
Казалось бы, при загрузке приложения можно и потерпеть секунду-другую. Но когда ваша программа используется часто, а в конкурентах — аналог от производителя самой ОС, то даже время запуска начинает сказываться. Разработчик Яндекса Виктор Брыксин bobermaniac выступил на встрече сообщества CocoaHeads в офисе наших коллег в Mail.Ru и рассказал, как заставить iOS-приложение запускаться побыстрее.
— Долгое время я занимался разработкой Яндекс.Браузера. Собственно, из оптимизации времени старта этого приложения и родился мой доклад.
Проблемы, которые мы решали в браузере, — общие для всех iOS-приложений. Если вы возьмете телефон и запустите что-нибудь, то, скорее всего, 2–3 секунды вы будете наблюдать сплэш-скрин. Мой личный рекордсмен — 7 секунд, не буду называть приложение, но это потрясающе: пока ты открываешь и смотришь на красивую картинку, ты уже забыл, что ты хотел с этим приложением сделать.
Наш браузер себе такого позволить не мог. У браузера есть ряд сценариев, которые требуют от приложения немедленного отклика. Пользователь должен иметь возможность быстро, на лету, открыть браузер, вбить что-то в поисковую строчку, получить ответ или прочитать что-то на бегу. Наверное, вы тоже на бегу, в переходах метро, читаете какие-то статейки урывками, потому что времени не очень много.
Естественно, у браузера есть фичи, от которых мы не можем просто так избавиться — ради них пользователи пользуются нашим продуктом.
Кроме того, у нас есть конкуренты. И один из наших главных конкурентов — встроенный в iOS браузер Safari, который стотонной гирей над нами нависает, занимает такое же доминирующее положение, как в свое время занимал IE в Windows, если вы помните. С ним нам тоже приходится конкурировать, поэтому необходимо постоянно уменьшать время запуска нашего браузера.
В свое время мы подошли к этой проблеме с наивностью, свойственной всем разработчикам. По их мнению, чтобы оптимизировать что-то, достаточно профилировщика и собственного опыта.
К нам в определенный момент подходил менеджер и говорил, что приложение тупит, тормозит, все плохо. Разработчики говорили — окей, посмотрим, оптимизируем, все будет прекрасно.
Оптимизировали. В результате получалась сборочка, которую тестирование себе брало и садилось с секундомером, потому что требовалось проверить, что мы все сделали правильно, нигде не налажали и все запускается быстрее. С секундомером они замеряли время старта, убеждались, что оно стало меньше, все прекрасно.
В дальнейшем этот подход эволюционировал. Вместо того, чтобы сажать тестировщика и давать ему секундомер, мы начали использовать видео. Снимали видео до оптимизации и после, накладывали друг на друга, смотрели покадрово, где какой элемент браузера появляется, как реагирует, все ли хорошо.
В дальнейшем менеджер почувствовал в себе видеомонтажера. Он начал снимать по пять видео до, по пять видео после, чтобы нивелировать эффекты, связанные со случайностью. Всем известно, что иногда время старта зависит от погоды на Марсе, и с этим просто ничего нельзя сделать.

Менеджер обрел навыки видеомонтажера, но нам это не помогало. У такого подхода было огромное количество проблем.
В первую очередь, об оптимизации мы вспоминали только тогда, когда все начинало тормозить. Мы оптимизировали, а через некоторое время все это деградировало. Кто-то вносит другие изменения, появляются новые фичи, и со временем опять все становится очень плохо. И у нас не было инструментов, чтобы контролировать это. А если мы не хотим потерять какой-то эффект, нам нужно осуществлять непрерывный контроль. К сожалению, вариант с видео, который мы использовали, достаточно трудоемок, чтобы использовать его постоянно. Он нам не подходил.

Поэтому сегодня мы поговорим о том, как правильно выстроить процесс оптимизации времени запуска, если вы действительно хотите получить какой-то эффект, и долгое время поддерживать его.
В первую очередь мы поговорим о метриках — без нихвообще невозможен никакой процесс, особенно такой, как оптимизация.
Мы поговорим о том, что из чужого опыта удалось адаптировать для себя. Поговорим о проекте Fake UI — благодаря ему нам удалось построить интерфейс, который буквально вылетает в лицо пользователю и говорит: «Работай со мной быстрее».
Вкратце расскажу об устранении горячих точек. Это тема, в которой немного понимают все, кто хоть раз занимался оптимизацией. Про ленивые сервисы, которые принесли нам очень много проблем, и об оценке, которую мы в итоге получаем.
Начнем с метрик. Вот первое и главное, с чем надо выходить с этого доклада. Если у вас нет удобных метрик, вы никогда не сможете сделать удобную оптимизацию, которая будет поддерживаться. Пример с видео. Менеджеру надо потратить очень много времени, чтобы снять метрики по видео, мы не могли снимать их постоянно. В итоге это делалось как-то, все терялось, и самое главное, мы не могли в промежутке найти, где потерялась та или иная оптимизация. Поэтому чем чаще мы будем снимать метрики, тем лучше для нас.
Метрики должны сниматься быстро, часто, быть простыми и понятными. Для браузера мы все выбранные метрики поделили на две большие группы — основные и вспомогательные. Основные — это те, что непосредственно ощущает пользователь, что влияют на его ощущение от работы браузера, и те, которые он видит. Они должны быть количественными, с цифрами легко работать, можно их складывать, вычитать, даже вычитать квадратные корни, но я лично не пробовал. И самое главное — они должны быть объективными. Как показал пример тестировщика с секундомером, слишком много стохастических факторов приводят к тому, что метрика вместо того, чтобы показывать эффект от приносимых улучшений, начинает показывать температуру за окном.
Основные метрики — это то, что мы хотим улучшать в процессе разработки продукта. Есть вспомогательные метрики. Они очень похожи на основные, за исключением того, что они уже существуют в мире разработчика. Это какие-то вещи, которые пользователям не видны, но разработчику скажут о том, что происходит у него в продукте, гораздо больше, чем обычное число.
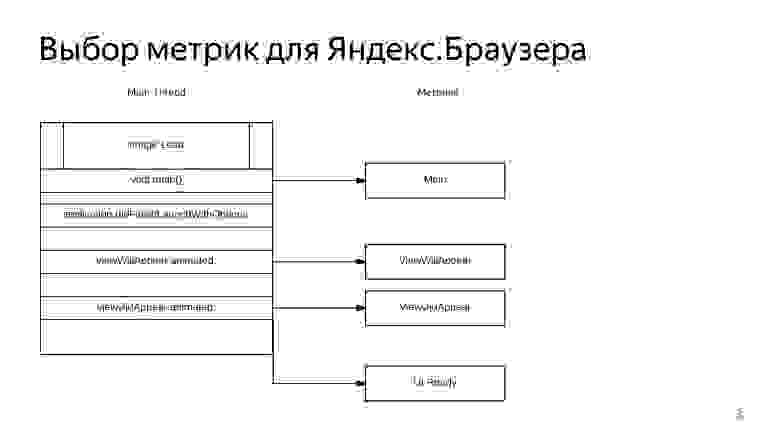
Для Яндекс.Браузера мы выбрали четыре метрики. Две из них вспомогательные, существуют для разработчика, и две основные.
Все эти метрики являются числами, которые показывают количество, условно, секунд, которые проходят от момента, когда пользователь тыкает на иконку приложения.
Первая точка, которую мы снимаем, это момент, когда запускается Main. Вторая, как только в оконной иерархии появился RootViewController и у него есть View. Мы снимаем точку, в которой выполняется ViewWillAppear.
Третья метрика — ViewDidAppear. Четвертая, самая интересная, это то, что мы в конце ViewDidAppear запускаем на главный поток с помощью Dispatch Async блок. И тот момент, когда он выполнится, это четвертая позиция, которую мы назвали UI Ready, самая важная. Мы еще часто будем в дальнейшем использовать. И основные оценки будем давать по ней.
Вкратце о том, что каждая из этих цифр значит. Main показывает самую понятную вещь — это момент, когда мы запустили приложение, весь образ запускается в память, происходят load, initialise, все что касается динамически загружаемых библиотек находится там. Он показывает эффект от тех библиотек, что у нас загружены в проект.
После этого выполняется application:didFinishLaunchingWithOptions, естественно. Конфигурируются некоторые сервисы, которые в дальнейшем будут использоваться, и после этого наступает момент ViewDidAppear.
Поэтому второе число ViewDidAppear показывает эффект от сконфигурированных, наших уже, собственных пользовательских сервисов.
В свою очередь ViewDidAppear как основная метрика показывает момент, когда пользователь наконец увидел на экране интерфейс приложения, с которым собирается работать.
И наконец UI Ready. На момент, когда интерфейс показан, он может быть заблокирован огромным количеством кода, который все еще должен выполниться на главном потоке. Из-за этого пользователь видит, но потрогать не может.
Четвертая метрика UI Ready, когда мы планируем блок на главный поток, показывает, когда он наконец разгрузился, и пользователь может взаимодействовать с нашим приложением.
Основная гипотеза, от которой мы отталкивались, что если мы уменьшим метрику UI Ready, то есть тот момент, когда пользователь сможет работать с приложением, то пользователь это заметит, поймет, что для него это хорошо, сможет радоваться продукту больше. А значит, у нас будут расти продуктовые метрики, такие как процент возврата. То есть мы должны наблюдать на графиках корреляцию: время старта UI Ready идет вниз — продуктовые метрики идут вверх.
Чтобы оценивать эффект от оптимизации, мы собираем метрики у разработчиков. Как только разработчик что-то делает, мы берем его сборку, после того как pull request влился в мастер, мы с мастера собираем сборки постоянно и отправляем на специальный тестировочный стенд. Это обычный Mac, подключенный к сети, к которому подключено устройство, у нас это был iPad Mini на базе iOS 8, как самое тормозное устройство на тот момент. На него ставится сборка, и запускается несколько сотен раз. Каждый раз мы получаем какие-то цифры по всем четырем метрикам, собираем их, усредняем и отправляем на специальный стенд, где по этим цифрам строится красивый график того, как время меняется с течением времени. Позже я эти графики покажу.
Эти цифры мы используем, чтобы быстро понять, к чему приводят изменения, которые мы вносим в проект.
Естественно, мы это делаем для пользователей, и собираем метрики у пользователей тоже. Те пользователи, которые разрешили отправку анонимной статистики, мы берем эти цифры и отправляем себе. Естественно, пользователя нельзя попросить запустить наше приложение 200 раз, но количество пользователей в принципе нивелирует здесь эффект случайности.
Надеюсь, вы поняли, что метрики — это важно. И когда у вас встанет такая задача, вы воспользуетесь этим советом.
Что касается того опыта, что мы переняли у других людей, в первую очередь я хотел бы сослаться на доклад моего коллеги Николая Лихогруда — «Оптимизация времени запуска iOS-приложений».

