
Всем привет! Я заметил, что на Хабре очень мало информации про такой сервер сборки, как ConcourseCI. Я решил восполнить этот пробел и написать небольшое введение. Под катом описание этого инструмента и небольшой туториал.
Итак, ConcourseCI — это сервер сборки CI/CD. Разрабатывается он компанией Pivotal, в данный момент находится в стадии активной разработки. В самой комании есть несколько человек, которые работают на полную ставку целиком на этом проекте, так что новые версии на данный момент выпускаются довольно регулярно, дополнительные фичи внедряются активно, и баги исправляются быстро. Изначально, как это чаще всего бывает, Pivotal сделали этот инструмент для внутреннего использования, потому что были неудовлетворены Дженкинсом, но в последствии опубликовали этот проект на Гитхабе и сообщество подтянулось, в релизах часто встречается новый функционал от сторонних разработчиков из сообщества. Написан целиком на языке Go.
В этой статье:
- Достоинства
- Установка
- Три концепции
- Внешний вид вэб интерфейса
- Fly
- Конфигурация конвейера
- Секреты
- Зачем нужны таски?
Достоинства
Перечислю основные достоинства этого продукта:
- каждая операция запускается в отдельном Docker-контейнере, что делает этот продукт абсолютно независимым от технологии. То есть собирать можно любой код, который собирается внутри какого-либо докер-контейнера
- процесс сборки описывается в форме т.н. pipeline (конвейере), потому что современная сборка всё реже становится линейной. И описать сложную процедуру сборки в виде такого графика становится очень удобно и наглядно. ConcourseCI поставляется с удобным графическим веб-интерфейсом, который используется только для чтения.
Хотя на данный момент запущен новый дизайн в бета-режиме, он активно обсуждается сообществом, так что мои скриншоты, вероятно, устареют в ближайшем будущем. Новый интерфейс, возможно, будет выглядеть примерно вот так:
- из коробки легко расширяется горизонтально. Если у вас не хватает ресурсов, вы можете запустить ещё один воркер на новой машине, указать в качестве параметров адрес главного сервера и всё остальное сделается за вас: воркер сам себя зарегистрирует, сообщит о себе и уже сразу же будет готов выполнять какую-то работу. Более того, если у вас есть в процессе сборки какие-то параллельные операции, то они вполне могут бежать на разных физических машинах. Операция добавления нового воркера — это буквально запуск одной команды.
Установка
Как я упоминал, проект написан на Go, поэтому релиз поставляется единым бинарным файлом, и его можно запустить одной командой. Но есть способ лучше. ConcourseCI предоставляет официальный докер-образ, так что можно запустить проект всего одной командой, используя уже docker-compose.
Запущенный ConcourseCI состоит из трёх частей:
- PostgreSQL база данных
- Concourse Web. Это что-то вроде мастера. Тут работает графический вэб интерфейс и самое главное — ATC (термин "ATC" или "Air Traffic Control", позаимствован из авиации: это вышка управления полётами, которая стоит в аэропортах у взлётно-посадочной полосы, где диспетчеры руководят полётами самолётов). ATC распределяет ресурсы, запускает разные задачи, следит за кластером. Важно помнить, что реальная сборка не происходит в Concourse Web, он только лишь руководит сборкой, делегируя задачи доступным воркерам. В системе может быть только один главный Concourse Web.
- Concourse Worker — вот тут-то и происходит реальная работа. Воркер получает задания от ATC и выполняет его, отчитавшись о своих результатах. Таких воркеров может быть в системе столько, на сколько у вас хватит железа. Рекомендуется запускать один воркер на один сервер/инстанс.
Таким образом, полностью рабочий сервер можно запустить всего одной docker-compose командой. Но перед самым первым запуском вам следует сгенерировать ключи, потому что ATC общается с воркерами по зашифрованному каналу и необходимо обоим сторонам подсунуть ключи перед запуском. Генерируем ключи вот так:
mkdir -p keys/web keys/worker
ssh-keygen -t rsa -f ./keys/web/tsa_host_key -N ''
ssh-keygen -t rsa -f ./keys/web/session_signing_key -N ''
ssh-keygen -t rsa -f ./keys/worker/worker_key -N ''
cp ./keys/worker/worker_key.pub ./keys/web/authorized_worker_keys
cp ./keys/web/tsa_host_key.pub ./keys/workerНу и после этого мы сможем запустить всю систему вот с таким файлом (смотрите официальный файл тут):
version: '3'
services:
concourse-db:
image: postgres:9.6
environment:
POSTGRES_DB: concourse
POSTGRES_USER: concourse
POSTGRES_PASSWORD: changeme
PGDATA: /database
concourse-web:
image: concourse/concourse
links: [concourse-db]
command: web
depends_on: [concourse-db]
ports: ["8080:8080"]
volumes: ["./keys/web:/concourse-keys"]
restart: unless-stopped # required so that it retries until concourse-db comes up
environment:
CONCOURSE_BASIC_AUTH_USERNAME: concourse
CONCOURSE_BASIC_AUTH_PASSWORD: changeme
CONCOURSE_EXTERNAL_URL: "${CONCOURSE_EXTERNAL_URL}"
CONCOURSE_POSTGRES_HOST: concourse-db
CONCOURSE_POSTGRES_USER: concourse
CONCOURSE_POSTGRES_PASSWORD: changeme
CONCOURSE_POSTGRES_DATABASE: concourse
concourse-worker:
image: concourse/concourse
privileged: true
links: [concourse-web]
depends_on: [concourse-web]
command: worker
volumes: ["./keys/worker:/concourse-keys"]
environment:
- CONCOURSE_TSA_HOST=concourse-web:2222Не забудьте экспортировать в переменную CONCOURSE_EXTERNAL_URL реальное значение вэб адреса, на котором будет доступен вэб-интерфейс.
export CONCOURSE_EXTERNAL_URL=http://192.168.99.100:8080Как видите, в этом примере мы запускаем всё на одной машине, но никто вас этим не ограничивает и можно смело создавать распределённый кластер согласно своим потребностям.
