По моим наблюдениям, разработчики довольно редко делают нагрузочное тестирование сайтов и веб-приложений. И бывает так, что выставят проект в Интернет, а тут вдруг посетители начнут ходить (хабраэффект, к примеру, случился), и сайт в самый подходящий момент ложится или начинает не по-детски тормозить.
Почему бы не избежать этих неприятностей, прогнав нагрузочный тест?
Наверное, кого-то останавливает неверное представление о том, что нагрузочное тестирование — это очень сложное дело, требующее специальных знаний. Однако не боги горшки обжигают. Если выбор — тестировать не слишком профессионально, или не тестировать вовсе, я бы выбрал первое. Тем более, что организовать примитивный тест производительности очень даже просто. Можно воспользоваться онлайн-средствами (см., например, Нагрузочное тестирование по-быстренькому), а можно замутить все своими руками, это ненамного сложнее.
Под катом рассказываю, как с нуля организовать незамысловатый нагрузочный тест сайта при помощи Apache JMeter.
Сразу хочу предупредить, что описанный подход (Log Replay) хорошо работает именно для сайтов, и не годится для веб-приложений, активно использующих POST, а также, по своей простоте, игнорирует существование cookie-based сессий. Кроме того, нежелательно тестировать проект, развернутый по адресу 127.0.0.1, результаты довольно сильно искажаюся из-за того, что JMeter и сайт тормозят друг друга (с другой стороны, плохо, когда сервер далеко — мешают задержки).
Нам понадобится:
Есть еще неплохой способ генерации файла, который для JMeter'а сойдет за лог, причем без захода в файловую систему сервера. Добываем откуда-нибудь список URL сайта. Приемлемый список делает Xenu в отчете о сканировании. Вставляем этот список в текстовый файл. Получится что-то вроде
Делаем глобальный реплейс «http://test.local» на «"GET » (с кавычкой и пробелом), получаем
Этот формат парсер хорошо кушает, принимая за чистую монету (закрывать кавычки в конце строки не надо).
Итак, скачали JMeter (http://jakarta.apache.org/site/downloads/downloads_jmeter.cgi, разворачиваем архив, идем в директорию bin и запускаем jmeter.bat (делаю пример под Виндой). После небольшой паузы стартует GUI традиционного жабьего вида.
Слева наблюдаем дерево из 2 узлов: TestPlan и Workbench (про второй сразу забываем, он нам не понадобится). На Test Plan кликаем правым кликом и говорим Add->Thread Group (в интерфейсе можно увидеть много фишек разной степени полезности, но мы сейчас не отвлекаемся, а кратчайшим путем идем к нашему тесту, потом, если захотим — будем изучать обширные возможности JMeter подробнее).
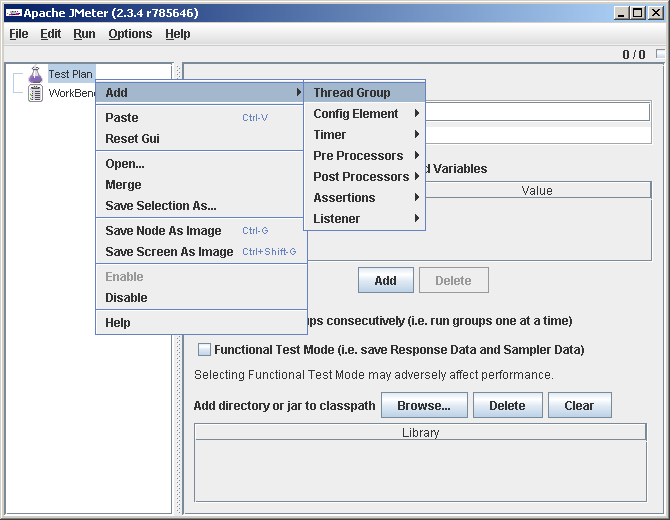
Группа потоков добавилась:
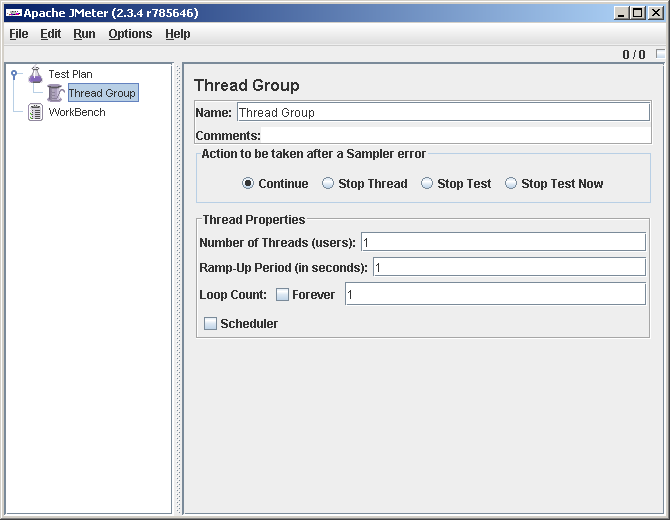
Менять мы тут пока ничего не будем. Цифры все стоят по 1, что хорошо. Это один виртуальный пользователь, поторый один раз выполнит сценарий (в случае используемого нами Access Log Sampler'а — выполнит один запрос, соответствующий первой строчке лога). А нам для отладки теста больше и не надо.