Он касается прежде всего времени запуска системных вещей, таких как загрузка динамических библиотек, что я говорил вначале, метрика Main, загрузка образа. Все это очень хорошо там описано, и мы тоже воспользовались его советами, отказались от динамических библиотек в браузере, все линкуется статистически.
Естественно, мы отказались от Swift, когда мы все это делали, у нас был еще iOS 7, для которого поддержка Swift сильно влияла на метрики и приводила к огромному росту всех цифр. Мы попробовали его использовать, увидели рост и отказались от этой идеи достаточно быстро.
Удивительно, но улучшение быстродействия показало просто перевод ресурсов из сырых ресурсов… Кто знает, мы можем просто положить картинку в xcassets, которые грузятся гораздо быстрее сырых ресурсов. И для проектов с большой историей, когда некоторые вещи просто не трогаются в силу того, что это никому не надо, это может быть актуально, если у вас еще есть сырые ресурсы в проекте, рекомендую их перевести в xcassets, и вы на ровном месте получите выигрыш в производительности.
К сожалению, у нас есть библиотеки, которые негативно влияют на время старта. Видимо, из-за того, что там выполняются множественные лоады и подобная штука. В первую очередь мы столкнулись с этим при использовали Facebook SDK, для которого мы воспользовались ленивой загрузкой и поздним связыванием, при котором мы не взаимодействуем с этой библиотекой напрямую, а используем Dial D и тому подобные вещи.
У меня не будет такого хардкора, как у моих коллег. Будет много красивых картинок.
Первая проблема в браузере — это проблема ядра. Многие знают или догадываются, что браузер основан на ядре Chromium, там есть код и от наших ребят, оно шарится между нашим десктопным браузером, мобильным браузером, и предоставляет множество функциональности, без которой работа браузера была бы не особо полезна.
Проблема iOS версии, что ядро для iOS — это монолит. Это большой объем кода, который загружается одномоментно, некоторое время работает, и только когда он наконец загрузится, мы можем предоставить пользователю какую-то функциональность.
С этим невозможно было мириться. Пользователь вроде уже увидел интерфейс, но ядро не загрузилось, интерфейс заблокирован, он ничего не может сделать.
Мы решили с этим что-то предпринять.
Первая идея, которая у нас была — а что если его выпилить? Если ядро тормозит, давайте его просто выкинем и не будет никаких проблем, все станет прекрасно.
Мы даже не пытались. Понятно, что когда ядро тебе дает огромное количество переиспользуемой функциональности, то выкинуть его, означало бы написать его с нуля, но уже своими силами. Пойти на это — это бессмысленно, выкидывать код, который работает, чтобы написать еще один такой же, который будет работать хуже.
Мы пошли по другому пути. Если есть UI, зависящий от ядра, который не может ничего сделать без него, почему бы не дать пользователю другой UI? Маленький, который, возможно, умеет не все, но может прекрасно работать без ядра, и который позволит пользователю выполнить какой-то набор сценариев, характерных для режима, когда нам надо быстро открыть приложение, и быстро в нем что-то сделать.
Естественно, он будет интерактивным, в нем можно будет писать, и он должен прозрачно переключиться на большой UI, как только ядро будет загружено.

Как мы это сделали на примере такого компонента, как Omnibox?
Все знают или догадываются, что браузер состоит из WebView и текстового филда для ввода запроса. Естественно, это не так. Филд для ввода запроса называется Omnibox. Ядро давало множество вещей, такие как саджесты, красивое форматирование URL, там же была работа с progress bar, и без этого всего Omnibox был мало функционален. Но нам очень хотелось, чтобы мы дали пользователю возможность до старта взять и что-то туда ввести.

Мы взяли большой Omnibox и разделили его на два. Старая модель Omnibox осталась точно такой же, так же работала с ядром. Рядом мы положили новую модель, которая была полностью от него оторвана, работала с какими-то кэшированными данными, мы их объединили в один большой композит, который маршрутизовал вызовы в зависимости от того, было ли загружено ядро или нет.
Пока ядро не загружено, у нас вызовы шли в кэшированный Omnibox и ответы шли оттуда. Как только ядро загружалось, мы переключались.

Чтобы у пользователя не было ощущения, что у него что-то сломалось, когда он выгрузил браузер, потом снова его запустил и увидел пустой Omnibox, а только что он был заполнен, мы сделали небольшой кэшик. Большой Omnibox, зависящий от ядра, писал в этот кэш, а кешированный Omnibox, как только он поднимался, из этого кэша читал и давал пользователю то состояние, с которым он остался.

И чтобы поддержать бесшовное переключение, мы сделали небольшой компонент, который в момент, когда ядро наконец стартует, фактически синхронизирует состояние кеширования Omnibox с нормальным. И для пользователя все выглядит так, будто он просто запустил браузер, начал в нем что-то делать и браузер просто работает. Он даже не замечает момента переключения.
При этом интерфейс стал стартовать гораздо быстрее. Как я уже говорил, раньше до старта ядра мы делали просто UserInteractionEnabled = null, и нет, уважаемый пользователь, ты ничего не сделаешь. Теперь мы разрешили UserInteraction, и увидели, что проблемы остались.
К сожалению, помимо ядра у нас были собственные сервисы, написанные нами. Некоторые из них тоже от ядра зависели и очень любили подписываться на callback, который сигнализировал о том, что ядро наконец запущено.
В тот момент, когда ядро загрузилось, все эти сервисы радостно бежали инициализироваться, и забивали главный поток, в результате чего интерфейс есть, взаимодействовать с ним можно было бы, но главный поток забит, в него не проходит ни одно сообщение.

Выглядело это примерно так. Было два десятка таких условных сервисов, которые что-то там делали, иногда делали много. Пока их было один-два, это не было проблемой, но их число постоянно росло вместе с ростом числа фич.

Сам по себе Chromium.performAfterStartup ничего не делал, он просто брал все колбэки, которые на него подписались, и большой пачкой записывал в главный поток. 20 сервисов в главном потоке — увы, надо было что-то сделать.
Поэтому мы отказались от одномоментного запуска всех сервисов. Первое, что мы сделали, некоторые сервисы перестали ждать Chromium, а были отложены на более поздний срок.
В основном это все, что касалось статистики и прочих вещей, которые пользователям либо не необходимы, либо не являются необходимыми прямо сразу. Все, что мы могли отложить, мы отложили на более дальний срок.

Мы решили, что те сервисы, которые мы не смогли отложить, мы будем запускать по одному — просто давая возможность главному потоку что-то провернуть в промежутке между запусками сервисов. Таким образом у пользователей хоть и был интерфейс, который лагал, но в то же время у него была возможность с ним взаимодействовать. И он был еще чуть-чуть ближе к счастью.
К сожалению, счастье было недолгим, потому что появились ленивые сервисы.

