Comments 44
Стоило использовать std::vector<std::string> вместо сырого владеющего указателя, не хочется вектор — тогда std::unique_ptr<std::string[]>.
Cтоит использовать std::string_type::npos, эта константа не обязана быть -1.
Использование const на возвращаемом по значению типе предотвращает всякие оптимизации.
if(Word.find('-')!=-1)
Cтоит использовать std::string_type::npos, эта константа не обязана быть -1.
Использование const на возвращаемом по значению типе предотвращает всякие оптимизации.
Интересно, почему именно С++? И почему такая странная кодировка?
Кодировка потому, что Windows. (там консоль работает в отличной от всего остального кодировке)
Хотя лично я до перехода на *nix использовал для вывода libiconv.
Хотя лично я до перехода на *nix использовал для вывода libiconv.
Грязный хак для libiconv
#include "iconv/iconv.h"
std::string convert(const std::string& str, iconv_t conv)
{
iconv(conv, 0, 0, 0, 0);
const size_t buffer_size = 512;
char out[buffer_size];
const char* in_buf = str.c_str();
size_t in_size = str.size();
std::string result;
while (in_size > 0)
{
char* out_buf = out;
size_t out_size = buffer_size;
int n = iconv(conv, &in_buf, &in_size, &out_buf, &out_size);
if (n < 0)
{
if (errno != E2BIG) break;
}
result.append(out, buffer_size - out_size);
}
return result;
}
char *Win2Dos(char *in)
{
iconv_t ic =iconv_open("CP866","windows-1251");
const std::string _a = (std::string)in;
char *_o = (char *)convert(_a,ic).c_str();
iconv_close(ic);
return _o;
}
char *Dos2Win(char *in)
{
iconv_t ic =iconv_open("windows-1251","CP866");
const std::string _a = (std::string)in;
char *_o = (char *)convert(_a,ic).c_str();
iconv_close(ic);
return _o;
}
Это ужасно… Windows до сих пор не знает что такое UTF8, а дети программисты пишут на C++ то, что стоило бы писать на скриптовом языке. Для обучения неплохо и, если вы школьник, даже круто, я таким в школе похвастаться не мог. Продолжайте в том же духе.
P.S. Но я бы автору рекомендовал посмотреть в сторону чего-нибудь попроще: Python, Ruby, Java. Ну или в сторону Qt если очень нравится C++. Вы получите как минимум кроссплатформенность (и никаких больше OEM 866) и гораздо более простую работу со строками (по крайней мере в Python). Но решать конечно вам.
P.S. Но я бы автору рекомендовал посмотреть в сторону чего-нибудь попроще: Python, Ruby, Java. Ну или в сторону Qt если очень нравится C++. Вы получите как минимум кроссплатформенность (и никаких больше OEM 866) и гораздо более простую работу со строками (по крайней мере в Python). Но решать конечно вам.
А я бы не советовал. Миру также нужны люди, которые будут разбираться в извращениях. Ведь как раз они и пишут, например, Qt, который скрывает за своим интерфейсом все это. Поэтому пешать действительно автору.
Если честно с qt и виндовой консолью тоже не все так просто.
Я тоже за qt очень приятная штука.
Хотя если жить с плюсами без boost не обойтись порой.
Я тоже за qt очень приятная штука.
Хотя если жить с плюсами без boost не обойтись порой.
Qt как слишком огромен что бы привлекать его для такой простой задачи.
Да и где логика- использовать 2гигабитный фреймверк со своими велосипедами почти для всего
ради одного маленького консольного приложения?
Python мне не нравится из за синтаксиса (да да, вложенность) + это не компилируемый язык.
Java на десктопеужасна не слишком быстра и создавалась она уж точно не для такого.
Ruby пугает своим ООП + Ruby поднялся только благодаря рельсам, благодаря им же и упал.
Вот и остается (Заметьте, для такой задачи) чистый C++ без тотального ООП, обязательного для всех стиля,
промежуточной компиляции и всего прочего, присущего тому что вы перечислили.
Да и где логика- использовать 2гигабитный фреймверк со своими велосипедами почти для всего
ради одного маленького консольного приложения?
Python мне не нравится из за синтаксиса (да да, вложенность) + это не компилируемый язык.
Java на десктопе
Ruby пугает своим ООП + Ruby поднялся только благодаря рельсам, благодаря им же и упал.
