Comments 18
Для чего вообще нужно складывать хеши? Чтобы усложнить возможность подбора и подмены значений? Почему бы просто не брать сразу один раз один общий хеш от всех транзакций в блоке?
hash(L1 + L2 + L3 + L4 + L5)Чтобы гарантировать порядок транзакций.
Но порядок транзакций и так будет соблюдён, ведь если их «переставить», то будет уже другой хеш:
hash(L1 + L2 + L3 + L4 + L5) = 111111
hash(L2 + L1 + L3 + L4 + L5) = 222222
hash(L1 + L2 + L3 + L4 + L5) = 111111
hash(L2 + L1 + L3 + L4 + L5) = 222222
Вы что то путаете. Сложение выполняется операцией XOR. Следовательно значение хеша не измениться если поменять их местами.
Нет, в en.bitcoin.it/wiki/Protocol_documentation указано, что используется конкатенация. Поиском по d5 = dhash(d1 concat d2) сможете найти нужное место
А XOR бы и при попарном хешировании не менялся при замене L1<->L2
А XOR бы и при попарном хешировании не менялся при замене L1<->L2
Чтобы при предоставлении доказательства не надо было все хеши давать, а только ветку.
Чтобы для проверки наличия транзакции в блоке не надо было тянуть весь блок.
Достаточно будет только цепочки хэшей от транзакции до корня и хэшей, которые с ними суммировались. Т.е. порядка 2*log(N) хэшей
Достаточно будет только цепочки хэшей от транзакции до корня и хэшей, которые с ними суммировались. Т.е. порядка 2*log(N) хэшей
Хороший вопрос. Для экономии места на диске, т.к. старые ветки можно удалять, не меняя нижележащие хеши.
Это описано в White Paper от Сатоши Накомото. Пункт 7 — «Reclaiming Disk Space»
«Once the latest transaction in a coin is buried under enough blocks, the spent transactions before
it can be discarded to save disk space. To facilitate this without breaking the block's hash,
transactions are hashed in a Merkle Tree [7][2][5], with only the root included in the block's hash.
Old blocks can then be compacted by stubbing off branches of the tree. The interior hashes do
not need to be stored.»
bitcoin.org/bitcoin.pdf
Это описано в White Paper от Сатоши Накомото. Пункт 7 — «Reclaiming Disk Space»
«Once the latest transaction in a coin is buried under enough blocks, the spent transactions before
it can be discarded to save disk space. To facilitate this without breaking the block's hash,
transactions are hashed in a Merkle Tree [7][2][5], with only the root included in the block's hash.
Old blocks can then be compacted by stubbing off branches of the tree. The interior hashes do
not need to be stored.»
bitcoin.org/bitcoin.pdf
UFO just landed and posted this here
концепция которого была запатентованаНе фига себе, концепции оказывается можно патентовать… куда мир катится. © Дебилы.
Картинки красивые, и гуглом находятся красивые — но что если количество листьев не 2^x? Например, как будет выглядеть дерево, если у нас 5 блоков, и что будет менятся при добавлении 6,7,8 блоков? Насколько я понял, будут использоваться дубликаты ключей, но при добавлении нового листа, хеши придется пересчитать и это инвалидирует предыдущий root.
Дерево будет достраиваться. Прочитайте комментарий в исходном коде
спасибо. «for transaction lists [1,2,3,4,5,6] and [1,2,3,4,5,6,5,6] (where 5 and 6 are repeated) result in the same root hash A (because the hash of both of (F) and (F,F) is C).»
Я правда непонимаю почему хеши от (F) и (F,F) одинаковые, но если исходить из того, что это работает именно так, то с выводами согласен.
Я правда непонимаю почему хеши от (F) и (F,F) одинаковые, но если исходить из того, что это работает именно так, то с выводами согласен.
Нет не будет одинаковым. Из-за уязвимости, блок будет сохранен в первоначальном варианте [1,2,3,4,5,6], то есть в другом месте добавлена проверка на этот случай. Ведь имея [1,2,3,4,5,6] нам все равно придется достраивать его до полного дерева, а значит получиться в конечном итоге [1,2,3,4,5,6,5,6]. Вот только если отправить в блокчейн [1,2,3,4,5,6,5,6], то это будет означать, что транзации 5,6 были потрачены два раза, а мы должны это исключить. Поэтому мы не храним повторяющиеся транзакции в блокчейне, а дерево мы достраиваем по мере необходимости. Пусть меня поправят коллеги, если я не прав.
При проверке дерева другим майнером, каким образом он знает порядок транзакций в блоке, для построения конечного результата? Временная метка?
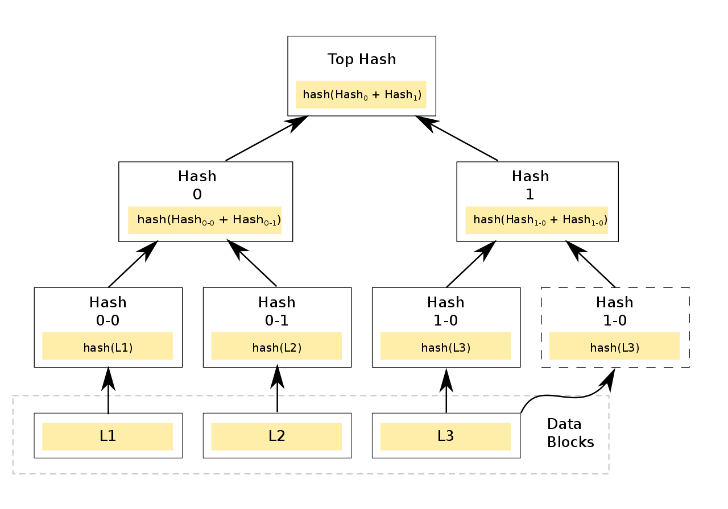
Если к примеру поменять местами L3 и L2, то результат будет другим.

Если к примеру поменять местами L3 и L2, то результат будет другим.
Sign up to leave a comment.
Как это работает: Деревья Меркла в биткойн сети