Проблема ленивых сервисов в том, что время их запуска не определено. С одной стороны, это не проблема, а их преимущество, потому что мы можем использовать ленивые сервисы тогда, нам необходимо максимально отложить его запуск до того момента, когда он действительно понадобится. Но бывает так, что ленивые сервисы, ссылаясь друг на друга, и трогая друг друга, собираются в огромные пачки, начинают запускаться всей толпой, в этом месте образуется горячая точка, которая может переместиться в другое место, если случайно задеть там этот ленивый сервис. Поэтому мы приняли решение, что отсутствие контроля это не очень хорошо для приложения, и мы будем отказываться от ленивости — прежде всего за счет того, что мы выделили определенные точки, где должны подгружаться те или иные сервисы.

Эти точки были там, где мы хотим, где приложение может быть более разгруженным и можно его запустить. А к моменту, когда кто-то начинает работать с этим сервисом, сервис был полностью готов.

Кроме того, естественно, рекомендуется, чтобы никаких тяжелых операций на главном потоке при запуске сервиса не было. Главный поток слишком важен для пользователя, чтобы просто забивать его чтением каких-то файлов и тому подобной ерундой. Все задачи, требующие большого количества времени, должны быть вынесены в отдельные потоки.
В браузере, чтобы понимать, когда был загружен тот или иной сервис в таких случаях, мы используем Promise. Я не касаюсь этой темы, про него уже много рассказывали.
Реальные графики с продакшена.
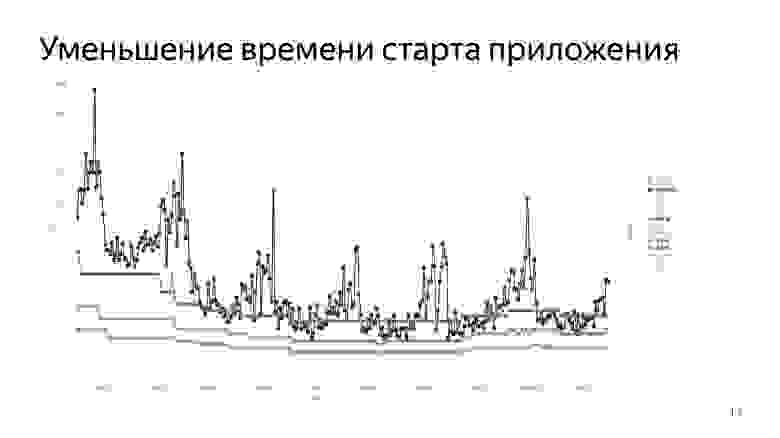
Мы действительно уменьшили время старта приложения. Это то, что у нас получилось. Эти ужасные пилообразные линии — средние. Почему они такие? К сожалению, у нас есть одна нерешенная проблема, связанная с тем, что когда мы замеряем у пользователя время, иногда по каким-то причинам это время слишком велико. Например, некоторые пользователи в статистику сообщали, что время старта — четыре года, во что я с трудом верю, потому что четыре года сидеть и смотреть на сплэш-скрин — это слишком даже для меня, который привык к 7-секундному запуску.
Но можно посмотреть на квантили 50%, 70% и 90%. Это то, как у пользователя в массе снижалось время старта по мере наших оптимизаций.
В конце небольшой рост, связанный с тем, что мы в очередной раз перешли с этапа оптимизации на этап добавления новых фич. Фичи аффектят время старта, и через некоторое время нам снова придется выполнять процесс оптимизации.
Что касается метрик у разработчиков, тут такой график.

График красивый и даже страшный, но он выполняет свою работу. Он показывает, что именно происходит. Думаю, даже первый раз видя этот график, вы сможете сказать, где получилось классно, а где мы крупно облажались.
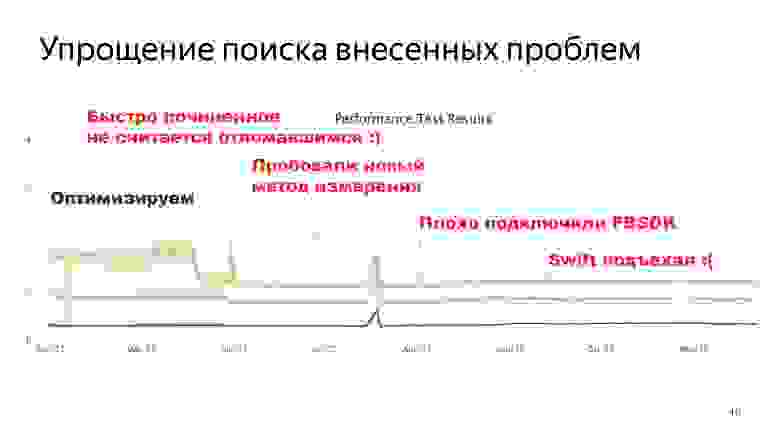
Я могу даже выделить отдельные точки, где происходили те или иные вещи.
Я говорил про Swift и про то, что сейчас это не является проблемой. У нас есть маленькая точка, где мы видим рост Main. Он с расстояния не очень очевиден, но он есть и не очень большой — по крайней мере, не настолько большой, чтобы продолжать не использовать Swift. Поэтому сейчас есть Swift, мы на нем пишем.
Эти графики дали возможность все сразу оценивать. У нас даже появился алгоритм, по которому мы вносим изменения в проект. Первое, что мы делаем: разработчик садится со старым добрым профилировщиком, делает оптимизации, готовит pull request, с которого мы собираем сборку. Мы отправляем ее на наш замечательный тестировочный стенд, который делает несколько сотен прогонов и дает четыре цифры. Мы их сравниваем с текущим мастером, который, в свою очередь, постоянно проверяется, и мы можем сказать, хорошо поработал разработчик или стоит еще поработать. Если кто-то что-то случайно зацепил и зааффектил время старта, то не позднее чем через два часа мы об этом узнаем и с легкостью найдем тот коммит, где произошла проблема.
В заключение: сначала метрики и только потом оптимизации. Без метрик все оптимизации рано или поздно потеряются, а это точно не то, чего хотите вы и ваши пользователи. Бессмысленно делать одну и ту же работу несколько раз, а пользователям очень нравится, когда приложение стартует быстро и очень не нравится видеть сплэш-скрин по семь секунд. Спасибо.
— Долгое время я занимался разработкой Яндекс.Браузера. Собственно, из оптимизации времени старта этого приложения и родился мой доклад.
Проблемы, которые мы решали в браузере, — общие для всех iOS-приложений. Если вы возьмете телефон и запустите что-нибудь, то, скорее всего, 2–3 секунды вы будете наблюдать сплэш-скрин. Мой личный рекордсмен — 7 секунд, не буду называть приложение, но это потрясающе: пока ты открываешь и смотришь на красивую картинку, ты уже забыл, что ты хотел с этим приложением сделать.
Наш браузер себе такого позволить не мог. У браузера есть ряд сценариев, которые требуют от приложения немедленного отклика. Пользователь должен иметь возможность быстро, на лету, открыть браузер, вбить что-то в поисковую строчку, получить ответ или прочитать что-то на бегу. Наверное, вы тоже на бегу, в переходах метро, читаете какие-то статейки урывками, потому что времени не очень много.
Естественно, у браузера есть фичи, от которых мы не можем просто так избавиться — ради них пользователи пользуются нашим продуктом.
Кроме того, у нас есть конкуренты. И один из наших главных конкурентов — встроенный в iOS браузер Safari, который стотонной гирей над нами нависает, занимает такое же доминирующее положение, как в свое время занимал IE в Windows, если вы помните. С ним нам тоже приходится конкурировать, поэтому необходимо постоянно уменьшать время запуска нашего браузера.
В свое время мы подошли к этой проблеме с наивностью, свойственной всем разработчикам. По их мнению, чтобы оптимизировать что-то, достаточно профилировщика и собственного опыта.
К нам в определенный момент подходил менеджер и говорил, что приложение тупит, тормозит, все плохо. Разработчики говорили — окей, посмотрим, оптимизируем, все будет прекрасно.
Оптимизировали. В результате получалась сборочка, которую тестирование себе брало и садилось с секундомером, потому что требовалось проверить, что мы все сделали правильно, нигде не налажали и все запускается быстрее. С секундомером они замеряли время старта, убеждались, что оно стало меньше, все прекрасно.
В дальнейшем этот подход эволюционировал. Вместо того, чтобы сажать тестировщика и давать ему секундомер, мы начали использовать видео. Снимали видео до оптимизации и после, накладывали друг на друга, смотрели покадрово, где какой элемент браузера появляется, как реагирует, все ли хорошо.
В дальнейшем менеджер почувствовал в себе видеомонтажера. Он начал снимать по пять видео до, по пять видео после, чтобы нивелировать эффекты, связанные со случайностью. Всем известно, что иногда время старта зависит от погоды на Марсе, и с этим просто ничего нельзя сделать.