Вот и остается (Заметьте, для такой задачи) чистый C++ без тотального ООП, обязательного для всех стиля,
промежуточной компиляции и всего прочего, присущего тому что вы перечислили.
Впрочем, каждому свое)
Насчет строк не знаю, а как калькулятор Python вполне пригоден)
Забыли C#. Вполне подходит.
Да, но промежуточная компиляция никуда не уходит. И можно забыть о UNIX
О *nix вы уже забыли с вашей кодировкой. Тот код, что вы воложили, будет нормально работать только на Windows.
Насколько я знаю в *nix проблема с кодировками вообще не стоит так. Убираем setlocale и радуемся жизни.
Насчет Mono- много ли вы знаете людей постоянно использующих Mono с *nix?
Кроме разработчиков Mono конечно.
Всегда казалось, что C# — язык ориентированный на разработку в Windows.
Поэтому для наглядности решил использовать C++ при написании статьи)
Насчет Mono- много ли вы знаете людей постоянно использующих Mono с *nix?
Кроме разработчиков Mono конечно.
Всегда казалось, что C# — язык ориентированный на разработку в Windows.
Поэтому для наглядности решил использовать C++ при написании статьи)
По поводу кодировки и *nix ничего не могу сказать, проблем быть не должно, но вероятно будут. Вообще в C и C++ лично для меня сложно что-то предсказывать про другие платформы, особенно в плане строк. Было дело пытались создать файл с русским именем и в него что-то на русском написать, с одной кодировкой в одном месте иероглифы, с другой в другом, как справились не помню, но решение искали втроём около часа. Так же делал Qt проект, под *nix'ами он собирался и работал как надо, а под Windows был Segmentation fault, очень долго пришлось всё отлаживать. С тех пор с C и C++ стараюсь не связываться, хоть иногда и приходится.
По поводу Mono я вообще ничего не знаю, как и о C#. Мне всегда, так же как и вам, казалось, что язык нацелен на Windows и кросыплатформенность у него посредственная, а у меня Windows только в виртуалке.
По поводу Mono я вообще ничего не знаю, как и о C#. Мне всегда, так же как и вам, казалось, что язык нацелен на Windows и кросыплатформенность у него посредственная, а у меня Windows только в виртуалке.
Уже было тут две статьи по поводу «кто быстрее» — плюсы или шарп. ИМХО — у Вас программа настолько мала, что даже самый большой оверхед на C# не будет ощутим даже на самой плохенбкой системе. Кроме того для UNIX, если я не ошибься, Microsoft недавно начала поддерживать Mono.
И кстати, GUI для бота я написал как раз на C#+WPF
В ветке идет обсуждение «почему С++, ведь у него строки», а не про интерфейс. Поэтому и предложил все на шарпе.
Почему вам кажется, что в C# работа со строками (в этом случае) легче чем в C++?
Ну хорошо, size() заменим на Length, а дальше?
Конкретно со строками я больших изменений не увидел)
Ну хорошо, size() заменим на Length, а дальше?
