Comments 306
одинаковый результат, когда вывод направлен в файл, то есть работают корректно.
А это точно означает «корректно»? Может, просто «одинаково неправильно»? :)
Вот да, я ожидал развязку в стиле "мы сделаем всё на шаблонах, чтобы итоговый FizzBuzz вычислился во время компиляции, а работа программы будет заключаться исключительно в том, чтобы вывести строку из секции .data в консоль." :D
Размер программы, соглашусь, критерий независимый, но это не точно :)
А тут речь про производительность или, может быть, скорость. Как же у меня бомбит от «перфоманса» и «генерации».
А вы не бомбите.
Алсо весьма любопытно, если "перфоманс" ещё куда ни шло (хотя встречается повсеместно), то что не так с генерацией?
В значение "Поколение" оно используется уже у Даля в словаре 1819 года, а как раз-таки смысл "результат глагола 'генерировать'" появился уже после 1950х. Возможно это не такое уж нововведение?
Окей, словарь Ушакова посвежее будет? https://gufo.me/dict/ushakov/%D0%B3%D0%B5%D0%BD%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F
Ожидают результата: «полёт на Марс».
Любой более менее опытный человек может загрузить любого другого опытного человека узкоспециализированной задача на который первый съел собаку
Опытный специалист должен не только уметь ускорять алгоритмы, но и понимать, когда пора остановиться и перейти к более важной работе. Возможно, потому и не перезвонили.
Для джуниора, я бы сказал, это даже хорошо. А вот для сениора…
Это было больно, но, пожалуй, заслужено. Ладно, я тебе покажу, кто тут джуниор.
плюс нежелание остановиться после команды работодателя, с политической точки зрения может расцениваться как вариант деструктивного поведения. (с программной точки зрения это — полное зависание процесса) ;)
Многие же, к сожалению, думают — раз я такой крутой программист что пишу так, что джуны не понимают — мой код самодокументирующийся. А на самом деле — чем больше опыта, тем проще и понятнее пишешь код.
Черные ящики на практике обычно оказываются не такими уж и черными, и каждая последующая версия хоть и быстрее но тем сложнее оптимизируется. Что если мы сделаем FizzBuzzFooBar? в превоначальном варианте это ещё два ифа, во втором нужно будет константу менять и заполнять пробелы формата выводом чисел, а про последующие даже думать не хочу. Что делать когда варианты перестают влезать не только в 10 байт, но и вообще в AVX512?
Такой код имеет право на жизнь, безусловно, очень крутая статья, свой плюсик я там нарисовал. Но не надо сениора который остановился на первом (втором?) варианте считать хоть чем-то хуже: минимум у него другие интересы, а как максимум он просто смог оценить что решение удовлетворительно и оптимизировать наносекунды ради катастрофического падения простоты кода не нужно
А вопрос, когда остановиться в оптимизации FizzBuzz, сам по себе ответа не имеет
Конечно имеет: когда наш интервьювер улыбнулся и начал переходить к следующим вопросам — это и был момент оптимальной производительности/читаемости. А когда он начал уползать сторону двери — уже сильно сильно ушли в сторону неоптимального решения.
В общем, понятное дело, что автор просто поделился о том как круто можно занютить физзбазз, в такой вот форме собеса с шутейками, но если вообразить что такое могло быть в реальности то имеем что вопросы "а зачем?" вполне обоснованы. Если воспринимать это как фон для "оптимизируем физзбазз в 5 этапов" тогда конеш вопросов никаких быть не может — круто пишем, простор для оптимизаций — широк.
Что до высокоуровневых языков свиней с дубами — у нас был хаскель код который по перфомансу примерно идентичен вылизанному плюсокоду, из минусов только что он жрал в 10 раз болше памяти. Но как раз-таки память не проблема, а по тактам все было отличненько. И выглядело прилично. Впрочем, уважаемый дедфуд несколько раз уже продемонстрировал подобное, так что за меня вопрос "написать статью про быстрый хачкель на хабр" уже выполнена.
вручную разложена, чтобы влезать в кэши CPU, алгоритмы перепидарашены, чтобы предсказатель ветвлений не фейлил, интринсики и вот это вот все?
Вот это всё, да.
Хаскеле, не превратившись в ужасающий «С++ на Хаскеле», не верится вовсе.
Ну, продакшн код увы показать не смогу, остается только поверить в эти цифры (из внутренней презы с бенчами разных вариантов):
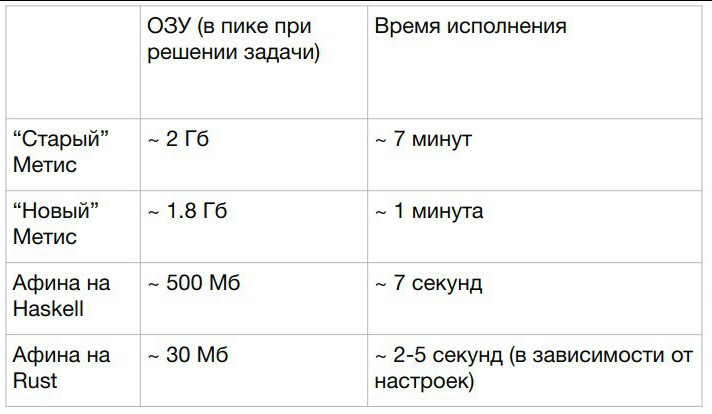
Сравнивается: говнокод на Java, нормальный код на Java, оптимизированный хаскель, оптимизированный раст
Ну я не эксперт в джаве, можете подскажете как в джаве:
- указать что вот через у этого интерфейса ровно две реализации, Причем чаще будет реализация А чем реализация Б (и на неё в IF нужно проверять в первую очередь)
- указать какая ветка ифа более вероятна чтобы компилятор её поставил первый и не нужно было делать лишний джамп в большинстве случаев, например в расте:
if likely(some_condition()) { ... } else { ... } - как указать что объекты X,Y,Z обязательно должны быть на стеке?
указать что вот через у этого интерфейса ровно две реализации
Вот может как-то так?
https://www.baeldung.com/java-sealed-classes-interfaces#1-sealed-interfaces
указать какая ветка ифа более вероятна чтобы компилятор её поставил первый и не нужно было делать лишний джамп в большинстве случаев, например в расте: if likely(some_condition()) {… } else {… }
https://www.baeldung.com/java-branch-prediction#2-order-of-branches
https://medium.com/swlh/branch-prediction-everything-you-need-to-know-da13ce05787e
По поводу третьего пункта — по-моему никак. Хотя я не гуру JVM :)
Вот может как-то так?
Прикольно, один вопрос: использует ли JIT как-то информацию об этом или это просто удобный способ указывать АДТ? Мне кажется что последнее, если есть другая инфа — поделитесь пожалуйста.
https://www.baeldung.com/java-branch-prediction#2-order-of-branches
https://medium.com/swlh/branch-prediction-everything-you-need-to-know-da13ce05787e
Речь как раз о кейсах где бранчпредиктор не справляется и нужно ему помочь. https://doc.rust-lang.org/std/intrinsics/fn.likely.html
поделитесь пожалуйста
Я так понимаю, это больше сахарок и на производительность особо не влияет. Впрочем, могу и ошибаться.
Речь как раз о кейсах где бранчпредиктор не справляется и нужно ему помочь.
Ну вот что пишут:
So you should order your branches in the order of decreasing likelihood to get the best branch prediction from a “first encounter”.
Ну вот что пишут:
Тут речь не о бранч предикторе вообще. Нас интересует, чтобы JIT код вида
if (unlikely(something)) {
add(a, 1);
}
else {
add(b, 2);
}превратил в (псевдокод)
1: cmp something 1
2: JE 4
3: ADD %b 2
4: ADD %a 1А не в
1: cmp something 1
2: JNE 4
3: ADD %b 2
4: ADD %a 1Ну вот пример на годболте: https://godbolt.org/z/1brP6G
Ассемблер знать не обязательно, обратите мнимание что синий квадратик num + num + num в скомпилированном коде выше красного квадратика num*123 который компилятор поставил за джамп на .LBB0_1
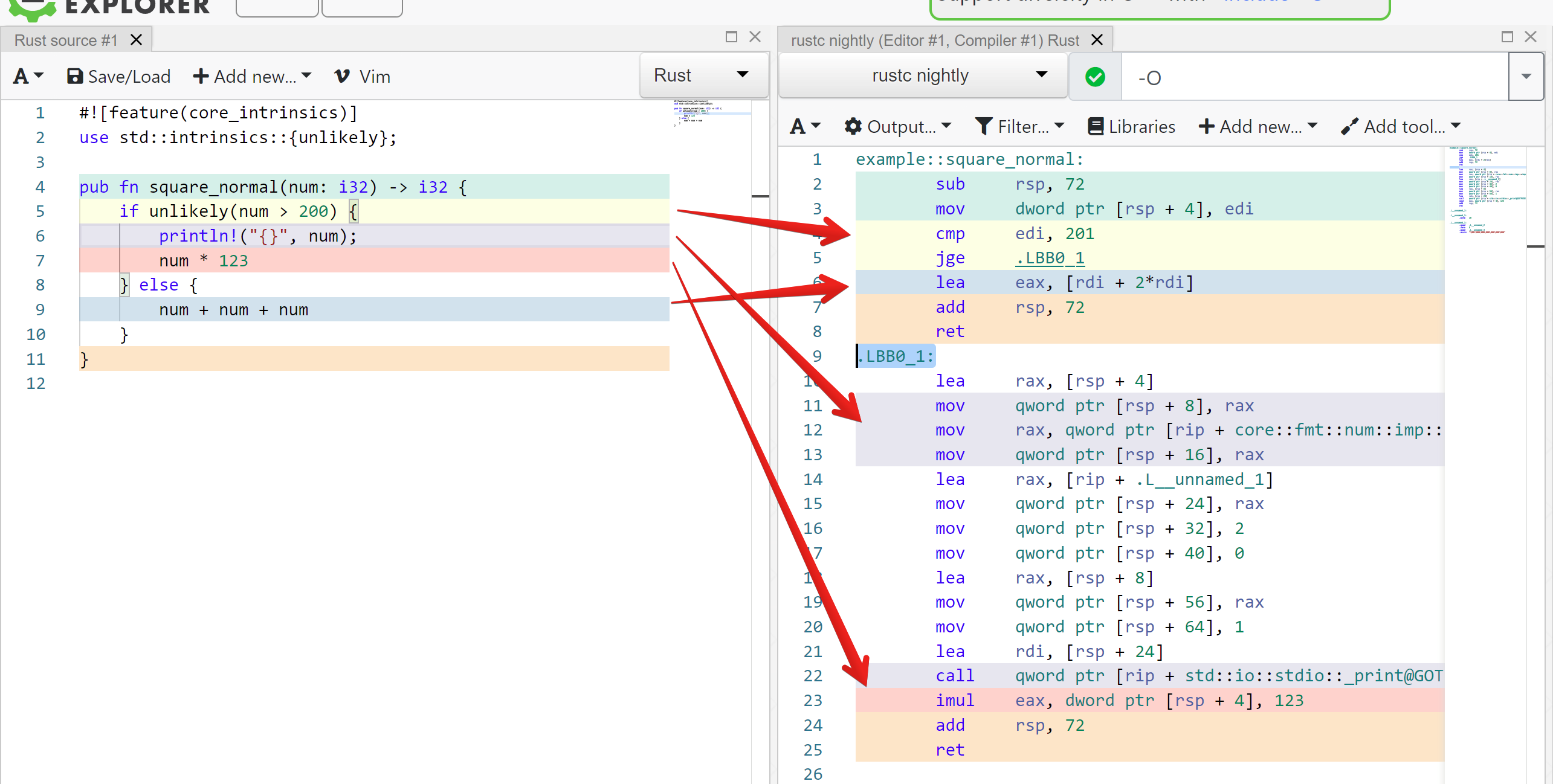
Видно что компилятор переупорядочил код согласно нашим хинтам чтобы более вероятному бранчу не приходилось делать джамп. Тут вопрос про то в какой код скомпилировалось, ни про какой бранчпредиктор пока не идет речи.