Переименовывать Test Plan и Thread Group тоже не будем, эти названия у нас в рамках теста уникальны.
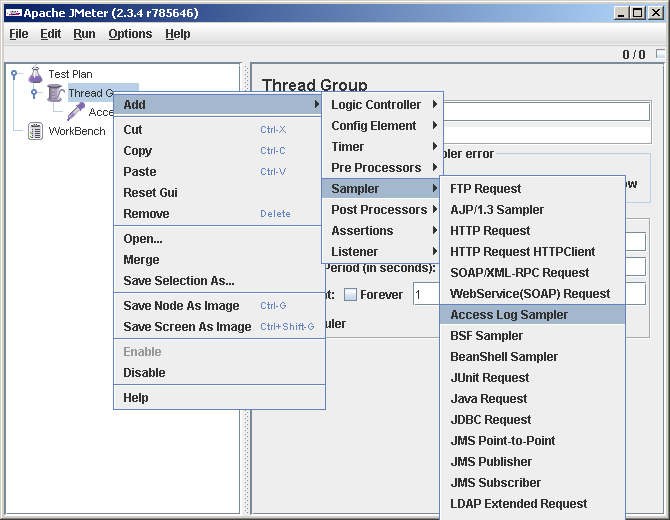
Правым кликом на Thread Group добавляем Access Log Sampler (Thread Group->Add->Sampler->Access Log Sampler)
Вбиваем адрес сервера и локальный путь к аксесс-логу (мы его утащили с сервера и положили к себе на диск):

Теперь добавляем в тест средства отображения:
Тест-план готов, переходим к его тестированию :) и отладке (ничего-ничего, он может и с первого раза заработать).
File->Save, и так каждый раз после внесения изменений в тест-план. Это важно, JMeter другой раз виснет, и тест приходится восстанавливать по памяти.
Run->Clear All (на первый раз можно не делать, но потом все равно понадобится).
Run->Start.
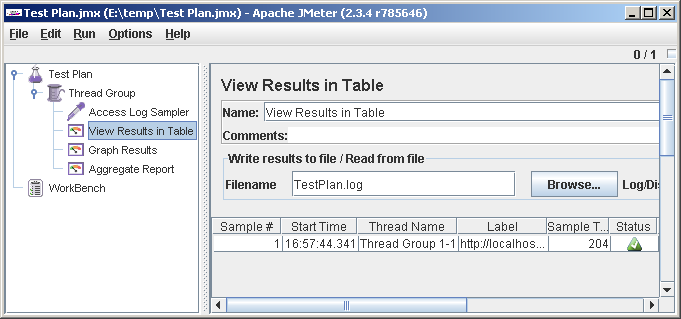
И идем смотреть во View Results in Table. Если нам повезло, там будет одна строчка, с зеленой галочкой в колонке Status.