Менеджер обрел навыки видеомонтажера, но нам это не помогало. У такого подхода было огромное количество проблем.
В первую очередь, об оптимизации мы вспоминали только тогда, когда все начинало тормозить. Мы оптимизировали, а через некоторое время все это деградировало. Кто-то вносит другие изменения, появляются новые фичи, и со временем опять все становится очень плохо. И у нас не было инструментов, чтобы контролировать это. А если мы не хотим потерять какой-то эффект, нам нужно осуществлять непрерывный контроль. К сожалению, вариант с видео, который мы использовали, достаточно трудоемок, чтобы использовать его постоянно. Он нам не подходил.

Поэтому сегодня мы поговорим о том, как правильно выстроить процесс оптимизации времени запуска, если вы действительно хотите получить какой-то эффект, и долгое время поддерживать его.
В первую очередь мы поговорим о метриках — без нихвообще невозможен никакой процесс, особенно такой, как оптимизация.
Мы поговорим о том, что из чужого опыта удалось адаптировать для себя. Поговорим о проекте Fake UI — благодаря ему нам удалось построить интерфейс, который буквально вылетает в лицо пользователю и говорит: «Работай со мной быстрее».
Вкратце расскажу об устранении горячих точек. Это тема, в которой немного понимают все, кто хоть раз занимался оптимизацией. Про ленивые сервисы, которые принесли нам очень много проблем, и об оценке, которую мы в итоге получаем.
Начнем с метрик. Вот первое и главное, с чем надо выходить с этого доклада. Если у вас нет удобных метрик, вы никогда не сможете сделать удобную оптимизацию, которая будет поддерживаться. Пример с видео. Менеджеру надо потратить очень много времени, чтобы снять метрики по видео, мы не могли снимать их постоянно. В итоге это делалось как-то, все терялось, и самое главное, мы не могли в промежутке найти, где потерялась та или иная оптимизация. Поэтому чем чаще мы будем снимать метрики, тем лучше для нас.
Метрики должны сниматься быстро, часто, быть простыми и понятными. Для браузера мы все выбранные метрики поделили на две большие группы — основные и вспомогательные. Основные — это те, что непосредственно ощущает пользователь, что влияют на его ощущение от работы браузера, и те, которые он видит. Они должны быть количественными, с цифрами легко работать, можно их складывать, вычитать, даже вычитать квадратные корни, но я лично не пробовал. И самое главное — они должны быть объективными. Как показал пример тестировщика с секундомером, слишком много стохастических факторов приводят к тому, что метрика вместо того, чтобы показывать эффект от приносимых улучшений, начинает показывать температуру за окном.
Основные метрики — это то, что мы хотим улучшать в процессе разработки продукта. Есть вспомогательные метрики. Они очень похожи на основные, за исключением того, что они уже существуют в мире разработчика. Это какие-то вещи, которые пользователям не видны, но разработчику скажут о том, что происходит у него в продукте, гораздо больше, чем обычное число.

Для Яндекс.Браузера мы выбрали четыре метрики. Две из них вспомогательные, существуют для разработчика, и две основные.
Все эти метрики являются числами, которые показывают количество, условно, секунд, которые проходят от момента, когда пользователь тыкает на иконку приложения.
Первая точка, которую мы снимаем, это момент, когда запускается Main. Вторая, как только в оконной иерархии появился RootViewController и у него есть View. Мы снимаем точку, в которой выполняется ViewWillAppear.
Третья метрика — ViewDidAppear. Четвертая, самая интересная, это то, что мы в конце ViewDidAppear запускаем на главный поток с помощью Dispatch Async блок. И тот момент, когда он выполнится, это четвертая позиция, которую мы назвали UI Ready, самая важная. Мы еще часто будем в дальнейшем использовать. И основные оценки будем давать по ней.
Вкратце о том, что каждая из этих цифр значит. Main показывает самую понятную вещь — это момент, когда мы запустили приложение, весь образ запускается в память, происходят load, initialise, все что касается динамически загружаемых библиотек находится там. Он показывает эффект от тех библиотек, что у нас загружены в проект.
После этого выполняется application:didFinishLaunchingWithOptions, естественно. Конфигурируются некоторые сервисы, которые в дальнейшем будут использоваться, и после этого наступает момент ViewDidAppear.
Поэтому второе число ViewDidAppear показывает эффект от сконфигурированных, наших уже, собственных пользовательских сервисов.
В свою очередь ViewDidAppear как основная метрика показывает момент, когда пользователь наконец увидел на экране интерфейс приложения, с которым собирается работать.
И наконец UI Ready. На момент, когда интерфейс показан, он может быть заблокирован огромным количеством кода, который все еще должен выполниться на главном потоке. Из-за этого пользователь видит, но потрогать не может.
Четвертая метрика UI Ready, когда мы планируем блок на главный поток, показывает, когда он наконец разгрузился, и пользователь может взаимодействовать с нашим приложением.
Основная гипотеза, от которой мы отталкивались, что если мы уменьшим метрику UI Ready, то есть тот момент, когда пользователь сможет работать с приложением, то пользователь это заметит, поймет, что для него это хорошо, сможет радоваться продукту больше. А значит, у нас будут расти продуктовые метрики, такие как процент возврата. То есть мы должны наблюдать на графиках корреляцию: время старта UI Ready идет вниз — продуктовые метрики идут вверх.
Чтобы оценивать эффект от оптимизации, мы собираем метрики у разработчиков. Как только разработчик что-то делает, мы берем его сборку, после того как pull request влился в мастер, мы с мастера собираем сборки постоянно и отправляем на специальный тестировочный стенд. Это обычный Mac, подключенный к сети, к которому подключено устройство, у нас это был iPad Mini на базе iOS 8, как самое тормозное устройство на тот момент. На него ставится сборка, и запускается несколько сотен раз. Каждый раз мы получаем какие-то цифры по всем четырем метрикам, собираем их, усредняем и отправляем на специальный стенд, где по этим цифрам строится красивый график того, как время меняется с течением времени. Позже я эти графики покажу.
Эти цифры мы используем, чтобы быстро понять, к чему приводят изменения, которые мы вносим в проект.
Естественно, мы это делаем для пользователей, и собираем метрики у пользователей тоже. Те пользователи, которые разрешили отправку анонимной статистики, мы берем эти цифры и отправляем себе. Естественно, пользователя нельзя попросить запустить наше приложение 200 раз, но количество пользователей в принципе нивелирует здесь эффект случайности.
Надеюсь, вы поняли, что метрики — это важно. И когда у вас встанет такая задача, вы воспользуетесь этим советом.
Что касается того опыта, что мы переняли у других людей, в первую очередь я хотел бы сослаться на доклад моего коллеги Николая Лихогруда — «Оптимизация времени запуска iOS-приложений».

Он касается прежде всего времени запуска системных вещей, таких как загрузка динамических библиотек, что я говорил вначале, метрика Main, загрузка образа. Все это очень хорошо там описано, и мы тоже воспользовались его советами, отказались от динамических библиотек в браузере, все линкуется статистически.
Естественно, мы отказались от Swift, когда мы все это делали, у нас был еще iOS 7, для которого поддержка Swift сильно влияла на метрики и приводила к огромному росту всех цифр. Мы попробовали его использовать, увидели рост и отказались от этой идеи достаточно быстро.
Удивительно, но улучшение быстродействия показало просто перевод ресурсов из сырых ресурсов… Кто знает, мы можем просто положить картинку в xcassets, которые грузятся гораздо быстрее сырых ресурсов. И для проектов с большой историей, когда некоторые вещи просто не трогаются в силу того, что это никому не надо, это может быть актуально, если у вас еще есть сырые ресурсы в проекте, рекомендую их перевести в xcassets, и вы на ровном месте получите выигрыш в производительности.
К сожалению, у нас есть библиотеки, которые негативно влияют на время старта. Видимо, из-за того, что там выполняются множественные лоады и подобная штука. В первую очередь мы столкнулись с этим при использовали Facebook SDK, для которого мы воспользовались ленивой загрузкой и поздним связыванием, при котором мы не взаимодействуем с этой библиотекой напрямую, а используем Dial D и тому подобные вещи.
У меня не будет такого хардкора, как у моих коллег. Будет много красивых картинок.