Немного поигрался с javac/javap, и похоже что описанных вами оптимизаций не происходит при изменении порядка следования веток.
Возможно, после прогрева JVM таки сделает какие-то оптимизации. Но мне такая магия пока не доступна :(
В общем, это я ктому что когда я выше говорил про оптимизированный код я имел в виду что да, мы настолько упоролись чтобы это считать и чтобы это давало существенную разницу. Поэтому мы взяли не джаву.
Вы правильно заметили: бессмысленно сравнивать порядок ветвления в javap в контексте быстродействия, т.к. основу быстродействия в Java обеспечивает JIT и runtime-профиль исполнения. Насколько я помню, JIT умеет перекомпилировать с переставлениями местами веток, он точно умеет понимать, что у вас не встречалось больше 2х имплементаций интерфейса, но с вопросом "X,Y,Z на стэке" чуть сложнее - так в принципе не бывает, но иногда может спасти инлайн.
Еще микро-офтопик про реализации интерфейса: как-то слабо вяжется в одном предложении "полностью оптимизированная" и "интерфейсы", особенно когда мы пошли считать лишние jmp.
(и на неё в IF нужно проверять в первую очередь)
Реализации интерфейсов обычно вообще не проверяют через if.
как указать что объекты X,Y,Z обязательно должны быть на стеке?
Кстати, а как это сделать в хаскеле?
А вообще в хаскеле нет стека
Вот по-этому я и спросил :)
Вообще, можно стеком считать nurcery, с-но аналогом такой штуки как "аллоцировать на стеке" были бы аннотации для хинтов гц вида: "в этом блоке гц не запускаем", "в этом блоке из nurcery не двигаем" и т.д.
Есть относительно релевантная штука — compact regions — можно один раз заэвалюэйтить терм и собрать мусор в транзитивном замыкании
Да, про это в курсе, но не совсем то. Я говорю несколько о другом сценарии.
Пусть у нас есть перемещающий сборщик — тогда затраты на сбор мусора пропорционально количеству достижимых данных. Тогда идеально запускать сборщик ровно тогда, когда у нас минимум достижимых данных и максимум недостижимых.
Далее — допустим у нас есть некоторая ф-я, которая что-то вычисляет — при этом порождает данные в процессе вычисления. Пусть это будет например 11мб данных (числа просто условные). Возвращает ф-я просто одно число, допустим. При этом ф-я вызывается в лупе.
С-но у нас есть два крайних случая — в первом случае (худшем) сборщик вызывается по триггеру, например, при 21мб заполненной памяти. Это значит что на каждом вызове будет 11мб недоступных данных (на которые нам пофиг) и 10мб доступных (которые сборщик должен обработать).
Идеальный сценарий — это если сборщик будет вызван непосредственно после вычисления ф-и. Тогда у нас вообще нет достижимых данных, он отрабатывает "мгновенно".
Вот собственно мы могли бы на этот луп вырубить гц и дергать его непосредственно после каждого вызова ф-и — это бы и дало идеальный сценарий работы.
В C++ стека тоже нет, но я как-то кладу туда переменные…
Вы не совсем правы. JIT разделяет интерфейсы с одной реализацией, двумя и более. И в первых двух случаях проверка производится условно через if (на самом деле совсем не обязательно, но упростим).
указать какая ветка ифа более вероятна чтобы компилятор её поставил первый
Ну так инвертируйте условие да поменяйте ветки местами. В нормальных IDE это делается одним quick fix-ом. Никакие «хайли лайкли» для этого на фиг не нужны.
А что делать с таким кодом:
int func(int param) {
if (param < 0) { // unlikely
// DEBUG_DUMP
// SHOW_WARNINGS
// BLA-BLA-BLA
}
return param+1;
}тут я хочу, чтоюы всё тело if было сгенерировано где-то в конце сегмента .code и не подгружалось в кеш инструкций. А на входе в функцию на него был условный переход (почти никогда не выполняющийся).
А что делать с таким кодом:
Какие с ним могут быть затруднения?
Если внутри if-а параметр не модифицируется, то точно так же можно инвертировать условие if и засунуть return в блок then, а весь этот DEBUG_DUMP в else.
Перенести всю отладочную требуху в else будет даже логичнее и удобнее для чтения кода.
Где гарантия, что компилятор ветку if ставит likely перед веткой else.
Вот тут я тоже особых гарантий не вижу. Напротив, висит предупреждение о том, что «This is a nightly-only experimental API. (core_intrinsics) intrinsics are unlikely to ever be stabilized».
Покажите мне в каком месте спецификации Java гарантируется что компилятор всегда будет генерировать джамп для ветки else?
Most of the Java programming language's other control constructs (if-then-else,do,while,break, andcontinue) are also compiled in the obvious ways.
Джамп для ветки else достаточно obvious. Но безопаснее считать, что гарантий нет. У нас там JIT дальше и чёрт знает какие bytecode transofrmers пользователь поназагружал.
Вот, кстати, при помощи bytecode transofrmation поддержку такой unlikely дичи можно сделать.
Не очень понятно утверждение. Если я правильно понял термин bytecode transofrmation, то на JIT оно (напрямую) не влияет.
Java agent может модифицировать байткод как сочтёт нужным (см. java.lang.instrument.Instrumentation). В этом случае до JIT дойдёт не совсем то, что лежит в оригинальных class-файлах и было сгенерировано javac.
Чтобы число в десятичном виде перестало влезать в AVX512, оно должно быть больше 64 байт, то есть 10^64 (здесь ^ — это степень, не XOR). Я не знаю имен для таких чисел, но сочувствую любому, кто решит писать FizzBuzz до 10^64 — ему не суждено увидеть результат :)
Суть статьи была не в том, кто круче, а в том, что если хочется упороться, то для этого почти всегда можно найти какую-то возможность, как-то так.
0-терминатор нас тут не волнует, строковые функции не используются, так что можем использовать все 64 байта.
Впрочем, в такой версии оно тоже даёт результат — «джун начитанный».
Как я понял, главное при написании FizzBuzz — надёжно заблокировать выход из переговорки.
с многопоточным использованием. :)
P.S. А, если серьёзно, cтатья просто суперская! Спасибо.
FizzBuzz on rosettacode.org
Ну, и немного отвлечённого Уроки от NeHe на masm64 — программирование задач с OpenGL на ассемблере.
P.P.S. Минусаторы, можете выдохнуть, этот комментарий не для вас!
Пользователи новомодных Фреймворков и языков программирования «курят» нервно в стороне когда вопрос решения задачи «максимально» отзывчив для пользователей и занимает немного в размере результирующего бинарника. :) (imho)
как будто на ARM нет ассемблера :)
Есть конечно. Что Вы будете делать со всем Вашим кодом, который Вы за эти 5-10 лет написали под x86_64?
Переписывать за сеньорскую зарплату!
"Минусаторы", думаю, негодуют из-за того, что вы упорно не понимаете, что дело не в наличии или отсутствии ассемблера.
они не понимают иронии. И, видимо, из тех, кто "программист на [%your_programming_language_name%]".
Смена технологий так сильно пугает, что "фсёпропало"?
Я за последнее время перепробовал толпу языков, постоянно пишу на трех совершенно разноплановых (шарп, раст, тс), и могу сказать что я лично больше верю в свою возможность сообщить нужную инфу компилятору чтобы он сделал что нужно. Да, я могу возиться с vtune и считать такты, но я никогда не полезу писать ассемблер, а подсуну интринсики/likely/… чтобы компилятор сам сделал то, что мне нужно. И обычно он куда умнее меня, а ещё он никогда* не ошибается.
Как итог: когда компилятор становится умнее, прогрмма оптимизируется автоматически, под любую платформу собирается максимум с некоторой потерей производительности, а минимум и без неё, потому что быстрый код написанный в таком стиле часто быстрый везде, просто по факту "думали прежде чем писали".
В общем, каждому своё, какой-нибудь asmbb за верх искусства воспринимать мне тяжело.
А с кодом на Delphi?
Но самое милое конечно это когда заходишь в универ и видишь, как там в виртуалочке запускают твою программу, написанную когда-то на turbo C. :)
https://github.com/DLTcollab/sse2neon
Некоторые костыли, конечно, но всё сразу с нуля переписывать не потребуется.
Да тут не только ASM. Тут с высокой вероятностью интринсики ровно так же отлетят в сторону.
Поэтому у нас в штате есть программист-алгоритмист который читает пейперы и тюнит ядро всей нашей продуктовой линейки в vtune выискивая такты. Пойду завтра ему скажу что его не существует. И нет, это ядро обычного вебсайта, с докерами, местами нодами, постгрями-монгами и прочим. Ну то есть обычный веб бекенд, но только есть там один апп, который в бд не ходит, имеет всего пару хттп ручек и б0льшую часть времени проводит в числодробилке с матрицами.