Если что-то пошло не так, в статусе будет ошибка:

Если такое дело, идем читать наш TestPlan.log. Как правило, по сообщениям в нем можно догадаться, что именно сломалось. Например, если тестируемый сервер не отвечает, в логе оказывается такая ругань:
Положим, разобрались, или все сразу прошло чисто. Идем в свойства Thread Group и ставим Loop Count: Forever
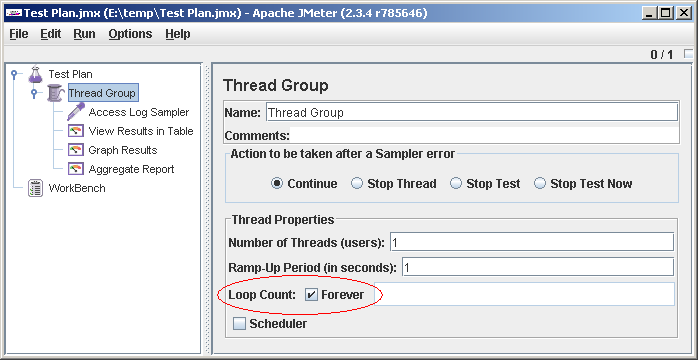
Запускаем (File->Save, Run->Clear All, Run->Start). Идем смотреть во View Results in Table. Должно получиться как-то так:
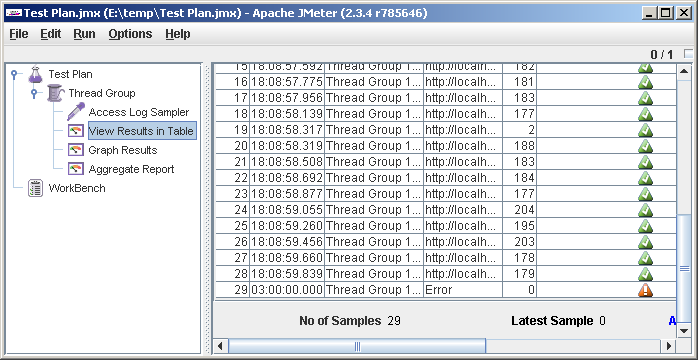
В последней строчке ошибка, это JMeter испытывает расстройство оттого, что файл закончился (видно, привык работать с бесконечными файлами). К сожалению, по окончании файла сценарий останавливается, игнорируя настройку Action to be taken after a Sampler error = Continue (мне это кажется багом, а разработчикам наверняка фичей). Чтобы это не исказило результаты теста, лучше брать достаточно длинные аксесс-логи. Длинный файл несложно организовать из короткого с помощью copy в командной строке или Ctrl+C, Ctrl+V в текстовом редакторе. Для наших опытов больше 1000 строк в логе вряд ли понадобится.
Еще, прежде чем начать тест, добавим в начало сценария случайную задержку (Uniform Random Timer) 0-1000 миллисекунд, она обычно помогает несколько сгладить графики. Сценарий в результате работает так: ждет случайное количество миллисекунд, читает строку из лога, делает HTTP запрос, передает результаты листенерам, снова ждет, читает следующую строчку, и так далее.
Делаем первый, пристрелочный, тест. В свойствах группы потоков поставим: Number of Threads (users): 100, Ramp-Up Period (in seconds): 100. Мы собираемся натравить на сайт 100 виртуальных юзеров, вводя их в бой по одному в течении 100 секунд, то есть по юзеру в секунду. Цифры 100 и 100 я взял откуда-то с потолка, но надо же с чего-то начать.
Еще раз напомним себе, что мы имеем хорошие шансы притормозить или даже завалить сайт (что может быть нехорошо, если речь идет об уже работающем проекте). ОК, будучи в здравом уме и трезвой памяти, осознавая ответственность за свои действия, начинаем.
File->Save, Run->Clear All, Run->Start и идем смотреть Graph Results. Видим, скажем, такую картинку:
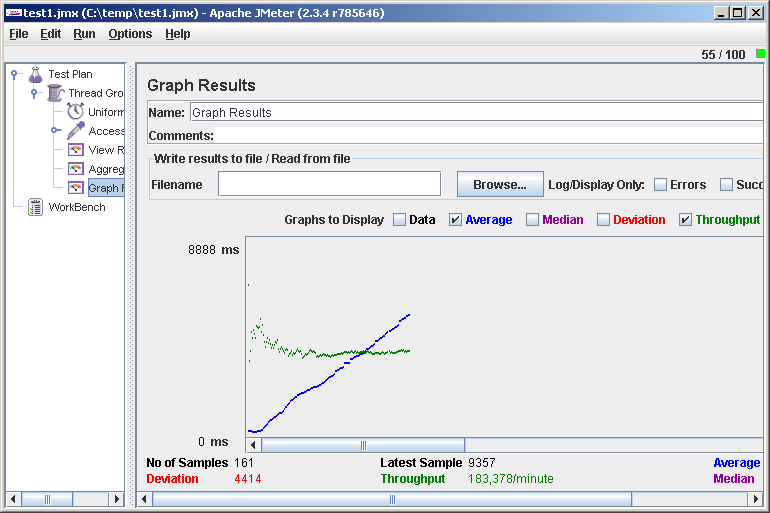
В правом верхнем углу можно наблюдать текущее количество виртуальных пользователей.