Аналогичный код на C# специально для вас
static class Bot{
public static readonly System.String MemoryPath="Memory.txt";
private static System.String[] GetWords(System.String Word){
//Подсчитывает слова для создания массива
//Не забываем, что последний символ массива- служебный, поэтому 1, а не 0
//В 0 изначально уходит строка
System.Int32 MaxIndex=1;
//Фиксирует наличие в предидущих циклах символов-разделителей
System.Boolean SeeFix=false;
for(System.Int32 i=0; i<Word.Length; ++i){
if(Word[i]==' '||Word[i]=='.'||Word[i]==','||Word[i]=='!'||Word[i]=='?'||Word[i]=='='||Word[i]=='/'||Word[i]=='\n'){
SeeFix=true;
continue;
}
if(SeeFix){
SeeFix=false;
++MaxIndex;
}
}
System.String[] ArrWords=new System.String[MaxIndex];
System.Boolean Fix=false;
for(System.Int32 i=0, ThisIndex=0; i<Word.Length; ++i){
if(Word[i]==' '||Word[i]=='.'||Word[i]==','||Word[i]=='!'||Word[i]=='?'||Word[i]=='='||Word[i]=='\n'){
Fix=true;
continue;
}
if(Fix){
Fix=false;
++ThisIndex;
}
ArrWords[ThisIndex]+=Word[i];
}
return ArrWords;
}
private static System.String GetAssociation(System.String Word){
System.IO.StreamReader Reader=System.IO.File.OpenText(MemoryPath);
while(true)
{
System.String Buffer=Reader.ReadLine();
if(Buffer==null){
break;
}
if(Buffer.Contains(Word)){
//Резервируем массив из двух слов для левой и правой ассоциаций
System.String[] Result=new System.String[2];
for(System.Int32 i=0, Index=0; i<Buffer.Length; ++i){
if(Buffer[i]=='='){
//Сиволы следующие после второго в строке символа '=' игнорируются
if(Index==1){
break;
}
++Index;
continue;
}
Result[Index]+=Buffer[i];
}
//Проверяем на содержание искомой строки только левую ассоциацию,
//При успехе возвращаем правую ассоциацию
if(Result[0].Contains(Word)){
Reader.Close();
return Result[1];
}
}
}
Reader.Close();
return null;
}
private static void PutAssociation(System.String Left, System.String Right){
System.IO.File.AppendAllText(MemoryPath, Left+'='+Right+'\n');
}
public static System.String GetFullAssociation(System.String Word){
if(Word==null){
return null;
}
System.String[] Words=GetWords(Word);
System.String Result=null;
System.Boolean FixResult=false;
for(System.Int32 i=0; i<Words.Length; ++i){
if(GetAssociation(Words[i])!=null){
FixResult=true;
Result+=Bot.GetAssociation(Words[i])+' ';
}
}
if(!FixResult){
Result=null;
}
if(Word.Contains("-")){
System.String[] NewAssociations=new System.String[2];
for(System.Int32 i=0, Index=0; i<Word.Length; ++i){
if(Word[i]=='-'){
if(Index==1){
break;
}
++Index;
continue;
}
if(Word[i]=='='){
continue;
}
NewAssociations[Index]+=Word[i];
}
PutAssociation(NewAssociations[0], NewAssociations[1]);
}
return Result;
}
}
Конкретно со строками я больших изменений не увидел)
А комментарием выше пишите что-то про *nix. Хм…
Qt не мал, но на нём хотябы писать можно, на чистых плюсах разве что серверные решения писать. Где вы там 2 гигабИта нашли я не знаю, вообще единицы измерения у вас не менее странные, чем кодировка, у меня выходило около 50-100МБ библиотек ссобой, что тоже не мало, но в современном мире особой роли не играют.
Синтаксис Python как говорится на вкус и цвет, но вот про компилируемость и «калькулятор» я совсем не понял. Зачем вам компилируемость? Что вы хотели сказать скрытым текстом? Ну да ладно, дело ваше. То что на этом языке ваша программа сократится раз в 10, а по скорости будет такая же плюс отладка в разы проще это впринципе не существенно. То что упаковать в .exe можно тоже, помимо того будет работать одинаково хорошо везде где есть интерпретатор питона. В общем много фич, но это не важно.
Java, на удивление, частично вытеснила C и C++ из серверного сегмента, а вы говорите, что она на десктопе медленная. Вы замеряли? Тесты просматривали хотябы? Почему не говорите, что скриптовые языки медленные, а про яву внезапно заявили? Знаете, но многие ресурсы вообще утверждают, что Java быстрей C++, вот, например.
Хм. Ну если вы боитесь ООП, то ок. Мне ООП кажется более удобным и перспективным.
А судя по вашим замечаниям создаётся ощущение, что вам не 16, а 61. Очень «устаревшие» взгляды, как по мне.
Синтаксис Python как говорится на вкус и цвет, но вот про компилируемость и «калькулятор» я совсем не понял. Зачем вам компилируемость? Что вы хотели сказать скрытым текстом? Ну да ладно, дело ваше. То что на этом языке ваша программа сократится раз в 10, а по скорости будет такая же плюс отладка в разы проще это впринципе не существенно. То что упаковать в .exe можно тоже, помимо того будет работать одинаково хорошо везде где есть интерпретатор питона. В общем много фич, но это не важно.
Java, на удивление, частично вытеснила C и C++ из серверного сегмента, а вы говорите, что она на десктопе медленная. Вы замеряли? Тесты просматривали хотябы? Почему не говорите, что скриптовые языки медленные, а про яву внезапно заявили? Знаете, но многие ресурсы вообще утверждают, что Java быстрей C++, вот, например.