После запуска, можете открыть в браузере адрес вашего сервера (в примере выше — http://192.168.99.100:8080) и вы увидите пока ещё пустой Concourse Web.
Подробнее про установку тут.
Три концепции
Итак, прежде чем перейти к делу, давайте разберёмся с терминологией, чтобы понимать друг друга. ConcourseCI оперирует тремя основными понятиями.
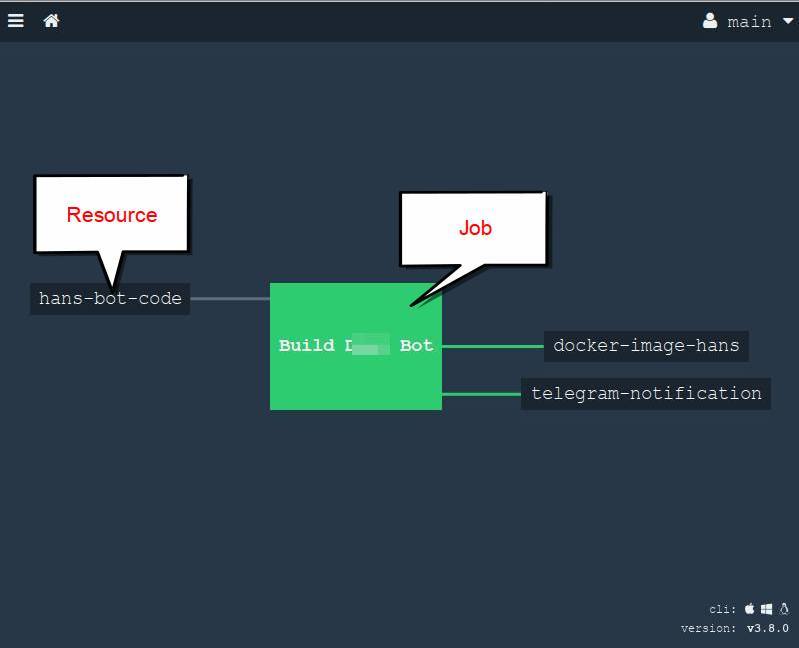
Resource — ресурс который может предоставлять материал для сборки, или может быть обновлён результатами сборки. Типичные примеры: git/hg репозитории, докер-регистри, FTP, S3, чаты, емайлы, телеграм-боты и проч. Полный список тут, плюс можно всегда что-то найти на просторах ГитХаба и на крайний случай можно написать самому. Важно понимать, что ресурс не делает никакой конкретной работы, он всего лишь "предоставляет" материал для дальнейших действий.
Task — это единица работы, которая может быть сделана в рамках вашей сборки. Таск запускается в выбранном вами докер-контейнере.
- Job — задание; объединяет ресурсы и таски в одно целое. Иными словами внутри задания мы берём ресурсы, как-то обрабатываем в тасках, собираем и обновляем ресурсы результатами. Одна задача полностью изолирована и может быть запущена отдельно сколько угодно раз.
Внешний вид вэб-интерфейса
И в браузере ConcourseCI выглядит примерно так:
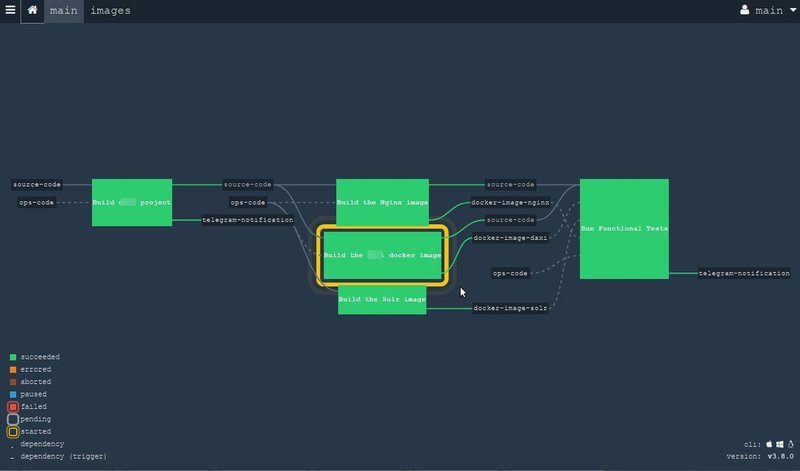
Это очень простой пример для конвейера, но тут видно, как мы берём исходники из Гит-репозитория и запускаем сборку проекта, создаём докер-образ и оповещаем всех в телеграм канале с помощью соотвествующего ресурса.