О чем говорит нам этот график? Среднее время отклика (Average) растет, а скорость обработки (Throughput) не меняется. Это значит, что где-то на сервере операции становятся в очередь, и производительности не хватает, чтобы обслужить все запросы. Зайдя браузером на сайт, убедимся, что он еле ворочается или вообще не респондит. Зачем зря мучить несчастного? Run->Stop. Ну вот, сайт снова ожил. Неудачная идея во время такого теста — отвлечься ненадолго и, вернувшись через несколько часов (как это бывает), обнаружить, что сайт полдня лежал.
В качестве содержательного результата мы получили одно число — максимальное значение Throughput (183 запроса в минуту). Можно считать его пределом производительности. Для начала этого числа может быть достаточно, например, уже ясно, что 100 000 хостов в сутки наш сайт не потянет.
Внимательно посмотрев на график времени отклика, можно увидеть полочку в его начале. В это время нагрузка росла, а реакция сервера не менялась, то есть ему было хорошо. Попробуем более подробно изучить этот диапазон нагрузок. Уменьшив Number of Threads и увеличив Ramp-Up Period, получаем такую картинку:
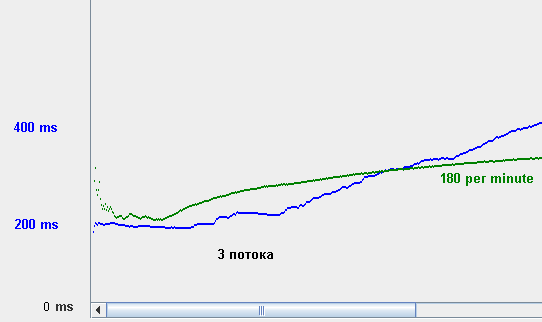
Видим, что сайту поплохело после 3 виртуальных юзеров и 150 запросов в минуту.
Для уверенности теперь есть смысл провести тест со статической нагрузкой. Ставим Number of Threads = 3, Ramp-Up Period= 0 (вводим потоки сразу) и смотрим, что получилось. Вроде все нормально, сайт реагирует живенько. Если хотим, снимаем несколько таких точек и на бумажке строим график. Эти цифры сильно достовернее, чем наблюдения по графику с динамической нагрузкой.
Заглянем теперь в Aggregate Report. Там для нас приготовлена статистика по URL-ам
(лучше всего смотреть после теста с большой, но не чрезмерной статической нагрузкой). Нас в первую очередь интересует колонка Average, среднее время отклика. Часто оказывется что есть несколько тяжелых страниц, которые в первую очередь и создают нагрузку на систему, и если их оттюнить, общая производительность многократно увеличивается (лучше всего начинать оптимизацию со страниц, которые по статистике вызываются часто, а отрабатывают долго). Справедливости ради надо отметить, что не всегда самые долгоиграющие страницы дают наибольший вклад в нагрузку, но чаще это так.
Пара слов об интерпретации полученных чисел: 3 виртуальных юзера, 150 запросов в минуту. Как эти величины соотносятся с реальными пользователями и, скажем, запросами страниц в сутки? Практически никак, мы не ставили себе цель смоделировать реального юзера. То, что мы имеем — относительная величина, на которую можно ориентироваться в процессе тюнинга. В данном случае 3 юзера получены при тестировании по списку урлов сайта, и «лог» не содержит картинок, css и прочих ресурсов. Так что 150 per minute как раз соответствуют настоящим запросам страниц в минуту. Если мы использовали реальный лог, то можно взять Aggregate Report, экспортировать его в csv (внизу есть кнопочка Save Table Data), повыкидывать из него все обращения к ресурсам, посчитать оставшиеся хиты и разделить на продолжительность теста.
В заключение хочется предупредить об одном недостатке описанного способа. Поскольку все виртуальные пользователи выполняют запросы в одном и том же порядке, эффективность кэширования на всех уровнях будет очень высокой. В реальности эффективность будет меньше, и это вносит в результаты наших исследований с трудом оцениваемую погрешность (кстати, надо будет написать сэмплер, который дергает строчки из лога в случайном порядке… если руки дойдут).