Хм. Ну если вы боитесь ООП, то ок. Мне ООП кажется более удобным и перспективным.
А судя по вашим замечаниям создаётся ощущение, что вам не 16, а 61. Очень «устаревшие» взгляды, как по мне.
Последний Qt если собирать MSVC в 10-12 мегабайт укладывается (без некоторых модулей).
Java щас больше в интерпрайзе, потому что покупной софт на джаве, а держать ещё и плюсовиков никому не хочется, вот и лезет в java. (зы по вашей ссылке я так и не увидел что java быстрее, а вот памяти точно сильно больше ест)
Java щас больше в интерпрайзе, потому что покупной софт на джаве, а держать ещё и плюсовиков никому не хочется, вот и лезет в java. (зы по вашей ссылке я так и не увидел что java быстрее, а вот памяти точно сильно больше ест)
Прошу прощения, читал, что быстрее несколько в другом месте, а этот ресурс обычно привожу для сравнения скорости ЯП и по ошибке интерпретировал приведённые там данные наоборот. И тем не менее там есть тест в котором Java отработала быстрее. По памяти я давно уже не заморачиваюсь, в современных ПК её с запасом, хотя возможно стоило бы.
А с Qt работал последний раз с 4.8-5.0 и с gcc/mingv. Если таскать ссобой заранее скомпилированные библиотеки, которые сам проект предоставляет у меня с GUI и network выходило около 80МБ. Сейчас возможно что-то поменялось, а по поводу MSVC вообще не знаю ибо работаю под Linux, дома Mac и так уже давно.
А с Qt работал последний раз с 4.8-5.0 и с gcc/mingv. Если таскать ссобой заранее скомпилированные библиотеки, которые сам проект предоставляет у меня с GUI и network выходило около 80МБ. Сейчас возможно что-то поменялось, а по поводу MSVC вообще не знаю ибо работаю под Linux, дома Mac и так уже давно.
Знаете, вам то может быть и удобно таскать с собой скомпилированные библиотеки из Qt по отдельности- а мне нет. Не вижу в этом смысла. Ну а насчет 2гб- загляните но оф сайт Qt
Что то мне подсказывает, что я еще и занизил цифры.
Что то мне подсказывает, что я еще и занизил цифры.
Не совсем понял о чём вы. Если брать *nix, то там библиотеки ставятся в системе и такскать их ссобой вообще не надо. Если брать Windows, то для разработки, возможно, нужны все, но таскать с приложением можно только те, которые это приложение использует. В случае данного приложения хватит всего одной(если я ничего не путаю). Смысл лишь в том, чтоб софт работал и писать код этого софта было удобней, приятней и быстрее.
По объёму на оф. сайте сходу не нашёл, раньше весили в полном комплекте меньше 1ГБ включая отладочные, которые весят раза в 2 больше и нужны только для отладки. Исходники библиотек вообще не нужны в большинстве случаев.
По объёму на оф. сайте сходу не нашёл, раньше весили в полном комплекте меньше 1ГБ включая отладочные, которые весят раза в 2 больше и нужны только для отладки. Исходники библиотек вообще не нужны в большинстве случаев.
А как насчет этого?
Я бы не хотел разбираться и возиться с Qt ради пары библиотек.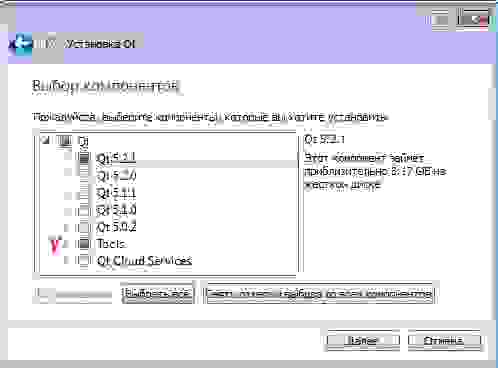
А использование Qt без Qt Creator автоматически означает возню с настройкой IDE и компилятора под Qt.
Я бы не хотел разбираться и возиться с Qt ради пары библиотек.