Первая проблема в браузере — это проблема ядра. Многие знают или догадываются, что браузер основан на ядре Chromium, там есть код и от наших ребят, оно шарится между нашим десктопным браузером, мобильным браузером, и предоставляет множество функциональности, без которой работа браузера была бы не особо полезна.
Проблема iOS версии, что ядро для iOS — это монолит. Это большой объем кода, который загружается одномоментно, некоторое время работает, и только когда он наконец загрузится, мы можем предоставить пользователю какую-то функциональность.
С этим невозможно было мириться. Пользователь вроде уже увидел интерфейс, но ядро не загрузилось, интерфейс заблокирован, он ничего не может сделать.
Мы решили с этим что-то предпринять.
Первая идея, которая у нас была — а что если его выпилить? Если ядро тормозит, давайте его просто выкинем и не будет никаких проблем, все станет прекрасно.
Мы даже не пытались. Понятно, что когда ядро тебе дает огромное количество переиспользуемой функциональности, то выкинуть его, означало бы написать его с нуля, но уже своими силами. Пойти на это — это бессмысленно, выкидывать код, который работает, чтобы написать еще один такой же, который будет работать хуже.
Мы пошли по другому пути. Если есть UI, зависящий от ядра, который не может ничего сделать без него, почему бы не дать пользователю другой UI? Маленький, который, возможно, умеет не все, но может прекрасно работать без ядра, и который позволит пользователю выполнить какой-то набор сценариев, характерных для режима, когда нам надо быстро открыть приложение, и быстро в нем что-то сделать.
Естественно, он будет интерактивным, в нем можно будет писать, и он должен прозрачно переключиться на большой UI, как только ядро будет загружено.
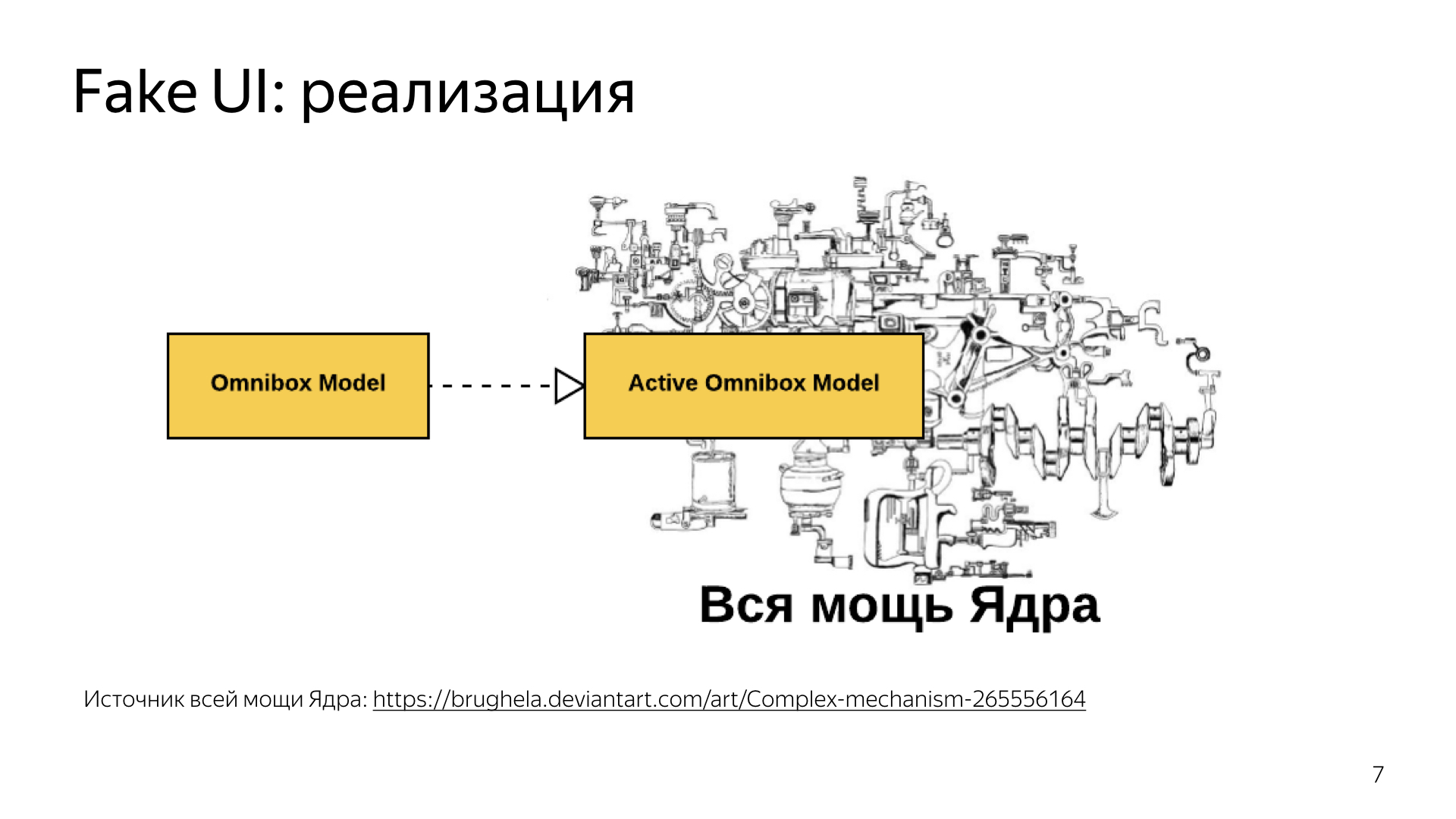
Ссылка на deviantart
Как мы это сделали на примере такого компонента, как Omnibox?
Все знают или догадываются, что браузер состоит из WebView и текстового филда для ввода запроса. Естественно, это не так. Филд для ввода запроса называется Omnibox. Ядро давало множество вещей, такие как саджесты, красивое форматирование URL, там же была работа с progress bar, и без этого всего Omnibox был мало функционален. Но нам очень хотелось, чтобы мы дали пользователю возможность до старта взять и что-то туда ввести.
