Всем, привет! Не секрет, что в последнее время в мире происходит резкий всплеск активности, по поводу исследования такой темы, как искусственный интеллект. Вот и меня это явление не обошло стороной.
Всё началось, когда в самолёте я посмотрел типичную, на первый взгляд американскую комедию – «Почему, он?» (англ. Why him? 2016). Там, у одного из ключевых персонажей в доме был установлен голосовой помощник, который нескромно позиционировал себя «как Siri, только круче». К слову бот из фильма умел не только вызывающе разговаривать с гостями, иногда ругаясь матом, но также контролировать весь дом и прилегающую территорию – от центрального отопления до смыва унитаза. После просмотра фильма, мне пришла идея реализовать что-то подобное и я начал писать код.

Рисунок 1 – Кадр из того самого фильма. Голосовой помощник на потолке.
Первый этап дался легко – было подключено Google Speech API для распознавания и синтеза речи. Текст, получаемый от Speech API обрабатывался через, вручную написанные, паттерны регулярных выражений, при совпадении с которыми определялось намерение (intent) человека, разговаривающего с чат ботом. На основании определённого regexp’ом намерения, рандомно выбиралась одна фраза из соответствующего списка ответов. Если сказанное человеком предложение не попадало ни под один паттерн, то бот говорил заранее заготовленные общие фразы, наподобие: «Мне нравится думать, что я не просто компьютер» и тд.
Очевидно, что вручную прописывать множество регулярных выражений для каждого intent’a – занятие трудоёмкое, поэтому, в результате поисков, я наткнулся на так называемый «наивный Байесовский классификатор». Наивным его называют потому, что при его использовании подразумевается, что слова в анализируемом тексте не связаны друг с другом. Несмотря на это, данный классификатор показывает неплохие результаты, о которых поговорим чуть ниже.
Просто так засунуть строку в классификатор не получится. Входная строка обрабатывается по нижеприведённой схеме:
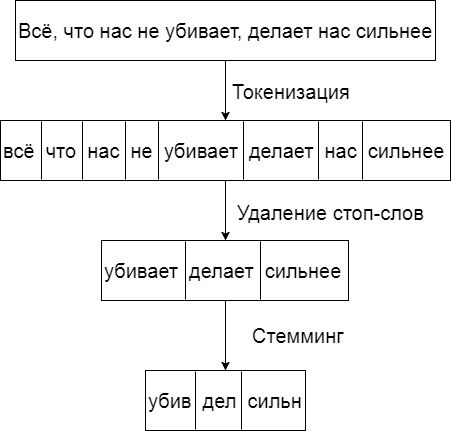
Рисунок 2 – Схема обработки входного текста
Объясню подробнее каждый этап. С токенизацией всё просто. Банально – это разбиение текста на слова. После чего, из полученных токенов (массив слов) удаляются так называемые стоп-слова. Заключительная стадия довольно непростая. Стемминг – это получение основы слова для заданного исходного слова. Причём, основа слова – это не всегда его корень. Я использовал Стеммер Портера для русского языка (ссылка ниже).
Перейдём к математической части. Формула, с которой всё начинается выглядит следующим образом:
 – это вероятность присвоения какого либо intent’a данной входной строке иными словами фразе, которую сказал нам человек.
– это вероятность присвоения какого либо intent’a данной входной строке иными словами фразе, которую сказал нам человек.  – вероятность intent’a, которая определяется отношением количества документов, принадлежащих intent’у к общему количеству документов в обучающем наборе. Вероятность документа –
– вероятность intent’a, которая определяется отношением количества документов, принадлежащих intent’у к общему количеству документов в обучающем наборе. Вероятность документа –  , поэтому отбрасываем её.
, поэтому отбрасываем её.  – вероятность отношения документа к intent’у. Она расписывается следующим образом:
– вероятность отношения документа к intent’у. Она расписывается следующим образом:
где — соответствующий токен (слово) в документе
— соответствующий токен (слово) в документе
Распишем ещё поподробнее:
где:
 – сколько раз токен был отнесён к данномй intent'у
– сколько раз токен был отнесён к данномй intent'у
 – сглаживание, предотвращающее нулевые вероятности
– сглаживание, предотвращающее нулевые вероятности
 – кол-во слов, отнесённых к intent'у в тренировочных данных
– кол-во слов, отнесённых к intent'у в тренировочных данных
 – количество уникальных слов в тренировочных данных
– количество уникальных слов в тренировочных данных
Для тренировки я создал несколько текстовых файлов с символичными названиями «hello», «howareyou», «whatareyoudoing», «weather» etc. Для примера приведу содержание файла hello:

Рисунок 3 – Пример содержимого текстового файла «hello.txt»
Процесс обучения в деталях я описывать не буду, ведь весь код на Java доступен на Github. Приведу лишь схему использования данного классификатора:

Рисунок 4 – Схема работы классификатора
После того, как мы обучили нашу модель, приступаем к классификации. Поскольку, в тренировочных данных мы определили несколько intent’ов, то и полученных вероятностей будет несколько.
Так какую же из них выбирать? Выбираем максимальную!
А теперь самое интересное, результаты классификации:
Первые результаты немножко огорчили, но в них я увидел подозрительные закономерности:
Решилась данная проблема уменьшением параметра сглаживания () с 0.5 до 0.1, после чего получились следующие результаты:
Полученные результаты я считаю удачными, и учитывая мой предыдущий опыт с regular expressions могу сказать, что наивный Байесовский классификатор намного более удобное и универсальное решение, особенно, когда дело касается масштабирования тренировочных данных.
Следующим этапом в данном проекте будет разработка модуля определения именованных сущностей в тексте (Named Entity Recognition), а также совершенствование текущих возможностей.
Спасибо за внимание, to be continued!
Википедия
Стоп-слова
Стеммер Портера
Предыстория
Всё началось, когда в самолёте я посмотрел типичную, на первый взгляд американскую комедию – «Почему, он?» (англ. Why him? 2016). Там, у одного из ключевых персонажей в доме был установлен голосовой помощник, который нескромно позиционировал себя «как Siri, только круче». К слову бот из фильма умел не только вызывающе разговаривать с гостями, иногда ругаясь матом, но также контролировать весь дом и прилегающую территорию – от центрального отопления до смыва унитаза. После просмотра фильма, мне пришла идея реализовать что-то подобное и я начал писать код.

Рисунок 1 – Кадр из того самого фильма. Голосовой помощник на потолке.
Начало разработки
Первый этап дался легко – было подключено Google Speech API для распознавания и синтеза речи. Текст, получаемый от Speech API обрабатывался через, вручную написанные, паттерны регулярных выражений, при совпадении с которыми определялось намерение (intent) человека, разговаривающего с чат ботом. На основании определённого regexp’ом намерения, рандомно выбиралась одна фраза из соответствующего списка ответов. Если сказанное человеком предложение не попадало ни под один паттерн, то бот говорил заранее заготовленные общие фразы, наподобие: «Мне нравится думать, что я не просто компьютер» и тд.
Очевидно, что вручную прописывать множество регулярных выражений для каждого intent’a – занятие трудоёмкое, поэтому, в результате поисков, я наткнулся на так называемый «наивный Байесовский классификатор». Наивным его называют потому, что при его использовании подразумевается, что слова в анализируемом тексте не связаны друг с другом. Несмотря на это, данный классификатор показывает неплохие результаты, о которых поговорим чуть ниже.
Пишем классификатор
Просто так засунуть строку в классификатор не получится. Входная строка обрабатывается по нижеприведённой схеме:

Рисунок 2 – Схема обработки входного текста
Объясню подробнее каждый этап. С токенизацией всё просто. Банально – это разбиение текста на слова. После чего, из полученных токенов (массив слов) удаляются так называемые стоп-слова. Заключительная стадия довольно непростая. Стемминг – это получение основы слова для заданного исходного слова. Причём, основа слова – это не всегда его корень. Я использовал Стеммер Портера для русского языка (ссылка ниже).
Перейдём к математической части. Формула, с которой всё начинается выглядит следующим образом:

– это вероятность присвоения какого либо intent’a данной входной строке иными словами фразе, которую сказал нам человек. – вероятность intent’a, которая определяется отношением количества документов, принадлежащих intent’у к общему количеству документов в обучающем наборе. Вероятность документа – , поэтому отбрасываем её. – вероятность отношения документа к intent’у. Она расписывается следующим образом:
где
— соответствующий токен (слово) в документеРаспишем ещё поподробнее:

где:
– сколько раз токен был отнесён к данномй intent'у – сглаживание, предотвращающее нулевые вероятности – кол-во слов, отнесённых к intent'у в тренировочных данных – количество уникальных слов в тренировочных данных Для тренировки я создал несколько текстовых файлов с символичными названиями «hello», «howareyou», «whatareyoudoing», «weather» etc. Для примера приведу содержание файла hello:

Рисунок 3 – Пример содержимого текстового файла «hello.txt»
Процесс обучения в деталях я описывать не буду, ведь весь код на Java доступен на Github. Приведу лишь схему использования данного классификатора:

Рисунок 4 – Схема работы классификатора
После того, как мы обучили нашу модель, приступаем к классификации. Поскольку, в тренировочных данных мы определили несколько intent’ов, то и полученных вероятностей
будет несколько.Так какую же из них выбирать? Выбираем максимальную!

А теперь самое интересное, результаты классификации:
| № | Входная строка | Определённый intent | Верно ли? |
| 1 | Здравствуйте, как дела? | Howareyou | Да |
| 2 | Рад вас приветствовать, друг | Whatdoyoulike | Нет |
| 3 | Как прошел вчерашний день | Howareyou | Да |
| 4 | Какая погода за окном? | Weather | Да |
| 5 | Какую погоду обещают на завтра? | Whatdoyoulike | Нет |
| 6 | Прошу прощения, мне нужно отлучиться | Whatdoyoulike | Нет |
| 7 | Удачного дня | Bye | Да |
| 8 | Давай познакомимся? | Name | Да |
| 9 | Привет | Hello | Да |
| 10 | Рад вас приветствовать | Hello | Да |
Первые результаты немножко огорчили, но в них я увидел подозрительные закономерности:
- Фразы №2 и №10 отличаются одним словом, но дают разные результаты.
- Все неправильно определенные intent’ы определяются как whatdoyoulike.
Решилась данная проблема уменьшением параметра сглаживания (
) с 0.5 до 0.1, после чего получились следующие результаты:| № | Входная строка | Определённый intent | Верно ли? |
| 1 | Здравствуйте, как дела? | Howareyou | Да |
| 2 | Рад вас приветствовать, друг | Hello | Да |
| 3 | Как прошел вчерашний день | Howareyou | Да |
| 4 | Какая погода за окном? | Weather | Да |
| 5 | Какую погоду обещают на завтра? | Weather | Да |
| 6 | Прошу прощения, мне нужно отлучиться | Bye | Да |
| 7 | Удачного дня | Bye | Да |
| 8 | Давай познакомимся? | Name | Да |
| 9 | Привет | Hello | Да |
| 10 | Рад вас приветствовать | Hello | Да |
Полученные результаты я считаю удачными, и учитывая мой предыдущий опыт с regular expressions могу сказать, что наивный Байесовский классификатор намного более удобное и универсальное решение, особенно, когда дело касается масштабирования тренировочных данных.
Следующим этапом в данном проекте будет разработка модуля определения именованных сущностей в тексте (Named Entity Recognition), а также совершенствование текущих возможностей.
Спасибо за внимание, to be continued!
Литература
Википедия
Стоп-слова
Стеммер Портера