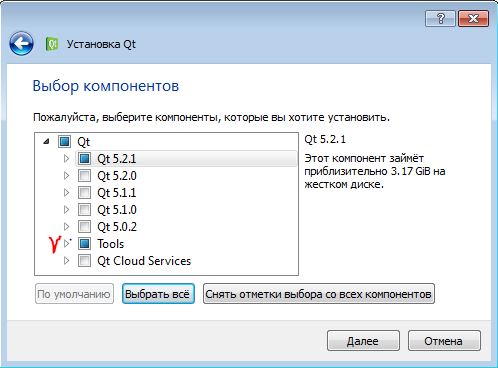
А использование Qt без Qt Creator автоматически означает возню с настройкой IDE и компилятора под Qt.
Возможно стоит ткнуть на стрелочки и посмотреть что он там ставит поподробней?
И последняя версия на данный момент 5.5, где вы взяли этот установщик?
P.S. И я конечно не исключаю, что что-то изменилось, но человек несколькими постами выше говорит об обратном.
И последняя версия на данный момент 5.5, где вы взяли этот установщик?
P.S. И я конечно не исключаю, что что-то изменилось, но человек несколькими постами выше говорит об обратном.
Опять-таки, столько весит среда разработки, необходимые для работы софта либы весят меньше. Но ИМХО, чистых сей хватит — если мы всё ещё обсуждаем кодировки, то легче нагуглить (или написать) простенький конвертер кодировок. (Хотя, некоторые считают, что тут пары строчек безо всяких либ хватит)
Гораздо приятней, чем 866, но всё ещё не кроссплатформенно (или я ошибаюсь?). А есть какой-нибудь вариант, чтобы во всех ОС работало нормально?
PS Я в институте всегда делал
Для вывода вроде помогало, но для ввода непомню.
PS Я в институте всегда делал
setlocale(LC_ALL, "Russian");
Для вывода вроде помогало, но для ввода непомню.
#ifdef _WIN32
setlocale(LC_ALL, "Russian");
#endif
только при переносе текстового файла его придётся конвертировать.
Вообще, если цель — кроссплатформенность (её у топикстартера нет, но всё же) лучше сохранить файл в зависимости то того, какую ОС вы уважаете больше в кодировке CP1251 (под windows она по умолчанию, а под *nix открывать в редакторе типа gedit с выбором кодировки) или UTF-8 (всё наоборот, к слову, gedit под windows тоже есть). К проекту приделываем libiconv и делаем что-то типа такого:
#ifdef _WIN32
#define OUTPUT_ENCODING "cp866"
#endif
#ifdef __linux__
#define OUTPUT_ENCODING "utf-8"
#endif
Хорошо, где конкретно в этой задаче применимо ООП?
Можно было бы создать статический класс (привет C#), инкапсулировать функции немного по другому, и это все?
Можно было бы создать статический класс (привет C#), инкапсулировать функции немного по другому, и это все?
Насчет отладки- как мне казалось современные IDE давно решили эту проблему…
И легкость (вами заявленная) в отладке- еще не повод выбирать Python
И легкость (вами заявленная) в отладке- еще не повод выбирать Python
Насчет Java.
Разумеется, я просматривал тесты.
Не видно, где это Java хоть немного на равных с C++.
Да и элементарное рассуждение- jvm с ее не далеко лучшей интеграцией с системой будет явно уступать C++ везде где только можно.
Кстати, в большинстве «сравнений C++ и Java» сравнения ведутся с примитивными типами, не с кучей, и к тому же Java оптимизирует код, компиляторы C++ в этом отношении ведут себя честнее.
Я не против jvm, я просто не понимаю вашего беспокойства за Java)
Разумеется, я просматривал тесты.
Не видно, где это Java хоть немного на равных с C++.
Да и элементарное рассуждение- jvm с ее не далеко лучшей интеграцией с системой будет явно уступать C++ везде где только можно.
Кстати, в большинстве «сравнений C++ и Java» сравнения ведутся с примитивными типами, не с кучей, и к тому же Java оптимизирует код, компиляторы C++ в этом отношении ведут себя честнее.
Я не против jvm, я просто не понимаю вашего беспокойства за Java)
Я не за Java. C++ тоже умеет делать и -O2 и -O3, так что в чём честность неясно.
Я просто не понимаю почему C++ и почему вы называете его единственным вариантом для данной задачи.