Не стоит рассуждать о вещах, от которых вы столь далеки. Но ничего, обычно мудрость приходит с возрастом.
/sarcasmoff
Я взял за основу customprint.c (работает примерно 9.2 сек на моей машине), и применил следующие идеи:
— Экономить на вызовах fwrite. Для этого процессим числа в блоках, кратных 15. Я остановился на 35000 блоках. Дает небольшой выигрыш.
— Поддерживать текущее число в виде строки и эмулировать инкремент. Ускоряет за счет того, мы не всегда итерируемся по всем цифрам текущего числа (гораздо чаще инкрементится только последняя цифра).
— Экономить на инкрементах. Для этого заметим, что если после числа мы следующим выведем слово, то можно инкрементить на сразу 2, если два слова — то на 3.
— Мелкие микрооптимизации, которые почти ни на что не повлияли (например, полное избавление от деления и взятия по модулю при инкременте)
Итоговое решение работает за примерно 3.4 сек на моей машине (ссылка)
Сомневаюсь, что это дает какой-то выигрыш, поскольку fwrite() уже буферизован. Возможно, если поиграть с размером буфера, используя setvbuf(), можно что-то выиграть, но это какие-то сущие копейки будут.
> Поддерживать текущее число в виде строки и эмулировать инкремент. Ускоряет за счет того, мы не всегда итерируемся по всем цифрам текущего числа (гораздо чаще инкрементится только последняя цифра).
Примерно эта идея и была использована в reusebuffer.c, только сразу для всего буфера.
> Мелкие микрооптимизации, которые почти ни на что не повлияли (например, полное избавление от деления и взятия по модулю при инкременте)
В customprint.c нет деления по модулю, я от него избавился шагом раньше, в unrolled.c (ну если не считать обработки хвоста, то его нет смысла хоть как-то оптимизировать, цикл на 10 итераций).
Я тоже так думал, но был удивлен, когда это дало примерно 1 сек выигрыша. Думаю передавать много маленьких буферов в fwrite хуже, чем буферы побольше.
Преверить можно установив константу CHUNK_COUNT в 1.
> В customprint.c нет деления по модулю
Он был нужен мне в инкременте. Как говорится сам добавил, сам же и соптимизировал.
По идее не должно, поскольку fwrite буферизует вывод, т.е. далеко не каждый вызов fwrite() приводит к syscall'у write(), который, конечно, довольно дорогой.
> Преверить можно установив константу CHUNK_COUNT в 1.
Попробую, интересно. Я в процессе своих экспериментов играл с размером буфера, и не обнаружил статистически значимой разницы, то есть стандартного буферу размера BIFSIZ, который используется для (f)printf/(f)puts/fwrite/etc, вполне хватает.
Возможно, тут сказывается какая-то разница в параметрах системы.
Вы попробуйте вместо этого цикла в 35000 итераций задать буфер в 5 MB через setvbuf — будет ли разница? Если будет, то тогда к fwrite есть вопросы, конечно.
Хотя у меня есть одно предположение — буферизация функций стандартной библиотеки обязательно должна быть thread-safe (а у меня ведь все компилируется с -pthread), так что скорее всего для сериализации доступа к единому буферу во всех этих функциях, в т.ч. и в fwrite(), используются mutex'ы, а блокировка/разблокировка mutex'а — это syscall'ы, переход из userspace в kernelspace, и это дорого. Как вариант, можно попробовать скомпилировать этот вариант без -pthread и посмотреть, изменится ли что-то.
В любом случае нет смысла городить свою буферизацию, потому что в стандартной библиотеке C она уже есть, максимум — ее надо включить/поменять размер буфера, используя setbuf/setvbuf.
История полностью выдуманная, захотелось добавить немного драмы в сухую статью об оптимизации. Просто как-то пришла идея про возможную оптимизацию FizzBuzz через небольшой unrolling цикла, а дальше просто не смог вовремя остановиться (почти как герой статьи).
Был еще один вариант, многопоточный с memory-mapped I/O, но он оказался сильно медленнее обычного многопоточного, я думаю, это вызвано тем, что когда маппируешь в память 7.5 гигов, и потом пишешь туда, то количество page fault'ов такое, что их обработка kernel'ом обходится очень дорого. Эта версия косвенно подтверждается тем, что использование huge pages (2M-байтных), вместо стандартных 4K-байтных заметно ускорило процесс, но все равно до обычного многопоточного варианта было далеко.
Вы не пробовали писать «технологические рассказы»? Ниша имхо свободна, последний раз ощущение схожее с ощущением, возникшим от вашей статьи у меня было от «мне не хватало одного байта» :)
я думаю, это вызвано тем, что когда маппируешь в память 7.5 гигов, и потом пишешь туда, то количество page fault'ов такое, что их обработка kernel'ом обходится очень дорого.Конечно, у Linux могут быть свои заморочки (хотя вряд ли), но под macOS, для десятков гигабайт, код:
for(int i = 0; i < LIMIT/NBUF; i++) {
fwrite(buf, 1, sizeof(buf), f);
} for(char *omap = pa->omap; omap < pa->omap + chunk; omap += pa->step) {
memcpy(omap, pa->buf, pa->szbuf);
}Был еще один вариант, многопоточный с memory-mapped I/O, но он оказался сильно медленнее обычного многопоточного, я думаю, это вызвано темК гадалке не ходи, проблема в организации многопоточной обработки больших данных, сиречь, в порядке записи.
К примеру, если писать не по столбцам, а по строкам, можно потерять разы.
Довольно очевидно, что они не эквиваленты. Для полноты картины надо бы добавить mmap() в начале и munmap() в конце, и они немоментальные. К тому же хочется посмотреть, как делался mmap, с какими флагами — мы же не просто о записи в память говорим.
> К гадалке не ходи, проблема в организации многопоточной обработки больших данных, сиречь, в порядке записи.
Очень странный, ни на чем не основанный вывод.
Но! Что гарантировано, так это, что все page fault уже обработаны.
В любом случае, цена open()/map()/munmap()/close(), без синхронизации с диском, — доли процента от записи нескольких гигабайт в память.
К тому же хочется посмотреть, как делался mmap, с какими флагами — мы же не просто о записи в память говорим.
mmap(0, LIMIT*LTXT, PROT_WRITE|PROT_READ, MAP_SHARED|MAP_FILE, f, 0)Возможно, для улучшения производительности можно было бы использовать что-то нестандартное, не POSIX, типа MAP_NOCACHE и т.п. Но и так неплохо ж.
> К гадалке не ходи, проблема в организации многопоточной обработки больших данных, сиречь, в порядке записи.Как бы, когда начинали грешить на немасшабируемость подсистемы виртуальной памяти, почти всегда так и оказывалось. 64-бит адресацию для больших баз данных же придумывали, в основном.
Очень странный, ни на чем не основанный вывод.
Как бы, понятно, если несколько потоков пишут в области с шагом гигабайты, это одно, если с шагом десятки-сотни килобайт, это другое, а если с шагом десятки байт, это третья, самая тяжёлая ситуация.
Попробуйте разделить записи между потоками на 1...250000000, 250000001...500000000, 500000001...750000000 и, 750000001...1000000000.
Именно так и делал (ну, ближайшие кратные 15 брал, конечно). И получал почти на секунду дольше, чем вариант с fwrite, при этом я даже huge page включал при mmap.
Может, на вашей системе нет Meltdown и Spectre mitigations, и переключения user space/kernel space намного быстрее происходят?
Это дало около 30% прироста скорости, больше, чем я ожидал.
Если да, наверное, можно попробовать подготовить относительно небольшие дампы (числа по возрастанию добитые пробелами до одного размера, Fizz/Buzz/FizzBuzz, дополнительные десятичные разряды, символы переноса строки). И потом накладывая их друг на друга с правильными смещениями собирать итоговый массив как из конструктора. Или нет?
p.s. Кстати, операцию наложения массивов можно перенести на видеокарту. Вот где простор для оптимизаций))
На самом деле, критерии "синьорности" зависят от компании, и в данном конкретном случае старший разработчик реально будет заниматься микро оптимизациями и выжимать производительность из каждой инструкции, но обычно это немного не так.
На мой взгляд, старший разработчик должен был бы скорее написать код (даже для FizzBuzz), который хоть как-то можно тестировать, расширять и сопровождать. Возможно даже с тестами, документацией и проверками пред- и пост- условий. Только не надо шуток про корпоративную версию FizzBuzz.
Безусловно так может получиться. Я поэтому и написал, что критерии для определения старшего разработчика разнятся от компании к компании.
Основной мой посыл был в любом случае в том, что старший разработчик обычно видит и держит в уме больше деталей связанных с жизненным циклом продукта, его архитектурой и развитием системы. Безусловно, для этого есть другие типы заданий и секции собеседований, но и по FizzBuzz можно многое сказать. Допустим, если я по какой-то странной причине попросил бы кандидата на должность старшего разработчика писать FizzBuzz, меня бы уже очень сильно насторожило что реализация, как в статье, не вынесена в отдельную функцию, да ещё и сверху добавлен макрос (!) с очень общим именем (!!).
Наоборот — самая приятная! :)
Reopened…
Фразу «Напишите программу, которая выводила бы числа от 1 до, скажем, миллиарда...» надо читать примерно так:
Наши аналитики провели исследование и пришли к выводу, что среднему пользователю будет достаточно вывода в миллиард строк. Поэтому давайте пока в качестве MVP сделаем так, а потом посмотрим на метрики, пособираем обратную связь и по результатам будем решать, как дальше развивать фичу.
А после торжественного выпуска фичи на прод события будут развиваться примерно так:
- Прибегут пользователи с пожеланиями сделать настраиваемым число выводимых строк. Найдутся те, кому миллиард — это очень много («Для нашего маленького бизнеса за глаза будет достаточно от 1 до 1000»), и будет крупняк, которому подавай вывод в секстильон строк, а то и в два.
- Прибегут эксплуататоры с вопросом: «А что фича жрет так много ресурсов впустую? Нам говорят, что большинству миллиард строк совсем не нужен, а вы всем так отдаёте!»
- Прибегут маркетологи со словами: «Ой, фича такая популярная, но жрёт столько ресурсов (эксплуататоры жалуются). Давайте её тарифицировать! Сделаем так, что на бесплатном тарифе будет доступен вывод 1..K строк, на базовом — 1..L строк, а на VIP-тарифе все 1..M строк!»
А ваш код к этим котелкам совсем не готов. Переписывать слишком много придётся…
Особенно прикольно, если фичей не будут пользоваться потому, что она слишком тормозная.