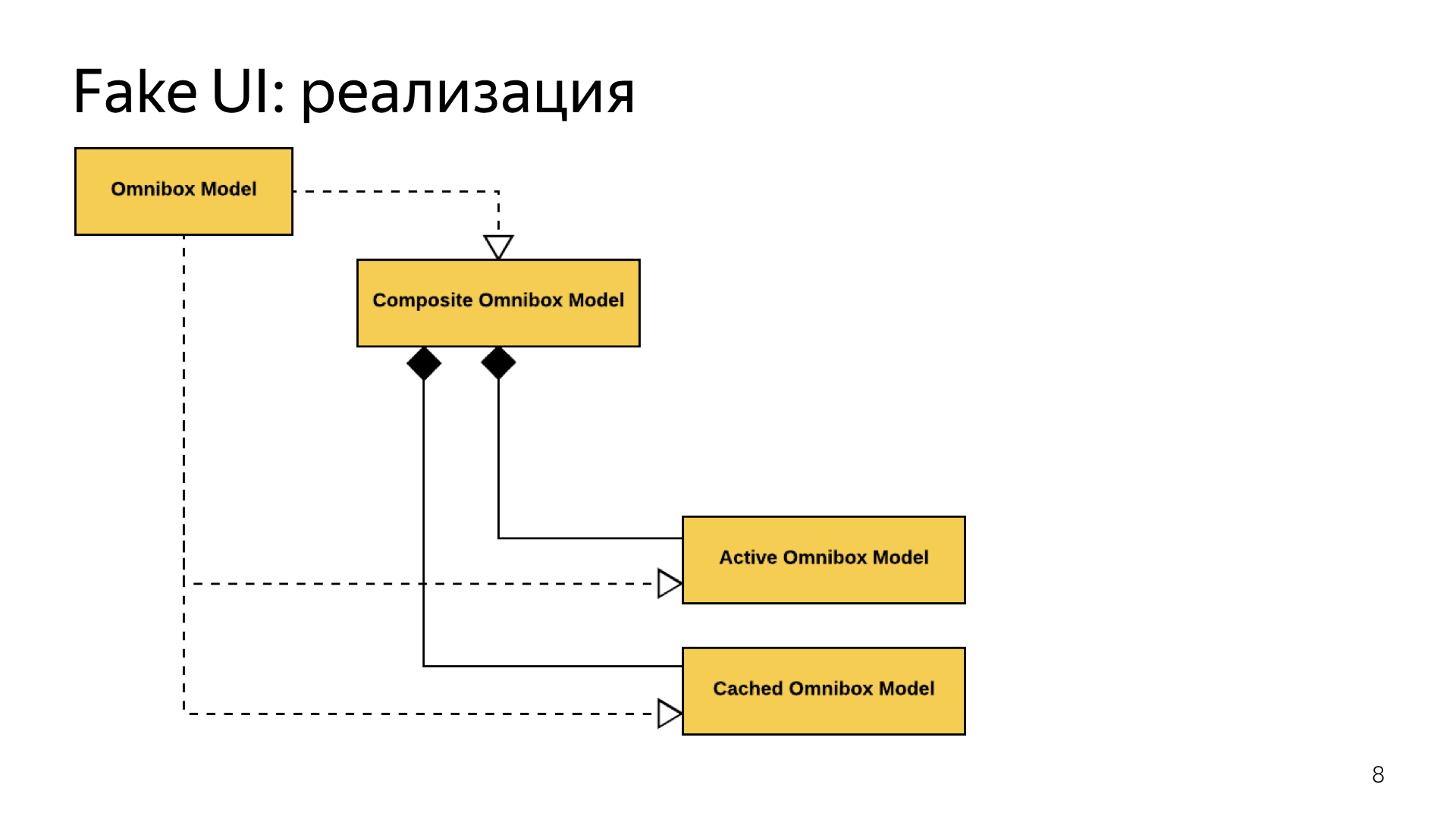
Мы взяли большой Omnibox и разделили его на два. Старая модель Omnibox осталась точно такой же, так же работала с ядром. Рядом мы положили новую модель, которая была полностью от него оторвана, работала с какими-то кэшированными данными, мы их объединили в один большой композит, который маршрутизовал вызовы в зависимости от того, было ли загружено ядро или нет.
Пока ядро не загружено, у нас вызовы шли в кэшированный Omnibox и ответы шли оттуда. Как только ядро загружалось, мы переключались.
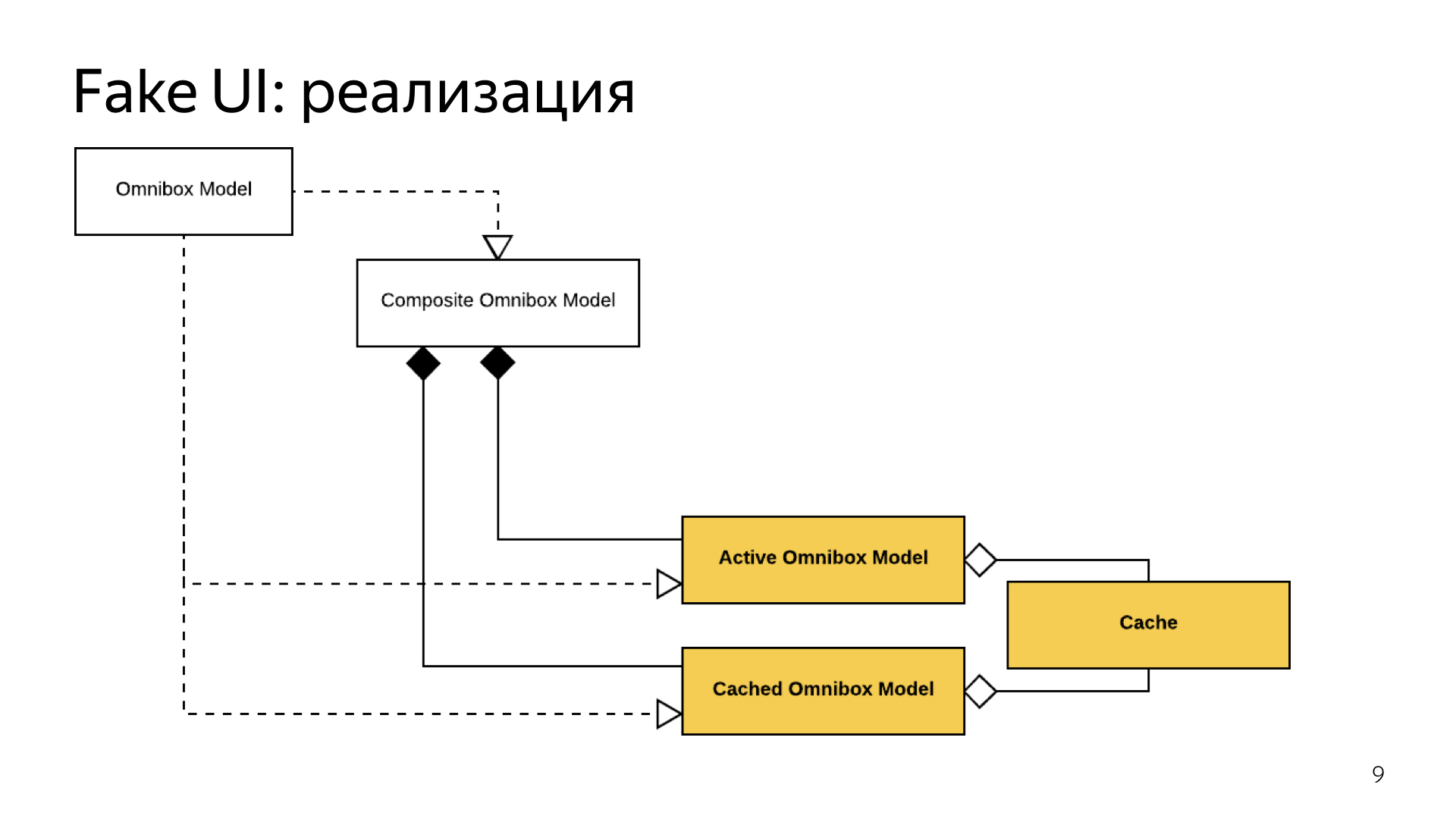
Чтобы у пользователя не было ощущения, что у него что-то сломалось, когда он выгрузил браузер, потом снова его запустил и увидел пустой Omnibox, а только что он был заполнен, мы сделали небольшой кэшик. Большой Omnibox, зависящий от ядра, писал в этот кэш, а кешированный Omnibox, как только он поднимался, из этого кэша читал и давал пользователю то состояние, с которым он остался.
И чтобы поддержать бесшовное переключение, мы сделали небольшой компонент, который в момент, когда ядро наконец стартует, фактически синхронизирует состояние кеширования Omnibox с нормальным. И для пользователя все выглядит так, будто он просто запустил браузер, начал в нем что-то делать и браузер просто работает. Он даже не замечает момента переключения.
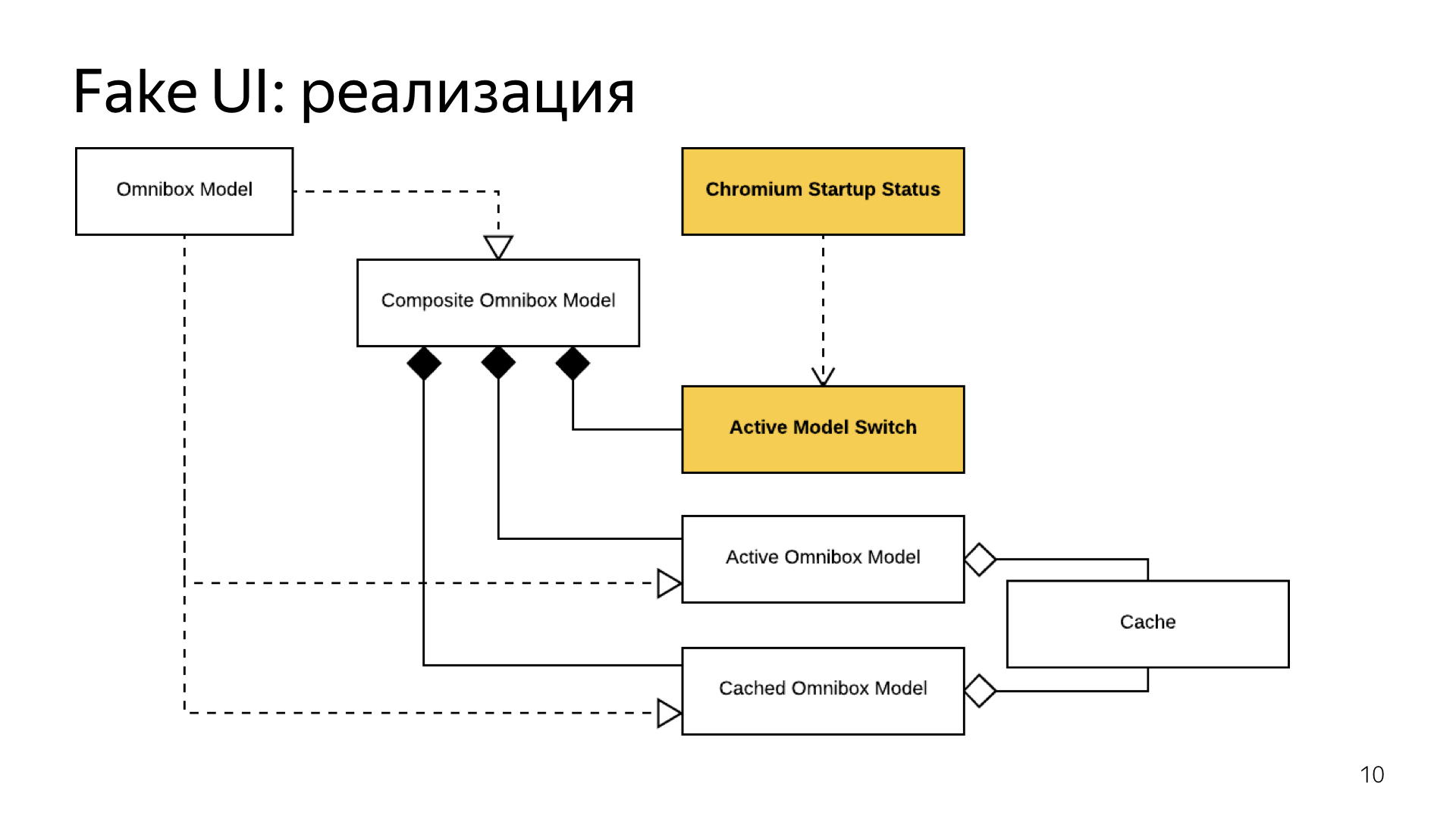
При этом интерфейс стал стартовать гораздо быстрее. Как я уже говорил, раньше до старта ядра мы делали просто UserInteractionEnabled = null, и нет, уважаемый пользователь, ты ничего не сделаешь. Теперь мы разрешили UserInteraction, и увидели, что проблемы остались.
К сожалению, помимо ядра у нас были собственные сервисы, написанные нами. Некоторые из них тоже от ядра зависели и очень любили подписываться на callback, который сигнализировал о том, что ядро наконец запущено.
В тот момент, когда ядро загрузилось, все эти сервисы радостно бежали инициализироваться, и забивали главный поток, в результате чего интерфейс есть, взаимодействовать с ним можно было бы, но главный поток забит, в него не проходит ни одно сообщение.