Но зато такой тест делается легко и быстро и обладает хорошей производительностью, так что для начала, имхо, в самый раз.
Почему бы не избежать этих неприятностей, прогнав нагрузочный тест?
Наверное, кого-то останавливает неверное представление о том, что нагрузочное тестирование — это очень сложное дело, требующее специальных знаний. Однако не боги горшки обжигают. Если выбор — тестировать не слишком профессионально, или не тестировать вовсе, я бы выбрал первое. Тем более, что организовать примитивный тест производительности очень даже просто. Можно воспользоваться онлайн-средствами (см., например, Нагрузочное тестирование по-быстренькому), а можно замутить все своими руками, это ненамного сложнее.
Под катом рассказываю, как с нуля организовать незамысловатый нагрузочный тест сайта при помощи Apache JMeter.
Сразу хочу предупредить, что описанный подход (Log Replay) хорошо работает именно для сайтов, и не годится для веб-приложений, активно использующих POST, а также, по своей простоте, игнорирует существование cookie-based сессий. Кроме того, нежелательно тестировать проект, развернутый по адресу 127.0.0.1, результаты довольно сильно искажаюся из-за того, что JMeter и сайт тормозят друг друга (с другой стороны, плохо, когда сервер далеко — мешают задержки).
Нам понадобится:
- JMeter
- Установленная Жаба, в наше время она водится почти на любой машине
- Access log нашего сайта. Если access log у нас пустой, нам ничто не мешает его слегка пополнить, взяв в руки браузер и полазив по сайту. Можно пройти сайт попавшимся под руку краулером, например HTTrack или Xenu. Если веб-сервер — IIS, то предварительно нужно переключить формат лога в NCSA, понимаемый парсером JMeter-а. Брать лог из-под работающего сервера (когда он туда пишет) не стоит, лучше взять уже закрытый, скажем, вчерашний, или приостановить веб-сервер на время выемки лога. Лог стоит посмотреть текстовым редактором на предмет корректности.
Есть еще неплохой способ генерации файла, который для JMeter'а сойдет за лог, причем без захода в файловую систему сервера. Добываем откуда-нибудь список URL сайта. Приемлемый список делает Xenu в отчете о сканировании. Вставляем этот список в текстовый файл. Получится что-то вроде
http://test.local/index.php
http://test.local/news/event-12.php
...
Делаем глобальный реплейс «http://test.local» на «"GET » (с кавычкой и пробелом), получаем
"GET /index.php
"GET /news/event-12.php
...
Этот формат парсер хорошо кушает, принимая за чистую монету (закрывать кавычки в конце строки не надо).
Итак, скачали JMeter (http://jakarta.apache.org/site/downloads/downloads_jmeter.cgi, разворачиваем архив, идем в директорию bin и запускаем jmeter.bat (делаю пример под Виндой). После небольшой паузы стартует GUI традиционного жабьего вида.
Слева наблюдаем дерево из 2 узлов: TestPlan и Workbench (про второй сразу забываем, он нам не понадобится). На Test Plan кликаем правым кликом и говорим Add->Thread Group (в интерфейсе можно увидеть много фишек разной степени полезности, но мы сейчас не отвлекаемся, а кратчайшим путем идем к нашему тесту, потом, если захотим — будем изучать обширные возможности JMeter подробнее).

Группа потоков добавилась:
Менять мы тут пока ничего не будем. Цифры все стоят по 1, что хорошо. Это один виртуальный пользователь, поторый один раз выполнит сценарий (в случае используемого нами Access Log Sampler'а — выполнит один запрос, соответствующий первой строчке лога). А нам для отладки теста больше и не надо.
Переименовывать Test Plan и Thread Group тоже не будем, эти названия у нас в рамках теста уникальны.