Во-первых делать расширяемым код под всевозможные будущие хотелки — невозможно.
Во-вторых это такой же антипаттерн как хардкод одного сценария, я бы назвал его "бесхребетный" код, который состоит из одних адаптеров-стратегий-репозиториев которые из пустого впорожнее переливают с миллиардом никогда не изменяемых опций. Посмотрите на физзбазз на Java из примеров выше — о да, вот уж где можно расширить и изменить что угодно. Явно подготовились к любой хотелке!
Вполне, однако, если мы /dev/null пишем, то это легко проверить, и тогда программа выполняется почти мговенно. А если не в /dev/null, то тут время io решает.
Шах и мат.
Смотря какие требования. Я бы не стал оптимизировать производительность любой ценой в ущерб читаемости кода.
Да, если senior на C (!) пишет такой неоптимальный первый вариант — это повод задуматься.
Суть FizzBuzz в том, чтобы сразу отсеять тех, кто не умеет писать код.
А в случае высокого уровня, тех, кто не умеет решить оптимально самую простую задачу, которая оптимально решается "в лоб":
#include <stdio.h>
int main()
{
for (int i = 0, f = 0; i < 1000000000; ++i)
{
if (!(i % 3)) printf("F"), f = 1;
if (!(i % 5)) printf("B"), f = 1;
if (f) printf("\n"), f = 0;
}
}Выше — самый простой и очевидный вариант (как раз тот "наивный вариант", от собеседуемого ожидаемый), который даёт (CPU такой же, проверил с Fizz/Buzz, да, там 28 секунд, за счёт длины строк):
gcc x.c && time ./a.out > /dev/null
./a.out > /dev/null 14,83s user 0,12s system 99% cpu 15,031 totalПосле этого (при желании — до) senior должен спросить, каковы, собственно, требования к решению, а не заниматься бездумной оптимизацией.
И только потом уже предлагают оптимизации, которыми являются:
- Уменьшение совокупного количества системных вызовов.
- Использование оптимизаций компилятора (как написать код, не мешающий компилятору).
- Возможные способы алгоритмической оптимизации без сильного ущерба читаемости.
Дальше — многопоточность с map->reduce.
Никаких извращений с интринсиками (да ещё и без проверки на этапе выполнения, сработают ли они) делать не стоит, если конечно интервьюер не просит такого явно (а если просит — возможно стоит задуматься, но это зависит от задач, которые вам придётся выполнять).
Ваша реализация решает другую задачу: она не печатает пропущенные числа (а должна).
Во-первых, это в данном случае, не столь важно: главное то, как должен выглядеть первичный вариант.
Во-вторых, если вы посмотрите изначальное условие, которое было дано автором в статье, то ничего подобного не увидите (т.е., нет прямого указания на вывод числа, если оно не кратно, хотя возможно предположить из условия, что это подразумевается):
— Здравствуйте, давайте начнем с небольшого теста, пока я ваше CV смотрю. Напишите программу, которая выводила бы числа от 1 до, скажем, миллиарда, притом если число кратно трем, то вместо числа выводится Fizz, если кратно пяти, то Buzz, а если и трем, и пяти, то FizzBuzz.
В-третьих, "просто добавьте else" или, например, так:
...
if (f)
{
printf("\n");
f = 0;
continue;
}
printf("%d\n", i);
...На моём железе и с моим gcc (всё собрано с O3) самый простой вариант автора (который первый) работает чуть меньше 35 секунд, а Ваш с continue (и полными строками) — чуть больше 45 секунд, разница больше четверти в пользу авторского простого решения.
Да, насчёт замеров вы правы, здесь я ошибся.
И чисто теоретически, любопытно: видимо, компилятор оптимизирует повторные вычисления (при желании, возможно посмотреть листинг того, что он нагенерил).
Без оптимизаций авторский вариант у меня выполняется за 70-71с:
➭ gcc x.c && time ./a.out > /dev/null
./a.out > /dev/null 70,03s user 0,76s system 99% cpu 1:10,94 totalМой же с continue за 81с. Автор немного выигрывает за счёт else if, и в таком варианте, я получаю 78 с.:
...
if (0 == i % 3) printf("Fizz"), f = 1;
else if (0 == i % 5) printf("Buzz"), f = 1;
if (!f)
{
printf("%d\n", i);
continue;
}
printf("\n");
f = 0;
...Но основный выигрыш автор за счёт числа системных вызовов: в случае двойной кратности, он сразу печатает "FizzBuzz", я же всегда делаю отдельный вызов для печати каждого слова.
И это всё-равно не меняет сути комментария выше.
Сам первичный код у автора написан запутанно и не оптимально (если хотите формально — у него цикломатическая сложность немного выше, чем нужно, при этом, задача на оптимизацию ещё не стояла).
И более простой код, пусть и чуть более медленный, предпочтительней.
Когда же, начинается оптимизация, как я писал в комментарии выше, возможно уменьшать число системных вызовов:
enum PrintType { pt_none = 0x0, pt_fizz = 0x1, pt_buzz = 0x2, pt_fizzbuzz = 0x3 };
for (int i = 0; i < 1000000000; ++i)
{
switch (!(i % 3) | (!(i % 5) << 1))
{
case pt_fizz: printf("Fizz\n"); break;
case pt_buzz: printf("Buzz\n"); break;
case pt_fizzbuzz: printf("FizzBuzz\n"); break;
default: printf("%d\n", i); break;
}
}
Результат:
➭ gcc x.c && time ./a.out > /dev/null
./a.out > /dev/null 69,39s user 0,68s system 99% cpu 1:10,17 totalНу и далее: последующее уменьшение числа системных вызовов, буферизация, низкоуровневые вещи, потоки и т.п..
Напишите программу, которая выводила бы числа
нет прямого указания на вывод числа
А вы точно синьор?
Во-первых, это в данном случае, не столь важно: главное то, как должен выглядеть первичный вариант.
Мы Вам перезвоним :)
нет прямого указания на вывод числа, если оно не кратно, хотя возможно предположить из условия, что это подразумевается
Напишите программу, которая выводила бы числа от 1 до, скажем, миллиардаИ как же должно выглядеть более прямое указание?
И как же должно выглядеть более прямое указание?
По крайней
Лучше, как явная приписка:
"притом если число кратно трем, то вместо числа выводится Fizz, если кратно пяти, то Buzz, а если и трем, и пяти, то FizzBuzz, в ином случае выводится само число".
Но да, меня вчера переглючило.
Оправдаюсь хотя бы тем, что собеседования обычно не проводят в два часа ночи. :-)
Выше — самый простой и очевидный вариант
За такой "простой и очевидный вариант" следует сразу лицо бить.
Бить лицо — перебор, но вариант с тремя if'ами и двумя printf'ами на КАЖДУЮ итерацию действительно очень плох, я бы сильно задумался, брать ли такого даже джуниора, потому как его придется слишком много чему учить.
потому как его придется слишком много чему учить.
Когда много учить — это еще хорошо. Проблема — когда научить нельзя. Можно научить писать человека быстрый код — это делается элементарно. Но вот, например, научить человека отличать хороший код от плохого — решительно невозможно, т.к. вкус у человека либо есть, либо его нет. И когда человек вот такое:
if (!(i % 3)) printf("F"), f = 1;
if (!(i % 5)) printf("B"), f = 1;
if (f) printf("\n"), f = 0;называет "более простым, предпочтительным" кодом, по сравнению с "запутанным и неоптимальным" оригиналом — то это конец.
но вариант с тремя if'ами и двумя printf'ами на КАЖДУЮ итерацию действительно очень плох
Плох по сравнению с чем именно? Вопросы оптимизации кода, вообще говоря, это не вопросы сениору, это вопросы мидлу. А сениор от мидла отличается тем, что после просьбы оптимизировать оригинальное решение скажет — "не стану, это не нужно".
Ну может не конец, но очень нехорошо, согласен.
> Плох по сравнению с чем именно?
По сравнению с начальным вариантом, где два if'a и один printf на итерацию. Я говорю чисто об алгоритмической сложности, не о лишней переменной и не об использовании comma оператора в таком контексте — это отдельный серьезный грех.
По сравнению с начальным вариантом, где два if'a и один printf на итерацию. Я говорю чисто об алгоритмической сложности
А я вам говорил про цикломатическую сложность.
Правда, я её неправильно посчитал вчера, так что с этой точки зрения, оба варианта одинаковы (сложность 4).
Модифицированная же лучше у варианта switch/case (тут по Маккейбу, 5 из-за цикла):
➭ pmccabe *.c
5 5 ... 3if.c: main
5 5 ... orig.c: main
3 5 ... switches.c: mainАлгоритмически же они всё-таки O(n), хотя и различаются константой.
Но всё же читается проще вариант без вложенных условий, а в таком примере, — это первое, на что бы я обратил внимание.
и не об использовании comma оператора в таком контексте — это отдельный серьезный грех.
Это вообще не "грех", обычно я его не использую, в данном случае просто нет разницы.
В одном вы правы точно: насчёт "лишних" вычислений я вчера написал херню, некорректно сравнил время, а также неправильно прикинул цикломатическую сложность.
В 2 часа ночи, видимо, лучше хотя бы пытаться заснуть, чем сидеть и что-то делать, когда не спится, т.к. делать не подумав — это не правильно…
Ваш пример выглядит сложнее, но он более оптимален, а формально по сложности он с 3if совпадает.
Проблема — когда научить нельзя.
И вы это всё увидели по FizzBuzz?
Но вот, например, научить человека отличать хороший код от плохого — решительно невозможно, т.к. вкус у человека либо есть, либо его нет.
И когда человек вот такое:
…
называет "более простым, предпочтительным" кодом, по сравнению с "запутанным и неоптимальным" оригиналом — то это конец.
Не придираясь к запятым, вы хотите сказать, что "вариант с тремя ифами" читается сложнее кода, в котором есть вложенные условия?
Вопросы оптимизации кода, вообще говоря, это не вопросы сениору, это вопросы мидлу. А сениор от мидла отличается тем, что после просьбы оптимизировать оригинальное решение скажет — "не стану, это не нужно".
Это вопрос не к "мидлу" или "сениору", разница между ними в том, что последний в контексте решения задачи бизнеса понимает, что сказать, и это не обязательно будет "не стану".
Не придираясь к запятым, вы хотите сказать, что "вариант с тремя ифами" читается сложнее кода, в котором есть вложенные условия?
Ну конечно!