Выглядело это примерно так. Было два десятка таких условных сервисов, которые что-то там делали, иногда делали много. Пока их было один-два, это не было проблемой, но их число постоянно росло вместе с ростом числа фич.

Сам по себе Chromium.performAfterStartup ничего не делал, он просто брал все колбэки, которые на него подписались, и большой пачкой записывал в главный поток. 20 сервисов в главном потоке — увы, надо было что-то сделать.
Поэтому мы отказались от одномоментного запуска всех сервисов. Первое, что мы сделали, некоторые сервисы перестали ждать Chromium, а были отложены на более поздний срок.
В основном это все, что касалось статистики и прочих вещей, которые пользователям либо не необходимы, либо не являются необходимыми прямо сразу. Все, что мы могли отложить, мы отложили на более дальний срок.

Мы решили, что те сервисы, которые мы не смогли отложить, мы будем запускать по одному — просто давая возможность главному потоку что-то провернуть в промежутке между запусками сервисов. Таким образом у пользователей хоть и был интерфейс, который лагал, но в то же время у него была возможность с ним взаимодействовать. И он был еще чуть-чуть ближе к счастью.
К сожалению, счастье было недолгим, потому что появились ленивые сервисы.

Проблема ленивых сервисов в том, что время их запуска не определено. С одной стороны, это не проблема, а их преимущество, потому что мы можем использовать ленивые сервисы тогда, нам необходимо максимально отложить его запуск до того момента, когда он действительно понадобится. Но бывает так, что ленивые сервисы, ссылаясь друг на друга, и трогая друг друга, собираются в огромные пачки, начинают запускаться всей толпой, в этом месте образуется горячая точка, которая может переместиться в другое место, если случайно задеть там этот ленивый сервис. Поэтому мы приняли решение, что отсутствие контроля это не очень хорошо для приложения, и мы будем отказываться от ленивости — прежде всего за счет того, что мы выделили определенные точки, где должны подгружаться те или иные сервисы.

Эти точки были там, где мы хотим, где приложение может быть более разгруженным и можно его запустить. А к моменту, когда кто-то начинает работать с этим сервисом, сервис был полностью готов.