На данном скриншоте видны только ресурсы и задача, но не видны таски. Но если нажать на одну из задач (в этом примере у нас она одна), то можно увидеть, что творится внутри зелёного квардрата:
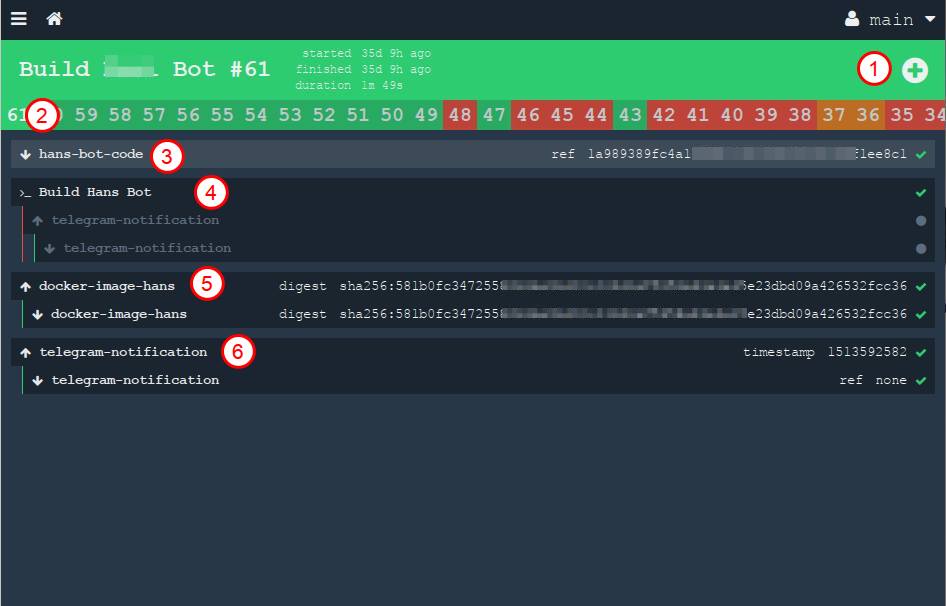
На данном снимке цифрами отмечены:
- кнопка ручного запуска задачи. Вы её можете запустить ещё раз в любой момент времени
- все предыдущие билды выстраиваются в длинную цепочку под заголовком в виде истории
- ресурс, который берёт исходники. Стрелочка вниз означает "get", то есть мы "забираем" из ресурса материал.
- вывод работы одного таска. Можно раскрыть эту ссылку и увидеть лог stdout из нашего контейнера, что происходило во время сборки нашего проекта
- мы собираем ресурс (докер-образ) и забрасываем его в приватный регистри. Стрелочка "наверх" означает "put", то есть мы "обновляем" ресурс
- наконец, кидаем сообщение в приватный телеграм канал
В этом интерфейсе можно просматривать все конвейеры и таски, следить за результами.
В качестве примера совсем "продвинутой" версии конвейера можно привести конвейер самого ConcourseCI (да, как ни удивительно, но сам он собирается им же самим :) )
Но как я уже упоминал выше, вэб тут только для чтения. Возникает резонный вопрос: а как же тогда добавлять новые конвейеры в проект? Настало время представить вам fly.
Fly
Fly — это утилита командной строки, которая позволяет управлять всем вашим кластером ConcourseCI из терминала. Ставится на ваш рабочий компьютер и упралвяет сервером. С ней вы можете совершать все необходимые операции и обслуживать кластер.
Вывод справки по данной команде (малая часть):
$ fly help
Usage:
fly [OPTIONS] <command>
Application Options:
-t, --target= Concourse target name
-v, --version Print the version of Fly and exit
--verbose Print API requests and responses
--print-table-headers Print table headers even for redirected output
Help Options:
-h, --help Show this help message
Available commands:
abort-build Abort a build (aliases: ab)
builds List builds data (aliases: bs)
check-resource Check a resource (aliases: cr)
checklist Print a Checkfile of the given pipeline (aliases: cl)
containers Print the active containers (aliases: cs)
destroy-pipeline Destroy a pipeline (aliases: dp)
destroy-team Destroy a team and delete all of its data (aliases: dt)
execute Execute a one-off build using local bits (aliases: e)
..... и т.д.
Команда из себя представляет так же один бинарник, написан на Go. Его можно скачать с гитхаба, но удобнее будет скачать воспользовавшись ссылкой внизу вэб интерфейса:
и закинуть в /usr/bin/fly, сделав его запускаемым.
Итак, вы установили fly. Для начала работы c ConcourseCI, необходимо пройти аутентификацию в ваш сервер. Делается это весьма просто:
$ fly --target office login --concourse-url=http://ci.your.concouce.server.com
Где:
- --target (или -t) вы задаёте любое имя для этого сервера (target, целевой сервер). В данном примере это имя "office". Дело в том, что вы можете иметь несколько серверов: общий для фирмы, один только для вашей команды и, предположим, один на вашем локальном компьютере, где вы тренируетесь на туториалах. И параметром -t вы можете легко переключаться между этими серверами.
- login — команда логина
- --concourse-url — вы задаёте УРЛ где находится ваш кластер ConcourseCI; указывается только в первый раз.
После ввода команды, у вас спросят логин и пароль. Введите те данные, что вы указали в docker-compose.yml файле при установке (переменные CONCOURSE_BASIC_AUTH_USERNAME и CONCOURSE_BASIC_AUTH_PASSWORD, см. выше)
Список всех доступных команд вы можете найти введя $ fly help или на странице документации.