На порядок проще, т.к. в нем вся логика выражена в явном виде. С первого взгляда на код понятно, что как и почему делается, четко виден флоу — нету никакого магического состояния в виде магического эф-а, которое этим флоу управляет и скрывает сам факт наличия условных переходов (вон вы цикломатическую сложность в итоге посчитать не смогли с первого раза правильно — именно из-за этого). С-но код, с управляющими эфами без обоснования просто не проходит нормальное ревью, вот и все.
Предсказание работает достаточно хорошо, и в большинстве случаев, конвейер не будет перезагружен.
Единственный реальный вариант, на котором предсказания бренчпредиктора работают хорошо — это вариант, при котором у вас подряд много раз одинаковых срабатываний. Ну, примерно как в случае проверки на выход из цикла — если у вас цикл длины 1000, то 999 раз подряд будет "да" и только в конце — "нет".
На любых более сложных паттернах конкретный бренч-предиктор конкретного процессора может сработать или не сработать в зависимости от фазы луны.
Интересный у вас подход. И как, много людей к вам идут на собеседование? И много уходят с разбитым лицом?
Речь, конечно, о том, когда такой код попадает в продакшн.
С первого взгляда на код понятно, что как и почему делается, четко виден флоу — нету никакого магического состояния в виде магического эф-а, которое этим флоу управляет и скрывает сам факт наличия условных переходов
Странно, вроде, флаг понятно, где ставится и где сбрасывается, и вся логика "плоская".
Ну, видимо, и тут "на вкус и цвет".
Учту.
вон вы цикломатическую сложность в итоге посчитать не смогли с первого раза правильно — именно из-за этого
Нет, я её посчитать не смог, потому что был "не в том состоянии". :-/
Единственный реальный вариант, на котором предсказания бренчпредиктора работают хорошо — это вариант, при котором у вас подряд много раз одинаковых срабатываний. Ну, примерно как в случае проверки на выход из цикла — если у вас цикл длины 1000, то 999 раз подряд будет "да" и только в конце — "нет".
Это основной вариант, под который он был "заточен", потому и хорошо работает.
Речь, конечно, о том, когда такой код попадает в продакшн.
Как-бы явно предполагалось и было указано, что это первый вариант для собеседования. Даже, если он не вполне корректный, о продакшне речи не шло. Да и вам не кажется странным заменять ревью кода мордобоем (и что вы будете делать, если программист окажется боксёром)?
Странно, вроде, флаг понятно, где ставится и где сбрасывается, и вся логика "плоская".
Она не плоская, как раз и проблема в том, что вам надо проследить весь алгоритм, чтобы узнать, как он ведет себя в тех или иных условиях — т.к. надо видеть весь флоу изменений флага. В явном же виде — вы просто смотрите нужный кейз.
Ну, видимо, и тут "на вкус и цвет".
Это никакой не "вкус и цвет", в 2021 не надо экономить на байтах кода и по-этому так писать уже давно не обязательно.
Это основной вариант, под который он был "заточен", потому и хорошо работает.
Ну да. А остальные варианты просто уже зависят от конкретных реализаций в конкретном процессоре — потому на них и надеяться не стоит.
(и что вы будете делать, если программист окажется боксёром)
Удар по затылку спасет отца русской демократии.
Как-бы явно предполагалось и было указано, что это первый вариант для собеседования. Даже, если он не вполне корректный, о продакшне речи не шло.
Окей, окей, но я уверен, что в продакшене вы тоже пишите с эфками :)
Если нет — то сорян, конечно.
вариант с тремя if'ами и двумя printf'ами на КАЖДУЮ итерацию действительно очень плох
Это самый легко читающийся вариант решения "в лоб". Повторюсь, задачи оптимизировать изначально не стояло.
При этом, if — всего-лишь сравнение и переход.
И как-бы там вообще не требуется многократное получение остатка через условия, что я и отметил (но это как-то пропустили, заминусовав):
flag = (!(i % 3) | (!(i % 5) << 1))if — не «всего лишь», это очень дорогая операция в случае, когда branch predictor ошибается, что приводит к перегрузке всего конвейера. Согласно Wiki: Modern microprocessors tend to have quite long pipelines so that the misprediction delay is between 10 and 20 clock cycles en.wikipedia.org/wiki/Branch_predictor
Поэтому убрать лишний if в цикле, который повторяется миллиард раз — огромный выигрыш, и когда это можно легко сделать, это обязательно надо делать. И это — то знание, которое лично я ожидаю от сениора.
Вариант со switch'ем действительно интересный, я его еще в том комменте заметил. Тут, конечно, у branch predictor'а шансов угадать почти нет, зато только один раз на цикл, надо будет проверить, какой он даст выигрыш. Сдвиг + ИЛИ + 2 НЕ сильно дешевле одного misprediction'а.
Предсказание работает достаточно хорошо, и в большинстве случаев, конвейер не будет перезагружен.
У Intel там совсем не не тривиальный проприетарный алгоритм предсказания.
Хотя, конечно, соглашусь, что лишнее условие при оптимизации, стоит убрать.
А switch, по сути, такой же if/else if, он в такой же cmp+je/jne выродится, так что бранч предиктор работать будет одинаково, т.к. он про него вообще не знает.
Также, начиная с C++-20, к switch/case возможно применять likely/unlikely.
Соответственно, в gcc возможно с __builtin_expect (макросами likely/unlikely в C) поэкспериментировать.
Выражение же, я так думаю, возможно ещё оптимизировать, надо только подумать, как.
Например, заменой div на сложения, используя признаки делимости, которые здесь вспомнили:
Признак делимости на 3 в двоичной системе счисления звучит следующим образом: «Число делится на 3 тогда и только тогда, когда сумма его цифр стоящих на четных местах отличается от суммы цифр, стоящих на нечетных местах, на число, делящееся на 3».
У нас есть программа где скорость работы ВСЕГО приложения на 20% изменяется в лучшую сторону при простановки LIKELY в трёх ифах в разных местах. Так что насчет "Достаточно хорошего предсказания" — бабка надвое сказала.
Мерили со статистикой критерионом.
Максимально точное определение работы branch predictor'а :)
Любопытно… Учту.
критерионом
А киньте ссылку, пожалуйста. Я поискал, и мне оно выдаёт только некий сименсовый комплекс для анализа работы станков. Или это оно?
Бранч предиктор предварительно обучали холостыми запусками программы?
Компилятор генерирует один и тот же код, я просто немного наврал: 20% разницы было не с лайкли, а с префетчем: https://doc.rust-lang.org/std/intrinsics/fn.prefetch_read_instruction.html
Начал в голове восстанавливать прошедшие события и наткнулся что лайкли мы расставляли позже
За такой "простой и очевидный вариант" следует сразу лицо бить.
Интересный у вас подход. И как, много людей к вам идут на собеседование? И много уходят с разбитым лицом?
В вот наконец то, когда последний вариант готов, настала пора заглянуть в performance counters процессора :) Вы, кстати, не смотрели — куда упираетесь? В память упираться вроде рановато.
Как это посмотреть? Есть какой-то гайд на эту тему?
Я подозреваю, что упирается все в память, syscall'ов в результате получается не так много. Кстати, появилась странная мысль попробовать отключить всякие Meltdown и Spectre mitigations в ядре, чтобы переключение user space-kernel space быстрее было, и сравнить.
Intel vTune Amplifier (есть триал), если попроще.
https://github.com/andikleen/pmu-tools — если под линуксом и хочется упороться на-отличненько. Вот статья, с которой можно начать: https://halobates.de/blog/p/262 .
Про память — не должно бы в неё упираться, потому что всего в районе 5 гбайт/с записи, к тому же линейной — кэш процессора должен порулить тут.
Очень хочется. Спасибо, займусь на досуге.
> Про память — не должно бы в неё упираться, потому что всего в районе 5 гбайт/с записи, к тому же линейной — кэш процессора должен порулить тут.
Разве кэш как-то помогает при записи в память? Чтения тут почти нет. 5 Gb/s при общем размере вывода в 7.5 Gb дают около 1.5 сек — очень близко к тому, во что я уперся.
вот тут 3 наверно
Я отвернулся от доски и увидел, что в переговорке я один. Через стеклянную стенку переговорки я разглядел интервьюера, который что-то быстро говорил секретарю, показывая пальцем в мою сторону. Он что, вызывает охрану? Похоже, что мне тут больше не рады.
А что если всё более прозаично — например, у автора есть привычка вроде «ругать пятиэтажным матом всё вокруг» или «вести себя странно» в момент сосредоточенного обдумывания задачи, чего он сам может не заметить и что на самом деле было причиной такого поведения интервьюера? Вот представьте картину со стороны интервьюера: даёте вы человеку задачу — он задумался, ушел глубоко в свои размышления и внезапно начал задумчиво корчить рожи, грызть листочек, почесывать ногой нос и вообще лезть на потолок. Может интервьюер после увиденного не охрану звал а экзорциста;) Это конечно всё шутка, но хотелось бы отметить — я на своем примере знаю, что когда я слишком сосредоточен, то не отдаю себе отчёт в совершаемых действиях (примеры: пошел налить кофе — насыпал кофе в сахарницу и выбросил кружку в мусорное ведро. Или в процессе обдумывания разгрыз карандаш в щепки с угрожающим выражением лица, и т.п.)
Знание технических тонкостей, показанные в статье — это конечно замечательно, но по моему не главное в сеньоре.
и сначала напишет тесты и документацию :)
Соглашусь, однако возможно этой конторе именно такой сениор и нужен. В конце концов, базы данных и браузеры кому-то писать надо, не боги таки точают. А гнаться кроме необходимых узких технавыков ещё и за софтскиллами стратегическим видением — можете не закрыть вакансию оочень долго
Тогда (без учёта времени настройки и загрузки плис) все вычисления и получение готовой строки будет занимать одну-две команды чтения из памяти.
Ну и запустить на каждое ядро свой поток.
Тут тормоз будет только в самом stdout
Если вывод на какую то физику, типа диска, то сделать мап для файла записи и зарядить dma. Тут скорость определится скоростью диска и размером кеша на нем.
О себе заранее хочу сказать, что я начинающий python разработчик, с опытом менее трех месяцев и возможно ошибаюсь, заранее прошу прощения за это.
Собственно касаемо самой статьи, а что если посчитать количество Fizz, Buzz и FizzBuzz в первой тысяче. А потом просто умножить на число кратное необходимому?
