Умы Силиконовой долины неустанно автоматизируют всё, что попадается им на глаза. На этот раз пьедестал их бессонных ночей занял Auto-GPT.
Auto-GPT — продвинутая система искусственного интеллекта, которая использует новейшие алгоритмы компании OpenAI для взаимодействия с программами и сервисами в Интернете. Она позволяет выполнять различные задачи в режиме автономности.
Однако, несмотря на мощность этой системы, она все ещё находится в процессе обучения и развития, и её возможности не столь широки. Аналогично океану, алгоритм Auto-GPT обладает широкими возможностями, но его познания в некоторых областях могут быть ограничены, подобно небольшой луже.
Отец-основатель и суперсила
Auto-GPT — открытый исходный код, написанный разработчиком игр Тораном Брюсом Ричардсом. Создатель совместил воедино GPT-3.5 и GPT-4 и приставил к ним бота-компаньона, который даёт им инструкции.
Торан Брюс Ричардс наделили Auto-GPT способностью взаимодействовать с другими приложениями, программным обеспечением и службами. Например, если вы отправите Auto-GPT запрос в духе «помоги мне развить мой бизнес в нише молодёжной одежды», он предоставит вам подробную рекламную стратегию и создаст веб-сайт для первого старта.
Вот, что пишет о Auto-GPT предприниматель Дэниел Крафт:
«AutoGPT — это новый подрывной ребенок в блоке. Он может применять рассуждения ChatGPT к более широким, сложным проблемам, требующим планирования и множества шагов.
Пока ещё рано что-то говорить, но это очень впечатляет — много приложений для здравоохранения и биомедицины.



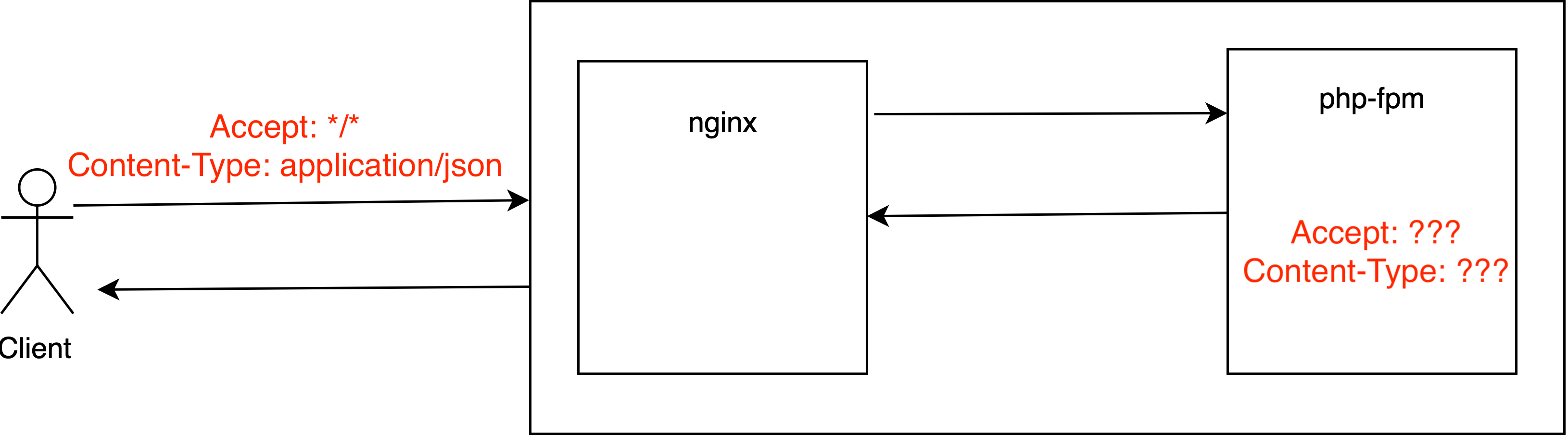

 Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?
Только не удивляйтесь, но второй заголовок к этому посту сгенерировала нейросеть, а точнее алгоритм саммаризации. А что такое саммаризация?