После успешного логина вы сможете уже начать работу. Скажем, создать ваш первый конвейер можете создать этой командой:
$ fly -t office sp -c pipeline.yml -p my-pipeline-name
где:
- -t office — мы указываем целевой сервер, где мы запускаем команду (в этом примере office, который мы создали на момент логина на предыдущем шаге)
- sp (или же set-pipeline) — непосредственно, команда создания новыго конвейера. У каждой команды есть свой короткий алиас. Вы можете писать полную команду
set-pipelineили же использовать короткий псевдонимsp— результат будет идентичен - -c pipeline.yml — файл с конфигурацией самого конвейера, описываемый на языке разметки YAML. Этому посвящена следующая глава
- -p my-pipeline-name — задаём имя этого конвейереа, с которым он появится в вэб-интерфейсе.
После запуска этой команды можно открыть в браузере наш ConcourseCI и увидеть наш свежий конвейер. Изначально он будет поставлен на паузу. Чтобы сделать новый конвейер активным, нужно нажать на синюю кнопку " ▸ " в браузере

или воспользоваться командой
$ fly -t office unpause-pipeline -p my-pipeline-name
Конфигурация конвейера
Настало время рассмотреть как же происходит описание конвейера. Файл описывается форматом YAML, и может храниться в том же репозитории, что и исходники вашего проекта, то есть как бы "ближе" к коду. Выражаясь иными словами, можно сказать, что каждый проект "знает как себя собрать", потому что конфигурация лежит в нём же. Это довольно удобно, так как каждый программист сможет посмотреть детали и тонкости полной сборки, что, несомненно, может помочь в разработке.
Файл можно условно разделить на несколько частей: декларация ресурсов (resources) и описание задач (jobs). Давайте создадим простенький конвейер, скажем, Java проекта. В данном случае мы забираем исходники из Git-репозитория, запускаем тесты и собираем проект с помощью Gradle, и, скажем, закинем результат сборки в амазоновское S3 облако.
Начнём с ресурса. Описаываются они в секции resources. В нашем случае, нам нужно задекларировать два ресурса: Git-репозиторий и AWS S3.
resources:
- name: source-code
type: git
source:
uri: git@your-project.git
branch: master
private_key: |
....ключ.....
- name: aws-s3-release
type: s3
source:
bucket: releases
regexp: directory_on_s3/release-(.*).tgz
access_key_id: ....ключ....
secret_access_key: ....ключ....Имя (- name) мы задаём любое, по нему мы будем обращаться к данным ресурсам, и с таким же именем мы будем из видeть наш ресурс в браузере.
Далее создадим одно задание (job), которое будет делать три вещи:
- брать исходники из объявленного ресурса
source-code - собирать проект
- деплоить в
aws-s3-release
Задачи описываются в секции jobs: и вы можете создать их сколько угодно. В нашем простом примере мы делаем всего одну задачу с именем "Build project".
jobs:
- name: "Build project"
plan:
# получаем исходники
- get: source-code
trigger: true
# и объявляем таск, где будет совершаться
# непосредственно сама сборка
- task: "Build gradle project"
config:
platform: linux
image_resource:
type: docker-image
source: {repository: "chickenzord/alpine-gradle", tag: "latest" }
inputs:
- name: source-code
outputs:
- name: result-jar
run:
path: sh
args:
- -exc
- |
cd source-code
gradle test
gradle build
# копируем результат в output,
# чтобы он был доступен следующему шагу
cp build/libs/app.jar ../result-jar
# закидываем результат в S3
- put: aws-s3-release
params:
file: result-jar/app.jar
acl: public-read
Давайте остановимся на этом примере подробнее.
С ресурсом всё понятно: мы объявляем его как - get: что значит мы будем брать из него данные. Параметр trigger: true означает, что задача будет сама запускаться каждый раз, когда ресурс будет обновляться (в данном случае это значит, что кто-то закоммитил и запушил коммит). Можно при желании указать более специфичные параметры, которые можно посмотреть в документации к конректному ресурсу.
Таск (task). Как вы помните, именно тут происходят реальные действия. У таска есть два свойства, о которых нужно помнить:
- у него могут быть входящие и исходящие данные (inputs и outputs)
- он запускается в докер-контейнере (ну… вообще-то тут всё запускается в контейнерах, но для таска образ нужно указывать явно).
В данном примере мы указали только один входящий источник:
inputs:
- name: source-codeВходящий источник может быть либо с ресурса, либо с другого таска, который был запущен прежде (так, можно запускать таски в цепочке и передавать промежуточные результаты далее следующему). На практике это означает, что внутри контейнера у нас будет папка с таким же именем и внутрь этой папки ConcourseCI аккуратно поместит содержимое ресурса (в нашем случае — содержимое гит-репозитория). Именно поэтому самое первое, что я сделал в теле таска — это зашёл в эту папку (cd source-code), где у меня будут исходники моего Java проекта.
Ещё необходимо указать образ докера, который вы хотите использовать для сборки. Логика тут очень простая: вам нужен контейнер, внутри которого имеются все инструменты сборки для конкретного проекта. Скажем, в моём случае, поскольку проект на джаве и собирается гредлом, то внутри контейнера мне необходима джава нужной мне версии и сам гредл. Вот, например, этот образ работает и прекрасно подходит для моей задачи. Указываем этот образ в конфиге вот так:
config:
platform: linux
image_resource:
type: docker-image
source: {repository: "chickenzord/alpine-gradle", tag: "latest" }и внутри этого контейнера мы сможем запустить свои таски Гредла, что я и делаю в качестве демонстрации:
cd source-code
gradle test
gradle buildИ да, если у вас есть какие-то совсем специфичные требования по окружению сборки, то собрать свой собственный докер-образ и хранить его в вашем приватном регистре не составит никакого труда: ConcourseCI без труда может закачивать образы откуда угодно.