IDE не решают всех проблем, я уже ощутил это. Да и не все ими пользуются. На данный момент сравнивая все языки на которых я писал меньше всего мне нравятся C и C++ за черезмерную сложность, большое количество кода, сложную отладку (а пару лет назад мне так не казалось, но я просто не видел другого), необходимость прямой работы с памятью, очень много непредвиденных поведений (они конечно вытекают из документации, но запомнить и всегда держать в голове их все довольно сложно) и так далее. И как мне кажется все эти минусы оправданы только когда нам нужна очень высокая производительность, а в задаче, описанной в статье, сверхпроизводительности не требуется и разница между С++ и чем угодно другим будет незаметна.
Я просто не понимаю почему C++ и почему вы называете его единственным вариантом для данной задачи.
IDE не решают всех проблем, я уже ощутил это. Да и не все ими пользуются. На данный момент сравнивая все языки на которых я писал меньше всего мне нравятся C и C++ за черезмерную сложность, большое количество кода, сложную отладку (а пару лет назад мне так не казалось, но я просто не видел другого), необходимость прямой работы с памятью, очень много непредвиденных поведений (они конечно вытекают из документации, но запомнить и всегда держать в голове их все довольно сложно) и так далее. И как мне кажется все эти минусы оправданы только когда нам нужна очень высокая производительность, а в задаче, описанной в статье, сверхпроизводительности не требуется и разница между С++ и чем угодно другим будет незаметна.
Я наоборот полюбил С за возможность прямой работы с памятью (да, рассматриваю как фичу), и навык разбираться в непредвиденных поведениях. При этом не отрицаю полезности и функциональности других ЯП, считаю что они применимы в зависимости от задачи, это инструмент. Но для школьника считаю написание приложений на С\++ крайне полезным, несмотря на целесообразность в конкретной задаче.
Насчет:
Буду благодарен, если вы покажете мне, как улучшить код в данном случае используя ООП.
Не нужно создавать систему с наследованием классов ради пары функций.
Если вам так нравится уделять кучу времени решению абстрактных задач, построению иерархии классов, по ходу чего частенько появляется еще с 10ок проблем только из за ООП- то пожалуйста.
Если _вам_так_нравится_Python_ опять же ваше _дело_.
Хм. Ну если вы боитесь ООП, то ок. Мне ООП кажется более удобным и перспективным
Буду благодарен, если вы покажете мне, как улучшить код в данном случае используя ООП.
Не нужно создавать систему с наследованием классов ради пары функций.
Если вам так нравится уделять кучу времени решению абстрактных задач, построению иерархии классов, по ходу чего частенько появляется еще с 10ок проблем только из за ООП- то пожалуйста.
Если _вам_так_нравится_Python_ опять же ваше _дело_.
Я лишь отвечаю на ваши комментарии и не могу понять ваш выбор. Что мне нравится это отдельная тема. Я лишь привожу доводы почему что-то лучше/хуже для тех или иных задач и пытаюсь от вас добиться доводов почему другие языки не могут решить ту же задачу с меньшими трудозатратами.
Если бы вы написали, что обожаете C++, а остальные языки втопку, было бы понятней, но когда вы начинаете объяснять, что все остальные такие плохие, хочется донести до вас, что не всегда это так и не в этом случае точно, ну или хотябы для себя узнать чем же всётаки так хорош C++, возможно я его недооценивал.
Если бы вы написали, что обожаете C++, а остальные языки втопку, было бы понятней, но когда вы начинаете объяснять, что все остальные такие плохие, хочется донести до вас, что не всегда это так и не в этом случае точно, ну или хотябы для себя узнать чем же всётаки так хорош C++, возможно я его недооценивал.
Это ужасно… Windows до сих пор не знает что такое UTF8
Windows отлично знает, что такое Unicode (UTF-16) и UTF-8.
Но если вы наберете скрипт в блокноте, и решите сохранить его не в UTF-8 или UTF-16, а в однобайтной кодировке ANSI (в случае русифицированной Windows — Windows-1251), то при выводе неанглийских символов в консоли будет абракадабра, т.к. консоль интерпретирует однобайтные символы в кодировке ASCII (DOS) (в случае русифицированной Windows то DOS-866).
программисты пишут на C++ то, что стоило бы писать на скриптовом языке
Возможно, автор-школьник будет тем, кто пишет на C++ интерпретаторы скриптовых языков.
На чем то нужно учиться.