Правым кликом на Thread Group добавляем Access Log Sampler (Thread Group->Add->Sampler->Access Log Sampler)

Вбиваем адрес сервера и локальный путь к аксесс-логу (мы его утащили с сервера и положили к себе на диск):
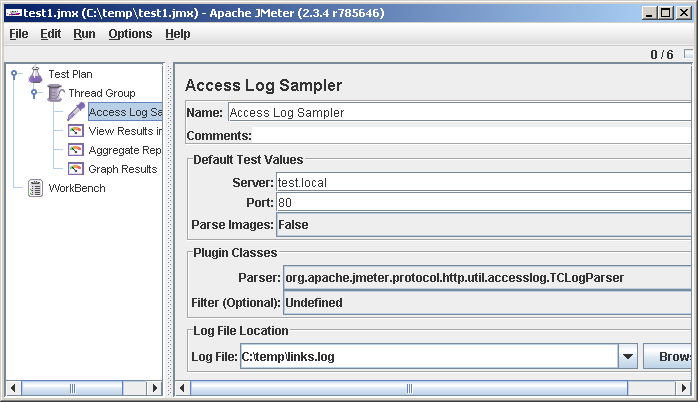
Теперь добавляем в тест средства отображения:
- Thread Group->Add->Listener->View Results in Table
- Thread Group->Add->Listener->Graph Results
- Thread Group->Add->Listener->Aggregate Report
Тест-план готов, переходим к его тестированию :) и отладке (ничего-ничего, он может и с первого раза заработать).
File->Save, и так каждый раз после внесения изменений в тест-план. Это важно, JMeter другой раз виснет, и тест приходится восстанавливать по памяти.
Run->Clear All (на первый раз можно не делать, но потом все равно понадобится).
Run->Start.
И идем смотреть во View Results in Table. Если нам повезло, там будет одна строчка, с зеленой галочкой в колонке Status.

Если что-то пошло не так, в статусе будет ошибка:

Если такое дело, идем читать наш TestPlan.log. Как правило, по сообщениям в нем можно догадаться, что именно сломалось. Например, если тестируемый сервер не отвечает, в логе оказывается такая ругань:
rc="Non HTTP response code: java.net.ConnectException" rm="Non HTTP response message: Connection refused: connect". Такой текст rc="Non HTTP response code: java.net.ProtocolException" rm="Non HTTP response message: Invalid HTTP method: null" скорее всего свидетельствует о том, что строка акцесс-лога неправильно распарсилась. Положим, разобрались, или все сразу прошло чисто. Идем в свойства Thread Group и ставим Loop Count: Forever

Запускаем (File->Save, Run->Clear All, Run->Start). Идем смотреть во View Results in Table. Должно получиться как-то так:

В последней строчке ошибка, это JMeter испытывает расстройство оттого, что файл закончился (видно, привык работать с бесконечными файлами). К сожалению, по окончании файла сценарий останавливается, игнорируя настройку Action to be taken after a Sampler error = Continue (мне это кажется багом, а разработчикам наверняка фичей). Чтобы это не исказило результаты теста, лучше брать достаточно длинные аксесс-логи. Длинный файл несложно организовать из короткого с помощью copy в командной строке или Ctrl+C, Ctrl+V в текстовом редакторе. Для наших опытов больше 1000 строк в логе вряд ли понадобится.
Еще, прежде чем начать тест, добавим в начало сценария случайную задержку (Uniform Random Timer) 0-1000 миллисекунд, она обычно помогает несколько сгладить графики. Сценарий в результате работает так: ждет случайное количество миллисекунд, читает строку из лога, делает HTTP запрос, передает результаты листенерам, снова ждет, читает следующую строчку, и так далее.
Делаем первый, пристрелочный, тест. В свойствах группы потоков поставим: Number of Threads (users): 100, Ramp-Up Period (in seconds): 100. Мы собираемся натравить на сайт 100 виртуальных юзеров, вводя их в бой по одному в течении 100 секунд, то есть по юзеру в секунду. Цифры 100 и 100 я взял откуда-то с потолка, но надо же с чего-то начать.
Еще раз напомним себе, что мы имеем хорошие шансы притормозить или даже завалить сайт (что может быть нехорошо, если речь идет об уже работающем проекте). ОК, будучи в здравом уме и трезвой памяти, осознавая ответственность за свои действия, начинаем.