Стоит ещё отметить, что я описал в данном примере всё довольно подробно, чтобы было максимально понятно в одном едином YAML файле. Но таски можно вынести в отдельный YAML файл. Так удобно переиспользовать таски в разных проектах. В таком случае, таск будет объявлен всего лишь двумя строчками, в то время как его "тело" будет сохранён отдельно:
- task: hello-world
file: path/to/my_task.ymlТо же самое касается и команды run: её содержимое так же можно вынести в шелл-скрипт и ссылаться одной командой, делая код короче. Это может пригодиться, если вы, скажем, хотите протестировать скрипт локально или же покрыть его юнит тестами. В этом случае таск будет выглядить примерно так:
- task: "Run altogether"
config:
platform: linux
image_resource:
type: docker-image
source:
repository: somedocker/image
tag: latest
run:
path: path/to/script.sh
Только не забывайте, что ваш скрипт должен возвращать стандартный Unix результат выхода (0 — всё в порядке, любое другое число — ошибка). Только так ConcourseCI узнает, завершилась ли ваша команда успехом или нет.
И последним штрихом стоит коротко упомянуть о втором ресурсе, который мы объявляем как - put:, что значит что мы будем его обновлять (а не получать из него данные, как в случае с source-code).
Теперь, когда наш файл с конфигурацией готов, сохраняем в файле под любым именем, скажем, pipeline.yml и теперь нам стоит создать/обновить конвейер (pipeline) на удалённом сервере ConcourseCI командой:
$ fly -t office sp -c pipeline.yml -p my-pipeline-name
и после чего мы открываем наш браузер и видим только что созданный (или обновлённый) конвейер. Если мы сделаем коммит в наш гит-репозиторий, он запустится автоматически:
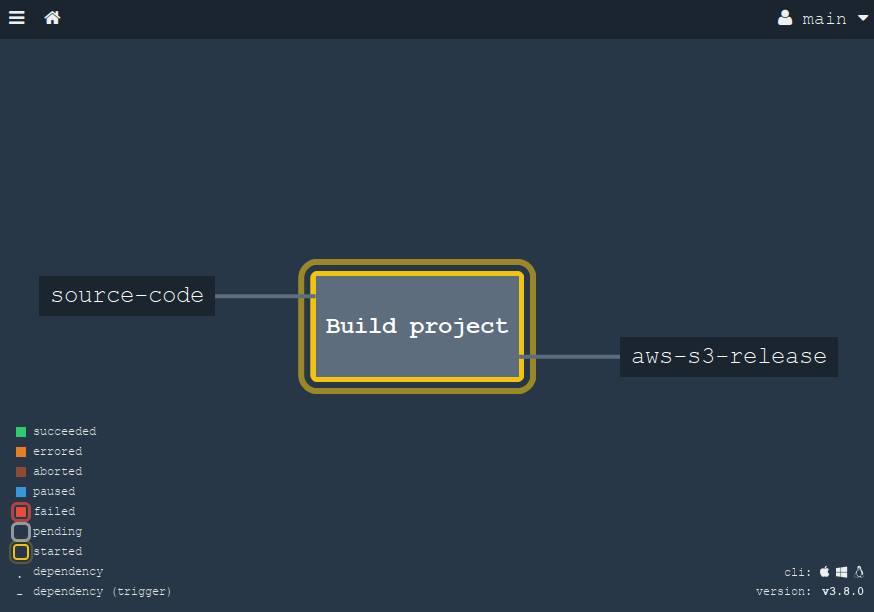
Когда мы кликнем на этот большой квадрат (job "Build project"), то нам раскроются детали. Все эти шаги на экране можно "разворачивать", чтобы посмотреть в них вывод из консоли.
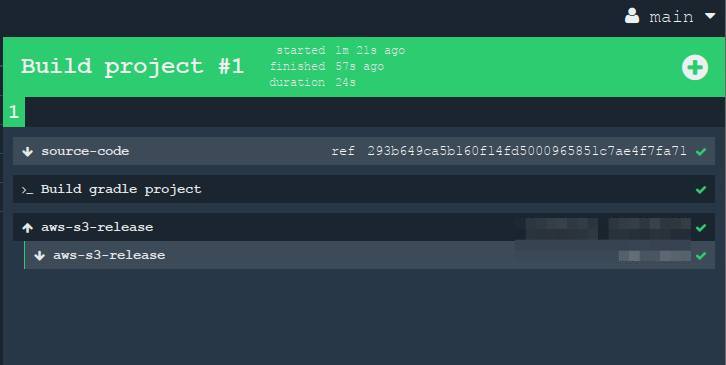
Секреты
Вы видели в моём примере, что я свои секреты (пароли, ключи) захардкодил прямо в коде. Конечно же в реальном проекте так делать не стоит в виду соображений безопасности, так как YAML-файл будет лежать в общем репозитории. Все секреты должны храниться отдельно. В конкорузе мы можем использовать специальные алиасы, в которые будут подставляться реальные значения только во время обновления конвейера. Скажем, заменим пароли и приватные ключи на плейсхолдер, заключённый в двойные скобки:
- name: source-code
type: git
source:
uri: git@your-project.git
branch: master
private_key: ((git-pivate-key))
- name: aws-s3-release
type: s3
source:
bucket: releases
regexp: directory_on_s3/release-(.*).tgz
access_key_id: ((aws-access-key))
secret_access_key: ((aws-secret-key))
И затем мы создадим локальный файл (который хранится надёжно только на вашем компьютере или в другом защищённом хранилище) с паролями и ключами в YAML формате (скажем, credentials-ci.yml), содержащий все значения:
aws-access-key: "myawsaccesskey"
aws-secret-key: "myawssecretkey"
ftp-password: "my-secure-password"
git-pivate-key: |
-----BEGIN RSA PRIVATE KEY-----
........ключ....И теперь мы должны использовать параметр --load-vars-from, чтобы подставить реальные значения для наших секретов. Итак, полная команда создания/обновления конвейера теперь выглядит так:
fly -t office sp -c pipeline.yml -p my-pipeline-name --load-vars-from ~/credentials-ci.yml
Теперь, наш конвейер будет храниться в общем репозитории, а пароли только на компьютере администратора в безопасном месте. Теперь вы спокойно можете оставлять ваш конфигуратор сборки хоть на публичном гитхабе.