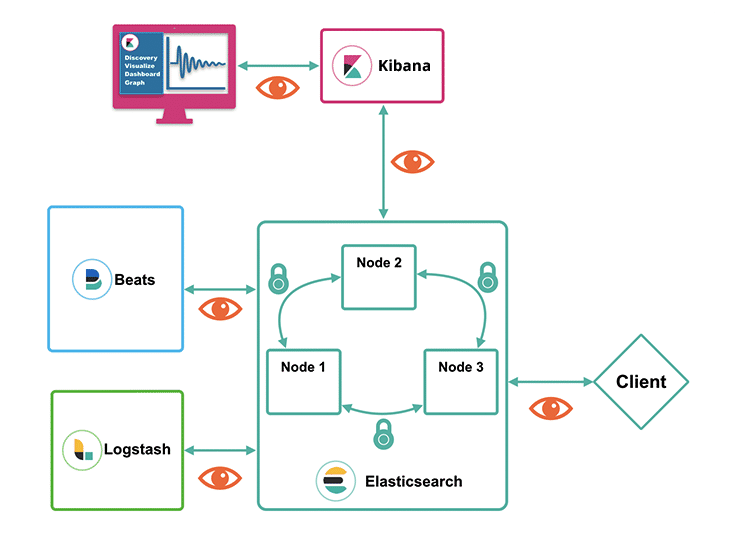
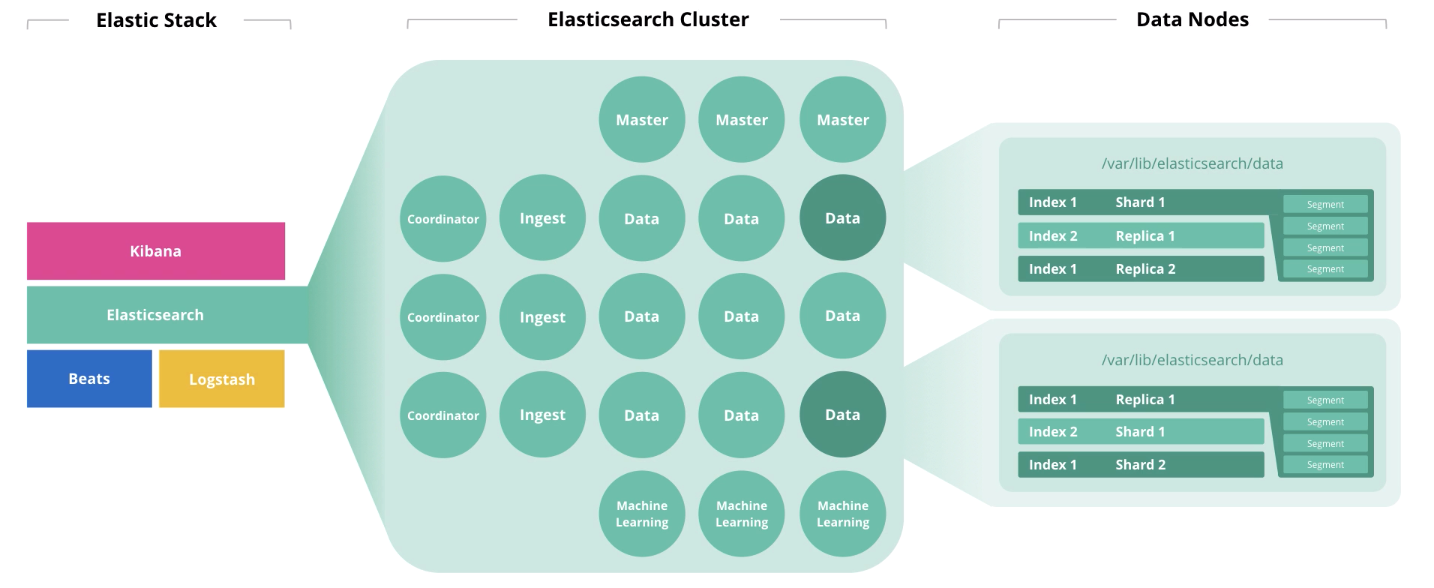
 Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.
Elasticsearch, вероятно, самая популярная поисковая система на данный момент с развитым сообществом, поддержкой и горой информации в сети. Однако эта информация поступает непоследовательно и дробно.