Например, если в первой тысяче Fizz, Buzz и FizzBuz каждый встречается по 10 раз, то получается в миллионе оно будет встречаться по 10.000 раз, а в миллиарде по 10.000.000 раз? Получается вместо пересчета можно всего миллиарда можно посчитать первую тысячу, и выводить просто кратные результаты?
Например, если Fizz встречается в первой тысяче в числах 10, 100, 110, 210, 310, 410, 510, 610, 710, 910. То логическим продолжением будет 1010, 1100, 1210… 1910 и так далее?
> Например, если в первой тысяче Fizz, Buzz и FizzBuz каждый встречается по 10 раз, то получается в миллионе оно будет встречаться по 10.000 раз, а в миллиарде по 10.000.000 раз? Получается вместо пересчета можно всего миллиарда можно посчитать первую тысячу, и выводить просто кратные результаты?
Это некорректно, поскольку ни тысяча, ни миллион не кратны 15. Вот если взять полторы тысячи и полтора миллиона, тогда да, эта логика сработает. Но, как сказано выше, числа тоже надо выводить.
Так там в какой-то момент вычисления (определение делимости) вообще уже не производятся, т.к. через каждые 15 чисел ситуация повторяется. Вопрос почти сразу сводится к скорости вывода.
Либо уменьшать кол-во сообщений, либо писать всё в буфер и печатать в конце выполнения, но так, не будет видно на каком этапе идёт выполнение программы.
Самый просто способ это печатать буфер скажем каждые 10,20, 100 сообщений.
операции логики можно сказать ничего не стоят, когда как операция печати очень даже тормозять
В стандартной библиотеке C (на Linux, по крайней мере) когда вывод идет на консоль, стандартные функции вывода (f)printf/(f)puts/fwrite/etc используют line buffering, т.е. каждый символ `\n` приводит к fflush'у. Когда вывод перенаправлен в файл, то по умолчанию full buffering с буфером размера BUFSIZ, но при желании можно установить и свой буфер, побольше.
Смысл в том, что, как я написал в начале, весь вывод идет в файл или даже в /dev/null, так что буферизация там уже есть.
* число делится на 5, если его последняя цифра — 5 или 0
* число делится на 3, если сумма его цифр делится на 3
Операции деления-умножения на современных ЦПУ для чисел до 64 бит(а иногда и более) — это 1 такт, так что косвенные признаки делимости(на 3 в вашем примере) начинают иметь смысл на ОЧЕНЬ больших числах — грубо тысячебитных и более.
чтобы уж совсем стало: ясно беззнаковое 64 бит число — это от 0 до 18,446,744,073,709,551,615
Intel optimization guide 2020 говорит нам на странице 758, что DIVPD(xmm) занимает 14–20 тактов, а MULPD(xmm) — 3–5 тактов. Тут, конечно, деление на константу, которое компилятор превратит в умножение, но всё ещё не один такт. На странице 762 ниже есть числа для некоторых невекторных инструкций, и там тоже не 1 такт.
С остальным, конечно, не поспоришь. Переводить в base10 и использовать признаки делимости из неё никакого смысла.
Для примера — 32бит деление(DIV/UDIV) на весьма тупеньком по нонешним временам ARM Cortex M4 — от 2 до 12 тактов.
Я векторную привёл, потому что для скалярных там пустые клеточки с примечанием, что latency ≈ throughput, как будто нет конвейера. И там div r64 — 80–95, div r32 — 20–26.
Но опять же, поскольку мы делим на константу, то это умножение, т.е. mul r64 с задержкой 3–5 тактов и throughput 1, что уже таки да, близко к 1 такту на операцию, если они хорошо переупорядочатся.
Дело в том, что заранее никогда не знаешь, как они изменятся, и, как показывает опыт, если ты закладываешься на некое возможное изменение какого-то требования. меняется какое-то другое требование, к которому ты не готов. Такая разновидность закона Мэрфи для программистов.
— заменить %3 или %5 на что-то другое
— убрать один из них
— добавить ещё один %N
— поменять надписи «Fizz» или «Buzz» на что-то другое
Чтобы сделать одно из первых изменений во многих примерах придётся много переписывать.
Все неподдерживаемые приседания с шага 2 до многопоточности ускорили код в 4 с небольшим раза. Даже с первого наивного варианта — разница в восемь раз. Современные машины, на которых будет выполняться такой код — уж как-нибудь наделены 4 камнями с гипертредингом.
Если в XXI веке человек начинает с микрооптимизации условных переходов и ручной буферизации, его можно смело отправлять обратно в 1980-й год. Я — от действительно профессионала — ждал бы только многопоточность (и общие слова про низкоуровневую шлифовку надфилем, с комментарием, почему она здесь и сейчас — не только не нужна, но даже вредна).
Что значит «неподдерживаемые»? Где? Если на ARMе или до-Haswell'овских Intel'ах (не помню AMD'шную линейку), то да, но герой оптимизировал под конкретный проц в своем конкретном лаптопе. И если будет задача оптимизации какого-то сервиса, например, то это нормально — учитывать, на какой архитектуре этот сервис бежит. Можно было реализовать как простое побайтовое сравнение, но зачем, если есть векторные инструкции? Тем более герой хотел уесть интервьюера, у него была мотивация.
И ускорение чего-то в 4 и 8 раз — это офигенно хороший результат. Я, бывает, на работе бьюсь неделями, чтобы выжать какие-то 10% из сервиса.
> Если в XXI веке человек начинает с микрооптимизации условных переходов и ручной буферизации, его можно смело отправлять обратно в 1980-й год
Одним махом уменьшить кол-во branch инструкций в 45 раз, и количество вызовов printf'а в 15 раз, что дало ускорение почти в 2 раза — микрооптимизация? Ну ok. Готов к ссылке в 1980, я тогда был сильно моложе :)
Правильно ли я понимаю, что все программы которым нужны оптимизации уже написали в 1980м и новые не нужны?
Нет, вы понимаете неправильно. Я уже имел шанс убедиться, что вы вообще крайне редко понимаете что-нибудь правильно (если тезис хоть немного отличается от вашего мнения).
Вон автор пишет:
Одним махом уменьшить кол-во branch инструкций в 45 раз, и количество вызовов printf’а в 15 раз, что дало ускорение почти в 2 раза — микрооптимизация?Сиречь, автор тоже не понимает, когда нужно полировать свое эго выкрутасами «смотри, как я умею», а когда — нет. Процитирую свой же комментарий, мне не впадлу, может быть, со второго раза зайдет:
Я [...] ждал бы только многопоточность (и общие слова про низкоуровневую шлифовку надфилем, с комментарием, почему она здесь и сейчас — не только не нужна, но даже вредна).
Такая задача не может быть регулярной (и даже если она регулярная, оптимизировать ее нужно не так, и даже не на этом языке). На нормальной машине (у нас же есть доступ в интернет, а тут целое собеседование — можно рублей сто и пожертвовать) — стартуем c5.metal(хотя ладно, не будем Бесоса кормить) — простую c5.12xlarge, — получаем оптимизацию в ≈20 раз.
А не лапшу, которую никто завтра просто не поймет, и не «уменьшение количества branch инструкций», которое требуется в совсем других случаях.
Нет, вы понимаете неправильно. Я уже имел шанс убедиться, что вы вообще крайне редко понимаете что-нибудь правильно (если тезис хоть немного отличается от вашего мнения).
Смелое и необоснованное утверждение, которое больше похоже на завуалированное оскорбление. Любопытно.
Такая задача не может быть регулярной
А на каком языке? Вот есть у меня знакомые в амазоне, в жетбрейнс. Сидит челик такой и на зарплате с профилировщике гоняет апп и тюнит по 2%. По 40 часов в неделю. Наверное дураки просто так ему зп платят
(и даже если она регулярная, оптимизировать ее нужно не так, и даже не на этом языке)
а на каком?
На нормальной машине (у нас же есть доступ в интернет, а тут целое собеседование — можно рублей сто и пожертвовать) — стартуем c5.metal(хотя ладно, не будем Бесоса кормить) — простую c5.12xlarge, — получаем оптимизацию в ≈20 раз.
А в проде тоже будем заказывать c5.metal? Потому что собес внезапно должен отражать навыки, которые требуются на вакансии, а не просто рандомные вопросы с рандомными ответами. Смысл оптимизированного физзбазза не в том чтобы отработать меньше чем за 2с, внезапно, а показать размышления человека и что он будет делать в реальности, когда бизнес его спросит "а нам точно нужен кластер из 100 высокопроизводительных серверов чтобы поднять маргинальный мессенджер?"
> Сиречь, автор тоже не понимает, когда нужно полировать свое эго выкрутасами «смотри, как я умею», а когда — нет.
Не знаю, при чем тут полировка эго. Я писал о том, что не считаю это микрооптимизацией, я считаю, что человек, приходящий на сениорскую позицию, знает стоимость if'а, и если он развернет цикл так, как описано во втором варианте решения, то я (как интервьюер) буду очень доволен.
> На нормальной машине (у нас же есть доступ в интернет, а тут целое собеседование — можно рублей сто и пожертвовать) — стартуем c5.metal(хотя ладно, не будем Бесоса кормить) — простую c5.12xlarge, — получаем оптимизацию в ≈20 раз.
Я считаю (подчеркиваю — это мое мнение), что это очень плохой подход, и он убивает нашу индустрию. «Что-то медленно — давайте накидаем побольше ресурсов» — вы не лоббист облачной мафии? :) Мне кажется, что в первую очередь стоит подумать, как можно оптимизировать на имеющемся железе, и только потом, когда уже упремся, подкидывать процов/памяти. Мы же инженеры!
P.S. Кстати, ускорение в 20 раз на здоровом серваке мы все равно не получим, так как упор скорее всего не в проц, а в память.
Я считаю (подчеркиваю — это мое мнение), что это очень плохой подход, и он убивает нашу индустрию. «Что-то медленно — давайте накидаем побольше ресурсов» — вы не лоббист облачной мафии? :) Мне кажется, что в первую очередь стоит подумать, как можно оптимизировать на имеющемся железе, и только потом, когда уже упремся, подкидывать процов/памяти. Мы же инженеры!
Что-то мне подсказывает, что это зависит от задачи: ресурсов, заказчика проекта, простоты реализации и т.п..
Я считаю (подчеркиваю — это мое мнение), что это очень плохой подход, и он убивает нашу индустрию. «Что-то медленно — давайте накидаем побольше ресурсов» — вы не лоббист облачной мафии? :) Мне кажется, что в первую очередь стоит подумать, как можно оптимизировать на имеющемся железе, и только потом, когда уже упремся, подкидывать процов/памяти. Мы же инженеры!