Как альтернатива, можно использовать ресурс стандартного инструмента vault.
Зачем нужны таски?
Вероятно, глядя на мой пример, вы задаётесь вопросом: зачем нужны jobs и tasks и почему их нельзя объединить в одно целое (как, к примеру, это сделано в GitLabCI)? Почему одну задачу надо дробить на более мелкие шаги? Хороший вопрос, попробую объяснить на примере.
По дизайну, job — это изолированная задача, которая не зависит от других частей конвейера. Это значит, что она может быть запущена в любой момент времени и она не требует каких-то предварительных действий. Все промежуточные и конечные операции происходят внутри, а снаружи всё выглядит единым шагом. Поэтому если у вас есть какие-то операции в сборке, которые не могут существовать отдельно, все зависимые шаги стоит объеденить в одну задачу. Это даёт с одной стороны затруднение, потому что слишком много телодвижений сконцентрировано в одной задаче, с другой — у нас есть отличный инструмент чтобы разбить процесс на логические шаги: таски (tasks). Причём, каждый таск может использовать разные инструменты.
Чтобы стало понятнее, рассмотрим пример сложнее. В предыдущем параграфе я привёл пример простого проекта, который собирается всего одной командой — gradle build. Но так бывает далеко не всегда. Возьмём пример классического монолита: некий единый проект, в котором фронтенд, бэкэнд и всё-всё-всё находятся в одном репозитории. Как происходит сборка такого проекта? Перечислим все гипотетические шаги:
нам нужно собрать фронтенд. Пускай это у нас будет препроцессор стилей, например sass/less. Можно ещё оптимизировать и минифицировать JS файлы. Для того, чтобы собрать морду проекта мы скачиваем зависимости с помощью команды
npm installи после этого через какой-нибудь инструмет сборки, типаgulp/gruntсгенерируем готовый код. Вполне стандартно. После сборки мы получим некую папкуdist, где будет полностью собранный оптимизированный и минимизированный CSS и JS код.
(этот шаг добавил для демонстрационных целей, чтоб было интереснее) иногда мы хотим на этапе сборки "вшить" некую информацию о текущем релизе куда-то прямо в код, чтобы можно было легко определить, какая именно версия сейчас бегает на продакшене. Будь то, небольшая запись
build version 0.11.34.1122, которая находится внизу страницы в подвале сайта, или же некая мета-информация о текущем коммите в Git (как хэш, имя автора и дата), которые доступны в виде JSON на каком-то урле, скажем/version. Таких вариантов много. Это очень актуально, если команда использует практику continuous delivery и делает релизы очень часто. Для этого пишут небольшой скрипт, который берёт мета информацию из Git и "вшивают" намертво в какой-то конфигурационный файл или прямо в HTML шаблон, кому как удобнее. (к слову сказать, в Go можно этой же цели достичь во время компиляции с помощью флага-ldflags, но я намеренно оставил этот шаг в отдельном таске для примера)
- ну и конечно же, сборка серверной стороны. Для этого нужно скачать зависимости, перекинуть сгенерированные файлы в предыдущем шаге, собрав всё воедино. Давайте в этот раз соберём проект на языке Go. В этом языке целый зоопарк разных пакетных менеджеров, я для примера взял govendor, но сути от этого не меняется. Перед сборкой мы делаем команду
govendor fetch -v +out, которая закачает все свежие зависимости в виде исходников и поместит их в папочкуvendor(ну тут стоит оговориться, что некоторые программисты коммитят всю эту папку целиком в гит, чтобы не выгружать зависимости снова и снова; у обоих подходов есть достоинства и недостатки, обсуждение которых выходит за рамки данной статьи). Ну и после того как исходники зависистей оказались у нас локально, мы сможем всё скомпилировать.
Итак, что мы насчитали? Для полноценной сборки нам нужно иметь в нашей системе: npm, gulp, git (который, в свою очередь, зависит от ssh), go, govendor. Как мы помним, сборка в ConcourseCI осуществляется в докер-контейнере, стало быть нам логика подсказывает, что хорошо бы построить наш кастомный докер-образ, запихнуть в него всё перечисленное выше и разместить его в нашем приватном регистри? Этот образ будет иметь всё необходимое и внутри него мы сможем запускать необходимые нам команды — и git, и npm, и go, так? Да, данный способ будет работать, но так делать, конечно же, не стоит. И вот тут нам пригождается разбиение одной задачи (job) на множество под-тасков, которые будут запущенны в разных маленьких докер-контейнерах. Итак, у нас будут такие таски:
- загрузка NPM зависимостей и сборка клиентской части.