Кроме того, естественно, рекомендуется, чтобы никаких тяжелых операций на главном потоке при запуске сервиса не было. Главный поток слишком важен для пользователя, чтобы просто забивать его чтением каких-то файлов и тому подобной ерундой. Все задачи, требующие большого количества времени, должны быть вынесены в отдельные потоки.
В браузере, чтобы понимать, когда был загружен тот или иной сервис в таких случаях, мы используем Promise. Я не касаюсь этой темы, про него уже много рассказывали.
Реальные графики с продакшена.
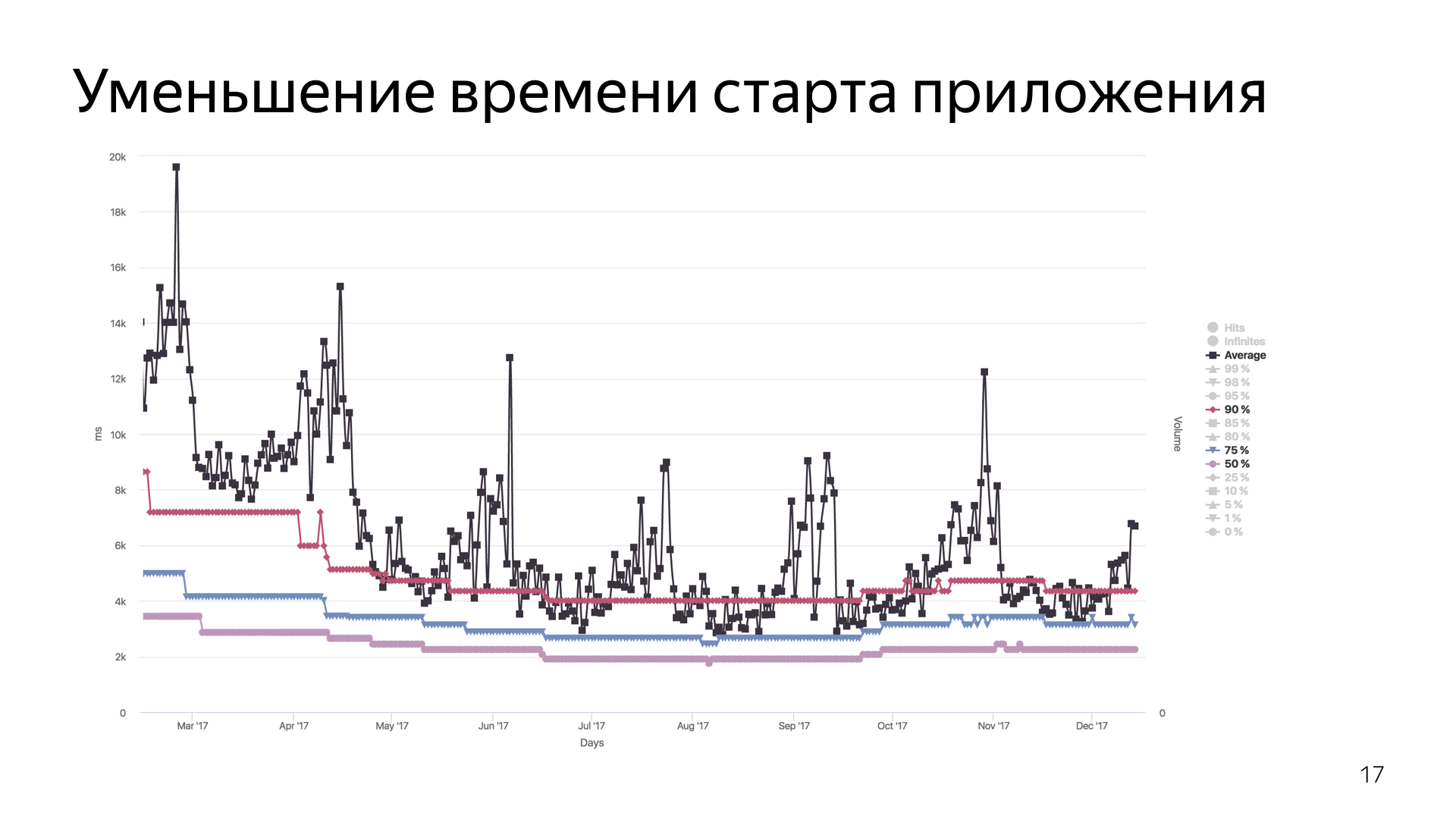
Мы действительно уменьшили время старта приложения. Это то, что у нас получилось. Эти ужасные пилообразные линии — средние. Почему они такие? К сожалению, у нас есть одна нерешенная проблема, связанная с тем, что когда мы замеряем у пользователя время, иногда по каким-то причинам это время слишком велико. Например, некоторые пользователи в статистику сообщали, что время старта — четыре года, во что я с трудом верю, потому что четыре года сидеть и смотреть на сплэш-скрин — это слишком даже для меня, который привык к 7-секундному запуску.
Но можно посмотреть на квантили 50%, 70% и 90%. Это то, как у пользователя в массе снижалось время старта по мере наших оптимизаций.
В конце небольшой рост, связанный с тем, что мы в очередной раз перешли с этапа оптимизации на этап добавления новых фич. Фичи аффектят время старта, и через некоторое время нам снова придется выполнять процесс оптимизации.
Что касается метрик у разработчиков, тут такой график.
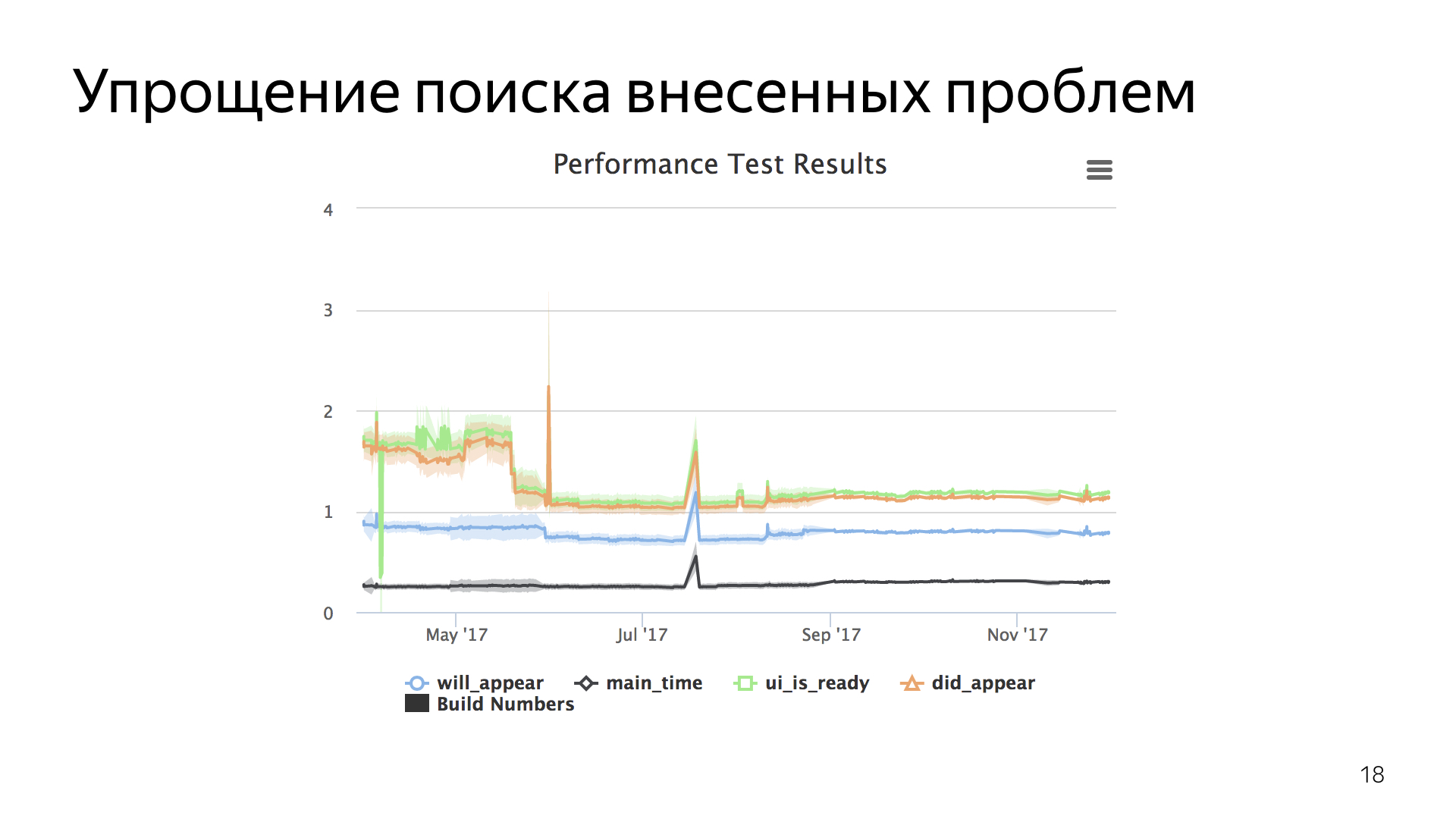
График красивый и даже страшный, но он выполняет свою работу. Он показывает, что именно происходит. Думаю, даже первый раз видя этот график, вы сможете сказать, где получилось классно, а где мы крупно облажались.
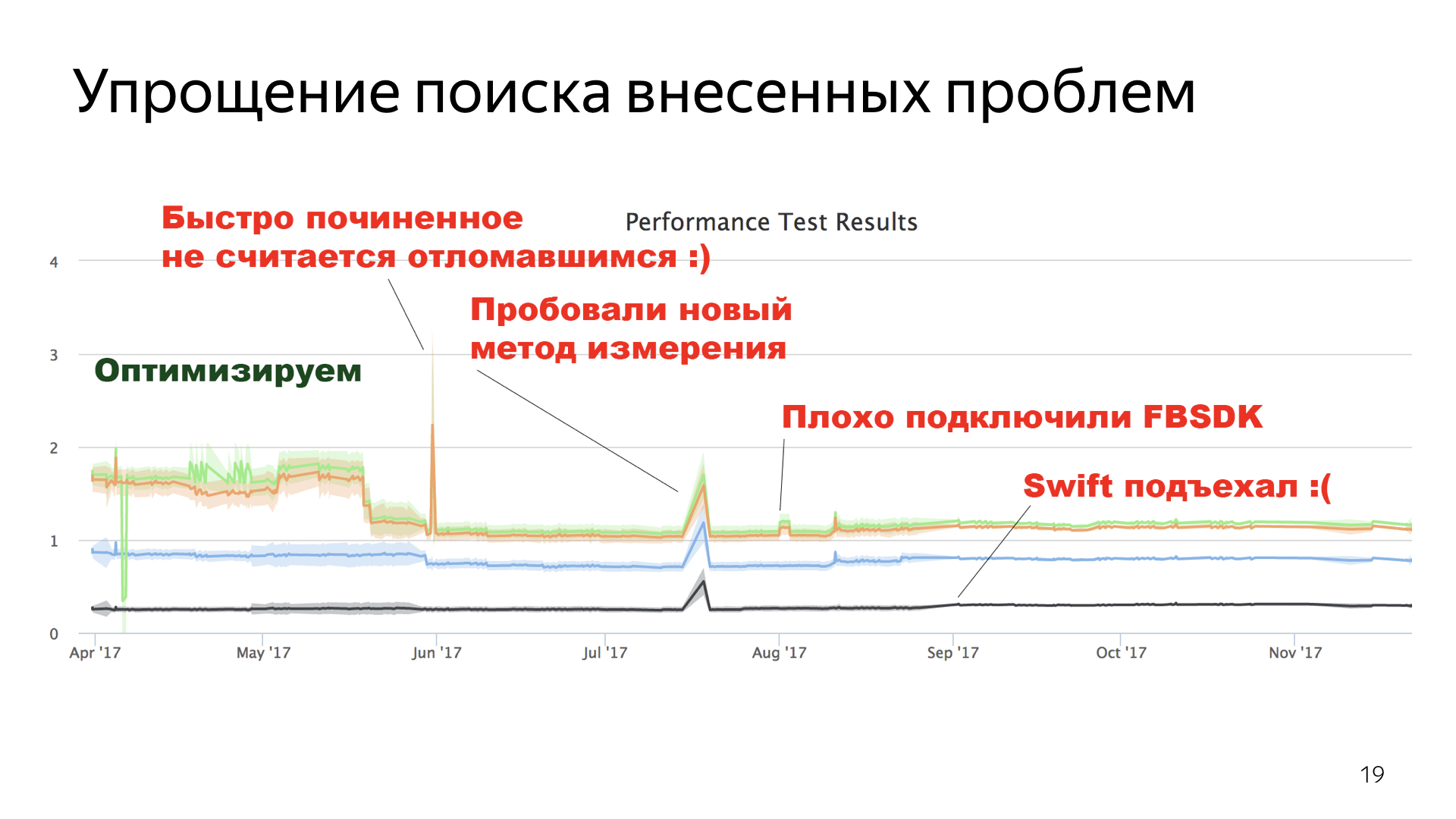
Я могу даже выделить отдельные точки, где происходили те или иные вещи.
Я говорил про Swift и про то, что сейчас это не является проблемой. У нас есть маленькая точка, где мы видим рост Main. Он с расстояния не очень очевиден, но он есть и не очень большой — по крайней мере, не настолько большой, чтобы продолжать не использовать Swift. Поэтому сейчас есть Swift, мы на нем пишем.
Эти графики дали возможность все сразу оценивать. У нас даже появился алгоритм, по которому мы вносим изменения в проект. Первое, что мы делаем: разработчик садится со старым добрым профилировщиком, делает оптимизации, готовит pull request, с которого мы собираем сборку. Мы отправляем ее на наш замечательный тестировочный стенд, который делает несколько сотен прогонов и дает четыре цифры. Мы их сравниваем с текущим мастером, который, в свою очередь, постоянно проверяется, и мы можем сказать, хорошо поработал разработчик или стоит еще поработать. Если кто-то что-то случайно зацепил и зааффектил время старта, то не позднее чем через два часа мы об этом узнаем и с легкостью найдем тот коммит, где произошла проблема.
В заключение: сначала метрики и только потом оптимизации. Без метрик все оптимизации рано или поздно потеряются, а это точно не то, чего хотите вы и ваши пользователи. Бессмысленно делать одну и ту же работу несколько раз, а пользователям очень нравится, когда приложение стартует быстро и очень не нравится видеть сплэш-скрин по семь секунд. Спасибо.