Это нормальный подход, но и подход оптимизировать тоже. Фанатики придерживающиеся только одного из них до добра не доводят: одни закидывают ресурсами и получают историю parler (500 серваков на 10м юзеров, это не смешно), другие вместо того чтобы докинуть 2 гига памяти сервису месяц изобретают спагетти которое умудряется отработать на текущем железе, а после этого доработку с оценкой 2 дня делают ещё полгода, потому что нужно всё выкинуть и писать заново.
Но если рассматривать её как пример «собеседование на должность сеньора» — всё плохо. Герой не тянет на сеньора. Как мидл — да. Оторвать с обоими руками и вообще «дайте два таких». А сеньору, всё таки, уже нужно по мимо «оптимизация по процессору» и «оптимизация по памяти» еще держать в голове и «оптимизация по деньгам». А если в организации всё плохо, и сеньор еще немного «тимлид» и «архитектор» — то совсем беда.
Поэтому на фразу «Вам не кажется, что можно побыстрее?» нужно было ответить «Кажется. И я знаю как. Но код станет сложнее сопровождать и он будет очень плохо переносим. Это действительно то, что нам нужно?»
Такая задача не может быть регулярной (и даже если она регулярная, оптимизировать ее нужно не так, и даже не на этом языке). На нормальной машине — стартуем c5.metalДа, представляю. Приходит программист в Microsoft делать Excel, ему дают задачу ускорить работу новых лямбд, а всё, что он может — предложить вынести вычисления в Azure. А что? Заодно и облако продадим.
Хм, по личным ощущениям, после использования продуктов MS, видимо они так и делают.
Но я удивился, увидев большое кол-во комментов о том, что не сениорское это дело — такие оптимизации. Мне кажется, есть два взгляда на то, кто такой сениор:
1. Сениор знает методики, пишет простой код с низкой цикломатической сложностью, этот код легко читать и поддерживать. Работает в большой конторе с четкими стандартами, читает на досуге GoF и «чистые» книги от дяди Боба. От джуниора отличается тем, что глубже влезает в предметную область, пишет код, который потом проще развивать. Он знает, где грабли, и обходит их метров за 10, так что нос у него красивый и ровный.
2. Сениор — опытный разработчик, который представляет, что с его кодом сделает компилятор, как он будет исполняться, знает, почему в большинстве случаев массив намного лучше связанного списка, при необходимости умеет в алгоритмы. Работает скорее всего в «бутике». Читает разное — МакКоннела, Ричарда Стивенса, да всякое разное, ну может кроме дяди Боба. От джуниора отличается тем, что занимается самыми сложными и нестандартными задачами, вянет от рутины. Про цикломатическую сложность его лучше не спрашивать, если не хочешь быть посланным куда подальше. Он тоже знает, где грабли, и ловко лавирует между ними, ну иногда получает по носу, как без этого.
Речь не о том, какой взгляд более правильный — скорее всего они оба правильные, просто каждый для своей ситуации. В «кровавом энтырпрайзе» от второго типа будет больше проблем, зато для «бутика» это находка. А когда первый тип приходит в «бутик» и пытается там навести порядок, редко это дает хороший результат, а в большой конторе он — столп. Бытие определяет сознание.
Мне лично ближе второй вариант, и примерно про такого сениора и был мой рассказ.
Лично знаю людей совмещающих оба пункта. Вот уж кого можно смело записывать в сениоры. ИМХО оба навыка важны, как и хард/софтскиллы, например. Знание как спроектировать архитектуру на высоком уровне не умаляет желания поковыряться в "байтиках" с vtune
Ну это очень редкие животные, как единороги. Мне не попадались.
> ИМХО оба навыка важны, как и хард/софтскиллы, например.
Согласен. Но в одних ситуациях важнее одно, а в других — другое. К первому пойдут, когда надо сделать «все красиво», а ко второму, когда надо сделать что-то невозможное.
Шутка, только с половиной шутки. Так как реально сеньор — это тот кого другие считают сеньором. И все. Сколько голов столько и заблуждений. В разных местах у разных людей разные
Что-то тут всё же не совсем однозначно. Думаю, что это 1+2, с упором на пункт 1. Алгоритмы я бы отнёс, если не к пункту 1, то к обоим, МакКоннел — тоже неплохо для всех, а вот с компилятором уже специфический навык.
Компиляторов для одного языка может быть несколько (есть продукты, собирающиеся GCC, CLang и MSVC на CI), да и внутри продукт может быть реализован на разных языках.
Речь не о том, какой взгляд более правильный — скорее всего они оба правильные, просто каждый для своей ситуации. В «кровавом энтырпрайзе» от второго типа будет больше проблем, зато для «бутика» это находка. А когда первый тип приходит в «бутик» и пытается там навести порядок, редко это дает хороший результат, а в большой конторе он — столп. Бытие определяет сознание.
А что мешает совмещать паттерны и эффективный код? Вроде, тут противоречия не предполагалось. Если кто-то приходит в другую контору и "пытается там навести порядок", осознавая зачем (т.е. не береём в расчёт случай "со своим уставом в чужой монастырь", без фанатизма), значит там есть проблемы, снижающие эффективность чего-либо (например, кодовой базы)?
Что такое "бутик"?
Очень часто паттерны (мы же про GoF ?) подразумевают наворачивание дополнительных абстракций, что снижает общую эффективность.
> Если кто-то приходит в другую контору и «пытается там навести порядок», осознавая зачем (т.е. не береём в расчёт случай «со своим уставом в чужой монастырь», без фанатизма), значит там есть проблемы, снижающие эффективность чего-либо (например, кодовой базы)?
К сожалению, на моем опыте это как раз обычно «со своим уставом в чужой монастырь» :( Может, просто не везло.
> Что такое «бутик»?
Обычно подразумевается мелкая контора, скажем, до 10 разработчиков, обычно все довольно высокого уровня, которые пилят какой-то нишевый продукт, сильно заточенный под требования вполне конкретных клиентов (часто этих клиентов немного, но зато high-profile). Сорри, я думал, что это довольно распространенный термин. www.quora.com/What-is-a-boutique-software-development-company-and-what-are-some-examples
Очень часто паттерны (мы же про GoF ?) подразумевают наворачивание дополнительных абстракций, что снижает общую эффективность.
Что насчет бесплатных абстракций? В качестве примера можно привести Option<NonZeroU8>, в котором оптимизатор это сворачивает до простого u8 но на уровне типов гарантирует что к нулю случайно вы не обратитесь
Сорри, я думал, что это довольно распространенный термин
Никогда не слышал, буду знать теперь)
Бесплатные абстракции — отлично!
Честно скажу — в паттернах я слаб, и мне кажется (возможно, неправильно), что большинство абстракций все же «платные», и многие даже такие недешевые.
"Цена" больше определяется скоростью разработки и простотой изменения на поздних этапах разработки и жизненного цикла, как известно.
В C++ огромное количество паттернов строится именно на бесплатных абстракциях. Конечно, не любая абстракция может быть бесплатной, но очень многие могут.
Правда, обильное их использование выливается в долгую компиляцию.
Зависит от языка. Какой-нибудь сишарп или там хаскель — да, там абстракции стоят. А вот весь раст построен вокруг идеи бесплатных абстракций, ИСЧХ у них получается. Те же итераторы такие же (а местами — быстрее) циклов.
Да и IoC, который является краеугольным камнем в enterprise-архитектурах, без которого кодинг в C#/java считается говнокодингом, в c++ не распространён, потому что его нельзя сделать zero-cost, а значит, для программистов c++/rust его просто нет.
ну, it depends (хех). Смысл зирокоста ведь в статье там процитирован:
C++ implementations obey the zero-overhead principle: What you don't use, you don't pay for [Stroustrup, 1994]. And further: What you do use, you couldn't hand code any better.
Диаю не надо быть бесплатным, достаточно чтобы вы не могли руками написать лучше.
И для DI это вполне себе выполняется, если делать его не на тормознутом рефлекшне, а в компайл тайм. В шарпе недавно появился компайл-тайм диай, ничего плохого в нем не вижу. На расте я что-то подобное накрутил в актиксе, тоже жить можно.
компайл-тайм диайВ этом нет большого смысла, потому что популярные di-фреймворки используют кодогенерацию и кеширование. То есть, рефлексируют они столько раз, сколько есть разных целей для внедрения, т.е. все накладные расходы — разовые, незаметные.
Во-первых все равно недешево. Например никакой инлайн офк не сможет сделаться в таком случае.
Во-вторых у меня 90% претензий к диаю в "тип не был зарегистрирован" в рантайме. Рад за разработчиков, у которых всегда один набор зависимостей регистрируются и они при запуске приложения сразу получают все ошибки всех типов которые забыли, но при чуть более сложной конфигурации оказывается что один хитрый сервис в одном хитром аппе иногда требует каку-то зависимость которой нет и упс.
Всё ещё не очень понимаю в чем незирокостность такого диай выходит. Зависимости вам нужны? Нужны. Получать в конструкторе вы их хотите? Хотите. Что ещё-то?:)
Всё ещё не очень понимаю в чем незирокостность такого диай выходитНеправильно вопрос поставлен. Не «такого di», а вообще di. Его незирокостность очевидна — если компонент пользуется другим компонентом через интерфейс, а не реализацию, у компилятора меньше возможностей для оптимизации.
Так просто вместо
public record Foo(IMyInerface bar)вы пишете
public record Foo<T>(T bar) where T : IMyInterfaceИ получаете все оптимизации потому что тип тут будет конкретным всегда. Диай как был так и остался.
public class MyService<L, R>
where L: ILog
where R: IRepo
{
public MyService(L log, R repo)
{
}
}Контейнер и все связи настраиваются при компиляции.
Этот тот compile-time di, о котором вы выше писали? По примерам оттуда, до такой жести они не дошли.
Это никак диая не касается, это вопрос того как сервисы объявлены. Диай просто делает Resolve<MyService>(sc => new MyService(sc.Resolve<ILog, Log>, sc.Resolve<IRepo, Repo>)).
Весь смысл диая в том что до самого верха код выглядит без магии — просто на конструкторах. Все что делает диай- рекурсивно эти конструкторы заполняет. Генерики там или нет ему до лампочки.
Ну и я бы не сказал что это жесть, просто если хотите сэкономить на индирекции пару тактов — то вот так один из примеров как можно сделать.
Очень часто паттерны (мы же про GoF ?) подразумевают наворачивание дополнительных абстракций, что снижает общую эффективность.