- Git
- загрузка зависимостей для Go
- сборка всего проекта
К слову сказать, все эти шаги не имеют особого смысла сами по себе, они являются частью сборки проекта. Поэтому мы их объеденяем в одну задачу (job), которая внутри разбита на четыре шага-таска, а снаружи выглядит единым цельным зелёным квадратиком и может быть запущена только все вместе.
И для каждого таска мы найдём один образ докера, который имеет только один соотвествующий инструмент, необходимый для конкретного шага. Для первого таска — образ в котором есть только один NPM, Gulp и больше ничего, для второго — только лишь с git и ssh, для третьего — только go-vendor. Согласитесь, найти готовые контейнеры для одного инструмента гораздо легче, чем один большой, но для целого зоопарка!
Более того, нам же вовсе необязательно делать первые три операции последовательно, верно? Мы же можем их сделать параллельно! Для этого ConcourseCI преставляет нам параметр aggregate, куда можно завернуть таски, которые хотим запускать одновременно, сократив время. В нашем примере, мы запустим три долгих таска параллельно, и последний, четвёртый, последовательно, когда первая группа закончит свою работу:
╭ качаем NPM зависимости, собираем фронтенд Gulp build
1. ┨получаем Git version
╰ качаем Go зависимости
2. собираем проект go buildИтак, давайте посмотрим как же может выглядеть наш готовый конвейер (деклорация ресурсов source-code и docker-example-image упущены для краткости):
...
jobs:
- name: "Build monolith example"
plan:
- get: source-code
trigger: true
# завернём три таска в aggregate,
# чтобы запустить их параллельно
- aggregate:
# Build the frontend (SASS and Javascript)
- task: "Build frontend, compile SASS, download dependencies"
config:
platform: linux
image_resource:
type: docker-image
source:
repository: 'monostream/nodejs-gulp-bower'
inputs:
- name: source-code
outputs:
- name: compiled-assets
run:
path: sh
args:
- -ec
- |
cd source-code/
# закачаем зависимости
npm install
# соберём проект
gulp build
# скопируем в результат в outputs,
# чтобы он был следующему другому таску
cp -r dist/* ../compiled-assets/
- task: "Download GO dependencies"
config:
platform: linux
image_resource:
type: docker-image
source:
repository: "electrotumbao/go-govendor"
inputs:
- name: source-code
# параметр специфичный для Go: проект на Го
# требует специальной структуры папок
# и мы создаём готовую структуру
# из нашего проекта использую
# опциональный параметр path
path: src/authorName/repoName
outputs:
- name: vendor-output
run:
path: sh
args:
- -ec
- |
export GOPATH
GOPATH="$(pwd)"
cd src/authorName/repoName/ || exit
# закачаем зависимости и сокпируем их в output,
# чтобы они были доступны следующему таску
govendor fetch -v +out
cp -r vendor/* "$GOPATH"/vendor-output
- task: "Update GIT commit details"
config:
platform: linux
image_resource:
type: docker-image
source: { repository: 'alpine/git', tag: "latest"}
inputs:
- name: source-code
outputs:
- name: versioned-file
run:
path: sh
args:
- -ec
- |
# считаем интересные нам данные из текущего коммита
cd source-code
GITSHA=$(git rev-parse HEAD)
GITAUTHOR=$(git log --format='%an %ae' -1)
GITDATE=$(git log --format='%aD' -1)
TODAY=$(date)
# вставим данные в какой-то удобный нам файл,
# допустим с помощью команды sed
sed ...
# ну и скопируем готовый файл в output,
# чтобы он был доступен другим таскам
cp version.config ../versioned-file/
# после того, как группа предыдщих тасков
# завершила свою работу, мы собираем наш проект
- task: "Build Source Code"
config:
platform: linux
image_resource:
type: docker-image
source: {repository: "golang", tag: "alpine" }
# декларируем inputs из прерыдущих тасков
# чтобы получить из них промежуточные результаты
inputs:
- name: source-code
path: src/authorName/repoName
- name: versioned-file
- name: compiled-assets
- name: vendor-output
outputs:
- name: output-for-docker
run:
path: sh
args:
- -ec
- |
set -e
export GOPATH
GOPATH="$(pwd)"
cd src/daxi.re/cyprus-tours/ || exit
# копируем промежутоные результаты из предыдущих тасков в наш проект
cp -r "$GOPATH"/compiled-assets/* ./assets/
cp -r "$GOPATH"/vendor-output/* ./vendor
# запускаем юнит тесты
go test
# наконец, компилируем проект
CGO_ENABLED=0 GOOS=linux go build -a -o app .
# дальше следует куда-то отправить собранную программу
# и этот шаг зависит от того как вы деплоите ваше приложение.
# В моём примере, я сразу же собираю докер-образ.
# Для этой цели я использую ресурс
# docker-example-image (см. ниже) и для этого я копирую
# все необходимые файлы для сборки образа в output
cp app "$GOPATH"/output-for-docker/
cp Dockerfile "$GOPATH"/output-for-docker/
# для примера, в качестве результата,
# выведем докер-образ и закинем в
# наш внутренний регистри,
# для этого в корне проекта должен
# быть Dockerfile
# (деклорацию этого ресура упустил для краткости)
- put: docker-example-image
params: { build: output-for-docker }
get_params: {rootfs: true}
Если мы загрузим этот конвейер на сервер и зайдём на конкоурз через бразуер, то мы увидим вот такую картину.