File->Save, Run->Clear All, Run->Start и идем смотреть Graph Results. Видим, скажем, такую картинку:
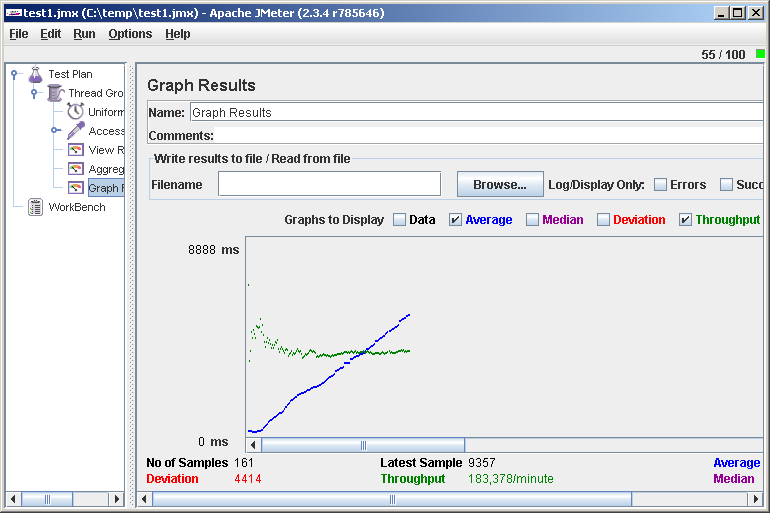
В правом верхнем углу можно наблюдать текущее количество виртуальных пользователей.
О чем говорит нам этот график? Среднее время отклика (Average) растет, а скорость обработки (Throughput) не меняется. Это значит, что где-то на сервере операции становятся в очередь, и производительности не хватает, чтобы обслужить все запросы. Зайдя браузером на сайт, убедимся, что он еле ворочается или вообще не респондит. Зачем зря мучить несчастного? Run->Stop. Ну вот, сайт снова ожил. Неудачная идея во время такого теста — отвлечься ненадолго и, вернувшись через несколько часов (как это бывает), обнаружить, что сайт полдня лежал.
В качестве содержательного результата мы получили одно число — максимальное значение Throughput (183 запроса в минуту). Можно считать его пределом производительности. Для начала этого числа может быть достаточно, например, уже ясно, что 100 000 хостов в сутки наш сайт не потянет.
Внимательно посмотрев на график времени отклика, можно увидеть полочку в его начале. В это время нагрузка росла, а реакция сервера не менялась, то есть ему было хорошо. Попробуем более подробно изучить этот диапазон нагрузок. Уменьшив Number of Threads и увеличив Ramp-Up Period, получаем такую картинку:

Видим, что сайту поплохело после 3 виртуальных юзеров и 150 запросов в минуту.
Для уверенности теперь есть смысл провести тест со статической нагрузкой. Ставим Number of Threads = 3, Ramp-Up Period= 0 (вводим потоки сразу) и смотрим, что получилось. Вроде все нормально, сайт реагирует живенько. Если хотим, снимаем несколько таких точек и на бумажке строим график. Эти цифры сильно достовернее, чем наблюдения по графику с динамической нагрузкой.
Заглянем теперь в Aggregate Report. Там для нас приготовлена статистика по URL-ам
(лучше всего смотреть после теста с большой, но не чрезмерной статической нагрузкой). Нас в первую очередь интересует колонка Average, среднее время отклика. Часто оказывется что есть несколько тяжелых страниц, которые в первую очередь и создают нагрузку на систему, и если их оттюнить, общая производительность многократно увеличивается (лучше всего начинать оптимизацию со страниц, которые по статистике вызываются часто, а отрабатывают долго). Справедливости ради надо отметить, что не всегда самые долгоиграющие страницы дают наибольший вклад в нагрузку, но чаще это так.
Пара слов об интерпретации полученных чисел: 3 виртуальных юзера, 150 запросов в минуту. Как эти величины соотносятся с реальными пользователями и, скажем, запросами страниц в сутки? Практически никак, мы не ставили себе цель смоделировать реального юзера. То, что мы имеем — относительная величина, на которую можно ориентироваться в процессе тюнинга. В данном случае 3 юзера получены при тестировании по списку урлов сайта, и «лог» не содержит картинок, css и прочих ресурсов. Так что 150 per minute как раз соответствуют настоящим запросам страниц в минуту. Если мы использовали реальный лог, то можно взять Aggregate Report, экспортировать его в csv (внизу есть кнопочка Save Table Data), повыкидывать из него все обращения к ресурсам, посчитать оставшиеся хиты и разделить на продолжительность теста.
В заключение хочется предупредить об одном недостатке описанного способа. Поскольку все виртуальные пользователи выполняют запросы в одном и том же порядке, эффективность кэширования на всех уровнях будет очень высокой. В реальности эффективность будет меньше, и это вносит в результаты наших исследований с трудом оцениваемую погрешность (кстати, надо будет написать сэмплер, который дергает строчки из лога в случайном порядке… если руки дойдут).
Но зато такой тест делается легко и быстро и обладает хорошей производительностью, так что для начала, имхо, в самый раз.