В т.ч. про GoF, но абстракции либо более высокоуровневые (внутри особо эффективный код не мешает никто писать), либо нивелируются на уровне реализации (т.е. не обязательно делать много уровней косвенности, например, если возможно использовать её разрешение на этапе компиляции (в каком-нибудь C++ через шаблоны и т.п.), либо реализовать этап постпроцессинга для скриптовых языков, например).
Обычно подразумевается мелкая контора, скажем, до 10 разработчиков, обычно все довольно высокого уровня, которые пилят какой-то нишевый продукт, сильно заточенный под требования вполне конкретных клиентов (часто этих клиентов немного, но зато high-profile). Сорри, я думал, что это довольно распространенный термин. www.quora.com/What-is-a-boutique-software-development-company-and-what-are-some-examples
Понял. Я просто раньше не слышал, чтобы в таком контексте это слово употребляли: "бутик обуви" знаю, а "бутик" в разработке — ни разу не слышал.
Ведь 2й пример дал увеличение производительности в 2 раза при минимуме затрат синьерства.
Для миллиарда уже было бы проще вообще не дергать printf, а просто подготовить сразу буфер с результатом, и его вывести — это уже выше предлагали. Размер программы вырастает на 7.5 Gb. Кстати, подозреваю, что станет сильно медленнее, так как при чтении .data (через memory-mapped I/O) опять же упираемся в кучу page fault'ов, значит переключения user space/kernel space, а это медленно.
Кстати, подозреваю, что станет сильно медленнее, так как при чтении .data (через memory-mapped I/O) опять же упираемся в кучу page fault'ов, значит переключения user space/kernel space, а это медленно.А время загрузки программы засчитывается к времени выполнения? А если с рамдиска запускать, то что будет?
Если засекать время, используя time (я именно так делал), то да, будет. Но вся программа не будет сразу грузится в этом случае, Linux мапит куски исполняемого файла в память, отдельно по сегментам, и в данном случае .data будет отдельно замаплен, и будет подгружаться по мере необходимости (ну как page fault случится), при этом будут использоваться скорее всего стандартные 4K-страницы, так что не исключаю, что каждый раз будет читаться с диска 4K, и это будет страшно медленно. Но я все же надеюсь, что тут есть какие-то оптимизации, и можно страницы читать пачками.
Запуск с RAM-диска, конечно, ускорит чтение, но от page fault'ов никуда не уйти, а это опять переключение user space/kernel space, а с недавних пор, спасибо Meltdown и Spectre, это стало очень дорогой операцией.
Можно же пожать. И подозреваю, что такие регулярные данные пожмутся достаточно неплохо.
Программа превратится в банальный zcat data.gz
Мой FizzBuzz закончился очень быстро, проходил собес в сбере, товарищ помидор не написал в условии, если кратно 15, то выводим FizzBuzz, а отдельно Fizz и Buzz на этом шаге нет, о чем я пошутил и сделал на тернарках 3 вывода, которые всегда срабатывали, думал он поймет что в условии не докопипастил, позже прямо сказал, когда он начал нервничать. А со мной просто попрощались со словами что я должен был сам догадаться))) ну видимо тз там тоже додумывают сами и много чего еще, ибо заказчик всегда прав, а ты дурак
А что, в Сбере спрашивают FizzBuzz? Тогда они скоро узнают про интринсики :D
На фронта спросили) но думаю не факт что у всех спрашивают, задание все таки дефолтное, скорее всего взятое из запроса в гугле «тестовые задания фронтенд», пока hr рассказывала про компанию и печеньки.
Это анекдот или как? Конец придуманный?
Почему это интервьювер вызывал охрану и Вам не рады? А подойти с просить или интервьювер был доволен результатами нельзя было? Мб он говорил, что это был лучший результат, который он видел в его жизни и никто за 1.748 секунд не выводил миллиард, и показывал на Вас пальцем из-за этого?
Только серьезно, пожалуйста.
Порой из институтов часто приходят молодые, но уже очень опытные в части алгоритмов и оптимизации талантливые ребята, которые творят лютый треш в части архитектуры, если на проекте нет кого-то, кто за всем этим проследит (потому что реаллайф). И потом приходится приколачивать это к другим частям проекта метровыми гвоздями. И вот поэтому они — не сеньоры.
О том и речь — задача не должна требовать больше нескольких минут на решение, поэтому и достаточно давать тривиальную, просто чтобы посмотреть как человек умеет взять и написать код. Если он это сделать умеет — то в реальной работе ничто не мешает ему смотреть алгоритмы/формулы/best practices, не экзамен же сдается.
Кстати некоторые мудрые преподаватели сложных дисциплин разрешают пользоваться любыми материалами во время сдачи, т.к. в реальной жизни намного важнее умение быстро найти ответ, чем помнить его наизусть
В C это довольно проблематично сделать ;)
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
char ** fizzBuzz(int n, int* returnSize)А их не было задано
Типичный джун
А тут как-то сидел Силантий во дворе, подсел к нему Колян и тоже про жизнь вопрос задал. Ну, Силантий и начал ему обстоятельно выкладывать, как он по Полкану скучает, как к внуку в гости ездил… Так Колян и половины не выслушал, поднялся со скамейки, по плечу Силантия похлопал и со словами "Ладно, отец, я тороплюсь" прочь пошел. Зачем тогда спрашивал, если послушать нет времени? Спросил бы, когда оно будет.
© Ольга Трушкова "По лабиринту памяти"
Такого вида оптимизации вполне имеют практический смысл. Например, в ClickHouse похожим образом сделана функция formatDateTime:
https://github.com/ClickHouse/ClickHouse/blob/master/src/Functions/formatDateTime.cpp#L54
На моем компьютере (у меня Windows/cygwin, поэтому мне сложно сравнить с вашими результатами напрямую) этот алгоритм работает 1.7 секунд. Я Вам послал пул реквест, было бы интересно узнать, будет ли он обгонять reusebuffer в ваших тестах. Правда, сейчас он работает только для LIMIT = 10^k, но, думаю, его можно доделать для любого диапазона чисел без ухудшения производительности.
#include <stdio.h>
#include <string.h>
#define LIMIT 1000000000
char *FIZZ = "Fizz";
char *BUZZ = "Buzz";
struct Segment {
char buffer[4096]; // 100 numbers
int buffer_length;
int positions[100]; // offsets in buffer1 of third digit of all numbers
int positions_length; // number of items in positions
};
int get_number_length(int number) {
int number_length = 1;
while (number >= 10) {
number /= 10;
number_length++;
}
return number_length;
}
char* print_number(int number, int numberLength, char* buf) {
for(int i = 0; i < numberLength; i++) {
int digit = number % 10;
buf[numberLength - i - 1] = (digit + '0');
number /= 10;
}
buf[numberLength] = '\n';
return buf + numberLength + 1;
}
char* print_fizz(char* buf) {
*(int*)buf = *(int*)FIZZ;
buf[4] = '\n';
return buf + 5;
}
char *print_buzz(char *buf) {
*(int *)buf = *(int *)BUZZ;
buf[4] = '\n';
return buf + 5;
}
char *print_fizz_buzz(char *buf) {
*(int *)buf = *(int *)FIZZ;
*(int *)(buf + 4) = *(int *)BUZZ;
buf[8] = '\n';
return buf + 9;
}
char *print(int num, int num_length, char *ptr) {
if (num_length == -1)
num_length = get_number_length(num);
if (num % 15 == 0)
ptr = print_fizz_buzz(ptr);
else if (num % 3 == 0)
ptr = print_fizz(ptr);
else if (num % 5 == 0)
ptr = print_buzz(ptr);
else
ptr = print_number(num, num_length, ptr);
return ptr;
}
char *print_first_segment(char *ptr) {
for(int num = 1; num < 100; num++)
ptr = print(num, -1, ptr);
return ptr;
}
char *print_last_number(char *ptr) {
return print(LIMIT, -1, ptr);
}
void print_initial_segment(int first_number, struct Segment* segment) {
int digits = get_number_length(first_number);
segment->positions_length = 0;
char *ptr = segment->buffer;
for (int i = first_number; i < first_number + 100; i++) {
ptr = print(i, digits, ptr);
if (i % 3 != 0 && i % 5 != 0)
segment->positions[segment->positions_length++] = ptr - segment->buffer - 4;
}
segment->buffer_length = ptr - segment->buffer;
}
void print_initial_segments(int segment, struct Segment* s1, struct Segment* s2, struct Segment* s3) {
print_initial_segment(segment, s1);
print_initial_segment(segment + 100, s2);
print_initial_segment(segment + 200, s3);
}
void next(struct Segment* s) {
char c = s->buffer[s->positions[0]];
char nextC = c + 3;
if(c < '7') {
for (int i = 0; i < s->positions_length; i++)
s->buffer[s->positions[i]] = nextC;
} else if (s->buffer[s->positions[0] - 1] < '9') {
nextC -= 10;
int nextD = s->buffer[s->positions[0] - 1] + 1;
for (int i = 0; i < s->positions_length; i++) {
s->buffer[s->positions[i]] = nextC;
s->buffer[s->positions[i] - 1] = nextD;
}
} else {
nextC -= 10;
for (int i = 0; i < s->positions_length; i++) {
int pos = s->positions[i];
s->buffer[pos--] = nextC;
while(s->buffer[pos] == '9')
s->buffer[pos--] = '0';
s->buffer[pos]++;
}
}
}
int main(void) {
char* ptr;
struct Segment s1, s2, s3;
ptr = print_first_segment(s1.buffer);
fwrite(s1.buffer, 1, ptr - s1.buffer, stdout);
for (int segment = 100; segment < LIMIT; segment *= 10) {
print_initial_segments(segment, &s1, &s2, &s3);
fwrite(s1.buffer, 1, s1.buffer_length, stdout);
fwrite(s2.buffer, 1, s2.buffer_length, stdout);
fwrite(s3.buffer, 1, s3.buffer_length, stdout);
int repeat_count = 3 * (segment / 100);
for(int i = 1; i < repeat_count; i++) {
next(&s1);
next(&s2);
next(&s3);
fwrite(s1.buffer, 1, s1.buffer_length, stdout);
fwrite(s2.buffer, 1, s2.buffer_length, stdout);
fwrite(s3.buffer, 1, s3.buffer_length, stdout);
}
}
ptr = print_last_number(s1.buffer);
fwrite(s1.buffer, 1, ptr - s1.buffer, stdout);
return 0;
}
FizzBuzz по-сениорски