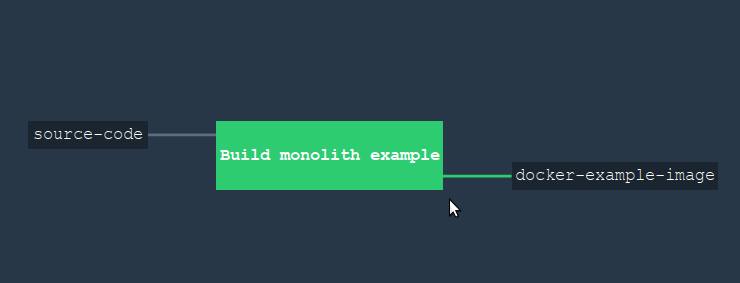
Как видите, внешне не особо поменялось, потому что вся магия скрыта в одной задаче (job). А вот если ткнуть на зелёный квардрат и открыть детали этой задачи, то мы увидим много интересного. На следующем скриншоте вы видите работающую задачу, причём два таска работают одновременно: один качает NPM зависимости, другой — Go библиотеки (третий таск уже выполнил свою работу). Параллельные таски указаны на интерфейсе вертикальной белой линией слева.
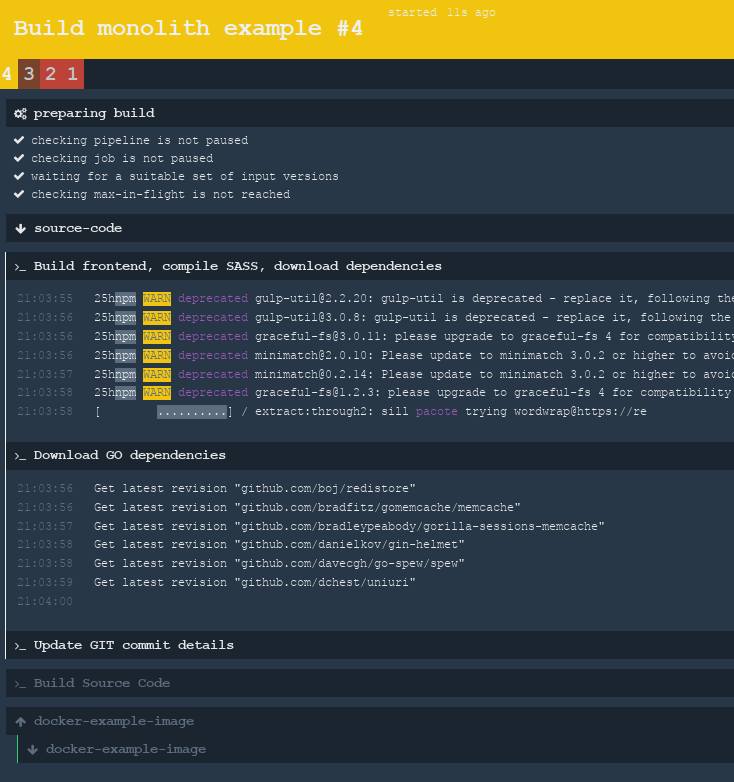
Ну и после того, как сборка завершится, готовая задача будет выглядеть вот так:
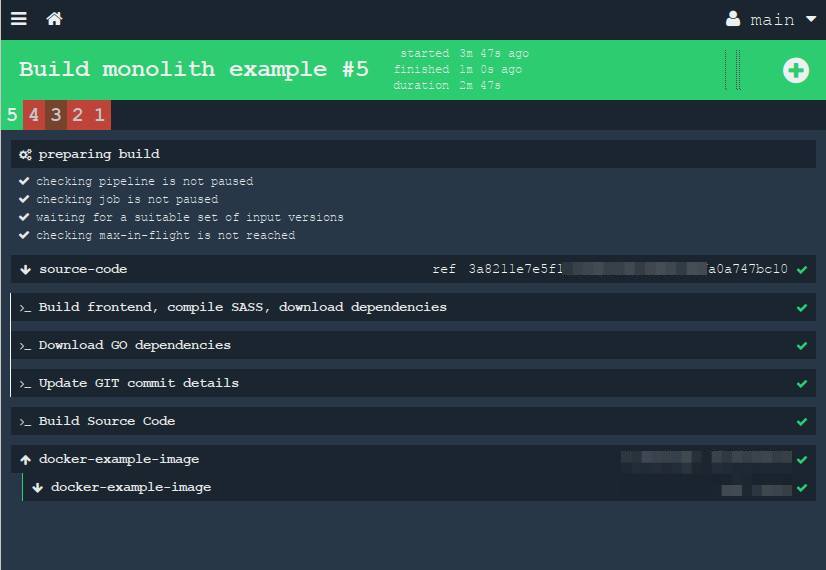
Вуаля! Обратите внимания, что для данного примера я не создавал сам ни одного докер образа для сборки! Я всё нашёл на просторах открытого докер хаба. Это является хорошей демонстрацией, как можно разбить одну задачу на множество под-тасков.
Получилось длинно, но старался быть короток и показать самые основные достоинства этого инструмента сборки. Буду рад ответить на возникшие вопросы. Спасибо, что дочитали до конца! Отличного вам дня!
Ссылки:
- Оффсайт
- Сайт с официальной документацией
- Видео с презентации "ConcourseCI: Не Дженкинском единым" с девклуба в г. Таллинн
UPD 15.3.2018: после того, как ребята поменяли адрес официального сайта по определённым причинам, я обновил все ссылки в статье.
