор перемещения будет иметь следующий вид
Чтобы получить перемещённую версию
 каждой точки
каждой точки  куба, нам нужно просто прибавить вектор перемещения:
куба, нам нужно просто прибавить вектор перемещения:
На этом этапе мы можем взять куб, переместить каждую вершину, а затем применить приведённый выше алгоритм, чтобы получить наконец наш первый 3D-куб:

Исходный код и рабочее демо >>
Модели и экземпляры
Но что если нам нужно отрендерить два куба?
Наивным подходом было бы создание ещё одного множества вершин и треугольников, описывающих второй куб. Это сработает, но займёт много памяти. А если мы захотим отрендерить миллион кубов?
Умнее будет думать в категориях моделей и экземпляров. Модель — это множество вершин и треугольников, описывающее объект как он есть (то есть "куб состоит из следующего множества вершин и треугольников"). С другой стороны, экземпляр модели — это конкретная реализация модели в некоторой позиции сцены (то есть "в (0, 0, 5) есть куб").
Преимущество второго подхода заключается в том, что каждый объект в сцене достаточно задать только один раз, после чего в сцену можно поместить произвольное количество экземпляров, просто описывая их позиции внутри сцены.
Вот грубое приближение того, как может быть описана подобная сцена:
model {
name = cube
vertexes {
...
}
triangles {
...
}
}
instance {
model = cube
position = (0, 0, 5)
}
instance {
model = cube
position = (1, 2, 3)
}Чтобы отрендерить её, нам нужно просто пройти по списку экземпляров; для каждого экземпляра создать копию вершин модели, применить к ним позицию экземпляра, а затем действовать как раньше:
RenderScene() {
for I in scene.instances {
RenderInstance(I);
}
}
RenderInstance(instance) {
projected = []
model = instance.model
for V in model.vertexes {
V' = V + instance.position
projected.append(ProjectVertex(V'))
}
for T in model.triangles {
RenderTriangle(T, projected)
}
}Заметьте, что для работы этого алгоритма координаты вершин модели должны быть определены в системе координат, «логичной» для объекта (это называется пространством модели). Например, куб определён таким образом, что его центр находится в (0, 0, 0); это значит, что когда мы говорим "куб расположен в (1, 2, 3)", мы имеем в виду "куб центрирован относительно (1, 2, 3)". При задании пространства модели нет никаких жёстких правил; в основном оно зависит от применения. Например, если у вас есть модель человека, то логично будет расположить точку начала координат у подошв его ног. Передвинутые вершины теперь будут выражаться в «абсолютной» системе координат сцены (называемой пространством мира).
Вот два куба:
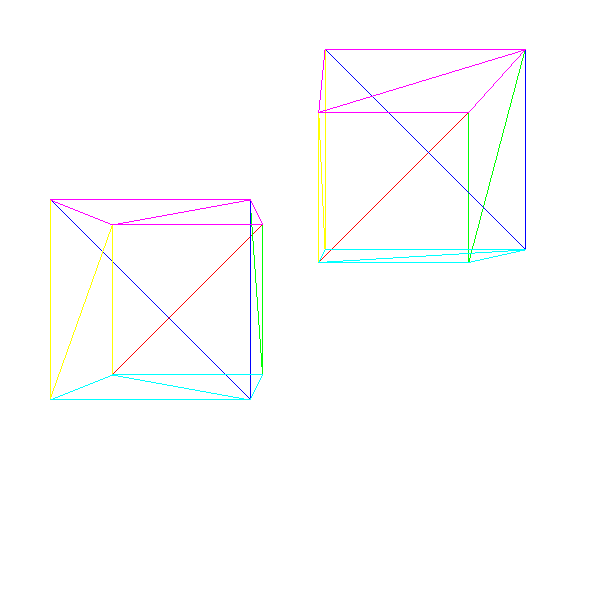
Исходный код и рабочее демо >>
Преобразование моделей
Данное выше определение сцены достаточно сильно нас ограничивает; в частности, поскольку мы можем указать только позицию куба, то способны создать сколько угодно экземпляров кубов, но все они будут ориентированы одинаково. В общем случае нам нужно иметь больше контроля над экземплярами; нам также хочется задавать их ориентацию, а возможно и масштаб.
Концептуально, мы можем задать преобразование модели точно с этими тремя элементами: коэффициентом масштаба, поворотом относительно точки начала координат пространства модели и перемещения в определённую точку сцены:
instance {
model = cube
transform {
scale = 1.5
rotation = <45 degrees around the Y axis>
translation = (1, 2, 3)
}
}Можно с лёгкостью расширить предыдущую версию псевдокода, добавив новые преобразования. Однако важен порядок применения этих преобразований; в частности, перемещение необходимо выполнять последним. Вот поворот на
 вокруг точки начала координат, за которым следует перемещение вдоль оси Z:
вокруг точки начала координат, за которым следует перемещение вдоль оси Z: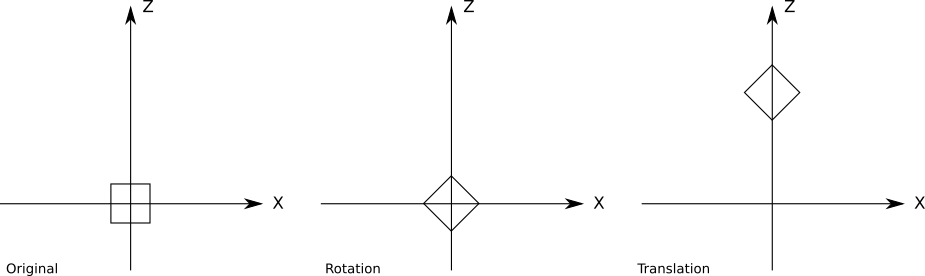
А вот перемещение, применённое до поворота:

Мы можем написать более общую версию
RenderInstance():RenderInstance(instance) {
projected = []
model = instance.model
for V in model.vertexes {
V' = ApplyTransform(V, instance.transform);
projected.append(ProjectVertex(V'))
}
for T in model.triangles {
RenderTriangle(T, projected)
}
}Метод
ApplyTransform() выглядит следующим образом:ApplyTransform(vertex, transform) {
V1 = vertex * transform.scale
V2 = V1 * transform.rotation
V3 = V2 + transform.translation
return V3
}Поворот выражается как матрица 3x3; если вы не знакомы с матрицами поворота, то пока считайте, что любой 3D-поворот можно представить как произведение точки на матрицу 3x3. См. подробнее в курсе линейной алгебры.
Преобразование камеры
В предыдущих разделах мы узнали, как можно расположить экземпляры моделей в разных точках сцены. В этом разделе мы узнаем, как двигать и поворачивать камеру в сцене.
Представьте, что вы висите посередине совершенно пустой системы координат. Всё окрашено в чёрный цвет. Внезапно прямо перед вами появляется красный куб. Мгновение спустя куб приближается на одну единицу к вам. Но приблизился ли куб к вам? Или вы сами передвинулись на одну единицу к кубу?
Поскольку у нас нет отправной точки, а систему координат не видно, мы никак не можем определить, что случилось.
Теперь куб повернулся вокруг вас на
по часовой стрелке. Но так ли это? Возможно, это вы повернулись вокруг него на против часовой стрелки? Мы снова не можем определить это.Этот мысленный эксперимент показывает нам, что нет никакой разницы между перемещением камеры по фиксированной сцене и неподвижной камерой в движущейся и поворачивающейся вокруг неё сцене!
Преимущество такого очевидно эгоистичного видения вселенной заключается в том, что при фиксированной в точке начала координат камере, смотрящей в направлении
, мы можем без всяких изменений сразу же использовать уравнения проецирования, выведенные в предыдущей главе. Система координат камеры называется пространством камеры.Будем считать, что у камеры тоже есть преобразование, состоящее из перемещения и поворота (масштаб мы опустим). Чтобы отрендерить сцену с точки обзора камеры, нам нужно применить к каждой вершине в сцене обратные преобразования:
V1 = V - camera.translation
V2 = V1 * inverse(camera.rotation)
V3 = perspective_projection(V2)Матрица преобразований
Давайте сделаем шаг назад и разберёмся, что происходит с вершиной
в пространстве модели, пока она не будет спроецирована в точку на холсте  .
.Сначала мы применяем преобразование модели, чтобы перейти из пространства модели в пространство мира:
V1 = V * instance.rotation
V2 = V1 * instance.scale
V3 = V2 + instance.translationЗатем мы применяем преобразование камеры, чтобы перейти из пространства мира в пространство камеры:
V4 = V3 - camera.translation
V5 = V4 * inverse(camera.rotation)Затем мы применяем уравнения перспективы:
vx = V5.x * d / V5.z
vy = V5.y * d / V5.zИ наконец мы привязываем координаты окна просмотра к координатам холста:
cx = vx * cw / vw
cy = vy * ch / vhКак вы видите, это довольно большой объём вычислений и для каждой вершины вычисляется множество промежуточных значений. Разве не будет удобно, если мы сократим всё это до единственного матричного произведения — возьмём
, умножим её на какую-нибудь матрицу и получим непосредственно  с
с  ?
?Давайте выразим преобразования в виде функций, получающих вершину и возвращающих преобразованную вершину. Пусть
 и
и  будут перемещением и поворотом камеры,
будут перемещением и поворотом камеры,  ,
,  и
и  — поворотом, масштабом и перемещением экземпляра, — перспективной проекцией, а — размещением окна просмотра на холсте. Если — это исходная вершина, а — точка на холсте, то мы можем выразить все вышеуказанные уравнения следующим образом:
— поворотом, масштабом и перемещением экземпляра, — перспективной проекцией, а — размещением окна просмотра на холсте. Если — это исходная вершина, а — точка на холсте, то мы можем выразить все вышеуказанные уравнения следующим образом:
В идеале нам бы хотелось иметь единственное преобразование, выполняющее то же, что и серия исходных преобразований, но имеющее гораздо более простое выражение:


Нахождение одной матрицы, представляющей
 , является нетривиальной задачей. Основная проблема заключается в том, что преобразования выражаются различными способами: перемещение — это сумма точки и вектора, поворот и масштаб — это произведение точки и матрицы 3x3, а в перспективной проекции используется деление. Но если мы сможем выразить все преобразования одним способом, и такой способ будет иметь простой механизм для создания преобразований, то мы получим то, что нам нужно.
, является нетривиальной задачей. Основная проблема заключается в том, что преобразования выражаются различными способами: перемещение — это сумма точки и вектора, поворот и масштаб — это произведение точки и матрицы 3x3, а в перспективной проекции используется деление. Но если мы сможем выразить все преобразования одним способом, и такой способ будет иметь простой механизм для создания преобразований, то мы получим то, что нам нужно.Однородные координаты
Рассмотрим выражение
 . представляет собой 3D-точку или 3D-вектор? Нет никакого способа узнать это, не имея дополнительного контекста.
. представляет собой 3D-точку или 3D-вектор? Нет никакого способа узнать это, не имея дополнительного контекста.Но давайте примем следующую договорённость: мы добавим к представлению четвёртый компонент, называемый
 . Если
. Если  , то мы говорим о векторе. Если
, то мы говорим о векторе. Если  , то мы говорим о точке. То есть точка недвусмысленно представляется в виде
, то мы говорим о точке. То есть точка недвусмысленно представляется в виде  , а вектор
, а вектор  представляется в виде
представляется в виде  . Поскольку точки и векторы имеют общее представление, это называется однородными координатами (Примечание: однородные координаты имеют гораздо более глубокую и подробную геометрическую интерпретацию, но она не относится к тематике нашей статьи; здесь мы просто используем их как удобный инструмент с определёнными свойствами.).
. Поскольку точки и векторы имеют общее представление, это называется однородными координатами (Примечание: однородные координаты имеют гораздо более глубокую и подробную геометрическую интерпретацию, но она не относится к тематике нашей статьи; здесь мы просто используем их как удобный инструмент с определёнными свойствами.).Такое представление имеет большой геометрический смысл. Например, при вычитании двух точек получается вектор:

При сложении двух векторов получается вектор:

Аналогично, можно легко увидеть, что при суммировании точки и вектора мы получаем точку, умножение вектора на скаляр даёт вектор, и так далее.
А что же представляют собой координаты с
, не равным ни  , ни ? Они тоже представляют точки; на самом деле, любая точка в 3D имеет бесконечное количество представлений в однородных координатах. Важно соотношение между координатами и значением ; то есть,
, ни ? Они тоже представляют точки; на самом деле, любая точка в 3D имеет бесконечное количество представлений в однородных координатах. Важно соотношение между координатами и значением ; то есть,  и
и  представляют одну и ту же точку, как
представляют одну и ту же точку, как  .
.Из всех этих представлений мы можем назвать представление с
каноническим представлением точки в однородных координатах; преобразование любого другого представления к её каноническому представлению или в декартовы координаты — тривиальная задача:
То есть мы можем преобразовать декартовы координаты в однородные координаты, и обратно в декартовы координаты. Но как это поможет нам найти единое представление для всех преобразований?
Однородная матрица поворота
Давайте начнём с матрицы поворота. Выражение декартовой матрицы поворота 3x3 в однородных координатах тривиально; поскольку координата
точки не должна меняться, мы добавим столбец справа, строку внизу, заполним их нулями и поместим в правый нижний элемент , чтобы хранить значение :
Однородная матрица масштаба
Матрица масштабирования тоже тривиальна в однородных координатах, и она создаётся точно так же, как и матрица поворота:

Однородная матрица трансляции
Предыдущие примеры были простыми; они уже были представлены как умножения матриц в декартовых координатах, нам достаточно было добавить
, чтобы сохранить координату . Но что нам делать с перемещением, которое мы выражали в декартовых координатах как сложение?Нам нужна такая матрица 4x4, что

Давайте сначала сосредоточимся на получении
 . Это значение — результат умножения первой строки матрицы на точку, то есть
. Это значение — результат умножения первой строки матрицы на точку, то есть
Если мы раскроем векторное произведение, то получим

И из этого мы можем вывести, что
 ,
,  , а
, а  .
.Применив те же рассуждения к остальным координатам, мы получим следующее матричное выражение для перемещения:

Однородная матрица проецирования
Сумму и произведение можно просто выразить как произведения матриц и векторов, которые являются суммами и произведениями. Но в уравнениях перспективного проецирования используется деление на
 . Как его выразить?
. Как его выразить?Есть большое искушение посчитать, что деление на
— это то же самое, что и умножение на  , что на самом деле правда; но в нашем случае это бесполезно, потому что координата конкретной точки не может находиться в матрице проецирования, применяемой к каждой точке.
, что на самом деле правда; но в нашем случае это бесполезно, потому что координата конкретной точки не может находиться в матрице проецирования, применяемой к каждой точке.К счастью, в однородных координатах присутствует один случай деления: деление на координату
при обратном преобразовании в декартовы координаты. Так что есть нам удастся превратить координату исходной точки в координату «спроецированной» точки, то мы получим спроецированные и после преобразования точки обратно в декартовы координаты:
Заметьте, что эта матрица имеет размер
 ; её можно умножить на четырёхэлементный вектор (преобразованную 3D-точку в однородных координатах), получив при этом трёхэлементный вектор (спроецированную 2D-точку в однородных координатах), который затем преобразуется в двухмерные декартовы координаты делением на . Это даст нам точные значения
; её можно умножить на четырёхэлементный вектор (преобразованную 3D-точку в однородных координатах), получив при этом трёхэлементный вектор (спроецированную 2D-точку в однородных координатах), который затем преобразуется в двухмерные декартовы координаты делением на . Это даст нам точные значения  и
и  , которые мы ищем.
, которые мы ищем.Здесь не хватает
 , которая, как мы знаем, по определению является .
, которая, как мы знаем, по определению является .Используя рассуждения, похожие на те, которые мы применяли для выведения матрицы трансляции, мы можем выразить перспективную проекцию как

Однородная матрица из окна просмотра на холст
Последний этап — размещение спроецированной на окно просмотра точки на холст. Это просто двухмерное преобразование масштаба с
 и
и  . То есть матрица будет следующей
. То есть матрица будет следующей
На самом деле её легко скомбинировать с матрицей проецирования и получить простую матрицу преобразования из 3D в холст:

Практическое применение
Из практических соображений мы не будем использовать матрицу проецирования. Вместо этого мы используем преобразования модели и камеры, а затем преобразуем их результаты обратно в декартовы координаты следующим образом:


Это позволит нам выполнить ещё и другие операции в 3D до проецирования точек, которые нельзя выразить как матричные преобразования.
Снова матрица преобразования
Так как теперь мы можем выразить любое 3D-преобразование исходной вершины
, выполняемое до проецирования как матрицы 4x4, мы можем тривиально объединить все эти преобразования в единую матрицу 4x4, перемножив их:
И тогда преобразование вершины — просто вопрос вычисления следующего произведения:

Более того, мы можем разложить преобразование на две части:



Эти матрицы не нужно вычислять для каждой вершины (в этом и заключается смысл использования матрицы). На самом деле, их даже не обязательно вычислять в каждом кадре.
 может изменяться каждый кадр; это зависит от камеры позиции и ориентации, поэтому если камера двигается или поворачивается, то её необходимо пересчитать. Однако после вычисления она остаётся постоянной для каждого объекта, отрисованного в кадре, поэтому она будет вычисляться максимум один раз за кадр.
может изменяться каждый кадр; это зависит от камеры позиции и ориентации, поэтому если камера двигается или поворачивается, то её необходимо пересчитать. Однако после вычисления она остаётся постоянной для каждого объекта, отрисованного в кадре, поэтому она будет вычисляться максимум один раз за кадр. зависит от преобразования экземпляра модели, и поэтому используемая матрица будет меняться только один раз для объекта в сцене; однако она будет оставаться постоянной для неподвижных объектов (например, деревьев, зданий), поэтому её можно вычислить заранее и хранить в самой сцене. Для подвижных объектов (например, для машин в гоночной игре) она всё равно должна вычисляться каждый раз, когда они двигаются (обычно в каждом кадре).
зависит от преобразования экземпляра модели, и поэтому используемая матрица будет меняться только один раз для объекта в сцене; однако она будет оставаться постоянной для неподвижных объектов (например, деревьев, зданий), поэтому её можно вычислить заранее и хранить в самой сцене. Для подвижных объектов (например, для машин в гоночной игре) она всё равно должна вычисляться каждый раз, когда они двигаются (обычно в каждом кадре).На очень высоком уровне псевдокод рендеринга сцены будет выглядеть так:
RenderModel(model, transform) {
projected = []
for V in model.vertexes {
projected.append(ProjectVertex(transform * V))
}
for T in model.triangles {
RenderTriangle(T, projected)
}
}
RenderScene() {
MCamera = MakeCameraMatrix(camera.position, camera.orientation)
for I in scene.instances {
M = MCamera*I.transform
RenderModel(I.model, M)
}
}Теперь мы можем отрисовать сцену, содержащую несколько экземпляров различных моделей, возможно, двигающихся и поворачивающихся, и можем двигать камеру по сцене.
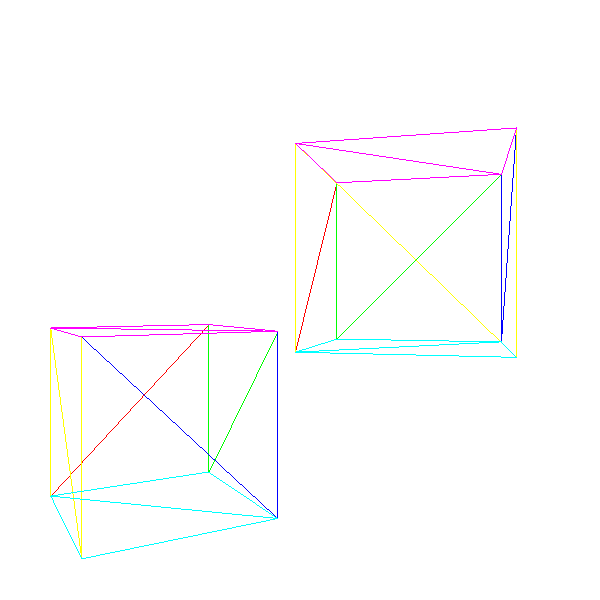
Исходный код и рабочее демо >>
Мы сделали большой шаг вперёд, но у нас по-прежнему есть два важных ограничения. Во-первых, при движении камеры объекты могут оказаться за ней, что создаёт всевозможные проблемы. Во-вторых, результат рендеринга выглядит не очень хорошо: он по-прежнему каркасный.
В следующей главе мы разберёмся с объектами, которые не должны быть видимы, а затем потратим оставшееся время на улучшение внешнего вида отрендеренных объектов.
Отсечение
В главе Перспективная проекция мы получили следующие уравнения:
Деление на
 вызывает проблемы; при нём может возникнуть деление на ноль. Также при нём могут получаться отрицательные значения, представляющие точки за камерой, которые обрабатываются неправильно. Даже точки, находящиеся перед камерой, но очень близко, могут вызывать проблемы в виде сильно искажённых объектов.
вызывает проблемы; при нём может возникнуть деление на ноль. Также при нём могут получаться отрицательные значения, представляющие точки за камерой, которые обрабатываются неправильно. Даже точки, находящиеся перед камерой, но очень близко, могут вызывать проблемы в виде сильно искажённых объектов.Чтобы избежать всех этих проблемных случаев, мы решили не рендерить ничего за плоскость проекции
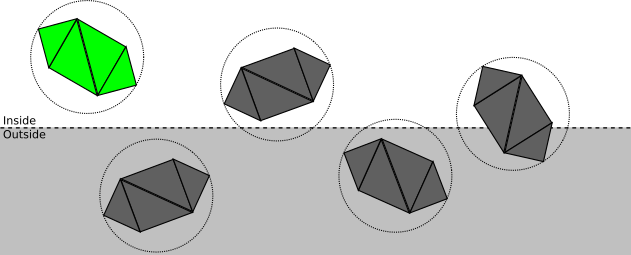
. Эта плоскость отсечения позволяет разделить все точки на находящиеся внутри или снаружи объёма отсечения, то есть подмножества пространства, которое на самом деле видно из камеры. В этом случае объём отсечения — это "полупространство перед ". Мы рендерим только части сцены, которые находятся внутри объёма отсечения.Чем меньше операций мы делаем, тем быстрее будет наш рендерер, поэтому мы используем подход «сверху вниз». Рассмотрим сцену с несколькими объектами, каждый из которых состоит из четырёх треугольников.
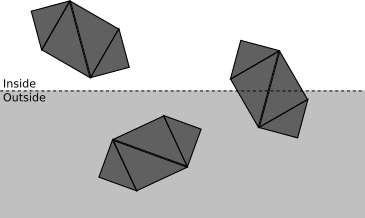
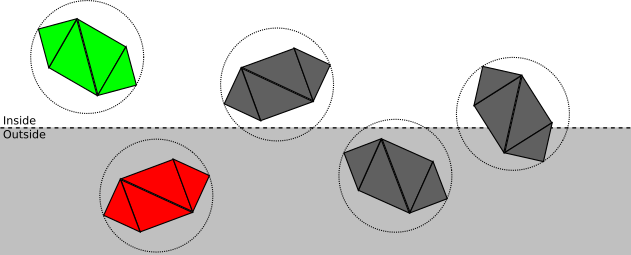
На каждом этапе мы стремимся как можно менее затратно определить, можно ли остановить отсечение на этой точке, или требуется дальнейшее и более подробное отсечение:
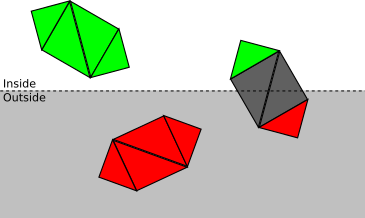
- Если объект полностью находится внутри объёма отсечения, то он принимается (выделен зелёным); если он полностью снаружи, то отбрасывается (красный):
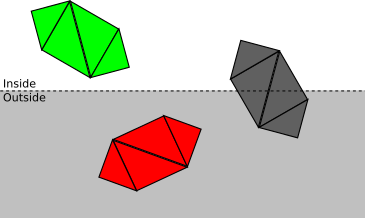
- В противном случае мы повторяем процесс для каждого треугольника. Если треугольник полностью находится внутри объёма отсечения, то он принимается, если полностью снаружи, то отбрасывается:
- В противном случае, нам нужно разбить сам треугольник. Исходный треугольник отбрасывается, и добавляются один или два треугольника, закрывающие часть треугольника, находящуюся внутри объёма отсечения:

Теперь мы подробноее рассмотрим каждый этап в процессе выполнения.
Задание плоскостей отсечения
Первое, что нужно сделать — найти уравнение плоскости отсечения. Нет ничего плохого в
, но это не самый удобный формат для наших целей; ниже в этой главе мы выработаем более общий подход к другим плоскостям отсечения, так что нам нужно придумать общий подход вместо этого конкретного случая.Общее уравнение 3D-плоскости имеет вид
 . Оно означает, что точка
. Оно означает, что точка  будет удовлетворять уравнению тогда и только тогда, когда находится на плоскости. Мы можем переписать уравнение как
будет удовлетворять уравнению тогда и только тогда, когда находится на плоскости. Мы можем переписать уравнение как  , где
, где  .
.Заметьте, что если
, то  при любом значении
при любом значении  . В частности, мы можем выбрать
. В частности, мы можем выбрать  и получить новое уравнение
и получить новое уравнение  , где
, где  — единичный вектор. То есть для любой заданной плоскости мы можем считать, что существует единичный вектор
— единичный вектор. То есть для любой заданной плоскости мы можем считать, что существует единичный вектор  и вещественное число
и вещественное число  такие, что
такие, что  является уравнением этой плоскости.
является уравнением этой плоскости.Это очень удобная формулировка:
на самом деле является нормалью плоскости, а  — расстояние со знаком от точки начала координат до плоскости. На самом деле, для любой точки
— расстояние со знаком от точки начала координат до плоскости. На самом деле, для любой точки  является расстоянием со знаком от до плоскости; легко увидеть, что — это особый случай, при котором лежит на плоскости.
является расстоянием со знаком от до плоскости; легко увидеть, что — это особый случай, при котором лежит на плоскости.Как мы видели ранее, если
— это нормаль к плоскости, как и  , поэтому мы выбираем такую, что она направлена «внутрь» объёма отсечения. Для плоскости мы выбираем нормаль
, поэтому мы выбираем такую, что она направлена «внутрь» объёма отсечения. Для плоскости мы выбираем нормаль  , которая направлена «вперёд» относительно камеры. Поскольку точка
, которая направлена «вперёд» относительно камеры. Поскольку точка  лежит на плоскости, она должна удовлетворять уравнению плоскости, мы можем вычислить её, зная :
лежит на плоскости, она должна удовлетворять уравнению плоскости, мы можем вычислить её, зная :
то есть
 (Примечание: можно было тривиально получить это из , переписав его как
(Примечание: можно было тривиально получить это из , переписав его как  . Однако представленные здесь рассуждения относятся и ко всем остальным плоскостям, с которыми мы будем иметь дело, и это позволяет нам справиться с тем, что
. Однако представленные здесь рассуждения относятся и ко всем остальным плоскостям, с которыми мы будем иметь дело, и это позволяет нам справиться с тем, что  тоже справедливо, но нормаль направлена в неправильном направлении.).
тоже справедливо, но нормаль направлена в неправильном направлении.).Объём отсечения
Хотя при использовании одной плоскости отсечения, позволяющей гарантировать, что объекты за камерой не будут рендериться, мы получаем правильные результаты, это не совсем эффективно. Некоторые объекты могут находиться перед камерой, но всё равно не быть видимыми; например, проекция объекта рядом с плоскостью проекции, но расположенная очень далеко вправо, выпадет из окна просмотра, и потому будет невидимой:
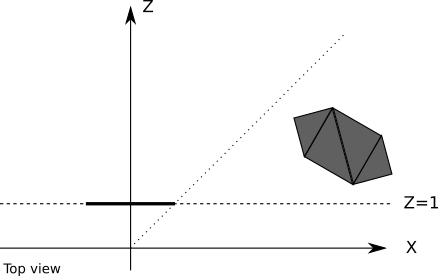
Все ресурсы, которые мы используем для вычисления проекции такого объекта, а также вычисления для треугольников и вершин, выполненные для его рендеринга, будут потрачены зря. Нам будет гораздо удобнее полностью игнорировать такие объекты.
К счастью, это совсем не сложно. Мы можем задать дополнительные плоскости, отсекающие сцену ровно до того, что будет видимо из окна просмотра; такие плоскости задаются камерой и обеими сторонами окна просмотра:
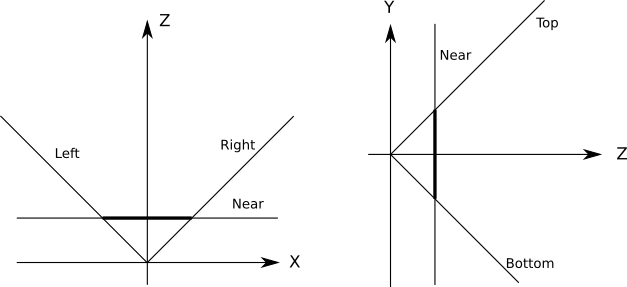
Все эти плоскости имеют
 (потому что точка начала координат находится на всех плоскостях), поэтому нам остаётся только определить нормали. Простейшим случаем будет FOV
(потому что точка начала координат находится на всех плоскостях), поэтому нам остаётся только определить нормали. Простейшим случаем будет FOV  , при которой плоскости находятся на , поэтому их нормали
, при которой плоскости находятся на , поэтому их нормали  для левой плоскости,
для левой плоскости,  для правой плоскости,
для правой плоскости,  для нижней и
для нижней и  для верхней плоскостей. Для вычисления плоскостей отсечения для любой произвольной FOV требует только небольшого количества тригонометрических вычислений.
для верхней плоскостей. Для вычисления плоскостей отсечения для любой произвольной FOV требует только небольшого количества тригонометрических вычислений.Для отсечения объектов или треугольников по объёму отсечения нам достаточно отсечь их по порядку каждой плоскостью. Все объекты, «выжившие» после отсечения одной плоскостью, отсекаются остальными плоскостями; это срабатывает, потому что объём отсечения является пересечением полупространств, задаваемых каждой плоскостью отсечения.
Отсечение целых объектов
Полностью задав объём отсечения его плоскостями отсечения, мы можем начать с определения того, находится ли объект полностью внутри или снаружи полупространства, задаваемого каждой из этих плоскостей.
Допустим, мы поместим каждую модель внутрь наименьшей сферы, которая может его содержать. Мы не будем рассматривать в статье, как это можно сделать; сферу можно вычислить из множества вершин одним из нескольких алгоритмов, или же приближение может быть задано разработчиком модели. В любом случае, будем считать, что у нас есть центр
и радиус  сферы, которая полностью содержит каждый объект:
сферы, которая полностью содержит каждый объект:
Мы можем разбить пространственные отношения между сферой и плоскостью на следующие категории:
- Сфера целиком находится перед плоскостью. В этом случае модель принимается; дальнейшего отсечения относительно плоскости не требуется (однако она всё равно может отсекаться другой плоскостью):
- Сфера целиком находится за плоскостью. В этом случае модель отбрасывается; дальнейшее отсечение не требуется (не важно, какими являются другие плоскости — ни одна часть модели не попадаёт внутрь объёма отсечения):
- Плоскость пересекается со сферой. Это не даёт нам достаточной информации о том, какие части объекта находятся внутри объёма отсечения; он может целиком находиться внутри, полностью снаружи, или частично внутри. Необходимо перейти к следующему этапу и отсечь модель треугольник за треугольником.
Как же на самом деле выполняется это разбиение на категории? Мы выбрали способ выражения плоскостей отсечения таким образом, что подстановка любой точки в уравнение плоскости даёт нам расстояние со знаком от точки до плоскости; в частности, мы можем вычислить расстояние со знаком
от центра ограничивающей сферы до плоскости. Поэтому если  , то сфера находится перед плоскостью; если
, то сфера находится перед плоскостью; если  , то сфера находится за плоскостью; в противном случае
, то сфера находится за плоскостью; в противном случае  , то есть плоскость пересекается со сферой.
, то есть плоскость пересекается со сферой.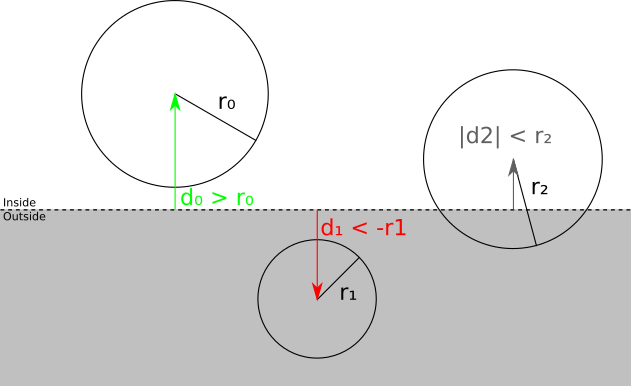
Отсечение треугольников
Если проверки сфера-плоскость недостаточно для определения того, находится ли объект полностью перед или полностью за плоскостью отсечения, то необходимо отсечь относительно неё каждый треугольник.
Мы можем классифицировать каждую вершину треугольника относительно плоскости отсечения, взяв знак расстояния со знаком до плоскости. Если расстояние равно нулю или положительно, то вершина находится перед плоскостью отсечения, в противном случае — за ней:
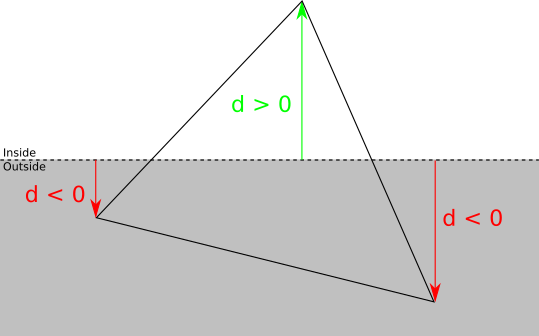
Существует четыре возможных случая:
- Три вершины находятся перед плоскостью. В таком случае весь треугольник находится перед плоскостью отсечения, поэтому он принимается без дальнейшего отсечения относительно этой плоскости.
- Три вершины находятся за плоскостью. В этом случае весь треугольник находится за плоскостью отсечения, поэтому он отбрасывается без дальнейших отсечений.
- Одна вершина находится перед плоскостью. Пусть — вершина треугольника
 , которая находится перед плоскостью. В этом случае отбрасывается, и добавляется новый треугольник
, которая находится перед плоскостью. В этом случае отбрасывается, и добавляется новый треугольник  , где
, где  и
и  — пересечения и
— пересечения и  с плоскостью отсечения.
с плоскостью отсечения.
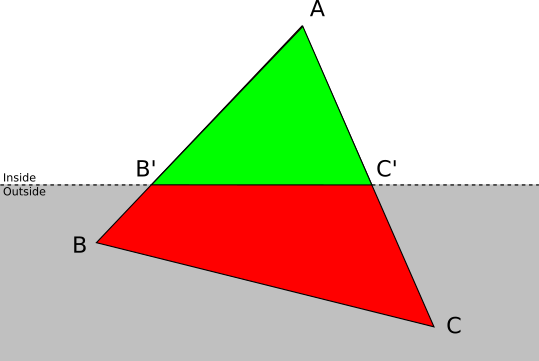
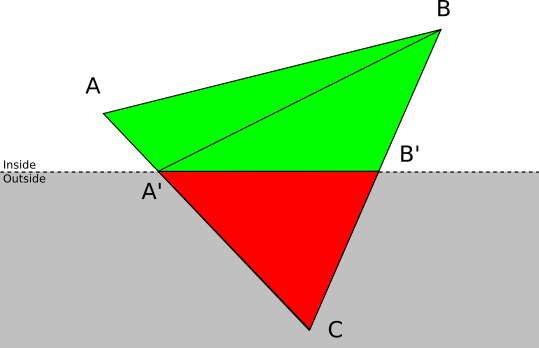
- Две вершины находятся перед плоскостью. Пусть и — вершины треугольника , находящиеся перед плоскостью. В этом случае ABC отбрасывается, и добавляются два новых треугольника:
 и
и  , где
, где  и — пересечения и
и — пересечения и  с плоскостью отсечения.
с плоскостью отсечения.
Пересечение отрезка и плоскости
Чтобы выполнить отсечение для каждого треугольника, нам нужно вычислить пересечение сторон треугольника с плоскостью отсечения. Надо заметить, что недостаточно вычислить координаты пересечения: необходимо также вычислить соответствующее значение атрибутов, связанных с вершинами, например, затенения, которое мы делали в главе Отрисовка затенённых треугольников, или одного из атрибутов, описанных в последующих главах.
У нас есть плоскость отсечения, заданная уравнением
 . Сторону треугольника можно выразить с помощью параметрического уравнения как
. Сторону треугольника можно выразить с помощью параметрического уравнения как  при
при  . Для вычисления значения параметра , при котором происходит пересечение, мы заменим в уравнении плоскости на параметрическое уравнение отрезка:
. Для вычисления значения параметра , при котором происходит пересечение, мы заменим в уравнении плоскости на параметрическое уравнение отрезка:
Воспользовавшись линейными свойствами скалярного произведения, получаем:

Вычисляем
:
Мы знаем, что решение существует всегда, потому что
пересекает плоскость; математически  не может быть нулём, потому что это будет подразумевать, что отрезок и нормаль перпендикулярны, что в свою очередь подразумевает, что отрезок и плоскость не пересекаются.
не может быть нулём, потому что это будет подразумевать, что отрезок и нормаль перпендикулярны, что в свою очередь подразумевает, что отрезок и плоскость не пересекаются.Вычислив
, мы получим, что пересечение  просто равно
просто равно
Заметьте, что
— это часть отрезка , в которой произошло пересечение. Пусть  и
и  будут значениями некоего атрибута
будут значениями некоего атрибута  в точках и ; если мы будем считать, что атрибут линейно изменяется вдоль , то
в точках и ; если мы будем считать, что атрибут линейно изменяется вдоль , то  можно просто вычислить как
можно просто вычислить как
Отсечение в конвейере
Порядок глав статьи не соответствует порядку операций, выполняемых в конвейере рендеринга; как объяснено во введении, главы расположены в таком порядке, чтобы можно было как можно быстрее достичь наглядного прогресса.
Отсечение — это 3D-операция; она получает два 3D-объекта в сцене и генерирует новое множество 3D-объектов в сцене, а именно, пересечение сцены и объёма отсечения. Должно быть понятно, что отсечение должно выполняться после того, как объекты были размещены в сцене (то есть использованы вершины после преобразований модели и камеры), но перед перспективным проецированием.
Представленные в этой главе техники надёжно работают, но они очень общие. Чем больше мы будем заранее знать о сцене, тем эффективнее будет отсечение. Например, многие игры предварительно обрабатывают игровые карты, добавляя на них информацию о видимости; если получится разделить сцену на «комнаты», то можно создать таблицу с перечислением комнат, видимых из каждой конкретной комнаты. При рендеринге сцены в дальнейшем вам просто нужно выяснить, в какой комнате находится камера, после чего можно игнорировать все комнаты, помеченные как «невидимые» из неё, экономя значительные ресурсы при рендеринге. Конечно, при этом приходится тратить больше времени на предварительную обработку, а сцена получается более жёстко заданной.
Удаление скрытых поверхностей
Теперь, когда мы можем отрендерить любую сцену с любой точки обзора, давайте усовершенствуем нашу каркасную графику.
Очевидным первым шагом будет придание сплошным объектам сплошного внешнего вида. Для этого давайте используем
DrawFilledTriangle() для отрисовки каждого треугольника случайным цветом, и посмотрим, что из этого получится: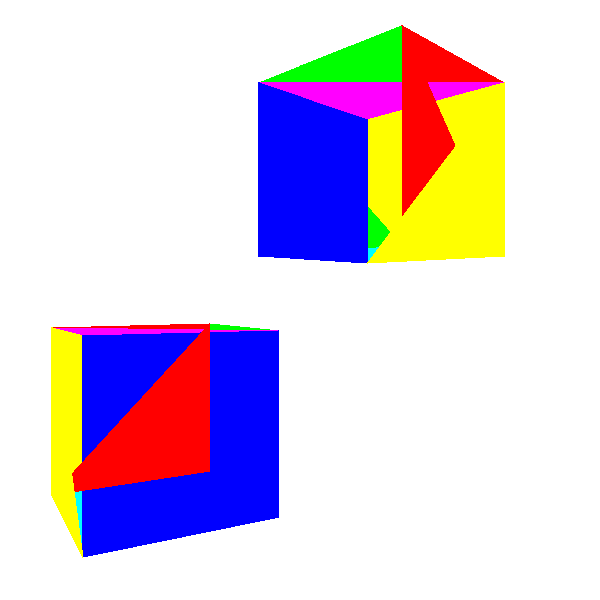
Не очень похоже на кубы, правда?
Проблема здесь в том, что некоторые треугольники, которые должны быть за другими, отрисовываются перед ними. Почему? Потому что мы просто отрисовываем 2D-треугольники на холсте практически в случайном порядке — в том порядке, который получился при задании модели.
Однако при задании треугольников модели нет «правильного» порядка. Предположим, что треугольники модели отсортированы таким образом, что сначала отрисовываются задние грани, а затем они перекрываются передними гранями. Мы получим ожидаемый результат. Однако если мы повернём куб на
 , то получим обратную ситуацию — дальние треугольники будут перекрывать ближние.
, то получим обратную ситуацию — дальние треугольники будут перекрывать ближние.Алгоритм художника
Первое решение этой проблемы известно как "алгоритм художника". Художники в реальном мире сначала отрисовывают фон, а затем закрывают его части передними объектами. Мы можем достичь того же эффекта, взяв каждый треугольник сцены, применив преобразования модели и камеры, отсортировав их сзади вперёд и отрисовав их в этом порядке.
Хотя при этом треугольники отрисуются в правильном порядке, этот алгоритм имеет недостатки, делающие его непрактичным.
Во-первых, он не очень хорошо масштабируется. Самый лучший алгоритм сортировки имеет скорость
 \), то есть время выполнения более чем удваивается при удвоении количества треугольников. Другими словами, он работает для небольших сцен, но быстро становится «узким местом» при увеличении сложности сцены.
\), то есть время выполнения более чем удваивается при удвоении количества треугольников. Другими словами, он работает для небольших сцен, но быстро становится «узким местом» при увеличении сложности сцены.Во-вторых, он требует одновременного знания всего списка треугольников. На это требуется много памяти, и не позволяет использовать потоковый подход к рендерингу. Если воспринимать рендеринг как конвейер, в котором треугольники модели входят с одного конца, а с другого выходят пиксели, то невозможно начать выводить пиксели, пока не будет обработан каждый треугольник. В свою очередь это означает, что мы не можем распараллелить этот алгоритм.
В-третьих, даже если вы смиритесь с этими ограничениями, то всё равно существуют случаи, когда правильного порядка треугольников не существует. Рассмотрим следующий случай:
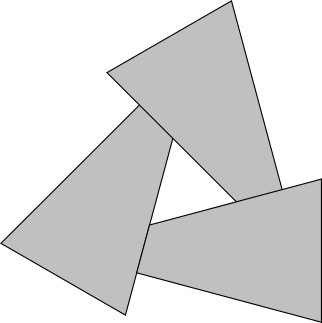
Неважно, в каком порядке вы будете отрисовывать эти треугольники — вы всегда будете получать неверный результат.
Буфер глубин
Если решение проблемы на уровне треугольников не срабатывает, то решение на уровне пикселей точно сработает, и в то же время оно преодолевает все ограничения алгоритма художника.
В сущности, каждый пиксель холста мы хотим закрасить «правильным» цветом. В этом случае, «правильный» цвет — это цвет ближайшего к камере объекта (в нашем случае
):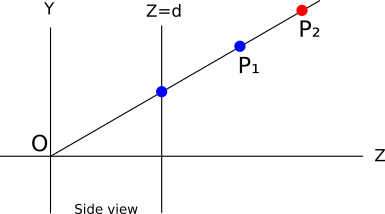
Оказывается, что мы можем запросто это сделать. Предположим, что мы храним значение
точки, в настоящее время представленной каждым пикселем холста. Когда мы решаем, стоит ли закрашивать пиксель определённым цветом, мы поступаем так только когда координата точки, которую мы собираемся закрашивать, меньше координаты точки, которая там уже есть.Представим такой порядок треугольников, при котором мы сначала хотим закрасить
, а потом . Пиксель закрашен красным, его помечена как  . Затем мы закрашиваем , и поскольку
. Затем мы закрашиваем , и поскольку  , пиксель перезаписывается синим цветом; мы получаем верные результаты.
, пиксель перезаписывается синим цветом; мы получаем верные результаты.Разумеется, мы получили верный результат вне зависимости от значений
. Что если мы хотели сначала закрасить , а потом ? Пиксель сначала закрасился синим, а  сохранилась; но затем мы хотим закрасить , и поскольку , мы не будем его закрашивать (потому что если бы это сделали, то закрасили бы удалённую точку, закрыв более близкую). Мы снова получаем синий пиксель, что является верным результатом.
сохранилась; но затем мы хотим закрасить , и поскольку , мы не будем его закрашивать (потому что если бы это сделали, то закрасили бы удалённую точку, закрыв более близкую). Мы снова получаем синий пиксель, что является верным результатом.С точки зрения реализации, нам нужен буфер для хранения координаты
каждого пикселя на холсте; он называется буфером глубин, и его размеры естественно равны размерам холста.Но откуда появляются значения
?Они должны быть значениями
точек после преобразования, но перед перспективным проецированием. Именно поэтому в главе Настройка сцены мы задали матрицы преобразования таким образом, что конечный результат содержит  .
.Итак, мы можем получить значения
из этих значений . Но у нас есть это значение только для вершин; нам нужно получить его для каждого пикселя.И это ещё один способ применения алгоритма присвоения атрибутов. Почему бы не использовать
в качестве атрибута и не интерполировать его вдоль грани треугольника? Вы уже знаете процедуру; берём значения Z0, Z1 и Z2, вычисляем Z01, Z02 и Z02, получаем из них z_left и z_right, а затем вычисляем z_segment для каждого пикселя каждого горизонтального отрезка. И вместо выполнения вслепую PutPixel(x, y, color) мы делаем следующее:z = z_segment[x - xl]
if (z < depth_buffer[x][y]) {
canvas.PutPixel(x, y, color)
depth_buffer[x][y] = z
}Чтобы это сработало,
depth_buffer должен быть инициализирован значениями  (или просто «очень большим значением»).
(или просто «очень большим значением»).Получаемые результаты теперь гораздо лучше:

Исходный код и рабочее демо >>
Почему 1/Z вместо Z
Но на этом история не заканчивается. Значения
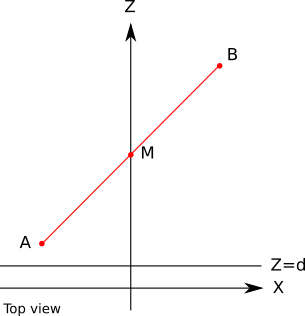
в вершинах верны (в конце концов, они получаются из данных), но в большинстве случаев линейно интерполированные значения для остальных пикселей будут неверными. Хотя такое приближение «достаточно хорошо» для буферизации глубин, в дальнейшем оно будет мешать.Чтобы проверить, насколько неверны значения, рассмотрим простой случай прямой из
 в
в  . Середина отрезка имеет координаты
. Середина отрезка имеет координаты  :
:
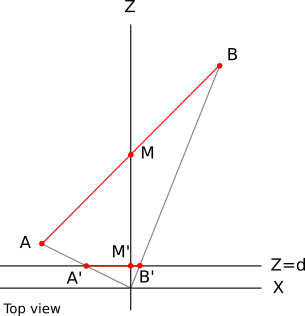
Давайте вычислим проекцию этих точек при
 .
.  . Аналогично,
. Аналогично,  и
и  :
:
Что теперь произойдёт, если мы линейно проинтерполируем значения
 и
и  для получения вычисленного значения для
для получения вычисленного значения для  ? Линейная функция выглядит так:
? Линейная функция выглядит так: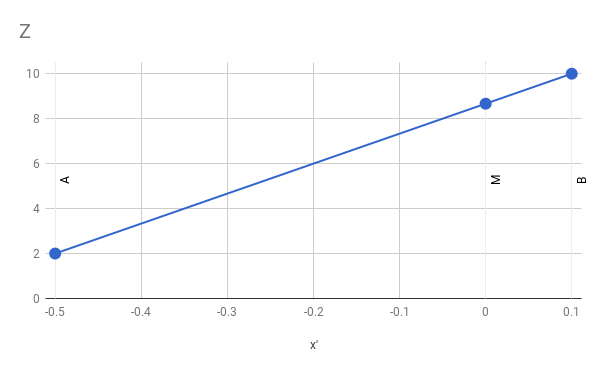
Из этого мы можем заключить, что


Если мы подставим числа и выполним арифметические вычисления, то получим

что очевидно не равно
 .
.Так в чём же проблема? Мы используем присвоение атрибутов, которое, как мы знаем, работает хорошо; мы передаём ему верные значения, которые получаются из данных; так почему же результаты неверны?
Проблема в том, что мы неявно подразумеваем, выполняя линейную интерполяцию: что интерполируемая нами функция линейна. А в нашем случае это не так!
Если
 была бы линейной функцией и , мы могли бы записать её как
была бы линейной функцией и , мы могли бы записать её как  для некоторого значения , и . Такой тип функций имеет следующее свойство: разность его значения между двумя точками зависит от разности между точками, а не от самих точек:
для некоторого значения , и . Такой тип функций имеет следующее свойство: разность его значения между двумя точками зависит от разности между точками, а не от самих точек:![$f(x' + \Delta x, y' + \Delta y) - f(x', y') = [A (x' + \Delta x) + B (y' + \Delta y) + C] - [A \cdot x' + B \cdot y' + C]$](https://habrastorage.org/getpro/habr/formulas/947/bca/90b/947bca90bdc8976c8cd0a363a815c493.svg)


То есть для заданной разности экранных координат разность
всегда будет одинаковой.Более формально, уравнение плоскости, содержащей изучаемый нами треугольник, имеет вид

С другой стороны, у нас есть уравнения перспективной проекции:


Мы можем снова получить из них
и :

Если мы заменим
и в уравнении плоскости этими выражениями, то получим
Умножив на
и выразив , получим


Что очевидно не является линейной функцией
и .Однако, если мы просто вычислим
, то получим
Что очевидно является линейной функцией от
и .Чтобы показать, что это действительно работает, вот приведённый выше пример, но на этот раз вычисленный с помощью линейной интерполяции
:


И следовательно

Что на самом деле является правильным значением.
Всё это значит, что для буферизации глубин мы должны вместо значений
использовать значения . Единственной практической разницей в псевдокоде будет то, что буфер должен инициализироваться значениями (то есть  ), а сравнение необходимо перевернуть (сохраняем большее значение , соответствующее меньшему значению ).
), а сравнение необходимо перевернуть (сохраняем большее значение , соответствующее меньшему значению ).Отсечение задних граней
Буферизация глубин даёт нам нужные результаты. Но можем ли мы добиться того же более быстрым способом?
Вернёмся к кубу: даже если каждый пиксель в результате получает правильный цвет, некоторые из них перерисовываются снова и снова несколько раз. Например, если задняя грань куба рендерится до передней грани, то многие пиксели будут закрашиваться дважды. С увеличением количества операций, выполняемых для каждого пикселя (пока мы вычисляем для каждого пикселя только
, но скоро добавим освещение, например), вычисление пикселей, которые никогда не окажутся видимыми, становится всё более и более затратным.Можем ли мы заранее отбросить пиксели, прежде чем выполнять все эти вычисления? Оказывается, мы можем отбрасывать целые треугольники ещё до того, как начнём отрисовку!
До этого момента мы говорили о передних гранях и задних гранях неформально. Представьте, что у каждого треугольника есть две стороны; одновременно мы можем видеть только одну из сторон треугольника. Чтобы разделить эти две стороны, мы добавим к каждому треугольнику стрелку, перпендикулярную его поверхности. Затем мы возьмём куб и убедимся, что каждая стрелка направлена наружу:
Теперь эта стрелка позволит нам классифицировать каждый треугольник как «передний» и «задний», в зависимости от того, направлен ли он к камере или от неё; если более формально, то если вектор просмотра и эта стрелка (на самом деле являющаяся вектором нормали треугольника) образуют угол соответственно меньше или больше
:
С другой стороны, наличие одинаково ориентированных двусторонних треугольников, позволяет нам задать то, что находится «внутри» и «снаружи» замкнутого объекта. По определению мы не должны видеть внутренние части замкнутого объекта. Это значит, что у любого замкнутого объекта вне зависимости от расположения камеры передние грани полностью перекрывают задние.
Что в свою очередь означает, что нам вообще не нужно отрисовывать задние грани, потому что они всё равно будут перерисовываться передними гранями!
Классификация треугольников
Давайте формализуем и реализуем это. Допустим, у нас есть вектор нормали треугольника
и вектор  из вершины треугольника к камере. Пусть указывает наружу объекта. Чтобы классифицировать треугольник как передний или задний, мы вычисляем угол между и , после чего проверим, находятся ли они в относительно друг друга.
из вершины треугольника к камере. Пусть указывает наружу объекта. Чтобы классифицировать треугольник как передний или задний, мы вычисляем угол между и , после чего проверим, находятся ли они в относительно друг друга.Мы снова можем воспользоваться свойствами скалярного произведения, чтобы ещё больше это упростить. Не забывайте, что если мы обозначим за
угол между и , то
Поскольку
 неотрицателен при
неотрицателен при  , для классификации грани как передней или задней нам достаточно только знать его знак. Стоит заметить, что
, для классификации грани как передней или задней нам достаточно только знать его знак. Стоит заметить, что  и
и  всегда положительны, поэтому они не влияют на знак выражения. Следовательно
всегда положительны, поэтому они не влияют на знак выражения. Следовательно
То есть классификация будет очень простой:
 |
Задняя грань |
 |
Передняя грань |
Пограничный случай
 соответствует случаю, который мы видим на ребре треугольника, то есть когда камера и треугольник копланарны (расположены в одной плоскости). Мы можем классифицировать его любым способом, и это не сильно повлияет на результат, поэтому мы решим классифицировать его как заднюю грань, чтобы избежать обработки вырожденных треугольников.
соответствует случаю, который мы видим на ребре треугольника, то есть когда камера и треугольник копланарны (расположены в одной плоскости). Мы можем классифицировать его любым способом, и это не сильно повлияет на результат, поэтому мы решим классифицировать его как заднюю грань, чтобы избежать обработки вырожденных треугольников.Откуда мы берём вектор нормали? Оказывается, существует векторная операция — векторное произведение
 , получающая два вектора и
, получающая два вектора и  и дающая в результате перпендикулярный им вектор. Мы можем запросто получить два вектора, копланарные треугольнику, вычтя его вершины из друг друга, то есть вычисление направления вектора нормали треугольника будет простой операцией:
и дающая в результате перпендикулярный им вектор. Мы можем запросто получить два вектора, копланарные треугольнику, вычтя его вершины из друг друга, то есть вычисление направления вектора нормали треугольника будет простой операцией:


Заметьте, что я сказал «направление вектора нормали», а не «вектор нормали». Для этого есть две причины. Первая заключается в том, что
 не обязательно равен . Это не очень важно, потому что нормализация
не обязательно равен . Это не очень важно, потому что нормализация  будет тривиальной операцией, и потому что нас волнует только знак
будет тривиальной операцией, и потому что нас волнует только знак  .
.Но вторая причина заключается в том, что если
— это вектор нормали , то им является и !Разумеется, в этом случае нам очень важно, в каком направлении указывает
, потому что именно это позволяет нам классифицировать треугольники как передние или задние. А векторное произведение не коммутативно; в частности,  . Это значит, что мы не можем просто вычесть вершины треугольника в любом порядке, потому что это определяет, указывает ли нормаль «внутрь» или «наружу».
. Это значит, что мы не можем просто вычесть вершины треугольника в любом порядке, потому что это определяет, указывает ли нормаль «внутрь» или «наружу».Хотя векторное произведение не является коммутативным, оно и не случайно, конечно же.
Система координат, которую мы всё время использовали (X вправо, Y вверх, Z вперёд), называется левосторонней, потому что можно направить большой, указательный и средний палец левой руки в этих направлениях (большой палец вверх, указательный вперёд, средний вправо). Правосторонняя система координат похожа на неё, но указательный палец правой руки указывает влево.
Затенение
Давайте продолжим добавлять «реализма» сцене; в этой главе мы изучим, как добавить в сцену источники освещения и как осветить содержащиеся в ней объекты.
Эта глава называется Затенение, а не Освещение; это две тесно связанные, но отличающиеся концепции. Освещение относится к математике и алгоритмам, необходимым для вычисления воздействия освещения на одну точку сцены; Затенение использует техники для распространения воздействия источника освещения от дискретного множества точек на объекты целиком.
В главе Освещение раздела Трассировка лучей я уже рассказал всё необходимое, что нужно знать об освещении. Мы можем задать окружающее, точечное и направленное освещение; вычисление освещённости любой точки в сцене при заданной позиции и нормали поверхности в этой точке выполняется одинаковым способом и в трассировщике лучей, и в растеризаторе; теория точно такая же.
Более интересная часть, которую мы изучим в этой главе, заключается в том, как взять эту "освещённость в точке" и заставить её работать для объектов, состоящих из треугольников.
Плоское затенение
Давайте начнём с простого. Поскольку мы можем вычислить освещённость в точке, давайте просто выберем любую точку в треугольнике (скажем, его центр), вычислим там освещение и используем значение освещённости для затенения всего треугольника (для выполнения действительного затенения мы можем умножить цвет треугольника на значение освещённости):

Не так уж плохо. И очень просто увидеть, почему так случилось. Каждая точка в треугольнике имеет одну и ту же нормаль, и пока источник освещения достаточно далеко, векторы света приблизительно параллельны, то есть каждая точка получает примерно равное количество освещения. Это примерно объясняет различия между двумя треугольниками, из которых состоит каждая сторона куба.
Но что произойдёт, если мы возьмём объект, у которого каждая точка имеет свою нормаль?

Не очень хорошо. Совершенно очевидно, что объект является не настоящей сферой, а приближением, состоящим из плоских треугольных фрагментов. Поскольку такой тип освещения делает изогнутые объекты похожими на плоские, он называется плоским затенением.
Затенение по Гуро
Как же нам улучшить картинку? Простейший способ, для которого у нас уже имеются почти все инструменты — вычисление освещения не центра треугольника, а его трёх вершин; эти значения освещения от
 до
до  можно затем линейно интерполировать сначала по рёбрам, а потом и по поверхности треугольника, закрасив каждый пиксель плавно изменяющимся оттенком. То есть фактически это именно то, что мы делали в главе Отрисовка затенённых треугольников; единственная разница заключается в том, что мы вычисляем значения яркости в каждой вершине с помощью модели освещения, а не назначаем фиксированные значения.
можно затем линейно интерполировать сначала по рёбрам, а потом и по поверхности треугольника, закрасив каждый пиксель плавно изменяющимся оттенком. То есть фактически это именно то, что мы делали в главе Отрисовка затенённых треугольников; единственная разница заключается в том, что мы вычисляем значения яркости в каждой вершине с помощью модели освещения, а не назначаем фиксированные значения.Это называется затенением по Гуро по имени Анри Гуро, придумавшего эту идею в 1971 году. Вот результаты его применения к кубу и сфере:

Куб выглядит немного лучше; неравномерность теперь пропала, потому что оба треугольника каждой стороны имеют две общие вершины, и разумеется освещённость для них обеих вычисляется совершенно одинаково.
Однако сфера по-прежнему выглядит гранёной, а неоднородности на её поверхности выглядят очень неправильными. Это не должно нас удивлять, потому что в конце концов мы работаем со сферой как с набором плоских поверхностей. В частности, мы используем для соседних граней очень отличающиеся нормали — и в частности, мы вычисляем освещённость одной и той же вершины с помощью очень отличающихся нормалей разных треугольников!
Давайте сделаем шаг назад. То, что мы используем плоские треугольники для представления изогнутого объекта, ограничивает наши техники, но не свойство самого объекта.
Каждая вершина в модели сферы соответствует точке в сфере, но задаваемые ими треугольники являются простым приближением поверхности сферы. Поэтому неплохо было бы, чтобы вершины представляли свои точки сферы как можно точнее — и это значит, среди прочего, что они должны использовать настоящие нормали сферы:
Однако это не относится к кубу; даже несмотря на то, что треугольники имеют общие позиции вершин, каждую грань нужно затенять независимо от остальных. У вершин куба нет единственной «верной» нормали.
Как же решить эту дилемму? Проще, чем кажется. Вместо вычисления нормалей треугольников, мы сделаем их частью модели; таким образом, разработчик объекта может использовать нормали для описания кривизны поверхности (или её отсутствия). Также, чтобы учесть случай куба и других поверхностей с плоскими гранями, мы сделаем нормали вершин свойством вершины в треугольнике, а не самой вершины:
model {
name = cube
vertexes {
0 = (-1, -1, -1)
1 = (-1, -1, 1)
2 = (-1, 1, 1)
...
}
triangles {
0 = {
vertexes = [0, 1, 2]
normals = [(-1, 0, 0), (-1, 0, 0), (-1, 0, 0)]
}
...
}
}Вот сцена, отрендеренная с помощью затенения Гуро при соответствующих нормалях вершин:

Куб по-прежнему выглядит как куб, а сфера теперь выглядит гораздо более похожей на сферу. На самом деле, взглянув на её контур, можно определить, что она составлена из треугольников (эту проблему можно решить использованием большего количества мелких треугольников, потратив больше вычислительной мощности).
Однако иллюзия разрушается, когда мы пытаемся рендерить блестящие объекты; зеркальный засвет на сфере потрясающе нереалистичный.
Есть здесь и более мелкая проблема: когда мы сдвигаем точечный источник очень близко к большой грани, мы естественно ожидаем, что она будет выглядеть ярче, а эффект зеркальности будет более явным; однако мы получаем строго противоположную картину:

Что здесь происходит: несмотря на то, что мы ожидаем, что точки рядом с центром треугольника получат больше освещения (потому что
 и приблизительно параллельны), мы вычисляем освещение не в этих точках, а в вершинах, то чем ближе источник освещения к поверхности, тем больше угол с нормалью. Это значит, что каждый внутренний пиксель будет использовать яркость, интерполированную между двумя низкими значениями, то есть тоже имеют низкое значение:
и приблизительно параллельны), мы вычисляем освещение не в этих точках, а в вершинах, то чем ближе источник освещения к поверхности, тем больше угол с нормалью. Это значит, что каждый внутренний пиксель будет использовать яркость, интерполированную между двумя низкими значениями, то есть тоже имеют низкое значение: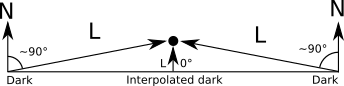
Затенение по Фонгу
Ограничения затенения по Гуро легко преодолеть, но как обычно существует компромисс между качеством и затрачиваемыми ресурсами.
При плоском затенении использовалось единственное вычисление освещения на треугольник. Для затенения по Гуро требовалось три вычисления освещения на треугольник плюс интерполяция единственного атрибута (освещённости) по треугольнику. Следующим шагом в этом увеличении качества и затрат на пиксель будет вычисление освещения для каждого пикселя треугольника.
Это не кажется особо сложным с точки зрения теории; в конце концов, мы уже вычисляли освещение для трёх точек, и вычисляли попиксельное освещение для трассировщика лучей. Но хитрость здесь в том, чтобы выяснить, откуда берутся входные данные для уравнения освещённости.
Нам нужен
. При направленном источнике освещения задан. Для точечного источника освещения задаётся как вектор из точки сцены в позицию источника освещения . Однако, у нас нет для каждого пикселя треугольника, а есть только для вершин.У нас есть проекция
— то есть и , которые мы собираемся отрисовать на холсте! Мы знаем, что
а также у нас есть интерполированное, но геометрически верное значение для
 как часть алгоритма буферизации глубин, поэтому
как часть алгоритма буферизации глубин, поэтому

Поэтому мы можем получить из этих значений
:


Нам нужен
. Это тривиально, потому что мы вычисляем так, как объяснено выше, потому что позиция камеры известна.Нам нужен
. У нас пока есть нормали только в вершинах. Когда у тебя в руках молоток, все задачи похожи на гвозди, а наш молоток — это линейная интерполяция значений атрибута! Мы можем взять значения  ,
,  и
и  в каждой вершине и воспринимать их как несвязанные вещественные числа, которые можно линейно проинтерполировать. В каждом пикселе мы заново собираем интерполированные компоненты в вектор, нормализуем его и используем в качестве нормали этого пикселя.
в каждой вершине и воспринимать их как несвязанные вещественные числа, которые можно линейно проинтерполировать. В каждом пикселе мы заново собираем интерполированные компоненты в вектор, нормализуем его и используем в качестве нормали этого пикселя.Эта техника называется затенением по Фонгу по имени Буи Тьена Фонга, придумавшего её в 1973 году. Вот её результаты:

Исходный код и рабочее демо >>
Сфера выглядит отлично, за исключением её контура (но алгоритм затенения в этом не виновать), а эффект от приближения источника света к треугольнику ведёт себя именно так, как мы ожидаем.
Это также решает проблему с приближением источника к грани, теперь мы получаем ожидаемые результаты:

На этом этапе мы уже достигли возможностей трассировщика лучей, разработанного в первой части, за исключением теней и отражений. Вот выходные данные разрабатываемого нами растеризатора при использовании той же сцены:

А вот версия с трассировкой лучей для справки:

Они выглядят почти аналогично, несмотря на то, что в них используются совершенно различные технологии. Это логично, потому что мы использовали разные техники для рендеринга одной сцены. Единственным заметным различием являются рёбра сфер, которые трассировщик лучей рендерит как математически идеальные сферы, а растеризатор аппроксимирует как множество треугольников.
Текстуры
Пока мы можем рендерить такие объекты, как кубы или сферы, и воздействовать на них освещением. Но обычно нам нужно рендерить не кубы и сферы, а ящики и планеты, игровые кости или мрамор.
Рассмотрим деревянный ящик. Как превратить куб в деревянный ящик? Один из вариантов — добавить множество треугольников, поссоздающих структуру дерева, шляпки гвоздей, и так далее. Это сработает, но из-за геометрическая сложность сцены сильно повысится, что повлияет на производительность.
Ещё один вариант — имитировать ящик: взять плоскую поверхность куба и просто нарисовать поверх неё что-то, напоминающее древесину. Если не приглядываться к ящику, то вы никогда не заметите разницы.
Мы воспользуемся вторым подходом. Во-первых, нам понадобится изображение, которое мы будем рисовать на поверхности; в этом контексте мы назовём это изображение текстурой, хотя это и противоположно тому, что мы называем текстурой объекта — грубый он или мягкий, и т.д… Вот текстура «деревянного ящика»:

Текстура Filter Forge — Attribution 2.0 Generic (CC BY 2.0)
Во-вторых, нам нужно указать, как текстура должна накладываться на модель. Мы можем задать наложение для каждого треугоьника, указав точки текстуры, накладываемые на каждую вершину треугольника:

Стоит заметить, что без проблем можно деформировать текстуру или использовать только части текстуры, меняя координаты текстуры для каждой вершины.
Чтобы задать это наложение, мы используем систему координат, определяющую точки этой текстуры; назовём эти координаты
 и
и  , чтобы не путать их с , которые обычно обозначают пиксели на холсте. Мы также объявим, что и являются вещественными значениями в интервале
, чтобы не путать их с , которые обычно обозначают пиксели на холсте. Мы также объявим, что и являются вещественными значениями в интервале ![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg) вне зависимости от разрешения изображения текстуры в пикселях. Это очень удобно по нескольким причинам; например, в зависимости от доступного объёма ОЗУ можно использовать текстуры более низкого или высокого разрешения, не меняя саму модель.
вне зависимости от разрешения изображения текстуры в пикселях. Это очень удобно по нескольким причинам; например, в зависимости от доступного объёма ОЗУ можно использовать текстуры более низкого или высокого разрешения, не меняя саму модель.Основная идея наложения текстур проста: вычисляем координаты
 для каждого пикселя треугольника, получаем соответствующий тексел (то есть текстурный элемент) из текстуры и закрашиваем пиксель этим цветом. Заданная пара в текстуре размером
для каждого пикселя треугольника, получаем соответствующий тексел (то есть текстурный элемент) из текстуры и закрашиваем пиксель этим цветом. Заданная пара в текстуре размером  накладывается на тексел в
накладывается на тексел в  .
.Но у нас есть только координаты
и для трёх вершин треугольника, а они необходимы для каждого пикселя… и наверно вы уже видите, что должно произойти. Да, линейная интерполяция. Мы используем присвоение атрибутов для интерполяции значений и по грани треугольника, что даст нам в каждом пикселе; мы закрасим пиксель соответствующим цветом, взятым из текстуры (возможно, с воздействием освещение), и получим…
…заурядные результаты. Ящики выглядят вполне неплохо, но если присмотреться к диагональным доскам, то становится очевидно, что они немного деформированы.
В чём же ошибка?
Мы снова попались в ловушку неверного предположения; мы считаем, что
и вдоль экрана меняются линейно. Очевидно, что это не так. Посмотрите на стену очень длинного коридора, покрашенного попеременно чёрными и белыми вертикальными полосами. При удалении стены мы должны видеть всё более и более тонкие полосы. Однако если мы предположим, что координата меняется линейно вместе с , то это будет неверно:
Ситуация очень похожа на ту, которая встречалась нам в главе Буферизация глубин, и решение тоже очень похоже: хотя
и нелинейны в экранных координатах,  и
и  линейны (Примечание: доказательство этого очень похоже на доказательство
линейны (Примечание: доказательство этого очень похоже на доказательство  : примем, что линейно изменяется в 3D-пространстве, и заменим и на их выражения в экранном пространстве.). Поскольку мы уже интерполировали значения для каждого пикселя, то достаточно интерполировать и , чтобы получить и :
: примем, что линейно изменяется в 3D-пространстве, и заменим и на их выражения в экранном пространстве.). Поскольку мы уже интерполировали значения для каждого пикселя, то достаточно интерполировать и , чтобы получить и :

При этом мы получим ожидаемые результаты:
Исходный код и рабочее демо >>
