Comments 23
2) Откуда взялась привязка к НОД(m, k)? Почему нельзя просто взять фиксированный список простых чисел (в общем случае независящий от ключа) и отмечать единичками разложение по этому списку? С учётом того что получателю сообщение неизвестно, ему и НОД неизвестен, и большой разницы между НОД(m, k) и НОД(m, r), где r — выбранное случайно число, нет (коль вы всё равно этот НОД передаёте)
3) Что вы предлагаете делать если в разложении m некое простое число встретится, к примеру, дважды?
День добрый!
- по п. 1 https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8 — при условии равной вероятности появления каждого символа и отсутствии шума в канале вырождается в двоичный логарифм от длины;
- по п. 2 — тогда ключей будет уж очень мало, а НОД сам не передаётся, только информация о позиции множителей — экономия за счёт этого и возникает, когда попытался обойти такое ограничение, то получается, что на ключи надо накладывать много правил типа отсутствия повторений простых множителей т.е. чтобы не было ключа типа 36 = [2,2,3,3];
- по п.3 это как раз и предусмотрено позиционным двоичным кодированием с_1 — учитывать этот момент, либо же как предыдущем пп. вводить доп. ограничения на ключ.
ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BB%D0%B8%D1%87%D0%B5%D1%81%D1%82%D0%B2%D0%BE_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8 — при условии равной вероятности появления каждого символа и отсутствии шума в канале вырождается в двоичный логарифм от длины;
Все-таки скорее просто в длину, а не в ее двоичный логарифм.
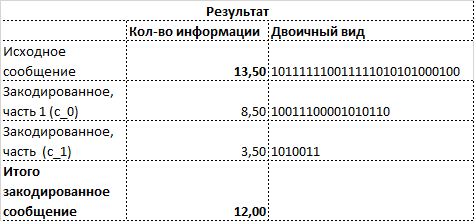
- меня интересует почему при битовой длине сообщения m равной 26 бит вы считаете кол-во информации равным 13 бит. Я не пойму где именно я упускаю множитель 1/2
- почему ключей будет мало? К примеру, можно рассмотреть в качестве списка простых множителей список [2, 3, 5, 7, 11, 17, 19], как у вас в примере. Можно считать что этот список передаётся приёмной стороне на этапе обмена ключей (если у нас модель с симметричным шифрованием) либо просто известен заранее как часть протокола (в ассиметричной схеме). Тогда замена сообщения m на пару c_0, c_1 остаётся такой же (т.е. выигрыш в битах сохраняется), а в качестве ключа можно брать любое число, не обязанное быть произведением множителей из списка
- вот мне как раз и непонятно, как вы будете составлять c_1. К примеру, для сообщения m = 100 267 332 = 2 * 2 * 3 * 11 * 19 * 39979 Какие для него будут c_0 и c_1?
- Там похоже действительно потеряна 1/2, хоть это и не сцщественно.
- Насколько я понимаю, по задумке метод рассчитан на m, заведомо имеющие большое количество различных делителей (по крайней мере для них получается хороший выигрыш). Тогда разумно наложить такое же требование на k, чтобы минимизировать c_0.
- Одна двойка попадает в c_1, то есть 1100101 и 39979 * 2.
Тогда разумно наложить такое же требование на k, чтобы минимизировать c_0.
Как будет минимизироваться c_0? Если мы не используем список множителей из ключа, а используем свой список множителей, то c_0 и c_1 не зависят от ключа, а зависят только от списка множителей.
По остальным вопросам мне всё понятно, спасибо большое!
кол-во информации в одном символе при условии равновероятного появления [0,1] = 1/2*log_2(2) = 1/2 соотв. если сообщение длины n, то кол-во информации n/2;
меньше т.к. из перечня ключей выкидываются, например [2,2,2,3,3,5] =360 — они не привносят доп. простых множителей относительно [2,3,5] = 30, а длину с_1 увеличивают.
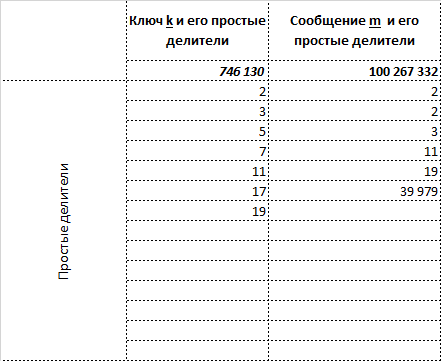
- если ключ тот же — 746130, то картина такая
Разложение на множители:

с_1 и с_2

получается если подставить в ячейки с5 и d5 в приложенном excel
меньше т.к. из перечня ключей выкидываются, например [2,2,2,3,3,5] =360 — они не привносят доп. простых множителей относительно [2,3,5] = 30, а длину с_1 увеличивают.
Почему этот ключ выкидывается? Если мы не используем список множителей из ключа, а используем свой список множителей, то c_0 и c_1 не зависят от ключа, а зависят только от списка множителей.
По остальным вопросам мне всё понятно, спасибо большое!
кол-во информации в одном символе при условии равновероятного появления [0,1] = 1/2*log_2(2) = 1/2 соотв. если сообщение длины n, то кол-во информации n/2;
То есть в однобитном сообщении содержится полбита информации?
Не совсем так — то, что написал касалось сообщений длины n, где надо учитывать вероятность появления каждого символа, для сообщений длины 1 лучше говорить о собственной информации ссылка т.к. там всё детерминировано.
Не пытаетесь ли вы изобрести велосипед сжатие с использованием словаря ?
Если начинать сравнивать, то да. Просто хотелось сначала показать, что в самом сложном случае, когда берутся два почти случайные числа, можно, найдя общую информацию её не передавать. А так как Вы верно заметили, что реальные сообщения не случайны, то дальше хочется заняться уже переложением этой темы на практику.
Простые делители ключа k: 2,3,5,11,19
Простые делители сообщения m: 2,3,11,19, 39 979
НОД(k,m): 2,3,11,19
Двоичная запись общих делителей: 1,1,0,1,1
Простые делители ключа k: 2,3,7,11,19
Простые делители сообщения m: 2,3,11,19, 39 979
НОД(k,m): 2,3,11,19
Двоичная запись общих делителей: 1,1,0,1,1
То есть, при разных комбинациях простых делителей передаваемая двоичная часть получается одинаковой и восстановить сообщение невозможно. Или я ошибаюсь и такого не может быть?
Передаваемая часть действительно будет одинаковой, в обоих случаях

Но т.к. ключ известен двум сторонам, то восстановить полученную информацию можно полностью т.к получив 11011 мы в обоих случаях восстанавливаем НОД(k,m)=1254 =[2,3,11,19].
Другое дело, что если ключ долго не менять, то поигравшись сообщениями (мы-то знаем делители сообщения) и понаблюдав за каналом, его можно и восстановить.
И, я так понимаю, отличие от алгоритма со словарём в том, что не нужно тратить время и ресурсы на составление словаря. Но зато надо их тратить на выделение информации из ключа.
Вы правы. Но есть надежда на то, что поиск простых делителей довольно отработанный хоть и не очень быстрый алгоритм — делим на всё подряд до корня из числа с оценкой O(n^{0.5})
Кодирование с изъятием информации. Часть 2-я, математическая