Неясно, зачем нужны внешние инклюд-гарды в Bot.h.
Более того, если кому-то нужны стримы, пусть заинклюдит их в соответствующем cpp-файле. В хедер-файле с одной функцией, не имеющей в сигнатуре стримов, им не место.
Более того, если кому-то нужны стримы, пусть заинклюдит их в соответствующем cpp-файле. В хедер-файле с одной функцией, не имеющей в сигнатуре стримов, им не место.
Хм, спасибо за идею. Захотелось на Go сделать что-то подобное, только на узкую тему.
> std::wcout<<«Bot: Не распознана ключевая последовательность!»
Уточка говорит: «Зря-зря».
По коду ничего говорить не буду, но дам пару рекомендаций для последующей реализации:
1. В юникод потоки следует посылать юникод строки. Но сперва нужно подключить к ним русскую локаль, тогда можно на человеческом языке писать, без 866 кодировки.
2. Перед сохранением конвертируй строки в utf8; при чтении — обратно в юникод.
3. Про ASCII строки пора бы уже начать забывать.
Уточка говорит: «Зря-зря».
По коду ничего говорить не буду, но дам пару рекомендаций для последующей реализации:
1. В юникод потоки следует посылать юникод строки. Но сперва нужно подключить к ним русскую локаль, тогда можно на человеческом языке писать, без 866 кодировки.
2. Перед сохранением конвертируй строки в utf8; при чтении — обратно в юникод.
3. Про ASCII строки пора бы уже начать забывать.
Помимо того, что уже сказали:
— Вместо того, чтобы добавлять к слову по одному символу, лучше сразу определить начало и конец, а потом сконструировать строку из диапазона.
— Правильный способ чтения файла по строкам это:
— Явно закрывать потоки нет необходимости, они автоматически закрываются в деструкторах. В этом вся сила RAII.
— (Стилистика) Настоятельно рекомендую добавлять пробелов вокруг операторов, будет лучше читаться.
— Ну и ещё раз, у вас какой-то ужас в заголовочном файле. Вам не нужно защищать чужие заголовки от повторного включения, это их задача. В заголовочнов файле должны быть включены только те заголовки, которые нужны именно в этом заголовочном файле, а не в cpp файле. Поскольку в объявлении функции используестя только std::string, то и включить следует только string. Для функции extern тут не нужен. Ну и как уже сказали, возвращать константное значение не стоит. Результат должен выглядеть вот так:
— Вместо того, чтобы добавлять к слову по одному символу, лучше сразу определить начало и конец, а потом сконструировать строку из диапазона.
— Правильный способ чтения файла по строкам это:
std::string line;
while (std::getline(Memory, line))
{
// ...
}
— Явно закрывать потоки нет необходимости, они автоматически закрываются в деструкторах. В этом вся сила RAII.
— (Стилистика) Настоятельно рекомендую добавлять пробелов вокруг операторов, будет лучше читаться.
— Ну и ещё раз, у вас какой-то ужас в заголовочном файле. Вам не нужно защищать чужие заголовки от повторного включения, это их задача. В заголовочнов файле должны быть включены только те заголовки, которые нужны именно в этом заголовочном файле, а не в cpp файле. Поскольку в объявлении функции используестя только std::string, то и включить следует только string. Для функции extern тут не нужен. Ну и как уже сказали, возвращать константное значение не стоит. Результат должен выглядеть вот так:
#ifndef BOT
#define BOT
#include <string>
std::string GetFullAssociation(const std::string&);
#endif //BOT
Спасибо, насчет возврата константы вы пожалуй правы)
Старался использовать const везде кроме тех случаев где его нельзя использовать, следуя советам из комментариев прочитанных ранее на хабре)
Старался использовать const везде кроме тех случаев где его нельзя использовать, следуя советам из комментариев прочитанных ранее на хабре)
const на user-defined типе, возвращаемом из функции, препятствует move-семантике, и никакой пользы не приносит. Поскольку может происходить копирование, этот const все равно ничего не дает. const (не top-level) имеет смысл при возврате из функции только если возвращается ссылочный тип (ссылка или указатель).
И еще есть вопрос- почему extern здесь не нужен?
Он нужен только в при объявлении прототипа из .cpp?
Он нужен только в при объявлении прототипа из .cpp?
Sign up to leave a comment.
Избитая банальность. Как школьник бота писал